

Knowledge Graph: der ideale Partner für große Modelle

Großformatige Sprachmodelle (LLM) sind in der Lage, flüssige und kohärente Texte zu generieren, was neue Perspektiven für Bereiche wie den Dialog mit künstlicher Intelligenz und kreatives Schreiben eröffnet. Allerdings weist LLM auch einige wesentliche Einschränkungen auf. Erstens beschränkt sich ihr Wissen auf Muster, die aus Trainingsdaten erkannt werden, und es mangelt ihnen an einem echten Verständnis der Welt. Zweitens sind die Denkfähigkeiten begrenzt und können keine logischen Schlussfolgerungen ziehen oder Fakten aus mehreren Datenquellen zusammenführen. Bei komplexeren und offeneren Fragen können die Antworten von LLM absurd oder widersprüchlich werden, was als „Illusionen“ bekannt ist. Obwohl LLM in einigen Aspekten sehr nützlich ist, weist es dennoch gewisse Einschränkungen bei der Bearbeitung komplexer Probleme und realer Situationen auf.
Um diese Lücken zu schließen, sind in den letzten Jahren Retrieval Augmented Generation (RAG)-Systeme entstanden, deren Kernidee darin besteht, LLM Kontext bereitzustellen, indem relevantes Wissen aus externen Quellen abgerufen wird, um fundiertere Antworten zu geben. Aktuelle Systeme verwenden zum Abrufen von Passagen meist semantische Ähnlichkeit von Vektoreinbettungen. Dieser Ansatz weist jedoch seine eigenen Mängel auf, wie z. B. das Fehlen einer echten Korrelation, die Unfähigkeit, Fakten zu aggregieren, und das Fehlen von Inferenzketten. Die Anwendungsgebiete von Wissensgraphen können diese Probleme lösen. Der Wissensgraph ist eine strukturierte Darstellung realer Entitäten und Beziehungen. Durch die Kodierung der Zusammenhänge zwischen kontextuellen Fakten überwinden Wissensgraphen die Mängel der reinen Vektorsuche, und die Graphensuche ermöglicht komplexe mehrstufige Argumentationen über mehrere Informationsquellen hinweg.
Die Kombination aus Vektoreinbettung und Wissensgraph kann die Argumentationsfähigkeit von LLM verbessern und seine Genauigkeit und Interpretierbarkeit verbessern. Diese Partnerschaft verbindet Oberflächensemantik perfekt mit strukturiertem Wissen und Logik und ermöglicht es LLM, statistisches Lernen und symbolische Darstellung gleichzeitig anzuwenden.
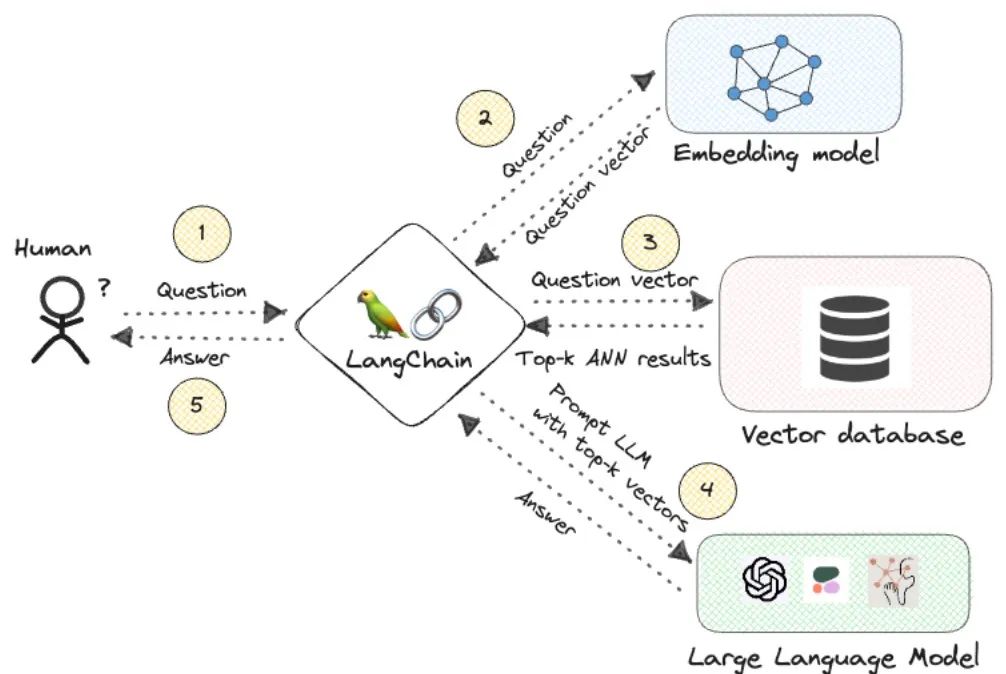 Bilder
Bilder
1. Einschränkungen der Vektorsuche
Die meisten RAG-Systeme finden den Kontext von LLM durch die Vektorsuche von Passagen in einer Sammlung von Dokumenten. In diesem Prozess gibt es mehrere wichtige Schritte.
- Textkodierung: Das System verwendet ein Einbettungsmodell wie BERT, um Text aus Absätzen im Korpus in Vektordarstellungen zu kodieren. Jeder Artikel wird in einen dichten Vektor komprimiert, um die Semantik zu erfassen.
- Index: Diese Kanalvektoren werden in einem hochdimensionalen Vektorraum indiziert, um eine schnelle Suche nach nächsten Nachbarn zu ermöglichen. Beliebte Methoden sind unter anderem Faiss und Pinecone.
- Abfragekodierung: Die Abfrageanweisung des Benutzers wird mithilfe desselben Einbettungsmodells auch in eine Vektordarstellung kodiert.
- Ähnlichkeitsabfrage: Eine Nächste-Nachbarn-Suche wird über die indizierten Absätze ausgeführt, wobei die Absätze, die dem Abfragevektor am nächsten liegen, basierend auf einer Distanzmetrik (z. B. Kosinusdistanz) gefunden werden.
- Absatzergebnisse zurückgeben: Gibt den ähnlichsten Absatzvektor zurück und extrahiert den Originaltext, um Kontext für LLM bereitzustellen.
Diese Pipeline weist mehrere wesentliche Einschränkungen auf:
- Kanalvektoren erfassen möglicherweise nicht vollständig die semantische Absicht der Abfrage, Einbettungen können bestimmte Inferenzverbindungen nicht darstellen und wichtiger Kontext wird letztendlich ignoriert.
- Durch das Zusammenfassen eines gesamten Absatzes in einem einzigen Vektor gehen Nuancen verloren und wichtige, im Satz eingebettete relevante Details werden unscharf.
- Der Abgleich erfolgt unabhängig für jeden Absatz, es gibt keine gemeinsame Analyse über verschiedene Absätze hinweg und es mangelt an der Verknüpfung von Fakten und der Erzielung von Antworten, die aggregiert werden müssen.
- Der Ranking- und Matching-Prozess ist undurchsichtig, es gibt keine Transparenz darüber, warum bestimmte Passagen als relevanter angesehen werden.
- Nur semantische Ähnlichkeit wird kodiert, Beziehungen, Strukturen, Regeln und andere Inhalte zwischen unterschiedlichen Zusammenhängen werden nicht dargestellt.
- Ein einziger Fokus auf semantische Vektorähnlichkeit führt zu einem Mangel an wirklichem Verständnis beim Abrufen.
Je komplexer die Abfragen werden, desto offensichtlicher werden diese Einschränkungen in der Unfähigkeit, über den abgerufenen Inhalt nachzudenken.
2. Wissensgraph integrieren
Wissensgraph basiert auf Entitäten und Beziehungen, überträgt Informationen über miteinander verbundene Netzwerke und verbessert die Abruffähigkeiten durch komplexe Argumentation.
- Explizite Fakten Fakten werden direkt als Knoten und Kanten erfasst und nicht in undurchsichtige Vektoren komprimiert, wodurch wichtige Details erhalten bleiben.
- Kontextdetails, Entitäten enthalten umfangreiche Attribute wie Beschreibungen, Aliase und Metadaten, die wichtigen Kontext bereitstellen.
- Die Netzwerkstruktur drückt die tatsächlichen Verbindungen, Erfassungsregeln, Hierarchien, Zeitpläne usw. zwischen Beziehungsmodellierungseinheiten aus.
- Mehrstufiges Denken basiert auf der Durchquerung von Beziehungen und der Verknüpfung von Fakten aus verschiedenen Quellen, um Antworten abzuleiten, die eine Argumentation über mehrere Schritte hinweg erfordern.
- Gemeinsames Denken verbindet sich durch Entitätsauflösung mit denselben realen Objekten und ermöglicht so eine kollektive Analyse.
- Interpretierbare Korrelation, Diagrammtopologie bietet eine Transparenz, die erklären kann, warum bestimmte basierte Fakten aufgrund Zusammenhängen relevant sind.
- Personalisierung, Erfassung von Benutzerattributen, Kontext und historischen Interaktionen, um maßgeschneiderte Ergebnisse zu erzielen.
Der Wissensgraph ist nicht nur eine einfache Übereinstimmung, sondern ein Prozess des Durchlaufens des Graphen, um kontextbezogene Fakten im Zusammenhang mit der Abfrage zu sammeln. Interpretierbare Ranking-Methoden nutzen die Topologie von Diagrammen, um die Abruffähigkeiten durch die Kodierung strukturierter Fakten, Beziehungen und Kontexte zu verbessern und so eine genaue mehrstufige Schlussfolgerung zu ermöglichen. Dieser Ansatz bietet im Vergleich zu reinen Vektorsuchen eine größere Korrelation und Erklärungskraft.
3. Verwenden Sie einfache Einschränkungen, um die Einbettung von Wissensgraphen zu verbessern.Die Einbettung von Wissensgraphen in einen kontinuierlichen Vektorraum ist ein aktueller Forschungsschwerpunkt. Wissensgraphen nutzen Vektoreinbettungen zur Darstellung von Entitäten und Beziehungen zur Unterstützung mathematischer Operationen. Darüber hinaus können zusätzliche Einschränkungen die Darstellung weiter optimieren.
- Nicht-Negativitätsbeschränkungen, die die Einbettung von Entitäten auf positive Werte zwischen 0 und 1 beschränken, führen zu Sparsität, modellieren explizit ihre positive Natur und verbessern die Interpretierbarkeit.
- Implikationsbeschränkungen kodieren logische Regeln wie Symmetrie, Inversion, Zusammensetzung usw. direkt in relational eingebettete Beschränkungen, um diese Muster durchzusetzen.
- Konfidenzmodellierung, weiche Einschränkungen mit Slack-Variablen können die Konfidenz logischer Regeln auf der Grundlage von Beweisen kodieren.
- Regularisierung, die eine nützliche induktive Vorspannung auferlegt und nur einen Projektionsschritt hinzufügt, ohne die Optimierung komplexer zu machen.
- Interpretierbarkeit und strukturierte Einschränkungen sorgen für Transparenz für die vom Modell gelernten Muster, was den Inferenzprozess erklärt.
- Genauigkeit und Einschränkung verbessern die Generalisierung, indem sie den Hypothesenraum auf eine Darstellung reduzieren, die den Anforderungen entspricht.
Einfache und universelle Einschränkungen werden der Einbettung des Wissensgraphen hinzugefügt, was zu einer optimierteren, einfacher zu interpretierenden und logisch kompatiblen Darstellung führt. Einbettungen erhalten induktive Verzerrungen, die Strukturen und Regeln der realen Welt nachahmen, ohne viel zusätzliche Komplexität für genauere und interpretierbarere Überlegungen mit sich zu bringen.
4. Integrieren Sie mehrere ArgumentationsrahmenWissensdiagramme erfordern Argumentation, um neue Fakten abzuleiten, Fragen zu beantworten und Vorhersagen zu treffen:
Logische Regeln drücken Wissen als logische Axiome und Ontologien aus, vernünftig und sinnvoll vollständige Argumentation durch Theorembeweise und begrenzte Unsicherheitsverarbeitung. Bei der Grapheinbettung handelt es sich um eine eingebettete Wissensgraphenstruktur, die für Vektorraumoperationen verwendet wird und mit Unsicherheit umgehen kann, aber nicht ausdrucksstark ist. Neuronale Netze in Kombination mit Vektorsuchen sind adaptiv, die Schlussfolgerung ist jedoch undurchsichtig. Regeln können automatisch durch statistische Analyse der Diagrammstruktur und der Daten erstellt werden, die Qualität ist jedoch ungewiss. Hybride Pipelines kodieren explizite Einschränkungen durch logische Regeln, Einbettungen stellen Vektorraumoperationen bereit und neuronale Netze profitieren durch gemeinsames Training von den Vorteilen der Fusion. Nutzen Sie fallbasierte, Fuzzy- oder probabilistische Logikmethoden, um die Transparenz zu erhöhen, Unsicherheit auszudrücken und das Vertrauen in Regeln zu stärken. Erweitern Sie Ihr Wissen, indem Sie abgeleitete Fakten und erlernte Regeln in Diagramme umsetzen und so eine Rückkopplungsschleife schaffen.
Der Schlüssel besteht darin, die erforderlichen Inferenztypen zu identifizieren und sie auf geeignete Techniken abzubilden, indem logische Formen, Vektordarstellungen und zusammensetzbare Pipelines neuronaler Komponenten kombiniert werden, um Robustheit und Interpretierbarkeit zu gewährleisten.
4.1 Aufrechterhaltung des Informationsflusses von LLM
Das Abrufen von Fakten im Wissensgraphen für LLM führt zu Informationsengpässen, die konstruktionsbedingt aufrechterhalten werden müssen, um die Relevanz aufrechtzuerhalten. Durch das Aufteilen von Inhalten in kleine Abschnitte wird die Isolation verbessert, es geht jedoch der umgebende Kontext verloren, was die Argumentation zwischen Abschnitten erschwert. Durch die Generierung von Blockzusammenfassungen wird der Kontext prägnanter, wobei wichtige Details komprimiert werden, um die Bedeutung hervorzuheben. Fügen Sie Zusammenfassungen, Titel, Tags usw. als Metadaten hinzu, um den Kontext zum Quellinhalt beizubehalten. Durch das Umschreiben der ursprünglichen Abfrage in eine detailliertere Version kann der Abruf besser auf die Anforderungen des LLM ausgerichtet werden. Die Durchquerungsfunktion des Wissensgraphen hält die Verbindung zwischen Fakten aufrecht und behält den Kontext bei. Durch chronologisches Sortieren oder Sortieren nach Relevanz kann die Informationsstruktur des LLM optimiert werden, und die Umwandlung impliziten Wissens in explizite, für das LLM angegebene Fakten kann die Argumentation erleichtern.
Das Ziel besteht darin, die Relevanz, den Kontext, die Struktur und den expliziten Ausdruck des abgerufenen Wissens zu optimieren, um die Denkfähigkeit zu maximieren. Es muss ein Gleichgewicht zwischen Granularität und Kohäsion gefunden werden. Knowledge-Graph-Beziehungen helfen dabei, einen Kontext für isolierte Fakten aufzubauen.
4.2 Denkfähigkeiten freischalten
Die Kombination von Wissensgraphen und eingebetteter Technologie hat den Vorteil, dass die Schwächen des jeweils anderen überwunden werden.
Wissensdiagramm bietet einen strukturierten Ausdruck von Entitäten und Beziehungen. Verbessern Sie komplexe Argumentationsfunktionen durch Traversierungsfunktionen und verarbeiten Sie mehrstufiges Denken; die Einbettung kodiert Informationen für ähnlichkeitsbasierte Operationen im Vektorraum, unterstützt eine effektive Näherungssuche in einem bestimmten Maßstab und deckt potenzielle Muster auf. Durch die gemeinsame Kodierung werden Einbettungen für Entitäten und Beziehungen in Wissensgraphen generiert. Graphische neuronale Netze bearbeiten Graphstrukturen und eingebettete Elemente über differenzierbare Nachrichtenübermittlung.
Der Wissensgraph sammelt zunächst strukturiertes Wissen und bettet dann eine auf verwandte Inhalte ausgerichtete Suche und Abfrage ein. Explizite Wissensgraph-Beziehungen sorgen für Interpretierbarkeit für den Argumentationsprozess. Abgeleitetes Wissen kann auf Diagramme ausgeweitet werden, und GNNs ermöglichen das Lernen kontinuierlicher Darstellungen.
Diese Partnerschaft erkennt man am Muster! Die Skalierbarkeit von Kräften und neuronalen Netzen verbessert die Darstellung strukturierten Wissens. Dies ist der Schlüssel zum Bedarf an statistischem Lernen und symbolischer Logik, um die sprachliche KI voranzutreiben.
4.3 Verwenden Sie kollaborative Filterung, um die Suche zu verbessern.
Die kollaborative Filterung nutzt die Verbindungen zwischen Entitäten, um die Suche zu verbessern. Der allgemeine Prozess ist wie folgt:
- Erstellen Sie einen Wissensgraphen, in dem Knoten Entitäten und Kanten Beziehungen darstellen.
- Generieren Sie einen Einbettungsvektor für bestimmte Schlüsselknotenattribute (wie Titel, Beschreibung usw.).
- Vektorindex – Erstellt einen Vektorähnlichkeitsindex von Knoteneinbettungen.
- Suche nach nächsten Nachbarn – Finden Sie für eine Suchabfrage Knoten mit den ähnlichsten Einbettungen.
- Kollaborative Anpassung – Knotenbasierte Verbindungen unter Verwendung von Algorithmen wie PageRank, um Ähnlichkeitswerte zu verbreiten und anzupassen.
- KantengewichtーPassen Sie das Gewicht je nach Kantentyp, Stärke, Selbstvertrauen usw. an.
- Score-Normalisierung ーーNormalisiert angepasste Scores, um relative Rankings beizubehalten.
- Ergebnisse neu geordnetーーErste Ergebnisse neu geordnet basierend auf angepassten Kollaborationsergebnissen.
- Benutzerkontextーーweiter abgestimmt auf Benutzerprofil, Verlauf und Präferenzen.
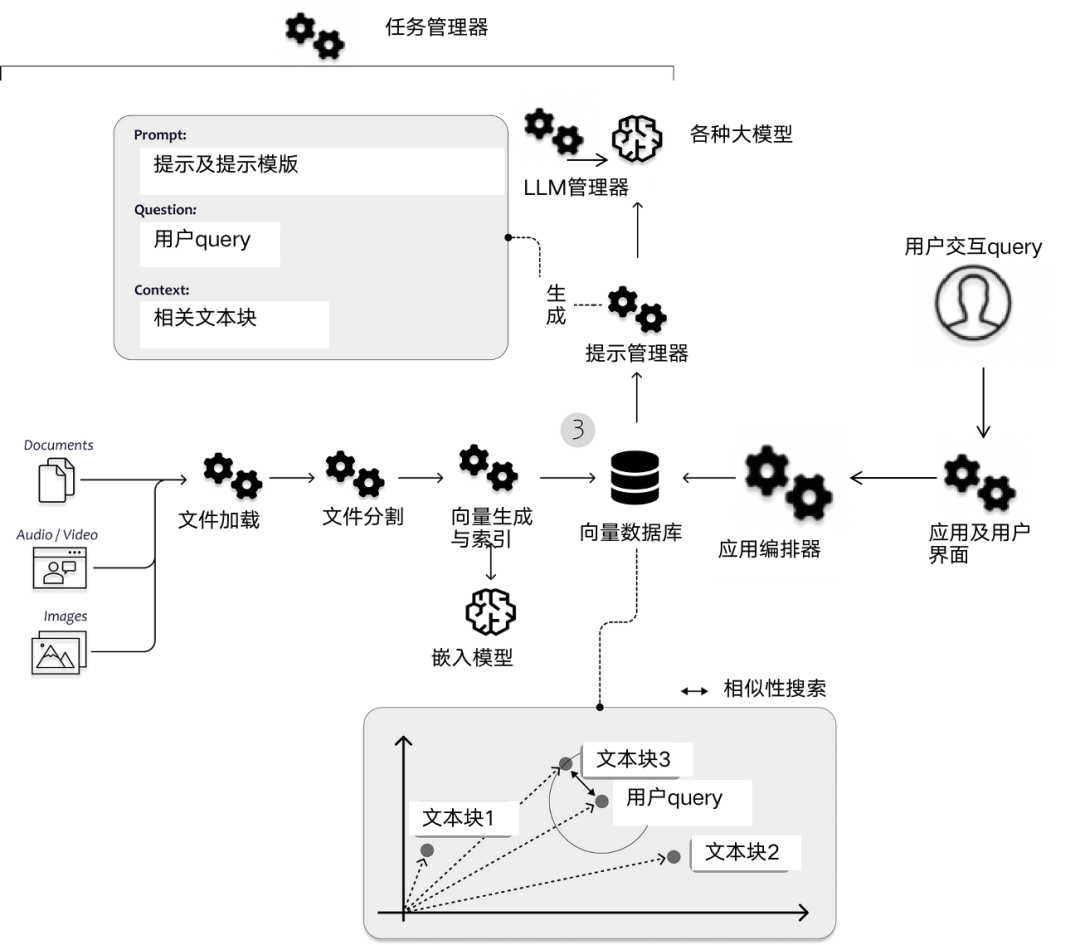 Bilder
Bilder
5. Befeuerung der RAG-Engine – Datenschwungrad
Der Aufbau eines immer besser werdenden, leistungsstarken Retrieval Augmentation Generation (RAG)-Systems erfordert möglicherweise die Implementierung eines Datenschwungrads. Wissensgraphen erschließen neue Argumentationsfähigkeiten für Sprachmodelle, indem sie strukturiertes Weltwissen bereitstellen. Die Erstellung qualitativ hochwertiger Karten bleibt jedoch eine Herausforderung. Hier kommt das Datenschwungrad ins Spiel, indem es Systeminteraktionen analysiert, um den Wissensgraphen kontinuierlich zu verbessern.
Protokollieren Sie alle Systemabfragen, Antworten, Bewertungen, Benutzeraktionen und mehr, um Einblick in die Verwendung des Wissensgraphen zu erhalten. Nutzen Sie die Datenaggregation, um fehlerhafte Antworten aufzudecken, gruppieren und analysieren Sie diese Antworten, um Muster zu identifizieren, die auf Wissenslücken hinweisen. Überprüfen Sie manuell problematische Systemreaktionen und führen Sie Probleme auf fehlende oder falsche Fakten in der Karte zurück. Ändern Sie dann das Diagramm direkt, um die fehlenden Sachdaten hinzuzufügen, die Struktur zu verbessern, die Klarheit zu verbessern und vieles mehr. Die oben genannten Schritte werden in einer kontinuierlichen Schleife ausgeführt und jede Iteration verbessert den Wissensgraphen weiter.
Das Streamen von Echtzeit-Datenquellen wie Nachrichten und sozialen Medien sorgt für einen ständigen Fluss neuer Informationen, um den Wissensgraphen auf dem neuesten Stand zu halten. Die Verwendung der Abfragegenerierung zur Identifizierung und Schließung kritischer Wissenslücken geht über den Rahmen der Möglichkeiten von Streaming hinaus. Finden Sie Lücken in der Grafik, stellen Sie Fragen, rufen Sie fehlende Fakten ab und ergänzen Sie sie. Für jeden Zyklus wird der Wissensgraph schrittweise verbessert, indem Nutzungsmuster analysiert und Datenprobleme behoben werden. Der verbesserte Graph steigert die Leistung des Systems.
Dieser Schwungradprozess ermöglicht die gemeinsame Entwicklung von Wissensgraphen und Sprachmodellen auf der Grundlage des Feedbacks aus der realen Nutzung. Karten werden aktiv an die Anforderungen des Modells angepasst.
Kurz gesagt bietet das Datenschwungrad ein Gerüst für die kontinuierliche und automatische Verbesserung des Wissensgraphen durch die Analyse von Systeminteraktionen. Dies fördert die Genauigkeit, Relevanz und Anpassungsfähigkeit graphabhängiger Sprachmodelle.
6. Zusammenfassung
Künstliche Intelligenz muss externes Wissen und Argumentation kombinieren, und hier kommt der Wissensgraph ins Spiel. Wissensgraphen bieten strukturierte Darstellungen realer Entitäten und Beziehungen und kodieren Fakten über die Welt und die Verbindungen zwischen ihnen. Dies ermöglicht komplexes logisches Denken über mehrere Schritte hinweg, indem diese miteinander verbundenen Fakten durchlaufen werden.
Wissensgraphen haben jedoch ihre eigenen Einschränkungen wie Sparsität und mangelnde Unsicherheitsbehandlung, und hier helfen Grapheinbettungen bei der Lokalisierung. Durch die Kodierung von Elementen von Wissensgraphen im Vektorraum ermöglichen Einbettungen statistisches Lernen von großen Korpora bis hin zu Darstellungen latenter Muster und ermöglichen außerdem effiziente, auf Ähnlichkeit basierende Operationen.
Weder Wissensgraphen noch Vektoreinbettungen allein reichen aus, um eine menschenähnliche Sprachintelligenz zu bilden, aber zusammen bieten sie eine effektive Kombination aus strukturierter Wissensdarstellung, logischem Denken und statistischem Lernen, und der Wissensgraph deckt das darüber hinausgehende neuronale Netzwerkmodell ab Die Fähigkeit, symbolische Logik und Beziehungen zu erkennen, Techniken wie graphische neuronale Netze vereinheitlichen diese Ansätze durch Informationsübertragungsgraphenstrukturen und -einbettungen weiter. Diese symbiotische Beziehung ermöglicht es dem System, sowohl statistisches Lernen als auch symbolische Logik zu nutzen und so die Vorteile neuronaler Netze und strukturierter Wissensdarstellung zu kombinieren.
Es gibt immer noch Herausforderungen bei der Erstellung hochwertiger Wissensdiagramme, Benchmark-Tests, Rauschverarbeitung usw. Hybridtechnologien, die symbolische und neuronale Netze umfassen, bleiben jedoch vielversprechend. Da sich Wissensgraphen und Sprachmodelle weiterentwickeln, wird ihre Integration neue Bereiche erklärbarer KI eröffnen.
Das obige ist der detaillierte Inhalt vonKnowledge Graph: der ideale Partner für große Modelle. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1371
1371
 52
52

 Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Diese Seite berichtete am 27. Juni, dass Jianying eine von FaceMeng Technology, einer Tochtergesellschaft von ByteDance, entwickelte Videobearbeitungssoftware ist, die auf der Douyin-Plattform basiert und grundsätzlich kurze Videoinhalte für Benutzer der Plattform produziert Windows, MacOS und andere Betriebssysteme. Jianying kündigte offiziell die Aktualisierung seines Mitgliedschaftssystems an und führte ein neues SVIP ein, das eine Vielzahl von KI-Schwarztechnologien umfasst, wie z. B. intelligente Übersetzung, intelligente Hervorhebung, intelligente Verpackung, digitale menschliche Synthese usw. Preislich beträgt die monatliche Gebühr für das Clipping von SVIP 79 Yuan, die Jahresgebühr 599 Yuan (Hinweis auf dieser Website: entspricht 49,9 Yuan pro Monat), das fortlaufende Monatsabonnement beträgt 59 Yuan pro Monat und das fortlaufende Jahresabonnement beträgt 499 Yuan pro Jahr (entspricht 41,6 Yuan pro Monat). Darüber hinaus erklärte der Cut-Beamte auch, dass diejenigen, die den ursprünglichen VIP abonniert haben, das Benutzererlebnis verbessern sollen
 Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Verbessern Sie die Produktivität, Effizienz und Genauigkeit der Entwickler, indem Sie eine abrufgestützte Generierung und ein semantisches Gedächtnis in KI-Codierungsassistenten integrieren. Übersetzt aus EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, Autor JanakiramMSV. Obwohl grundlegende KI-Programmierassistenten natürlich hilfreich sind, können sie oft nicht die relevantesten und korrektesten Codevorschläge liefern, da sie auf einem allgemeinen Verständnis der Softwaresprache und den gängigsten Mustern beim Schreiben von Software basieren. Der von diesen Coding-Assistenten generierte Code eignet sich zur Lösung der von ihnen zu lösenden Probleme, entspricht jedoch häufig nicht den Coding-Standards, -Konventionen und -Stilen der einzelnen Teams. Dabei entstehen häufig Vorschläge, die geändert oder verfeinert werden müssen, damit der Code in die Anwendung übernommen wird
 Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Um mehr über AIGC zu erfahren, besuchen Sie bitte: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou unterscheidet sich von der traditionellen Fragendatenbank, die überall im Internet zu sehen ist erfordert einen Blick über den Tellerrand hinaus. Large Language Models (LLMs) gewinnen in den Bereichen Datenwissenschaft, generative künstliche Intelligenz (GenAI) und künstliche Intelligenz zunehmend an Bedeutung. Diese komplexen Algorithmen verbessern die menschlichen Fähigkeiten, treiben Effizienz und Innovation in vielen Branchen voran und werden zum Schlüssel für Unternehmen, um wettbewerbsfähig zu bleiben. LLM hat ein breites Anwendungsspektrum und kann in Bereichen wie der Verarbeitung natürlicher Sprache, der Textgenerierung, der Spracherkennung und Empfehlungssystemen eingesetzt werden. Durch das Lernen aus großen Datenmengen ist LLM in der Lage, Text zu generieren
 Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) werden auf riesigen Textdatenbanken trainiert und erwerben dort große Mengen an realem Wissen. Dieses Wissen wird in ihre Parameter eingebettet und kann dann bei Bedarf genutzt werden. Das Wissen über diese Modelle wird am Ende der Ausbildung „verdinglicht“. Am Ende des Vortrainings hört das Modell tatsächlich auf zu lernen. Richten Sie das Modell aus oder verfeinern Sie es, um zu erfahren, wie Sie dieses Wissen nutzen und natürlicher auf Benutzerfragen reagieren können. Aber manchmal reicht Modellwissen nicht aus, und obwohl das Modell über RAG auf externe Inhalte zugreifen kann, wird es als vorteilhaft angesehen, das Modell durch Feinabstimmung an neue Domänen anzupassen. Diese Feinabstimmung erfolgt mithilfe von Eingaben menschlicher Annotatoren oder anderer LLM-Kreationen, wobei das Modell auf zusätzliches Wissen aus der realen Welt trifft und dieses integriert
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
 SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
Herausgeber |. KX Im Bereich der Arzneimittelforschung und -entwicklung ist die genaue und effektive Vorhersage der Bindungsaffinität von Proteinen und Liganden für das Arzneimittelscreening und die Arzneimitteloptimierung von entscheidender Bedeutung. Aktuelle Studien berücksichtigen jedoch nicht die wichtige Rolle molekularer Oberflächeninformationen bei Protein-Ligand-Wechselwirkungen. Auf dieser Grundlage schlugen Forscher der Universität Xiamen ein neuartiges Framework zur multimodalen Merkmalsextraktion (MFE) vor, das erstmals Informationen über Proteinoberfläche, 3D-Struktur und -Sequenz kombiniert und einen Kreuzaufmerksamkeitsmechanismus verwendet, um verschiedene Modalitäten zu vergleichen Ausrichtung. Experimentelle Ergebnisse zeigen, dass diese Methode bei der Vorhersage von Protein-Ligand-Bindungsaffinitäten Spitzenleistungen erbringt. Darüber hinaus belegen Ablationsstudien die Wirksamkeit und Notwendigkeit der Proteinoberflächeninformation und der multimodalen Merkmalsausrichtung innerhalb dieses Rahmens. Verwandte Forschungen beginnen mit „S
 GlobalFoundries erschließt Märkte wie KI und erwirbt die Galliumnitrid-Technologie von Tagore Technology und zugehörige Teams
Jul 15, 2024 pm 12:21 PM
GlobalFoundries erschließt Märkte wie KI und erwirbt die Galliumnitrid-Technologie von Tagore Technology und zugehörige Teams
Jul 15, 2024 pm 12:21 PM
Laut Nachrichten dieser Website vom 5. Juli veröffentlichte GlobalFoundries am 1. Juli dieses Jahres eine Pressemitteilung, in der die Übernahme der Power-Galliumnitrid (GaN)-Technologie und des Portfolios an geistigem Eigentum von Tagore Technology angekündigt wurde, in der Hoffnung, seinen Marktanteil in den Bereichen Automobile und Internet auszubauen Anwendungsbereiche für Rechenzentren mit künstlicher Intelligenz, um höhere Effizienz und bessere Leistung zu erforschen. Da sich Technologien wie generative künstliche Intelligenz (GenerativeAI) in der digitalen Welt weiterentwickeln, ist Galliumnitrid (GaN) zu einer Schlüssellösung für nachhaltiges und effizientes Energiemanagement, insbesondere in Rechenzentren, geworden. Auf dieser Website wurde die offizielle Ankündigung zitiert, dass sich das Ingenieurteam von Tagore Technology im Rahmen dieser Übernahme mit GF zusammenschließen wird, um die Galliumnitrid-Technologie weiterzuentwickeln. G
