
 Technologie-Peripheriegeräte
KI
Das chinesische UIUC-Team enthüllt den Zauberstab des LLM-Assistenten und enthüllt die drei Hauptvorteile von Codedaten
Technologie-Peripheriegeräte
KI
Das chinesische UIUC-Team enthüllt den Zauberstab des LLM-Assistenten und enthüllt die drei Hauptvorteile von Codedaten
Das chinesische UIUC-Team enthüllt den Zauberstab des LLM-Assistenten und enthüllt die drei Hauptvorteile von Codedaten

Die Größe des Sprachmodells (LLM) und die Trainingsdaten im Zeitalter der großen Modelle haben zugenommen, einschließlich natürlicher Sprache und Code.
Code ist der Vermittler zwischen Mensch und Computer und wandelt übergeordnete Ziele in ausführbare Zwischenschritte um. Es weist die Merkmale grammatikalischer Standard, logische Konsistenz, Abstraktion und Modularität auf.
Ein Forschungsteam der University of Illinois in Urbana-Champaign hat kürzlich einen Überprüfungsbericht veröffentlicht, in dem die vielfältigen Vorteile der Integration von Code in LLM-Trainingsdaten zusammengefasst werden.

Papierlink: https://arxiv.org/abs/2401.00812v1
Zu den Vorteilen gehören neben der Verbesserung der Fähigkeit von LLM bei der Codegenerierung insbesondere auch die folgenden drei Punkte:
1. Hilft, die Argumentationsfähigkeiten von LLM freizuschalten, sodass es auf eine Reihe komplexerer natürlichsprachlicher Aufgaben angewendet werden kann.
2 Leitet LLM an, um strukturierte und präzise Zwischenschritte zu generieren, die dann aufgerufen werden können Funktionen zur Verbindung mit externen Ausführungsenden;
3 Die Code-Kompilierungs- und Ausführungsumgebung kann verwendet werden, um vielfältigere Feedback-Signale zur weiteren Verbesserung des Modells bereitzustellen.
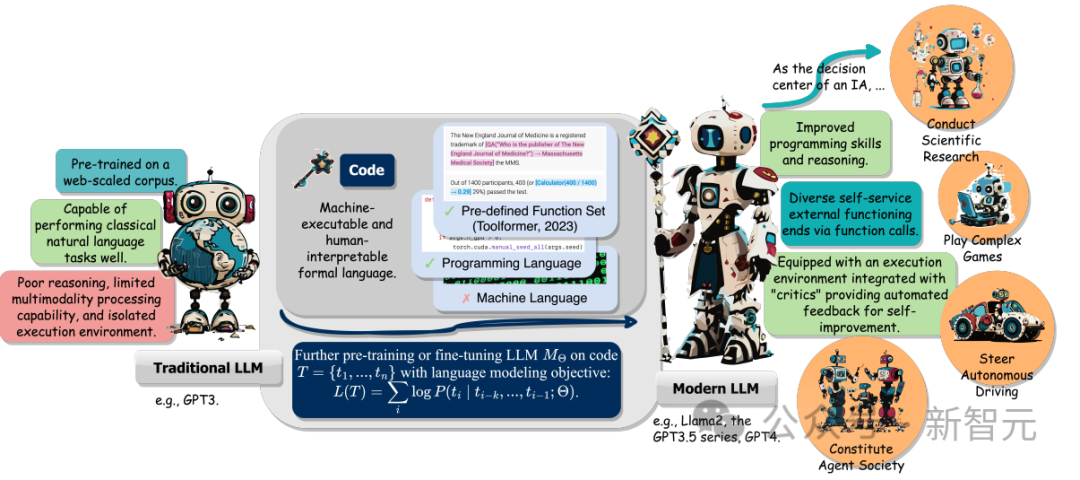
Darüber hinaus untersuchten die Forscher auch die Fähigkeit von LLM, Anweisungen zu verstehen, Ziele zu zerlegen, Aktionen zu planen und auszuführen und aus Feedback zu extrahieren, wenn es als intelligenter Agent (IA) eine Schlüsselrolle bei nachgelagerten Aufgaben spielt.
Abschließend schlägt der Artikel auch zentrale Herausforderungen und zukünftige Forschungsrichtungen im Bereich „Verbesserung von LLM mit Code“ vor.
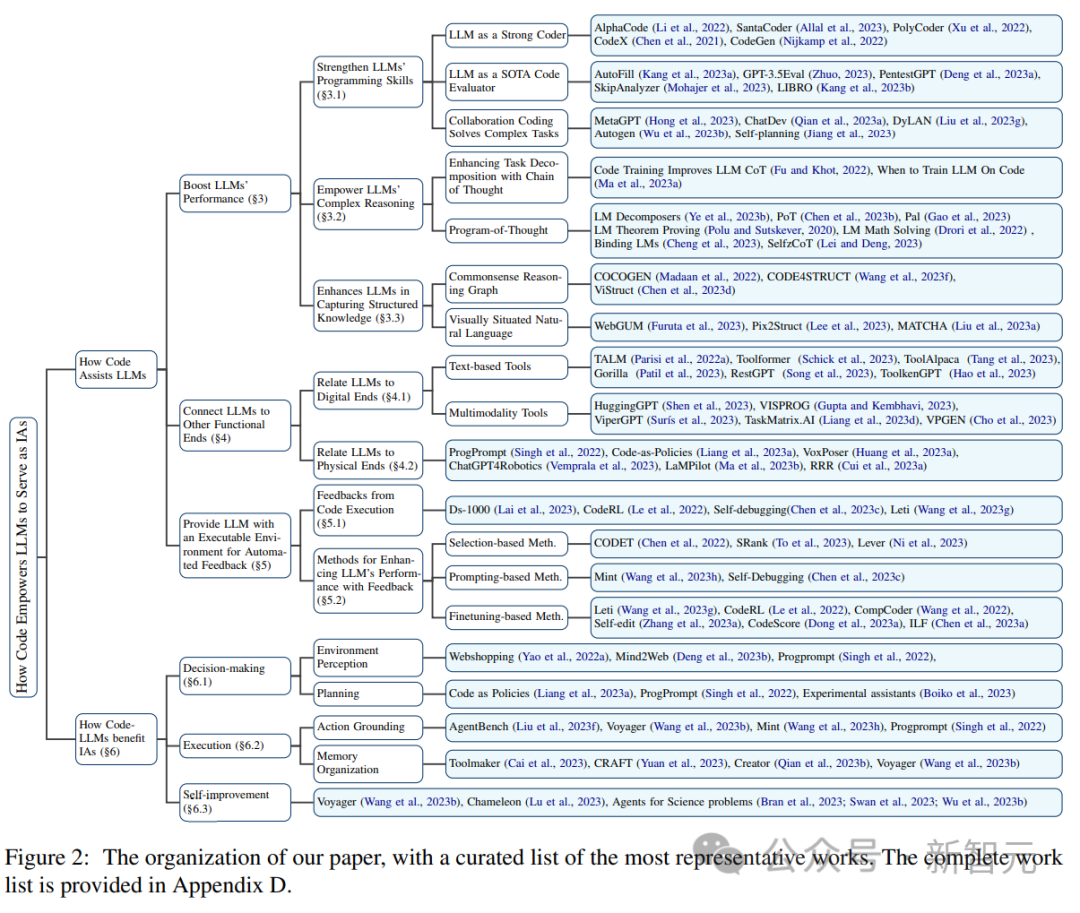
Code-Vortraining verbessert die LLM-Leistung
Am Beispiel des GPT-Codex von OpenAI kann nach dem Code-Vortraining für LLM der Umfang der LLM-Aufgaben zusätzlich zur Verarbeitung natürlicher Sprache erweitert werden kann auch für die mathematische Theorie verwendet werden. Generieren Sie Code, führen Sie allgemeine Programmieraufgaben aus, rufen Sie Daten ab und mehr.
Die Codegenerierungsaufgabe weist zwei Merkmale auf: 1) Die Codesequenz muss effektiv ausgeführt werden, daher muss sie über eine kohärente Logik verfügen, 2) jeder Zwischenschritt kann einer schrittweisen Logiküberprüfung unterzogen werden.
Die Verwendung und Einbettung von Code im Vortraining kann die Leistung der LLM Chain of Thought (CoT)-Technologie bei herkömmlichen Downstream-Aufgaben in natürlicher Sprache verbessern, was darauf hindeutet, dass Codetraining die Fähigkeit von LLM verbessern kann, komplexe Überlegungen anzustellen.
Durch das implizite Lernen aus der strukturierten Form von Code zeigt Code LLM auch eine bessere Leistung bei Aufgaben des gesunden Menschenverstandes zum strukturellen Denken, beispielsweise im Zusammenhang mit Markup, HTML und Diagrammverständnis.
Unterstützung für Funktion/Funktionsenden
Neueste Forschungsergebnisse zeigen, dass die Verbindung von LLMs mit anderen Funktionsenden (d. h. die Erweiterung von LLMs mit externen Tools und Ausführungsmodulen) LLMs dabei hilft, Aufgaben genauer und zuverlässiger auszuführen.
Diese funktionalen Zwecke ermöglichen es LLMs, externes Wissen zu erwerben, an mehreren modalen Daten teilzunehmen und effektiv mit der Umgebung zu interagieren.

Forscher haben in verwandten Arbeiten einen gemeinsamen Trend beobachtet, nämlich dass LLMs Programmiersprachen generieren oder vordefinierte Funktionen verwenden, um Verbindungen mit anderen Funktionsterminals herzustellen, also das „codezentrierte“ Paradigma.
Im Gegensatz zum festen praktischen Prozess streng fest codierter Toolaufrufe im LLM-Inferenzmechanismus ermöglicht das codezentrierte Paradigma LLM, dynamisch Token zu generieren und Ausführungsmodule mit anpassbaren Parametern aufzurufen, wodurch LLM weitere funktionale Terminalinteraktionen bietet eine einfache und klare Methode, die die Flexibilität und Skalierbarkeit ihrer Anwendungen erhöht.
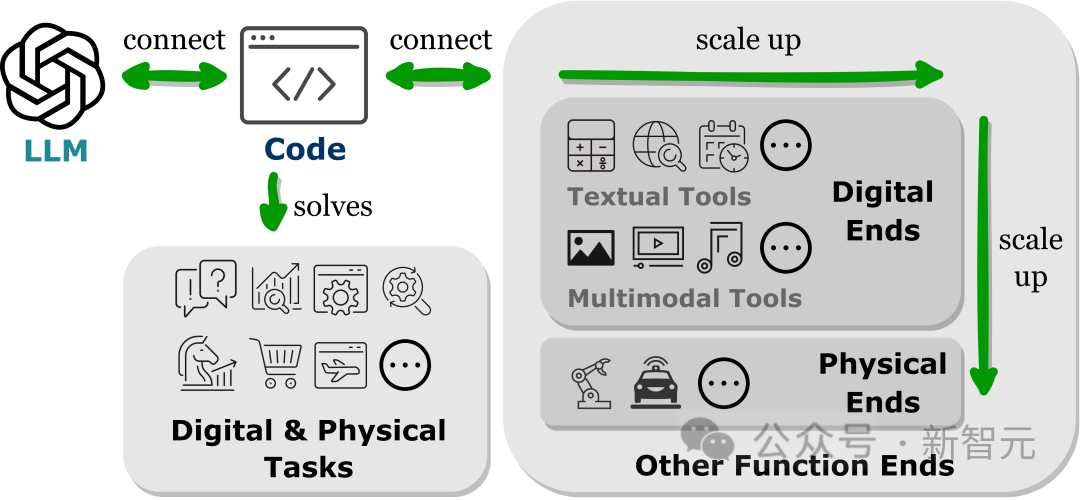
Wichtig ist, dass dieses Paradigma es LLM ermöglicht, mit zahlreichen Funktionsterminals über verschiedene Modalitäten und Domänen hinweg zu interagieren. Durch die Erweiterung der Anzahl und Vielfalt der zugänglichen Funktionsterminals kann LLM komplexere Aufgaben bewältigen.
Dieser Artikel untersucht hauptsächlich Text- und multimodale Tools im Zusammenhang mit LLM sowie den funktionalen Aspekt der physischen Welt, einschließlich Robotik und autonomem Fahren, und demonstriert die Vielseitigkeit von LLM bei der Lösung von Problemen in verschiedenen Modi und Bereichen.
Ausführbare Umgebung, die automatisches Feedback bietet
LLMs weisen eine Leistung auf, die über ihre Trainingsparameter hinausgeht, was zum Teil auf die Fähigkeit des Modells zurückzuführen ist, Feedbacksignale zu absorbieren, insbesondere in nicht statischen realen Anwendungen.
Allerdings muss bei der Auswahl des Feedbacksignals vorsichtig vorgegangen werden, da verrauschte Hinweise die Leistung von LLM bei nachgelagerten Aufgaben beeinträchtigen können.
Da die Arbeitskosten außerdem hoch sind, ist es entscheidend, automatisch Feedback zu sammeln und gleichzeitig die Loyalität aufrechtzuerhalten.
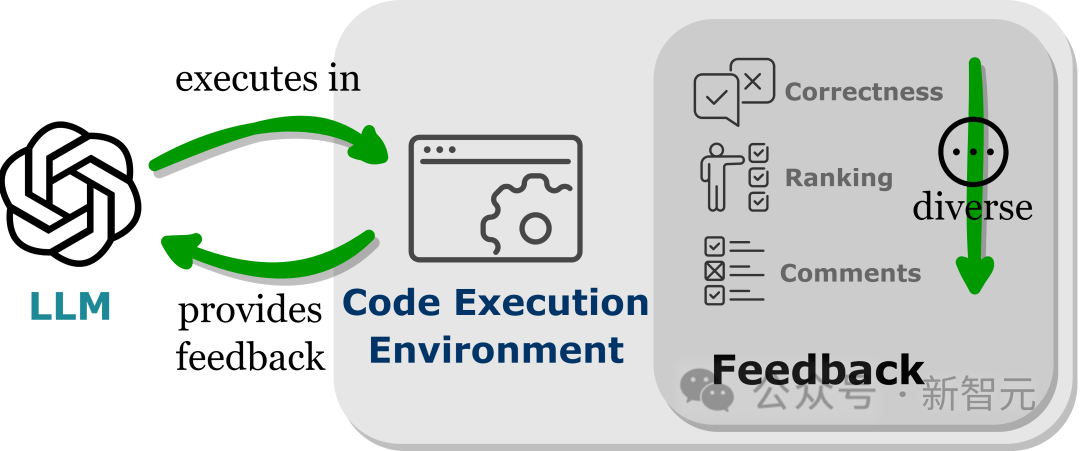
Durch die Einbettung von LLMs in die Codeausführungsumgebung kann eine automatische Rückmeldung der oben genannten Bedingungen erreicht werden.
Da die Codeausführung weitgehend deterministisch ist, bleibt das Feedback, das LLMs aus den Ergebnissen der Codeausführung erhalten, der Zielaufgabe treu. Der Codeinterpreter bietet LLMs außerdem einen automatisierten Weg, internes Feedback abzufragen, ohne dass manuelle Anmerkungen erforderlich sind kann zum Debuggen und Optimieren des von LLMs generierten Fehlercodes verwendet werden.
Darüber hinaus ermöglicht die Codeumgebung LLMs die Integration verschiedener externer Feedbackformen, einschließlich, aber nicht beschränkt auf binäres Korrektheitsfeedback, Erklärungen der Ergebnisse in natürlicher Sprache und Belohnungswertranking, und ermöglicht so einen hochgradig anpassbaren Ansatz zur Leistungsverbesserung.

Aktuelle Herausforderungen
Der kausale Zusammenhang zwischen Code-Vortraining und der Inferenzverbesserung von LLMs
Während es intuitiv erscheint, dass bestimmte Eigenschaften von Codedaten zu den Inferenzfähigkeiten von LLMs beitragen können, ist The Das genaue Ausmaß seiner Auswirkungen auf die Verbesserung der Denkfähigkeit bleibt unklar.
Im nächsten Schritt der Forschungsarbeit wird es wichtig sein zu untersuchen, ob diese Codeattribute tatsächlich die Inferenzfähigkeiten trainierter LLMs in den Trainingsdaten verbessern können.
Wenn es wahr ist, dass ein Vortraining zu bestimmten Eigenschaften von Code die Argumentationsfähigkeiten von LLMs direkt verbessern kann, dann wird das Verständnis dieses Phänomens der Schlüssel zur weiteren Verbesserung der komplexen Argumentationsfähigkeiten aktueller Modelle sein.
Denkfähigkeiten sind nicht auf Code beschränkt
Trotz der Verbesserung der Denkfähigkeiten, die durch Code-Vortraining erreicht werden, fehlen dem Basismodell immer noch die menschenähnlichen Denkfähigkeiten, die man von echter allgemeiner künstlicher Intelligenz erwartet.
Neben Code haben auch zahlreiche andere Textdatenquellen das Potenzial, die LLM-Inferenzfähigkeiten zu verbessern, wobei die inhärenten Eigenschaften des Codes, wie z. B. mangelnde Mehrdeutigkeit, Ausführbarkeit und logische sequentielle Struktur, Richtlinien für die Sammlung liefern oder das Erstellen dieser Datensätze.
Aber wenn wir weiterhin am Paradigma des Trainings von Sprachmodellen auf großen Korpora mit Sprachmodellierungszielen festhalten, wird es schwierig sein, eine sequentiell lesbare Sprache zu haben, die abstrakter als eine formale Sprache ist: stark strukturiert, eng verwandt mit symbolische Sprachen und sind in der digitalen Netzwerkumgebung in großer Zahl vorhanden.
Die Forscher gehen davon aus, dass die Erforschung alternativer Datenmuster, verschiedener Trainingsziele und neuartiger Architekturen mehr Möglichkeiten bieten wird, die Modellinferenzfähigkeiten weiter zu verbessern.
Herausforderungen bei der Anwendung des Code-zentrierten Paradigmas
In LLMs besteht die größte Herausforderung bei der Verwendung von Code zur Verbindung mit verschiedenen Funktionsterminals darin, die richtigen Aufrufmethoden verschiedener Funktionen zu erlernen, einschließlich der Auswahl der richtigen Funktion (Funktions-)Terminal und Übergabe der richtigen Argumente zum richtigen Zeitpunkt.
Für eine einfache Aufgabe (Webseitennavigation) wird beispielsweise ein begrenzter Satz an Aktionsprimitiven wie Mausbewegung, Klick und Seitenscrollen gegeben und dann einige Beispiele (wenige Aufnahmen) angegeben, ein starkes LLM-Grundlagenprinzip erfordert oft, dass LLM die Verwendung dieser Grundelemente genau beherrscht.
Für komplexere Aufgaben in datenintensiven Bereichen wie Chemie, Biologie und Astronomie, die Aufrufe an domänenspezifische Python-Bibliotheken beinhalten, die viele komplexe Funktionen mit unterschiedlichen Funktionen enthalten, ist die Fähigkeit von LLMs, diese Funktionsfunktionen korrekt aufzurufen, verbessert eine zukunftsweisende Ausrichtung, die es LLMs ermöglicht, Aufgaben auf Expertenebene in fein abgestimmten Bereichen auszuführen.
Lernen Sie aus mehreren Interaktions- und Feedbackrunden
LLMs erfordern oft mehrere Interaktionen mit Benutzern und der Umgebung und korrigieren sich ständig selbst, um die Erledigung komplexer Aufgaben zu verbessern.
Während die Codeausführung zuverlässiges und anpassbares Feedback liefert, wurde noch kein perfekter Weg gefunden, dieses Feedback vollständig zu nutzen.
Obwohl die aktuelle auswahlbasierte Methode nützlich ist, kann sie keine verbesserte Leistung garantieren und ist in hohem Maße auf die Kontextlernfähigkeit von LLM angewiesen, was ihre Anwendbarkeit einschränken kann hat zwar kontinuierliche Verbesserungen erzielt, aber die Datenerfassung und Feinabstimmung ist ressourcenintensiv und in der Praxis schwer umzusetzen.
Forscher glauben, dass Reinforcement Learning ein effektiverer Weg sein könnte, Feedback zu nutzen und sich zu verbessern, indem es durch sorgfältig gestaltete Belohnungsfunktionen eine dynamische Möglichkeit zur Anpassung an Feedback bietet und möglicherweise die Einschränkungen der aktuellen Technologie angeht.
Aber es ist noch viel Forschung nötig, um zu verstehen, wie man Belohnungsfunktionen gestaltet und wie man Reinforcement Learning optimal in LLMs integriert, um komplexe Aufgaben zu erledigen.
Das obige ist der detaillierte Inhalt vonDas chinesische UIUC-Team enthüllt den Zauberstab des LLM-Assistenten und enthüllt die drei Hauptvorteile von Codedaten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
Der Befehl centOS stilldown wird heruntergefahren und die Syntax wird von [Optionen] ausgeführt [Informationen]. Zu den Optionen gehören: -h das System sofort stoppen; -P schalten Sie die Leistung nach dem Herunterfahren aus; -r neu starten; -t Wartezeit. Zeiten können als unmittelbar (jetzt), Minuten (Minuten) oder als bestimmte Zeit (HH: MM) angegeben werden. Hinzugefügten Informationen können in Systemmeldungen angezeigt werden.
 Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Backup- und Wiederherstellungsrichtlinie von GitLab im Rahmen von CentOS -System Um die Datensicherheit und Wiederherstellung der Daten zu gewährleisten, bietet GitLab on CentOS eine Vielzahl von Sicherungsmethoden. In diesem Artikel werden mehrere gängige Sicherungsmethoden, Konfigurationsparameter und Wiederherstellungsprozesse im Detail eingeführt, um eine vollständige GitLab -Sicherungs- und Wiederherstellungsstrategie aufzubauen. 1. Manuell Backup Verwenden Sie den GitLab-RakegitLab: Backup: Befehl erstellen, um die manuelle Sicherung auszuführen. Dieser Befehl unterstützt wichtige Informationen wie GitLab Repository, Datenbank, Benutzer, Benutzergruppen, Schlüssel und Berechtigungen. Die Standardsicherungsdatei wird im Verzeichnis/var/opt/gitlab/backups gespeichert. Sie können /etc /gitlab ändern
 So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
Vollständige Anleitung zur Überprüfung der HDFS -Konfiguration in CentOS -Systemen In diesem Artikel wird die Konfiguration und den laufenden Status von HDFS auf CentOS -Systemen effektiv überprüft. Die folgenden Schritte helfen Ihnen dabei, das Setup und den Betrieb von HDFs vollständig zu verstehen. Überprüfen Sie die Hadoop -Umgebungsvariable: Stellen Sie zunächst sicher, dass die Hadoop -Umgebungsvariable korrekt eingestellt ist. Führen Sie im Terminal den folgenden Befehl aus, um zu überprüfen, ob Hadoop ordnungsgemäß installiert und konfiguriert ist: Hadoopsion-Check HDFS-Konfigurationsdatei: Die Kernkonfigurationsdatei von HDFS befindet sich im/etc/hadoop/conf/verzeichnis, wobei core-site.xml und hdfs-site.xml von entscheidender Bedeutung sind. verwenden
 Was sind die Methoden zur Abstimmung der Leistung von Zookeeper auf CentOS
Apr 14, 2025 pm 03:18 PM
Was sind die Methoden zur Abstimmung der Leistung von Zookeeper auf CentOS
Apr 14, 2025 pm 03:18 PM
Die Zookeper -Leistungsstimmung auf CentOS kann von mehreren Aspekten beginnen, einschließlich Hardwarekonfiguration, Betriebssystemoptimierung, Konfigurationsparameteranpassung, Überwachung und Wartung usw. Hier finden Sie einige spezifische Tuning -Methoden: SSD wird für die Hardwarekonfiguration: Da die Daten von Zookeeper an Disk geschrieben werden, wird empfohlen, SSD zu verbessern, um die I/O -Leistung zu verbessern. Genug Memory: Zookeeper genügend Speicherressourcen zuweisen, um häufige Lesen und Schreiben von häufigen Festplatten zu vermeiden. Multi-Core-CPU: Verwenden Sie Multi-Core-CPU, um sicherzustellen, dass Zookeeper es parallel verarbeiten kann.
 Wie man ein Pytorch -Modell auf CentOS trainiert
Apr 14, 2025 pm 03:03 PM
Wie man ein Pytorch -Modell auf CentOS trainiert
Apr 14, 2025 pm 03:03 PM
Effizientes Training von Pytorch -Modellen auf CentOS -Systemen erfordert Schritte, und dieser Artikel bietet detaillierte Anleitungen. 1.. Es wird empfohlen, YUM oder DNF zu verwenden, um Python 3 und Upgrade PIP zu installieren: Sudoyumupdatepython3 (oder sudodnfupdatepython3), PIP3Install-upgradepip. CUDA und CUDNN (GPU -Beschleunigung): Wenn Sie Nvidiagpu verwenden, müssen Sie Cudatool installieren
 Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Aktivieren Sie die Pytorch -GPU -Beschleunigung am CentOS -System erfordert die Installation von CUDA-, CUDNN- und GPU -Versionen von Pytorch. Die folgenden Schritte führen Sie durch den Prozess: Cuda und Cudnn Installation Bestimmen Sie die CUDA-Version Kompatibilität: Verwenden Sie den Befehl nvidia-smi, um die von Ihrer NVIDIA-Grafikkarte unterstützte CUDA-Version anzuzeigen. Beispielsweise kann Ihre MX450 -Grafikkarte CUDA11.1 oder höher unterstützen. Download und installieren Sie Cudatoolkit: Besuchen Sie die offizielle Website von Nvidiacudatoolkit und laden Sie die entsprechende Version gemäß der höchsten CUDA -Version herunter und installieren Sie sie, die von Ihrer Grafikkarte unterstützt wird. Installieren Sie die Cudnn -Bibliothek:
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 So wählen Sie die Pytorch -Version unter CentOS aus
Apr 14, 2025 pm 02:51 PM
So wählen Sie die Pytorch -Version unter CentOS aus
Apr 14, 2025 pm 02:51 PM
Bei der Auswahl einer Pytorch -Version unter CentOS müssen die folgenden Schlüsselfaktoren berücksichtigt werden: 1. Cuda -Version Kompatibilität GPU -Unterstützung: Wenn Sie NVIDIA -GPU haben und die GPU -Beschleunigung verwenden möchten, müssen Sie Pytorch auswählen, der die entsprechende CUDA -Version unterstützt. Sie können die CUDA-Version anzeigen, die unterstützt wird, indem Sie den Befehl nvidia-smi ausführen. CPU -Version: Wenn Sie keine GPU haben oder keine GPU verwenden möchten, können Sie eine CPU -Version von Pytorch auswählen. 2. Python Version Pytorch
