
 System-Tutorial
LINUX
Verstehen Sie die Architektur von Oracle12.2: Dateisystem und Mandantenfähigkeit
System-Tutorial
LINUX
Verstehen Sie die Architektur von Oracle12.2: Dateisystem und Mandantenfähigkeit
Verstehen Sie die Architektur von Oracle12.2: Dateisystem und Mandantenfähigkeit

- RVWR: Recovery Writer-Prozess Wenn die Datenbank einen Flashback-Bereich einrichtet, schreibt der Prozess regelmäßig die Flashback-Daten im Speicher, insbesondere den Flashback-Puffer im gemeinsam genutzten Pool, in Flashback-Protokolle.
- Ergebniscache –> RCBG:Ergebniscache wird verwendet, um die Ergebnisse der ursprünglichen Datenoperation während der Ausführung von SQL-Anweisungen oder Plsql-Funktionen zu speichern direkt erhalten, um die Verschwendung von Rechenressourcen zu vermeiden.
- ASH-Puffer–>MMNL: ASH-Puffer wird zum Speichern statistischer Informationen aktiver Sitzungen verwendet, einschließlich SQL-Ausführungsstatus, Anwendungsverbindungsstatus, Warteereignisse usw. Wenn der ASH-Puffer voll ist, ist der MMNL-Prozess dafür verantwortlich, die Daten im Puffer auf die Festplatte zu schreiben.
- Im Speicher rückgängig machen (IMU): Öffnen Sie einen Bereich im gemeinsam genutzten Pool, um temporäres Rückgängigmachen zu speichern. Wenn mehrere Daten in einer Transaktion geändert werden, wird nicht mehr der Rückgängig-Datenblock im Puffercache geändert, sondern ein IMU Knoten wird zur Aufnahme hinzugefügt. Hauptsächlich, um das durch Rückgängigmachen erzeugte Redo zu reduzieren.
- Private Redo-Log-Puffer: Wird hauptsächlich verwendet, um das von der IMU generierte temporäre Redo zu verwalten, die Redo-Informationen der Transaktion im gemeinsam genutzten Pool zu speichern und den Verbrauch des Redo-Log-Puffers zu reduzieren.
- Flash-Cache: Der vollständige Name lautet Database Smart Flash Cache. Es handelt sich um eine Optimierungstechnologie für Flash-Speicher, die ab 11.2 entwickelt wurde. Sie zielt darauf ab, die Gesamtlatenz der Datenbank zu reduzieren, indem sie herkömmliche langsame Festplattengeräte zum Speichern einiger Daten verwendet Der Zweck besteht darin, die IOPS der Datenbank zu verbessern und die Leistung der Datenbank zu verbessern.
Flash Cache funktioniert wie folgt:
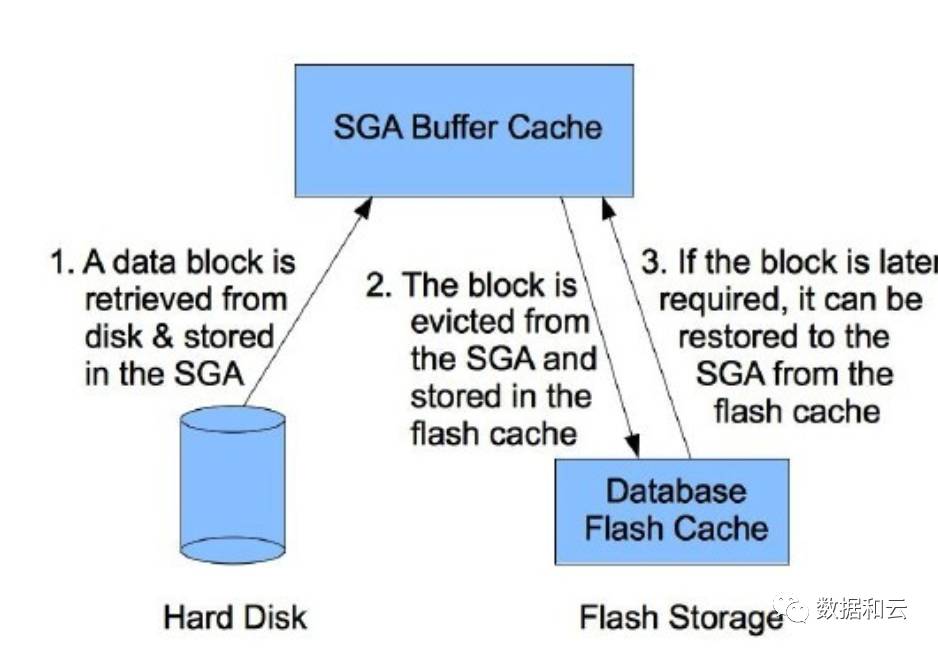
Der im Flash-Cache gespeicherte Inhalt wird auf zwei Arten gesteuert:
1. Der intelligente Auswahlalgorithmus von Flash Cache: Bestimmen Sie die Zugriffshäufigkeit von Datenblöcken und Indexblöcken.
2. Ändern Sie das Attribut cell_flash_cache des Datenbankobjekts.
Grundlegende Standards für Flash-Cache-Speicherinhalte
Hauptsächlich kleine IO-Operationen sowie Datenblöcke, Indexblöcke, Dateiheader, Steuerdateien usw. werden zwischengespeichert
;Für RMAN-Sicherungs-E/A-Vorgänge, Datenpumpen-E/A-Vorgänge, ASM-Spiegelungsvorgänge und Tabellenbereichsformatierung usw. werden sie nicht zwischengespeichert
;Die Cache-Priorität von E/A-Vorgängen für vollständige Tabellenscans ist relativ niedrig.
Wenn Daten im Flash-Cache gespeichert werden, dient dies hauptsächlich der Verbesserung der Abfragegeschwindigkeit. Mit anderen Worten, es entspricht dem Hinzufügen eines Teils des Puffer-Cache-Bereichs zusätzlich zum Speicher, aber die Leistung ist besser und die Geschwindigkeit besser. Wenn dann, genau wie beim Puffer-Cache, die Daten im Flash-Cache voll sind oder bis zu einem gewissen Grad geschrieben wurden, müssen die Daten auf die Festplatte geschrieben werden, um Platz für neue Betriebsdaten zu schaffen.
Das Schreiben von Daten im Cache auf die Festplatte wird als Flushing bezeichnet. Sie können den Wert „Starten und Stoppen des Cache-Flushing-Levels“ konfigurieren, der den Prozentsatz der gesamten belegten Cache-Größe darstellt. Wenn die Daten im Cache, die nicht auf die Festplatte geschrieben wurden, den Startwert für das Leeren erreichen, beginnt der Controller mit dem Leeren (Schreiben vom Cache auf die Festplatte). Wenn die Menge der nicht geschriebenen Festplattendaten im Cache geringer ist als der Stop-Flush-Wert, wird der Flush-Vorgang angehalten.
Wenn der Start-Flushing-Level höher eingestellt ist, können mehr ungeschriebene Daten im Speicher zwischengespeichert werden. Dies trägt dazu bei, die Leistung von Schreibvorgängen zu verbessern, allerdings auf Kosten des Datenschutzes. Wenn Sie Datenschutz wünschen, können Sie niedrigere Start- und Stoppwerte verwenden. Tests zeigen, dass die Leistung besser ist, wenn die Spülstufen mit engem Start und Stopp verwendet werden. Wenn der Stopppegelwert weit unter dem Startwert liegt, kommt es während des Spülens zu einer Festplattenüberlastung
Smart Flash LoggingDer E/A-Engpass des Redo-Protokolls war lange Zeit ein großes Problem, das das OLTP-System plagte, da die Schreibverzögerung von Redo die Reaktionsgeschwindigkeit des gesamten Systems und sogar des gesamten Clusters direkt beeinträchtigt.
In der traditionellen Datenbankarchitektur weisen einige DBAs Redo separat kleinen Blockspeicher mit geringer Lese- und Schreiblatenz zu. Ab 11204 schlägt Oracle eine neue Lösung vor, um einen Bereich speziell für Redo zum Speichern zu öffnen vorübergehendes Wiederherstellen.
Platzieren Sie den Spaltenspeicher im Flash-Cache, um die Schreib-E/A für häufig verwendete Spaltenspeicherobjekte zu verbessern
- Änderungsverfolgungsdatei:Blockänderungen in inkrementellen Sicherungen erkennen und in Dateien aufzeichnen. Die Aufnahmeeinheit ist blockiert.
- Wallet: Oracle Wallet ist ein Container zur Aufbewahrung von Schlüsseln. Vereinfacht gesagt handelt es sich um ein Passwortfeld, das Sie in Situationen, in denen ursprünglich die Eingabe eines Passworts erforderlich war, ohne Eingabe eines Passworts verwenden können, wodurch vertrauliche Informationen wie Kontopasswörter geschützt, die Sicherheit verbessert und die Bedienung komfortabler wird benutzen.
Anwendungscontainer ist eine neue Komponente, die in 12.2 vorgeschlagen wird. Sie unterteilt das Datenbanksystem unter derselben Anwendung in einen Untercontainer, um relative Geschäftsisolation und Datensicherheit zu erreichen und gleichzeitig die gleiche Verwaltung mehrerer Mandanten sicherzustellen.
PDB verfügt über einen eigenen Undo-TablespaceAb 12.2 verfügt jede PDB über einen eigenen Undo-Tablespace. Dadurch werden Konflikte zwischen mehreren PDBs vermieden. Wenn Sie eine Flashback- oder zeitstempelbasierte Wiederherstellung durchführen möchten, müssen Sie nur in Ihren eigenen Undo-Daten suchen, um die Effizienz zu verbessern.
Flexible Möglichkeit, PDB zu erstellen1. Aus PDB$seed (oder Anwendungsstammverzeichnis) erstellen: durch Kopieren von Dateien
2. Die vorhandene PDB wird durch Hot Clone erstellt
Hinweis: Wenn Sie in 12.1 eine neue PDB basierend auf einer PDB erstellen, müssen Sie die Originalbibliothek im schreibgeschützten Modus öffnen.
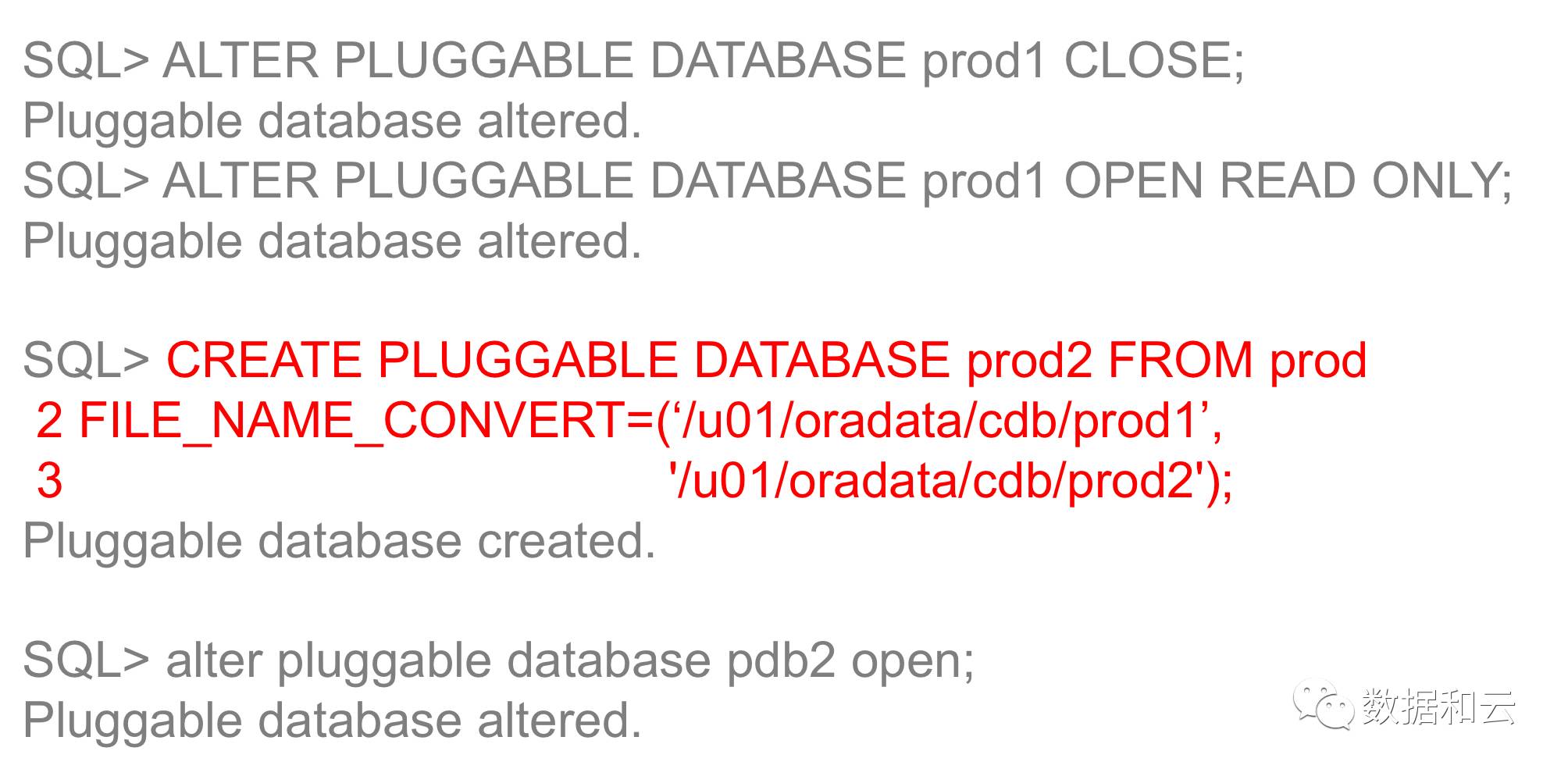
In 12.2 kann die Originalbibliothek weiterhin DML-Vorgänge ausführen, ohne dass dies beeinträchtigt wird.
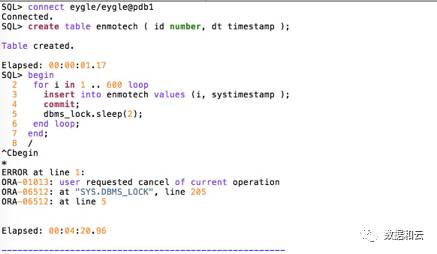
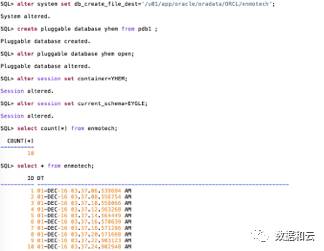
Nachdem das Klonen abgeschlossen ist, werden die Daten kontinuierlich in der neuen Datenbank aktualisiert.
3. Migration von PDBs in andere CDBs: Umziehen
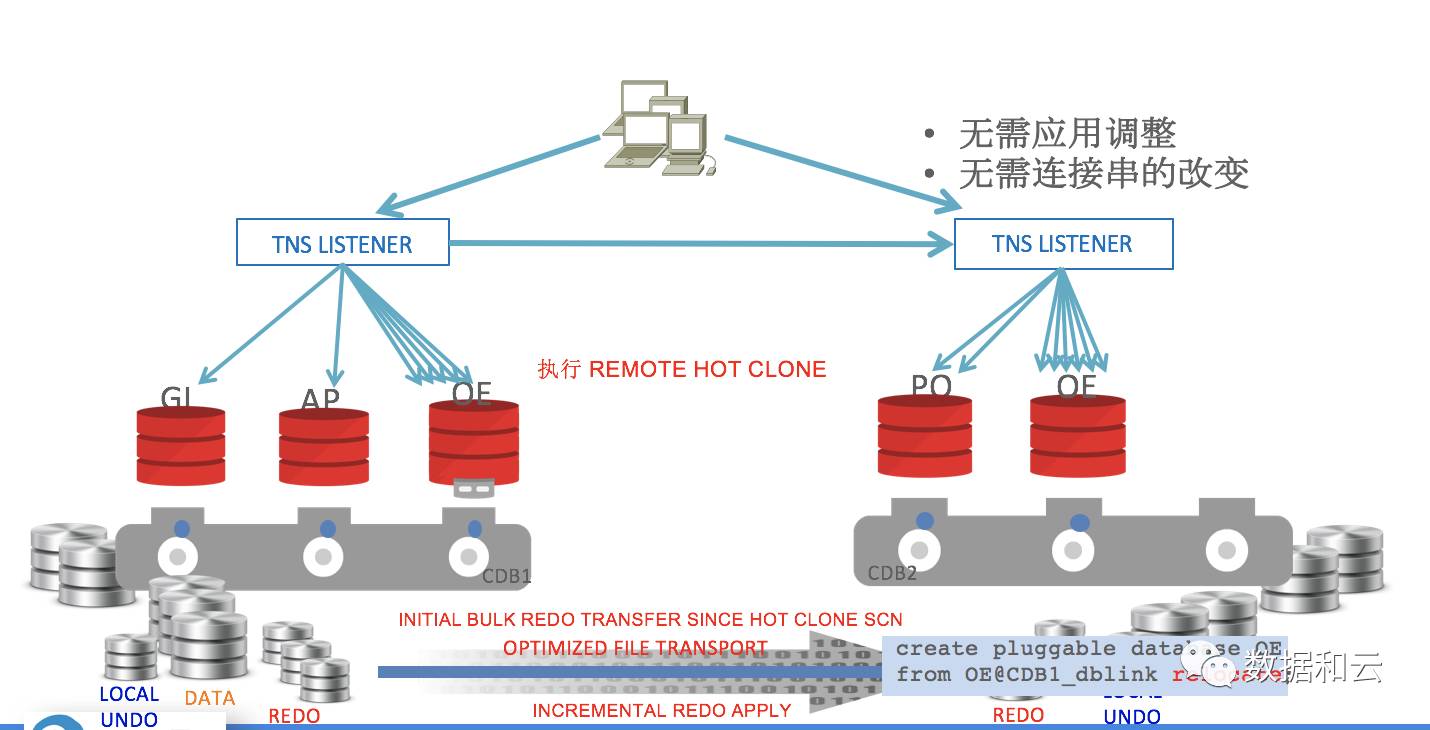
Das Front-End führt einen Befehl aus, z. B. „Create Pluggable Database from Relocate“, und der Hintergrund führt automatisch Remote-Hot-Clone aus, kopiert und synchronisiert Remote-Dateien.
4. Erstellen Sie eine neue PDB durch Schattenkopie der ASM-Festplattendateien.
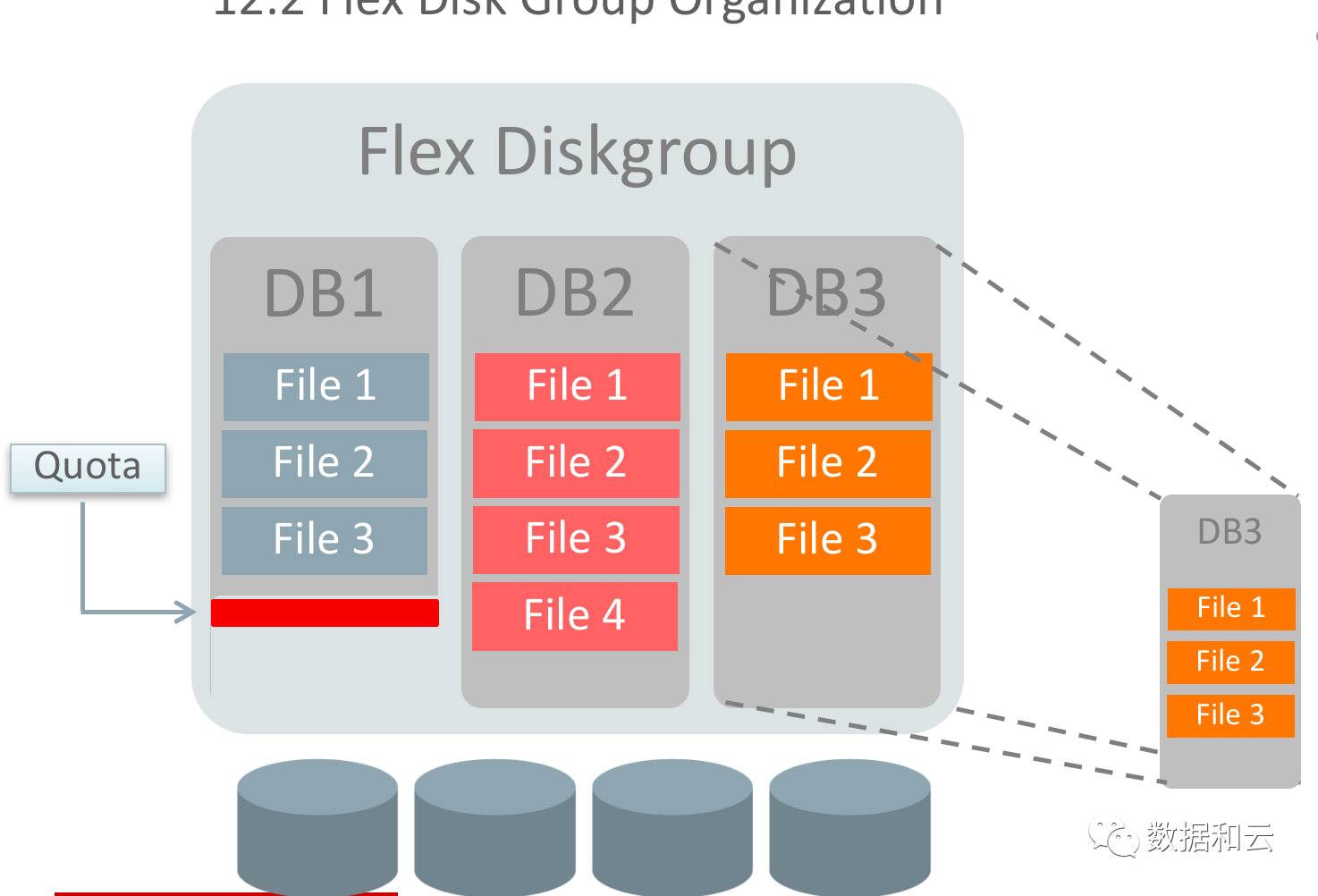
PDB-Speicherressourcenverwaltung
In einer Umgebung mit mehreren Mandanten teilen sich mehrere PDBs Speicherressourcen. Wenn ein PDB den Puffercache adressieren muss, muss er die gesamten gemeinsam genutzten Ressourcen durchsuchen, was sehr unpraktisch ist. In 12.2 implementierte Oracle für einige Ressourcen eine PDB-basierte Domänenaufteilung.
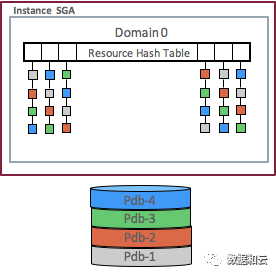
Die Hash-Liste der Speicherressourcen in 12.1 lautet wie folgt:
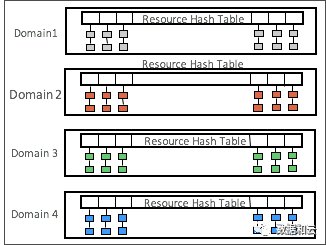
So sieht es in 12.2 aus:
Weitere neue Funktionen von PDB
1. Zeichensatz: Wenn der CDB-Zeichensatz in 12.2 ein Obersatz ist, also AL32UTF8, werden PDBs mit unterschiedlichen Zeichensätzen unterstützt. Gleichzeitig können PDBs mit unterschiedlichen Zeichensätzen über Proxy PDB abgefragt werden, um die Zeichensätze beider Parteien ohne verstümmelte Zeichen zu identifizieren und kompatibel zu machen.
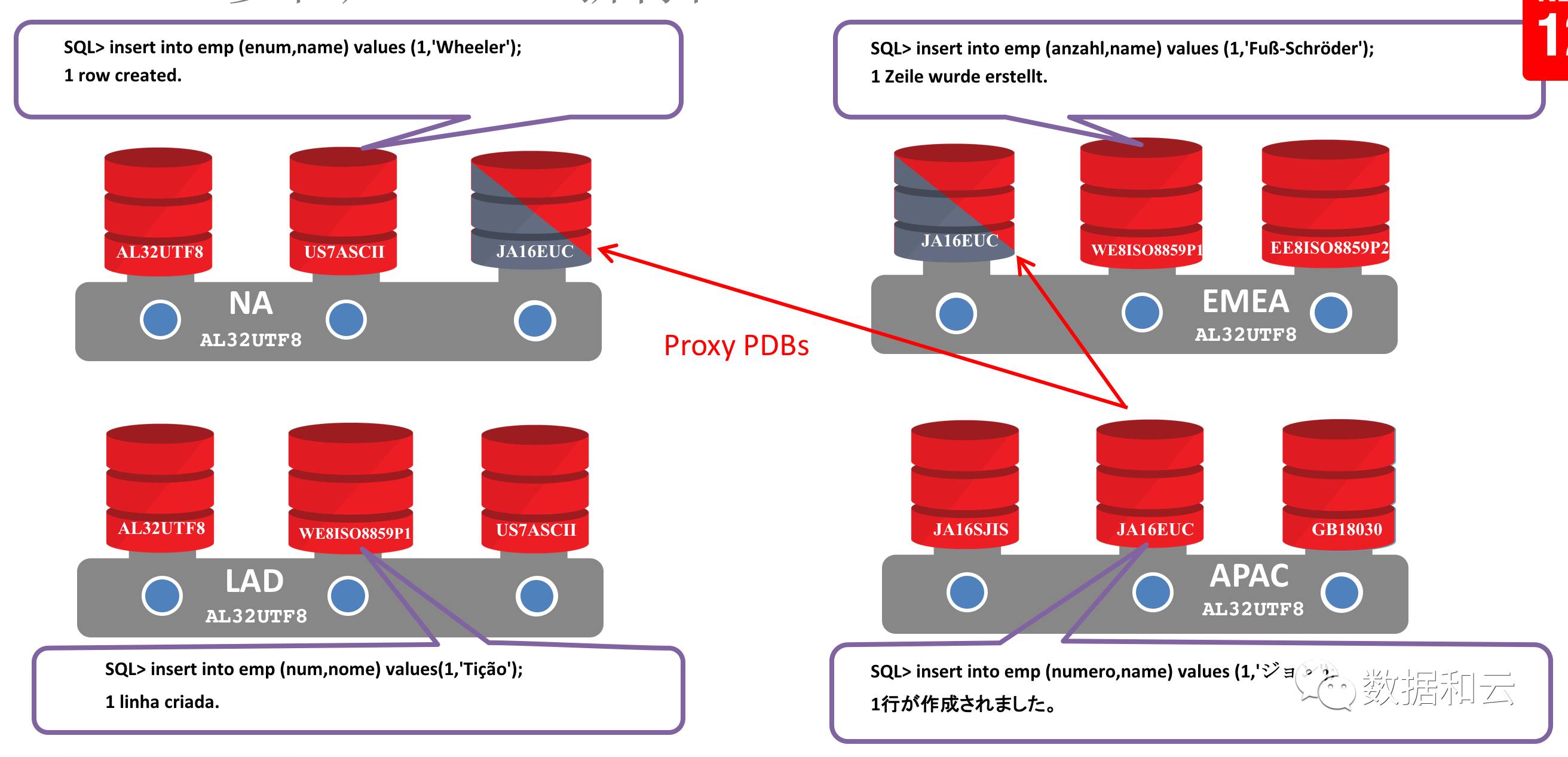
Multi-Tenant-Technologie wird von Benutzern häufig genutzt, und Yunhe Enmo hat als führendes Unternehmen in der Datendienstbranche Benutzern durch die Kombination von zData-Lösungen und Oracle-Multi-Tenant dabei geholfen, die System-Cloud-Transformation im Internet+-Zeitalter zu erreichen.
Ausführlichere Erläuterungen zu neuen Funktionen der Mandantenfähigkeit finden Sie unter
YH9:Oracle Multitenant Knowledge Base
Als führendes Unternehmen in der Datendienstleistungsbranche hat Yunhe Enmo Benutzern dabei geholfen, die Cloud-Transformation ihrer Systeme im Internet+-Zeitalter durch die Kombination von zData-Lösungen und Oracle-Multi-Tenant-Technologie zu realisieren.
Artikel aus dem öffentlichen WeChat-Konto: Daten und Cloud
Das obige ist der detaillierte Inhalt vonVerstehen Sie die Architektur von Oracle12.2: Dateisystem und Mandantenfähigkeit. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 So starten Sie Apache
Apr 13, 2025 pm 01:06 PM
So starten Sie Apache
Apr 13, 2025 pm 01:06 PM
Die Schritte zum Starten von Apache sind wie folgt: Installieren Sie Apache (Befehl: sudo apt-Get-Get-Installieren Sie Apache2 oder laden Sie ihn von der offiziellen Website herunter). (Optional, Linux: sudo systemctl
 Was tun, wenn der Port Apache80 belegt ist
Apr 13, 2025 pm 01:24 PM
Was tun, wenn der Port Apache80 belegt ist
Apr 13, 2025 pm 01:24 PM
Wenn der Port -80 -Port der Apache 80 besetzt ist, lautet die Lösung wie folgt: Finden Sie den Prozess, der den Port einnimmt, und schließen Sie ihn. Überprüfen Sie die Firewall -Einstellungen, um sicherzustellen, dass Apache nicht blockiert ist. Wenn die obige Methode nicht funktioniert, konfigurieren Sie Apache bitte so, dass Sie einen anderen Port verwenden. Starten Sie den Apache -Dienst neu.
 So überwachen Sie die NGINX SSL -Leistung auf Debian
Apr 12, 2025 pm 10:18 PM
So überwachen Sie die NGINX SSL -Leistung auf Debian
Apr 12, 2025 pm 10:18 PM
In diesem Artikel wird beschrieben, wie die SSL -Leistung von NGINX -Servern auf Debian -Systemen effektiv überwacht wird. Wir werden Nginxexporter verwenden, um Nginx -Statusdaten in Prometheus zu exportieren und sie dann visuell über Grafana anzeigen. Schritt 1: Konfigurieren von Nginx Erstens müssen wir das Modul stub_status in der nginx -Konfigurationsdatei aktivieren, um die Statusinformationen von Nginx zu erhalten. Fügen Sie das folgende Snippet in Ihre Nginx -Konfigurationsdatei hinzu (normalerweise in /etc/nginx/nginx.conf oder deren inklusive Datei): location/nginx_status {stub_status
 So richten Sie im Debian -System einen Recyclingbehälter ein
Apr 12, 2025 pm 10:51 PM
So richten Sie im Debian -System einen Recyclingbehälter ein
Apr 12, 2025 pm 10:51 PM
In diesem Artikel werden zwei Methoden zur Konfiguration eines Recycling -Bin in einem Debian -System eingeführt: eine grafische Schnittstelle und eine Befehlszeile. Methode 1: Verwenden Sie die grafische Schnittstelle Nautilus, um den Dateimanager zu öffnen: Suchen und starten Sie den Nautilus -Dateimanager (normalerweise als "Datei") im Menü Desktop oder Anwendungen. Suchen Sie den Recycle Bin: Suchen Sie nach dem Ordner recycelner Behälter in der linken Navigationsleiste. Wenn es nicht gefunden wird, klicken Sie auf "Andere Speicherort" oder "Computer", um sie zu suchen. Konfigurieren Sie Recycle Bin-Eigenschaften: Klicken Sie mit der rechten Maustaste auf "Recycle Bin" und wählen Sie "Eigenschaften". Im Eigenschaftenfenster können Sie die folgenden Einstellungen einstellen: Maximale Größe: Begrenzen Sie den im Recycle -Behälter verfügbaren Speicherplatz. Aufbewahrungszeit: Legen Sie die Erhaltung fest, bevor die Datei automatisch im Recyclingbehälter gelöscht wird
 Die Bedeutung von Debian Sniffer für die Netzwerküberwachung
Apr 12, 2025 pm 11:03 PM
Die Bedeutung von Debian Sniffer für die Netzwerküberwachung
Apr 12, 2025 pm 11:03 PM
Obwohl in den Suchergebnissen "Debiansniffer" und ihre spezifische Anwendung bei der Netzwerküberwachung nicht direkt erwähnt werden, können wir schließen, dass sich "Sniffer" auf ein Tool für Netzwerkpaket -Capture -Analyse bezieht, und seine Anwendung im Debian -System unterscheidet sich nicht wesentlich von anderen Linux -Verteilungen. Die Netzwerküberwachung ist entscheidend für die Aufrechterhaltung der Netzwerkstabilität und die Optimierung der Leistung, und Tools für die Analyse der Paketerfassung spielen eine Schlüsselrolle. Im Folgenden werden die wichtige Rolle von Tools zur Netzwerküberwachung (z. B. in Debian-Systemen ausgeführt) erklärt: Der Wert von Netzwerküberwachungstools: Schneller Fehlerstandort: Echtzeitüberwachung von Netzwerkmetriken, wie z.
 So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
In Debian -Systemen werden Readdir -Systemaufrufe zum Lesen des Verzeichnisinhalts verwendet. Wenn seine Leistung nicht gut ist, probieren Sie die folgende Optimierungsstrategie aus: Vereinfachen Sie die Anzahl der Verzeichnisdateien: Teilen Sie große Verzeichnisse so weit wie möglich in mehrere kleine Verzeichnisse auf und reduzieren Sie die Anzahl der gemäß Readdir -Anrufe verarbeiteten Elemente. Aktivieren Sie den Verzeichnis -Inhalt Caching: Erstellen Sie einen Cache -Mechanismus, aktualisieren Sie den Cache regelmäßig oder bei Änderungen des Verzeichnisinhalts und reduzieren Sie häufige Aufrufe an Readdir. Speicher -Caches (wie Memcached oder Redis) oder lokale Caches (wie Dateien oder Datenbanken) können berücksichtigt werden. Nehmen Sie eine effiziente Datenstruktur an: Wenn Sie das Verzeichnis -Traversal selbst implementieren, wählen Sie effizientere Datenstrukturen (z.
 So starten Sie den Apache -Server neu
Apr 13, 2025 pm 01:12 PM
So starten Sie den Apache -Server neu
Apr 13, 2025 pm 01:12 PM
Befolgen Sie die folgenden Schritte, um den Apache -Server neu zu starten: Linux/MacOS: Führen Sie sudo systemCTL RESTART APache2 aus. Windows: Net Stop Apache2.4 und dann Net Start Apache2.4 ausführen. Führen Sie Netstat -a | Findstr 80, um den Serverstatus zu überprüfen.
 Wie man Debian Syslog lernt
Apr 13, 2025 am 11:51 AM
Wie man Debian Syslog lernt
Apr 13, 2025 am 11:51 AM
In diesem Leitfaden werden Sie erfahren, wie Sie Syslog in Debian -Systemen verwenden. Syslog ist ein Schlüsseldienst in Linux -Systemen für Protokollierungssysteme und Anwendungsprotokollnachrichten. Es hilft den Administratoren, die Systemaktivitäten zu überwachen und zu analysieren, um Probleme schnell zu identifizieren und zu lösen. 1. Grundkenntnisse über syslog Die Kernfunktionen von Syslog umfassen: zentrales Sammeln und Verwalten von Protokollnachrichten; Unterstützung mehrerer Protokoll -Ausgabesformate und Zielorte (z. B. Dateien oder Netzwerke); Bereitstellung von Echtzeit-Protokoll- und Filterfunktionen. 2. Installieren und Konfigurieren von Syslog (mit Rsyslog) Das Debian -System verwendet standardmäßig Rsyslog. Sie können es mit dem folgenden Befehl installieren: sudoaptupdatesud
