
 Technologie-Peripheriegeräte
KI
Keine manuelle Anmerkung erforderlich! LLM unterstützt das Lernen der Texteinbettung: Unterstützt problemlos 100 Sprachen und passt sich Hunderttausenden nachgelagerten Aufgaben an
Technologie-Peripheriegeräte
KI
Keine manuelle Anmerkung erforderlich! LLM unterstützt das Lernen der Texteinbettung: Unterstützt problemlos 100 Sprachen und passt sich Hunderttausenden nachgelagerten Aufgaben an
Keine manuelle Anmerkung erforderlich! LLM unterstützt das Lernen der Texteinbettung: Unterstützt problemlos 100 Sprachen und passt sich Hunderttausenden nachgelagerten Aufgaben an

Texteinbettung (Worteinbettung) ist eine grundlegende Technologie im Bereich der Verarbeitung natürlicher Sprache (NLP). Sie kann Text dem semantischen Raum zuordnen und ihn in eine dichte Vektordarstellung umwandeln. Diese Methode wird häufig in verschiedenen NLP-Aufgaben eingesetzt, darunter Informationsabruf (IR), Beantwortung von Fragen, Berechnung der Textähnlichkeit und Empfehlungssysteme. Durch die Texteinbettung können wir die Bedeutung und Beziehung von Texten besser verstehen und dadurch die Effektivität von NLP-Aufgaben verbessern.
Im Bereich des Information Retrieval (IR) werden in der ersten Stufe des Retrievals üblicherweise Texteinbettungen zur Ähnlichkeitsberechnung verwendet. Es funktioniert, indem es einen kleinen Satz Kandidatendokumente in einem großen Korpus abruft und dann feinkörnige Berechnungen durchführt. Einbettungsbasierter Abruf ist auch ein wichtiger Bestandteil der Retrieval-Augmented Generation (RAG). Es ermöglicht großen Sprachmodellen (LLMs), auf dynamisches externes Wissen zuzugreifen, ohne Modellparameter zu ändern. Auf diese Weise kann das IR-System Texteinbettungen und externes Wissen besser nutzen, um die Abrufergebnisse zu verbessern.
Obwohl frühe Lernmethoden zur Texteinbettung wie word2vec und GloVe weit verbreitet sind, schränken ihre statischen Eigenschaften die Fähigkeit ein, umfangreiche Kontextinformationen in natürlicher Sprache zu erfassen. Mit dem Aufkommen vorab trainierter Sprachmodelle haben jedoch einige neue Methoden wie Sentence-BERT und SimCSE erhebliche Fortschritte bei NLI-Datensätzen (Natural Language Inference) erzielt, indem BERT so optimiert wurde, dass es Texteinbettungen lernt. Diese Methoden nutzen die kontextbewussten Fähigkeiten von BERT, um die Semantik und den Kontext von Text besser zu verstehen und dadurch die Qualität und Ausdruckskraft von Texteinbettungen zu verbessern. Durch die Kombination von Vortraining und Feinabstimmung können diese Methoden umfangreichere semantische Informationen aus großen Korpora für die Verarbeitung natürlicher Sprache lernen Schulung genutzt wurde. Sie werden zunächst anhand von Milliarden schwach überwachter Textpaare vorab trainiert und dann anhand mehrerer annotierter Datensätze verfeinert. Diese Strategie kann die Leistung der Texteinbettung effektiv verbessern.
Bestehende mehrstufige Methoden weisen noch zwei Mängel auf:
1 Der Aufbau einer komplexen mehrstufigen Trainingspipeline erfordert viel technische Arbeit, um eine große Anzahl von Korrelationspaaren zu verwalten.
2. Die Feinabstimmung basiert auf manuell erfassten Datensätzen, die häufig durch die Aufgabenvielfalt und die Sprachabdeckung eingeschränkt sind.
Die meisten Methoden verwenden Encoder im BERT-Stil und ignorieren den Trainingsfortschritt besserer LLM und verwandter Techniken.
Das Forschungsteam von Microsoft hat kürzlich eine einfache und effiziente Trainingsmethode zur Texteinbettung vorgeschlagen, um einige der Mängel früherer Methoden zu überwinden. Dieser Ansatz erfordert keine komplexen Pipeline-Designs oder manuell erstellten Datensätze, sondern nutzt LLM, um verschiedene Textdaten zu synthetisieren. Mit diesem Ansatz konnten sie hochwertige Texteinbettungen für Hunderttausende Texteinbettungsaufgaben in fast 100 Sprachen generieren, während der gesamte Trainingsprozess weniger als 1.000 Schritte umfasste.
 Link zum Papier: https://arxiv.org/abs/2401.00368
Link zum Papier: https://arxiv.org/abs/2401.00368
Konkret verwendeten die Forscher eine zweistufige Aufforderungsstrategie, indem sie zuerst den LLM-Brainstorming-Kandidaten-Aufgabenpool aufforderten und dann Aufforderung LLM generiert Daten für eine bestimmte Aufgabe aus dem Pool.
Um verschiedene Anwendungsszenarien abzudecken, entwarfen die Forscher mehrere Eingabeaufforderungsvorlagen für jeden Aufgabentyp und kombinierten die von verschiedenen Vorlagen generierten Daten, um die Vielfalt zu erhöhen.
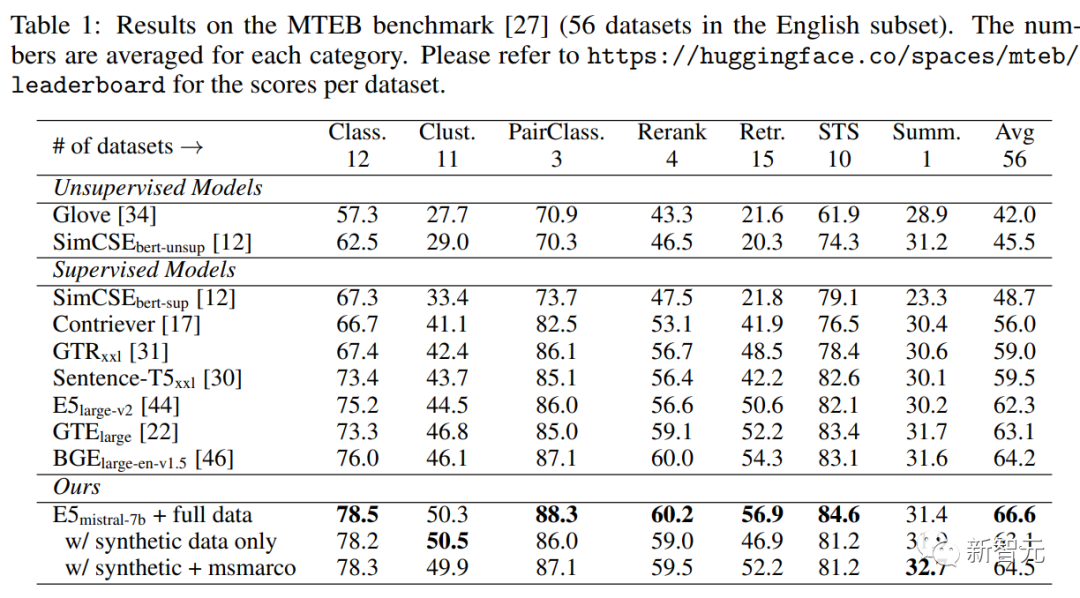
Experimentelle Ergebnisse belegen, dass Mistral-7B bei der Feinabstimmung „nur synthetischer Daten“ eine sehr wettbewerbsfähige Leistung bei den BEIR- und MTEB-Benchmarks erzielt; wenn die Feinabstimmung sowohl synthetischer als auch annotierter Daten hinzugefügt wird, wird eine Sota-Leistung erreicht.
Verwenden Sie große Modelle, um die Texteinbettung zu verbessern
1. Generierung synthetischer DatenDie Verwendung modernster großer Sprachmodelle (LLM) wie GPT-4 zur Synthese von Daten gewinnt immer mehr an Bedeutung , was das Modell hinsichtlich Multitasking und Mehrsprachenfähigkeitsvielfalt verbessern kann, wodurch robustere Texteinbettungen trainiert werden können, die bei verschiedenen nachgelagerten Aufgaben (z. B. semantischer Abruf, Textähnlichkeitsberechnung, Clustering) eine gute Leistung erbringen.
Um vielfältige synthetische Daten zu generieren, schlugen die Forscher eine einfache Taxonomie vor, die zunächst Einbettungsaufgaben klassifiziert und dann für jeden Aufgabentyp unterschiedliche Eingabeaufforderungsvorlagen verwendet.
Asymmetrische Aufgaben
Umfasst Aufgaben, bei denen die Abfrage und das Dokument semantisch miteinander verbunden sind, sich aber nicht gegenseitig umschreiben. Basierend auf der Länge der Abfrage und des Dokuments unterteilten die Forscher die asymmetrischen Aufgaben weiter in vier Unterkategorien: Short-Long-Matching (kurze Abfrage und langes Dokument, ein typisches Szenario in kommerziellen Suchmaschinen), Long-Short-Matching, kurz – Kurzes Spiel und langes langes Spiel. Für jede Unterkategorie entwarfen die Forscher eine zweistufige Eingabeaufforderungsvorlage, bei der sie LLM zunächst dazu aufforderten, eine Aufgabenliste zu erstellen, und dann ein spezifisches Beispiel für die aufgabendefinierten Bedingungen generierten. Die Ausgabe von GPT-4 war größtenteils kohärent. Die Qualität ist sehr hoch. In Vorversuchen versuchten die Forscher auch, mit einer einzigen Eingabeaufforderung Aufgabendefinitions- und Abfragedokumentpaare zu generieren, aber die Datenvielfalt war nicht so gut wie bei der oben erwähnten zweistufigen Methode. Symmetrieaufgaben umfassen hauptsächlich Abfragen und Dokumente mit ähnlicher Semantik, aber unterschiedlichen Oberflächenformen. In diesem Artikel werden zwei Anwendungsszenarien untersucht: monolinguale semantische Textähnlichkeit (STS) und Bi-Text-Retrieval. Für jedes Szenario werden zwei verschiedene Eingabeaufforderungsvorlagen entworfen, die seit der Definition der Aufgabe an ihre spezifischen Ziele angepasst werden relativ einfach ist, kann der Brainstorming-Schritt weggelassen werden. Um die Vielfalt der Eingabeaufforderungswörter weiter zu erhöhen und die Vielfalt der synthetischen Daten zu verbessern, haben die Forscher zu jeder Eingabeaufforderungstafel mehrere Platzhalter hinzugefügt und diese zur Laufzeit zufällig abgetastet. Beispielsweise steht „{query_length}“ für „Sampled from“. die Menge „{weniger als 5 Wörter, 5-10 Wörter, mindestens 10 Wörter}“. Um mehrsprachige Daten zu generieren, haben Forscher den Wert von „{Sprache}“ aus der Sprachliste von XLM-R entnommen und dabei allen generierten Daten, die nicht dem vordefinierten JSON entsprechen, mehr Gewicht gegeben Das Format wird beim Parsen verworfen; Duplikate werden auch basierend auf der genauen Zeichenfolgenübereinstimmung entfernt. Verwenden Sie bei einem gegebenen Abfrage-Dokument-Paar zunächst die ursprüngliche Abfrage q+, um eine neue Anweisung q_inst zu generieren, wobei „{task_definition}“ ein Platzhalter zum Einbetten einer einsatzigen Beschreibung ist Aufgabensymbol. Für die generierten synthetischen Daten wird die Ausgabe des Brainstorming-Schritts verwendet; für andere Datensätze, wie z. B. MS-MARCO, erstellen Forscher manuell Aufgabendefinitionen und wenden sie auf alle Abfragen im Datensatz an, ohne die Dateien zu ändern Beliebiges Befehlspräfix am Ende. Auf diese Weise ist der Dokumentenindex vorgefertigt und die auszuführenden Aufgaben können angepasst werden, indem nur die Abfrageseite geändert wird. Hängen Sie bei einem vorab trainierten LLM ein [EOS]-Token an das Ende der Abfrage und des Dokuments an und geben Sie es dann in das LLM ein, um die Abfrage- und Dokumenteinbettungen zu erhalten, indem Sie den [EOS]-Vektor der letzten Ebene abrufen. Dann verwenden Sie den Standard-InfoNCE-Verlust, um den Verlust für Intra-Batch-Negative und Hard-Negative zu berechnen. wobei ℕ die Menge aller Negative darstellt, Die Forscher nutzten den Azure OpenAI-Dienst, um 500.000 Beispiele mit 150.000 eindeutigen Anweisungen zu generieren, von denen 25 % von GPT-3.5-Turbo und der Rest von GPT-4 generiert wurden , die insgesamt 180 Millionen Token verbrauchte. Die Hauptsprache ist Englisch und deckt insgesamt 93 Sprachen ab. Für 75 ressourcenarme Sprachen gibt es durchschnittlich etwa 1.000 Beispiele pro Sprache. In Bezug auf die Datenqualität stellten die Forscher fest, dass einige der Ergebnisse von GPT-3.5-Turbo nicht strikt den in der Eingabeaufforderungsvorlage angegebenen Richtlinien entsprachen, die Gesamtqualität jedoch dennoch akzeptabel und vorläufig war Experimente haben auch gezeigt, dass die Verwendung dieser Teilmenge von Daten Vorteile bietet. Modellfeinabstimmung und -bewertung Die Forscher nutzten den oben genannten Verlust, um den vorab trainierten Mistral-7B für eine Epoche zu optimieren, folgten der Trainingsmethode von RankLLaMA und verwendeten LoRA mit Rang 16 . Um den GPU-Speicherbedarf weiter zu reduzieren, kommen Technologien wie Gradient Checkpointing, Mixed Precision Training und DeepSpeed ZeRO-3 zum Einsatz. In Bezug auf Trainingsdaten wurden sowohl generierte synthetische Daten als auch 13 öffentliche Datensätze verwendet, was nach der Stichprobe zu etwa 1,8 Millionen Beispielen führte. Für einen fairen Vergleich mit einigen früheren Arbeiten berichten die Forscher auch über Ergebnisse, wenn die einzige Annotationsüberwachung der MS-MARCO-Kapitelranking-Datensatz ist, und bewerten das Modell auch anhand des MTEB-Benchmarks. Wie Sie in der Tabelle unten sehen können, erreichte das im Artikel erhaltene Modell „E5mistral-7B + vollständige Daten“ die höchste durchschnittliche Punktzahl im MTEB-Benchmark, die 2,4 höher ist als das vorherige fortschrittlichstes Modell. In der Einstellung „nur mit synthetischen Daten“ werden keine annotierten Daten für das Training verwendet, aber die Leistung ist immer noch sehr konkurrenzfähig. Die Forscher verglichen auch mehrere kommerzielle Texteinbettungsmodelle, aber die mangelnde Transparenz und Dokumentation dieser Modelle verhinderte einen fairen Vergleich. Aus den Ergebnissen des Abrufleistungsvergleichs auf dem BEIR-Benchmark geht jedoch hervor, dass das trainierte Modell dem aktuellen kommerziellen Modell weit überlegen ist. Mehrsprachiger Abruf Um die Mehrsprachigkeit des Modells zu bewerten, führten die Forscher eine Auswertung des MIRACL-Datensatzes durch, der von Menschen kommentierte Abfragen und Relevanzbeurteilungen in 18 Sprachen enthält. Die Ergebnisse zeigen, dass das Modell mE5-large in ressourcenreichen Sprachen, insbesondere in Englisch, übertrifft und seine Leistung besser ist. Für ressourcenarme Sprachen ist das Modell jedoch immer noch nicht ideal im Vergleich zu mE5-base. Die Forscher führen dies darauf zurück, dass Mistral-7B vorab hauptsächlich anhand englischer Daten trainiert wurde, eine Methode, mit der prädiktive mehrsprachige Modelle diese Lücke schließen können. 
2. Training
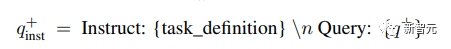
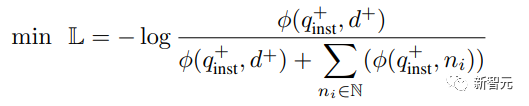
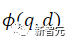 zur Berechnung des Matching-Scores zwischen der Abfrage und dem Dokument verwendet wird, t ein Temperatur-Hyperparameter ist, der im Experiment auf 0,02 festgelegt wurde
zur Berechnung des Matching-Scores zwischen der Abfrage und dem Dokument verwendet wird, t ein Temperatur-Hyperparameter ist, der im Experiment auf 0,02 festgelegt wurde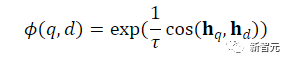
Experimentergebnisse
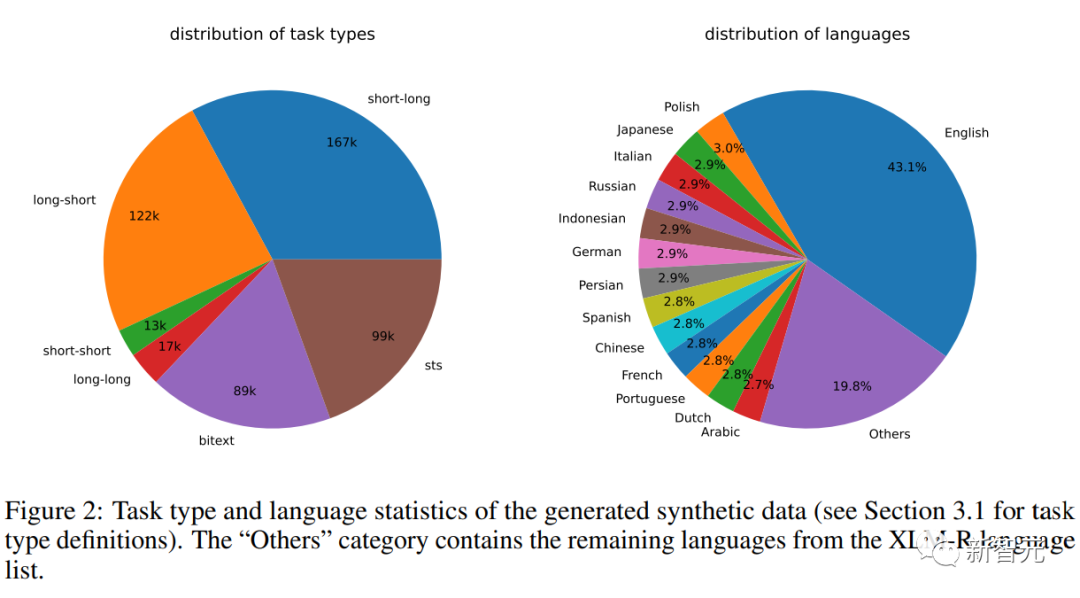
Synthetische Datenstatistik
Hauptergebnisse
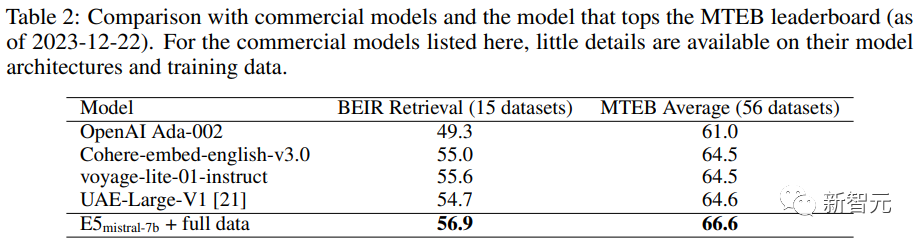
Das obige ist der detaillierte Inhalt vonKeine manuelle Anmerkung erforderlich! LLM unterstützt das Lernen der Texteinbettung: Unterstützt problemlos 100 Sprachen und passt sich Hunderttausenden nachgelagerten Aufgaben an. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Was? Wird Zootopia durch heimische KI in die Realität umgesetzt? Zusammen mit dem Video wird ein neues groß angelegtes inländisches Videogenerationsmodell namens „Keling“ vorgestellt. Sora geht einen ähnlichen technischen Weg und kombiniert eine Reihe selbst entwickelter technologischer Innovationen, um Videos zu produzieren, die nicht nur große und vernünftige Bewegungen aufweisen, sondern auch die Eigenschaften der physischen Welt simulieren und über starke konzeptionelle Kombinationsfähigkeiten und Vorstellungskraft verfügen. Den Daten zufolge unterstützt Keling die Erstellung ultralanger Videos von bis zu 2 Minuten mit 30 Bildern pro Sekunde, mit Auflösungen von bis zu 1080p und unterstützt mehrere Seitenverhältnisse. Ein weiterer wichtiger Punkt ist, dass es sich bei Keling nicht um eine vom Labor veröffentlichte Demo oder Video-Ergebnisdemonstration handelt, sondern um eine Anwendung auf Produktebene, die von Kuaishou, einem führenden Anbieter im Bereich Kurzvideos, gestartet wurde. Darüber hinaus liegt das Hauptaugenmerk darauf, pragmatisch zu sein, keine Blankoschecks auszustellen und sofort nach der Veröffentlichung online zu gehen. Das große Modell von Ke Ling wurde bereits in Kuaiying veröffentlicht.
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
