
 Java
javaLernprogramm
Flume vs. Kafka: Welches Tool eignet sich besser für die Handhabung Ihrer Datenflüsse?
Java
javaLernprogramm
Flume vs. Kafka: Welches Tool eignet sich besser für die Handhabung Ihrer Datenflüsse?
Flume vs. Kafka: Welches Tool eignet sich besser für die Handhabung Ihrer Datenflüsse?


Flume vs. Kafka: Welches Tool ist besser für die Verarbeitung Ihres Datenstroms?
Überblick
Flume und Kafka sind beide beliebte Tools zur Datenstromverarbeitung, mit denen große Mengen an Echtzeitdaten gesammelt, aggregiert und übertragen werden. Beide zeichnen sich durch hohen Durchsatz, geringe Latenz und Zuverlässigkeit aus, weisen jedoch einige Unterschiede in den Funktionen, der Architektur und den anwendbaren Szenarien auf.
Flume
Flume ist ein verteiltes, zuverlässiges und hochverfügbares Datenerfassungs-, Aggregations- und Übertragungssystem, das Daten aus verschiedenen Quellen sammeln und diese dann in HDFS, HBase oder anderen Speichersystemen speichern kann. Flume besteht aus mehreren Komponenten, darunter:
- Agent: Der Flume-Agent ist für das Sammeln von Daten aus Datenquellen verantwortlich.
- Kanal: Der Flume-Kanal ist für die Speicherung und Pufferung von Daten verantwortlich.
- Sink: Flume Sink ist für das Schreiben von Daten in das Speichersystem verantwortlich.
Zu den Vorteilen von Flume gehören:
- Einfach zu bedienen: Flume verfügt über eine benutzerfreundliche Oberfläche und eine einfache Konfiguration, wodurch es einfach zu installieren und zu verwenden ist.
- Hoher Durchsatz: Flume kann große Datenmengen verarbeiten und eignet sich daher für Big-Data-Verarbeitungsszenarien.
- Zuverlässigkeit: Flume verfügt über einen zuverlässigen Datenübertragungsmechanismus, um sicherzustellen, dass keine Daten verloren gehen.
Zu den Nachteilen von Flume gehören:
- Geringe Latenz: Flume hat eine hohe Latenz und ist nicht für Szenarien geeignet, die eine Echtzeitverarbeitung von Daten erfordern.
- Skalierbarkeit: Flume verfügt über eine begrenzte Skalierbarkeit und ist nicht für Szenarien geeignet, die die Verarbeitung großer Datenmengen erfordern.
Kafka
Kafka ist ein verteiltes, skalierbares und fehlertolerantes Nachrichtensystem, das große Mengen an Echtzeitdaten speichern und verarbeiten kann. Kafka besteht aus mehreren Komponenten, darunter:
- Broker: Der Kafka-Broker ist für die Speicherung und Verwaltung von Daten verantwortlich.
- Thema: Ein Kafka-Thema ist eine logische Datenpartition, die mehrere Partitionen enthalten kann.
- Partition: Die Kafka-Partition ist eine physische Datenspeichereinheit, die eine bestimmte Datenmenge speichern kann.
- Verbraucher: Der Kafka-Verbraucher ist für die Nutzung von Daten aus Kafka-Themen verantwortlich.
Zu den Vorteilen von Kafka gehören:
- Hoher Durchsatz: Kafka kann große Datenmengen verarbeiten und eignet sich daher für Big-Data-Verarbeitungsszenarien.
- Geringe Latenz: Kafka hat eine geringe Latenz und eignet sich daher für Szenarien, die eine Echtzeitverarbeitung von Daten erfordern.
- Skalierbarkeit: Kafka verfügt über eine gute Skalierbarkeit, sodass es problemlos erweitert werden kann, um mehr Daten zu verarbeiten.
Zu den Nachteilen von Kafka gehören:
- Komplexität: Die Konfiguration und Verwaltung von Kafka ist komplexer und erfordert gewisse technische Erfahrung.
- Zuverlässigkeit: Kafkas Datenspeichermechanismus ist nicht zuverlässig und Daten können verloren gehen.
Anwendbare Szenarien
Sowohl Flume als auch Kafka eignen sich für Big-Data-Verarbeitungsszenarien, unterscheiden sich jedoch in bestimmten Anwendungsszenarien.
Flume eignet sich für folgende Szenarien:
- Müssen Daten aus verschiedenen Quellen gesammelt und aggregiert werden.
- Erfordert die Speicherung der Daten in HDFS, HBase oder anderen Speichersystemen.
- Erfordert eine einfache Verarbeitung und Transformation von Daten.
Kafka eignet sich für folgende Szenarien:
- Muss große Mengen an Echtzeitdaten verarbeiten.
- Erfordert eine komplexe Verarbeitung und Analyse von Daten.
- Erfordert die Speicherung der Daten in einem verteilten Dateisystem.
Codebeispiel
Flume
# 创建一个Flume代理 agent1.sources = r1 agent1.sinks = hdfs agent1.channels = c1 # 配置数据源 r1.type = exec r1.command = tail -F /var/log/messages # 配置数据通道 c1.type = memory c1.capacity = 1000 c1.transactionCapacity = 100 # 配置数据汇 hdfs.type = hdfs hdfs.hdfsUrl = hdfs://localhost:9000 hdfs.fileName = /flume/logs hdfs.rollInterval = 3600 hdfs.rollSize = 10485760
Kafka
# 创建一个Kafka主题 kafka-topics --create --topic my-topic --partitions 3 --replication-factor 2 # 启动一个Kafka代理 kafka-server-start config/server.properties # 启动一个Kafka生产者 kafka-console-producer --topic my-topic # 启动一个Kafka消费者 kafka-console-consumer --topic my-topic --from-beginning
Fazit
Flume und Kafka sind beide beliebte Tools zur Datenstromverarbeitung mit unterschiedlichen Funktionen, Architekturen und anwendbaren Szenarien. Bei der Auswahl müssen Sie Ihre spezifischen Bedürfnisse bewerten.
Das obige ist der detaillierte Inhalt vonFlume vs. Kafka: Welches Tool eignet sich besser für die Handhabung Ihrer Datenflüsse?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1359
1359
 52
52

 So geben Sie mit @KafkaListener in Springboot + Kafka dynamisch mehrere Themen an
May 20, 2023 pm 08:58 PM
So geben Sie mit @KafkaListener in Springboot + Kafka dynamisch mehrere Themen an
May 20, 2023 pm 08:58 PM
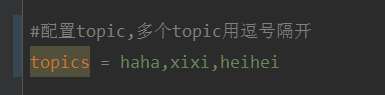
Erklären Sie, dass es sich bei diesem Projekt um ein Springboot+Kafak-Integrationsprojekt handelt und daher die Kafak-Verbrauchsanmerkung @KafkaListener in Springboot verwendet. Konfigurieren Sie zunächst mehrere durch Kommas getrennte Themen in application.properties. Methode: Verwenden Sie den SpEl-Ausdruck von Spring, um Themen wie folgt zu konfigurieren: @KafkaListener(topics="#{’${topics}’.split(',')}"), um das Programm auszuführen. Der Konsolendruckeffekt ist wie folgt
 So implementieren Sie eine Echtzeit-Aktienanalyse mit PHP und Kafka
Jun 28, 2023 am 10:04 AM
So implementieren Sie eine Echtzeit-Aktienanalyse mit PHP und Kafka
Jun 28, 2023 am 10:04 AM
Mit der Entwicklung des Internets und der Technologie sind digitale Investitionen zu einem Thema mit zunehmender Besorgnis geworden. Viele Anleger erforschen und studieren weiterhin Anlagestrategien in der Hoffnung, eine höhere Kapitalrendite zu erzielen. Im Aktienhandel ist die Aktienanalyse in Echtzeit für die Entscheidungsfindung sehr wichtig, und der Einsatz der Kafka-Echtzeit-Nachrichtenwarteschlange und der PHP-Technologie ist ein effizientes und praktisches Mittel. 1. Einführung in Kafka Kafka ist ein von LinkedIn entwickeltes verteiltes Publish- und Subscribe-Messagingsystem mit hohem Durchsatz. Die Hauptmerkmale von Kafka sind
 Fünf Auswahlmöglichkeiten an Visualisierungstools zur Erkundung von Kafka
Feb 01, 2024 am 08:03 AM
Fünf Auswahlmöglichkeiten an Visualisierungstools zur Erkundung von Kafka
Feb 01, 2024 am 08:03 AM
Fünf Optionen für Kafka-Visualisierungstools ApacheKafka ist eine verteilte Stream-Verarbeitungsplattform, die große Mengen an Echtzeitdaten verarbeiten kann. Es wird häufig zum Aufbau von Echtzeit-Datenpipelines, Nachrichtenwarteschlangen und ereignisgesteuerten Anwendungen verwendet. Die Visualisierungstools von Kafka können Benutzern dabei helfen, Kafka-Cluster zu überwachen und zu verwalten und Kafka-Datenflüsse besser zu verstehen. Im Folgenden finden Sie eine Einführung in fünf beliebte Kafka-Visualisierungstools: ConfluentControlCenterConfluent
 Vergleichende Analyse der Kafka-Visualisierungstools: Wie wählt man das am besten geeignete Tool aus?
Jan 05, 2024 pm 12:15 PM
Vergleichende Analyse der Kafka-Visualisierungstools: Wie wählt man das am besten geeignete Tool aus?
Jan 05, 2024 pm 12:15 PM
Wie wählt man das richtige Kafka-Visualisierungstool aus? Vergleichende Analyse von fünf Tools Einführung: Kafka ist ein leistungsstarkes verteiltes Nachrichtenwarteschlangensystem mit hohem Durchsatz, das im Bereich Big Data weit verbreitet ist. Mit der Popularität von Kafka benötigen immer mehr Unternehmen und Entwickler ein visuelles Tool zur einfachen Überwachung und Verwaltung von Kafka-Clustern. In diesem Artikel werden fünf häufig verwendete Kafka-Visualisierungstools vorgestellt und ihre Merkmale und Funktionen verglichen, um den Lesern bei der Auswahl des Tools zu helfen, das ihren Anforderungen entspricht. 1. KafkaManager
 Wie installiere ich Apache Kafka unter Rocky Linux?
Mar 01, 2024 pm 10:37 PM
Wie installiere ich Apache Kafka unter Rocky Linux?
Mar 01, 2024 pm 10:37 PM
Um ApacheKafka auf RockyLinux zu installieren, können Sie die folgenden Schritte ausführen: Aktualisieren Sie das System: Stellen Sie zunächst sicher, dass Ihr RockyLinux-System auf dem neuesten Stand ist. Führen Sie den folgenden Befehl aus, um die Systempakete zu aktualisieren: sudoyumupdate Java installieren: ApacheKafka hängt von Java ab, also von Ihnen Sie müssen zuerst JavaDevelopmentKit (JDK) installieren. OpenJDK kann mit dem folgenden Befehl installiert werden: sudoyuminstalljava-1.8.0-openjdk-devel Herunterladen und dekomprimieren: Besuchen Sie die offizielle Website von ApacheKafka (), um das neueste Binärpaket herunterzuladen. Wählen Sie eine stabile Version
 So erstellen Sie Echtzeit-Datenverarbeitungsanwendungen mit React und Apache Kafka
Sep 27, 2023 pm 02:25 PM
So erstellen Sie Echtzeit-Datenverarbeitungsanwendungen mit React und Apache Kafka
Sep 27, 2023 pm 02:25 PM
So verwenden Sie React und Apache Kafka zum Erstellen von Echtzeit-Datenverarbeitungsanwendungen. Einführung: Mit dem Aufkommen von Big Data und Echtzeit-Datenverarbeitung ist die Erstellung von Echtzeit-Datenverarbeitungsanwendungen für viele Entwickler zum Ziel geworden. Die Kombination von React, einem beliebten Front-End-Framework, und Apache Kafka, einem leistungsstarken verteilten Messaging-System, kann uns beim Aufbau von Echtzeit-Datenverarbeitungsanwendungen helfen. In diesem Artikel wird erläutert, wie Sie mit React und Apache Kafka Echtzeit-Datenverarbeitungsanwendungen erstellen
 Die Praxis von Go-Zero und Kafka+Avro: Aufbau eines leistungsstarken interaktiven Datenverarbeitungssystems
Jun 23, 2023 am 09:04 AM
Die Praxis von Go-Zero und Kafka+Avro: Aufbau eines leistungsstarken interaktiven Datenverarbeitungssystems
Jun 23, 2023 am 09:04 AM
In den letzten Jahren haben mit dem Aufkommen von Big Data und aktiven Open-Source-Communities immer mehr Unternehmen begonnen, nach leistungsstarken interaktiven Datenverarbeitungssystemen zu suchen, um den wachsenden Datenanforderungen gerecht zu werden. In dieser Welle von Technologie-Upgrades werden Go-Zero und Kafka+Avro von immer mehr Unternehmen beachtet und übernommen. go-zero ist ein auf der Golang-Sprache entwickeltes Microservice-Framework. Es zeichnet sich durch hohe Leistung, Benutzerfreundlichkeit, einfache Erweiterung und einfache Wartung aus und soll Unternehmen dabei helfen, schnell effiziente Microservice-Anwendungssysteme aufzubauen. sein schnelles Wachstum
 Vertiefendes Verständnis des zugrunde liegenden Implementierungsmechanismus der Kafka-Nachrichtenwarteschlange
Feb 01, 2024 am 08:15 AM
Vertiefendes Verständnis des zugrunde liegenden Implementierungsmechanismus der Kafka-Nachrichtenwarteschlange
Feb 01, 2024 am 08:15 AM
Überblick über die zugrunde liegenden Implementierungsprinzipien der Kafka-Nachrichtenwarteschlange Kafka ist ein verteiltes, skalierbares Nachrichtenwarteschlangensystem, das große Datenmengen verarbeiten kann und einen hohen Durchsatz und eine geringe Latenz aufweist. Kafka wurde ursprünglich von LinkedIn entwickelt und ist heute ein Top-Level-Projekt der Apache Software Foundation. Architektur Kafka ist ein verteiltes System, das aus mehreren Servern besteht. Jeder Server wird als Knoten bezeichnet und jeder Knoten ist ein unabhängiger Prozess. Knoten werden über ein Netzwerk verbunden, um einen Cluster zu bilden. K
