
 Java
javaLernprogramm
Detaillierte Erläuterung der Kafka-Startbefehlsparameter und Optimierungsvorschläge
Java
javaLernprogramm
Detaillierte Erläuterung der Kafka-Startbefehlsparameter und Optimierungsvorschläge
Detaillierte Erläuterung der Kafka-Startbefehlsparameter und Optimierungsvorschläge


Kafka-Startbefehlsparameteranalyse und -optimierungsleitfaden
1. Startbefehlsparameteranalyse
Das Format des Kafka-Startbefehls ist wie folgt:
kafka-server-start.sh [options] [config.file]
Daunter Optionen</code > ist der Startbefehlsparameter, <code>config.file ist die Kafka-Konfigurationsdatei. options是启动命令的参数,config.file是Kafka配置文件。
常见的启动命令参数有:
-daemon: 以守护进程的方式启动Kafka。-port: 指定Kafka监听的端口号。默认端口号为9092。-log.dirs: 指定Kafka日志文件的存储目录。-zookeeper.connect: 指定Kafka连接ZooKeeper的地址。-broker.id: 指定Kafka代理的ID。-num.partitions: 指定每个主题的分区数。-replication.factor: 指定每个主题的副本数。-min.insync.replicas: 指定每个主题的最小同步副本数。
2. 启动命令参数优化
为了提高Kafka的性能,我们可以对启动命令参数进行优化。
常见的优化参数有:
-num.io.threads: 指定Kafka处理IO请求的线程数。默认值为8。-num.network.threads: 指定Kafka处理网络请求的线程数。默认值为8。-num.replica.fetchers: 指定每个副本从领导者副本获取数据的线程数。默认值为1。-num.replica.alter.log.dirs.threads: 指定更改副本日志文件存储目录的线程数。默认值为1。-socket.send.buffer.bytes: 指定Kafka发送数据的套接字缓冲区大小。默认值为102400。-socket.receive.buffer.bytes: 指定Kafka接收数据的套接字缓冲区大小。默认值为102400。-log.segment.bytes: 指定Kafka日志分段的大小。默认值为1073741824。-log.retention.hours: 指定Kafka日志保留的小时数。默认值为24。-log.retention.minutes
-daemon: Starten Sie Kafka als Daemon-Prozess.
-port: Geben Sie die Portnummer an, die Kafka abhört. Die Standard-Portnummer ist 9092. -log.dirs: Geben Sie das Speicherverzeichnis für Kafka-Protokolldateien an. -zookeeper.connect: Geben Sie die Adresse an, unter der Kafka eine Verbindung zu ZooKeeper herstellt. -broker.id: Geben Sie die ID des Kafka-Brokers an. -num.partitions: Geben Sie die Anzahl der Partitionen für jedes Thema an. -replication.factor: Gibt die Anzahl der Replikate pro Thema an. -min.insync.replicas: Gibt die Mindestanzahl synchronisierter Replikate pro Thema an. 🎜2. Optimierung der Startbefehlsparameter🎜🎜🎜Um die Leistung von Kafka zu verbessern, können wir die Startbefehlsparameter optimieren. 🎜🎜🎜Gemeinsame Optimierungsparameter sind: 🎜🎜-num.io.threads: Geben Sie die Anzahl der Threads an, die Kafka zur Verarbeitung von E/A-Anfragen verwendet. Der Standardwert ist 8. 🎜-num.network.threads: Geben Sie die Anzahl der Threads an, die Kafka zur Verarbeitung von Netzwerkanfragen verwendet. Der Standardwert ist 8. 🎜-num.replica.fetchers: Gibt die Anzahl der Threads für jedes Replikat an, um Daten vom führenden Replikat abzurufen. Der Standardwert ist 1. 🎜-num.replica.alter.log.dirs.threads: Geben Sie die Anzahl der Threads an, um das Verzeichnis zu ändern, in dem Replikatprotokolldateien gespeichert werden. Der Standardwert ist 1. 🎜-socket.send.buffer.bytes: Gibt die Socket-Puffergröße an, damit Kafka Daten senden kann. Der Standardwert ist 102400. 🎜-socket.receive.buffer.bytes: Gibt die Socket-Puffergröße an, damit Kafka Daten empfängt. Der Standardwert ist 102400. 🎜-log.segment.bytes: Geben Sie die Größe der Kafka-Protokollsegmente an. Der Standardwert ist 1073741824. 🎜-log.retention.hours: Geben Sie die Anzahl der Stunden für die Kafka-Protokollaufbewahrung an. Der Standardwert ist 24. 🎜-log.retention.minutes: Geben Sie die Anzahl der Minuten für die Kafka-Protokollaufbewahrung an. Der Standardwert ist 0. 🎜🎜🎜🎜3. Codebeispiel🎜🎜🎜Das Folgende ist ein Beispiel für die Optimierung der Kafka-Startbefehlsparameter: 🎜🎜🎜4. Durch die Optimierung der Kafka-Startbefehlsparameter können wir die Leistung von Kafka verbessern. Bei der Optimierung von Parametern müssen diese entsprechend der tatsächlichen Situation angepasst werden. 🎜kafka-server-start.sh -daemon -port 9092 -log.dirs /var/log/kafka -zookeeper.connect localhost:2181 -broker.id 0 -num.partitions 1 -replication.factor 1 -min.insync.replicas 1 -num.io.threads 8 -num.network.threads 8 -num.replica.fetchers 1 -num.replica.alter.log.dirs.threads 1 -socket.send.buffer.bytes 102400 -socket.receive.buffer.bytes 102400 -log.segment.bytes 1073741824 -log.retention.hours 24 -log.retention.minutes 0
Nach dem Login kopierenDas obige ist der detaillierte Inhalt vonDetaillierte Erläuterung der Kafka-Startbefehlsparameter und Optimierungsvorschläge. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 So implementieren Sie eine Echtzeit-Aktienanalyse mit PHP und Kafka
Jun 28, 2023 am 10:04 AM
So implementieren Sie eine Echtzeit-Aktienanalyse mit PHP und Kafka
Jun 28, 2023 am 10:04 AM
Mit der Entwicklung des Internets und der Technologie sind digitale Investitionen zu einem Thema mit zunehmender Besorgnis geworden. Viele Anleger erforschen und studieren weiterhin Anlagestrategien in der Hoffnung, eine höhere Kapitalrendite zu erzielen. Im Aktienhandel ist die Aktienanalyse in Echtzeit für die Entscheidungsfindung sehr wichtig, und der Einsatz der Kafka-Echtzeit-Nachrichtenwarteschlange und der PHP-Technologie ist ein effizientes und praktisches Mittel. 1. Einführung in Kafka Kafka ist ein von LinkedIn entwickeltes verteiltes Publish- und Subscribe-Messagingsystem mit hohem Durchsatz. Die Hauptmerkmale von Kafka sind
 So geben Sie mit @KafkaListener in Springboot + Kafka dynamisch mehrere Themen an
May 20, 2023 pm 08:58 PM
So geben Sie mit @KafkaListener in Springboot + Kafka dynamisch mehrere Themen an
May 20, 2023 pm 08:58 PM
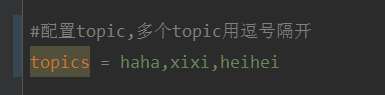
Erklären Sie, dass es sich bei diesem Projekt um ein Springboot+Kafak-Integrationsprojekt handelt und daher die Kafak-Verbrauchsanmerkung @KafkaListener in Springboot verwendet. Konfigurieren Sie zunächst mehrere durch Kommas getrennte Themen in application.properties. Methode: Verwenden Sie den SpEl-Ausdruck von Spring, um Themen wie folgt zu konfigurieren: @KafkaListener(topics="#{’${topics}’.split(',')}"), um das Programm auszuführen. Der Konsolendruckeffekt ist wie folgt
 Wie SpringBoot die Kafka-Konfigurationstoolklasse integriert
May 12, 2023 pm 09:58 PM
Wie SpringBoot die Kafka-Konfigurationstoolklasse integriert
May 12, 2023 pm 09:58 PM
Spring-Kafka basiert auf der Integration der Java-Version von Kafkaclient und Spring. Es bietet KafkaTemplate, das verschiedene Methoden für eine einfache Bedienung kapselt. Es kapselt den Kafka-Client von Apache und es ist nicht erforderlich, den Client zu importieren, um von der Organisation abhängig zu sein .springframework.kafkaspring-kafkaYML-Konfiguration. kafka:#bootstrap-servers:server1:9092,server2:9093#kafka-Entwicklungsadresse,#producer-Konfigurationsproduzent:#Serialisierungs- und Deserialisierungsklassenschlüssel, bereitgestellt von Kafka
 So erstellen Sie Echtzeit-Datenverarbeitungsanwendungen mit React und Apache Kafka
Sep 27, 2023 pm 02:25 PM
So erstellen Sie Echtzeit-Datenverarbeitungsanwendungen mit React und Apache Kafka
Sep 27, 2023 pm 02:25 PM
So verwenden Sie React und Apache Kafka zum Erstellen von Echtzeit-Datenverarbeitungsanwendungen. Einführung: Mit dem Aufkommen von Big Data und Echtzeit-Datenverarbeitung ist die Erstellung von Echtzeit-Datenverarbeitungsanwendungen für viele Entwickler zum Ziel geworden. Die Kombination von React, einem beliebten Front-End-Framework, und Apache Kafka, einem leistungsstarken verteilten Messaging-System, kann uns beim Aufbau von Echtzeit-Datenverarbeitungsanwendungen helfen. In diesem Artikel wird erläutert, wie Sie mit React und Apache Kafka Echtzeit-Datenverarbeitungsanwendungen erstellen
 Fünf Auswahlmöglichkeiten an Visualisierungstools zur Erkundung von Kafka
Feb 01, 2024 am 08:03 AM
Fünf Auswahlmöglichkeiten an Visualisierungstools zur Erkundung von Kafka
Feb 01, 2024 am 08:03 AM
Fünf Optionen für Kafka-Visualisierungstools ApacheKafka ist eine verteilte Stream-Verarbeitungsplattform, die große Mengen an Echtzeitdaten verarbeiten kann. Es wird häufig zum Aufbau von Echtzeit-Datenpipelines, Nachrichtenwarteschlangen und ereignisgesteuerten Anwendungen verwendet. Die Visualisierungstools von Kafka können Benutzern dabei helfen, Kafka-Cluster zu überwachen und zu verwalten und Kafka-Datenflüsse besser zu verstehen. Im Folgenden finden Sie eine Einführung in fünf beliebte Kafka-Visualisierungstools: ConfluentControlCenterConfluent
 Vergleichende Analyse der Kafka-Visualisierungstools: Wie wählt man das am besten geeignete Tool aus?
Jan 05, 2024 pm 12:15 PM
Vergleichende Analyse der Kafka-Visualisierungstools: Wie wählt man das am besten geeignete Tool aus?
Jan 05, 2024 pm 12:15 PM
Wie wählt man das richtige Kafka-Visualisierungstool aus? Vergleichende Analyse von fünf Tools Einführung: Kafka ist ein leistungsstarkes verteiltes Nachrichtenwarteschlangensystem mit hohem Durchsatz, das im Bereich Big Data weit verbreitet ist. Mit der Popularität von Kafka benötigen immer mehr Unternehmen und Entwickler ein visuelles Tool zur einfachen Überwachung und Verwaltung von Kafka-Clustern. In diesem Artikel werden fünf häufig verwendete Kafka-Visualisierungstools vorgestellt und ihre Merkmale und Funktionen verglichen, um den Lesern bei der Auswahl des Tools zu helfen, das ihren Anforderungen entspricht. 1. KafkaManager
 Beispielcode für ein Springboot-Projekt zum Konfigurieren mehrerer Kafka
May 14, 2023 pm 12:28 PM
Beispielcode für ein Springboot-Projekt zum Konfigurieren mehrerer Kafka
May 14, 2023 pm 12:28 PM
1.spring-kafkaorg.springframework.kafkaspring-kafka1.3.5.RELEASE2. Informationen zur Konfigurationsdatei kafka.bootstrap-servers=localhost:9092kafka.consumer.group.id=20230321#Die Anzahl der Threads, die gleichzeitig verwendet werden können (normalerweise konsistent). mit der Anzahl der Partitionen )kafka.consumer.concurrency=10kafka.consumer.enable.auto.commit=falsekafka.boo
 Wie installiere ich Apache Kafka unter Rocky Linux?
Mar 01, 2024 pm 10:37 PM
Wie installiere ich Apache Kafka unter Rocky Linux?
Mar 01, 2024 pm 10:37 PM
Um ApacheKafka auf RockyLinux zu installieren, können Sie die folgenden Schritte ausführen: Aktualisieren Sie das System: Stellen Sie zunächst sicher, dass Ihr RockyLinux-System auf dem neuesten Stand ist. Führen Sie den folgenden Befehl aus, um die Systempakete zu aktualisieren: sudoyumupdate Java installieren: ApacheKafka hängt von Java ab, also von Ihnen Sie müssen zuerst JavaDevelopmentKit (JDK) installieren. OpenJDK kann mit dem folgenden Befehl installiert werden: sudoyuminstalljava-1.8.0-openjdk-devel Herunterladen und dekomprimieren: Besuchen Sie die offizielle Website von ApacheKafka (), um das neueste Binärpaket herunterzuladen. Wählen Sie eine stabile Version
