
 Technologie-Peripheriegeräte
KI
Ein 8-jähriges Meisterwerk des Teams von NTU Zhou Zhihua! Das „Learningware'-System löst das Problem der Wiederverwendung maschinellen Lernens und die „Modellfusion' bringt ein neues Paradigma der wissenschaftlichen Forschung hervor
Technologie-Peripheriegeräte
KI
Ein 8-jähriges Meisterwerk des Teams von NTU Zhou Zhihua! Das „Learningware'-System löst das Problem der Wiederverwendung maschinellen Lernens und die „Modellfusion' bringt ein neues Paradigma der wissenschaftlichen Forschung hervor
Ein 8-jähriges Meisterwerk des Teams von NTU Zhou Zhihua! Das „Learningware'-System löst das Problem der Wiederverwendung maschinellen Lernens und die „Modellfusion' bringt ein neues Paradigma der wissenschaftlichen Forschung hervor

HuggingFace ist die beliebteste Open-Source-Community für maschinelles Lernen mit 300.000 verschiedenen Modellen für maschinelles Lernen und 100.000 verfügbaren Anwendungen.
Wenn diese 300.000 Modelle auf HuggingFace frei kombiniert werden könnten, um gemeinsam neue Lernaufgaben zu erledigen, wie würde es aussehen?
Tatsächlich schlug Professor Zhou Zhihua von der Universität Nanjing im Jahr 2016, als HuggingFace herauskam, das Konzept der „Learnware“ vor und zeichnete einen solchen Entwurf.
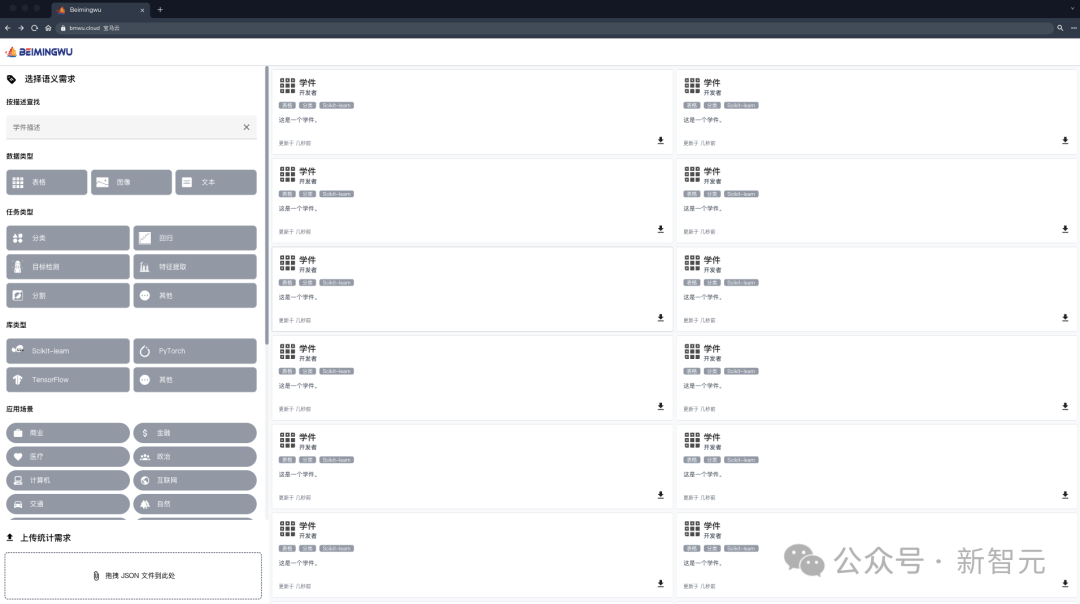
Kürzlich hat das Team von Professor Zhou Zhihua von der Universität Nanjing eine solche Plattform ins Leben gerufen – Beimingwu.
Adresse: https://bmwu.cloud/
Beimingwu bietet Forschern und Benutzern nicht nur die Möglichkeit, ihre eigenen Modelle hochzuladen, sondern führt auch Modellabgleich und Kollaborationsfusion entsprechend den Benutzeranforderungen durch, um das Lernen effizient abzuwickeln Aufgaben .

Papieradresse: https://arxiv.org/abs/2401.14427
Beimingwu Systemlager: https://www.gitlink.org.cn/beimingwu/beimingwu
Wissenschaftliche Forschung Toolkit-Lager: https://www.gitlink.org.cn/beimingwu/learnware
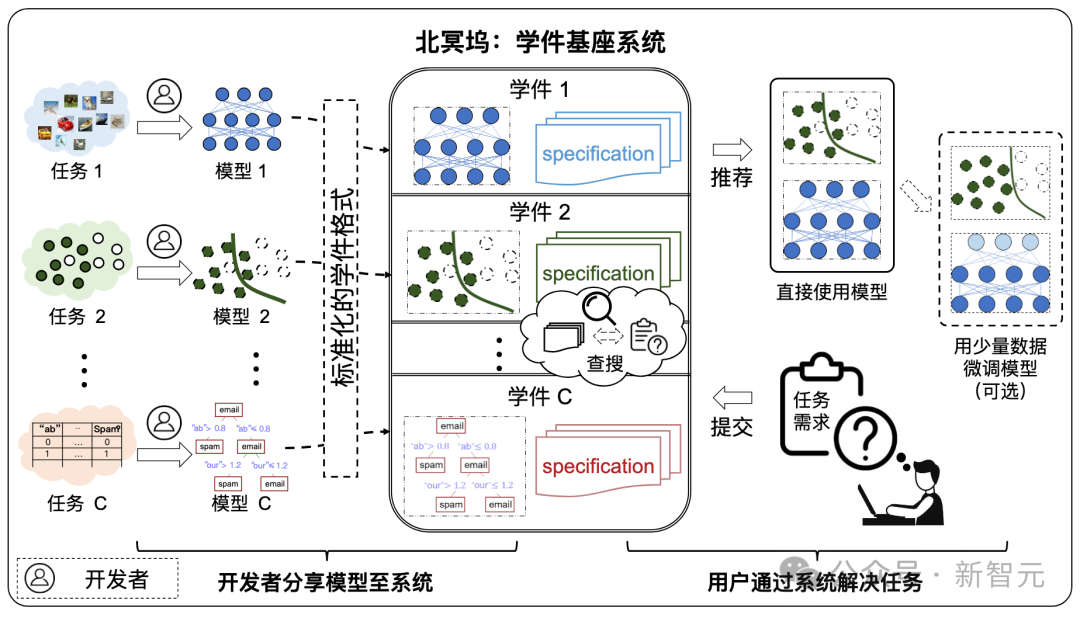
Das größte Merkmal dieser Plattform ist die Einführung des Learnware-Systems, wodurch ein Durchbruch bei der Realisierung von Modellen basierend auf Benutzerbedürfnissen erzielt wird. Adaptives Matching und Möglichkeiten zur Zusammenarbeit.
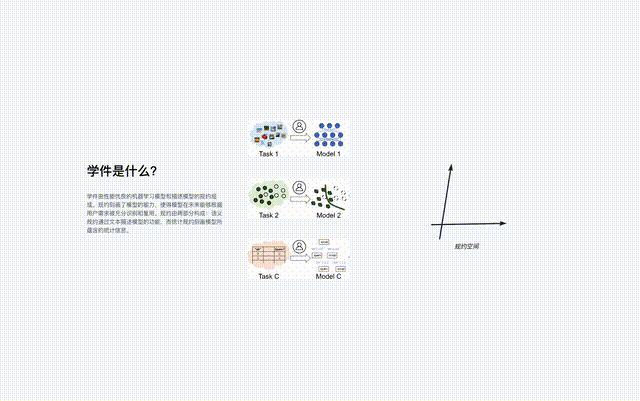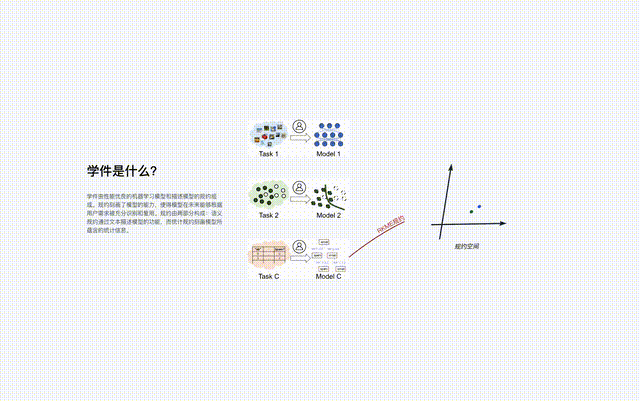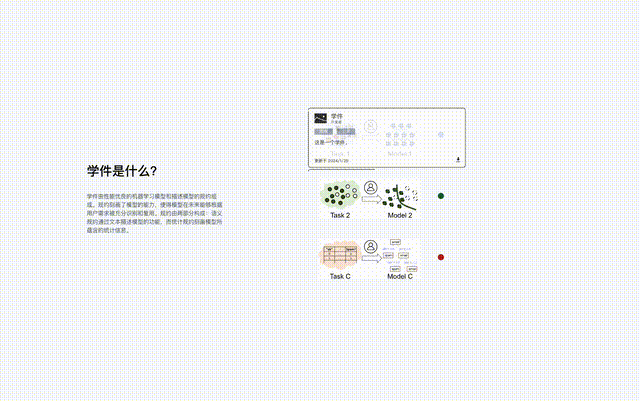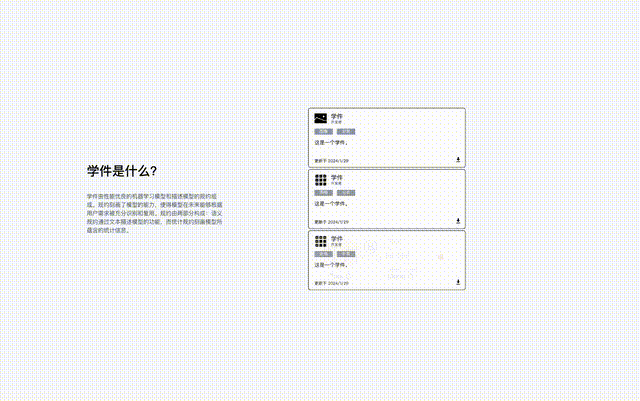
Learningware besteht aus einem Modell für maschinelles Lernen und einer Spezifikation, die das Modell beschreibt, also „Learningware = Modell + Spezifikation“.
Die Spezifikation der Lernsoftware besteht aus zwei Teilen: „semantische Spezifikation“ und „statistische Spezifikation“:
- semantische Spezifikation beschreibt die Art und Funktion des Modells durch Text;
- statistische Spezifikation nutzt verschiedene maschinelles Lernen Technologien, die die im Modell enthaltenen statistischen Informationen darstellen.
Die Spezifikation der Lernware beschreibt die Fähigkeiten des Modells, sodass das Modell in Zukunft vollständig erkannt und wiederverwendet werden kann, ohne dass der Benutzer im Voraus etwas über die Lernware weiß, um die Benutzeranforderungen zu erfüllen.
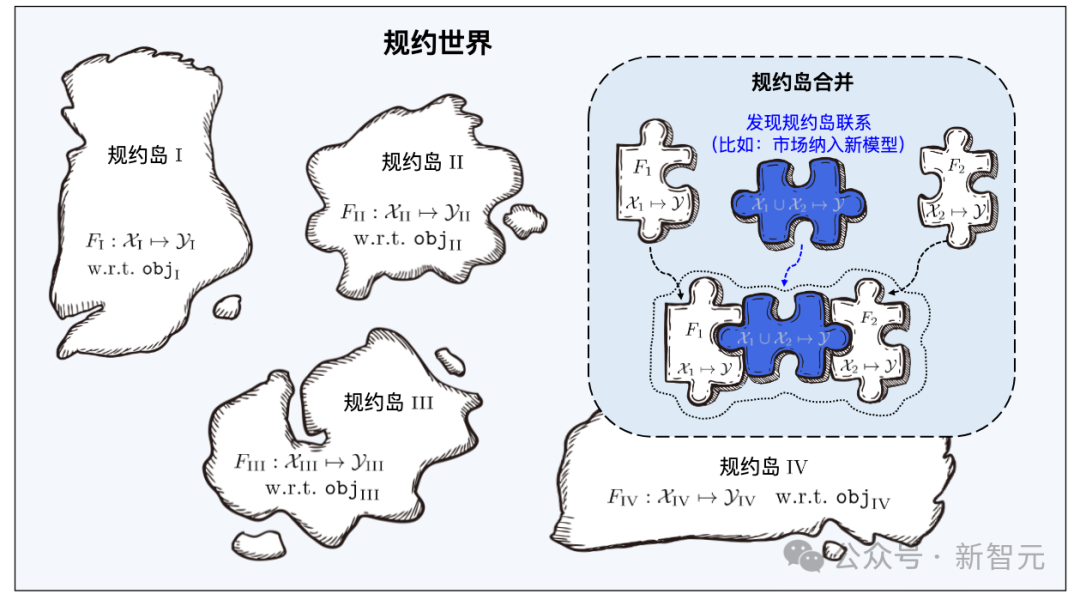
Das Protokoll ist die Kernkomponente des Learningware-Basissystems, das alle Learningware-Prozesse im System verbindet, einschließlich Hochladen, Organisation, Suche, Bereitstellung und Wiederverwendung von Learningware.
So wie Yanziwu in „Dragon“ aus vielen kleinen Inseln besteht, sind auch die Vorschriften in Beimingwu wie kleine Inseln.
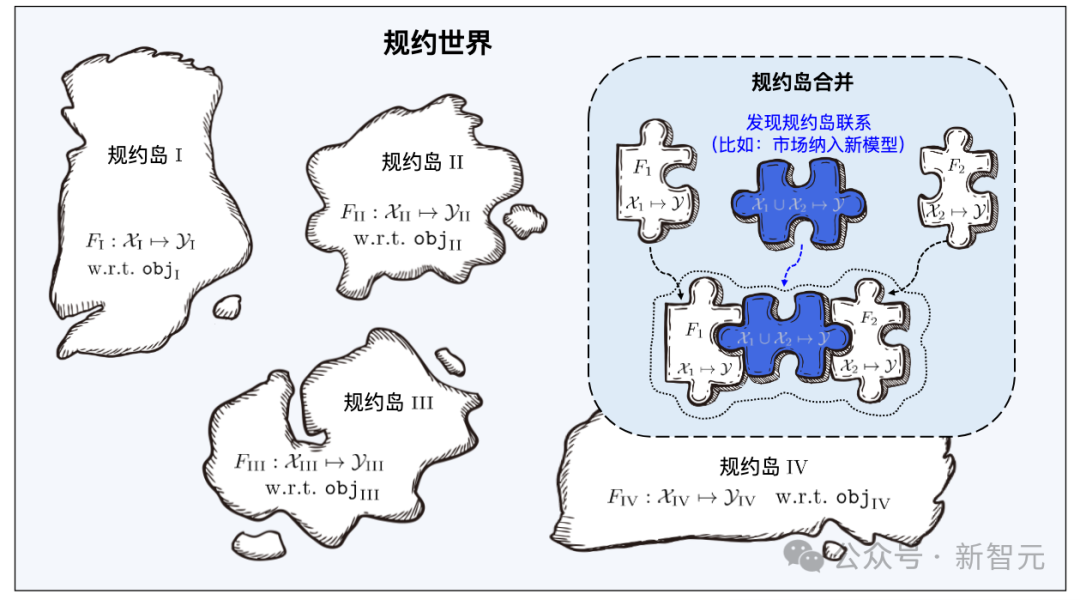
Learningware aus verschiedenen Feature-/Markerräumen bilden zahlreiche Protokollinseln, und alle Protokollinseln zusammen bilden die Protokollwelt im Learningware-Basissystem. Wenn in der Protokollwelt die Verbindungen zwischen verschiedenen Inseln entdeckt und hergestellt werden können, können die entsprechenden Protokollinseln zusammengeführt werden.
Unter dem Learningware-Paradigma können Entwickler auf der ganzen Welt Modelle für das Learningware-Basissystem freigeben. Das System hilft Benutzern, maschinelle Lernaufgaben effizient zu lösen, indem es Learningware effektiv durchsucht und wiederverwendet, ohne maschinelles Lernen von Grund auf neu erstellen zu müssen.
Beimingwu ist die erste systematische Open-Source-Implementierung akademischer Software und bietet eine vorläufige wissenschaftliche Forschungsplattform für akademische softwarebezogene Forschung.
Entwickler, die bereit sind, Modelle zu teilen, können das Learning Warehouse bei der Generierung von Spezifikationen zur Bildung von Lernsoftware unterstützen und diese im Learning Warehouse speichern. In diesem Prozess müssen Entwickler ihre Ausbildung nicht offenlegen Daten an das Learning Warehouse.
Zukünftige Benutzer können ihre Anforderungen an das Learning Warehouse übermitteln und mit Hilfe des Learning Warehouse nach wiederverwendeten Lernmaterialien suchen, um ihre maschinellen Lernaufgaben abzuschließen, und Benutzer müssen ihre eigenen Daten nicht an das Learning Warehouse weitergeben.
Und in Zukunft, wenn das Lerndock über Millionen von Lernstücken verfügt, wird es wahrscheinlich zu „emergentem“ Verhalten kommen: Aufgaben des maschinellen Lernens, für die es in der Vergangenheit keine speziell entwickelten Modelle gab, können durch die Wiederverwendung mehrerer vorhandener Lernstücke wiederverwendet werden. Und lösen.
Learningware-Basissystem
Maschinelles Lernen hat in vielen Bereichen große Erfolge erzielt, ist jedoch immer noch mit vielen Problemen konfrontiert, z. B. dem Bedarf an großen Mengen an Trainingsdaten und hervorragenden Trainingsfähigkeiten, der Schwierigkeit des kontinuierlichen Lernens und katastrophalen Folgen Vergessen. Risiken und Verlust von Datenschutz/Eigentum usw.
Obwohl es für jedes der oben genannten Probleme entsprechende Untersuchungen gibt, kann die Lösung eines der Probleme dazu führen, dass andere Probleme schwerwiegender werden, da die Probleme miteinander verknüpft sind.
Das Lernbasissystem hofft, durch einen Gesamtrahmen viele der oben genannten Probleme gleichzeitig zu lösen:
- Mangel an Trainingsdaten/Fähigkeiten: Auch für normale Benutzer, denen es an Trainingsfähigkeiten mangelt oder die nur über geringe Trainingsfähigkeiten verfügen Daten können sie leistungsstarke Modelle für maschinelles Lernen erhalten, da Benutzer leistungsstarke Lernware aus einem Lernware-Basissystem übernehmen und diese weiter optimieren oder verbessern können, anstatt das Modell selbst von Grund auf zu erstellen.
- Kontinuierliches Lernen: Da kontinuierlich Lernsoftware mit hervorragender Leistung für verschiedene Aufgaben eingereicht wird, wird das Wissen im Basissystem der Lernsoftware weiter bereichert, wodurch auf natürliche Weise kontinuierliches und lebenslanges Lernen realisiert wird.
- Katastrophales Vergessen: Sobald ein Lernstück empfangen wurde, wird es immer im Lernstück-Basissystem untergebracht, es sei denn, alle Aspekte seiner Funktionen können durch andere Lernstücke ersetzt werden. Daher bleibt altes Wissen im Lernbasissystem immer erhalten und wird nie vergessen.
- Datenschutz/Eigentum: Entwickler reichen nur Modelle ein, ohne private Daten weiterzugeben, sodass Datenschutz/Eigentum gut geschützt werden können. Obwohl die Möglichkeit eines Reverse Engineering des Modells nicht vollständig ausgeschlossen werden kann, ist das Risiko eines Datenschutzverlusts beim Lernbasissystem im Vergleich zu vielen anderen Datenschutzsystemen sehr gering.
Die Zusammensetzung des Learningware-Basissystems
Wie in der folgenden Abbildung dargestellt, ist der Systemworkflow in die folgenden zwei Phasen unterteilt:
- Übermittlungsphase: Entwickler senden spontan verschiedene Learningware an ein Basissystem für Lernstücke, die Qualitätsprüfungen und weitere Organisation durchführen.
- Bereitstellungsphase: Wenn der Benutzer Aufgabenanforderungen übermittelt, empfiehlt das Learningware-Basissystem Lernware, die gemäß der Learningware-Spezifikation für die Aufgabe des Benutzers hilfreich ist, und leitet den Benutzer bei der Bereitstellung und Wiederverwendung an.
Protokollwelt
Protokoll ist die Kernkomponente des Learningware-Basissystems, das alle Learningware-Prozesse im System verbindet, einschließlich Hochladen, Organisieren, Suchen, Bereitstellen und Wiederverwenden von Learningware.
Learningware aus verschiedenen Feature-/Markerräumen bilden zahlreiche Protokollinseln, und alle Protokollinseln zusammen bilden die Protokollwelt im Learningware-Basissystem. Wenn in der Protokollwelt die Verbindungen zwischen verschiedenen Inseln entdeckt und hergestellt werden können, können die entsprechenden Protokollinseln zusammengeführt werden.
Bei der Suche lokalisiert das Lernbasissystem zunächst die spezifische Protokollinsel anhand der semantischen Spezifikationen in den Benutzeranforderungen und identifiziert dann die Lernmaterialien auf der Protokollinsel anhand der statistischen Spezifikationen in den Benutzeranforderungen genau. Durch die Zusammenführung verschiedener Protokollinseln kann die entsprechende Lernsoftware für Aufgaben in unterschiedlichen Feature-/Marker-Räumen eingesetzt werden, also für Aufgaben über ihren ursprünglichen Zweck hinaus wiederverwendet werden.
Das Learningware-Paradigma schafft einen einheitlichen Spezifikationsraum, indem es die Fähigkeiten der von der Community gemeinsam genutzten Modelle für maschinelles Lernen voll ausnutzt und maschinelle Lernaufgaben für neue Benutzer auf einheitliche Weise effizient löst. Mit zunehmender Anzahl von Lernstücken wird durch eine effektive Organisation der Lernstückstruktur die Gesamtfähigkeit des Lernstück-Basissystems zur Lösung von Aufgaben erheblich verbessert.
Die Architektur von Beimingwu
Wie in der folgenden Abbildung dargestellt, umfasst die Systemarchitektur von Beimingwu vier Ebenen, von der Learningware-Speicherschicht bis zur Benutzerinteraktionsschicht. Es ist das erste Mal, dass Learningware systematisch implementiert wird das Bottom-up-Paradigma. Die spezifischen Funktionen der vier Ebenen sind wie folgt:
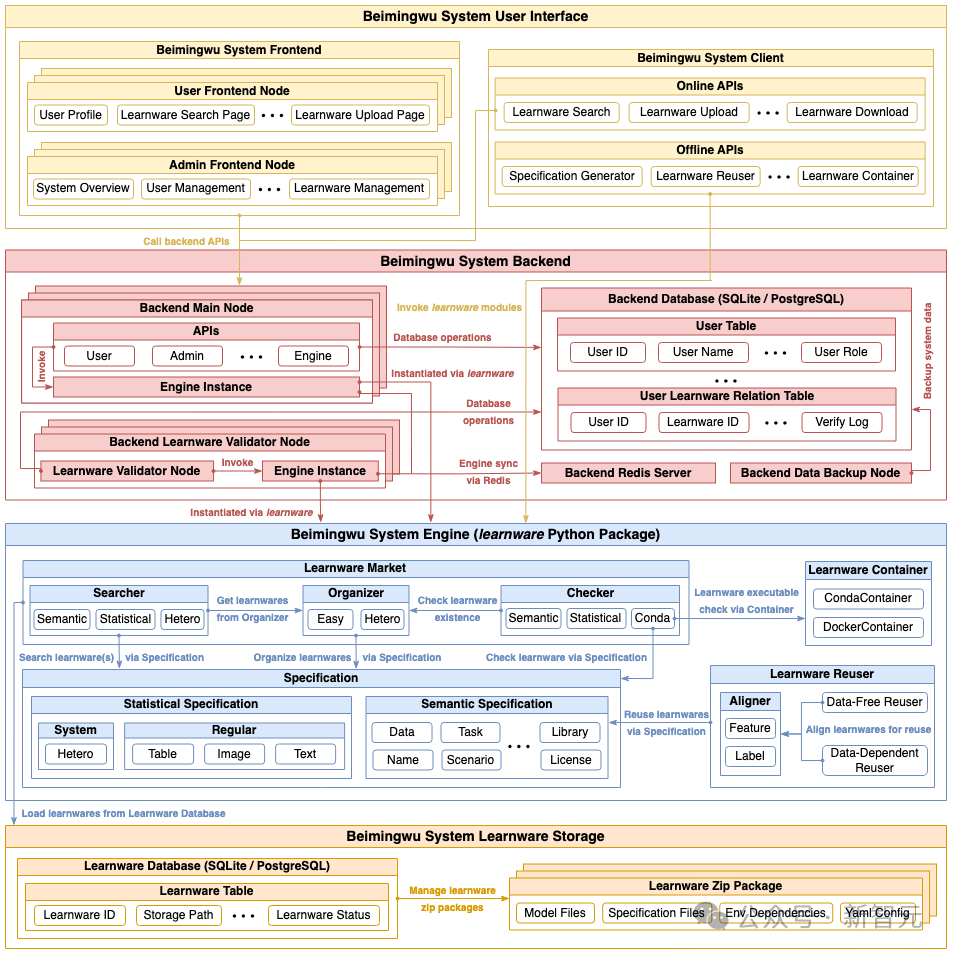
- Learningware-Speicherschicht: verwaltet im ZIP-Paketformat gespeicherte Lernware und bietet Zugriff auf relevante Informationen über die Learningware-Datenbank.
- System-Engine-Schicht: umfasst alle Prozesse im Learningware-Paradigma, einschließlich Hochladen, Erkennen, Organisieren, Suchen und Bereitstellen von Lernware und wiederverwenden und unabhängig vom Back-End und Front-End in Form eines Learnware-Python-Pakets ausführen, das eine umfangreiche Algorithmusschnittstelle für Learnware-bezogene Aufgaben und wissenschaftliche Forschungserkundung bietet.
- System-Back-End-Schicht: Implementierung Mit dem Durch die Bereitstellung von Beimingwu in Industriequalität werden stabile Online-Systemdienste bereitgestellt und die Benutzerinteraktion zwischen dem Front-End und dem Client durch die Bereitstellung einer umfangreichen Back-End-API unterstützt.
- Benutzerinteraktionsebene: Implementiert webbasiertes Front-End und Befehle zeilenbasiert Der Client bietet umfangreiche und bequeme Möglichkeiten für die Benutzerinteraktion.
Experimentelle Auswertung
In der Arbeit konstruierte das Forschungsteam auch verschiedene Arten grundlegender experimenteller Szenarien, um Benchmark-Algorithmen für die Protokollgenerierung, Lernartefakterkennung und Wiederverwendung in Tabellen, Bildern und Textdaten zu evaluieren.
Tabular Data Experiment
An verschiedenen tabellarischen Datensätzen bewertete das Team zunächst die Leistung der Identifizierung und Wiederverwendung von Learningware aus dem Learningware-System, das über denselben Funktionsraum wie die Benutzeraufgabe verfügt.
Da Formularaufgaben in der Regel aus unterschiedlichen Merkmalsräumen stammen, bewertete das Forschungsteam darüber hinaus auch die Identifizierung und Wiederverwendung von Lernstücken aus unterschiedlichen Merkmalsräumen.
Homogener Fall
Im homogenen Fall fungieren die 53 Filialen im PFS-Datensatz als 53 unabhängige Benutzer.
Jeder Store nutzt seine eigenen Testdaten als Benutzeraufgabendaten und verfolgt einen einheitlichen Feature-Engineering-Ansatz. Diese Benutzer können dann das Basissystem nach homogenen Lernelementen durchsuchen, die denselben Funktionsraum wie ihre Aufgaben haben.
Wenn der Benutzer keine gekennzeichneten Daten hat oder die Menge der gekennzeichneten Daten begrenzt ist, hat das Team verschiedene Benchmark-Algorithmen verglichen und der durchschnittliche Verlust für alle Benutzer ist in der folgenden Abbildung dargestellt. Die linke Tabelle zeigt, dass der datenfreie Ansatz viel besser ist als die zufällige Auswahl und Bereitstellung einer Lernware vom Markt. Das rechte Diagramm zeigt, dass die Identifizierung und Wiederverwendung einzelner oder mehrerer Lernware besser ist als die vom Benutzer trainierte Modelle. Bessere Leistung.
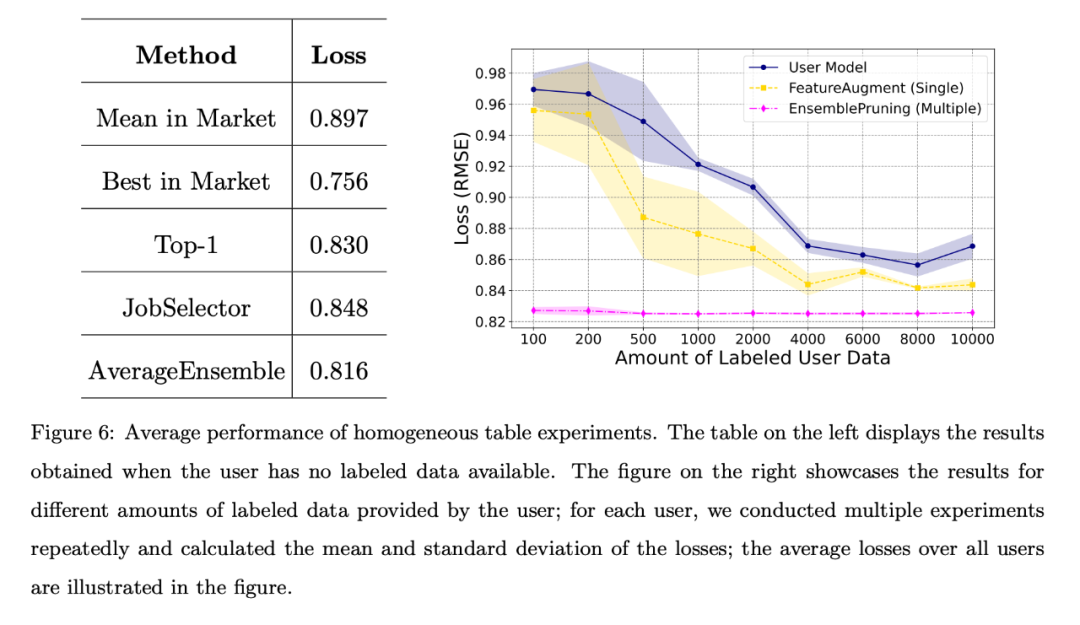
Die linke Tabelle zeigt, dass die datenfreie Methode viel besser ist als die zufällige Auswahl und Bereitstellung eines Lernstücks vom Markt. Die rechte Abbildung zeigt, dass bei begrenzten Trainingsdaten des Benutzers die Identifizierung und Wiederverwendung einzelner bzw Mehrfaches Lernen Die Software bietet eine bessere Leistung als das vom Benutzer trainierte Modell.
Heterogene Fälle
Basierend auf der Ähnlichkeit zwischen Marktsoftware und Benutzeraufgaben können heterogene Fälle weiter in unterschiedliche Feature-Engineering- und unterschiedliche Aufgabenszenarien unterteilt werden.
Verschiedene Feature-Engineering-Szenarien:
Die links in der Abbildung unten gezeigten Ergebnisse zeigen, dass die Lernsoftware im System auch dann eine starke Leistung zeigen kann, wenn dem Benutzer keine Annotationsdaten vorliegen, insbesondere wenn mehrere Lernsoftware vorhanden ist wird die AverageEnsemble-Methode wiederverwendet.
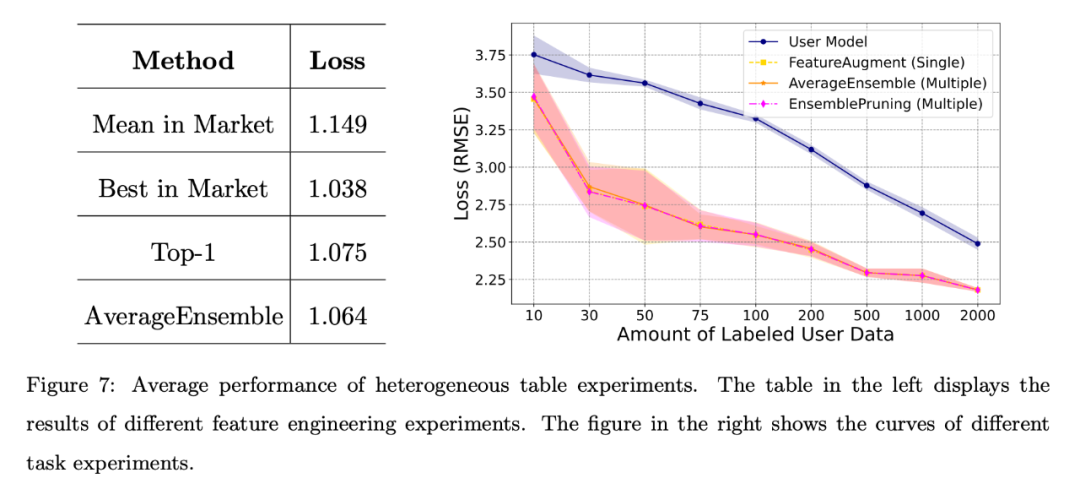
Verschiedene Aufgabenszenarien:
Die rechte Seite der Abbildung oben zeigt die Verlustkurven des Benutzer-Selbsttrainingsmodells und verschiedener Wiederverwendungsmethoden für Lernware.
Offensichtlich ist die experimentelle Überprüfung heterogener Lernkomponenten von Vorteil, wenn die Menge der vom Benutzer annotierten Daten begrenzt ist, und hilft dabei, sich besser an den Funktionsraum des Benutzers anzupassen.
Bild- und Textdatenexperimente
Darüber hinaus führte das Forschungsteam eine grundlegende Bewertung des Systems anhand von Bilddatensätzen durch.
Die folgende Abbildung zeigt, dass die Nutzung eines Lernbasissystems zu einer guten Leistung führen kann, wenn Benutzer mit einem Mangel an annotierten Daten konfrontiert sind oder nur über eine begrenzte Datenmenge (weniger als 2000 Instanzen) verfügen.
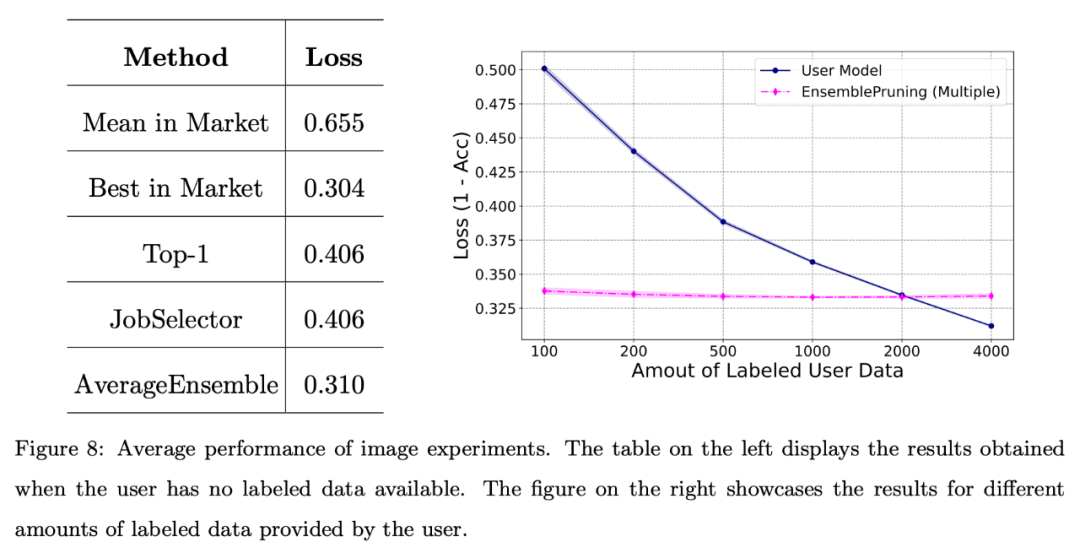
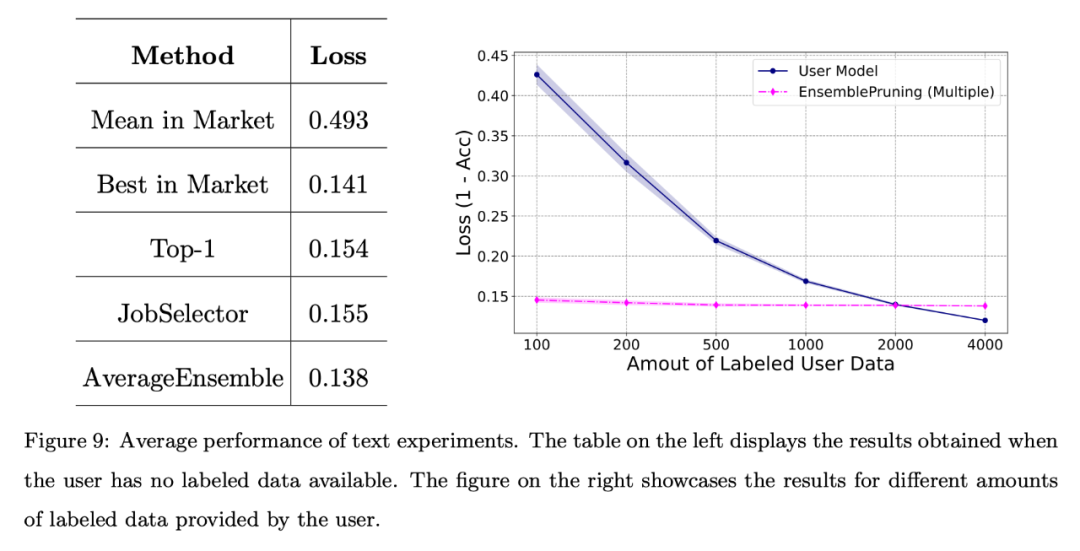
Das Team führte außerdem eine grundlegende Bewertung des Systems anhand eines Benchmark-Textdatensatzes durch. Feature-Space-Ausrichtung über einen einheitlichen Feature-Extraktor.
Wie in der folgenden Abbildung dargestellt, ist die durch die Identifizierung und Wiederverwendung von Lernware erzielte Leistung selbst dann, wenn keine Anmerkungsdaten bereitgestellt werden, mit der der besten Lernware im System vergleichbar.
Darüber hinaus können im Vergleich zum Training des Modells von Grund auf durch die Verwendung des Lernbasissystems etwa 2000 Proben eingespart werden.
Das obige ist der detaillierte Inhalt vonEin 8-jähriges Meisterwerk des Teams von NTU Zhou Zhihua! Das „Learningware'-System löst das Problem der Wiederverwendung maschinellen Lernens und die „Modellfusion' bringt ein neues Paradigma der wissenschaftlichen Forschung hervor. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.
Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
In Debian -Systemen wird die Readdir -Funktion zum Lesen des Verzeichnisinhalts verwendet, aber die Reihenfolge, in der sie zurückgibt, ist nicht vordefiniert. Um Dateien in einem Verzeichnis zu sortieren, müssen Sie zuerst alle Dateien lesen und dann mit der QSORT -Funktion sortieren. Der folgende Code zeigt, wie Verzeichnisdateien mithilfe von Readdir und QSORT in Debian System sortiert werden:#include#include#include#include // benutzerdefinierte Vergleichsfunktion, verwendet für QSortIntCompare (constvoid*a, constvoid*b) {rettrcmp (*(*(*(
 So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
In Debian -Systemen werden Readdir -Systemaufrufe zum Lesen des Verzeichnisinhalts verwendet. Wenn seine Leistung nicht gut ist, probieren Sie die folgende Optimierungsstrategie aus: Vereinfachen Sie die Anzahl der Verzeichnisdateien: Teilen Sie große Verzeichnisse so weit wie möglich in mehrere kleine Verzeichnisse auf und reduzieren Sie die Anzahl der gemäß Readdir -Anrufe verarbeiteten Elemente. Aktivieren Sie den Verzeichnis -Inhalt Caching: Erstellen Sie einen Cache -Mechanismus, aktualisieren Sie den Cache regelmäßig oder bei Änderungen des Verzeichnisinhalts und reduzieren Sie häufige Aufrufe an Readdir. Speicher -Caches (wie Memcached oder Redis) oder lokale Caches (wie Dateien oder Datenbanken) können berücksichtigt werden. Nehmen Sie eine effiziente Datenstruktur an: Wenn Sie das Verzeichnis -Traversal selbst implementieren, wählen Sie effizientere Datenstrukturen (z.
 Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Die Readdir -Funktion im Debian -System ist ein Systemaufruf, der zum Lesen des Verzeichnisgehalts verwendet wird und häufig in der C -Programmierung verwendet wird. In diesem Artikel wird erläutert, wie Readdir in andere Tools integriert wird, um seine Funktionalität zu verbessern. Methode 1: Kombinieren Sie C -Sprachprogramm und Pipeline zuerst ein C -Programm, um die Funktion der Readdir aufzurufen und das Ergebnis auszugeben:#include#include#includeIntmain (intargc, char*argv []) {Dir*Dir; structDirent*Eintrag; if (argc! = 2) {{
 Wie Debian OpenSSL verhindert, dass Mann-in-the-Middle-Angriffe
Apr 13, 2025 am 10:30 AM
Wie Debian OpenSSL verhindert, dass Mann-in-the-Middle-Angriffe
Apr 13, 2025 am 10:30 AM
In Debian Systems ist OpenSSL eine wichtige Bibliothek für Verschlüsselung, Entschlüsselung und Zertifikatverwaltung. Um einen Mann-in-the-Middle-Angriff (MITM) zu verhindern, können folgende Maßnahmen ergriffen werden: Verwenden Sie HTTPS: Stellen Sie sicher, dass alle Netzwerkanforderungen das HTTPS-Protokoll anstelle von HTTP verwenden. HTTPS verwendet TLS (Transport Layer Security Protocol), um Kommunikationsdaten zu verschlüsseln, um sicherzustellen, dass die Daten während der Übertragung nicht gestohlen oder manipuliert werden. Überprüfen Sie das Serverzertifikat: Überprüfen Sie das Serverzertifikat im Client manuell, um sicherzustellen, dass es vertrauenswürdig ist. Der Server kann manuell durch die Delegate -Methode der URLSession überprüft werden
 Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Das Konfigurieren der Firewall eines Debian -Mailservers ist ein wichtiger Schritt zur Gewährleistung der Serversicherheit. Im Folgenden sind mehrere häufig verwendete Firewall -Konfigurationsmethoden, einschließlich der Verwendung von Iptables und Firewalld. Verwenden Sie Iptables, um Firewall so zu konfigurieren, dass Iptables (falls bereits installiert) installiert werden:
 Wie man Debian Syslog lernt
Apr 13, 2025 am 11:51 AM
Wie man Debian Syslog lernt
Apr 13, 2025 am 11:51 AM
In diesem Leitfaden werden Sie erfahren, wie Sie Syslog in Debian -Systemen verwenden. Syslog ist ein Schlüsseldienst in Linux -Systemen für Protokollierungssysteme und Anwendungsprotokollnachrichten. Es hilft den Administratoren, die Systemaktivitäten zu überwachen und zu analysieren, um Probleme schnell zu identifizieren und zu lösen. 1. Grundkenntnisse über syslog Die Kernfunktionen von Syslog umfassen: zentrales Sammeln und Verwalten von Protokollnachrichten; Unterstützung mehrerer Protokoll -Ausgabesformate und Zielorte (z. B. Dateien oder Netzwerke); Bereitstellung von Echtzeit-Protokoll- und Filterfunktionen. 2. Installieren und Konfigurieren von Syslog (mit Rsyslog) Das Debian -System verwendet standardmäßig Rsyslog. Sie können es mit dem folgenden Befehl installieren: sudoaptupdatesud
 So konfigurieren Sie Firewall -Regeln für Debian Syslog
Apr 13, 2025 am 06:51 AM
So konfigurieren Sie Firewall -Regeln für Debian Syslog
Apr 13, 2025 am 06:51 AM
In diesem Artikel wird beschrieben, wie Sie Firewall -Regeln mit Iptables oder UFW in Debian -Systemen konfigurieren und Syslog verwenden, um Firewall -Aktivitäten aufzuzeichnen. Methode 1: Verwenden Sie IptableSiptables ist ein leistungsstarkes Befehlszeilen -Firewall -Tool im Debian -System. Vorhandene Regeln anzeigen: Verwenden Sie den folgenden Befehl, um die aktuellen IPTables-Regeln anzuzeigen: Sudoiptables-L-N-V Ermöglicht spezifische IP-Zugriff: ZBELTE IP-Adresse 192.168.1.100 Zugriff auf Port 80: sudoiptables-ainput-ptcp--dort80-s192.16
 So setzen Sie die Debian Apache -Protokollebene fest
Apr 13, 2025 am 08:33 AM
So setzen Sie die Debian Apache -Protokollebene fest
Apr 13, 2025 am 08:33 AM
In diesem Artikel wird beschrieben, wie Sie die Protokollierungsstufe des Apacheweb -Servers im Debian -System anpassen. Durch Ändern der Konfigurationsdatei können Sie die ausführliche Ebene der von Apache aufgezeichneten Protokollinformationen steuern. Methode 1: Ändern Sie die Hauptkonfigurationsdatei, um die Konfigurationsdatei zu finden: Die Konfigurationsdatei von Apache2.x befindet sich normalerweise im Verzeichnis/etc/apache2/. Der Dateiname kann je nach Installationsmethode Apache2.conf oder httpd.conf sein. Konfigurationsdatei bearbeiten: Öffnen Sie die Konfigurationsdatei mit Stammberechtigungen mit einem Texteditor (z. B. Nano): Sudonano/etc/apache2/apache2.conf
