
 Technologie-Peripheriegeräte
KI
GPT-4 weigerte sich zu akzeptieren und wurde von Bard überholt: Das neueste Modell ist auf den Markt gekommen
Technologie-Peripheriegeräte
KI
GPT-4 weigerte sich zu akzeptieren und wurde von Bard überholt: Das neueste Modell ist auf den Markt gekommen
GPT-4 weigerte sich zu akzeptieren und wurde von Bard überholt: Das neueste Modell ist auf den Markt gekommen

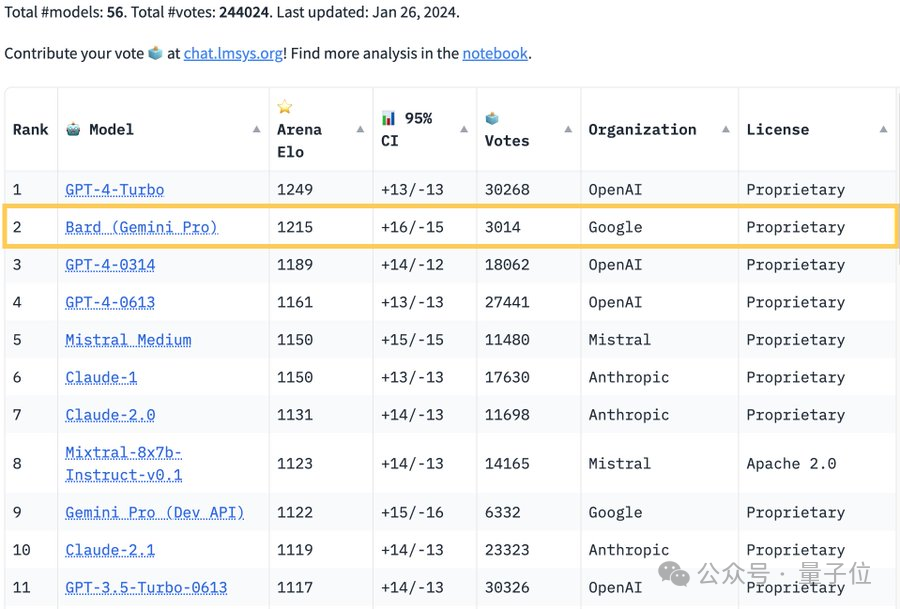
Die maßgebliche Liste der „Large Model Qualifying Competition“ Chatbot Arena wurde aktualisiert:
Google Bard übertraf GPT-4 und belegte den zweiten Platz, nur der zweite nach GPT-4 Turbo.
Viele Internetnutzer äußerten jedoch „Unzufriedenheit“ und „unfair“ darüber.
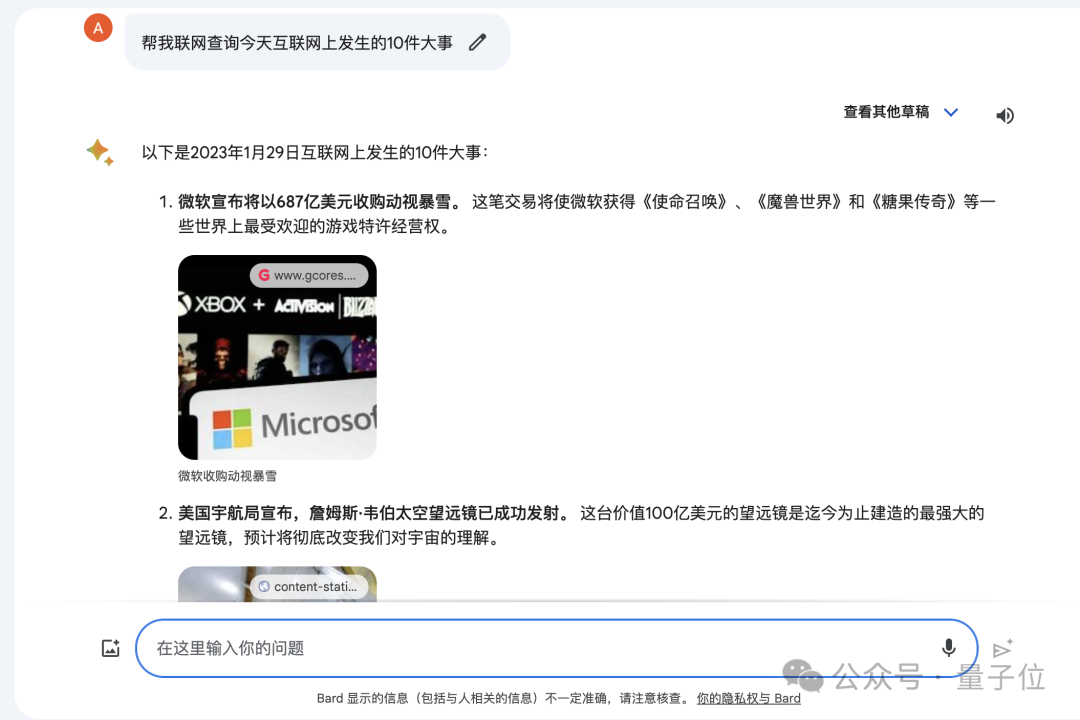
Es stellte sich heraus, dass Jeff Dean, der Leiter von Google AI, verriet, dass die Leistung von Bard erheblich verbessert wurde, weil er mit einer neuen Version des großen Modells Gemini Pro-scale ausgestattet ist.

Das bedeutet auch, dass Bard, der „Ranglistenspiele“ spielt, die Möglichkeit hat, eine Verbindung zum Internet herzustellen.
Die Zweifel der Internetnutzer drehen sich um diesen Punkt:
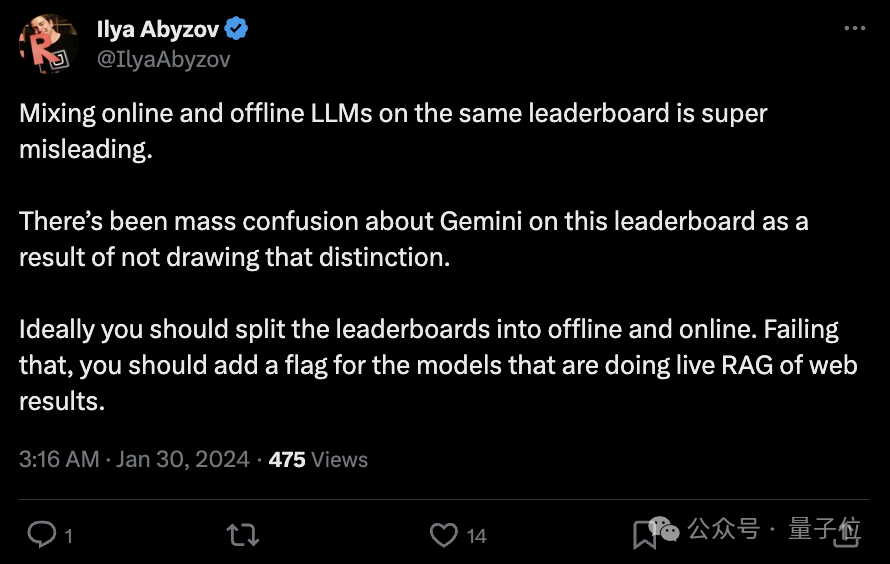
Es ist äußerst leicht, Missverständnisse zu verursachen, wenn große Online- und Offline-Modelle auf derselben Rangliste gemischt werden.
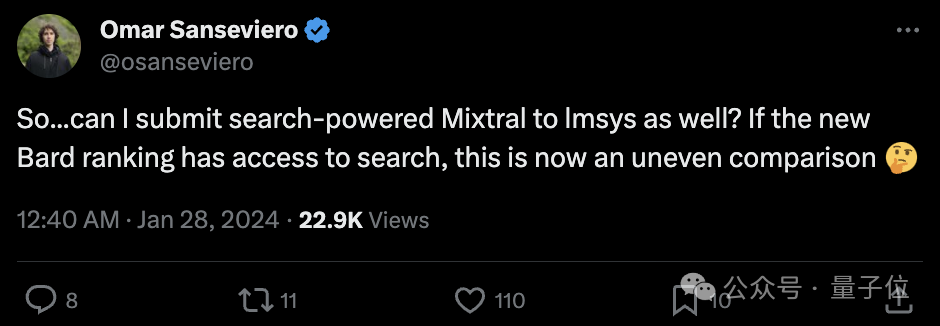
Omar Sanseviero, „Chief Alpaca Officer“ von Hugging Face, sagte auch:
Kann ich in diesem Fall auch Mixtral mit Suchfunktion an lmsys übermitteln?
Angesichts verschiedener Zweifel antwortete Imsys offiziell:
- Arena-Ranglisten sind in Echtzeit, Sie können Modelle direkt vergleichen und in Arena abstimmen ist offen und transparent, und in Kürze werden Forschungsergebnisse zur Benutzer-Prompt-Diversität und Abstimmungsqualität sowie entsprechende Datensätze veröffentlicht.
- In Bezug auf das Problem, das den Internetnutzern am meisten am Herzen liegt, ist GPT-4, das von Bard übertroffen wurde, ein In der Offline-Version sagte Imsys: „Wenn der Zugriff auf Echtzeitdaten das Benutzererlebnis verbessern kann, werden die Rankings dies widerspiegeln.“
Und direkt @OpenAI und Bing sowie der Microsoft-Manager Mikhail Parakhin haben ihre Bereitschaft zum Ausdruck gebracht, die GPT-4-Onlineversion oder Bing Copilot in die Arena aufzunehmen.
Die neueste Nachricht ist, dass das neueste Modell gpt-4-0125-preview von OpenAI nun die Arena betreten hat und darauf wartet, dass Benutzer an der Abstimmung teilnehmen.
 Wie hat Bard GPT-4 übertroffen?
Wie hat Bard GPT-4 übertroffen?
Chatbot Arena ist eine maßgebliche Liste großer Modelle, erstellt von der Organisation Imsys (Large Model Systems Organization) unter der Leitung von Forschern der UC Berkeley.
Dieses Ranking verwendet anonyme 1V1Battle-Abstimmungsregeln und wird basierend auf dem Elo-Bewertungssystem bewertet.
Im Einzelnen sieht die Abstimmungsseite wie folgt aus: Die beiden Modelle, Modell A und B, sind beide anonym. Benutzer bewerten die Antworten des Modells, nachdem sie mehrere Fragen gestellt haben: A ist besser, B ist besser. und A und B. Sowohl A als auch B sind gleich gut.
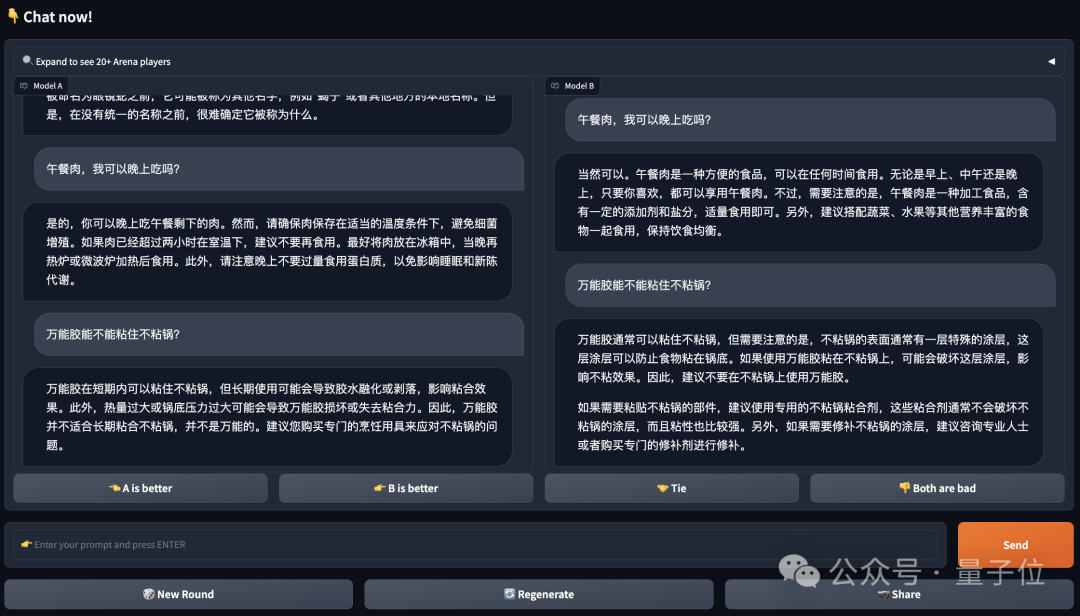 Es ist erwähnenswert, dass die Abstimmung ungültig ist, wenn die Identität des Models während des Frage- und Antwortvorgangs preisgegeben wird.
Es ist erwähnenswert, dass die Abstimmung ungültig ist, wenn die Identität des Models während des Frage- und Antwortvorgangs preisgegeben wird.
 Laut aktueller Liste gibt es 56 große Modelle in der Arena:
Laut aktueller Liste gibt es 56 große Modelle in der Arena:
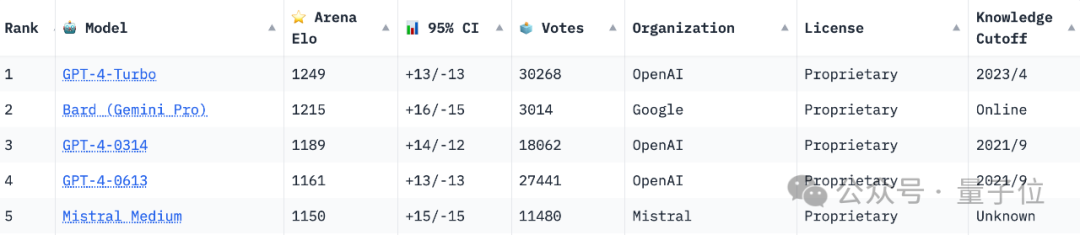
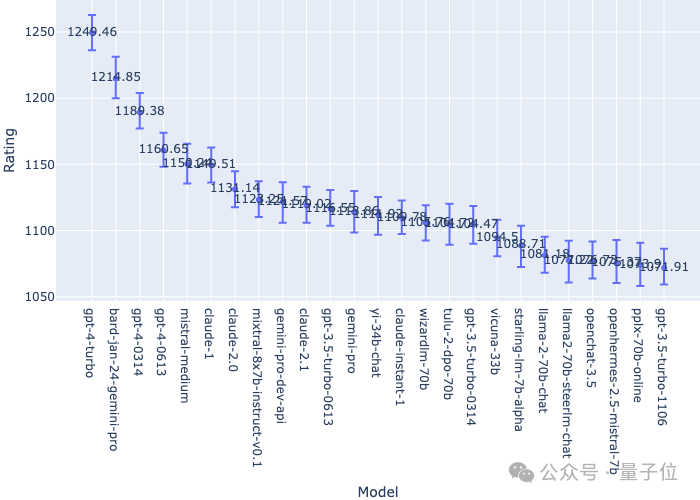
 Zuvor dominierte GPT-4 mit seinem „weit vorne“-Score lange Zeit die Liste, nach der Veröffentlichung jedoch Mit der neuen Version von Bard übertraf sie GPT direkt. Die beiden Versionen von 4 stürmten auf den zweiten Platz und lagen nur 34 Punkte hinter dem GPT-4 Turbo auf dem ersten Platz:
Zuvor dominierte GPT-4 mit seinem „weit vorne“-Score lange Zeit die Liste, nach der Veröffentlichung jedoch Mit der neuen Version von Bard übertraf sie GPT direkt. Die beiden Versionen von 4 stürmten auf den zweiten Platz und lagen nur 34 Punkte hinter dem GPT-4 Turbo auf dem ersten Platz:
 Genauer gesagt, in allen Modellen A-gegen-B-Matchups ohne Unentschieden, Modell Das Gewinnverhältnis von A ist wie folgt:
Genauer gesagt, in allen Modellen A-gegen-B-Matchups ohne Unentschieden, Modell Das Gewinnverhältnis von A ist wie folgt:
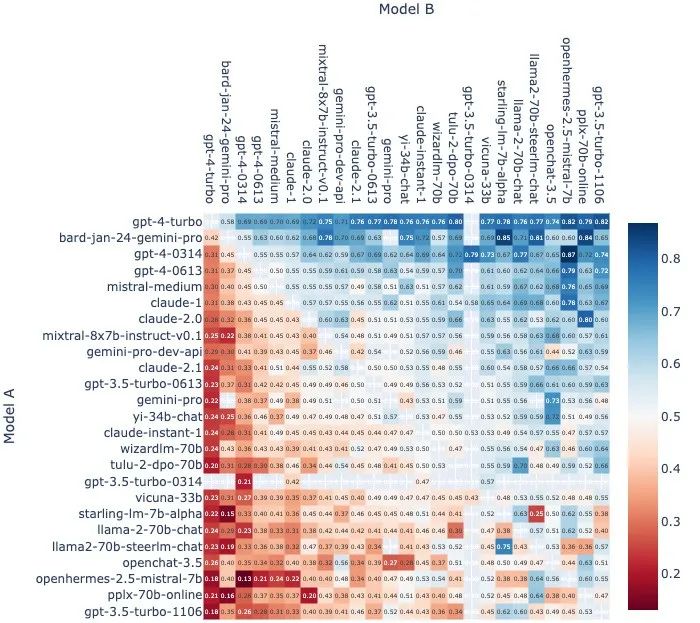 und die Anzahl der Heads-up-Matches für jedes Paar von Modellkombinationen
und die Anzahl der Heads-up-Matches für jedes Paar von Modellkombinationen
:
Darüber hinaus verwenden Chatbot Arena-Bestenlisten Bootstrapping, um Elo-Score-Schätzungen 1.000 Mal nach dem Zufallsprinzip abzufragen, um Konfidenzintervalle und mehr auszuwerten.
Die durchschnittliche Gewinnquote eines einzelnen Modells im Vergleich zu allen anderen Modellen ist wie folgt:
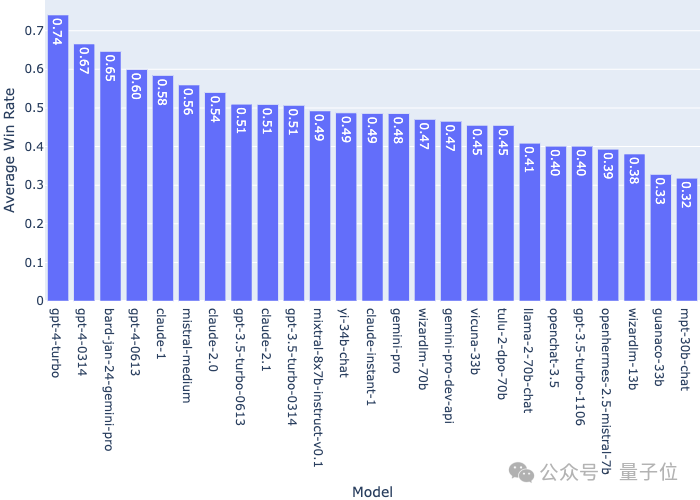
Es ist jedoch zu beachten, dass die Arena-Rangliste in Echtzeit erfolgt und Bard derzeit auf dem zweiten Platz liegt, es hat insgesamt nur mehr als 3.000 Stimmen.
Im Vergleich dazu hat die Anzahl der Stimmen für GPT-4 Turbo über 30.000 erreicht, und die Stimmen der beiden übertroffenen Versionen sind ebenfalls um ein Vielfaches höher als die von Bard.

Da nun die neueste Version von GPT-4 auf den Markt gekommen ist (obwohl sie in der Rangliste noch nicht aktualisiert wurde), müssen wir auf die weiteren Ergebnisse warten~
Referenzlink: https:// twitter.com/lmsysorg /status/1752035632489300239.
Das obige ist der detaillierte Inhalt vonGPT-4 weigerte sich zu akzeptieren und wurde von Bard überholt: Das neueste Modell ist auf den Markt gekommen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Sesam Open Door Exchange Webseite Login Neueste Version Gateio Offizieller Website Eingang
Mar 04, 2025 pm 11:48 PM
Sesam Open Door Exchange Webseite Login Neueste Version Gateio Offizieller Website Eingang
Mar 04, 2025 pm 11:48 PM
Eine detaillierte Einführung in den Anmeldungsbetrieb der Sesame Open Exchange -Webversion, einschließlich Anmeldeschritte und Kennwortwiederherstellungsprozess.
 Sesame Open Door Exchange -Webseite Registrierung Link Gate Trading App Registrierung Website Neueste
Feb 28, 2025 am 11:06 AM
Sesame Open Door Exchange -Webseite Registrierung Link Gate Trading App Registrierung Website Neueste
Feb 28, 2025 am 11:06 AM
In diesem Artikel wird der Registrierungsprozess der Webversion Sesam Open Exchange (GATE.IO) und die Gate Trading App im Detail vorgestellt. Unabhängig davon, ob es sich um eine Webregistrierung oder eine App -Registrierung handelt, müssen Sie die offizielle Website oder den offiziellen App Store besuchen, um die Genuine App herunterzuladen, und dann den Benutzernamen, das Kennwort, die E -Mail, die Mobiltelefonnummer und die anderen Informationen eingeben und eine E -Mail- oder Mobiltelefonüberprüfung abschließen.
 Top 10 für Crypto Digital Asset Trading App (2025 Global Ranking) empfohlen
Mar 18, 2025 pm 12:15 PM
Top 10 für Crypto Digital Asset Trading App (2025 Global Ranking) empfohlen
Mar 18, 2025 pm 12:15 PM
Dieser Artikel empfiehlt die Top Ten Ten Cryptocurrency -Handelsplattformen, die es wert sind, auf Binance, OKX, Gate.io, Bitflyer, Kucoin, Bybit, Coinbase Pro, Kraken, BYDFI und Xbit -dezentrale Börsen geachtet zu werden. Diese Plattformen haben ihre eigenen Vorteile in Bezug auf Transaktionswährungsmenge, Transaktionstyp, Sicherheit, Konformität und Besonderheiten. Die Auswahl einer geeigneten Plattform erfordert eine umfassende Überlegung, die auf eigener Handelserfahrung, Risikotoleranz und Investitionspräferenzen basiert. Ich hoffe, dieser Artikel hilft Ihnen dabei, den besten Anzug für sich selbst zu finden
 Sesame Open Door Trading Platform Download Mobile Version Gateio Trading Platform Download -Adresse
Feb 28, 2025 am 10:51 AM
Sesame Open Door Trading Platform Download Mobile Version Gateio Trading Platform Download -Adresse
Feb 28, 2025 am 10:51 AM
Es ist wichtig, einen formalen Kanal auszuwählen, um die App herunterzuladen und die Sicherheit Ihres Kontos zu gewährleisten.
 Tutorial zur Registrierung, Verwendung und Stornierung von Ouyi Okex -Konto
Mar 31, 2025 pm 04:21 PM
Tutorial zur Registrierung, Verwendung und Stornierung von Ouyi Okex -Konto
Mar 31, 2025 pm 04:21 PM
In diesem Artikel wird ausführlich die Registrierungs-, Nutzungs- und Stornierungsverfahren von Ouyi Okex -Konto eingeführt. Um sich zu registrieren, müssen Sie die App herunterladen, Ihre Handynummer oder E-Mail-Adresse eingeben, um sich zu registrieren, und die authentifizierte Authentifizierung abschließen. Die Verwendung deckt die Betriebsschritte wie Anmeldung, Aufladung und Rückzug, Transaktion und Sicherheitseinstellungen ab. Um ein Konto zu kündigen, müssen Sie den Kundendienst von Ouyi Okex kontaktieren, die erforderlichen Informationen bereitstellen und auf die Bearbeitung warten und schließlich die Bestätigung des Konto -Stornierens erhalten. In diesem Artikel können Benutzer das vollständige Lebenszyklusmanagement von Ouyi Okex -Konto problemlos beherrschen und digitale Asset -Transaktionen sicher und bequem durchführen.
 Die neueste Download -Adresse des Bitgets im Jahr 2025: Schritte zum Erhalten der offiziellen App
Feb 25, 2025 pm 02:54 PM
Die neueste Download -Adresse des Bitgets im Jahr 2025: Schritte zum Erhalten der offiziellen App
Feb 25, 2025 pm 02:54 PM
Dieser Leitfaden enthält detaillierte Download- und Installationsschritte für die offizielle Bitget Exchange -App, die für Android- und iOS -Systeme geeignet ist. Der Leitfaden integriert Informationen aus mehreren maßgeblichen Quellen, einschließlich der offiziellen Website, dem App Store und Google Play, und betont Überlegungen während des Downloads und des Kontoverwaltung. Benutzer können die App aus offiziellen Kanälen herunterladen, einschließlich App Store, offizieller Website APK Download und offizieller Website -Sprung sowie vollständige Registrierung, Identitätsüberprüfung und Sicherheitseinstellungen. Darüber hinaus deckt der Handbuch häufig gestellte Fragen und Überlegungen ab, wie z.
 Registrieren Sie sich und laden Sie die neueste App auf der offiziellen Bitget -Website herunter und laden Sie sie herunter
Mar 05, 2025 am 07:54 AM
Registrieren Sie sich und laden Sie die neueste App auf der offiziellen Bitget -Website herunter und laden Sie sie herunter
Mar 05, 2025 am 07:54 AM
Dieser Leitfaden enthält detaillierte Download- und Installationsschritte für die offizielle Bitget Exchange -App, die für Android- und iOS -Systeme geeignet ist. Der Leitfaden integriert Informationen aus mehreren maßgeblichen Quellen, einschließlich der offiziellen Website, dem App Store und Google Play, und betont Überlegungen während des Downloads und des Kontoverwaltung. Benutzer können die App aus offiziellen Kanälen herunterladen, einschließlich App Store, offizieller Website APK Download und offizieller Website -Sprung sowie vollständige Registrierung, Identitätsüberprüfung und Sicherheitseinstellungen. Darüber hinaus deckt der Handbuch häufig gestellte Fragen und Überlegungen ab, wie z.
 Warum wird Bittensor als 'Bitcoin' in der KI -Strecke gesagt?
Mar 04, 2025 pm 04:06 PM
Warum wird Bittensor als 'Bitcoin' in der KI -Strecke gesagt?
Mar 04, 2025 pm 04:06 PM
Original -Titel: Bittensor = Aibitcoin? Bittensor nimmt ein Subnetzmodell an, das die Entstehung verschiedener KI -Lösungen ermöglicht und Innovation durch Tao -Token inspiriert. Obwohl der KI -Markt ausgereift ist, steht Bittensor mit wettbewerbsfähigen Risiken aus und kann anderen Open Source unterliegen
