
 Technologie-Peripheriegeräte
KI
Die Genauigkeitsrate beträgt weniger als 20 %, GPT-4V/Gemini kann keine Comics lesen! Erster Open-Source-Benchmark für Bildsequenzen
Technologie-Peripheriegeräte
KI
Die Genauigkeitsrate beträgt weniger als 20 %, GPT-4V/Gemini kann keine Comics lesen! Erster Open-Source-Benchmark für Bildsequenzen
Die Genauigkeitsrate beträgt weniger als 20 %, GPT-4V/Gemini kann keine Comics lesen! Erster Open-Source-Benchmark für Bildsequenzen

OpenAIs GPT-4V und das multimodale große Sprachmodell Gemini von Google haben in der Industrie und in der Wissenschaft große Aufmerksamkeit erregt. Diese Modelle demonstrieren ein tiefes Verständnis von Video in mehreren Bereichen und demonstrieren sein Potenzial aus verschiedenen Perspektiven. Diese Fortschritte werden allgemein als wichtiger Schritt in Richtung künstlicher allgemeiner Intelligenz (AGI) angesehen.
Aber wenn ich Ihnen sage, dass GPT-4V sogar das Verhalten von Charakteren in Comics falsch interpretieren kann, lassen Sie mich fragen: Yuanfang, was denken Sie?
Werfen wir einen Blick auf diese Mini-Comic-Serie:
 Bilder
Bilder
Wenn Sie die höchste Intelligenz in der biologischen Welt – Menschen, also Leserfreunde, es beschreiben lassen, werden Sie es am meisten tun Sagen Sie wahrscheinlich:
 Bilder
Bilder
Dann wollen wir mal sehen, was die höchste Intelligenz der Maschinenwelt – also GPT-4V – beschreiben wird, wenn es um diese Mini-Comic-Serie geht?
 Bilder
Bilder
GPT - 4V, als Maschinenintelligenz, von der man annahm, dass sie an der Spitze der Missachtungskette steht, hat tatsächlich unverhohlen gelogen.
Was noch empörender ist, ist, dass GPT-4V, selbst wenn ihm echte Bildausschnitte gegeben werden, das Verhalten einer Person, die mit einer anderen Person spricht, während sie die Treppe hinaufgeht, absurderweise als zwei Personen erkennt, die mit „Waffen“ gegeneinander kämpfen. Verspielt (Bild unten).
 Bilder
Bilder
Gemini ist nicht weit dahinter. Derselbe Bildclip zeigt den Prozess, wie ein Mann sich bemüht, nach oben zu gehen, mit seiner Frau streitet und im Haus eingesperrt wird.
 Bilder
Bilder
Diese Beispiele stammen aus den neuesten Ergebnissen des Forschungsteams der University of Maryland und North Carolina Chapel Hill, das Mementos ins Leben gerufen hat, einen Inferenz-Benchmark für Bildsequenzen, der speziell für MLLM entwickelt wurde.
So wie Nolans Memento das Geschichtenerzählen neu definiert hat, definiert Mementos die Grenzen des Testens künstlicher Intelligenz neu.
Als neuer Benchmark-Test stellt er das Verständnis künstlicher Intelligenz für Bildsequenzen wie Erinnerungsfragmente in Frage.
 Bilder
Bilder
Papierlink: https://arxiv.org/abs/2401.10529
Projekthomepage: https://mementos-bench.github.io
Mementos ist der erste speziell für MLLM entwickelte Benchmark für Bildsequenz-Schlussfolgerungen, die sich auf Objekthalluzinationen und Verhaltenshalluzinationen großer Modelle auf aufeinanderfolgenden Bildern konzentrieren.
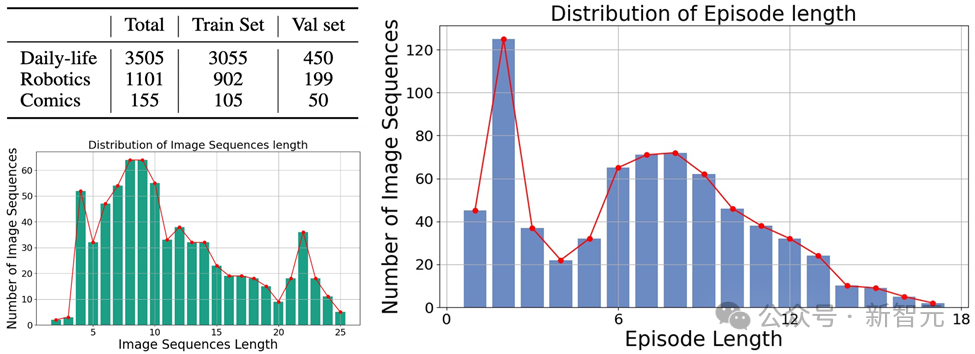
Es handelt sich um verschiedene Arten von Bildern, die drei Hauptkategorien abdecken: Bilder aus der realen Welt, Roboterbilder und Animationsbilder.
Und enthält 4.761 verschiedene Bildsequenzen unterschiedlicher Länge, jede mit menschlichen Anmerkungen, die die Hauptobjekte und ihr Verhalten in der Sequenz beschreiben.
 Bilder
Bilder
Die Daten sind derzeit Open Source und werden noch aktualisiert.
Arten von Halluzinationen
In dem Artikel erklärt der Autor zwei Arten von Halluzinationen, die MLLM in Erinnerungsstücken hervorrufen wird: Objekthalluzinationen und Verhaltenshalluzinationen.
Wie der Name schon sagt, handelt es sich bei der Objekthalluzination um die Vorstellung eines nicht existierenden Objekts (Objekts), während es sich bei der Verhaltenshalluzination um die Vorstellung von Handlungen und Verhaltensweisen handelt, die das Objekt nicht ausgeführt hat.
Bewertungsmethode
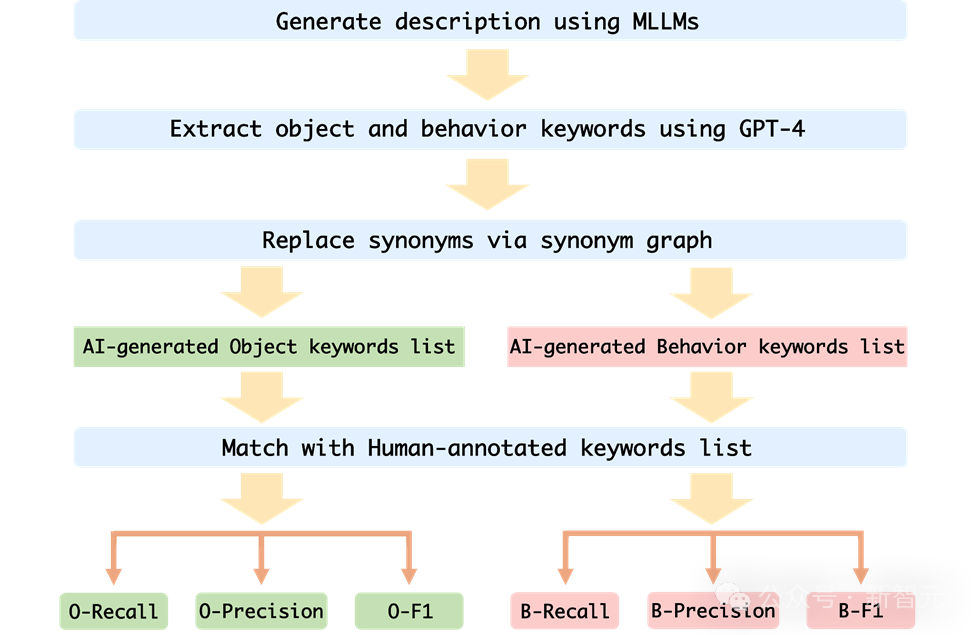
Um die Verhaltenshalluzination und Objekthalluzination von MLLM auf Erinnerungsstücken genau zu bewerten, entschied sich das Forschungsteam für einen Stichwortabgleich der von MLLM generierten Bildbeschreibung und der Beschreibung der menschlichen Anmerkung.
Um die Leistung jedes MLLM automatisch zu bewerten, verwendet der Autor die GPT-4-Hilfstestmethode zur Bewertung:
 Bilder
Bilder
1 Der Autor verwendet die Bildsequenz und die Eingabeaufforderungswörter als Eingabe für MLLM generiert die entsprechende Beschreibung, die der Bildsequenz entspricht.
2. Fordern Sie GPT-4 auf, die Objekt- und Verhaltensschlüsselwörter in der von der KI generierten Beschreibung zu extrahieren Von der KI generierte Verhaltensschlüsselwortliste;
4. Berechnen Sie die Rückrufrate, die Genauigkeitsrate und den F1-Index der von der KI generierten Objektschlüsselwortliste und der vom Menschen kommentierten Schlüsselwortliste.
Bewertungsergebnisse
Der Autor bewertete die Leistung von MLLMs beim Sequence Image Reasoning auf Mementos und führte eine detaillierte Bewertung von neun neuesten MLLMs durch, darunter GPT4V und Gemini.
MLLM wird gebeten, die in der Bildsequenz auftretenden Ereignisse zu beschreiben, um die Argumentationsfähigkeit von MLLM für kontinuierliche Bilder zu bewerten.
Die Ergebnisse zeigen, wie in der folgenden Abbildung dargestellt, dass die Genauigkeit von GPT-4V und Gemini für das Charakterverhalten im Comic-Datensatz weniger als 20 % beträgt.
Bilder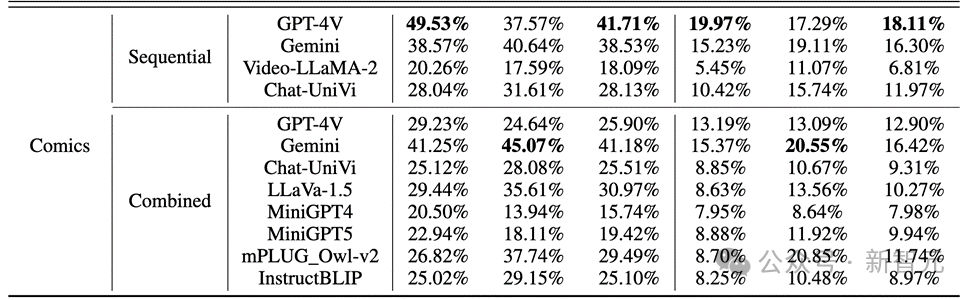 Bei realen Bildern und Roboterbildern ist die Leistung von GPT-4V und Gemini nicht zufriedenstellend:
Bei realen Bildern und Roboterbildern ist die Leistung von GPT-4V und Gemini nicht zufriedenstellend:
Bilder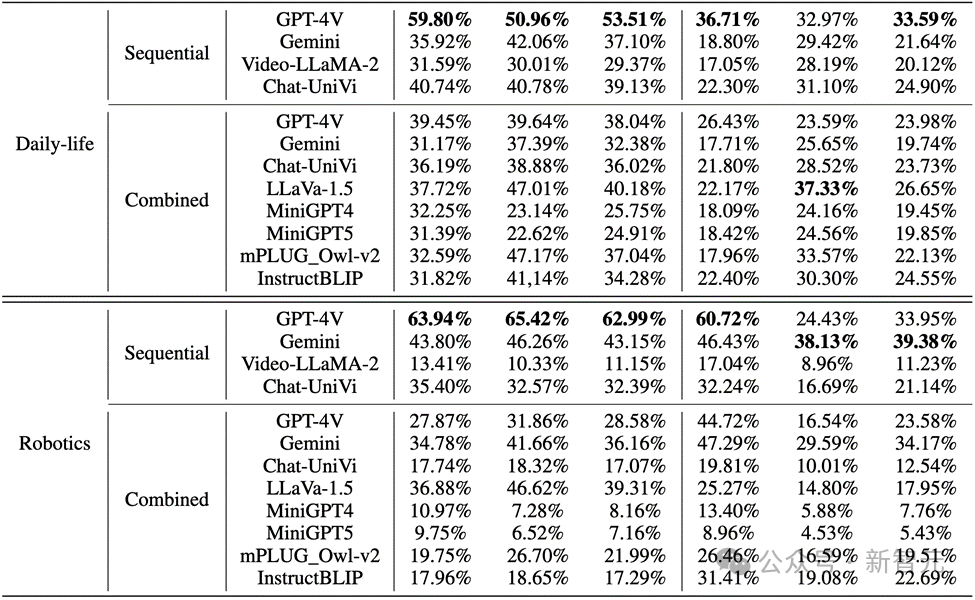 Wichtige Punkte
Wichtige Punkte
1. Bei der Bewertung mehrerer Wenn es Wenn es um modale groß angelegte Sprachmodelle geht, sind GPT-4V und LLaVA-1.5 die leistungsstärksten Modelle in Black-Box- bzw. Open-Source-MLLMs. GPT-4V übertrifft alle anderen MLLMs hinsichtlich der Denkfähigkeit zum Verständnis von Bildsequenzen, während LLaVA-1.5 beim Objektverständnis fast mit dem Black-Box-Modell Gemini mithalten oder es sogar übertrifft.
2. Obwohl Video-LLaMA-2 und Chat-UniVi für das Videoverständnis konzipiert sind, zeigen sie keine besseren Vorteile als LLaVA-1.5.
3. Alle MLLMs schneiden bei den drei Indikatoren des Objektdenkens in Bildsequenzen deutlich besser ab als das Verhaltensdenken, was darauf hindeutet, dass aktuelle MLLMs nicht gut darin sind, Verhaltensweisen aus aufeinanderfolgenden Bildern autonom abzuleiten.
4. Das Black-Box-Modell schneidet im Bereich Robotik am besten ab, während das Open-Source-Modell im Bereich des täglichen Lebens relativ gut abschneidet. Dies kann mit der Verteilungsverschiebung der Trainingsdaten zusammenhängen.
5. Die Einschränkungen der Trainingsdaten führen zu schwachen Inferenzfähigkeiten von Open-Source-MLLMs. Dies zeigt die Bedeutung von Trainingsdaten und ihren direkten Einfluss auf die Modellleistung.
Fehlergründe
Die Analyse des Autors der Gründe, warum aktuelle multimodale groß angelegte Sprachmodelle bei der Verarbeitung von Bildsequenzbegründungen versagen, identifiziert hauptsächlich drei Fehlergründe:
1. Die Beziehung zwischen Objekten und Verhaltensillusionen
Die Studie geht davon aus, dass eine falsche Objekterkennung zu einer ungenauen nachfolgenden Handlungserkennung führt. Quantitative Analysen und Fallstudien zeigen, dass Objekthalluzinationen bis zu einem gewissen Grad zu Verhaltenshalluzinationen führen können. Wenn MLLM beispielsweise eine Szene fälschlicherweise als Tennisplatz identifiziert, beschreibt sie möglicherweise eine Tennis spielende Figur, obwohl dieses Verhalten in der Bildsequenz nicht vorhanden ist.
2. Der Einfluss des gleichzeitigen Auftretens auf Verhaltenshalluzinationen
MLLM neigt dazu, Verhaltenskombinationen zu erzeugen, die beim Denken in Bildsequenzen häufig vorkommen, was das Problem von Verhaltenshalluzinationen verschärft. Beispielsweise beschreibt MLLM bei der Verarbeitung von Bildern aus dem Robotikbereich möglicherweise fälschlicherweise einen Roboterarm, der eine Schublade öffnet, nachdem er „den Griff gegriffen“ hat, obwohl die eigentliche Aktion darin bestand, „die Seite der Schublade zu greifen“.
3. Schneeballeffekt der Verhaltensillusion
Mit fortschreitender Bildsequenz können sich Fehler allmählich anhäufen oder verstärken, was als Schneeballeffekt bezeichnet wird. Wenn bei der Bildsequenzbetrachtung Fehler frühzeitig auftreten, können sich diese Fehler in der Sequenz anhäufen und verstärken, was zu einer verringerten Genauigkeit bei der Objekt- und Aktionserkennung führt.
Zum Beispiel
Bild
Wie aus der obigen Abbildung ersichtlich ist, gehören Objekthalluzination und die Korrelation zwischen Objekthalluzination und Verhaltenshalluzination zu den Gründen für das Scheitern von MLLM gleichzeitig auftretende Verhaltensweisen.
Nachdem MLLM beispielsweise die Objekthalluzination „Tennisplatz“ erlebt hatte, zeigte es dann die Verhaltenshalluzination „einen Tennisschläger halten“ (Korrelation zwischen Objekthalluzination und Verhaltenshalluzination) und das gleichzeitig auftretende Verhalten „den Anschein zu erwecken, Tennis zu spielen“. " .
 Bilder
Bilder
Wenn Sie sich das Beispiel im Bild oben ansehen, können Sie sehen, dass MLLM fälschlicherweise glaubte, der Stuhl sei weiter nach hinten geneigt und glaubte, der Stuhl sei kaputt.
Dieses Phänomen zeigt, dass MLLM auch bei statischen Objekten in der Bildsequenz die Illusion erzeugen kann, dass eine Aktion am Objekt stattgefunden hat.
 Bilder
Bilder
In der obigen Bildsequenzanzeige des Roboterarms greift der Roboterarm neben den Griff, und MLLM geht fälschlicherweise davon aus, dass der Roboterarm den Griff ergriffen hat, was beweist, dass MLLM generiert wird Das Bild sind Kombinationen von Verhaltensweisen, die in der Reihenfolge des Denkens häufig auftreten und dadurch Halluzinationen hervorrufen.
 Bild
Bild
Im obigen Fall glaubte der alte Meister nicht, dass das Führen des Hundes erforderlich sei, und „Hundestabhochsprung“ wurde als „Der Brunnen“ erkannt entstand.“
Die große Anzahl von Fehlern spiegelt die Unkenntnis von MLLM im Bereich der zweidimensionalen Animation wider.
Im Anhang zeigt der Autor jede Hauptkategorie detaillierte Fehlerfälle und führte eine tiefgreifende Analyse durch.
Zusammenfassung
In den letzten Jahren haben multimodale groß angelegte Sprachmodelle hervorragende Fähigkeiten bei der Bewältigung verschiedener visuell-linguistischer Aufgaben bewiesen.
Diese Modelle wie GPT-4V und Gemini sind in der Lage, Text in Bezug auf Bilder zu verstehen und zu generieren, was die Entwicklung der Technologie der künstlichen Intelligenz erheblich vorantreibt.
Bestehende MLLM-Benchmarks konzentrieren sich jedoch hauptsächlich auf Rückschlüsse auf der Grundlage eines einzelnen statischen Bildes, während die Fähigkeit, aus Bildsequenzen Rückschlüsse zu ziehen, die für das Verständnis unserer sich verändernden Welt von entscheidender Bedeutung ist, relativ wenig untersucht wurde.
Um dieser Herausforderung zu begegnen, schlagen Forscher einen neuen Benchmark „Mementos“ vor, der darauf abzielt, die Fähigkeiten von MLLMs beim Sequence Image Reasoning zu bewerten.
Mementos enthält 4761 verschiedene Bildsequenzen unterschiedlicher Länge. Darüber hinaus hat das Forschungsteam auch die GPT-4-Hilfsmethode übernommen, um die Inferenzleistung von MLLM zu bewerten.
Durch sorgfältige Auswertung von neun neuesten MLLMs (einschließlich GPT-4V und Gemini) auf Mementos stellte die Studie fest, dass diese Modelle Schwierigkeiten bei der genauen Beschreibung der dynamischen Informationen einer bestimmten Bildsequenz haben, was häufig zu Halluzinationen von Objekten und deren Verhalten führt /falscher Ausdruck.
Quantitative Analyse und Fallstudien identifizieren drei Schlüsselfaktoren, die das Sequenzbilddenken in MLLMs beeinflussen:
1. Zusammenhang zwischen Objekt- und Verhaltensillusionen;
3. Kumulative Auswirkungen von Verhaltenshalluzinationen.
Diese Entdeckung ist von großer Bedeutung für das Verständnis und die Verbesserung der Fähigkeit von MLLMs, dynamische visuelle Informationen zu verarbeiten. Der Mementos-Benchmark zeigt nicht nur die Grenzen aktueller MLLMs auf, sondern bietet auch Hinweise für zukünftige Forschung und Verbesserungen.
Mit der rasanten Entwicklung der Technologie der künstlichen Intelligenz wird die Anwendung von MLLMs im Bereich des multimodalen Verständnisses umfassender und tiefgreifender. Die Einführung des Mementos-Benchmarks fördert nicht nur die Forschung in diesem Bereich, sondern bietet uns auch neue Perspektiven, um zu verstehen und zu verbessern, wie diese fortschrittlichen KI-Systeme unsere komplexe und sich ständig verändernde Welt verarbeiten und verstehen.
Referenzen:
https://github.com/umd-huanglab/Mementos
Das obige ist der detaillierte Inhalt vonDie Genauigkeitsrate beträgt weniger als 20 %, GPT-4V/Gemini kann keine Comics lesen! Erster Open-Source-Benchmark für Bildsequenzen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1369
1369
 52
52

 Tokenisierung in einem Artikel verstehen!
Apr 12, 2024 pm 02:31 PM
Tokenisierung in einem Artikel verstehen!
Apr 12, 2024 pm 02:31 PM
Sprachmodelle basieren auf Text, der normalerweise in Form von Zeichenfolgen vorliegt. Da die Eingabe in das Modell jedoch nur Zahlen sein kann, muss der Text in eine numerische Form umgewandelt werden. Die Tokenisierung ist eine grundlegende Aufgabe der Verarbeitung natürlicher Sprache. Sie kann eine fortlaufende Textsequenz (z. B. Sätze, Absätze usw.) entsprechend den spezifischen Anforderungen in eine Zeichenfolge (z. B. Wörter, Phrasen, Zeichen, Satzzeichen usw.) unterteilen. Die darin enthaltenen Einheiten werden als Token oder Wort bezeichnet. Gemäß dem in der Abbildung unten gezeigten spezifischen Prozess werden die Textsätze zunächst in Einheiten unterteilt, dann werden die einzelnen Elemente digitalisiert (in Vektoren abgebildet), dann werden diese Vektoren zur Codierung in das Modell eingegeben und schließlich an nachgelagerte Aufgaben ausgegeben erhalten Sie weiterhin das Endergebnis. Die Textsegmentierung kann entsprechend der Granularität der Textsegmentierung in Toke unterteilt werden.
 Der Ameca der zweiten Generation ist da! Er kann fließend mit dem Publikum kommunizieren, sein Gesichtsausdruck ist realistischer und er kann Dutzende Sprachen sprechen.
Mar 04, 2024 am 09:10 AM
Der Ameca der zweiten Generation ist da! Er kann fließend mit dem Publikum kommunizieren, sein Gesichtsausdruck ist realistischer und er kann Dutzende Sprachen sprechen.
Mar 04, 2024 am 09:10 AM
Der humanoide Roboter Ameca wurde auf die zweite Generation aufgerüstet! Kürzlich erschien auf der World Mobile Communications Conference MWC2024 erneut der weltweit fortschrittlichste Roboter Ameca. Rund um den Veranstaltungsort lockte Ameca zahlreiche Zuschauer an. Mit dem Segen von GPT-4 kann Ameca in Echtzeit auf verschiedene Probleme reagieren. „Lass uns tanzen.“ Auf die Frage, ob sie Gefühle habe, antwortete Ameca mit einer Reihe von Gesichtsausdrücken, die sehr lebensecht aussahen. Erst vor wenigen Tagen stellte EngineeredArts, das britische Robotikunternehmen hinter Ameca, die neuesten Entwicklungsergebnisse des Teams vor. Im Video verfügt der Roboter Ameca über visuelle Fähigkeiten und kann den gesamten Raum und bestimmte Objekte sehen und beschreiben. Das Erstaunlichste ist, dass sie es auch kann
 Der erste Roboter erscheint, der menschliche Aufgaben autonom erledigt, mit fünf flexiblen Fingern und übermenschlicher Geschwindigkeit, und große Modelle unterstützen das Training im virtuellen Raum
Mar 11, 2024 pm 12:10 PM
Der erste Roboter erscheint, der menschliche Aufgaben autonom erledigt, mit fünf flexiblen Fingern und übermenschlicher Geschwindigkeit, und große Modelle unterstützen das Training im virtuellen Raum
Mar 11, 2024 pm 12:10 PM
Diese Woche gab FigureAI, ein Robotikunternehmen, an dem OpenAI, Microsoft, Bezos und Nvidia beteiligt sind, bekannt, dass es fast 700 Millionen US-Dollar an Finanzmitteln erhalten hat und plant, im nächsten Jahr einen humanoiden Roboter zu entwickeln, der selbstständig gehen kann. Und Teslas Optimus Prime hat immer wieder gute Nachrichten erhalten. Niemand zweifelt daran, dass dieses Jahr das Jahr sein wird, in dem humanoide Roboter explodieren. SanctuaryAI, ein in Kanada ansässiges Robotikunternehmen, hat kürzlich einen neuen humanoiden Roboter auf den Markt gebracht: Phoenix. Beamte behaupten, dass es viele Aufgaben autonom und mit der gleichen Geschwindigkeit wie Menschen erledigen kann. Pheonix, der weltweit erste Roboter, der Aufgaben autonom in menschlicher Geschwindigkeit erledigen kann, kann jedes Objekt sanft greifen, bewegen und elegant auf der linken und rechten Seite platzieren. Es kann Objekte autonom identifizieren
 Wie kann KI Roboter autonomer und anpassungsfähiger machen?
Jun 03, 2024 pm 07:18 PM
Wie kann KI Roboter autonomer und anpassungsfähiger machen?
Jun 03, 2024 pm 07:18 PM
Im Bereich der industriellen Automatisierungstechnik gibt es zwei aktuelle Hotspots, die kaum zu ignorieren sind: Künstliche Intelligenz (KI) und Nvidia. Ändern Sie nicht die Bedeutung des ursprünglichen Inhalts, optimieren Sie den Inhalt, schreiben Sie den Inhalt neu, fahren Sie nicht fort: „Darüber hinaus sind beide eng miteinander verbunden, da Nvidia nicht auf seine ursprüngliche Grafikverarbeitungseinheit (GPU) beschränkt ist ) erweitert es seine GPU. Die Technologie erstreckt sich auf den Bereich der digitalen Zwillinge und ist eng mit neuen KI-Technologien verbunden. „Vor kurzem hat NVIDIA eine Zusammenarbeit mit vielen Industrieunternehmen geschlossen, darunter führende Industrieautomatisierungsunternehmen wie Aveva, Rockwell Automation und Siemens und Schneider Electric sowie Teradyne Robotics und seine Unternehmen MiR und Universal Robots. Kürzlich hat Nvidia gesammelt
 Nach 2 Monaten kann der humanoide Roboter Walker S Kleidung falten
Apr 03, 2024 am 08:01 AM
Nach 2 Monaten kann der humanoide Roboter Walker S Kleidung falten
Apr 03, 2024 am 08:01 AM
Herausgeber des Machine Power Report: Wu Xin Die heimische Version des humanoiden Roboters + eines großen Modellteams hat zum ersten Mal die Betriebsaufgabe komplexer flexibler Materialien wie das Falten von Kleidung abgeschlossen. Mit der Enthüllung von Figure01, das das multimodale große Modell von OpenAI integriert, haben die damit verbundenen Fortschritte inländischer Kollegen Aufmerksamkeit erregt. Erst gestern veröffentlichte UBTECH, Chinas „größter Bestand an humanoiden Robotern“, die erste Demo des humanoiden Roboters WalkerS, der tief in das große Modell von Baidu Wenxin integriert ist und einige interessante neue Funktionen aufweist. Jetzt sieht WalkerS, gesegnet mit Baidu Wenxins großen Modellfähigkeiten, so aus. Wie Figure01 bewegt sich WalkerS nicht umher, sondern steht hinter einem Schreibtisch, um eine Reihe von Aufgaben zu erledigen. Es kann menschlichen Befehlen folgen und Kleidung falten
 Zehn humanoide Roboter gestalten die Zukunft
Mar 22, 2024 pm 08:51 PM
Zehn humanoide Roboter gestalten die Zukunft
Mar 22, 2024 pm 08:51 PM
Die folgenden 10 humanoiden Roboter prägen unsere Zukunft: 1. ASIMO: ASIMO wurde von Honda entwickelt und ist einer der bekanntesten humanoiden Roboter. Mit einer Höhe von 1,20 m und einem Gewicht von 50 kg ist ASIMO mit fortschrittlichen Sensoren und künstlichen Intelligenzfunktionen ausgestattet, die es ihm ermöglichen, sich in komplexen Umgebungen zurechtzufinden und mit Menschen zu interagieren. Aufgrund seiner Vielseitigkeit eignet sich ASIMO für eine Vielzahl von Aufgaben, von der Unterstützung von Menschen mit Behinderungen bis hin zur Durchführung von Präsentationen bei Veranstaltungen. 2. Pepper: Pepper wurde von Softbank Robotics entwickelt und möchte ein sozialer Begleiter für Menschen sein. Mit seinem ausdrucksstarken Gesicht und der Fähigkeit, Emotionen zu erkennen, kann Pepper an Gesprächen teilnehmen, im Einzelhandel helfen und sogar pädagogische Unterstützung leisten. Pfeffer
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 Drei Geheimnisse für die Bereitstellung großer Modelle in der Cloud
Apr 24, 2024 pm 03:00 PM
Drei Geheimnisse für die Bereitstellung großer Modelle in der Cloud
Apr 24, 2024 pm 03:00 PM
Zusammenstellung|Produziert von Ich fange an, serverloses Cloud Computing zu vermissen. Ihre Anwendungen reichen von der Verbesserung der Konversations-KI bis hin zur Bereitstellung komplexer Analyselösungen für verschiedene Branchen und vielen anderen Funktionen. Viele Unternehmen setzen diese Modelle auf Cloud-Plattformen ein, da öffentliche Cloud-Anbieter bereits ein fertiges Ökosystem bereitstellen und dies der Weg des geringsten Widerstands ist. Allerdings ist es nicht billig. Die Cloud bietet darüber hinaus weitere Vorteile wie Skalierbarkeit, Effizienz und erweiterte Rechenfunktionen (GPUs auf Anfrage verfügbar). Es gibt einige wenig bekannte Aspekte der Bereitstellung von LLM auf öffentlichen Cloud-Plattformen
