
 Technologie-Peripheriegeräte
KI
Daten sind König! Wie kann man anhand von Daten Schritt für Schritt einen effizienten autonomen Fahralgorithmus aufbauen?
Technologie-Peripheriegeräte
KI
Daten sind König! Wie kann man anhand von Daten Schritt für Schritt einen effizienten autonomen Fahralgorithmus aufbauen?
Daten sind König! Wie kann man anhand von Daten Schritt für Schritt einen effizienten autonomen Fahralgorithmus aufbauen?

Oben geschrieben und das persönliche Verständnis des Autors
Die nächste Generation der autonomen Fahrtechnologie wird voraussichtlich auf einer speziellen Integration und Interaktion zwischen intelligenter Wahrnehmung, Vorhersage, Planung und Steuerung auf niedriger Ebene basieren. Es gab schon immer einen großen Engpass bei der Leistungsobergrenze des autonomen Fahralgorithmus. Wissenschaftler und Industrie sind sich einig, dass der Schlüssel zur Überwindung des Engpasses in der datenzentrierten autonomen Fahrtechnologie liegt. AD-Simulation, Closed-Loop-Modelltraining und AD-Big-Data-Engine haben kürzlich einige wertvolle Erfahrungen gesammelt. Es mangelt jedoch an systematischem Wissen und tiefem Verständnis dafür, wie eine effiziente datenzentrierte AD-Technologie aufgebaut werden kann, um die Selbstentwicklung von AD-Algorithmen und eine bessere AD-Big-Data-Akkumulation zu realisieren. Um diese Forschungslücke zu schließen, werden wir hier ein besonderes Augenmerk auf die neueste datengesteuerte autonome Fahrtechnologie legen und uns auf eine umfassende Klassifizierung autonomer Fahrdatensätze konzentrieren, die hauptsächlich Meilensteine, Schlüsselmerkmale, Datenerfassungseinstellungen usw. umfassen. Darüber hinaus haben wir eine systematische Überprüfung der bestehenden Benchmark-Pipeline für AD-Big-Data mit geschlossenem Regelkreis von der Branchengrenze aus durchgeführt, einschließlich des Prozesses, der Schlüsseltechnologien und der empirischen Forschung des Closed-Loop-Frameworks. Abschließend werden zukünftige Entwicklungsrichtungen, mögliche Anwendungen, Einschränkungen und Bedenken diskutiert, um gemeinsame Anstrengungen von Wissenschaft und Industrie zur Förderung der Weiterentwicklung des autonomen Fahrens anzuregen.
Zusammenfassend sind die Hauptbeiträge wie folgt:
- Einführung der ersten umfassenden Taxonomie autonomer Fahrdatensätze, klassifiziert nach Meilensteingenerationen, modularen Aufgaben, Sensorsuiten und Schlüsselfunktionen;
- Basierend auf Deep Learning und generativem Modell der künstlichen Intelligenz, eine systematische Übersicht über die fortschrittlichsten datengesteuerten Pipelines für autonomes Fahren und die damit verbundenen Schlüsseltechnologien; aktuell Die Vor- und Nachteile von Pipeline
- und Lösungen, sowie die zukünftigen Forschungsrichtungen des datenzentrierten autonomen Fahrens.
- SOTA-Datensatz zum autonomen Fahren: Klassifizierung und Entwicklung
 Die Entwicklung des Datensatzes zum autonomen Fahren spiegelt technologische Fortschritte und wachsende Ambitionen auf diesem Gebiet wider. Die frühe AVT-Forschung am Institute of Advancement und das PATH-Programm an der University of California, Berkeley, am Ende des 20. Jahrhunderts legten den Grundstein für grundlegende Sensordaten, waren jedoch durch den technologischen Stand der Zeit begrenzt. In den letzten zwei Jahrzehnten gab es bedeutende Fortschritte, angetrieben durch Fortschritte in der Sensortechnologie, der Rechenleistung und ausgefeilten Algorithmen für maschinelles Lernen. Im Jahr 2014 kündigte die Society of Automotive Engineers (SAE) der Öffentlichkeit ein systematisches sechsstufiges (L0-L5) autonomes Fahrsystem an, das durch den Fortschritt der Forschung und Entwicklung zum autonomen Fahren weithin anerkannt wurde. Angetrieben durch Deep Learning haben auf Computer Vision basierende Methoden die intelligente Wahrnehmung dominiert. Deep Reinforcement Learning und seine Varianten sorgen für entscheidende Verbesserungen bei der intelligenten Planung und Entscheidungsfindung. In jüngster Zeit haben große Sprachmodelle (LLM) und visuelle Sprachmodelle (VLM) ihr leistungsstarkes Szenenverständnis, ihre Argumentation und Vorhersage des Fahrverhaltens sowie ihre intelligenten Entscheidungsfähigkeiten unter Beweis gestellt und damit neue Möglichkeiten für die zukünftige Entwicklung des autonomen Fahrens eröffnet.
Die Entwicklung des Datensatzes zum autonomen Fahren spiegelt technologische Fortschritte und wachsende Ambitionen auf diesem Gebiet wider. Die frühe AVT-Forschung am Institute of Advancement und das PATH-Programm an der University of California, Berkeley, am Ende des 20. Jahrhunderts legten den Grundstein für grundlegende Sensordaten, waren jedoch durch den technologischen Stand der Zeit begrenzt. In den letzten zwei Jahrzehnten gab es bedeutende Fortschritte, angetrieben durch Fortschritte in der Sensortechnologie, der Rechenleistung und ausgefeilten Algorithmen für maschinelles Lernen. Im Jahr 2014 kündigte die Society of Automotive Engineers (SAE) der Öffentlichkeit ein systematisches sechsstufiges (L0-L5) autonomes Fahrsystem an, das durch den Fortschritt der Forschung und Entwicklung zum autonomen Fahren weithin anerkannt wurde. Angetrieben durch Deep Learning haben auf Computer Vision basierende Methoden die intelligente Wahrnehmung dominiert. Deep Reinforcement Learning und seine Varianten sorgen für entscheidende Verbesserungen bei der intelligenten Planung und Entscheidungsfindung. In jüngster Zeit haben große Sprachmodelle (LLM) und visuelle Sprachmodelle (VLM) ihr leistungsstarkes Szenenverständnis, ihre Argumentation und Vorhersage des Fahrverhaltens sowie ihre intelligenten Entscheidungsfähigkeiten unter Beweis gestellt und damit neue Möglichkeiten für die zukünftige Entwicklung des autonomen Fahrens eröffnet.
Meilensteinentwicklung des Datensatzes zum autonomen Fahren
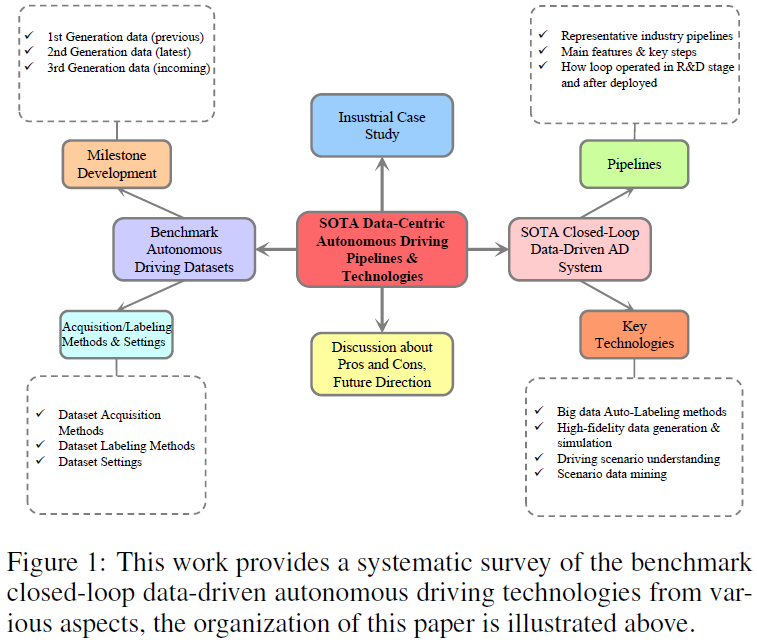
Abbildung 2 zeigt die Meilensteinentwicklung des Open-Source-Datensatzes zum autonomen Fahren in chronologischer Reihenfolge. Bedeutende Fortschritte haben zur Klassifizierung gängiger Datensätze in drei Generationen geführt, die durch erhebliche Sprünge in der Komplexität, dem Volumen, der Szenenvielfalt und der Annotationsgranularität der Datensätze gekennzeichnet sind und das Gebiet an eine neue Grenze der technologischen Reife gebracht haben. Insbesondere stellt die horizontale Achse die Entwicklungszeitleiste dar. Die Kopfzeile jeder Zeile enthält den Namen des Datensatzes, die Sensormodalität, die geeignete Aufgabe, den Ort der Datenerfassung und die damit verbundenen Herausforderungen. Um Datensätze über Generationen hinweg weiter zu vergleichen, verwenden wir verschiedenfarbige Balkendiagramme, um die wahrgenommenen und vorhergesagten/geplanten Datensatzgrößen zu visualisieren. Die frühen Stadien, die erste Generation ab 2012, angeführt von KITTI und Cityscapes, lieferten hochauflösende Bilder für Wahrnehmungsaufgaben und bildeten die Grundlage für Benchmark-Fortschritte bei Sehalgorithmen. Mit dem Übergang zur zweiten Generation haben Datensätze wie NuScenes, Waymo und Argoverse 1 eine Multisensormethode eingeführt, die Daten von Bordkameras, hochpräzisen Karten (HD Maps), Lidar, Radar, GPS, IMU kombiniert. Die Integration von Flugbahnen und umgebenden Objekten ist für eine umfassende Modellierung der Fahrumgebung und Entscheidungsprozesse von entscheidender Bedeutung. In jüngerer Zeit haben NuPlan, Argoverse 2 und Lyft L5 die Messlatte für die Wirkung deutlich höher gelegt, indem sie einen beispiellosen Datenumfang lieferten und ein Ökosystem förderten, das der Spitzenforschung förderlich ist. Diese Datensätze zeichnen sich durch ihre enorme Größe und die multimodale Sensorintegration aus und haben eine wichtige Rolle bei der Entwicklung von Algorithmen für Erfassungs-, Vorhersage- und Planungsaufgaben gespielt und den Weg für fortschrittliche End2End- oder hybride autonome Fahrmodelle geebnet. Im Jahr 2024 werden wir die dritte Generation autonomer Fahrdatensätze einläuten. Unterstützt durch VLM, LLM und andere künstliche Intelligenztechnologien der dritten Generation unterstreicht der Datensatz der dritten Generation das Engagement der Branche, die immer komplexeren Herausforderungen des autonomen Fahrens anzugehen, wie z. Eckfallanalyse usw. .
Datensatzerfassung, Einrichtung und Hauptfunktionen
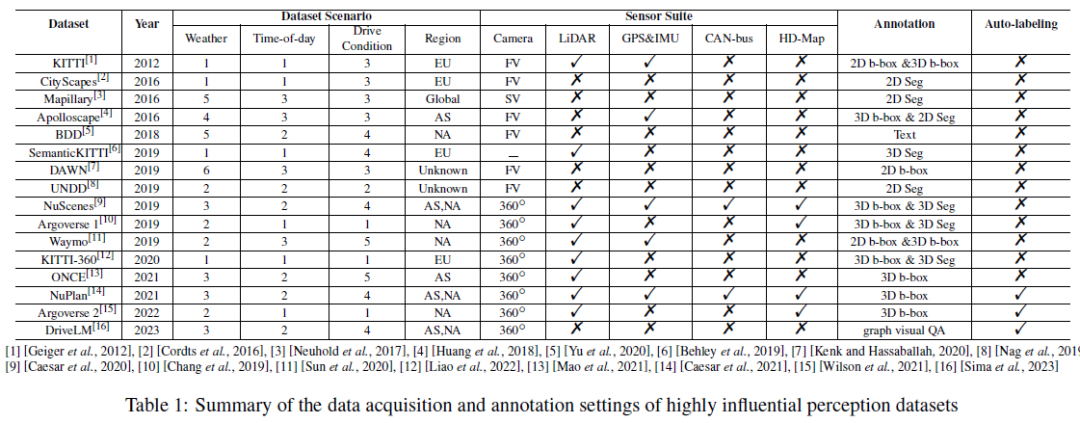
Tabelle 1 fasst den Datenerfassungs- und Anmerkungsaufbau des äußerst einflussreichen Wahrnehmungsdatensatzes zusammen, einschließlich Fahrszenarien, Sensorsuiten und Anmerkungen. Wir berichten über die Wetter-/Gesamtzahl der Zeit-/Fahrzustandskategorien , wobei das Wetter typischerweise sonnig/bewölkt/Nebel/Regen/Schnee/Sonstiges umfasst (extreme Tageszeiten umfassen typischerweise Morgen-, Nachmittags- und Abendstraßen); , Tunnel, Parkplätze usw. Je vielfältiger die Szenarien, desto aussagekräftiger ist der Datensatz. Wir berichten auch über die Region, in der der Datensatz erfasst wurde, bezeichnet als (Asien), EU (Europa), NA (Nordamerika), SA (Südamerika), AU (Australien), AF (Afrika). Es ist erwähnenswert, dass Mapillary über AS/EU/NA/SA/AF/AF erfasst wird und DAWN über die Bildsuchmaschinen Google und Bing erfasst wird. Für die Sensorsuite haben wir uns Kameras, Lidar, GPS und IMU usw. angesehen. FV und SV in Tabelle 1 sind die Abkürzungen für Frontkamera bzw. Straßenkamera. Ein 360°-Panoramakamera-Setup besteht normalerweise aus mehreren Frontkameras, seltenen Kameras und Seitenkameras. Wir können beobachten, dass mit der Entwicklung der AD-Technologie die Art und Anzahl der im Datensatz enthaltenen Sensoren zunimmt und die Datenmuster immer vielfältiger werden. Was die Annotation von Datensätzen betrifft, verwendeten frühe Datensätze normalerweise manuelle Annotationsmethoden, während die neueren Versionen NuPlan, Argoverse 2 und DriveLM die automatische Annotationstechnologie für AD-Big Data übernommen haben. Wir glauben, dass der Übergang von der traditionellen manuellen Annotation zur automatischen Annotation ein wichtiger Trend beim datenzentrierten autonomen Fahren der Zukunft ist.
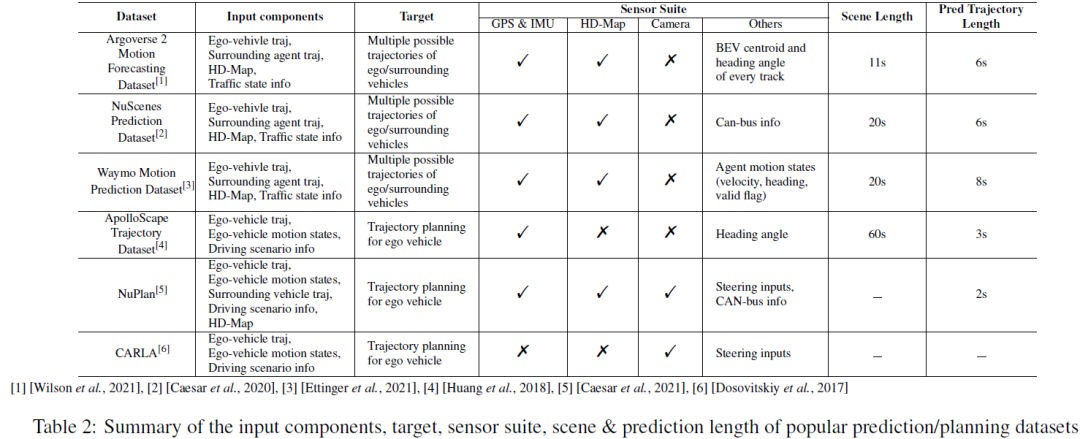
Für Vorhersage- und Planungsaufgaben fassen wir die Eingabe-/Ausgabekomponenten, Sensorsuiten, Szenenlängen und Vorhersagelängen der Mainstream-Datensätze in Tabelle 2 zusammen. Für Bewegungsvorhersage-/Vorhersageaufgaben umfassen die Eingabekomponenten normalerweise die historische Flugbahn des eigenen Fahrzeugs, die historische Flugbahn der umliegenden Agenten, hochpräzise Karten und Verkehrsstatusinformationen (d. h. Ampelstatus, Straßen-ID, Stoppschilder usw.). ). Bei der Zielausgabe handelt es sich um mehrere wahrscheinlichste Trajektorien (z. B. die Top-5- oder Top-10-Trajektorien) des eigenen Fahrzeugs und/oder umliegender Subjekte in einem kurzen Zeitraum. Bewegungsvorhersageaufgaben verwenden normalerweise eine gleitende Zeitfenstereinstellung, um die gesamte Szene in mehrere kürzere Zeitfenster zu unterteilen. NuScenes verwendet beispielsweise die letzten 2 Sekunden GT-Daten und hochpräzise Karten, um die Flugbahn der nächsten 6 Sekunden vorherzusagen, während Argoverse 2 historische 5 Sekunden Bodenwahrheit und hochpräzise Karten verwendet, um die Flugbahn der nächsten 6 Sekunden vorherzusagen Sekunden. NuPlan, CARLA und ApoloScape sind die beliebtesten Datensätze für Planungsaufgaben. Zu den Eingabekomponenten gehören historische Trajektorien des eigenen Fahrzeugs bzw. des umgebenden Fahrzeugs, Bewegungszustände des eigenen Fahrzeugs und Darstellungen von Fahrszenen. Während NuPlan und ApoloScape in der realen Welt erstellt wurden, handelt es sich bei CARLA um einen simulierten Datensatz. CARLA enthält Straßenbilder, die während einer simulierten Fahrt in verschiedenen Städten aufgenommen wurden. Jedem Straßenbild ist ein Lenkwinkel zugeordnet, der die erforderliche Einstellung darstellt, um das Fahrzeug ordnungsgemäß in Bewegung zu halten. Die Vorhersagelänge des Plans kann je nach den Anforderungen verschiedener Algorithmen variieren.
Datengesteuertes autonomes Fahrsystem mit geschlossenem Regelkreis
Wir bewegen uns jetzt von der vorherigen Ära des software- und algorithmusdefinierten autonomen Fahrens in die neue inspirierende Ära des Big-Data-gesteuerten und intelligenten modellkollaborativen autonomen Fahrens . Das datengesteuerte System mit geschlossenem Regelkreis zielt darauf ab, die Lücke zwischen dem Training des AD-Algorithmus und seiner realen Anwendung/Bereitstellung zu schließen. Im Gegensatz zu herkömmlichen Open-Loop-Ansätzen, bei denen Modelle passiv anhand von Datensätzen trainiert werden, die beim Fahren menschlicher Kunden oder bei Straßentests gesammelt werden, interagieren Closed-Loop-Systeme dynamisch mit der realen Umgebung. Dieser Ansatz befasst sich mit der Herausforderung der Verteilungsvariation – Verhaltensweisen, die aus statischen Datensätzen gelernt werden, lassen sich möglicherweise nicht auf die dynamische Natur realer Fahrszenarien übertragen. Systeme mit geschlossenem Regelkreis ermöglichen es AVs, aus Interaktionen zu lernen, sich an neue Situationen anzupassen und sich durch iterative Aktions- und Feedbackzyklen zu verbessern.
Der Aufbau eines realen, datenzentrierten AD-Systems mit geschlossenem Regelkreis ist jedoch aufgrund mehrerer wichtiger Probleme immer noch eine Herausforderung: Das erste Problem betrifft die AD-Datenerfassung. Bei der realen Datenerfassung handelt es sich bei den meisten Datenproben um normale/normale Fahrszenarien, während es nahezu unmöglich ist, Daten zu Kurven und anormalen Fahrszenarien zu erfassen. Zweitens sind weitere Anstrengungen erforderlich, um genaue und effiziente automatische Annotationsmethoden für AD-Daten zu erforschen. Drittens sollte der Schwerpunkt auf Szenendaten-Mining und Szenenverständnis gelegt werden, um das Problem der schlechten Leistung von AD-Modellen in bestimmten Szenen in städtischen Umgebungen zu lindern.
SOTA-Pipeline für autonomes Fahren mit geschlossenem Regelkreis
Die autonome Fahrbranche baut aktiv eine integrierte Big-Data-Plattform auf, um die Herausforderungen zu bewältigen, die sich aus der Ansammlung großer Mengen an AD-Daten ergeben. Dies kann treffend als die neue Infrastruktur für das Zeitalter des datengesteuerten autonomen Fahrens bezeichnet werden. In unserer Umfrage zu datengesteuerten Closed-Loop-Systemen, die von führenden AD-Unternehmen/Forschungsinstituten entwickelt wurden, haben wir mehrere Gemeinsamkeiten entdeckt:
- Diese Pipeline folgen normalerweise einem Workflow-Zyklus, einschließlich: (I) Datenerfassung, (II) Datenspeicherung, (III) Datenauswahl und -vorverarbeitung, (IV) Datenanmerkung, (V) AD-Modelltraining, (VI) Simulation/Testvalidierung und (VII) realer Einsatz.
- Für die Gestaltung geschlossener Kreisläufe innerhalb des Systems wählen bestehende Lösungen entweder die separate Einrichtung von „Daten-Schleife“ und „Modell-Schleife“ oder die Einrichtung verschiedener Phasen von Zyklen: „Geschlossener Kreis der F&E-Phase“ und „Bereitstellungsphase“. geschlossener Kreislauf“.
- Darüber hinaus wies die Branche auch auf die langfristigen Probleme bei der Verteilung realer AD-Datensätze und die Herausforderungen bei der Bewältigung von Sonderfällen hin. Tesla und Nvidia sind Branchenpioniere auf diesem Gebiet und ihre Datensystemarchitektur stellt eine wichtige Referenz für die Entwicklung dieses Bereichs dar.
NVIDIA MagLev AV-Plattform (Abbildung 3 (links)) folgt „Sammeln → Auswählen → Beschriften → Train the Dragon“ als Programm, einem replizierbaren Workflow, der aktives Lernen von SDC erreichen und intelligente Anmerkungen in der Schleife durchführen kann. MagLev umfasst hauptsächlich zwei geschlossene Kreisläufe Pipeline. Der erste Zyklus konzentriert sich auf autonome Fahrdaten, angefangen bei der Datenaufnahme und intelligenten Auswahl über Annotation und Annotation bis hin zur Modellsuche und dem Training. Das trainierte Modell wird dann bewertet, debuggt und schließlich in der realen Welt eingesetzt. Der zweite geschlossene Kreislauf ist das Infrastrukturunterstützungssystem der Plattform, einschließlich des Rechenzentrums-Backbones und der Hardware-Infrastruktur. Diese Schleife umfasst sichere Datenverarbeitung, skalierbare DNN- und System-KPIs sowie Dashboards zur Nachverfolgung und Fehlerbehebung. Es unterstützt den gesamten Zyklus der AV-Entwicklung und gewährleistet eine kontinuierliche Verbesserung und Integration realer Daten und Simulationsfeedbacks während des Entwicklungsprozesses.
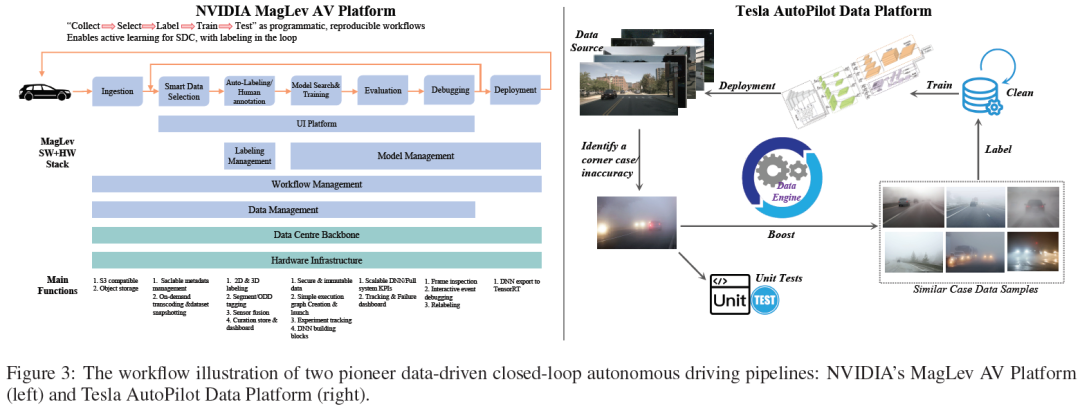
Die Tesla Autonomous Driving Data Platform (Abbildung 3 (rechts)) ist eine weitere repräsentative AD-Plattform, die den Einsatz einer Big-Data-gesteuerten Closed-Loop-Pipeline betont, um die Leistung des autonomen Fahrmodells deutlich zu verbessern. PipelineBeginnt mit der Quelldatenerfassung, typischerweise aus dem Flottenlernen von Tesla, der ereignisgesteuerten fahrzeugseitigen Datenerfassung und dem Schattenmodus. Die gesammelten Daten werden von Datenplattformalgorithmen oder menschlichen Experten gespeichert, verwaltet und überprüft. Immer wenn ein Grenzfall/eine Ungenauigkeit entdeckt wird, ruft die Daten-Engine Datenproben ab, die dem Grenzfall/der Ungenauigkeit aus der vorhandenen Datenbank sehr ähnlich sind, und gleicht sie ab. Gleichzeitig werden Unit-Tests entwickelt, um das Szenario nachzubilden und die Reaktion des Systems rigoros zu testen. Die abgerufenen Datenproben werden dann von automatischen Annotationsalgorithmen oder menschlichen Experten mit Anmerkungen versehen. Die gut kommentierten Daten werden dann an die AD-Datenbank zurückgegeben, die aktualisiert wird, um neue Versionen von Trainingsdatensätzen für AD-Erkennungs-/Vorhersage-/Planungs-/Kontrollmodelle zu generieren. Nach Modelltraining, Verifizierung, Simulation und realen Tests werden neue AD-Modelle mit höherer Leistung veröffentlicht und bereitgestellt.
Generative AD-Datengenerierung und -Simulation mit hoher Wiedergabetreue auf Basis generativer KIDie meisten aus der realen Welt gesammelten AD-Datenbeispiele sind alltägliche/normale Fahrszenarien, von denen wir bereits eine große Anzahl ähnlicher Beispiele in der Datenbank haben. Um jedoch AD-Datenproben aus realen Erfassungen zu sammeln, müssten wir exponentiell lange fahren, was bei industriellen Anwendungen nicht machbar ist. Daher haben hochpräzise Methoden zur Generierung und Simulation von autonomen Fahrdaten große Aufmerksamkeit in der akademischen Gemeinschaft auf sich gezogen. CARLA ist ein Open-Source-Simulator für die autonome Fahrforschung, der autonome Fahrdaten unter verschiedenen benutzerspezifischen Einstellungen generieren kann. Die Stärke von CARLA ist seine Flexibilität, die es Benutzern ermöglicht, unterschiedliche Straßenbedingungen, Verkehrsszenarien und Wetterdynamiken zu erstellen, was ein umfassendes Modelltraining und -tests erleichtert. Als Simulator besteht sein Hauptnachteil jedoch in der Domänenlücke. Die von CARLA generierten AD-Daten können die physischen und visuellen Effekte der realen Welt nicht vollständig simulieren; die dynamischen und komplexen Eigenschaften der realen Fahrumgebung werden ebenfalls nicht abgebildet.
In letzter Zeit werden Weltmodelle mit ihren fortschrittlicheren intrinsischen Konzepten und ihrer vielversprechenderen Leistung für die Generierung von AD-Daten mit hoher Wiedergabetreue verwendet. Ein Weltmodell kann als ein künstliches Intelligenzsystem definiert werden, das eine interne Darstellung der von ihm wahrgenommenen Umgebung erstellt und die erlernte Darstellung verwendet, um Daten oder Ereignisse in der Umgebung zu simulieren. Das Ziel eines allgemeinen Weltmodells besteht darin, Situationen und Interaktionen so darzustellen und zu simulieren, wie sie erwachsene Menschen in der realen Welt antreffen. Im Bereich des autonomen Fahrens sind GAIA-1 und DriveDreamer Meisterwerke der Datengenerierung auf Basis von Weltmodellen. GAIA-1 ist ein generatives Modell der künstlichen Intelligenz, das die Bild-/Video-zu-Bild-/Video-Generierung erreicht, indem Rohbilder/-videos zusammen mit Text und Handlungsaufforderungen als Eingabe verwendet werden. Die Eingabemodalitäten von GAIA-1 werden in einer einheitlichen Folge von Token kodiert. Diese Anmerkungen werden von einem autoregressiven Transformator innerhalb des Weltmodells verarbeitet, um nachfolgende Bildanmerkungen vorherzusagen. Der Videodecoder rekonstruiert diese Anmerkungen dann in kohärente Videoausgaben mit verbesserter zeitlicher Auflösung und ermöglicht so die dynamische und kontextreiche Generierung visueller Inhalte. DriveDreamer übernimmt in seiner Architektur auf innovative Weise ein Diffusionsmodell und konzentriert sich auf die Erfassung der Komplexität realer Fahrumgebungen. Seine zweistufige Trainingspipeline ermöglicht es dem Modell zunächst, strukturierte Verkehrsbeschränkungen zu erlernen und dann zukünftige Zustände vorherzusagen, wodurch ein starkes Umweltverständnis gewährleistet wird, das auf autonome Fahranwendungen zugeschnitten ist.
Automatische Kennzeichnungsmethode für autonome Fahrdatensätze
Eine qualitativ hochwertige Datenkennzeichnung ist für Erfolg und Zuverlässigkeit unerlässlich. Bisher kann die DatenanmerkungPipeline in drei Typen unterteilt werden, von der herkömmlichen manuellen Annotation über die halbautomatische Annotation bis hin zu hochmodernen vollautomatischen Annotationsmethoden, wie in Abbildung 4 dargestellt. AD-Datenannotation wird normalerweise als AD-Annotation angesehen aufgabenspezifisch /Modell. Der Arbeitsablauf beginnt mit der sorgfältigen Vorbereitung der Anforderungen für die Annotationsaufgabe und den Originaldatensatz. Anschließend besteht der nächste Schritt darin, erste Annotationsergebnisse mithilfe menschlicher Experten, automatischer Annotationsalgorithmen oder großer End2End-Modelle zu generieren. Anschließend wird die Annotationsqualität durch menschliche Experten oder automatisierte Qualitätsprüfalgorithmen anhand vordefinierter Anforderungen überprüft. Wenn die Annotationsergebnisse dieser Runde die Qualitätsprüfung nicht bestehen, werden sie erneut an den Annotationszyklus zurückgesendet und dieser Annotationsauftrag wird wiederholt, bis sie die vordefinierten Anforderungen erfüllen. Schließlich können wir einen vorgefertigten, beschrifteten AD-Datensatz erhalten.

-Pipeline erforscht erstmals AD-bewusste Marker auf räumlich-zeitlicher Ebene. Im Bereich des autonomen Fahrens werden 3D-Zielbegrenzungsrahmenmarkierungen auf der räumlichen Skala und entsprechende 1D-Zeitstempelmarkierungen auf der Zeitskala als 4D-Markierung bezeichnet. Die Auto4D-Pipeline beginnt mit einer kontinuierlichen Lidar-Punktwolke, um erste Objekttrajektorien zu ermitteln. Die Flugbahn wird durch den Zielgrößenzweig verfeinert, der die Zielgröße anhand von Zielbeobachtungen kodiert und dekodiert. Gleichzeitig codiert der Bewegungspfadzweig Pfadbeobachtungen und Bewegung, sodass der Pfaddecoder die Trajektorie mit einer konstanten Zielgröße verfeinern kann.
Die automatische Beschriftung statischer 3D-Szenen kann als HDMap-Generierung betrachtet werden, bei der Fahrspuren, Straßengrenzen, Zebrastreifen, Ampeln und andere relevante Elemente in der Fahrszene beschriftet werden sollten. Zu diesem Thema gibt es mehrere attraktive Forschungsarbeiten: Vision-basierte Methoden wie MVMap, NeMO; Lidar-basierte Methoden wie VMA vorab trainierte 3D-Szenenrekonstruktionsmethoden wie OccBEV, OccNet/ADPT, ALO. VMA ist eine kürzlich vorgeschlagene Arbeit zur automatischen Beschriftung statischer 3D-Szenen. Das VMA-Framework nutzt Crowdsourcing-basierte, über mehrere Fahrten aggregierte LIDAR-Punktwolken, um statische Szenen zu rekonstruieren und sie zur Verarbeitung in Einheiten zu segmentieren. Der MapTR-basierte Unit-Annotator kodiert die Roheingabe durch Abfragen und Dekodierung in Feature-Maps und generiert so semantisch typisierte Punktsequenzen. Das Ergebnis von VMA ist eine vektorisierte Karte, die durch Annotation im geschlossenen Regelkreis und manuelle Überprüfung verfeinert wird, um eine zufriedenstellende hochpräzise Karte für autonomes Fahren bereitzustellen.
Empirische Studie
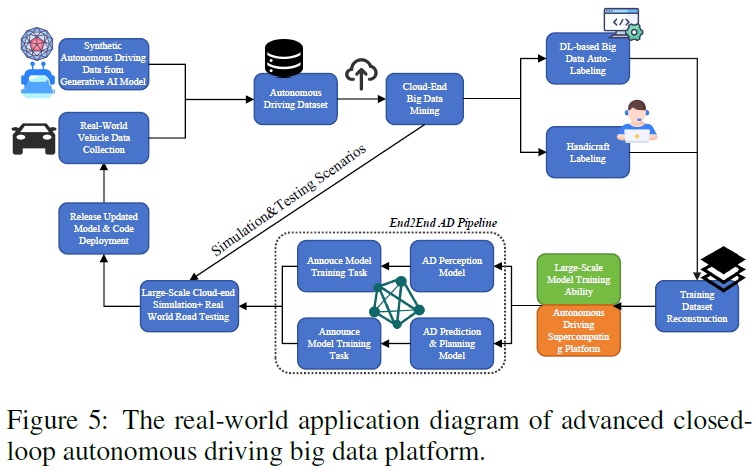
Wir stellen eine empirische Studie zur Verfügung, um die in diesem Artikel erwähnte fortschrittliche AD-Datenplattform mit geschlossenem Regelkreis besser zu veranschaulichen. Das gesamte Prozessdiagramm ist in Abbildung 5 dargestellt. In diesem Fall besteht das Ziel der Forscher darin, eine AD-Big-Data-Pipeline mit geschlossenem Regelkreis zu entwickeln, die auf generativer KI und verschiedenen Deep-Learning-basierten Algorithmen basiert und so die Entwicklungsphase des autonomen Fahralgorithmus und die OTA-Upgrade-Phase (nach der realen Welt) ermöglicht Bereitstellung), um einen geschlossenen Datenkreislauf zu erreichen. Konkret wird das generierte Modell der künstlichen Intelligenz verwendet, um (1) hochpräzise AD-Daten für bestimmte Szenarien auf der Grundlage von Textaufforderungen zu generieren, die von Ingenieuren bereitgestellt werden. (2) Automatische Kennzeichnung von AD-Big-Data zur effektiven Erstellung von Ground-Truth-Kennzeichnungen. Das Diagramm zeigt zwei geschlossene Kreisläufe. Eine der größeren Phasen ist die Entwicklungsphase des autonomen Fahralgorithmus, die mit der Datenerfassung synthetischer autonomer Fahrdaten beginnt, um Modelle der künstlichen Intelligenz und Datenproben aus dem realen Fahren zu generieren. Diese beiden Datenquellen werden in einen selbstfahrenden Datensatz integriert und in der Cloud ausgewertet, um wertvolle Erkenntnisse zu gewinnen. Anschließend durchläuft der Datensatz einen dualen Kennzeichnungspfad: automatische Kennzeichnung auf Basis von Deep Learning oder manuelle manuelle Kennzeichnung, um die Geschwindigkeit und Genauigkeit der Annotation sicherzustellen. Die gekennzeichneten Daten werden dann verwendet, um das Modell auf einer leistungsstarken Supercomputing-Plattform für autonomes Fahren zu trainieren. Diese Modelle werden in Simulationen und auf realen Straßen getestet, um ihre Wirksamkeit zu bewerten. Dies führt zur Veröffentlichung und anschließenden Bereitstellung autonomer Fahrmodelle. Die kleinere Variante ist für die OTA-Upgrade-Phase nach der realen Bereitstellung gedacht, die groß angelegte Cloud-Simulationen und reale Tests umfasst, um Ungenauigkeiten/Eckfälle des AD-Algorithmus zu erfassen. Die identifizierten Ungenauigkeiten/Eckfälle werden verwendet, um die nächste Iteration von Modelltests und -aktualisierungen zu informieren. Angenommen, wir stellen beispielsweise fest, dass unser AD-Algorithmus in einem Tunnelfahrszenario eine schlechte Leistung erbringt. Identifizierte Tunnelfahrkurven werden dem Ring sofort bekannt gegeben und in der nächsten Iteration aktualisiert. Das generative künstliche Intelligenzmodell verwendet relevante Beschreibungen von Tunnelfahrszenen als Textaufforderungen, um umfangreiche Tunnelfahrdatenproben zu generieren. Die generierten Daten und Rohdatensätze werden in Simulationen, Tests und Modellaktualisierungen eingespeist. Der iterative Charakter dieser Prozesse ist von entscheidender Bedeutung für die Optimierung von Modellen zur Anpassung an anspruchsvolle Umgebungen und neue Daten und die Aufrechterhaltung einer hohen Genauigkeit und Zuverlässigkeit der autonomen Fahrfähigkeiten.
neue autonome Fahrdatensätze der dritten Generation und darüber hinaus
. Obwohl grundlegende Modelle wie LLM/VLM Erfolge beim Sprachverständnis und beim Computersehen erzielt haben, ist es immer noch eine Herausforderung, sie direkt auf das autonome Fahren anzuwenden. Dafür gibt es zwei Gründe: Einerseits müssen diese LLM/VLM in der Lage sein, AD-Big-Data aus mehreren Quellen (z. B. FOV-Bilder/Videos, Lidar-Wolkenpunkte, hochauflösende Karten usw.) vollständig zu integrieren und zu verstehen. GPS/IMU-Daten usw.), was effizienter ist als Es ist noch schwieriger, die Bilder zu verstehen, die wir in unserem täglichen Leben sehen. Andererseits sind der vorhandene Datenumfang und die Qualität im Bereich des autonomen Fahrens nicht mit anderen Bereichen (wie Finanzen und medizinischer Versorgung) vergleichbar, was es schwierig macht, das Training und die Optimierung von LLM/VLM mit größerer Kapazität zu unterstützen. Big Data für autonomes Fahren ist derzeit aufgrund von Vorschriften, Datenschutzbedenken und Kosten in Umfang und Qualität begrenzt. Wir glauben, dass die nächste Generation von AD-Big Data durch die gemeinsamen Anstrengungen aller Parteien in Umfang und Qualität deutlich verbessert werden wird.
Hardware-Unterstützung für autonome Fahralgorithmen. Aktuelle Hardwareplattformen haben erhebliche Fortschritte gemacht, insbesondere mit dem Aufkommen spezialisierter Prozessoren wie GPUs und TPUs, die die enorme parallele Rechenleistung bereitstellen, die für Deep-Learning-Aufgaben entscheidend ist. Für die Verarbeitung der riesigen Datenströme, die von Fahrzeugsensoren in Echtzeit erzeugt werden, sind leistungsstarke Rechenressourcen in der On-Board- und Cloud-Infrastruktur von entscheidender Bedeutung. Trotz dieser Fortschritte gibt es bei der Bewältigung der zunehmenden Komplexität autonomer Fahralgorithmen immer noch Einschränkungen in Bezug auf Skalierbarkeit, Energieeffizienz und Verarbeitungsgeschwindigkeit. VLM/LLM-geführte Benutzer-Fahrzeug-Interaktion ist ein vielversprechender Anwendungsfall. Basierend auf dieser Anwendung können benutzerspezifische verhaltensbezogene Big Data erfasst werden. VLM/LLM-In-Vehicle-Geräte erfordern jedoch hohe Standards an Hardware-Rechenressourcen und interaktive Anwendungen werden voraussichtlich eine geringe Latenz aufweisen. Daher könnte es in Zukunft einige leichte, groß angelegte autonome Fahrmodelle geben, oder die Komprimierungstechnologie von LLM/VLM wird weiter untersucht. Personalisierte autonome Fahrempfehlungen basierend auf Benutzerverhaltensdaten. Intelligente Autos haben sich vom einfachen Fortbewegungsmittel zur neuesten Anwendungserweiterung in Smart-Terminal-Szenarien entwickelt. Daher wird von Fahrzeugen, die mit fortschrittlichen autonomen Fahrfunktionen ausgestattet sind, erwartet, dass sie die Verhaltenspräferenzen des Fahrers, wie z. B. Fahrstil und Fahrroutenpräferenzen, aus historischen Fahrdatensätzen lernen können. Dadurch können sich intelligente Autos in Zukunft besser an die Lieblingsfahrzeuge der Nutzer anpassen, da sie den Fahrern bei der Fahrzeugkontrolle, bei Fahrentscheidungen und bei der Routenplanung helfen. Wir nennen das obige Konzept einen personalisierten Empfehlungsalgorithmus für autonomes Fahren. Empfehlungssysteme werden häufig im E-Commerce, beim Online-Shopping, bei der Lieferung von Lebensmitteln, in sozialen Medien und auf Live-Streaming-Plattformen eingesetzt. Allerdings stecken personalisierte Empfehlungen im Bereich des autonomen Fahrens noch in den Kinderschuhen. Wir glauben, dass in naher Zukunft ein geeigneteres Datensystem und ein besserer Datenerfassungsmechanismus entwickelt werden, um mit der Erlaubnis des Benutzers und der Einhaltung relevanter Vorschriften große Datenmengen über die Fahrverhaltenspräferenzen der Benutzer zu sammeln und so maßgeschneiderte autonome Fahrempfehlungen für Benutzer zu erhalten . Datensicherheit und vertrauenswürdiges autonomes Fahren. Die enorme Menge an Big Data beim autonomen Fahren stellt große Herausforderungen an die Datensicherheit und den Schutz der Privatsphäre der Benutzer. Mit der Weiterentwicklung der Technologien für vernetzte autonome Fahrzeuge (CAVs) und Internet der Fahrzeuge (IoV) werden Fahrzeuge zunehmend vernetzt, und die Erfassung detaillierter Benutzerdaten von Fahrgewohnheiten bis hin zu häufigen Routen hat Bedenken hinsichtlich des möglichen Missbrauchs personenbezogener Daten geweckt. Wir empfehlen die Notwendigkeit von Transparenz hinsichtlich der Art der erfassten Daten, der Aufbewahrungsrichtlinien und der Weitergabe an Dritte. Es betont die Bedeutung der Einwilligung und Kontrolle des Nutzers, einschließlich der Berücksichtigung von „Do Not Track“-Anfragen und der Möglichkeit, personenbezogene Daten zu löschen. Für die Branche des autonomen Fahrens erfordert der Schutz dieser Daten bei gleichzeitiger Förderung von Innovationen die strikte Einhaltung dieser Richtlinien, um das Vertrauen der Benutzer und die Einhaltung der sich entwickelnden Datenschutzgesetze sicherzustellen. Neben Datensicherheit und Datenschutz geht es auch darum, wie man vertrauenswürdiges autonomes Fahren erreichen kann. Mit der enormen Entwicklung der AD-Technologie werden intelligente Algorithmen und generative künstliche Intelligenzmodelle (wie LLM, VLM) „als treibende Faktoren“ bei der Durchführung immer komplexerer Fahrentscheidungen und -aufgaben fungieren. In diesem Bereich stellt sich natürlich die Frage: Können Menschen autonomen Fahrmodellen vertrauen? Aus unserer Sicht liegt der Schlüssel zur Vertrauenswürdigkeit in der Interpretierbarkeit selbstfahrender Modelle. Sie sollten in der Lage sein, einem menschlichen Fahrer die Gründe für eine Entscheidung zu erklären und nicht nur Fahrhandlungen durchzuführen. Von LLM/VLM wird erwartet, dass es das vertrauenswürdige autonome Fahren verbessert, indem es fortschrittliche Argumente und verständliche Erklärungen in Echtzeit liefert. Diese Umfrage bietet den ersten systematischen Überblick über die datenzentrierte Entwicklung beim autonomen Fahren, einschließlich Big-Data-Systemen, Data-Mining und Closed-Loop-Technologien. In dieser Umfrage entwickeln wir zunächst eine Taxonomie von Datensätzen nach Meilensteingenerierung, überprüfen die Entwicklung von AD-Datensätzen über die historische Zeitachse und stellen die Erfassung, Einrichtung und Schlüsselfunktionen von Datensätzen vor. Darüber hinaus erläutern wir das datengesteuerte autonome Fahrsystem mit geschlossenem Regelkreis sowohl aus akademischer als auch aus industrieller Sicht. WorkflowPipeline, Prozesse und Schlüsseltechnologien in datenzentrierten Closed-Loop-Systemen werden ausführlich besprochen. Durch empirische Untersuchungen werden die Nutzungsrate und Vorteile der datenzentrierten AD-Plattform mit geschlossenem Regelkreis bei der Algorithmenentwicklung und OTA-Upgrades demonstriert. Abschließend werden die Vor- und Nachteile bestehender datengesteuerter autonomer Fahrtechnologien und zukünftige Forschungsrichtungen umfassend diskutiert. Im Fokus stehen neue Datensätze, Hardwareunterstützung, personalisierte AD-Empfehlungen und erklärbares autonomes Fahren nach der dritten Generation. Wir äußerten auch Bedenken hinsichtlich der Vertrauenswürdigkeit generativer KI-Modelle, der Datensicherheit und der zukünftigen Entwicklung des autonomen Fahrens. Originallink: https://mp.weixin.qq.com/s/YEjWSvKk6f-TDAR91Ow2rAFazit

Das obige ist der detaillierte Inhalt vonDaten sind König! Wie kann man anhand von Daten Schritt für Schritt einen effizienten autonomen Fahralgorithmus aufbauen?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1386
1386
 52
52

 Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Gestern wurde ich während des Interviews gefragt, ob ich irgendwelche Long-Tail-Fragen gestellt hätte, also dachte ich, ich würde eine kurze Zusammenfassung geben. Das Long-Tail-Problem des autonomen Fahrens bezieht sich auf Randfälle bei autonomen Fahrzeugen, also mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Das wahrgenommene Long-Tail-Problem ist einer der Hauptgründe, die derzeit den betrieblichen Designbereich intelligenter autonomer Einzelfahrzeugfahrzeuge einschränken. Die zugrunde liegende Architektur und die meisten technischen Probleme des autonomen Fahrens wurden gelöst, und die verbleibenden 5 % der Long-Tail-Probleme wurden nach und nach zum Schlüssel zur Einschränkung der Entwicklung des autonomen Fahrens. Zu diesen Problemen gehören eine Vielzahl fragmentierter Szenarien, Extremsituationen und unvorhersehbares menschliches Verhalten. Der „Long Tail“ von Randszenarien beim autonomen Fahren bezieht sich auf Randfälle in autonomen Fahrzeugen (AVs). Randfälle sind mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. diese seltenen Ereignisse
 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Leitfaden für den Lebensneustart-Simulator
May 07, 2024 pm 05:28 PM
Leitfaden für den Lebensneustart-Simulator
May 07, 2024 pm 05:28 PM
Life Restart Simulator ist ein sehr interessantes Simulationsspiel. Es gibt viele Möglichkeiten, das Spiel zu spielen. Schauen Sie sich das Spiel an Strategien gibt es? Life Restart Simulator-Anleitung Anleitung Funktionen von Life Restart Simulator Dies ist ein sehr kreatives Spiel, in dem Spieler nach ihren eigenen Vorstellungen spielen können. Es gibt jeden Tag viele Aufgaben zu erledigen und Sie können ein neues Leben in dieser virtuellen Welt genießen. Es gibt viele Lieder im Spiel und alle möglichen Leben warten darauf, von Ihnen erlebt zu werden. Spielinhalt des Life Restart Simulators Talent-Zeichnungskarten: Talent: Sie müssen die geheimnisvolle kleine Kiste auswählen, um ein Unsterblicher zu werden. Um ein Absterben auf halbem Weg zu vermeiden, sind verschiedene kleine Kapseln erhältlich. Cthulhu kann wählen
 Einführung in die Schriftarteinstellungsmethode des Joiplay-Simulators
May 09, 2024 am 08:31 AM
Einführung in die Schriftarteinstellungsmethode des Joiplay-Simulators
May 09, 2024 am 08:31 AM
Der Jojplay-Simulator kann die Schriftarten des Spiels tatsächlich anpassen und das Problem fehlender Zeichen und umrahmter Zeichen im Text lösen. Ich vermute, dass viele Spieler immer noch nicht wissen, wie man ihn bedient Schriftart des Jojplay-Simulators vorstellen. So legen Sie die Schriftart des Joiplay-Simulators fest: 1. Öffnen Sie zunächst den Joiplay-Simulator, klicken Sie auf die Einstellungen (drei Punkte) in der oberen rechten Ecke und suchen Sie ihn. 2. Klicken Sie in der Spalte „RPGMSettings“ auf die benutzerdefinierte Schriftart „CustomFont“ in der dritten Zeile, um sie auszuwählen. 3. Wählen Sie die Schriftartdatei aus und klicken Sie auf „OK“. Klicken Sie nicht auf das Symbol „Speichern“ in der unteren rechten Ecke, da sonst die Standardeinstellungen wiederhergestellt werden. 4. Empfehlen Sie Founder und Quasi-Yuan Simplified Chinese (bereits in den Ordnern der Spiele Fuxing und Rebirth). joi
 cURL vs. wget: Welches ist besser für Sie?
May 07, 2024 am 09:04 AM
cURL vs. wget: Welches ist besser für Sie?
May 07, 2024 am 09:04 AM
Wenn Sie Dateien direkt über die Linux-Befehlszeile herunterladen möchten, fallen Ihnen sofort zwei Tools ein: wget und cURL. Sie haben viele der gleichen Eigenschaften und können problemlos einige der gleichen Aufgaben erfüllen. Obwohl sie einige ähnliche Eigenschaften haben, sind sie nicht genau gleich. Diese beiden Programme eignen sich für unterschiedliche Situationen und haben in bestimmten Situationen ihre eigenen Besonderheiten. cURL vs. wget: Ähnlichkeiten Sowohl wget als auch cURL können Inhalte herunterladen. So sind sie im Kern konzipiert. Sie können sowohl Anfragen an das Internet senden als auch angeforderte Artikel zurücksenden. Dies kann eine Datei, ein Bild oder etwas anderes wie der Roh-HTML-Code der Website sein. Beide Programme können HTTPPOST-Anfragen stellen. Das bedeutet, dass sie alle senden können
 Wie lösche ich die Donner- und Blitzsimulatoranwendung? -Wie lösche ich Anwendungen im Thunderbolt Simulator?
May 08, 2024 pm 02:40 PM
Wie lösche ich die Donner- und Blitzsimulatoranwendung? -Wie lösche ich Anwendungen im Thunderbolt Simulator?
May 08, 2024 pm 02:40 PM
Die offizielle Version von Thunderbolt Simulator ist ein sehr professionelles Android-Emulator-Tool. Wie lösche ich also die Donner- und Blitzsimulatoranwendung? Wie lösche ich Anwendungen im Thunderbolt Simulator? Lassen Sie sich vom Herausgeber unten die Antwort geben! Wie lösche ich die Donner- und Blitz-Simulator-Anwendung? 1. Klicken und halten Sie das Symbol der App, die Sie löschen möchten. 2. Warten Sie eine Weile, bis die Option zum Deinstallieren oder Löschen der App angezeigt wird. 3. Ziehen Sie die App auf die Deinstallationsoption. 4. Klicken Sie im daraufhin angezeigten Bestätigungsfenster auf OK, um den Löschvorgang der Anwendung abzuschließen.
 Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Kürzlich wurde die Militärwelt von der Nachricht überwältigt: US-Militärkampfflugzeuge können jetzt mithilfe von KI vollautomatische Luftkämpfe absolvieren. Ja, erst kürzlich wurde der KI-Kampfjet des US-Militärs zum ersten Mal der Öffentlichkeit zugänglich gemacht und sein Geheimnis gelüftet. Der vollständige Name dieses Jägers lautet „Variable Stability Simulator Test Aircraft“ (VISTA). Er wurde vom Minister der US-Luftwaffe persönlich geflogen, um einen Eins-gegen-eins-Luftkampf zu simulieren. Am 2. Mai startete US-Luftwaffenminister Frank Kendall mit einer X-62AVISTA auf der Edwards Air Force Base. Beachten Sie, dass während des einstündigen Fluges alle Flugaktionen autonom von der KI durchgeführt wurden! Kendall sagte: „In den letzten Jahrzehnten haben wir über das unbegrenzte Potenzial des autonomen Luft-Luft-Kampfes nachgedacht, aber es schien immer unerreichbar.“ Nun jedoch,
