
 Technologie-Peripheriegeräte
KI
Anonyme Zeitungen kommen mit überraschenden Ideen! Dies kann tatsächlich getan werden, um die Langtextfähigkeiten großer Modelle zu verbessern
Technologie-Peripheriegeräte
KI
Anonyme Zeitungen kommen mit überraschenden Ideen! Dies kann tatsächlich getan werden, um die Langtextfähigkeiten großer Modelle zu verbessern
Anonyme Zeitungen kommen mit überraschenden Ideen! Dies kann tatsächlich getan werden, um die Langtextfähigkeiten großer Modelle zu verbessern

Wenn es um die Verbesserung der Langtextfunktionen großer Modelle geht, denken Sie an Längenextrapolation oder Kontextfenstererweiterung?
Nein, diese verbrauchen zu viele Hardwareressourcen.
Werfen wir einen Blick auf eine wunderbare neue Lösung:
unterscheidet sich wesentlich vom KV-Cache, der von Methoden wie der Längenextrapolation verwendet wird. Es nutzt die Parameter des Modells, um eine große Menge an Kontextinformationen zu speichern .
Die spezifische Methode besteht darin, ein temporäres Lora-Modul zu erstellen, so dass es während des Langtextgenerierungsprozesses „nur Aktualisierungen streamt“, d. h. es verwendet kontinuierlich zuvor generierte Inhalte als Eingabe und dient als Trainingsdaten Dadurch wird sichergestellt, dass Wissen in Modellparametern gespeichert wird.
DannSobald die Inferenz vollständig ist, werfen Sie sie weg , um sicherzustellen, dass es keine langfristigen Auswirkungen auf die Modellparameter gibt.
Diese Methode ermöglicht es uns, so viele Kontextinformationen zu speichern, wie wir möchten, ohne das Kontextfenster zu erweitern.Speichern Sie so viel, wie Sie möchten. Experimente haben gezeigt, dass diese Methode:
die Qualität von Langtextaufgaben des Modells erheblich verbessern kann, indem eine Reduzierung der Ratlosigkeit um 29,6 % und eine Verbesserung der Übersetzungsqualität von Langtexten um 53,2 % erreicht wird
- (BLAUER Wert)
- ; kann auch mit den meisten vorhandenen Methoden zur Langtextgenerierung kompatibel sein und diese verbessern. Das Wichtigste ist, dass dadurch die Rechenkosten erheblich gesenkt werden können.
- Bei gleichzeitiger Gewährleistung einer leichten Verbesserung der Generierungsqualität (Verwirrung um 3,8 % reduziert) werden die für die Inferenz erforderlichen FLOPs um 70,5 % und die Verzögerung um 51,5 % reduziert!
Lassen Sie uns für die konkrete Situation das Papier öffnen und einen Blick darauf werfen. Erstellen Sie ein temporäres Lora-Modul und werfen Sie es nach der Verwendung weg. Die Methode heißt
Temp-Lora. Das Architekturdiagramm lautet wie folgt:
Der Kern besteht darin, den zuvor generierten Text schrittweise zu verwenden autoregressiv trainieren Temporäres Lora-Modul. Dieses Modul ist sehr anpassungsfähig und kann kontinuierlich angepasst werden, sodass ein tiefes Verständnis für Kontexte unterschiedlicher Entfernung möglich ist.
Der spezifische Algorithmus ist wie folgt: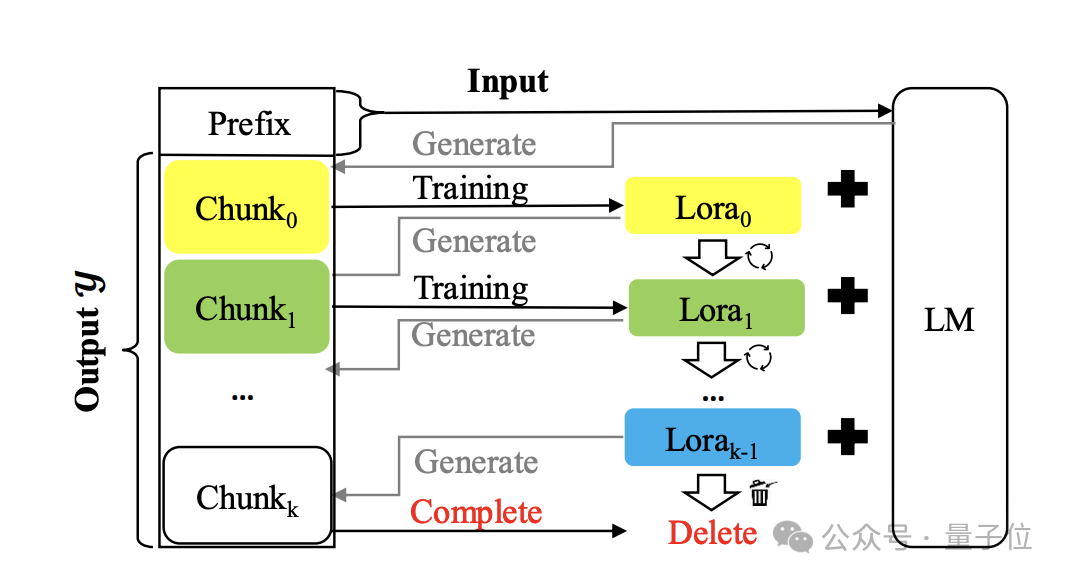 Während des Generierungsprozesses werden Token Block für Block generiert. Jedes Mal, wenn ein Block generiert wird, wird der neueste L
Während des Generierungsprozesses werden Token Block für Block generiert. Jedes Mal, wenn ein Block generiert wird, wird der neueste L
Token als Eingabe X verwendet, um nachfolgende Token zu generieren.
Sobald die Anzahl der generierten Token die vordefinierte Blockgröße Δ erreicht, starten Sie das Training des Temp-Lora-Moduls mit dem neuesten Block und starten Sie dann die nächste Blockgenerierung.
Im Experiment setzt der Autor Δ+Lx
auf W, um die Kontextfenstergröße des Modells voll auszunutzen. Für das Training des Temp-Lora-Moduls stellt das Erlernen der bedingungslosen Generierung neuer Blöcke möglicherweise kein wirksames Trainingsziel dar und führt zu einer ernsthaften Überanpassung. Um dieses Problem zu lösen, integrieren die Autoren L
Um dieses Problem zu lösen, integrieren die Autoren L
-Tags vor jedem Block in den Trainingsprozess und verwenden sie als Eingabe und den Block als Ausgabe. Schließlich schlägt der Autor auch eine Strategie namens
Cache-Wiederverwendung (Cache-Wiederverwendung)vor, um effizientere Schlussfolgerungen zu erzielen. Im Allgemeinen müssen wir nach der Aktualisierung des Temp-Loramo-Moduls im Standard-Framework den KV-Status mit den aktualisierten Parametern neu berechnen.
Alternativ können Sie den vorhandenen zwischengespeicherten KV-Status wiederverwenden und gleichzeitig das aktualisierte Modell für die nachfolgende Textgenerierung verwenden. Konkret verwenden wir das neueste Temp-Lora-Modul, um den KV-Zustand nur dann neu zu berechnen, wenn das Modell eine maximale Länge (Kontextfenstergröße W) generiert.
Eine solche Cache-Wiederverwendungsmethode kann die Generierung beschleunigen, ohne die Generierungsqualität wesentlich zu beeinträchtigen.
Das ist die Einführung in die Temp-Lora-Methode. Schauen wir uns hauptsächlich den folgenden Test an.
Je länger der Text, desto besser der EffektDer Autor bewertete das Temp-Lora-Framework für die Modelle Llama2-7B-4K, Llama2-13B-4K, Llama2-7B-32K und Yi-Chat-6B und behandelte diese beiden Arten von Langtextaufgaben sind Generierung und Übersetzung.
Der Testdatensatz ist eine Teilmenge des Langtext-Sprachmodellierungs-Benchmarks PG19, aus dem 40 Bücher zufällig ausgewählt wurden.
Bei der anderen handelt es sich um eine zufällig ausgewählte Teilmenge des Guofeng-Datensatzes von WMT 2023, der 20 chinesische Online-Romane enthält, die von Fachleuten ins Englische übersetzt wurden.
Schauen wir uns zunächst die Ergebnisse von PG19 an.
Die folgende Tabelle zeigt den PPL
(Ratlosigkeit, spiegelt die Unsicherheit des Modells für eine bestimmte Eingabe wider, je niedriger, desto besser)Vergleich verschiedener Modelle auf PG19 mit und ohne Temp-Lora-Modul. Teilen Sie jedes Dokument in Segmente von 0-100.000 bis 500.000+Tokens auf. Es ist ersichtlich, dass die PPL aller Modelle nach Temp-Lora deutlich gesunken ist, und je länger die Clips werden, desto offensichtlicher ist der Einfluss von Temp-Lora (1-100K sank nur um 3,6 %, 500K+ sank um 13,2%) .
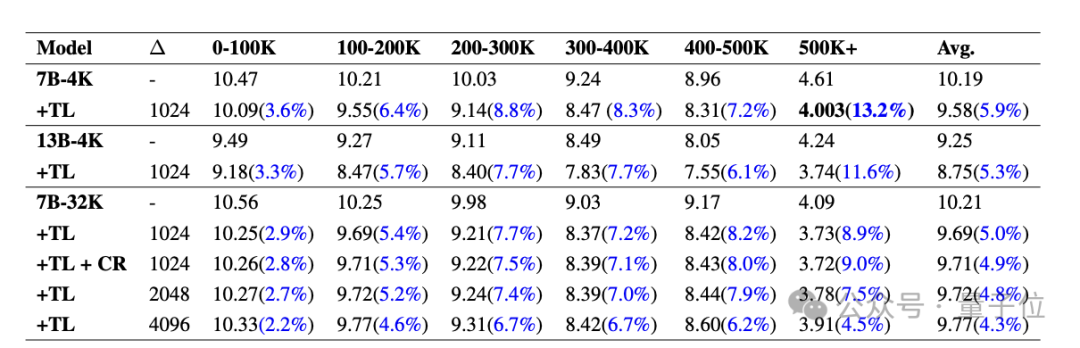
Daher können wir einfach schlussfolgern: Je mehr Text vorhanden ist, desto stärker ist die Notwendigkeit, Temp-Lora zu verwenden.
Darüber hinaus können wir feststellen, dass die Anpassung der Blockgröße von 1024 auf 2048 und 4096 zu einem leichten Anstieg des PPL führt.
Das ist nicht verwunderlich, schließlich wird das Temp-Lora-Modul auf den Daten des vorherigen Blocks trainiert.
Diese Daten zeigen uns hauptsächlich, dass die Wahl der Blockgröße ein wichtiger Kompromiss zwischen Erzeugungsqualität und Recheneffizienz ist (weitere Analysen finden Sie im Artikel) .
Schließlich können wir auch feststellen, dass die Wiederverwendung des Caches keinen Leistungsverlust verursacht. Der Autor sagte: Das sind sehr ermutigende Neuigkeiten.Das Folgende sind die Ergebnisse des Guofeng-Datensatzes.
Es ist ersichtlich, dass Temp-Lora auch einen erheblichen Einfluss auf literarische Langtextübersetzungsaufgaben hat. Signifikante Verbesserungen bei allen Metriken im Vergleich zum Basismodell: -29,6 % Reduzierung des PPL, +53,2 % Verbesserung des BLEU-Scores(Ähnlichkeit von maschinell übersetztem Text mit hochwertigen Referenzübersetzungen), +53,2 % Verbesserung des COMET-Scores (Auch ein Qualitätsindikator) um +8,4 % verbessert.
 Abschließend geht es um die Erforschung der Recheneffizienz und -qualität.
Abschließend geht es um die Erforschung der Recheneffizienz und -qualität.
Der Autor hat durch Experimente herausgefunden, dass die Verwendung der
„wirtschaftlichsten“ Temp-Lora-Konfiguration (Δ=2K, W=4K) den PPL um 3,8 % reduzieren und gleichzeitig 70,5 % der FLOPs und 51,5 % Verzögerung einsparen kann. Im Gegenteil, wenn wir den Rechenaufwand völlig ignorieren und
die „luxuriöseste“ Konfiguration (Δ=1K und W=24K) verwenden, können wir auch eine PPL-Reduzierung von 5,0 % und weitere 17 erreichen % FLOP-Anstieg und 19,6 % Latenz. Verwendungsvorschläge
Um die obigen Ergebnisse zusammenzufassen, gibt der Autor außerdem drei Vorschläge für die praktische Anwendung von Temp-Lora:
1 Für Anwendungen, die ein Höchstmaß an Langtextgenerierung erfordern, integrieren Sie Temp, ohne Parameter zu ändern. -Lora kann zu bestehenden Modellen hinzugefügt werden, um die Leistung bei relativ geringen Kosten deutlich zu verbessern.
2. Für Anwendungen, die Wert auf minimale Latenz oder Speichernutzung legen, können die Rechenkosten erheblich reduziert werden, indem die Eingabelänge und die in Temp-Lora gespeicherten Kontextinformationen reduziert werden.
In dieser Einstellung können wir eine feste kurze Fenstergröße
(z. B. 2 KB oder 4 KB)verwenden, um nahezu unendlich langen Text (500 KB+ in den Experimenten des Autors) zu verarbeiten. 3. Bitte beachten Sie abschließend, dass Temp-Lora in Szenarien, die keine große Textmenge enthalten, beispielsweise wenn der Kontext im Vortraining kleiner ist als die Fenstergröße des Modells, nutzlos ist.
Der Autor stammt von einer vertraulichen Organisation
Es ist erwähnenswert, dass der Autor für die Erfindung einer so einfachen und innovativen Methode nicht viele Quelleninformationen hinterlassen hat:
Der Name der Organisation ist direkt mit „Sekretärorganisation“ signiert. und die Namen der drei Autoren sind nur vollständige Nachnamen.
 Den E-Mail-Informationen zufolge könnte es sich jedoch um Schulen wie die City University of Hong Kong und die Hong Kong Chinese Language School handeln.
Den E-Mail-Informationen zufolge könnte es sich jedoch um Schulen wie die City University of Hong Kong und die Hong Kong Chinese Language School handeln.
Was halten Sie abschließend von dieser Methode?
Papier:Das obige ist der detaillierte Inhalt vonAnonyme Zeitungen kommen mit überraschenden Ideen! Dies kann tatsächlich getan werden, um die Langtextfähigkeiten großer Modelle zu verbessern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1386
1386
 52
52

 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
 Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Was? Wird Zootopia durch heimische KI in die Realität umgesetzt? Zusammen mit dem Video wird ein neues groß angelegtes inländisches Videogenerationsmodell namens „Keling“ vorgestellt. Sora geht einen ähnlichen technischen Weg und kombiniert eine Reihe selbst entwickelter technologischer Innovationen, um Videos zu produzieren, die nicht nur große und vernünftige Bewegungen aufweisen, sondern auch die Eigenschaften der physischen Welt simulieren und über starke konzeptionelle Kombinationsfähigkeiten und Vorstellungskraft verfügen. Den Daten zufolge unterstützt Keling die Erstellung ultralanger Videos von bis zu 2 Minuten mit 30 Bildern pro Sekunde, mit Auflösungen von bis zu 1080p und unterstützt mehrere Seitenverhältnisse. Ein weiterer wichtiger Punkt ist, dass es sich bei Keling nicht um eine vom Labor veröffentlichte Demo oder Video-Ergebnisdemonstration handelt, sondern um eine Anwendung auf Produktebene, die von Kuaishou, einem führenden Anbieter im Bereich Kurzvideos, gestartet wurde. Darüber hinaus liegt das Hauptaugenmerk darauf, pragmatisch zu sein, keine Blankoschecks auszustellen und sofort nach der Veröffentlichung online zu gehen. Das große Modell von Ke Ling wurde bereits in Kuaiying veröffentlicht.
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
