
 Technologie-Peripheriegeräte
KI
UCLA-Chinesen schlagen einen neuen Selbstspielmechanismus vor! LLM trainiert sich selbst und der Effekt ist besser als der der GPT-4-Expertenanleitung.
Technologie-Peripheriegeräte
KI
UCLA-Chinesen schlagen einen neuen Selbstspielmechanismus vor! LLM trainiert sich selbst und der Effekt ist besser als der der GPT-4-Expertenanleitung.
UCLA-Chinesen schlagen einen neuen Selbstspielmechanismus vor! LLM trainiert sich selbst und der Effekt ist besser als der der GPT-4-Expertenanleitung.

Synthetische Daten sind zum wichtigsten Eckpfeiler in der Entwicklung großer Sprachmodelle geworden.
Ende letzten Jahres enthüllten einige Internetnutzer, dass der ehemalige OpenAI-Chefwissenschaftler Ilya wiederholt erklärt habe, dass es bei der Entwicklung von LLM keine Datenengpässe gebe und synthetische Daten die meisten Probleme lösen könnten.
 Bilder
Bilder
Nach dem Studium der neuesten Arbeiten kam Jim Fan, ein leitender Wissenschaftler bei NVIDIA, zu dem Schluss, dass die Kombination synthetischer Daten mit traditioneller Spiel- und Bilderzeugungstechnologie es LLM ermöglichen kann, eine enorme Selbstentwicklung zu erreichen.
 Bilder
Bilder
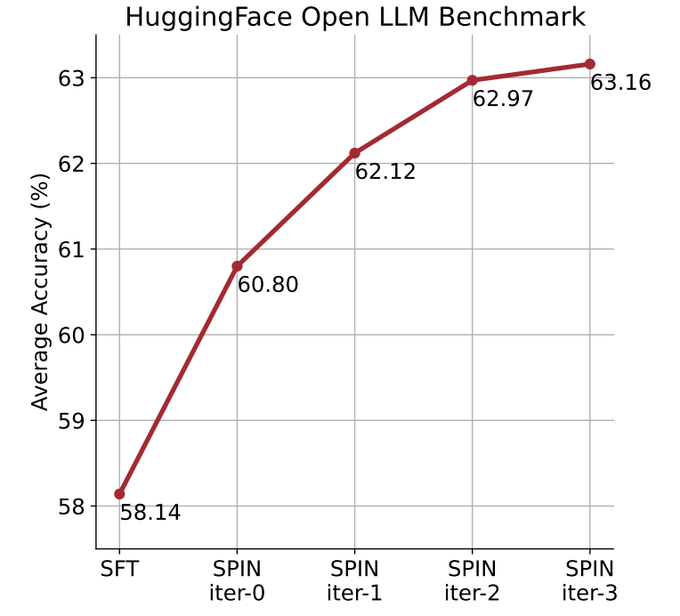
Der Artikel, der diese Methode offiziell vorschlug, wurde von einem chinesischen Team der UCLA verfasst. ? durch das Selbst- Feinabstimmungsmethode, nein Basierend auf dem neuen Datensatz wird die durchschnittliche Punktzahl des schwächeren LLM im Open LLM Leaderboard Benchmark von 58,14 auf 63,16 verbessert.

Die Forscher schlugen eine selbstverfeinernde Methode namens SPIN vor, die selbstspielendes Schach verwendet – LLM konkurriert mit seiner vorherigen Iterationsversion, um die Leistung des Sprachmodells schrittweise zu verbessern.
Bilder
 Auf diese Weise kann die Selbstentwicklung des Modells abgeschlossen werden, ohne dass zusätzliche menschliche Annotationsdaten oder Feedback von übergeordneten Sprachmodellen erforderlich sind.
Auf diese Weise kann die Selbstentwicklung des Modells abgeschlossen werden, ohne dass zusätzliche menschliche Annotationsdaten oder Feedback von übergeordneten Sprachmodellen erforderlich sind.
Die Parameter des Hauptmodells und des Gegnermodells sind genau gleich. Spielen Sie mit zwei verschiedenen Versionen gegen sich selbst.
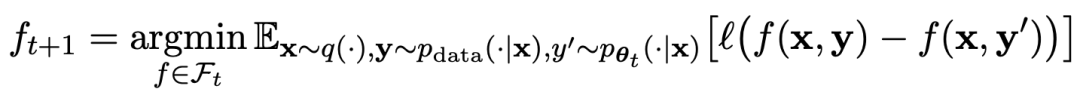 Der Spielablauf kann durch die Formel zusammengefasst werden:
Der Spielablauf kann durch die Formel zusammengefasst werden:
Bilder
Die Trainingsmethode des Selbstspiels. Zusammenfassend ist die Idee ungefähr so:
Unterscheiden Sie die Antworten Das Gegnermodell wird vom Gegnermodell durch Training des Hauptmodells und menschlicher Zielreaktionen generiert. Das Gegnermodell ist ein Sprachmodell, das iterativ in Runden erhalten wird, mit dem Ziel, Antworten zu generieren, die möglichst nicht unterscheidbar sind.
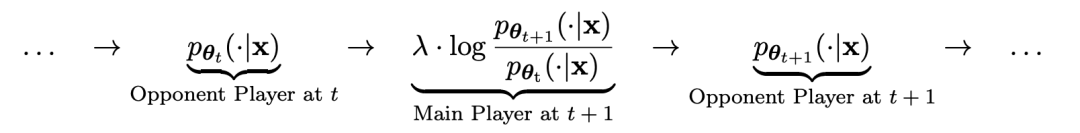 Angenommen, die in der t-ten Iteration erhaltenen Sprachmodellparameter sind θt. Verwenden Sie dann in der t + 1-Iteration θt als Gegenspieler und verwenden Sie θt, um die Antwort y' für jede Eingabeaufforderung x in zu generieren überwachter Feinabstimmungsdatensatz.
Angenommen, die in der t-ten Iteration erhaltenen Sprachmodellparameter sind θt. Verwenden Sie dann in der t + 1-Iteration θt als Gegenspieler und verwenden Sie θt, um die Antwort y' für jede Eingabeaufforderung x in zu generieren überwachter Feinabstimmungsdatensatz.
Optimieren Sie dann die neuen Sprachmodellparameter θt+1, damit sie y' von der menschlichen Antwort y im überwachten Feinabstimmungsdatensatz unterscheiden können. Dies kann einen schrittweisen Prozess bilden und sich schrittweise der Zielreaktionsverteilung nähern.
Hier verwendet die Verlustfunktion des Hauptmodells einen logarithmischen Verlust und berücksichtigt dabei den Unterschied in den Funktionswerten zwischen y und y‘.
Fügen Sie dem Gegnermodell eine KL-Divergenz-Regularisierung hinzu, um zu verhindern, dass die Modellparameter zu stark abweichen.
Die spezifischen Trainingsziele für gegnerische Spiele sind in Formel 4.7 dargestellt. Aus der theoretischen Analyse ist ersichtlich, dass der Optimierungsprozess konvergiert, wenn die Antwortverteilung des Sprachmodells gleich der Zielantwortverteilung ist.
Wenn Sie die nach dem Spiel generierten synthetischen Daten für das Training verwenden und dann SPIN zur Selbstoptimierung verwenden, kann die Leistung von LLM effektiv verbessert werden.
Bilder
Aber dann führt eine einfache erneute Feinabstimmung der anfänglichen Feinabstimmungsdaten zu Leistungseinbußen.
SPIN erfordert lediglich das Ausgangsmodell selbst und den vorhandenen fein abgestimmten Datensatz, damit sich LLM durch SPIN verbessern kann.
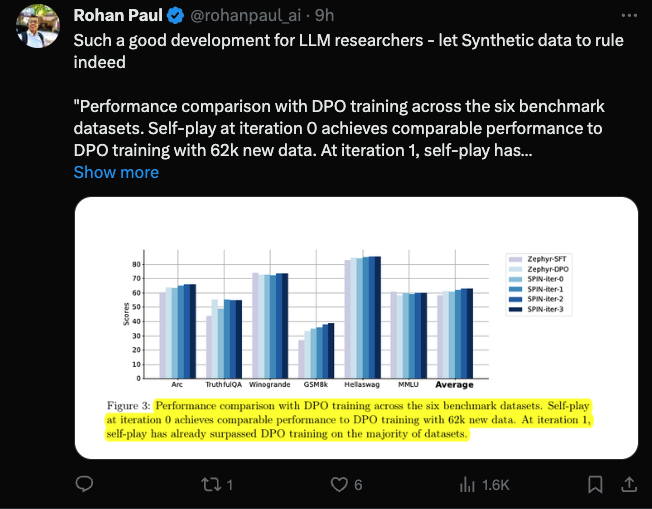
Insbesondere übertrifft SPIN sogar Modelle, die mit zusätzlichen GPT-4-Präferenzdaten über DPO trainiert wurden.
 Bilder
Bilder
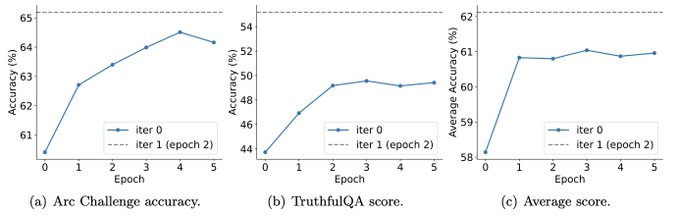
Und Experimente zeigen auch, dass iteratives Training die Modellleistung effektiver verbessern kann als Training mit mehr Epochen.
 Bilder
Bilder
Durch die Verlängerung der Trainingsdauer einer einzelnen Iteration wird die Leistung von SPIN nicht beeinträchtigt, es stößt jedoch an seine Grenzen.
Je mehr Iterationen, desto offensichtlicher ist die Wirkung von SPIN.
Nach der Lektüre dieses Artikels seufzten die Internetnutzer:
Synthetische Daten werden die Entwicklung großer Sprachmodelle dominieren, was für Forscher großer Sprachmodelle eine sehr gute Nachricht sein wird!
 Bilder
Bilder
Selbstspielen ermöglicht es LLM, sich kontinuierlich zu verbessern
Konkret handelt es sich bei dem von den Forschern entwickelten SPIN-System um ein System, bei dem sich zwei sich gegenseitig beeinflussende Modelle gegenseitig fördern.
bezeichnet durch 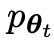 das LLM der vorherigen Iteration t, das die Forscher verwendet haben, um die Antwort y auf den Hinweis x im vom Menschen kommentierten SFT-Datensatz zu generieren.
das LLM der vorherigen Iteration t, das die Forscher verwendet haben, um die Antwort y auf den Hinweis x im vom Menschen kommentierten SFT-Datensatz zu generieren.
Das nächste Ziel besteht darin, ein neues LLM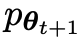 zu finden, das in der Lage ist, zwischen der
zu finden, das in der Lage ist, zwischen der 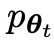 generierten Antwort y und der vom Menschen generierten Antwort y‘ zu unterscheiden.
generierten Antwort y und der vom Menschen generierten Antwort y‘ zu unterscheiden.
Dieser Prozess kann als ein Spiel für zwei Spieler angesehen werden:
Der Hauptspieler oder das neue LLM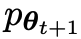 versucht, die Reaktion des gegnerischen Spielers und die vom Menschen erzeugte Reaktion zu erkennen, während der Gegner oder das alte LLM
versucht, die Reaktion des gegnerischen Spielers und die vom Menschen erzeugte Reaktion zu erkennen, während der Gegner oder das alte LLM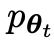 generiert Antworten, die den Daten im manuell kommentierten SFT-Datensatz so ähnlich wie möglich sind.
generiert Antworten, die den Daten im manuell kommentierten SFT-Datensatz so ähnlich wie möglich sind.
Das neue LLM 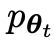 , das durch Feinabstimmung des alten
, das durch Feinabstimmung des alten 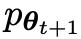 erhalten wurde, bevorzugt die Reaktion von
erhalten wurde, bevorzugt die Reaktion von 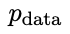 , was zu einer konsistenteren Verteilung
, was zu einer konsistenteren Verteilung 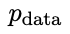 mit
mit 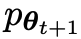 führt.
führt.
In der nächsten Iteration wird das neu erworbene LLM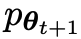 zum Gegner der Antwortgenerierung, und das Ziel des selbstspielenden Prozesses besteht darin, dass das LLM schließlich zu
zum Gegner der Antwortgenerierung, und das Ziel des selbstspielenden Prozesses besteht darin, dass das LLM schließlich zu 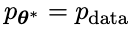 konvergiert, so dass das stärkste LLM dazu nicht mehr in der Lage ist Unterscheiden Sie zwischen der zuvor generierten Antwortversion und der vom Menschen generierten Version.
konvergiert, so dass das stärkste LLM dazu nicht mehr in der Lage ist Unterscheiden Sie zwischen der zuvor generierten Antwortversion und der vom Menschen generierten Version.
So nutzen Sie SPIN zur Verbesserung der Modellleistung
Die Forscher entwickelten ein Spiel für zwei Spieler, bei dem das Hauptziel des Modells darin besteht, zwischen LLM-generierten Antworten und von Menschen generierten Antworten zu unterscheiden. Gleichzeitig besteht die Rolle des Gegners darin, Reaktionen hervorzurufen, die nicht von denen des Menschen zu unterscheiden sind. Im Mittelpunkt des Ansatzes der Forscher steht das Training des Primärmodells.
Erklären Sie zunächst, wie Sie das Hauptmodell trainieren, um LLM-Antworten von menschlichen Antworten zu unterscheiden.
Im Mittelpunkt des Ansatzes der Forscher steht ein Selbstspielmechanismus, bei dem sowohl der Hauptspieler als auch der Gegner aus demselben LLM stammen, jedoch aus unterschiedlichen Iterationen.
Genauer gesagt ist der Gegner der alte LLM aus der vorherigen Iteration, und der Hauptakteur ist der neue LLM, der in der aktuellen Iteration gelernt werden muss. Die Iteration t+1 umfasst die folgenden zwei Schritte: (1) Training des Hauptmodells, (2) Aktualisierung des Gegenmodells.
Training des Master-Modells
Zunächst erklären die Forscher, wie man dem Master-Spieler beibringt, zwischen LLM-Reaktionen und menschlichen Reaktionen zu unterscheiden. Inspiriert durch das integrale Wahrscheinlichkeitsmaß (IPM) formulierten die Forscher die Zielfunktion:
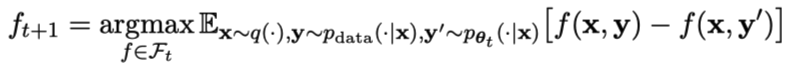 Bild
Bild
Aktualisieren Sie das Gegnermodell.
Das Ziel des Gegnermodells besteht darin, ein besseres LLM zu finden erzeugt Die Antwort von unterscheidet sich nicht von den p-Daten des Hauptmodells.
Experimente
SPIN verbessert effektiv die Benchmark-Leistung
Die Forscher nutzten das HuggingFace Open LLM Leaderboard als umfassende Bewertung, um die Wirksamkeit von SPIN zu beweisen.
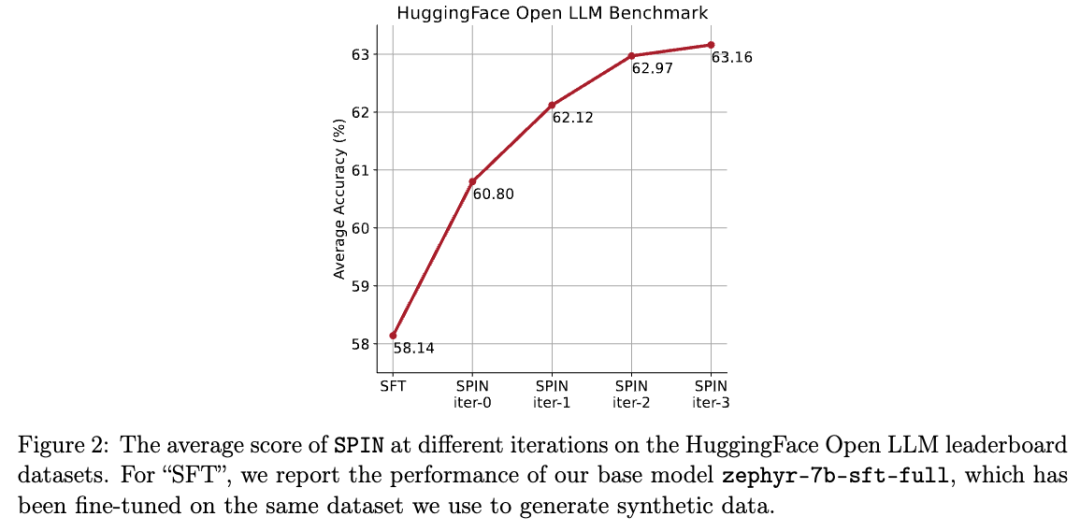
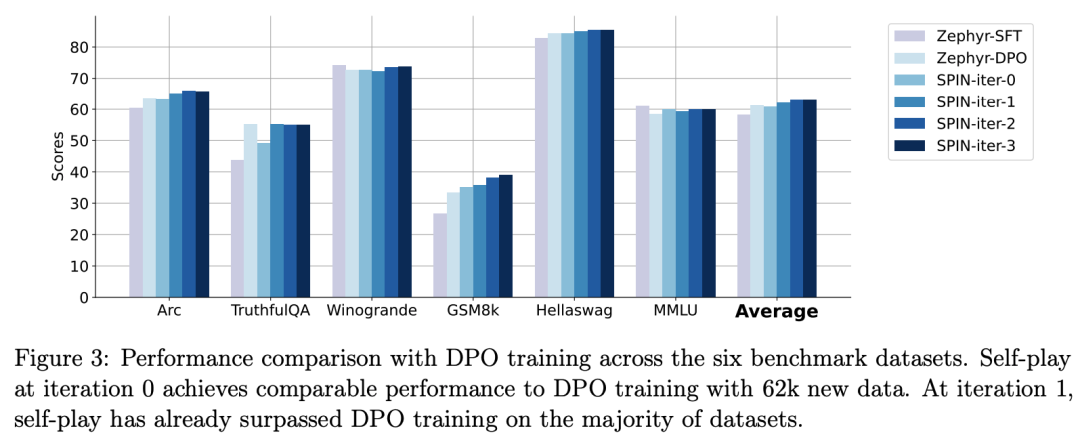
In der folgenden Abbildung verglichen die Forscher die Leistung des von SPIN fein abgestimmten Modells nach 0 bis 3 Iterationen mit dem Basismodell zephyr-7b-sft-full.
Forscher können beobachten, dass SPIN signifikante Ergebnisse bei der Verbesserung der Modellleistung zeigt, indem es den SFT-Datensatz weiter nutzt, auf dem das Basismodell vollständig verfeinert wurde.
In Iteration 0 wurde die Modellantwort aus zephyr-7b-sft-full generiert, und die Forscher beobachteten eine Gesamtverbesserung der durchschnittlichen Punktzahl um 2,66 %.
Diese Verbesserung macht sich besonders bei den Benchmarks TruthfulQA und GSM8k bemerkbar, mit Steigerungen von über 5 % bzw. 10 %.
In Iteration 1 verwendeten die Forscher das LLM-Modell aus Iteration 0, um eine neue Antwort für SPIN zu generieren, indem sie dem in Algorithmus 1 beschriebenen Prozess folgten.
Diese Iteration führt zu einer weiteren Verbesserung von durchschnittlich 1,32 %, was besonders bei den Arc Challenge- und TruthfulQA-Benchmarks von Bedeutung ist.
Nachfolgende Iterationen setzten den Trend schrittweiser Verbesserungen für verschiedene Aufgaben fort. Gleichzeitig ist die Verbesserung bei Iteration t+1 natürlich geringer ausgebildet.
 Die Forscher weisen darauf hin, dass DPO menschliche Eingaben oder Rückmeldungen von Hochsprachenmodellen erfordert, um Präferenzen zu ermitteln, sodass die Datengenerierung ein ziemlich kostspieliger Prozess ist.
Die Forscher weisen darauf hin, dass DPO menschliche Eingaben oder Rückmeldungen von Hochsprachenmodellen erfordert, um Präferenzen zu ermitteln, sodass die Datengenerierung ein ziemlich kostspieliger Prozess ist.
Im Gegensatz dazu benötigt der SPIN der Forscher nur das Ausgangsmodell selbst.
Darüber hinaus nutzt die Methode der Forscher im Gegensatz zu DPO, das neue Datenquellen erfordert, vollständig vorhandene SFT-Datensätze.
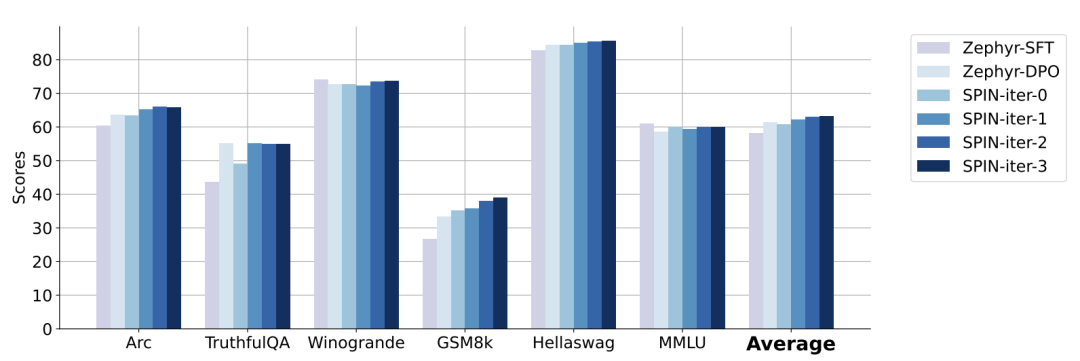
Die folgende Abbildung zeigt den Leistungsvergleich von SPIN mit dem DPO-Training bei den Iterationen 0 und 1 (unter Verwendung von 50.000 SFT-Daten).
 Bilder
Bilder
Die Forscher können beobachten, dass SPIN auf der Grundlage vorhandener SFT-Daten ab Iteration 1 beginnt, obwohl DPO mehr Daten aus neuen Quellen nutzt. SPIN übertrifft in der Rangliste sogar die Leistung von DPO und SPIN Benchmark-Tests übertreffen sogar die von DPO.
Referenz:
Das obige ist der detaillierte Inhalt vonUCLA-Chinesen schlagen einen neuen Selbstspielmechanismus vor! LLM trainiert sich selbst und der Effekt ist besser als der der GPT-4-Expertenanleitung.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 Schritt-für-Schritt-Anleitung zur lokalen Verwendung von Groq Llama 3 70B
Jun 10, 2024 am 09:16 AM
Schritt-für-Schritt-Anleitung zur lokalen Verwendung von Groq Llama 3 70B
Jun 10, 2024 am 09:16 AM
Übersetzer |. Bugatti Review |. Chonglou Dieser Artikel beschreibt, wie man die GroqLPU-Inferenz-Engine verwendet, um ultraschnelle Antworten in JanAI und VSCode zu generieren. Alle arbeiten daran, bessere große Sprachmodelle (LLMs) zu entwickeln, beispielsweise Groq, der sich auf die Infrastrukturseite der KI konzentriert. Die schnelle Reaktion dieser großen Modelle ist der Schlüssel, um sicherzustellen, dass diese großen Modelle schneller reagieren. In diesem Tutorial wird die GroqLPU-Parsing-Engine vorgestellt und erläutert, wie Sie mithilfe der API und JanAI lokal auf Ihrem Laptop darauf zugreifen können. In diesem Artikel wird es auch in VSCode integriert, um uns dabei zu helfen, Code zu generieren, Code umzugestalten, Dokumentation einzugeben und Testeinheiten zu generieren. In diesem Artikel erstellen wir kostenlos unseren eigenen Programmierassistenten für künstliche Intelligenz. Einführung in die GroqLPU-Inferenz-Engine Groq
 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 Caltech-Chinesen nutzen KI, um mathematische Beweise zu untergraben! Beschleunigen Sie 5-mal schockiert Tao Zhexuan, 80 % der mathematischen Schritte sind vollständig automatisiert
Apr 23, 2024 pm 03:01 PM
Caltech-Chinesen nutzen KI, um mathematische Beweise zu untergraben! Beschleunigen Sie 5-mal schockiert Tao Zhexuan, 80 % der mathematischen Schritte sind vollständig automatisiert
Apr 23, 2024 pm 03:01 PM
LeanCopilot, dieses formale Mathematikwerkzeug, das von vielen Mathematikern wie Terence Tao gelobt wurde, hat sich erneut weiterentwickelt? Soeben gab Caltech-Professorin Anima Anandkumar bekannt, dass das Team eine erweiterte Version des LeanCopilot-Papiers veröffentlicht und die Codebasis aktualisiert hat. Adresse des Bildpapiers: https://arxiv.org/pdf/2404.12534.pdf Die neuesten Experimente zeigen, dass dieses Copilot-Tool mehr als 80 % der mathematischen Beweisschritte automatisieren kann! Dieser Rekord ist 2,3-mal besser als der vorherige Basiswert von Aesop. Und wie zuvor ist es Open Source unter der MIT-Lizenz. Auf dem Bild ist er Song Peiyang, ein chinesischer Junge
 Wie wirkt sich LLM von „Mensch + RPA' bis „Mensch + generative KI + RPA' auf die RPA-Mensch-Computer-Interaktion aus?
Jun 05, 2023 pm 12:30 PM
Wie wirkt sich LLM von „Mensch + RPA' bis „Mensch + generative KI + RPA' auf die RPA-Mensch-Computer-Interaktion aus?
Jun 05, 2023 pm 12:30 PM
Bildquelle@visualchinesewen|Wang Jiwei Wie wirkt sich LLM von „Mensch + RPA“ auf „Mensch + generative KI + RPA“ auf die RPA-Mensch-Computer-Interaktion aus? Wie wirkt sich LLM aus einer anderen Perspektive auf RPA aus der Perspektive der Mensch-Computer-Interaktion aus? Wird RPA, das die Mensch-Computer-Interaktion in der Programmentwicklung und Prozessautomatisierung betrifft, nun auch durch LLM verändert? Wie wirkt sich LLM auf die Mensch-Computer-Interaktion aus? Wie verändert generative KI die RPA-Mensch-Computer-Interaktion? Erfahren Sie mehr darüber in einem Artikel: Die Ära der großen Modelle steht vor der Tür und die auf LLM basierende generative KI verändert die RPA-Mensch-Computer-Interaktion rasant. Die generative KI definiert die Mensch-Computer-Interaktion neu und LLM beeinflusst die Veränderungen in der RPA-Softwarearchitektur. Wenn man fragt, welchen Beitrag RPA zur Programmentwicklung und -automatisierung leistet, lautet eine der Antworten, dass es die Mensch-Computer-Interaktion (HCI, h
 Plaud bringt den tragbaren NotePin AI-Recorder für 169 US-Dollar auf den Markt
Aug 29, 2024 pm 02:37 PM
Plaud bringt den tragbaren NotePin AI-Recorder für 169 US-Dollar auf den Markt
Aug 29, 2024 pm 02:37 PM
Plaud, das Unternehmen hinter dem Plaud Note AI Voice Recorder (erhältlich bei Amazon für 159 US-Dollar), hat ein neues Produkt angekündigt. Das als NotePin bezeichnete Gerät wird als KI-Speicherkapsel beschrieben und ist wie der Humane AI Pin tragbar. Der NotePin ist
 Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Um mehr über AIGC zu erfahren, besuchen Sie bitte: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou unterscheidet sich von der traditionellen Fragendatenbank, die überall im Internet zu sehen ist erfordert einen Blick über den Tellerrand hinaus. Large Language Models (LLMs) gewinnen in den Bereichen Datenwissenschaft, generative künstliche Intelligenz (GenAI) und künstliche Intelligenz zunehmend an Bedeutung. Diese komplexen Algorithmen verbessern die menschlichen Fähigkeiten, treiben Effizienz und Innovation in vielen Branchen voran und werden zum Schlüssel für Unternehmen, um wettbewerbsfähig zu bleiben. LLM hat ein breites Anwendungsspektrum und kann in Bereichen wie der Verarbeitung natürlicher Sprache, der Textgenerierung, der Spracherkennung und Empfehlungssystemen eingesetzt werden. Durch das Lernen aus großen Datenmengen ist LLM in der Lage, Text zu generieren
 Der Ameca der zweiten Generation ist da! Er kann fließend mit dem Publikum kommunizieren, sein Gesichtsausdruck ist realistischer und er kann Dutzende Sprachen sprechen.
Mar 04, 2024 am 09:10 AM
Der Ameca der zweiten Generation ist da! Er kann fließend mit dem Publikum kommunizieren, sein Gesichtsausdruck ist realistischer und er kann Dutzende Sprachen sprechen.
Mar 04, 2024 am 09:10 AM
Der humanoide Roboter Ameca wurde auf die zweite Generation aufgerüstet! Kürzlich erschien auf der World Mobile Communications Conference MWC2024 erneut der weltweit fortschrittlichste Roboter Ameca. Rund um den Veranstaltungsort lockte Ameca zahlreiche Zuschauer an. Mit dem Segen von GPT-4 kann Ameca in Echtzeit auf verschiedene Probleme reagieren. „Lass uns tanzen.“ Auf die Frage, ob sie Gefühle habe, antwortete Ameca mit einer Reihe von Gesichtsausdrücken, die sehr lebensecht aussahen. Erst vor wenigen Tagen stellte EngineeredArts, das britische Robotikunternehmen hinter Ameca, die neuesten Entwicklungsergebnisse des Teams vor. Im Video verfügt der Roboter Ameca über visuelle Fähigkeiten und kann den gesamten Raum und bestimmte Objekte sehen und beschreiben. Das Erstaunlichste ist, dass sie es auch kann
 Nach 750.000 Runden Einzelkampf zwischen großen Modellen gewann GPT-4 die Meisterschaft und Llama 3 belegte den fünften Platz
Apr 23, 2024 pm 03:28 PM
Nach 750.000 Runden Einzelkampf zwischen großen Modellen gewann GPT-4 die Meisterschaft und Llama 3 belegte den fünften Platz
Apr 23, 2024 pm 03:28 PM
Zu Llama3 wurden neue Testergebnisse veröffentlicht – die große Modellbewertungs-Community LMSYS veröffentlichte eine große Modell-Rangliste, die Llama3 auf dem fünften Platz belegte und mit GPT-4 den ersten Platz in der englischen Kategorie belegte. Das Bild unterscheidet sich von anderen Benchmarks. Diese Liste basiert auf Einzelkämpfen zwischen Modellen, und die Bewerter aus dem gesamten Netzwerk machen ihre eigenen Vorschläge und Bewertungen. Am Ende belegte Llama3 den fünften Platz auf der Liste, gefolgt von drei verschiedenen Versionen von GPT-4 und Claude3 Super Cup Opus. In der englischen Einzelliste überholte Llama3 Claude und punktgleich mit GPT-4. Über dieses Ergebnis war Metas Chefwissenschaftler LeCun sehr erfreut und leitete den Tweet weiter
