
 Technologie-Peripheriegeräte
KI
Das erste 100 % Open-Source-Großmodell der Geschichte ist da! Rekordverdächtige Offenlegung von Code/Gewichten/Datensätzen/dem gesamten Trainingsprozess, AMD kann ihn trainieren
Technologie-Peripheriegeräte
KI
Das erste 100 % Open-Source-Großmodell der Geschichte ist da! Rekordverdächtige Offenlegung von Code/Gewichten/Datensätzen/dem gesamten Trainingsprozess, AMD kann ihn trainieren
Das erste 100 % Open-Source-Großmodell der Geschichte ist da! Rekordverdächtige Offenlegung von Code/Gewichten/Datensätzen/dem gesamten Trainingsprozess, AMD kann ihn trainieren

Sprachmodelle sind seit vielen Jahren der Kern der Technologie zur Verarbeitung natürlicher Sprache (NLP). Angesichts des enormen kommerziellen Werts des Modells wurden die technischen Details des fortschrittlichsten Modells nicht veröffentlicht.
Jetzt ist das wirklich komplett Open-Source-Großmodell da!
Forscher des Allen Institute for Artificial Intelligence, der University of Washington, der Yale University, der New York University und der Carnegie Mellon University haben kürzlich zusammengearbeitet, um eine wichtige Arbeit zu veröffentlichen, die für den Meilenstein der KI-Open-Source-Community von Bedeutung sein wird.
Sie haben fast alle Daten und Informationen im Prozess des Trainings eines großen Modells von Grund auf als Open Source bereitgestellt!
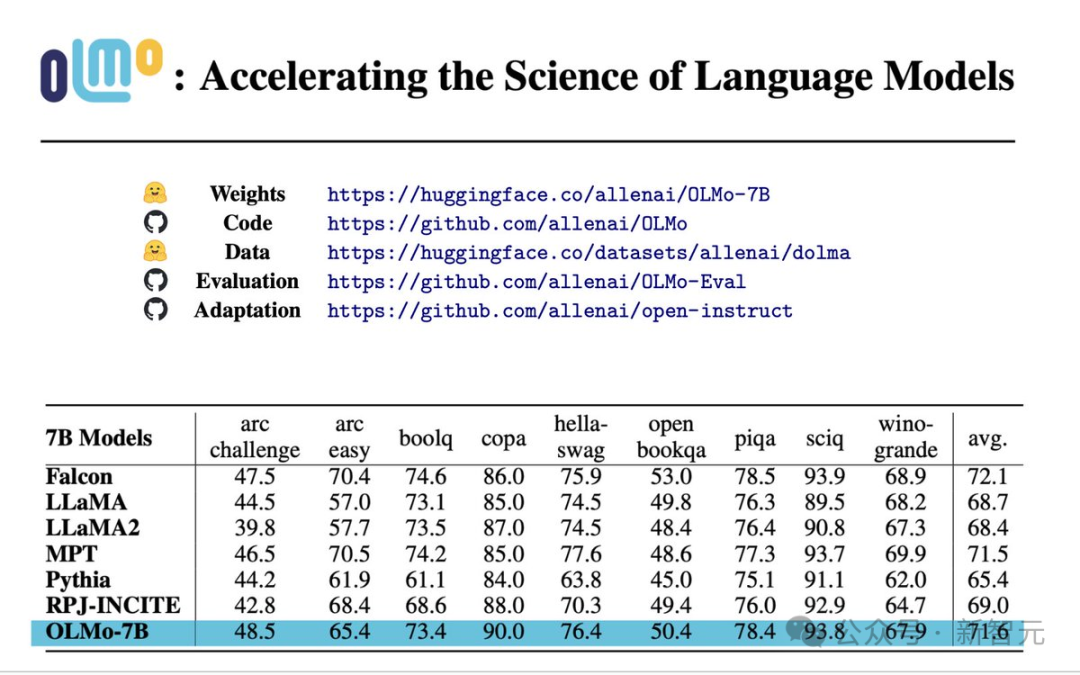
Papier: https://allenai.org/olmo/olmo-paper.pdf
Gewichte: https://huggingface.co/allenai/OLMo-7B
Code: https ://github.com/allenai/OLMo
Daten: https://huggingface.co/datasets/allenai/dolma
Bewertung: https://github.com/allenai/OLMo-Eval
Anpassung: https://github.com/allenai/open-instruct

Konkret handelt es sich um dieses vom Allen Artificial Intelligence Institute ins Leben gerufene Open Language Model (OLMo)-Experiment und eine Schulungsplattform, die eine vollständig offene Quelle bietet großes Modell sowie alle Daten und technischen Details im Zusammenhang mit dem Training und der Entwicklung dieses Modells –
Training und Modellierung: Es umfasst vollständige Modellgewichte, Trainingscode, Trainingsprotokolle, Ablationsstudien, Trainingsmetriken, und Inferenzcode.
Vortrainingskorpus: Ein vorab trainierter Open-Source-Korpus, der bis zu 3T-Tokens sowie den Code zum Generieren dieser Trainingsdaten enthält.
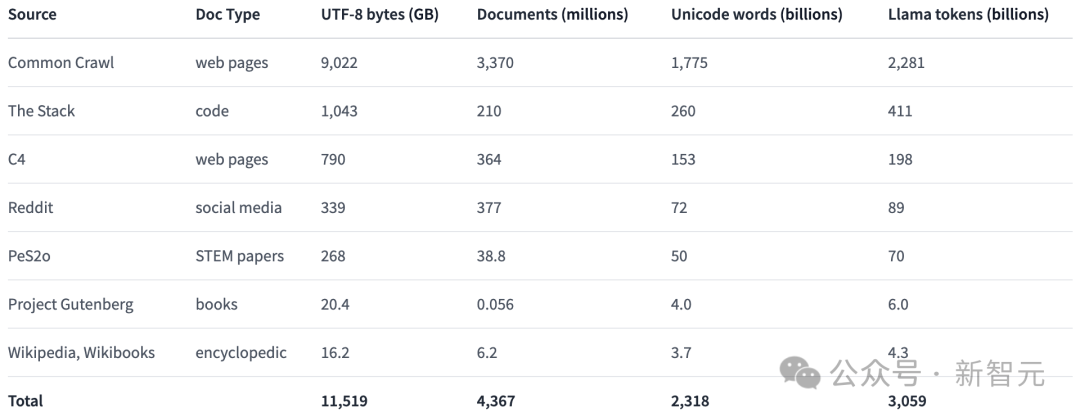
Modellparameter: OLMo-Framework bietet vier Modelle der Größe 7B unter verschiedenen Architekturen, Optimierern und Trainingshardwaresystemen sowie ein Modell der Größe 1B, alle Modelle sind mindestens 2T-Token. Das Training wurde durchgeführt .
Gleichzeitig werden auch der für die Modellinferenz verwendete Code, verschiedene Indikatoren des Trainingsprozesses und Trainingsprotokolle bereitgestellt.
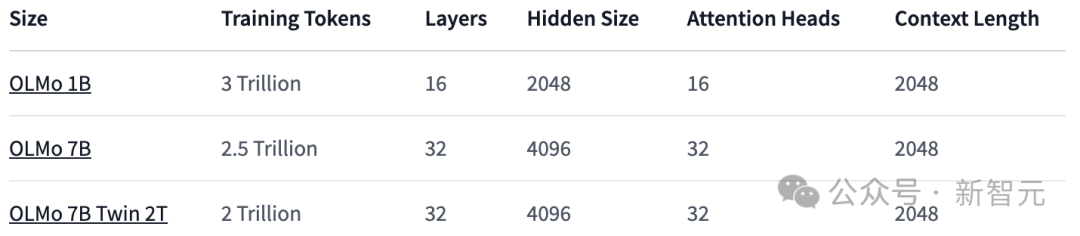
7B: OLMo 7B, OLMo 7B (nicht geglüht), OLMo 7B-2T, OLMo-7B-Twin-2T
Bewertungstools: hat die Bewertungstools während des Entwicklungsprozesses offengelegt Die Suite umfasst über 500 Prüfpunkte und Bewertungscode für jeweils 1.000 Schritte in jedem Modelltrainingsprozess.
Alle Daten sind für die Nutzung unter Apache 2.0 lizenziert (kostenlos für kommerzielle Nutzung).

Solch gründliches Open Source scheint ein Muster für die Open-Source-Community zu sein – wenn Sie nicht wie ich Open Source sind, sagen Sie in Zukunft nicht, dass Sie ein Open-Source-Modell sind.
Leistungsbewertung
Aus den Ergebnissen der Kernbewertung geht hervor, dass OLMo-7B etwas besser ist als ähnliche Open-Source-Modelle.
Unter den ersten 9 Bewertungen landete OLMo-7B in 8 davon unter den ersten drei und 2 davon übertrafen alle anderen Modelle.
OLMo-7B übertrifft Llama 2 bei vielen Generierungsaufgaben oder Leseverständnisaufgaben (z. B. truefulQA), schneidet jedoch bei einigen beliebten Frage- und Antwortaufgaben (z. B. MMLU oder Big-bench Hard) schlechter ab.
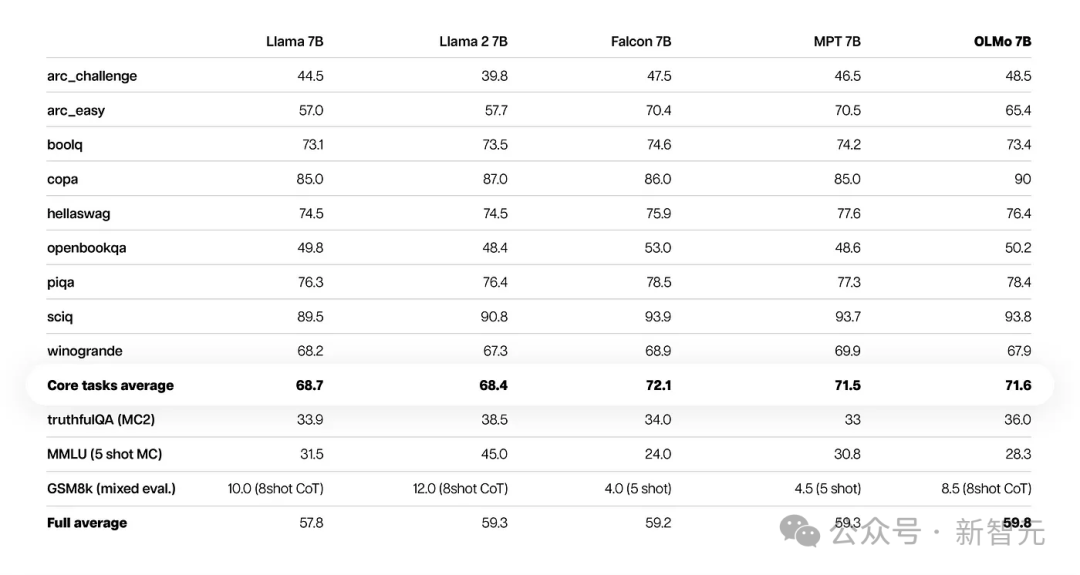
Die ersten 9 Aufgaben sind die internen Bewertungskriterien der Forscher für das vorab trainierte Modell, während die folgenden drei Aufgaben hinzugefügt wurden, um das HuggingFace Open LLM-Ranking zu verbessern
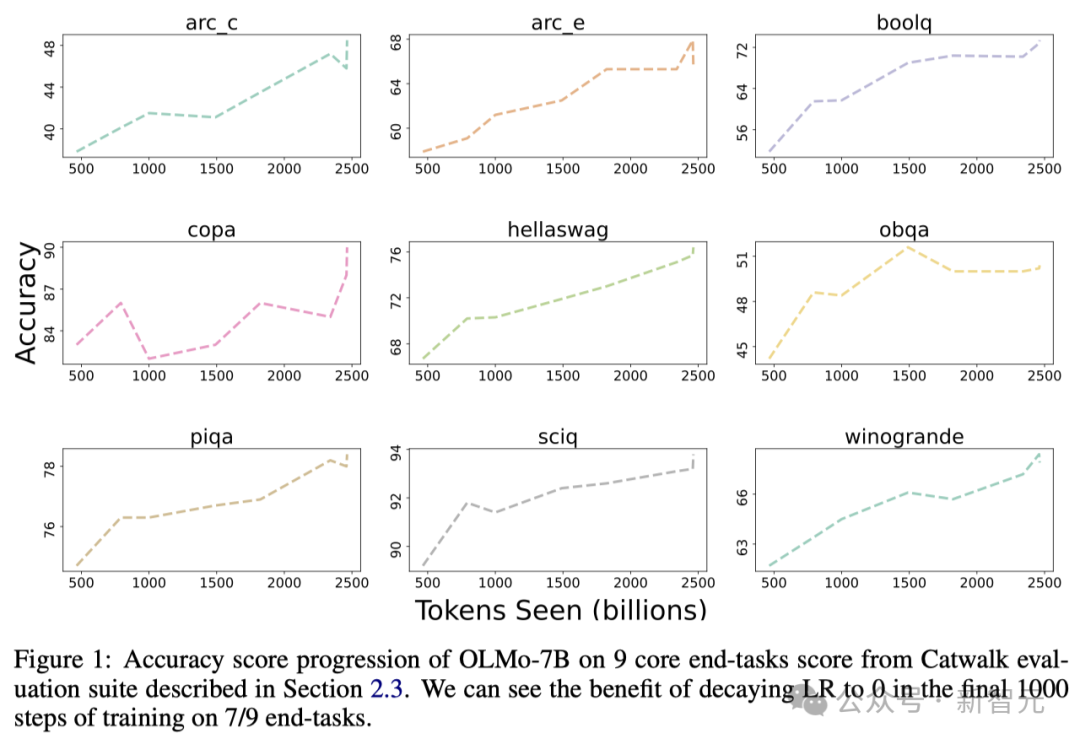
Die folgende Abbildung zeigt die Genauigkeit des 9-Kernaufgaben-Trends .
Mit Ausnahme von OBQA zeigt die Genauigkeit fast aller Aufgaben einen Aufwärtstrend, da OLMo-7B mehr Daten für das Training erhält.
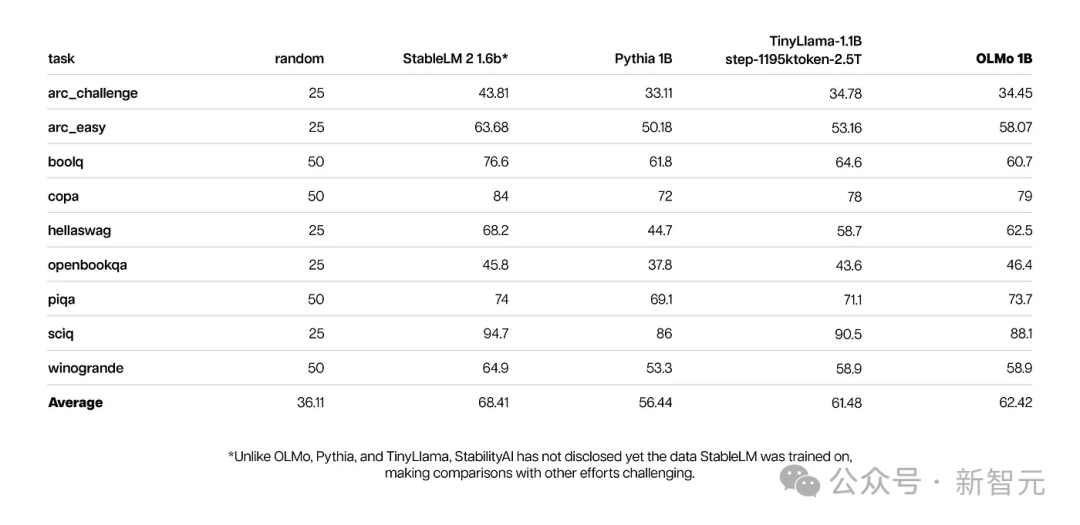
Gleichzeitig zeigen die Kernbewertungsergebnisse von OLMo 1B und seinen ähnlichen Modellen, dass OLMo auf dem gleichen Niveau liegt wie sie.
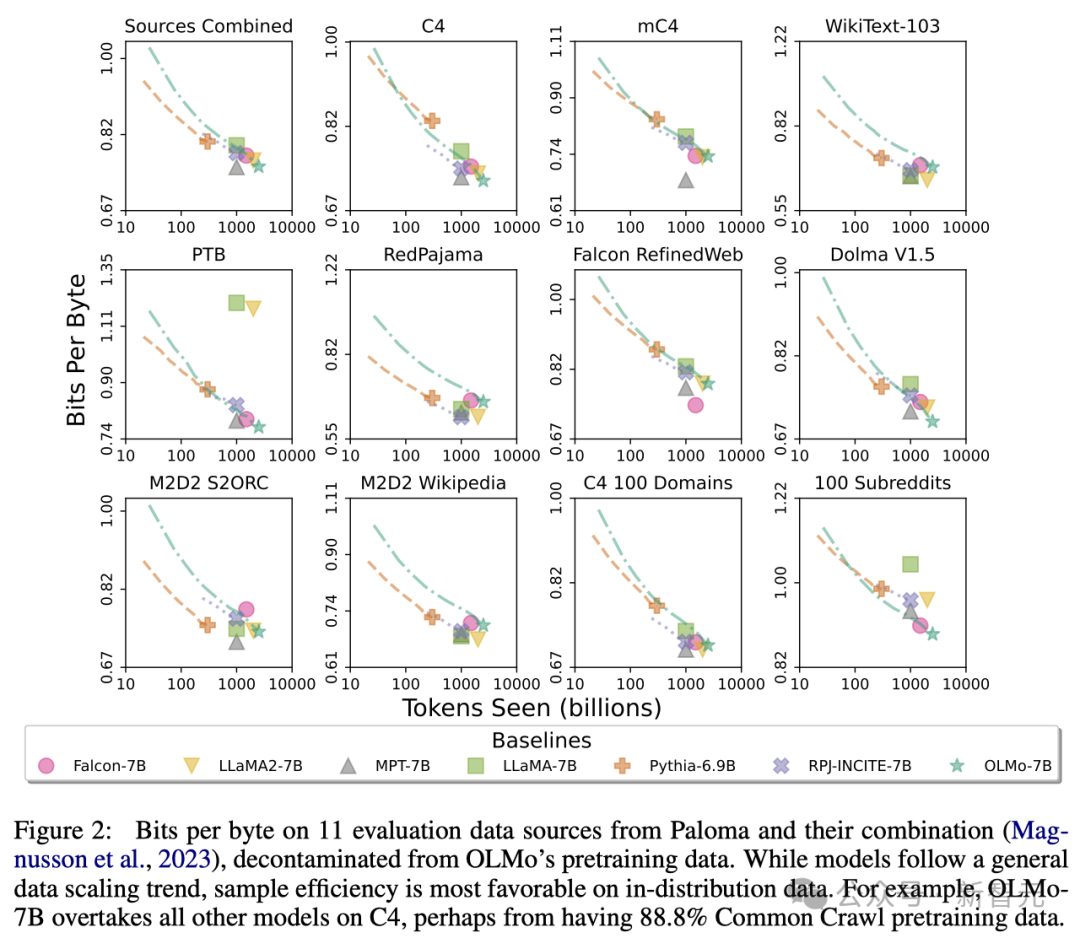
Anhand des Paloma des Allen AI Institute (ein Benchmark) und verfügbarer Prüfpunkte analysierten die Forscher die Beziehung zwischen der Fähigkeit des Modells, Sprache vorherzusagen, und der Beziehung zwischen Modellgrößenfaktoren (z. B. der Anzahl der trainierten Token).
Man erkennt, dass der OLMo-7B hinsichtlich der Leistung mit Mainstream-Modellen mithalten kann. Dabei gilt: Je geringer die Anzahl der Bits pro Byte (Bits pro Byte), desto besser.
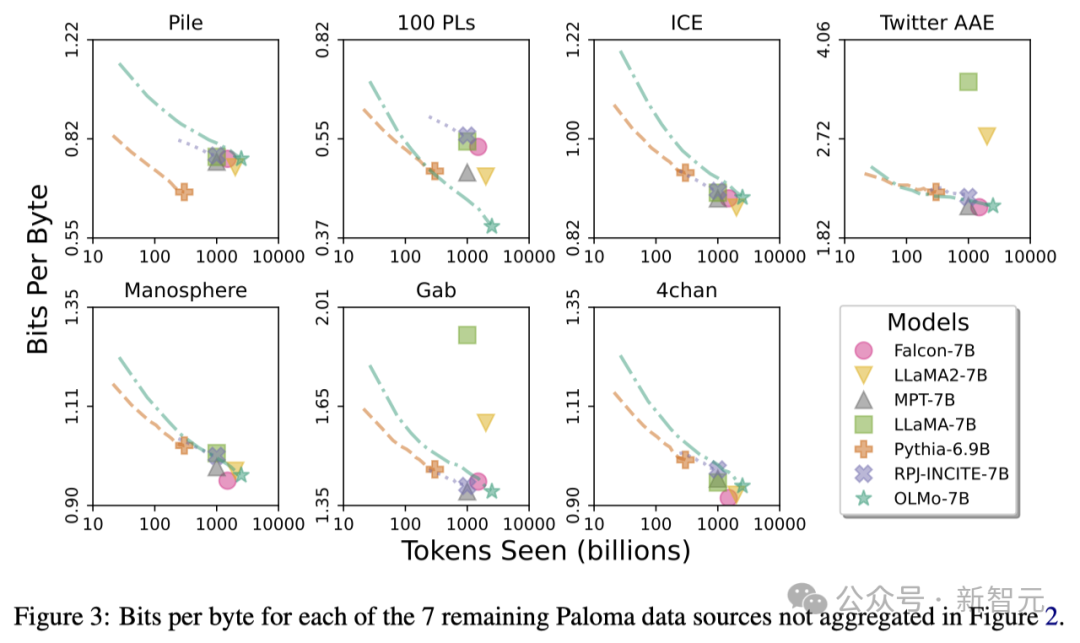
Durch diese Analysen stellten die Forscher fest, dass die Effizienz des Modells bei der Verarbeitung verschiedener Datenquellen stark variiert, was hauptsächlich von der Ähnlichkeit zwischen den Modelltrainingsdaten und den Bewertungsdaten abhängt.
Insbesondere OLMo-7B schneidet gut bei Datenquellen ab, die hauptsächlich auf Common Crawl basieren (wie C4).
Allerdings ist OLMo-7B bei Datenquellen, die wenig mit Web-Scraping-Text zu tun haben, wie WikiText-103, M2D2 S2ORC und M2D2 Wikipedia, weniger effizient als andere Modelle.
Die Bewertung von RedPajama spiegelt ebenfalls einen ähnlichen Trend wider, möglicherweise weil nur zwei seiner sieben Felder von Common Crawl abgeleitet sind und Paloma jedem Feld in jeder Datenquelle das gleiche Gewicht beimisst.
Angesichts der Tatsache, dass kuratierte Datenquellen wie Wikipedia und arXiv-Artikel weitaus weniger heterogene Daten liefern als Web-Scraping-Texte, wird die Aufrechterhaltung einer hohen Effizienz über diese Sprachverteilungen noch wichtiger, da die Datensätze vor dem Training weiter wachsen.
OLMo-Architektur
In Bezug auf die Modellarchitektur basiert das Team auf der reinen Decoder-Transformer-Architektur, übernimmt die von PaLM und Llama verwendete SwiGLU-Aktivierungsfunktion und führt die Rotationspositionseinbettungstechnologie (RoPE) ein. und verbesserter Byte Pair Encoding (BPE)-basierter Tokenizer von GPT-NeoX-20B, um persönlich identifizierbare Informationen in der Modellausgabe zu reduzieren.
Um die Stabilität des Modells sicherzustellen, verwendeten die Forscher außerdem keine Bias-Terme (dies ist dasselbe wie bei PaLM).
Wie in der Tabelle unten gezeigt, haben die Forscher zwei Versionen veröffentlicht, 1B und 7B, und planen außerdem, bald eine 65B-Version auf den Markt zu bringen.
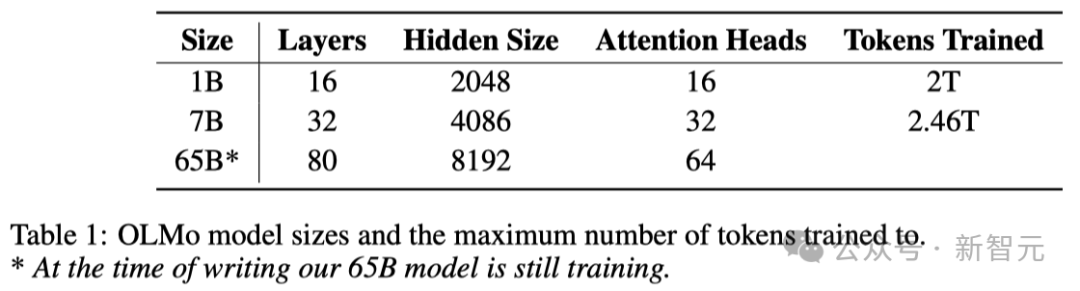
Die folgende Tabelle bietet einen detaillierten Vergleich der Leistung der 7B-Architektur mit diesen anderen Modellen in ähnlichen Maßstäben.
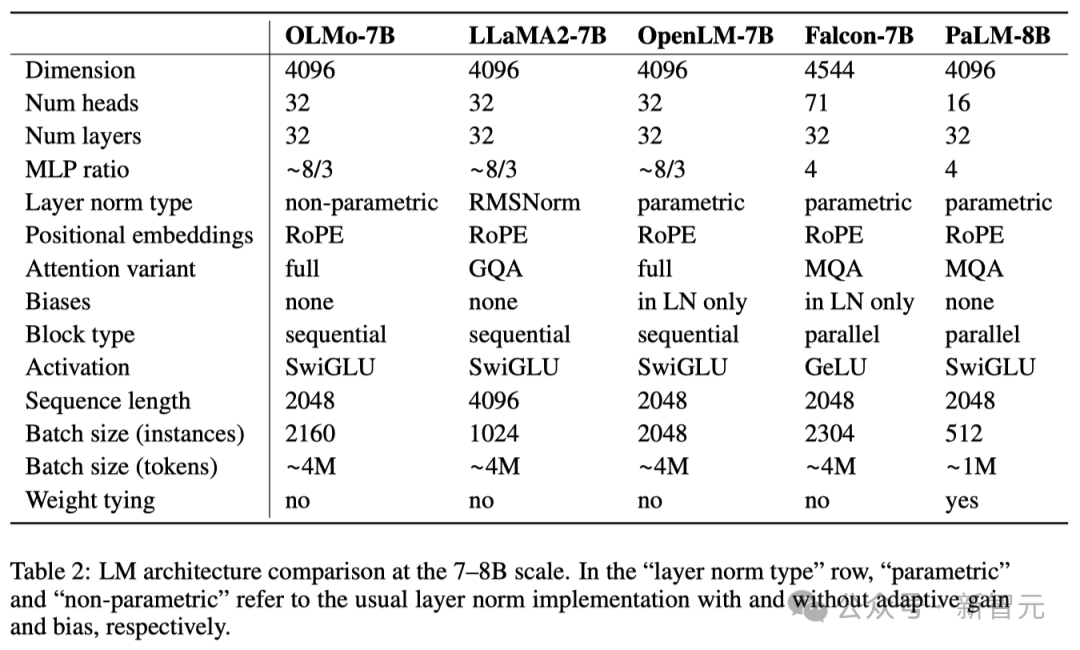
Datensatz vor dem Training: Dolma
Obwohl Forscher einige Fortschritte bei der Erlangung von Modellparametern gemacht haben, reicht der aktuelle Grad der Offenheit von Datensätzen vor dem Training in der Open-Source-Community bei weitem nicht aus.
Vorherige Daten vor dem Training werden bei der Open-Source-Version des Modells oft nicht veröffentlicht (ganz zu schweigen vom Closed-Source-Modell).
Und in der Dokumentation dieser Daten mangelt es oft an ausreichenden Details, aber diese Details sind entscheidend, um die Forschung zu reproduzieren oder die damit verbundene Arbeit vollständig zu verstehen.
Diese Situation erschwert die Erforschung von Sprachmodellen – beispielsweise das Verständnis, wie sich Trainingsdaten auf die Modellfähigkeiten und deren Grenzen auswirken.
Um die offene Forschung im Bereich des Sprachmodell-Pre-Trainings zu fördern, haben Forscher den Pre-Training-Datensatz Dolma erstellt und veröffentlicht.
Dies ist ein vielfältiger Korpus aus mehreren Quellen, der 3 Billionen Token enthält, die aus 7 verschiedenen Datenquellen stammen.
Einerseits sind diese Datenquellen im Vortraining großer Sprachmodelle üblich, andererseits sind sie auch für die breite Öffentlichkeit zugänglich.
Die folgende Tabelle gibt einen Überblick über das Datenvolumen aus verschiedenen Datenquellen.
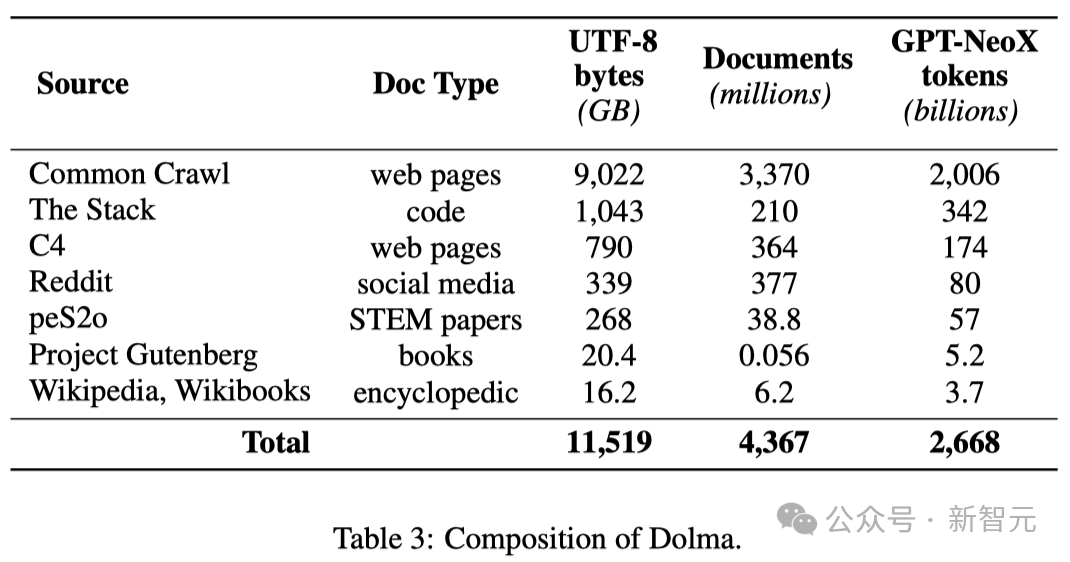
Der Konstruktionsprozess von Dolma umfasst sechs Schritte: Sprachfilterung, Qualitätsfilterung, Inhaltsfilterung, Deduplizierung, Mischen mehrerer Quellen und Tokenisierung.
Während des Prozesses der Zusammenstellung und endgültigen Veröffentlichung von Dolma stellten die Forscher sicher, dass die Dokumente jeder Datenquelle unabhängig blieben.
Sie haben auch eine Reihe effizienter Tools zur Datenorganisation als Open-Source-Lösung bereitgestellt, die dabei helfen können, Dolma weiter zu untersuchen, Ergebnisse zu replizieren und die Organisation des Korpus vor dem Training zu vereinfachen.
Darüber hinaus haben Forscher auch das WIMBD-Tool als Open-Source-Lösung bereitgestellt, um die Analyse von Datensätzen zu erleichtern. „Netzwerkdatenverarbeitungsprozess“ Das FS DP-Framework und die ZeRO-Optimierungsstrategien kommen zum Trainieren des Modells . Dieser Ansatz reduziert effektiv die Speichernutzung, indem die Gewichtungen des Modells und die entsprechenden Optimierungszustände auf mehrere GPUs aufgeteilt werden.
 Bei der Verarbeitung von Modellen mit einer Größe von bis zu 7B ermöglicht diese Technologie Forschern die Verarbeitung von Mikrobatchgrößen von 4096 Token pro GPU für ein effizienteres Training.
Bei der Verarbeitung von Modellen mit einer Größe von bis zu 7B ermöglicht diese Technologie Forschern die Verarbeitung von Mikrobatchgrößen von 4096 Token pro GPU für ein effizienteres Training.
Für die Modelle OLMo-1B und 7B legten die Forscher eine globale Stapelgröße von etwa 4 Millionen Token fest (2048 Dateninstanzen, wobei jede Instanz eine Sequenz von 2048 Token enthält).

Um das Modelltraining zu beschleunigen, verwendeten die Forscher eine Mixed-Precision-Trainingstechnologie, die durch die interne Konfiguration von FSDP und das Verstärkermodul von PyTorch implementiert wird.
Diese Methode wurde speziell entwickelt, um sicherzustellen, dass einige wichtige Berechnungsschritte (z. B. die Softmax-Funktion) immer mit höchster Genauigkeit ausgeführt werden, um die Stabilität des Trainingsprozesses sicherzustellen.
Mittlerweile verwenden die meisten anderen Berechnungen ein Format mit halber Genauigkeit namens bfloat16, um den Speicherverbrauch zu reduzieren und die Recheneffizienz zu erhöhen.
In bestimmten Konfigurationen werden Modellgewichte und Optimiererstatus mit maximaler Genauigkeit auf jeder GPU gespeichert.
Nur wenn eine Vorwärts- und Rückwärtsausbreitung des Modells durchgeführt wird, also die Ausgabe des Modells berechnet und die Gewichte aktualisiert werden, werden die Gewichte in jedem Transformer-Modul vorübergehend in das bfloat16-Format konvertiert.
Wenn außerdem Gradientenaktualisierungen zwischen GPUs synchronisiert werden, werden diese auch mit höchster Genauigkeit durchgeführt, um die Trainingsqualität sicherzustellen. 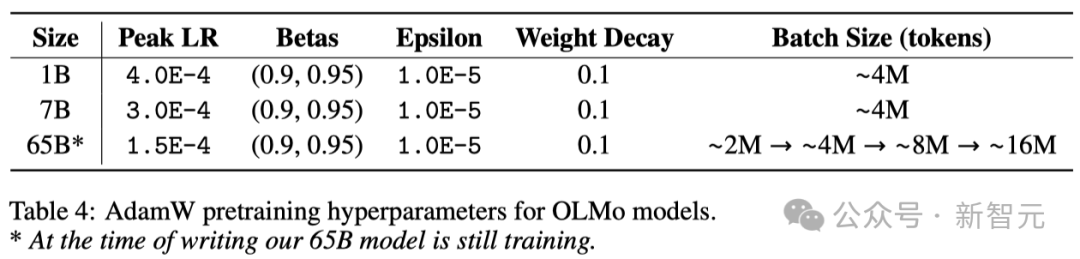
Optimierer
Die Forscher verwendeten den AdamW-Optimierer, um die Modellparameter anzupassen.
Unabhängig von der Größe des Modells erhöhen die Forscher die Lernrate schrittweise innerhalb der ersten 5000 Schritte des Trainings (ungefähr die Verarbeitung von 21 Milliarden Token). Dieser Prozess wird als Aufwärmen der Lernrate bezeichnet.
Nach Abschluss des Aufwärmens nimmt die Lernrate schrittweise linear ab, bis sie auf ein Zehntel der maximalen Lernrate abfällt.
Darüber hinaus werden die Forscher auch die Gradienten der Modellparameter beschneiden, um sicherzustellen, dass ihre gesamte L1-Norm 1,0 nicht überschreitet.
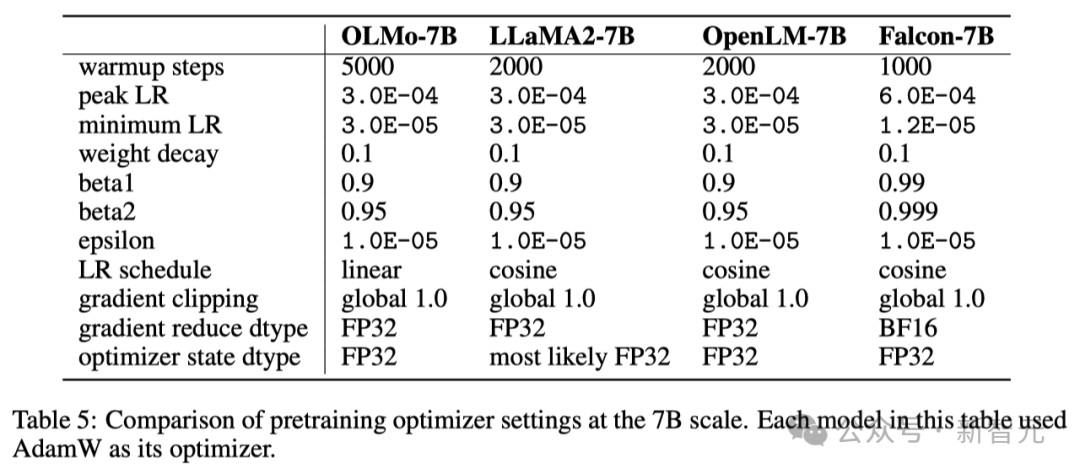
In der folgenden Tabelle vergleichen die Forscher ihre Optimiererkonfiguration im 7B-Modellmaßstab mit anderen aktuellen großen Sprachmodellen, die den AdamW-Optimierer verwenden.
Datensatz
Die Forscher verwendeten eine 2T-Token-Probe im offenen Datensatz Dolma, um ihren Trainingsdatensatz zu erstellen.
Die Forscher verbanden die Token jedes Dokuments, fügten am Ende jedes Dokuments einen speziellen EOS-Token hinzu und teilten diese Token dann in Gruppen von 2048 auf, um Trainingsbeispiele zu bilden.
Diese Trainingsproben werden bei jedem Training auf die gleiche Weise zufällig gemischt. Die Forscher stellen außerdem Tools bereit, mit denen jeder die genaue Datenreihenfolge und Zusammensetzung jedes Trainingsstapels wiederherstellen kann.
Alle Modelle, die die Forscher veröffentlicht haben, wurden mindestens eine Runde lang trainiert (2T-Token). Einige dieser Modelle wurden zusätzlich trainiert, indem die Daten einer zweiten Trainingsrunde unterzogen wurden, jedoch mit einer anderen zufälligen Mischreihenfolge.
Laut früheren Untersuchungen sind die Auswirkungen der Wiederverwendung einer kleinen Datenmenge auf diese Weise minimal.
Sowohl NVIDIA als auch AMD wollen JA!
Um sicherzustellen, dass die Codebasis sowohl auf NVIDIA- als auch auf AMD-GPUs effizient ausgeführt werden kann, wählten die Forscher zwei verschiedene Cluster für Modelltrainingstests aus:
Mit dem LUMI-Supercomputer setzten die Forscher bis zu 256 ein Knoten, jeder Knoten ist mit 4 AMD MI250X GPUs ausgestattet, jede GPU verfügt über 128 GB Speicher und eine Datenübertragungsrate von 800 Gbit/s.
Mit der Unterstützung von MosaicML (Databricks) verwendeten die Forscher 27 Knoten, jeder Knoten ist mit 8 NVIDIA A100-GPUs ausgestattet, jede GPU verfügt über 40 GB Speicher und eine Datenübertragungsrate von 800 Gbit/s.
Obwohl die Forscher die Batch-Größe optimierten, um die Trainingseffizienz zu verbessern, gab es nach Abschluss der Evaluierung der 2T-Tokens fast keinen Unterschied in der Leistung der beiden Cluster.
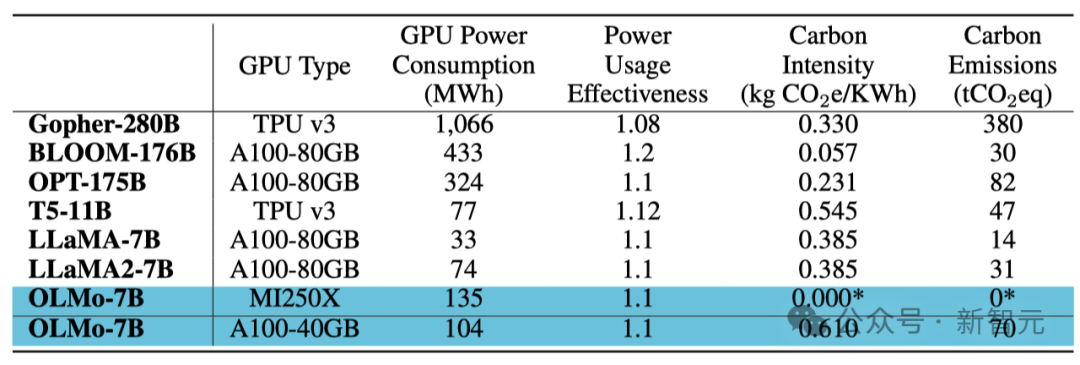
Trainingsenergieverbrauch
Zusammenfassung
Im Gegensatz zu den meisten früheren Modellen, die nur Modellgewichte und Inferenzcode bereitstellen, haben die Forscher den gesamten Inhalt von OLMo, einschließlich Trainingsdaten, Trainings- und Bewertungscode, als Open Source bereitgestellt. Sowie Trainingsprotokolle, Versuchsergebnisse, wichtige Erkenntnisse, Gewichts- und Bias-Aufzeichnungen usw.
Darüber hinaus untersucht das Team, wie OLMo durch Instruktionsoptimierung und verschiedene Arten des Reinforcement Learning (RLHF) verbessert werden kann. Diese fein abgestimmten Codes, Daten und fein abgestimmten Modelle werden ebenfalls Open Source sein.
Forscher sind bestrebt, OLMo und sein Framework weiterhin zu unterstützen und weiterzuentwickeln, die Entwicklung offener Sprachmodelle (LM) zu fördern und die Entwicklung der offenen Forschungsgemeinschaft zu unterstützen. Zu diesem Zweck planen die Forscher die Einführung weiterer Modelle unterschiedlicher Maßstäbe, mehrerer Modalitäten, Datensätze, Sicherheitsmaßnahmen und Bewertungsmethoden, um die OLMo-Familie zu bereichern.
Sie hoffen, die Macht der Open-Source-Forschungsgemeinschaft zu stärken und durch weiterhin gründliche Open-Source-Arbeit in Zukunft eine neue Innovationswelle auszulösen.
Teamvorstellung
Yizhong Wang (王义中)

Yizhong Wang ist Doktorand an der Paul G. Allen School of Computer Science and Engineering der University of Washington, betreut von Hannaneh Hajishirzi und Noah Schmied. Gleichzeitig ist er Teilzeit-Forschungspraktikant am Allen Institute for Artificial Intelligence.
Zuvor hatte er Praktika bei Meta AI, Microsoft Research und Baidu NLP absolviert. Zuvor erhielt er einen Master-Abschluss von der Peking-Universität und einen Bachelor-Abschluss von der Shanghai Jiao Tong University.
Seine Forschungsrichtungen sind Verarbeitung natürlicher Sprache, maschinelles Lernen und Large Language Model (LLM).
- Anpassungsfähigkeit von LLM: Wie lassen sich Modelle, die Anweisungen befolgen können, effizienter erstellen und bewerten? Welche Faktoren sollten wir bei der Feinabstimmung dieser Modelle berücksichtigen und wie wirken sie sich auf die Generalisierbarkeit des Modells aus? Welche Arten der Aufsicht sind effektiv und skalierbar?
- Kontinuierliches Lernen für LLM: Wo verläuft die Grenze zwischen Vorschulung und Feinabstimmung? Welche Architekturen und Lernstrategien können es LLM ermöglichen, sich nach der Vorschulung weiterzuentwickeln? Wie interagiert vorhandenes Wissen innerhalb des Modells mit neu erlerntem Wissen?
- Anwendung großer synthetischer Daten: Welchen Einfluss haben diese Daten heute auf unsere Modellentwicklung und sogar auf das gesamte Internet und die Gesellschaft, wenn generative Modelle schnell Daten generieren? Wie stellen wir sicher, dass wir vielfältige und qualitativ hochwertige Daten in großem Maßstab generieren können? Können wir diese Daten von menschengenerierten Daten unterscheiden?
Yuling Gu

Yuling Gu ist Forscher im Aristo-Team am Allen Institute for Artificial Intelligence (AI2).
Im Jahr 2020 erhielt sie ihren Bachelor-Abschluss von der New York University (NYU). Zusätzlich zu ihrem Informatik-Hauptfach belegte sie als Nebenfach das interdisziplinäre Hauptfach „Sprache und Geist“, das Linguistik, Psychologie und Philosophie vereint. Anschließend erwarb sie einen Master-Abschluss an der University of Washington (UW).
Sie ist voller Begeisterung für die Integration und Anwendung von maschineller Lerntechnologie und kognitionswissenschaftlicher Theorie.
Das obige ist der detaillierte Inhalt vonDas erste 100 % Open-Source-Großmodell der Geschichte ist da! Rekordverdächtige Offenlegung von Code/Gewichten/Datensätzen/dem gesamten Trainingsprozess, AMD kann ihn trainieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1381
1381
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Stehen Sie vor einer Verzögerung oder einer langsamen mobilen Datenverbindung auf dem iPhone? Normalerweise hängt die Stärke des Mobilfunk-Internets auf Ihrem Telefon von mehreren Faktoren ab, wie z. B. der Region, dem Mobilfunknetztyp, dem Roaming-Typ usw. Es gibt einige Dinge, die Sie tun können, um eine schnellere und zuverlässigere Mobilfunk-Internetverbindung zu erhalten. Fix 1 – Neustart des iPhone erzwingen Manchmal werden durch einen erzwungenen Neustart Ihres Geräts viele Dinge zurückgesetzt, einschließlich der Mobilfunkverbindung. Schritt 1 – Drücken Sie einfach einmal die Lauter-Taste und lassen Sie sie los. Drücken Sie anschließend die Leiser-Taste und lassen Sie sie wieder los. Schritt 2 – Der nächste Teil des Prozesses besteht darin, die Taste auf der rechten Seite gedrückt zu halten. Lassen Sie das iPhone den Neustart abschließen. Aktivieren Sie Mobilfunkdaten und überprüfen Sie die Netzwerkgeschwindigkeit. Überprüfen Sie es erneut. Fix 2 – Datenmodus ändern 5G bietet zwar bessere Netzwerkgeschwindigkeiten, funktioniert jedoch besser, wenn das Signal schwächer ist
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
 Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Kürzlich wurde die Militärwelt von der Nachricht überwältigt: US-Militärkampfflugzeuge können jetzt mithilfe von KI vollautomatische Luftkämpfe absolvieren. Ja, erst kürzlich wurde der KI-Kampfjet des US-Militärs zum ersten Mal der Öffentlichkeit zugänglich gemacht und sein Geheimnis gelüftet. Der vollständige Name dieses Jägers lautet „Variable Stability Simulator Test Aircraft“ (VISTA). Er wurde vom Minister der US-Luftwaffe persönlich geflogen, um einen Eins-gegen-eins-Luftkampf zu simulieren. Am 2. Mai startete US-Luftwaffenminister Frank Kendall mit einer X-62AVISTA auf der Edwards Air Force Base. Beachten Sie, dass während des einstündigen Fluges alle Flugaktionen autonom von der KI durchgeführt wurden! Kendall sagte: „In den letzten Jahrzehnten haben wir über das unbegrenzte Potenzial des autonomen Luft-Luft-Kampfes nachgedacht, aber es schien immer unerreichbar.“ Nun jedoch,
