

Kann es ein universelles Graphenmodell geben –
, das Toxizität basierend auf der Molekülstruktur vorhersagen und Freunde in sozialen Netzwerken empfehlen kann?
Oder können Sie nicht nur die Zitierungen der Arbeiten verschiedener Autoren vorhersagen, sondern auch den menschlichen Alterungsmechanismus im Gennetzwerk entdecken?
Sag mir nicht, das „One for All(OFA)“-Framework, das von ICLR 2024 als Spotlight akzeptiert wurde, hat diese „Essenz“ verwirklicht.
Diese Forschung wurde gemeinsam von Forschern wie dem Team von Professor Chen Yixin an der Washington University in St. Louis, Zhang Muhan von der Peking-Universität und Tao Dacheng vom JD Research Institute vorgeschlagen.
Als erstes allgemeines Framework im Graphfeld ermöglicht OFA das Training eines einzelnen GNN-Modells, um die Klassifizierungsaufgaben jedes Datensatzes, jedes Aufgabentyps und jeder Szene im Graphfeld zu lösen.

Wie man es konkret umsetzt, das Folgende ist der Beitrag des Autors.
Der Entwurf eines universellen Grundmodells zur Lösung einer Vielzahl von Aufgaben ist ein langfristiges Ziel im Bereich der künstlichen Intelligenz. In den letzten Jahren haben sich grundlegende große Sprachmodelle (LLMs) bei der Verarbeitung natürlichsprachlicher Aufgaben gut bewährt.
Obwohl grafische neuronale Netze (GNNs) im Bereich der Diagramme eine gute Leistung bei verschiedenen Diagrammdaten aufweisen, gibt es immer noch einen Weg, ein grundlegendes Diagrammmodell zu entwerfen und zu trainieren, das mehrere Diagrammaufgaben gleichzeitig bewältigen kann vorwärts riesig.
Im Vergleich zum Bereich der natürlichen Sprache ist der Entwurf allgemeiner Modelle im Graphenbereich mit vielen einzigartigen Schwierigkeiten konfrontiert.
Erstens haben unterschiedliche Diagrammdaten im Gegensatz zur natürlichen Sprache völlig unterschiedliche Attribute und Verteilungen.
Ein Moleküldiagramm beschreibt beispielsweise, wie mehrere Atome durch unterschiedliche Kraftverhältnisse unterschiedliche chemische Substanzen bilden. Das Citation-Relationship-Diagramm beschreibt das Netzwerk gegenseitiger Zitate zwischen Artikeln.
Diese verschiedenen Diagrammdaten lassen sich nur schwer in einem Trainingsrahmen vereinen.
Zweitens umfassen Diagrammaufgaben im Gegensatz zu allen Aufgaben in LLMs, die in einheitliche Kontextgenerierungsaufgaben umgewandelt werden können, eine Vielzahl von Unteraufgaben, wie Knotenaufgaben, Verknüpfungsaufgaben, Volldiagrammaufgaben usw.
Unterschiedliche Teilaufgaben erfordern in der Regel unterschiedliche Aufgabendarstellungen und unterschiedliche Diagrammmodelle.
Schließlich ist der Erfolg großer Sprachmodelle untrennbar mit dem Kontextlernen (In-Kontext-Lernen) verbunden, das durch prompte Paradigmen erreicht wird.
In großen Sprachmodellen ist das Prompt-Paradigma normalerweise eine lesbare Textbeschreibung der nachgelagerten Aufgabe.
Aber für Diagrammdaten, die unstrukturiert und schwer in Worten zu beschreiben sind, ist es immer noch ein ungelöstes Rätsel, wie man ein effektives Diagramm-Prompt-Paradigma entwirft, um kontextbezogenes Lernen zu erreichen.
Die folgende Abbildung zeigt den Gesamtrahmen von OFA:
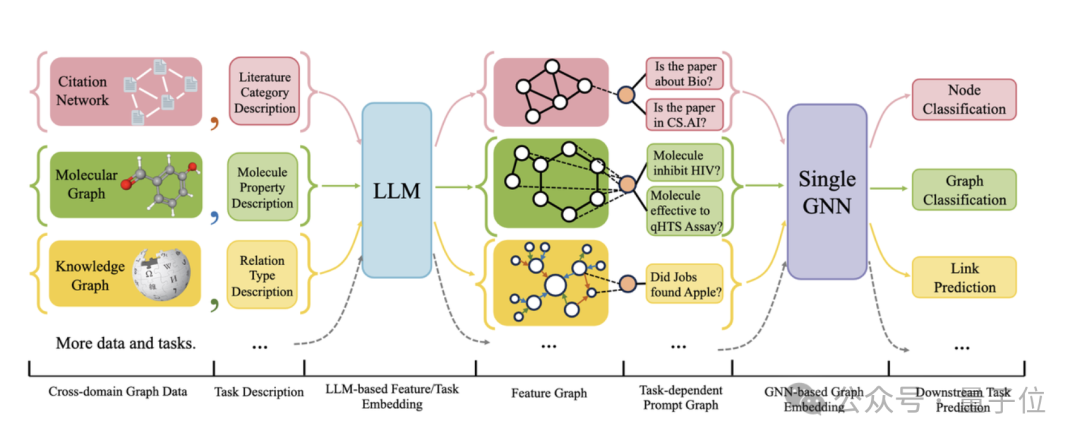
Konkret löst das OFA-Team die drei oben genannten Hauptprobleme durch cleveres Design.
Für das Problem unterschiedlicher Diagrammdatenattribute und -verteilungen vereinheitlicht OFA alle Diagrammdaten, indem es das Konzept des Text-Attributed Graph (TAGs) vorschlägt . Mithilfe von Textdiagrammen beschreibt OFA die Knoteninformationen und Kanteninformationen in allen Diagrammdaten mithilfe eines einheitlichen Rahmens in natürlicher Sprache, wie in der folgenden Abbildung dargestellt:


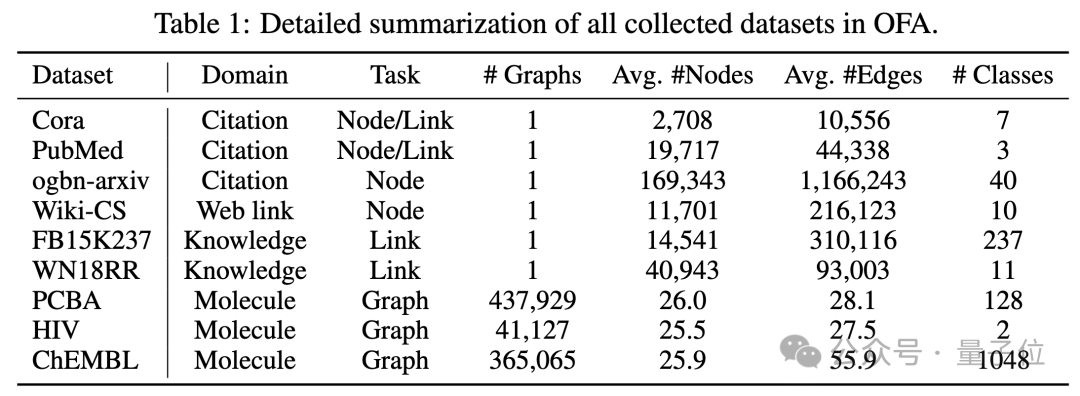
(NOI) Untergraph und NOI-Eingabeaufforderungsknoten (NOI-Eingabeaufforderungsknoten) , um verschiedene Unteraufgabentypen im Diagrammfeld zu vereinheitlichen. Hier repräsentiert NOI eine Reihe von Zielknoten, die an der entsprechenden Aufgabe teilnehmen.
Zum Beispiel bezieht sich der NOI in der Knotenvorhersageaufgabe auf einen einzelnen Knoten, der vorhergesagt werden muss, während der NOI in der Verbindungsaufgabe zwei Knoten umfasst, die den Link vorhersagen müssen. Der NOI-Subgraph bezieht sich auf einen Subgraphen, der H-Hop-Nachbarschaften enthält, die sich um diese NOI-Knoten erstrecken.
Dann ist der NOI-Eingabeaufforderungsknoten ein neu eingeführter Knotentyp, der direkt mit allen NOIs verbunden ist.
Wichtig ist, dass jeder NOI-Eingabeaufforderungsknoten Beschreibungsinformationen der aktuellen Aufgabe enthält. Diese Informationen liegen in natürlicher Sprache vor und werden durch dasselbe LLM wie das Textdiagramm dargestellt.
Da die in den Knoten im NOI enthaltenen Informationen nach der Weitergabe der GNN-Nachricht vom NOI-Eingabeaufforderungsknoten erfasst werden, muss das GNN-Modell nur Vorhersagen über den NOI-Eingabeaufforderungsknoten treffen.
Auf diese Weise erhalten alle verschiedenen Aufgabentypen eine einheitliche Aufgabendarstellung. Das konkrete Beispiel ist in der folgenden Abbildung dargestellt:
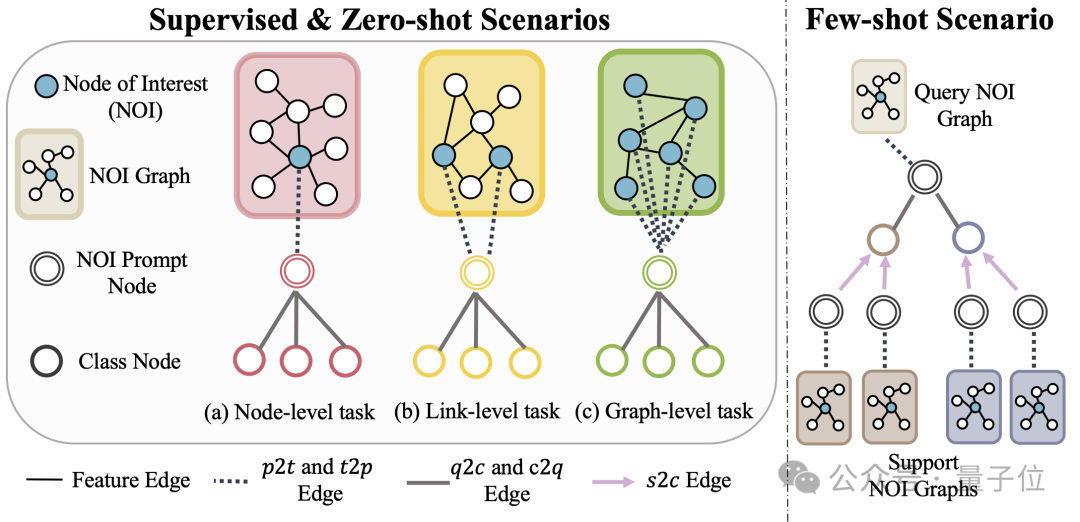
Um das Lernen im Kontext im Diagrammfeld zu realisieren, führt OFA schließlich einen einheitlichen Eingabeaufforderungs-Untergraphen ein.
In einem überwachten K-Wege-Klassifizierungsaufgabenszenario enthält dieser Eingabeaufforderungs-Untergraph zwei Arten von Knoten: einer ist der oben erwähnte NOI-Eingabeaufforderungsknoten und der andere sind Kategorieknoten, die k verschiedene Kategorien darstellen (Klassenknoten).
Der Text jedes Kategorieknotens beschreibt die relevanten Informationen dieser Kategorie. NOI-Eingabeaufforderungsknoten werden in einer Richtung mit allen Kategorieknoten verbunden. Der auf diese Weise erstellte Graph wird zur Nachrichtenübermittlung und zum Lernen in das neuronale Netzwerkmodell des Graphen eingegeben. Schließlich führt OFA eine binäre Klassifizierungsaufgabe für jeden Kategorieknoten durch und verwendet den Kategorieknoten mit der höchsten Wahrscheinlichkeit als endgültiges Vorhersageergebnis. Da Kategorieinformationen im Cue-Subgraphen vorhanden sind, kann OFA selbst dann, wenn ein völlig neues Klassifizierungsproblem auftritt, direkt vorhersagen, ohne dass eine Feinabstimmung erforderlich ist, indem der entsprechende Cue-Subgraph erstellt wird, wodurch Zero-Shot-Lernen erreicht wird. Für Lernszenarien mit wenigen Schüssen umfasst eine Klassifizierungsaufgabe ein Abfrage-Eingabediagramm und mehrere Support-Eingabediagramme. Das OFA-Prompt-Graph-Paradigma verbindet den NOI-Prompt-Knoten jedes Support-Eingabediagramms gleichzeitig mit seinem entsprechenden Kategorieknoten Der NOI-Eingabeaufforderungsknoten des Abfrageeingabediagramms ist mit allen Kategorieknoten verbunden. Die nachfolgenden Vorhersageschritte stimmen mit den oben genannten überein. Auf diese Weise erhält jeder Kategorieknoten zusätzliche Informationen aus dem Support-Eingabediagramm, wodurch ein Lernen mit wenigen Schüssen unter einem einheitlichen Paradigma erreicht wird. Die Hauptbeiträge von OFA lassen sich wie folgt zusammenfassen: Einheitliche Verteilung von Diagrammdaten: Durch den Vorschlag von Textdiagrammen und die Verwendung von LLM zur Transformation von Textinformationen erreicht OFA eine Verteilungsausrichtung und Vereinheitlichung von Diagrammdaten. Einheitliche Diagrammaufgabenform: Durch NOI-Unterdiagramme und NOI-Eingabeaufforderungsknoten erreicht OFA eine einheitliche Darstellung von Unteraufgaben in verschiedenen Diagrammfeldern. Einheitliches Graph-Prompting-Paradigma: Durch den Vorschlag eines neuartigen Graph-Prompting-Paradigmas realisiert OFA kontextübergreifendes Lernen mit mehreren Szenarien im Graphenbereich. Super-GeneralisierungsfähigkeitDer Artikel testete das OFA-Framework anhand von 9 gesammelten Datensätzen. Diese Tests deckten zehn verschiedene Aufgaben in überwachten Lernszenarien ab, einschließlich Knotenvorhersage, Linkvorhersage und Figurenklassifizierung. Der Zweck des Experiments besteht darin, die Fähigkeit eines einzelnen OFA-Modells zur Bewältigung mehrerer Aufgaben zu überprüfen. Dabei vergleicht der Autor die Verwendung verschiedener LLMs(OFA-{LLM}) und das Training separater Modelle für jede Aufgabe (OFA-ind-{LLM}) Wirkung.
Die Vergleichsergebnisse sind in der folgenden Tabelle dargestellt: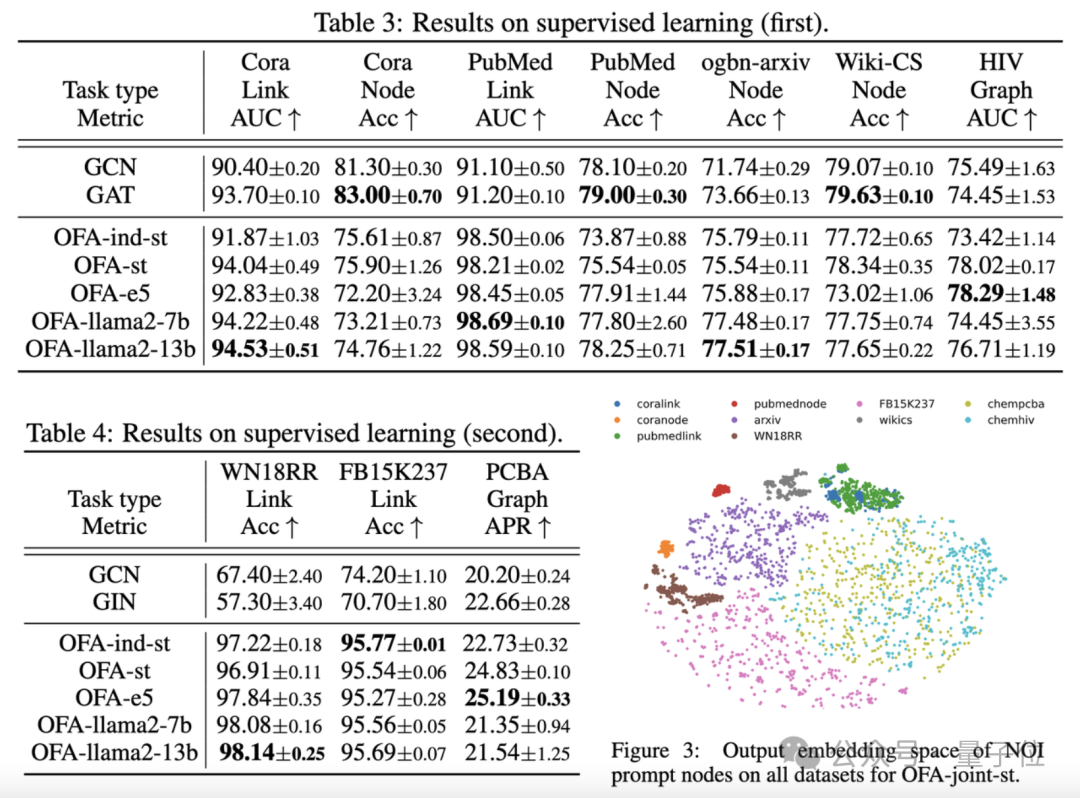
(OFA-st, OFA-e5, OFA-llama2-7b, OFA -llama2 -13b)Das heißt, es kann bei allen Aufgaben eine ähnliche oder bessere Leistung erzielen als das herkömmliche separate Trainingsmodell(GCN, GAT, OFA-ind-st).
Gleichzeitig kann der Einsatz eines leistungsfähigeren LLM gewisse Leistungsverbesserungen mit sich bringen. Der Artikel stellt außerdem die Darstellung von NOI-Eingabeaufforderungsknoten für verschiedene Aufgaben durch das trainierte OFA-Modell dar. Sie können sehen, dass das Modell verschiedene Aufgaben in verschiedene Unterräume eingebettet hat, sodass OFA verschiedene Aufgaben separat lernen kann, ohne sich gegenseitig zu beeinflussen. Im Szenario mit wenigen Stichproben und null Stichproben verwendet OFA ein einzelnes Modell auf ogbn-arxiv(Referenzgraph), FB15K237 (Wissensgraph) und Chemble (Molekulargraph) für das Vortraining und Testen Leistung bei verschiedenen nachgelagerten Aufgaben und Datensätzen. Die Ergebnisse sind wie folgt:
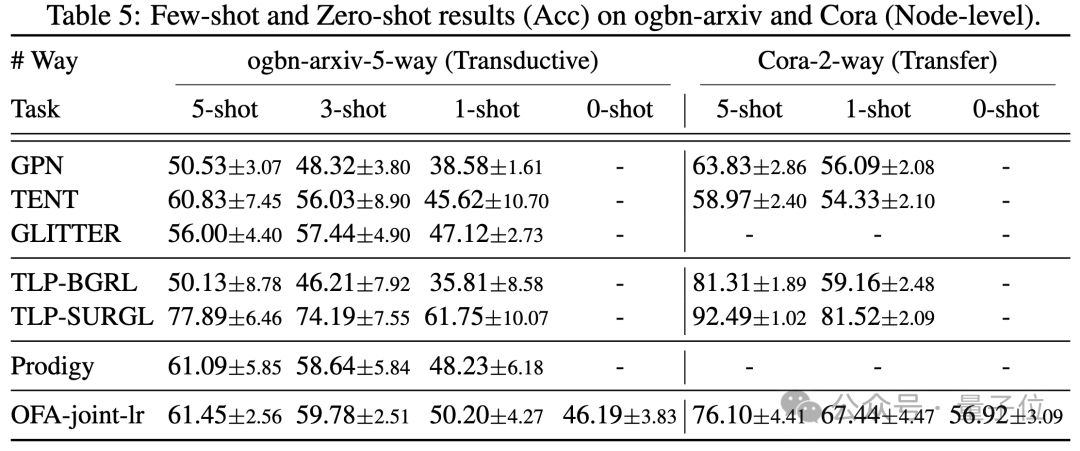
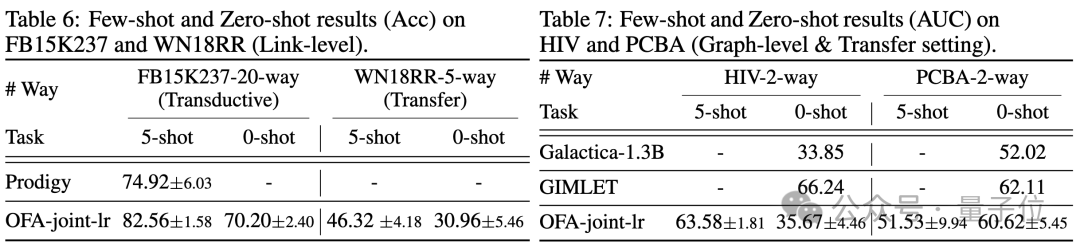
Es zeigt sich, dass OFA auch im Null-Proben-Szenario noch gute Ergebnisse erzielen kann. Zusammengenommen bestätigen die experimentellen Ergebnisse die starke allgemeine Leistung von OFA und sein Potenzial als Basismodell im Graphenbereich.
Weitere Forschungsdetails finden Sie im Originalpapier.
Adresse: https://www.php.cn/link/dd4729902a3476b2bc9675e3530a852chttps://github.com/LechengKong/OneForAll
Das obige ist der detaillierte Inhalt vonDas erste universelle Framework im Graphenbereich ist da! Durch Auswahl in ICLR\'24 Spotlight kann jedes Datensatz- und Klassifizierungsproblem gelöst werden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 http 400 Ungültige Anfrage
http 400 Ungültige Anfrage
 Implementierungsmethode für die Android-Sprachwiedergabefunktion
Implementierungsmethode für die Android-Sprachwiedergabefunktion
 Verwendung des Velocitytrackers
Verwendung des Velocitytrackers
 securefx kann keine Verbindung herstellen
securefx kann keine Verbindung herstellen
 Offizieller Website-Eingang der Okx-Handelsplattform
Offizieller Website-Eingang der Okx-Handelsplattform
 Hauptanwendungen des Linux-Betriebssystems
Hauptanwendungen des Linux-Betriebssystems
 Metasuchmaschine
Metasuchmaschine
 So führen Sie Code mit vscode aus
So führen Sie Code mit vscode aus
 So führen Sie ein PHPStudy-Projekt aus
So führen Sie ein PHPStudy-Projekt aus








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



