
 Technologie-Peripheriegeräte
KI
Das erste universelle Framework im Graphenbereich ist da! Durch die Auswahl in ICLR\'24 Spotlight kann jeder Datensatz oder jedes Klassifizierungsproblem gelöst werden
Technologie-Peripheriegeräte
KI
Das erste universelle Framework im Graphenbereich ist da! Durch die Auswahl in ICLR\'24 Spotlight kann jeder Datensatz oder jedes Klassifizierungsproblem gelöst werden
Das erste universelle Framework im Graphenbereich ist da! Durch die Auswahl in ICLR\'24 Spotlight kann jeder Datensatz oder jedes Klassifizierungsproblem gelöst werden

Kann es ein universelles Graphenmodell geben –
, das Toxizität basierend auf der Molekülstruktur vorhersagen und Freunde in sozialen Netzwerken empfehlen kann?
Oder können Sie nicht nur die Zitierungen der Arbeiten verschiedener Autoren vorhersagen, sondern auch den menschlichen Alterungsmechanismus im Gennetzwerk entdecken?
Sag mir nicht, das „One for All(OFA)“-Framework, das von ICLR 2024 als Spotlight akzeptiert wurde, hat diese „Essenz“ verwirklicht.
Diese Forschung wurde gemeinsam von Forschern wie dem Team von Professor Chen Yixin an der Washington University in St. Louis, Zhang Muhan von der Peking-Universität und Tao Dacheng vom JD Research Institute vorgeschlagen.
Als erstes allgemeines Framework im Graphfeld ermöglicht OFA das Training eines einzelnen GNN-Modells, um die Klassifizierungsaufgaben jedes Datensatzes, jedes Aufgabentyps und jeder Szene im Graphfeld zu lösen.

Wie man es konkret umsetzt, das Folgende ist der Beitrag des Autors.
Der Entwurf universeller Modelle im Graphenbereich steht vor drei großen Schwierigkeiten
Der Entwurf eines universellen Grundmodells zur Lösung einer Vielzahl von Aufgaben ist ein langfristiges Ziel im Bereich der künstlichen Intelligenz. In den letzten Jahren haben sich grundlegende große Sprachmodelle (LLMs) bei der Verarbeitung natürlichsprachlicher Aufgaben gut bewährt.
Obwohl grafische neuronale Netze (GNNs) im Bereich der Diagramme eine gute Leistung bei verschiedenen Diagrammdaten aufweisen, gibt es immer noch einen Weg, ein grundlegendes Diagrammmodell zu entwerfen und zu trainieren, das mehrere Diagrammaufgaben gleichzeitig bewältigen kann vorwärts riesig.
Im Vergleich zum Bereich der natürlichen Sprache ist der Entwurf allgemeiner Modelle im Graphenbereich mit vielen einzigartigen Schwierigkeiten konfrontiert.
Erstens haben unterschiedliche Diagrammdaten im Gegensatz zur natürlichen Sprache völlig unterschiedliche Attribute und Verteilungen.
Ein Moleküldiagramm beschreibt beispielsweise, wie mehrere Atome durch unterschiedliche Kraftverhältnisse unterschiedliche chemische Substanzen bilden. Das Citation-Relationship-Diagramm beschreibt das Netzwerk gegenseitiger Zitate zwischen Artikeln.
Diese verschiedenen Diagrammdaten lassen sich nur schwer in einem Trainingsrahmen vereinen.
Zweitens umfassen Diagrammaufgaben im Gegensatz zu allen Aufgaben in LLMs, die in einheitliche Kontextgenerierungsaufgaben umgewandelt werden können, eine Vielzahl von Unteraufgaben, wie Knotenaufgaben, Verknüpfungsaufgaben, Volldiagrammaufgaben usw.
Unterschiedliche Teilaufgaben erfordern in der Regel unterschiedliche Aufgabendarstellungen und unterschiedliche Diagrammmodelle.
Schließlich ist der Erfolg großer Sprachmodelle untrennbar mit dem Kontextlernen (In-Kontext-Lernen) verbunden, das durch prompte Paradigmen erreicht wird.
In großen Sprachmodellen ist das Prompt-Paradigma normalerweise eine lesbare Textbeschreibung der nachgelagerten Aufgabe.
Aber für Diagrammdaten, die unstrukturiert und schwer in Worten zu beschreiben sind, ist es immer noch ein ungelöstes Rätsel, wie man ein effektives Diagramm-Prompt-Paradigma entwirft, um kontextbezogenes Lernen zu erreichen.
Verwenden Sie das Konzept des „Textdiagramms“, um es zu lösen
Die folgende Abbildung zeigt den Gesamtrahmen von OFA:
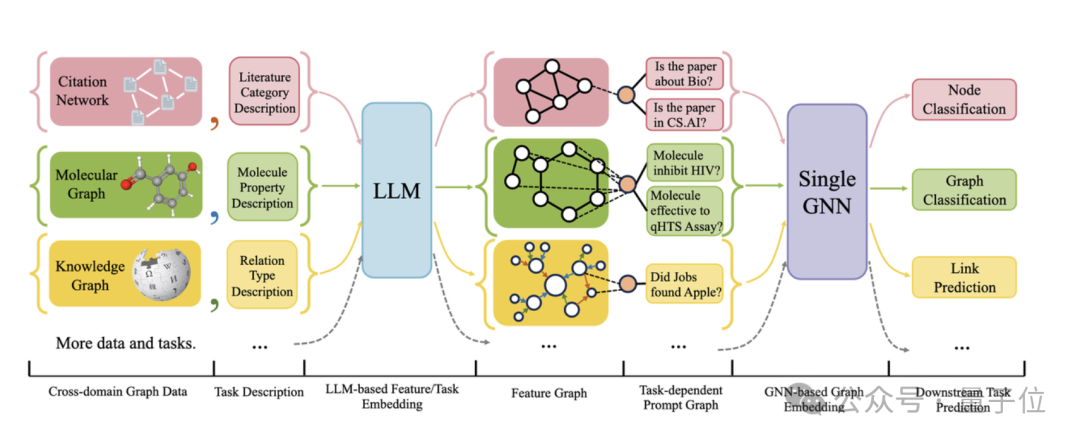
Konkret löst das OFA-Team die drei oben genannten Hauptprobleme durch cleveres Design.
Für das Problem unterschiedlicher Diagrammdatenattribute und -verteilungen vereinheitlicht OFA alle Diagrammdaten, indem es das Konzept des Text-Attributed Graph (TAGs) vorschlägt . Mithilfe von Textdiagrammen beschreibt OFA die Knoteninformationen und Kanteninformationen in allen Diagrammdaten mithilfe eines einheitlichen Rahmens in natürlicher Sprache, wie in der folgenden Abbildung dargestellt:


(NOI) Untergraph und NOI-Eingabeaufforderungsknoten (NOI-Eingabeaufforderungsknoten) , um verschiedene Unteraufgabentypen im Diagrammfeld zu vereinheitlichen. Hier repräsentiert NOI eine Reihe von Zielknoten, die an der entsprechenden Aufgabe teilnehmen.
Zum Beispiel bezieht sich der NOI in der Knotenvorhersageaufgabe auf einen einzelnen Knoten, der vorhergesagt werden muss, während der NOI in der Verbindungsaufgabe zwei Knoten umfasst, die den Link vorhersagen müssen. Der NOI-Subgraph bezieht sich auf einen Subgraphen, der H-Hop-Nachbarschaften enthält, die sich um diese NOI-Knoten erstrecken.
Dann ist der NOI-Eingabeaufforderungsknoten ein neu eingeführter Knotentyp, der direkt mit allen NOIs verbunden ist.
Wichtig ist, dass jeder NOI-Eingabeaufforderungsknoten Beschreibungsinformationen der aktuellen Aufgabe enthält. Diese Informationen liegen in natürlicher Sprache vor und werden durch dasselbe LLM wie das Textdiagramm dargestellt.
Da die in den Knoten im NOI enthaltenen Informationen nach der Weitergabe der GNN-Nachricht vom NOI-Eingabeaufforderungsknoten erfasst werden, muss das GNN-Modell nur Vorhersagen über den NOI-Eingabeaufforderungsknoten treffen.
Auf diese Weise erhalten alle verschiedenen Aufgabentypen eine einheitliche Aufgabendarstellung. Das konkrete Beispiel ist in der folgenden Abbildung dargestellt:
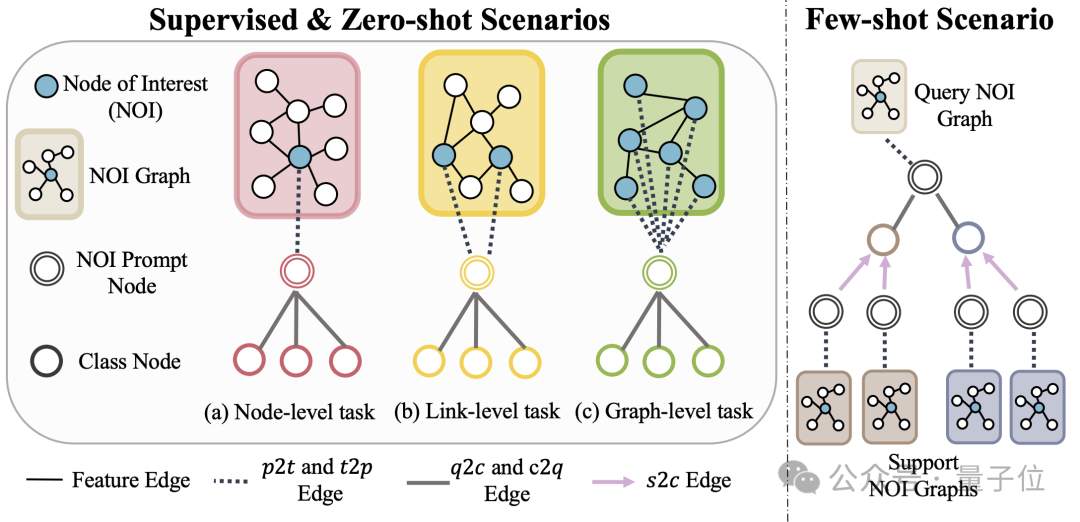
Um das Lernen im Kontext im Diagrammfeld zu realisieren, führt OFA schließlich einen einheitlichen Eingabeaufforderungs-Untergraphen ein.
In einem überwachten K-Wege-Klassifizierungsaufgabenszenario enthält dieser Eingabeaufforderungs-Untergraph zwei Arten von Knoten: einer ist der oben erwähnte NOI-Eingabeaufforderungsknoten und der andere sind Kategorieknoten, die k verschiedene Kategorien darstellen (Klassenknoten).
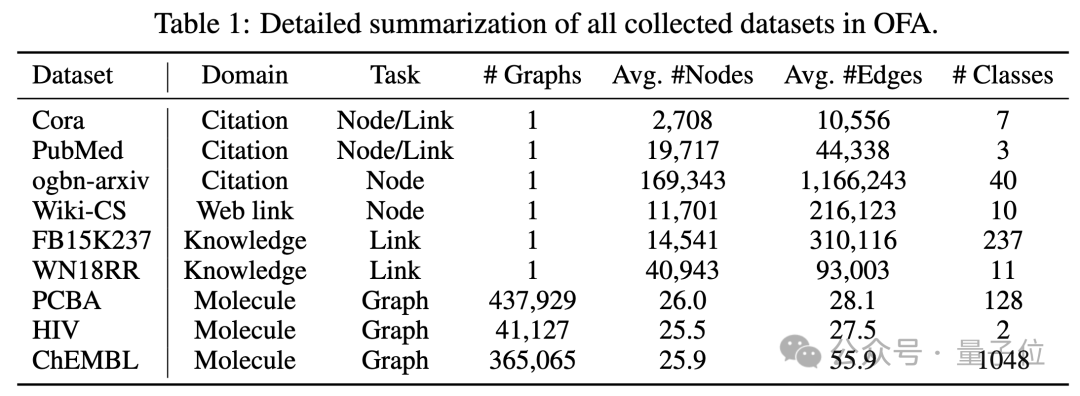
Der Text jedes Kategorieknotens beschreibt die relevanten Informationen dieser Kategorie. NOI-Eingabeaufforderungsknoten werden in einer Richtung mit allen Kategorieknoten verbunden. Der auf diese Weise erstellte Graph wird zur Nachrichtenübermittlung und zum Lernen in das neuronale Netzwerkmodell des Graphen eingegeben. Schließlich führt OFA eine binäre Klassifizierungsaufgabe für jeden Kategorieknoten durch und verwendet den Kategorieknoten mit der höchsten Wahrscheinlichkeit als endgültiges Vorhersageergebnis. Da Kategorieinformationen im Cue-Subgraphen vorhanden sind, kann OFA selbst dann, wenn ein völlig neues Klassifizierungsproblem auftritt, direkt vorhersagen, ohne dass eine Feinabstimmung erforderlich ist, indem der entsprechende Cue-Subgraph erstellt wird, wodurch Zero-Shot-Lernen erreicht wird. Für Lernszenarien mit wenigen Schüssen umfasst eine Klassifizierungsaufgabe ein Abfrage-Eingabediagramm und mehrere Support-Eingabediagramme. Das OFA-Prompt-Graph-Paradigma verbindet den NOI-Prompt-Knoten jedes Support-Eingabediagramms gleichzeitig mit seinem entsprechenden Kategorieknoten Der NOI-Eingabeaufforderungsknoten des Abfrageeingabediagramms ist mit allen Kategorieknoten verbunden. Die nachfolgenden Vorhersageschritte stimmen mit den oben genannten überein. Auf diese Weise erhält jeder Kategorieknoten zusätzliche Informationen aus dem Support-Eingabediagramm, wodurch ein Lernen mit wenigen Schüssen unter einem einheitlichen Paradigma erreicht wird. Die Hauptbeiträge von OFA lassen sich wie folgt zusammenfassen: Einheitliche Verteilung von Diagrammdaten: Durch den Vorschlag von Textdiagrammen und die Verwendung von LLM zur Transformation von Textinformationen erreicht OFA eine Verteilungsausrichtung und Vereinheitlichung von Diagrammdaten. Einheitliche Diagrammaufgabenform: Durch NOI-Unterdiagramme und NOI-Eingabeaufforderungsknoten erreicht OFA eine einheitliche Darstellung von Unteraufgaben in verschiedenen Diagrammfeldern. Einheitliches Graph-Prompting-Paradigma: Durch den Vorschlag eines neuartigen Graph-Prompting-Paradigmas realisiert OFA kontextübergreifendes Lernen mit mehreren Szenarien im Graphenbereich. Super-GeneralisierungsfähigkeitDer Artikel testete das OFA-Framework anhand von 9 gesammelten Datensätzen. Diese Tests deckten zehn verschiedene Aufgaben in überwachten Lernszenarien ab, einschließlich Knotenvorhersage, Linkvorhersage und Figurenklassifizierung. Der Zweck des Experiments besteht darin, die Fähigkeit eines einzelnen OFA-Modells zur Bewältigung mehrerer Aufgaben zu überprüfen. Dabei vergleicht der Autor die Verwendung verschiedener LLMs(OFA-{LLM}) und das Training separater Modelle für jede Aufgabe (OFA-ind-{LLM}) Wirkung.
Die Vergleichsergebnisse sind in der folgenden Tabelle dargestellt: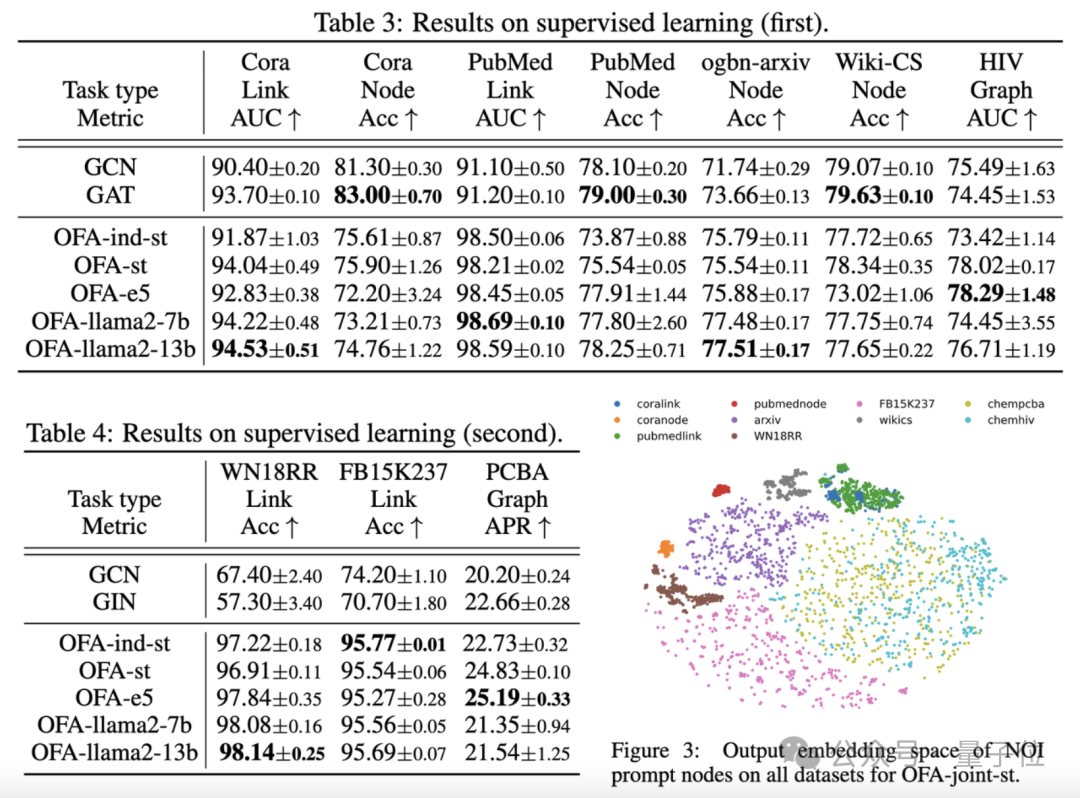
(OFA-st, OFA-e5, OFA-llama2-7b, OFA -llama2 -13b)Das heißt, es kann bei allen Aufgaben eine ähnliche oder bessere Leistung erzielen als das herkömmliche separate Trainingsmodell(GCN, GAT, OFA-ind-st).
Gleichzeitig kann der Einsatz eines leistungsfähigeren LLM gewisse Leistungsverbesserungen mit sich bringen. Der Artikel stellt außerdem die Darstellung von NOI-Eingabeaufforderungsknoten für verschiedene Aufgaben durch das trainierte OFA-Modell dar. Sie können sehen, dass das Modell verschiedene Aufgaben in verschiedene Unterräume eingebettet hat, sodass OFA verschiedene Aufgaben separat lernen kann, ohne sich gegenseitig zu beeinflussen. Im Szenario mit wenigen Stichproben und null Stichproben verwendet OFA ein einzelnes Modell auf ogbn-arxiv(Referenzgraph), FB15K237 (Wissensgraph) und Chemble (Molekulargraph) für das Vortraining und Testen Leistung bei verschiedenen nachgelagerten Aufgaben und Datensätzen. Die Ergebnisse sind wie folgt:
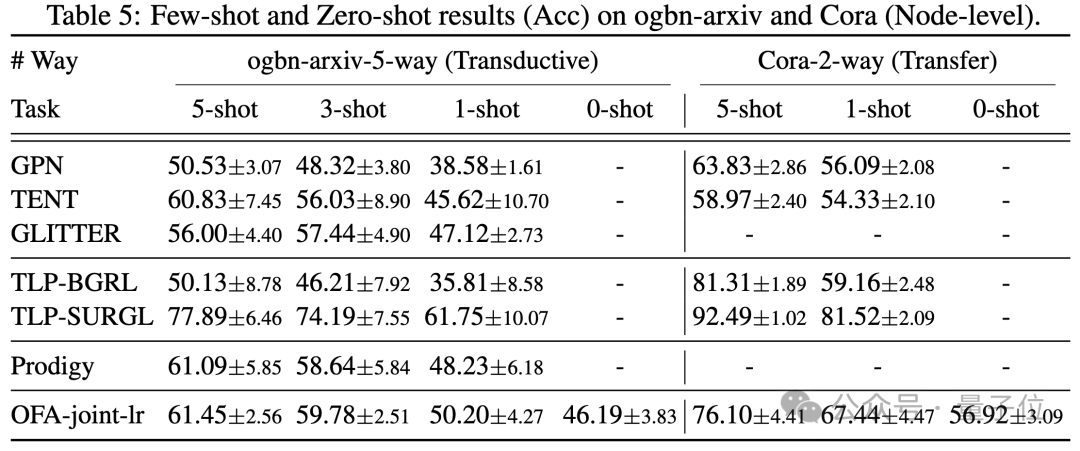
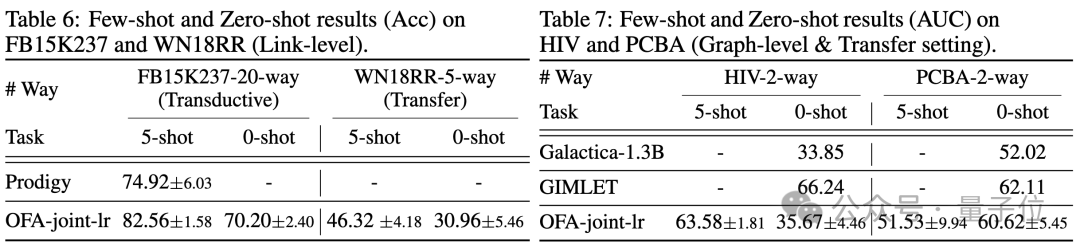
Es zeigt sich, dass OFA auch im Null-Proben-Szenario noch gute Ergebnisse erzielen kann. Zusammengenommen bestätigen die experimentellen Ergebnisse die starke allgemeine Leistung von OFA und sein Potenzial als Basismodell im Graphenbereich.
Weitere Forschungsdetails finden Sie im Originalpapier.
Adresse: https://www.php.cn/link/dd4729902a3476b2bc9675e3530a852chttps://github.com/LechengKong/OneForAll
Das obige ist der detaillierte Inhalt vonDas erste universelle Framework im Graphenbereich ist da! Durch die Auswahl in ICLR\'24 Spotlight kann jeder Datensatz oder jedes Klassifizierungsproblem gelöst werden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Was? Wird Zootopia durch heimische KI in die Realität umgesetzt? Zusammen mit dem Video wird ein neues groß angelegtes inländisches Videogenerationsmodell namens „Keling“ vorgestellt. Sora geht einen ähnlichen technischen Weg und kombiniert eine Reihe selbst entwickelter technologischer Innovationen, um Videos zu produzieren, die nicht nur große und vernünftige Bewegungen aufweisen, sondern auch die Eigenschaften der physischen Welt simulieren und über starke konzeptionelle Kombinationsfähigkeiten und Vorstellungskraft verfügen. Den Daten zufolge unterstützt Keling die Erstellung ultralanger Videos von bis zu 2 Minuten mit 30 Bildern pro Sekunde, mit Auflösungen von bis zu 1080p und unterstützt mehrere Seitenverhältnisse. Ein weiterer wichtiger Punkt ist, dass es sich bei Keling nicht um eine vom Labor veröffentlichte Demo oder Video-Ergebnisdemonstration handelt, sondern um eine Anwendung auf Produktebene, die von Kuaishou, einem führenden Anbieter im Bereich Kurzvideos, gestartet wurde. Darüber hinaus liegt das Hauptaugenmerk darauf, pragmatisch zu sein, keine Blankoschecks auszustellen und sofort nach der Veröffentlichung online zu gehen. Das große Modell von Ke Ling wurde bereits in Kuaiying veröffentlicht.
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Kürzlich wurde die Militärwelt von der Nachricht überwältigt: US-Militärkampfflugzeuge können jetzt mithilfe von KI vollautomatische Luftkämpfe absolvieren. Ja, erst kürzlich wurde der KI-Kampfjet des US-Militärs zum ersten Mal der Öffentlichkeit zugänglich gemacht und sein Geheimnis gelüftet. Der vollständige Name dieses Jägers lautet „Variable Stability Simulator Test Aircraft“ (VISTA). Er wurde vom Minister der US-Luftwaffe persönlich geflogen, um einen Eins-gegen-eins-Luftkampf zu simulieren. Am 2. Mai startete US-Luftwaffenminister Frank Kendall mit einer X-62AVISTA auf der Edwards Air Force Base. Beachten Sie, dass während des einstündigen Fluges alle Flugaktionen autonom von der KI durchgeführt wurden! Kendall sagte: „In den letzten Jahrzehnten haben wir über das unbegrenzte Potenzial des autonomen Luft-Luft-Kampfes nachgedacht, aber es schien immer unerreichbar.“ Nun jedoch,
 Für nur 250 US-Dollar zeigt Ihnen der technische Leiter von Hugging Face Schritt für Schritt, wie Sie Llama 3 verfeinern
May 06, 2024 pm 03:52 PM
Für nur 250 US-Dollar zeigt Ihnen der technische Leiter von Hugging Face Schritt für Schritt, wie Sie Llama 3 verfeinern
May 06, 2024 pm 03:52 PM
Die bekannten großen Open-Source-Sprachmodelle wie Llama3 von Meta, Mistral- und Mixtral-Modelle von MistralAI und Jamba von AI21 Lab sind zu Konkurrenten von OpenAI geworden. In den meisten Fällen müssen Benutzer diese Open-Source-Modelle anhand ihrer eigenen Daten verfeinern, um das Potenzial des Modells voll auszuschöpfen. Es ist nicht schwer, ein großes Sprachmodell (wie Mistral) im Vergleich zu einem kleinen mithilfe von Q-Learning auf einer einzelnen GPU zu optimieren, aber die effiziente Feinabstimmung eines großen Modells wie Llama370b oder Mixtral blieb bisher eine Herausforderung . Deshalb Philipp Sch, technischer Leiter von HuggingFace
 Übertrifft DPO umfassend: Das Team von Chen Danqi schlug eine einfache Präferenzoptimierung (SimPO) vor und verfeinerte außerdem das stärkste 8B-Open-Source-Modell
Jun 01, 2024 pm 04:41 PM
Übertrifft DPO umfassend: Das Team von Chen Danqi schlug eine einfache Präferenzoptimierung (SimPO) vor und verfeinerte außerdem das stärkste 8B-Open-Source-Modell
Jun 01, 2024 pm 04:41 PM
Um große Sprachmodelle (LLMs) an menschlichen Werten und Absichten auszurichten, ist es wichtig, menschliches Feedback zu lernen, um sicherzustellen, dass sie nützlich, ehrlich und harmlos sind. Im Hinblick auf die Ausrichtung von LLM ist Reinforcement Learning basierend auf menschlichem Feedback (RLHF) eine wirksame Methode. Obwohl die Ergebnisse der RLHF-Methode ausgezeichnet sind, gibt es einige Herausforderungen bei der Optimierung. Dazu gehört das Training eines Belohnungsmodells und die anschließende Optimierung eines Richtlinienmodells, um diese Belohnung zu maximieren. Kürzlich haben einige Forscher einfachere Offline-Algorithmen untersucht, darunter die direkte Präferenzoptimierung (Direct Preference Optimization, DPO). DPO lernt das Richtlinienmodell direkt auf der Grundlage von Präferenzdaten, indem es die Belohnungsfunktion in RLHF parametrisiert, wodurch die Notwendigkeit eines expliziten Belohnungsmodells entfällt. Diese Methode ist einfach und stabil
 Keine OpenAI-Daten erforderlich, schließen Sie sich der Liste der großen Codemodelle an! UIUC veröffentlicht StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Keine OpenAI-Daten erforderlich, schließen Sie sich der Liste der großen Codemodelle an! UIUC veröffentlicht StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
An der Spitze der Softwaretechnologie kündigte die Gruppe von UIUC Zhang Lingming zusammen mit Forschern der BigCode-Organisation kürzlich das StarCoder2-15B-Instruct-Großcodemodell an. Diese innovative Errungenschaft erzielte einen bedeutenden Durchbruch bei Codegenerierungsaufgaben, übertraf erfolgreich CodeLlama-70B-Instruct und erreichte die Spitze der Codegenerierungsleistungsliste. Die Einzigartigkeit von StarCoder2-15B-Instruct liegt in seiner reinen Selbstausrichtungsstrategie. Der gesamte Trainingsprozess ist offen, transparent und völlig autonom und kontrollierbar. Das Modell generiert über StarCoder2-15B Tausende von Anweisungen als Reaktion auf die Feinabstimmung des StarCoder-15B-Basismodells, ohne auf teure manuelle Annotationen angewiesen zu sein.
