
 Technologie-Peripheriegeräte
KI
Graphenbewusstes kontrastives Lernen verbessert die Klassifizierungseffekte multivariater Zeitreihen
Technologie-Peripheriegeräte
KI
Graphenbewusstes kontrastives Lernen verbessert die Klassifizierungseffekte multivariater Zeitreihen
Graphenbewusstes kontrastives Lernen verbessert die Klassifizierungseffekte multivariater Zeitreihen

Dieses Papier in AAAI 2024 wurde gemeinsam von der Singapore Agency for Science, Technology and Research (A*STAR) und der Nanyang Technological University, Singapur, veröffentlicht. Es schlägt eine Methode vor, um graphenbewusstes kontrastives Lernen zu nutzen, um die Klassifizierung multivariater Zeitreihen zu verbessern. Experimentelle Ergebnisse zeigen, dass diese Methode bemerkenswerte Ergebnisse bei der Verbesserung der Leistung der Zeitreihenklassifizierung erzielt hat.
 Bilder
Bilder
Papiertitel: Graph-Aware Contrasting for Multivariate Time-Series Classification
Download-Adresse: https://arxiv.org/pdf/2309.05202.pdf
Offener Quellcode: https://github .com/Frank-Wang-oss/TS-GAC
1. Basierend auf den vorhandenen kontrastiven Lernmethoden schlug der Autor eine Methode namens „Graph-Aware Contrast“ (TS-GAC) vor Lösen Sie das räumliche Konsistenzproblem von Multisensoren in MTS-Daten. TS-GAC besteht aus zwei Hauptkomponenten: Diagrammverbesserung und Diagrammvergleich. Die Diagrammverbesserung verbessert die räumliche Konsistenz durch Knoten- und Kantenverbesserung, um die Stabilität und Relevanz des Sensors aufrechtzuerhalten. Der Diagrammvergleich führt einen Zeitvergleich in mehreren Fenstern ein, um die Zeitkonsistenz aufrechtzuerhalten. Durch umfangreiche experimentelle Verifizierung erreicht diese Methode eine optimale Leistung bei verschiedenen MTS-Klassifizierungsaufgaben. Die Ergebnisse unterstreichen die Bedeutung der Berücksichtigung der räumlichen Konsistenz beim kontrastiven Lernen von MTS-Daten und bieten eine umfassende Lösung, die die Klassifizierungsleistung erheblich verbessert. Diese Forschung ist von großer Bedeutung für die weitere Verbesserung der Wirkung des kontrastiven Lernens und stellt ein leistungsstarkes Werkzeug für die Verarbeitung von MTS-Daten dar.
Bilder 2. Modellstruktur
2. Modellstruktur
Die in diesem Artikel vorgeschlagene Methode umfasst hauptsächlich zwei Teile: Bildverbesserung und Bildvergleich.
Um MTS-Daten effektiv zu verbessern, führen wir eine Knoten- und Kantenverbesserung ein, um schwache und starke Ansichten zu generieren. Die Knotenverbesserung umfasst die Verbesserung des Frequenzbereichs und des Zeitbereichs, um Diagrammknoten vollständig zu verbessern. Zuerst wenden wir eine Frequenzbereichsverbesserung an, um die Knoten zu verbessern, und segmentieren dann die verbesserten Abtastwerte entsprechend den dynamischen lokalen Mustern in den MTS-Daten in mehrere Fenster (wie in Abbildung 2 dargestellt). In jedem Fenster verwenden wir die zeitliche Knotenerweiterung und führen eine Merkmalsextraktion für das Fenster über ein eindimensionales Faltungs-Neuronales Netzwerk durch. Anschließend erstellen wir für jedes Fenster ein Diagramm und verbessern das Diagramm durch Kantenverstärkung weiter. Schließlich verwenden wir einen auf einem graphischen neuronalen Netzwerk basierenden Encoder für die Graphverarbeitung und das Lernen von Merkmalen.
Bilder Diagrammvergleich: einschließlich Vergleich auf Knotenebene und Vergleich auf Diagrammebene, um räumliche Konsistenz zu erreichen. Der Vergleich auf Knotenebene stellt die Robustheit der Knotenfunktionen sicher, indem entsprechende Sensoren in verschiedenen Ansichten näher herangezogen und verschiedene Sensoren in verschiedenen Ansichten weiter entfernt werden. Der Vergleich auf Diagrammebene stellt außerdem die Robustheit globaler Merkmale sicher, indem Stichproben in verschiedenen Ansichten verglichen werden.
Diagrammvergleich: einschließlich Vergleich auf Knotenebene und Vergleich auf Diagrammebene, um räumliche Konsistenz zu erreichen. Der Vergleich auf Knotenebene stellt die Robustheit der Knotenfunktionen sicher, indem entsprechende Sensoren in verschiedenen Ansichten näher herangezogen und verschiedene Sensoren in verschiedenen Ansichten weiter entfernt werden. Der Vergleich auf Diagrammebene stellt außerdem die Robustheit globaler Merkmale sicher, indem Stichproben in verschiedenen Ansichten verglichen werden.
Die Architektur zielt darauf ab, räumliche Konsistenz beim kontrastiven Lernen zu erreichen, indem sie spezifische Verbesserungs- und Kontrasttechniken für die MTS-Klassifizierung bereitstellt. Indem zuerst die Knotenverbesserung angewendet wird, dann die zeitliche Verbesserung innerhalb der Knoten verwendet wird und schließlich die Kantenverbesserung durch GNN verarbeitet wird, ist diese Methode in der Lage, schwache und starke Ansichten mit unterschiedlichen räumlichen und zeitlichen Eigenschaften für jede Probe zu generieren. Die Innovation dieser Methode besteht darin, dass sie nicht nur die zeitliche Konsistenz berücksichtigt, sondern durch die Diagrammstruktur auch die räumliche Konsistenz verbessert und so eine neue Perspektive für die eingehende Analyse und Verarbeitung von MTS-Daten bietet.
3. Diagrammverbesserungsmodul
Angesichts der Eigenschaften von MTS-Daten, d und Zeitbereichserweiterung. Die Frequenzbereichsverbesserung wandelt das Signal jedes Sensors in den Frequenzbereich um, verbessert die extrahierten Frequenzmerkmale und wandelt die verbesserten Frequenzmerkmale dann zurück in den Zeitbereich um, um ein verbessertes Signal zu erhalten. Insbesondere wird die diskrete Wavelet-Transformation verwendet, um das Signal durch Hochpass- und Tiefpassfilter zu zerlegen, um Makrotrends und Mikrotrends innerhalb des Signals darzustellen. Die Zeitbereichsverbesserung berücksichtigt die dynamischen Eigenschaften von MTS-Daten, indem jede MTS-Probe in mehrere Fenster unterteilt und in jedem Fenster eine Zeitbereichsverbesserung durchgeführt wird.
Kantenverbesserung: zielt darauf ab, die Korrelation zwischen Sensoren, also den Kanten im erstellten Diagramm, zu verbessern. Die Knoten (Sensoren) und Kanten (Korrelationen zwischen Sensoren) werden zunächst durch einen Graphenerstellungsprozess definiert. Anschließend wird die Korrelation zwischen Sensoren durch die Kantenverstärkungsmethode effektiv verbessert. In diesem Schritt wird unter Berücksichtigung der Tatsache, dass bei der Merkmalsausbreitung von GNN eine starke Korrelation wichtiger ist als eine schwache Korrelation, bei der Kantenverstärkung die stärkste Korrelation beibehalten, um die Stabilität topologischer Informationen sicherzustellen. Die verbleibenden Korrelationen werden durch Zufallswerte ersetzt zur Verbesserung der Randverbindungen.
Durch diese Verbesserungsstrategien möchte der Autor schwache Ansichten und starke Ansichten generieren, damit der anschließende kontrastive Lernprozess robuste Sensormerkmale und Beziehungen zwischen Sensoren erlernen kann. Das Design dieser Verbesserungsstrategien berücksichtigt die Multiquellen- und Dynamik von MTS-Daten und erweitert die Fähigkeiten von CL durch die Bereitstellung von Datenansichten aus verschiedenen Blickwinkeln, sodass robustere und allgemeinere Darstellungen erlernt werden können.
4. Diagrammvergleichsmodul
Das Papier schlägt eine diagrammbewusste Vergleichsmethode vor, die speziell Knoten- und Kantenverbesserungs- und Diagrammvergleichsstrategien entwickelt, um die räumliche Konsistenz von MTS-Daten zu verbessern. Es umfasst hauptsächlich drei Vergleichsebenen: Zeitvergleich mit mehreren Fenstern, Vergleich auf Knotenebene und Vergleich auf Diagrammebene.
Multi-Window Temporal Contrasting (MWTC): Diese Methode gewährleistet die zeitliche Konsistenz jedes Sensors auf Sensorebene und erhält die Robustheit der zeitlichen Abhängigkeit innerhalb von MTS-Daten durch prädiktive Codierung aufrecht. MWTC erhält die Robustheit zeitlicher Muster aufrecht, indem vergangene Fensterinformationen in einer Ansicht zusammengefasst und in einer anderen Ansicht mit zukünftigen Fenstern verglichen werden.
Kontrastierung auf Knotenebene (NC): NC lernt robuste Funktionen auf Sensorebene, indem es Sensoren in verschiedenen Ansichten innerhalb jeder MTS-Probe vergleicht. Dabei geht es darum, die Ähnlichkeit zwischen entsprechenden Sensoren in zwei Ansichten zu maximieren und gleichzeitig die Ähnlichkeit zwischen verschiedenen Sensoren in diesen Ansichten zu minimieren.
Kontrastierung auf Diagrammebene (GC): GC fördert robustes Merkmalslernen auf globaler Ebene durch den Vergleich von Beispielen innerhalb jedes Trainingsstapels. Bei dieser Strategie wird die Ähnlichkeit zwischen entsprechenden Stichproben in zwei Ansichten maximiert und gleichzeitig die Ähnlichkeit zwischen verschiedenen Stichproben in diesen Ansichten minimiert.
Diese kontrastiven Lernstrategien arbeiten zusammen, um das Repräsentationslernen von MTS-Daten durch Diagrammstrukturen zu verbessern und dadurch die Klassifizierungsgenauigkeit zu verbessern. Der Artikel hebt auch die Bedeutung des zeitlichen Vergleichs hervor, um die zeitliche Konsistenz für jeden Sensor aufrechtzuerhalten, sowie die Rolle des Diagrammvergleichs beim Erlernen robuster Merkmale auf Sensor- und globaler Ebene. Durch die Kombination von Vergleichen auf Knotenebene und Diagrammebene kann diese Methode komplexe räumliche und zeitliche Muster in MTS-Daten effektiv lernen und eine erhebliche Verbesserung der MTS-Klassifizierungsleistung erzielen.
5. Experimentelle Ergebnisse
Im experimentellen Teil vergleicht das Papier die Leistung von zehn öffentlichen multivariaten Zeitreihendatensätzen und vergleicht sie mit den vorhandenen Methoden nach dem neuesten Stand der Technik. Zu diesen Datensätzen gehören Human Activity Recognition (HAR), ISRUC-Schlafphasenklassifizierung und Unterdatensätze im UEA-Datensatz wie Fingerbewegungen, gesprochene arabische Ziffern usw. Für einen fairen Vergleich verwenden alle Methoden denselben Encoder. Experimentelle Ergebnisse zeigen, dass TS-GAC bei acht Datensätzen die beste Leistung erzielte, insbesondere bei den HAR- und ISRUC-Datensätzen. Im Vergleich zu anderen Methoden stieg die Genauigkeit um 1,44 % bzw. 3,13 %.
 Bilder
Bilder
Gleichzeitig visualisierte der Autor auch die Modellmerkmale, und die Visualisierungsergebnisse ermöglichten es TS-GAC, erkennbarere Merkmale auf Sensorebene zu extrahieren. Gleichzeitig kann TS-GAC im Vergleich zu anderen Methoden konsistentere Merkmale auf Sensorebene für Daten aus verschiedenen Betrachtungswinkeln erhalten.
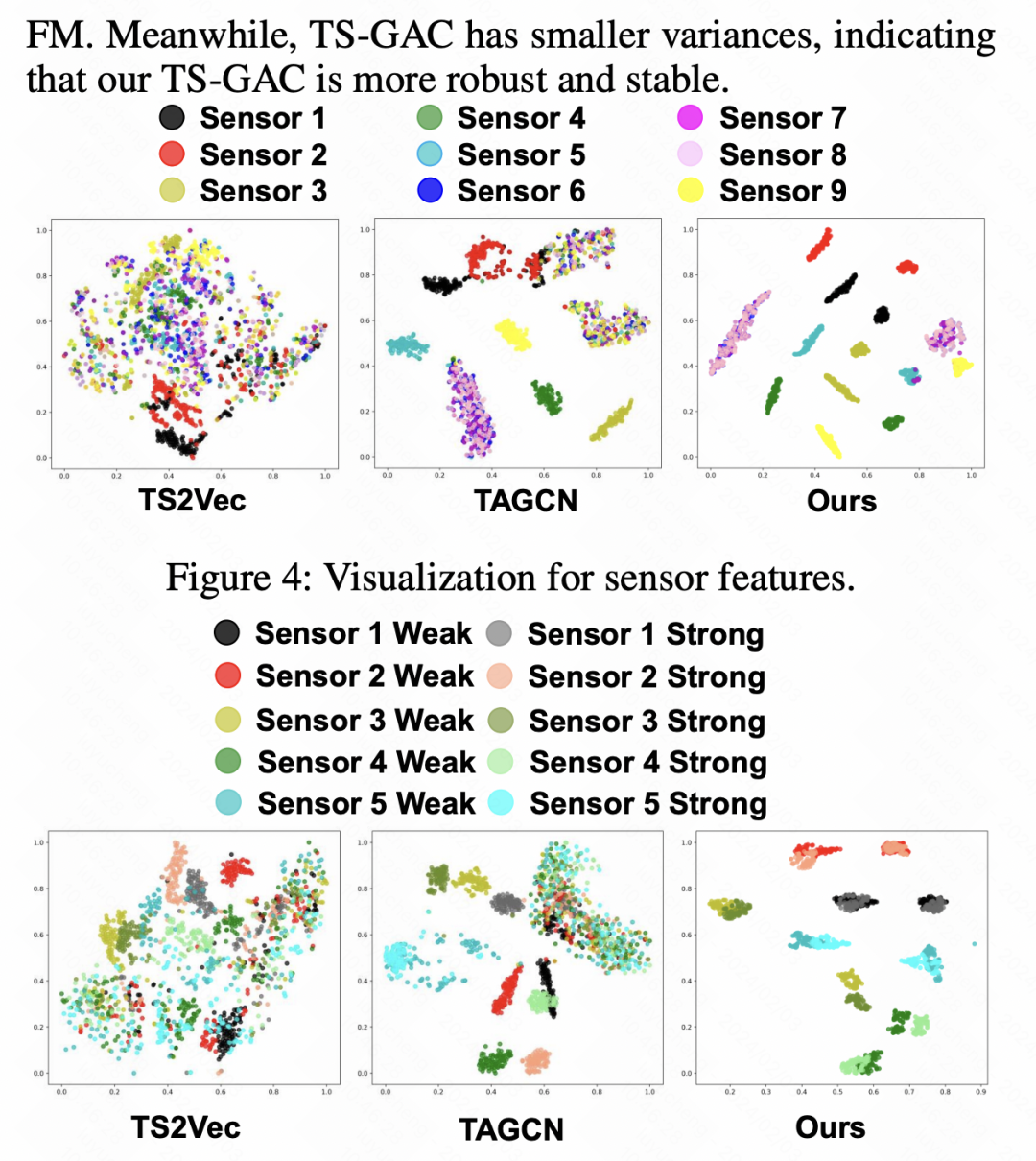 Bilder
Bilder
Die Autoren führten auch Ablationsstudien durch, um die Auswirkungen der entwickelten Verstärkungs- und Kontrasttechniken auf die Modellleistung zu bewerten. In der Ablationsstudie wurden verschiedene Varianten getestet, darunter solche, bei denen die Knotenverstärkung, die Kantenverstärkung, der Kontrast auf Diagrammebene, der Kontrast auf Knotenebene und der zeitliche Mehrfensterkontrast entfernt wurden. Die Ergebnisse zeigen, dass Diagrammverbesserungs- und Diagrammkontrasttechniken die räumliche Konsistenz von MTS-Daten äußerst effektiv verbessern und dass der vollständige TS-GAC eine bessere Leistung zeigt als jede Variante, die den Kontrastverlust reduziert.
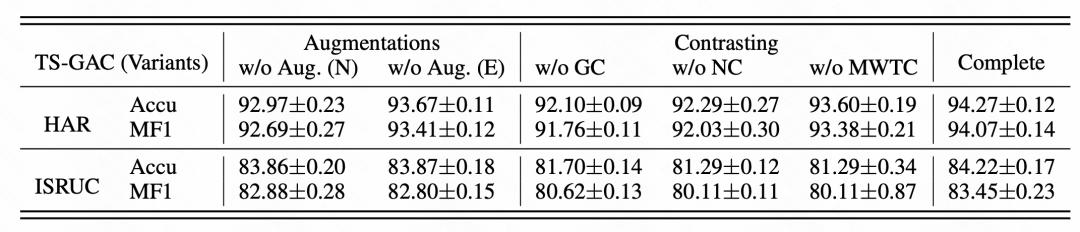 Bild
Bild
Darüber hinaus analysierte der Autor auch die Empfindlichkeit des Modells, einschließlich des Einflusses von Hyperparametern (wie λMWTC, λGC, λNC) und des Einflusses der Anzahl der beibehaltenen Kanten. Diese Analysen bestätigen weiterhin die Wirksamkeit und Robustheit der vorgeschlagenen Methode.
Insgesamt unterstreichen die experimentellen Ergebnisse die Fähigkeit von TS-GAC, bei mehreren MTS-Klassifizierungsaufgaben eine optimale Leistung zu erzielen, was die Bedeutung der vorgeschlagenen Diagrammverbesserungs- und Diagrammvergleichstechniken für die Verbesserung der räumlichen Konsistenz des Modells für MTS-Daten zeigt Wirksamkeit.
Das obige ist der detaillierte Inhalt vonGraphenbewusstes kontrastives Lernen verbessert die Klassifizierungseffekte multivariater Zeitreihen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 MHz ist Geschichte! Die Speichergeschwindigkeitseinheit von Microsoft Windows 11 wird auf MT/s umgestellt
Jun 25, 2024 pm 05:10 PM
MHz ist Geschichte! Die Speichergeschwindigkeitseinheit von Microsoft Windows 11 wird auf MT/s umgestellt
Jun 25, 2024 pm 05:10 PM
Alle Enthusiasten digitaler Hardware wissen, dass es in den letzten Jahren zwei Speicherparameter-Kennzeichnungseinheiten gab, nämlich „MHz“ und „MT/s“, was für digitale Anfänger verwirrend sein kann. „MHz“ und „MT/s“ sind beides Maßeinheiten für die Speicherübertragungsleistung, weisen jedoch dennoch erhebliche Unterschiede auf. MHz gibt an, wie viele Millionen Zyklen ein Speichermodul pro Sekunde ausführen kann, und jeder Zyklus ist ein Vorgang, der auf dem Speichermodul ausgeführt wird, z. B. das Speichern und Abrufen von Daten. Aufgrund der rasanten Entwicklung der aktuellen Technologie ermöglicht die neue Technologie jedoch, dass der DDR-Speicher die Datenübertragungsrate erhöht, ohne die Taktrate zu erhöhen, und die alte Speichermessmethode hat dies auch getan
 So schreiben Sie einen Algorithmus zur Zeitreihenvorhersage mit C#
Sep 19, 2023 pm 02:33 PM
So schreiben Sie einen Algorithmus zur Zeitreihenvorhersage mit C#
Sep 19, 2023 pm 02:33 PM
So schreiben Sie einen Algorithmus für die Zeitreihenprognose mit C#. Die Zeitreihenprognose ist eine Methode zur Vorhersage zukünftiger Datentrends durch die Analyse vergangener Daten. Es hat breite Anwendungsmöglichkeiten in vielen Bereichen wie Finanzen, Vertrieb und Wettervorhersage. In diesem Artikel stellen wir anhand spezifischer Codebeispiele vor, wie man Zeitreihenprognosealgorithmen mit C# schreibt. Datenvorbereitung Bevor Sie Zeitreihenprognosen durchführen, müssen Sie zunächst die Daten vorbereiten. Im Allgemeinen sollten Zeitreihendaten eine ausreichende Länge haben und in chronologischer Reihenfolge angeordnet sein. Sie können es aus der Datenbank beziehen oder
 Wow cool! Samsung Galaxy Ring-Erlebnis: 2999 Yuan echter Smart Ring
Jul 19, 2024 pm 02:31 PM
Wow cool! Samsung Galaxy Ring-Erlebnis: 2999 Yuan echter Smart Ring
Jul 19, 2024 pm 02:31 PM
Samsung hat am 17. Juli offiziell die nationale Version des Samsung Galaxy Ring zum Preis von 2.999 Yuan veröffentlicht. Das echte Telefon des Galaxy Ring ist wirklich die 2024-Version von „WowAwesome, das ist mein exklusiver Moment“. Es ist das elektronische Produkt, das uns in den letzten Jahren das frischeste Gefühl gibt (obwohl es wie eine Flagge klingt). (Im Bild sind die Ringe links und rechts Galaxy Ring ↑) Samsung Galaxy Ring-Spezifikationen (Daten von der offiziellen Website der Bank of China): ZephyrRTOS-System, 8 MB wasserdicht + IP68; Batteriekapazität 18 mAh mAh (verschiedene Größen
 So verwenden Sie XGBoost und InluxDB für die Zeitreihenvorhersage
Apr 04, 2023 pm 12:40 PM
So verwenden Sie XGBoost und InluxDB für die Zeitreihenvorhersage
Apr 04, 2023 pm 12:40 PM
XGBoost ist eine beliebte Open-Source-Bibliothek für maschinelles Lernen, die zur Lösung einer Vielzahl von Vorhersageproblemen verwendet werden kann. Man muss verstehen, wie man es mit InfluxDB für Zeitreihenprognosen verwendet. Übersetzer |. Rezensiert von Li Rui |. XGBoost ist eine Open-Source-Bibliothek für maschinelles Lernen, die einen optimierten verteilten Gradienten-Boosting-Algorithmus implementiert. XGBoost verwendet Parallelverarbeitung für eine schnelle Leistung, verarbeitet fehlende Werte gut, bietet eine gute Leistung bei kleinen Datensätzen und verhindert eine Überanpassung. All diese Vorteile machen XGBoost zu einer beliebten Lösung für Regressionsprobleme wie Vorhersagen. Prognosen sind für verschiedene Geschäftsziele wie Predictive Analytics, Predictive Maintenance, Produktplanung, Budgetierung usw. von entscheidender Bedeutung. Bei vielen Prognosen oder Prognoseproblemen handelt es sich um Zeitreihen
 Upgrade auf Vollbild! Das iPhone SE4 ist auf September vorgerückt
Jul 24, 2024 pm 12:56 PM
Upgrade auf Vollbild! Das iPhone SE4 ist auf September vorgerückt
Jul 24, 2024 pm 12:56 PM
Kürzlich wurden auf Weibo neue Neuigkeiten zum iPhone SE4 enthüllt. Es heißt, dass der Backcover-Prozess des iPhone SE4 genau derselbe ist wie der der iPhone 16-Standardversion. Mit anderen Worten, das iPhone SE4 wird eine Glasrückwand verwenden gerader Bildschirm und gerades Kantendesign. Es wird berichtet, dass das iPhone SE4 vor September dieses Jahres auf den Markt kommen wird, was bedeutet, dass es wahrscheinlich gleichzeitig mit dem iPhone 16 vorgestellt wird. 1. Den belichteten Renderings zufolge ähnelt das Frontdesign des iPhone SE4 dem des iPhone 13, mit einer Frontkamera und einem FaceID-Sensor auf dem Notch-Bildschirm. Die Rückseite weist ein ähnliches Layout wie das iPhoneXr auf, verfügt jedoch nur über eine Kamera und kein umfassendes Kameramodul.
 Quantilregression für probabilistische Zeitreihenprognosen
May 07, 2024 pm 05:04 PM
Quantilregression für probabilistische Zeitreihenprognosen
May 07, 2024 pm 05:04 PM
Ändern Sie nicht die Bedeutung des ursprünglichen Inhalts, optimieren Sie den Inhalt nicht, schreiben Sie den Inhalt neu und fahren Sie nicht fort. „Die Quantilregression erfüllt diesen Bedarf, indem sie Vorhersageintervalle mit quantifizierten Chancen bereitstellt. Dabei handelt es sich um eine statistische Technik zur Modellierung der Beziehung zwischen einer Prädiktorvariablen und einer Antwortvariablen, insbesondere wenn die bedingte Verteilung der Antwortvariablen von Interesse ist. Im Gegensatz zur herkömmlichen Regression Methoden: Die Quantilregression konzentriert sich auf die Schätzung der bedingten Größe der Antwortvariablen und nicht auf den bedingten Mittelwert Quantile der erklärten Variablen Y. Das bestehende Regressionsmodell ist eigentlich eine Methode zur Untersuchung der Beziehung zwischen der erklärten Variablen und der erklärenden Variablen. Sie konzentrieren sich auf die Beziehung zwischen erklärenden Variablen und erklärten Variablen
 Wie groß ist der 1-Zoll-Sensor eines Mobiltelefons? Er ist tatsächlich größer als der 1-Zoll-Sensor einer Kamera
May 08, 2024 pm 06:40 PM
Wie groß ist der 1-Zoll-Sensor eines Mobiltelefons? Er ist tatsächlich größer als der 1-Zoll-Sensor einer Kamera
May 08, 2024 pm 06:40 PM
Im gestrigen Artikel wurde die „Sensorgröße“ nicht erwähnt. Ich hatte nicht erwartet, dass es so viele Missverständnisse geben würde ... Wie viel ist 1 Zoll? Aufgrund einiger historischer Probleme* beträgt „1 Zoll“ in der Diagonalenlänge des Sensors nicht 25,4 mm, unabhängig davon, ob es sich um eine Kamera oder ein Mobiltelefon handelt. *Bei Vakuumröhren gibt es hier keine Ausdehnung. Es ist ein bisschen so, als ob der Hintern eines Pferdes über die Breite einer Eisenbahnschiene entscheidet. Um Missverständnisse zu vermeiden, lautet die strengere Schreibweise „Typ 1.0“ oder „Typ 1.0“. Wenn die Sensorgröße außerdem kleiner als 1/2 Typ ist, ist Typ 1 = 18 mm, und wenn die Sensorgröße größer oder gleich 1/2 Typ ist, ist Typ 1 =
 Mar 18, 2024 am 09:20 AM
Mar 18, 2024 am 09:20 AM
Heute möchte ich eine aktuelle Forschungsarbeit der University of Connecticut vorstellen, die eine Methode zum Abgleichen von Zeitreihendaten mit großen NLP-Modellen (Natural Language Processing) im latenten Raum vorschlägt, um die Leistung von Zeitreihenprognosen zu verbessern. Der Schlüssel zu dieser Methode besteht darin, latente räumliche Hinweise (Eingabeaufforderungen) zu verwenden, um die Genauigkeit von Zeitreihenvorhersagen zu verbessern. Titel des Papiers: S2IP-LLM: SemanticSpaceInformedPromptLearningwithLLMforTimeSeriesForecasting Download-Adresse: https://arxiv.org/pdf/2403.05798v1.pdf 1. Hintergrundmodell für große Probleme
