

Dinge über die Linux-Byte-Ausrichtung

Vor kurzem habe ich an einem Projekt gearbeitet und bin auf ein Problem gestoßen. Wenn ThreadX, das auf ARM ausgeführt wird, mit dem DSP kommuniziert, verwendet es eine Nachrichtenwarteschlange, um Nachrichten zu übermitteln (die endgültige Implementierung verwendet Interrupts und Shared-Memory-Methoden). Während des tatsächlichen Betriebs wurde jedoch festgestellt, dass ThreadX häufig abstürzte. Nach einer Untersuchung wurde festgestellt, dass das Problem darin liegt, dass die Struktur, die die Nachricht weiterleitet, die Byteausrichtung nicht berücksichtigt.
Ich möchte die Probleme mit der Byteausrichtung in der C-Sprache klären und sie mit Ihnen teilen.
1. Konzept
Die Byteausrichtung hängt mit der Position der Daten im Speicher zusammen. Wenn die Speicheradresse einer Variablen genau ein ganzzahliges Vielfaches ihrer Länge ist, spricht man von natürlicher Ausrichtung. Wenn beispielsweise unter einer 32-Bit-CPU angenommen wird, dass die Adresse einer Ganzzahlvariablen 0x00000004 ist, ist sie natürlich ausgerichtet.
Verstehen Sie zunächst, was Bits, Bytes und Wörter sind
| Name | Englischer Name | Bedeutung |
|---|---|---|
| Bits | bit | 1 Binärziffer heißt 1 Bit |
| Byte | Byte | 8 Binärbits werden als 1 Byte bezeichnet |
| Wörter | Wort | Eine feste Länge, die von Computern verwendet wird, um Transaktionen gleichzeitig zu verarbeiten |
Länge
Die Anzahl der Bits in einem Wort, die Wortlänge moderner Computer beträgt normalerweise 16, 32 oder 64 Bit. (Im Allgemeinen beträgt die Wortlänge von N-Bit-Systemen N/8 Bytes.)
Verschiedene CPUs können eine unterschiedliche Anzahl von Datenbits gleichzeitig verarbeiten. Eine 32-Bit-CPU kann jeweils 32-Bit-Daten verarbeiten, und eine 64-Bit-CPU kann jeweils 64-Bit-Daten verarbeiten die Wortlänge.
Die sogenannte Wortlänge wird manchmal als Wort bezeichnet. In einer 16-Bit-CPU besteht ein Wort aus genau zwei Bytes, während in einer 32-Bit-CPU ein Wort aus vier Bytes besteht. Wenn wir Wörter als Einheit nehmen, gibt es Doppelwörter (zwei Wörter) und vier Wörter (vier Wörter) aufwärts.
2. Ausrichtungsregeln
Bei Standard-Datentypen muss seine Adresse nur ein ganzzahliges Vielfaches seiner Länge sein. Nicht-Standard-Datentypen werden nach den folgenden Prinzipien ausgerichtet: Array: Ausrichtung nach Basisdatentypen. Wenn der erste Datentyp ausgerichtet ist, gilt Folgendes diejenigen werden natürlich ausgerichtet. Union: Ausgerichtet nach dem darin enthaltenen Datentyp mit der größten Länge. Struktur: Jeder Datentyp in der Struktur muss ausgerichtet sein.
3. Wie kann die Anzahl der festen Byte-Ausrichtungsbits begrenzt werden?
1. Standard
Standardmäßig weist der C-Compiler Platz für jede Variable oder Dateneinheit entsprechend ihren natürlichen Randbedingungen zu. Im Allgemeinen können die Standardrandbedingungen mit den folgenden Methoden geändert werden:
2. #pragma pack(n)
· Mit der Direktive #pragma pack (n) richtet sich der C-Compiler um n Bytes aus. · Verwenden Sie die Direktive #pragma pack(), um die benutzerdefinierte Byteausrichtung abzubrechen.
#pragma pack(n) wird verwendet, um Variablen auf n-Byte-Ausrichtung einzustellen. N-Byte-Ausrichtung bedeutet, dass es zwei Situationen für den Offset der Startadresse gibt, an der die Variable gespeichert wird:
- Wenn n größer oder gleich der Anzahl der von der Variablen belegten Bytes ist, muss der Offset der Standardausrichtung entsprechen
- Wenn n kleiner ist als die Anzahl der vom Variablentyp belegten Bytes, ist der Offset ein Vielfaches von n und muss nicht der Standardausrichtung entsprechen.
Die Gesamtgröße der Struktur unterliegt ebenfalls einer Einschränkung. Wenn n größer oder gleich der Anzahl der von allen Mitgliedsvariablentypen belegten Bytes ist, muss die Gesamtgröße der Struktur ein Vielfaches des von ihr belegten Speicherplatzes sein Variable mit dem größten Leerzeichen; andernfalls müssen es n Vielfache sein.
3. __Attribut
Darüber hinaus gibt es die folgende Methode: · __attribute((aligned (n))), die es ermöglicht, die Strukturelemente an der natürlichen Grenze von n Bytes auszurichten. Wenn die Länge eines Elements in der Struktur größer als n ist, wird es entsprechend der Länge des größten Elements ausgerichtet. · Attribut ((gepackt)), bricht die optimierte Ausrichtung der Struktur während des Kompilierungsprozesses ab und richtet sie entsprechend der tatsächlich belegten Anzahl von Bytes aus.
3. Compilation.align
Assembly-Code verwendet normalerweise .align, um die Anzahl der Byte-Ausrichtungsbits anzugeben.
.align: Wird zur Angabe der Datenausrichtung verwendet. Das Format lautet wie folgt:
.align [absexpr1, absexpr2]
Palle ungenutzte Speicherbereiche mit Werten in einer bestimmten Ausrichtung. Der erste Wert stellt die Ausrichtung dar, 4, 8, 16 oder 32. Der zweite Ausdruckswert stellt den gefüllten Wert dar.
四、为什么要对齐?
操作系统并非一个字节一个字节访问内存,而是按2,4,8这样的字长来访问。因此,当CPU从存储器读数据到寄存器,IO的数据长度通常是字长。如32位系统访问粒度是4字节(bytes), 64位系统的是8字节。当被访问的数据长度为n字节且该数据地址为n字节对齐时,那么操作系统就可以高效地一次定位到数据, 无需多次读取,处理对齐运算等额外操作。数据结构应该尽可能地在自然边界上对齐。如果访问未对齐的内存,CPU需要做两次内存访问。
字节对齐可能带来的隐患:
代码中关于对齐的隐患,很多是隐式的。比如在强制类型转换的时候。例如:
unsigned int i = 0x12345678; unsigned char *p=NULL; unsigned short *p1=NULL; p=&i; *p=0x00; p1=(unsigned short *)(p+1); *p1=0x0000;
最后两句代码,从奇数边界去访问unsignedshort型变量,显然不符合对齐的规定。在x86上,类似的操作只会影响效率,但是在MIPS或者sparc上,可能就是一个error,因为它们要求必须字节对齐.
五、举例
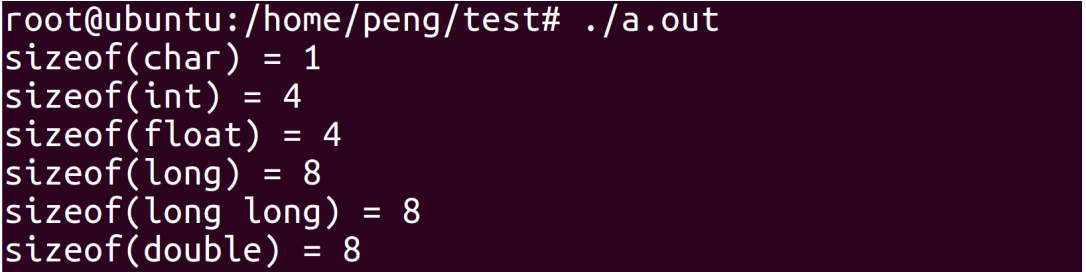
例1:os基本数据类型占用的字节数
首先查看操作系统的位数
在64位操作系统下查看基本数据类型占用的字节数:
#include
int main()
{
printf("sizeof(char) = %ld\n", sizeof(char));
printf("sizeof(int) = %ld\n", sizeof(int));
printf("sizeof(float) = %ld\n", sizeof(float));
printf("sizeof(long) = %ld\n", sizeof(long));
printf("sizeof(long long) = %ld\n", sizeof(long long));
printf("sizeof(double) = %ld\n", sizeof(double));
return 0;
}
例2:结构体占用的内存大小–默认规则
考虑下面的结构体占用的位数
struct yikou_s
{
double d;
char c;
int i;
} yikou_t;
执行结果
sizeof(yikou_t) = 16
在内容中各变量位置关系如下:
其中成员C的位置
还受字节序的影响,有的可能在位置8
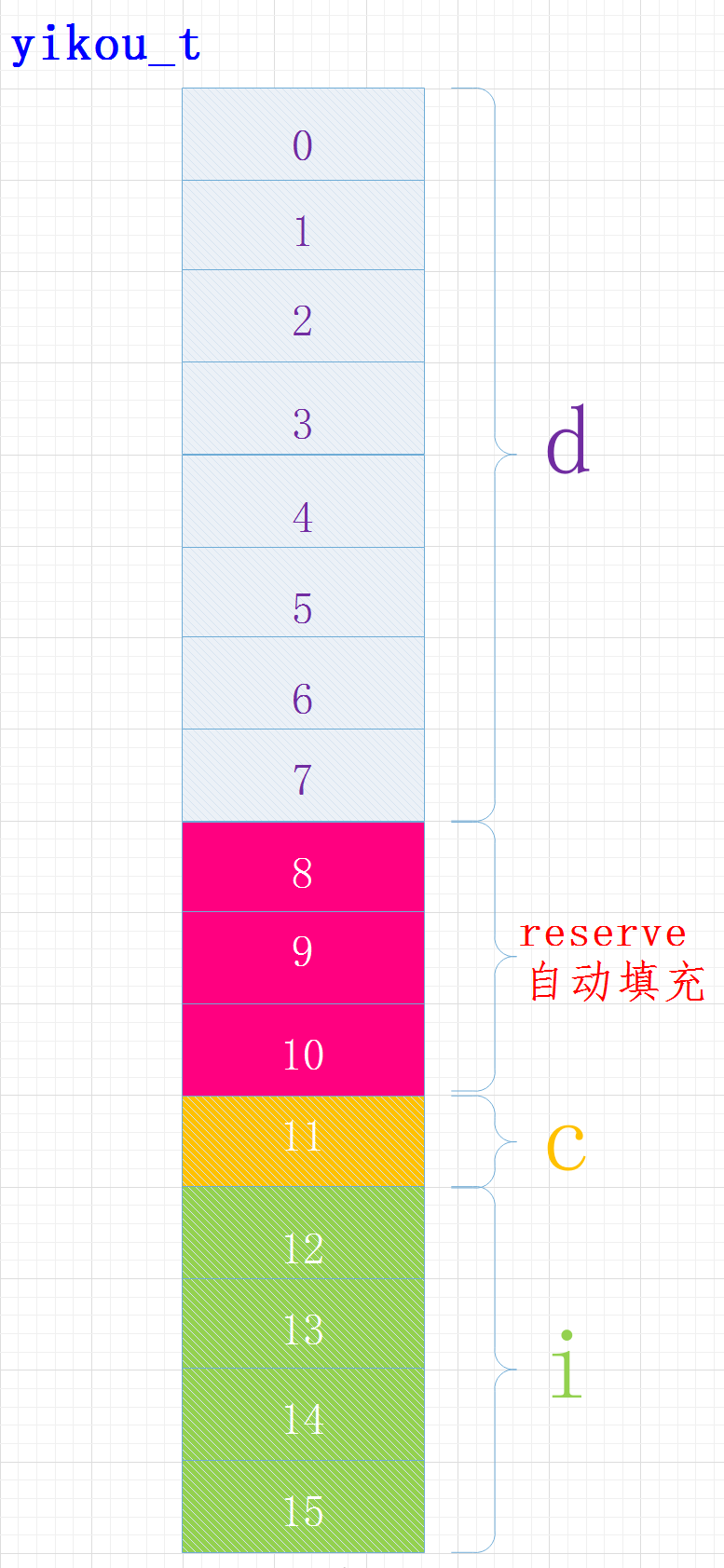 还受字节序的影响,有的可能在位置8
还受字节序的影响,有的可能在位置8编译器给我们进行了内存对齐,各成员变量存放的起始地址相对于结构的起始地址的偏移量必须为该变量类型所占用的字节数的倍数, 且结构的大小为该结构中占用最大空间的类型所占用的字节数的倍数。
对于偏移量:变量type n起始地址相对于结构体起始地址的偏移量必须为sizeof(type(n))的倍数结构体大小:必须为成员最大类型字节的倍数
char: 偏移量必须为sizeof(char) 即1的倍数 int: 偏移量必须为sizeof(int) 即4的倍数 float: 偏移量必须为sizeof(float) 即4的倍数 double: 偏移量必须为sizeof(double) 即8的倍数
例3:调整结构体大小
我们将结构体中变量的位置做以下调整:
struct yikou_s
{
char c;
double d;
int i;
} yikou_t;
执行结果
sizeof(yikou_t) = 24
各变量在内存中布局如下:
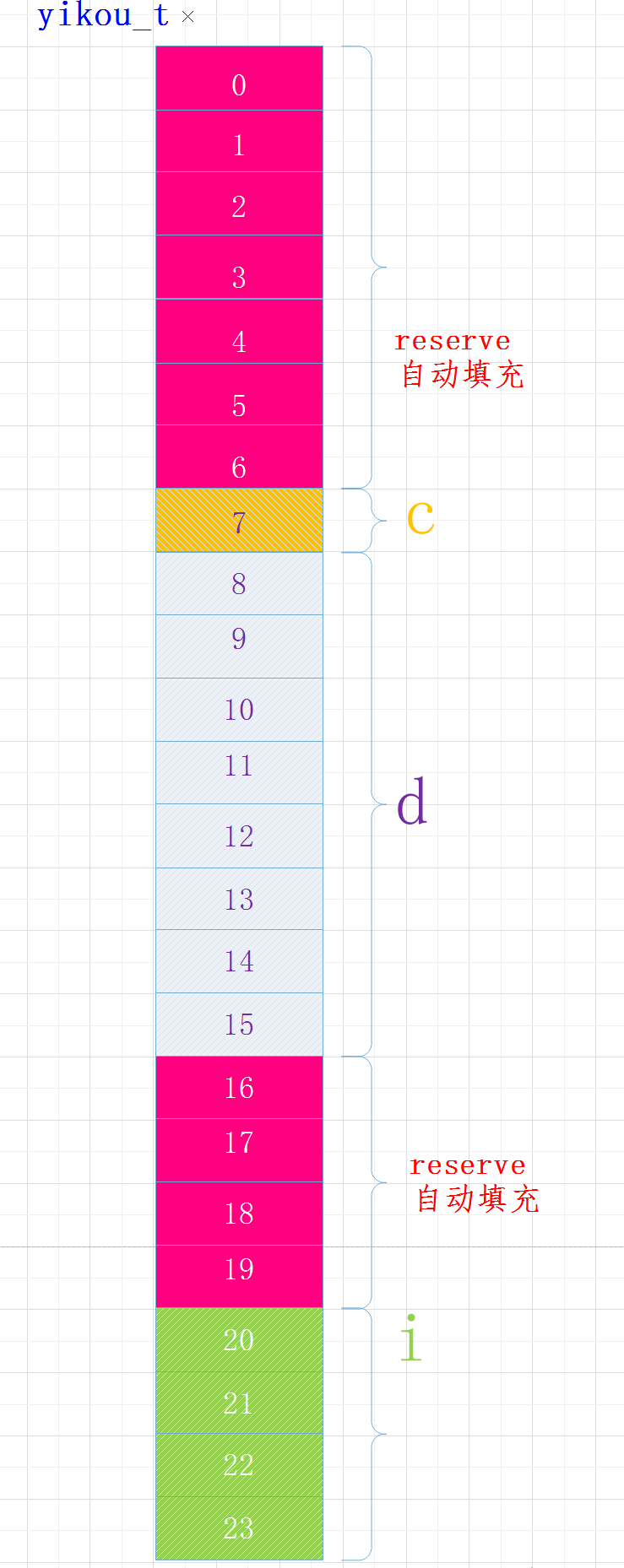
当结构体中有嵌套符合成员时,复合成员相对于结构体首地址偏移量是复合成员最宽基本类型大小的整数倍。
例4:#pragma pack(4)
#pragma pack(4)
struct yikou_s
{
char c;
double d;
int i;
} yikou_t;
sizeof(yikou_t) = 16
例5:#pragma pack(8)
#pragma pack(8)
struct yikou_s
{
char c;
double d;
int i;
} yikou_t;
sizeof(yikou_t) = 24
例6:汇编代码
举例:以下是截取的uboot代码中异常向量irq、fiq的入口位置代码: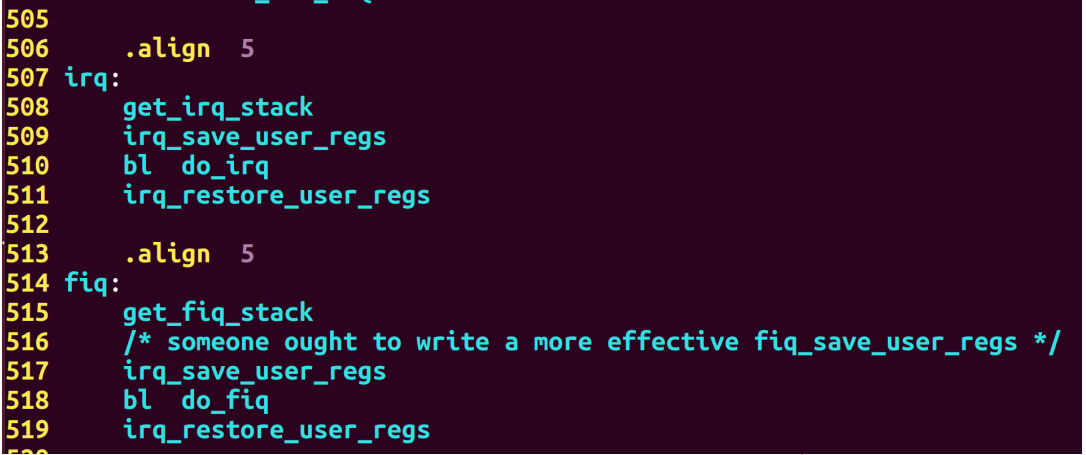
六、汇总实力
有手懒的同学,直接贴一个完整的例子给你们:
#include
main()
{
struct A {
int a;
char b;
short c;
};
struct B {
char b;
int a;
short c;
};
struct AA {
// int a;
char b;
short c;
};
struct BB {
char b;
// int a;
short c;
};
#pragma pack (2) /*指定按2字节对齐*/
struct C {
char b;
int a;
short c;
};
#pragma pack () /*取消指定对齐,恢复缺省对齐*/
#pragma pack (1) /*指定按1字节对齐*/
struct D {
char b;
int a;
short c;
};
#pragma pack ()/*取消指定对齐,恢复缺省对齐*/
int s1=sizeof(struct A);
int s2=sizeof(struct AA);
int s3=sizeof(struct B);
int s4=sizeof(struct BB);
int s5=sizeof(struct C);
int s6=sizeof(struct D);
printf("%d\n",s1);
printf("%d\n",s2);
printf("%d\n",s3);
printf("%d\n",s4);
printf("%d\n",s5);
printf("%d\n",s6);
}
Das obige ist der detaillierte Inhalt vonDinge über die Linux-Byte-Ausrichtung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Welche Computerkonfiguration ist für VSCODE erforderlich?
Apr 15, 2025 pm 09:48 PM
Welche Computerkonfiguration ist für VSCODE erforderlich?
Apr 15, 2025 pm 09:48 PM
VS Code system requirements: Operating system: Windows 10 and above, macOS 10.12 and above, Linux distribution processor: minimum 1.6 GHz, recommended 2.0 GHz and above memory: minimum 512 MB, recommended 4 GB and above storage space: minimum 250 MB, recommended 1 GB and above other requirements: stable network connection, Xorg/Wayland (Linux)
 VSCODE kann die Erweiterung nicht installieren
Apr 15, 2025 pm 07:18 PM
VSCODE kann die Erweiterung nicht installieren
Apr 15, 2025 pm 07:18 PM
Die Gründe für die Installation von VS -Code -Erweiterungen können sein: Netzwerkinstabilität, unzureichende Berechtigungen, Systemkompatibilitätsprobleme, VS -Code -Version ist zu alt, Antiviren -Software oder Firewall -Interferenz. Durch Überprüfen von Netzwerkverbindungen, Berechtigungen, Protokolldateien, Aktualisierungen von VS -Code, Deaktivieren von Sicherheitssoftware und Neustart von Code oder Computern können Sie Probleme schrittweise beheben und beheben.
 So führen Sie Java -Code in Notepad aus
Apr 16, 2025 pm 07:39 PM
So führen Sie Java -Code in Notepad aus
Apr 16, 2025 pm 07:39 PM
Obwohl Notepad den Java -Code nicht direkt ausführen kann, kann er durch Verwendung anderer Tools erreicht werden: Verwenden des Befehlszeilencompilers (JAVAC), um eine Bytecode -Datei (Dateiname.class) zu generieren. Verwenden Sie den Java Interpreter (Java), um Bytecode zu interpretieren, den Code auszuführen und das Ergebnis auszugeben.
 Linux -Architektur: Enthüllung der 5 Grundkomponenten
Apr 20, 2025 am 12:04 AM
Linux -Architektur: Enthüllung der 5 Grundkomponenten
Apr 20, 2025 am 12:04 AM
Die fünf grundlegenden Komponenten des Linux -Systems sind: 1. Kernel, 2. Systembibliothek, 3. System Utilities, 4. Grafische Benutzeroberfläche, 5. Anwendungen. Der Kernel verwaltet Hardware -Ressourcen, die Systembibliothek bietet vorkompilierte Funktionen, Systemversorgungsunternehmen werden für die Systemverwaltung verwendet, die GUI bietet visuelle Interaktion und Anwendungen verwenden diese Komponenten, um Funktionen zu implementieren.
 So verwenden Sie VSCODE
Apr 15, 2025 pm 11:21 PM
So verwenden Sie VSCODE
Apr 15, 2025 pm 11:21 PM
Visual Studio Code (VSCODE) ist ein plattformübergreifender, Open-Source-Editor und kostenloser Code-Editor, der von Microsoft entwickelt wurde. Es ist bekannt für seine leichte, Skalierbarkeit und Unterstützung für eine Vielzahl von Programmiersprachen. Um VSCODE zu installieren, besuchen Sie bitte die offizielle Website, um das Installateur herunterzuladen und auszuführen. Bei der Verwendung von VSCODE können Sie neue Projekte erstellen, Code bearbeiten, Code bearbeiten, Projekte navigieren, VSCODE erweitern und Einstellungen verwalten. VSCODE ist für Windows, MacOS und Linux verfügbar, unterstützt mehrere Programmiersprachen und bietet verschiedene Erweiterungen über den Marktplatz. Zu den Vorteilen zählen leicht, Skalierbarkeit, umfangreiche Sprachunterstützung, umfangreiche Funktionen und Versionen
 Kann VSCODE für MAC verwendet werden
Apr 15, 2025 pm 07:36 PM
Kann VSCODE für MAC verwendet werden
Apr 15, 2025 pm 07:36 PM
VS -Code ist auf Mac verfügbar. Es verfügt über leistungsstarke Erweiterungen, GIT -Integration, Terminal und Debugger und bietet auch eine Fülle von Setup -Optionen. Für besonders große Projekte oder hoch berufliche Entwicklung kann VS -Code jedoch Leistung oder funktionale Einschränkungen aufweisen.
 Wofür ist VSCODE Wofür ist VSCODE?
Apr 15, 2025 pm 06:45 PM
Wofür ist VSCODE Wofür ist VSCODE?
Apr 15, 2025 pm 06:45 PM
VS Code ist der vollständige Name Visual Studio Code, der eine kostenlose und open-Source-plattformübergreifende Code-Editor und Entwicklungsumgebung von Microsoft ist. Es unterstützt eine breite Palette von Programmiersprachen und bietet Syntax -Hervorhebung, automatische Codebettel, Code -Snippets und intelligente Eingabeaufforderungen zur Verbesserung der Entwicklungseffizienz. Durch ein reiches Erweiterungs -Ökosystem können Benutzer bestimmte Bedürfnisse und Sprachen wie Debugger, Code -Formatierungs -Tools und Git -Integrationen erweitern. VS -Code enthält auch einen intuitiven Debugger, mit dem Fehler in Ihrem Code schnell gefunden und behoben werden können.
 So überprüfen Sie die Lageradresse von Git
Apr 17, 2025 pm 01:54 PM
So überprüfen Sie die Lageradresse von Git
Apr 17, 2025 pm 01:54 PM
Um die Git -Repository -Adresse anzuzeigen, führen Sie die folgenden Schritte aus: 1. Öffnen Sie die Befehlszeile und navigieren Sie zum Repository -Verzeichnis; 2. Führen Sie den Befehl "git remote -v" aus; 3.. Zeigen Sie den Repository -Namen in der Ausgabe und der entsprechenden Adresse an.
