

Detaillierte Erläuterung des Linux-Programmkompilierungsprozesses

Computerprogrammiersprachen werden normalerweise in drei Kategorien unterteilt: Maschinensprache, Assemblersprache und Hochsprache. Hochsprachen müssen in Maschinensprache übersetzt werden, bevor sie ausgeführt werden können. Es gibt zwei Arten der Übersetzung: eine wird kompiliert und die andere wird interpretiert.
Daher teilen wir Hochsprachen grundsätzlich in zwei Kategorien ein: Eine davon sind kompilierte Sprachen wie C, C++, Java und die andere sind interpretierte Sprachen wie Python, Ruby, MATLAB und JavaScript.
In diesem Artikel wird der Prozess der Konvertierung von High-Level-Programmen, die in der Sprache C/C++ geschrieben sind, in Binärcodes vorgestellt, die vom Prozessor ausgeführt werden können, einschließlich vier Schritten:
- Vorverarbeitung
- Zusammenstellung
- Montage
- Verlinkung
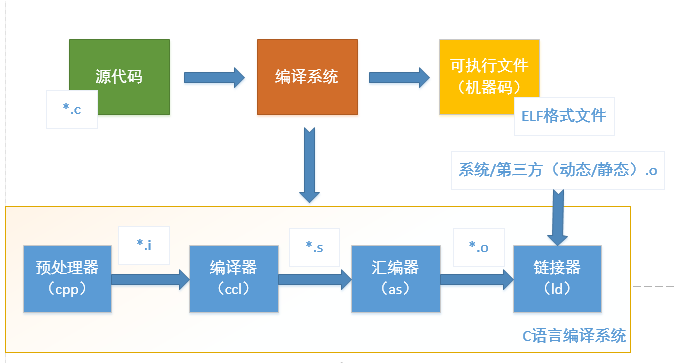
Einführung in die GCC-Toolkette
Der allgemein als GCC bezeichnete Code ist die Abkürzung für GUN Compiler Collection, ein häufig verwendetes Kompilierungstool auf Linux-Systemen. Die GCC-Toolkettensoftware umfasst GCC, Binutils, C-Laufzeitbibliothek usw.
GCC
GCC (GNU C Compiler) ist ein Kompilierungstool. In diesem Artikel wird der Prozess der Konvertierung eines in der Sprache C/C++ geschriebenen Programms in einen Binärcode vorgestellt, der vom Prozessor ausgeführt werden kann und der vom Compiler vervollständigt wird.
Binutils
Eine Reihe von Tools zur Verarbeitung binärer Programme, darunter: addr2line, ar, objcopy, objdump, as, ld, ldd, readelf, size usw. Diese Tools sind ein unverzichtbares Tool für die Entwicklung und das Debuggen. Ihre jeweiligen Einführungen sind wie folgt:
- addr2line: Wird verwendet, um die Programmadresse in die entsprechende Programmquelldatei und die entsprechende Codezeile umzuwandeln und auch die entsprechende Funktion zu erhalten. Dieses Tool hilft dem Debugger beim Debuggen, den entsprechenden Quellcodespeicherort zu finden.
- als: Wird hauptsächlich für die Montage verwendet. Eine detaillierte Einführung in die Montage finden Sie im folgenden Artikel.
- ld: Wird hauptsächlich für Links verwendet. Einzelheiten zu Links finden Sie im folgenden Artikel.
- ar: Wird hauptsächlich zum Erstellen statischer Bibliotheken verwendet. Um Anfängern das Verständnis zu erleichtern, werden hier die Konzepte dynamischer Bibliotheken und statischer Bibliotheken vorgestellt:
- Wenn Sie mehrere .o-Zieldateien in einer Bibliotheksdatei generieren möchten, gibt es zwei Arten von Bibliotheken: eine statische Bibliothek und eine dynamische Bibliothek.
- In Windows sind statische Bibliotheken Dateien mit dem Suffix .lib und gemeinsam genutzte Bibliotheken sind Dateien mit dem Suffix .dll. Unter Linux sind statische Bibliotheken Dateien mit dem Suffix .a und gemeinsam genutzte Bibliotheken sind Dateien mit dem Suffix .so.
- Der Unterschied zwischen statischen Bibliotheken und dynamischen Bibliotheken liegt in der Zeit, zu der der Code geladen wird. Der Code der statischen Bibliothek wurde während des Kompilierungsprozesses in das ausführbare Programm geladen und ist daher größer. Der Code der gemeinsam genutzten Bibliothek wird beim Ausführen des ausführbaren Programms in den Speicher geladen und während des Kompilierungsprozesses nur referenziert, sodass die Codegröße kleiner ist. In Linux-Systemen können Sie den Befehl ldd verwenden, um die gemeinsam genutzten Bibliotheken anzuzeigen, von denen ein ausführbares Programm abhängt.
- Wenn es in einem System mehrere Programme gibt, die gleichzeitig ausgeführt werden müssen, und zwischen diesen Programmen gemeinsam genutzte Bibliotheken vorhanden sind, spart die Verwendung einer dynamischen Bibliothek mehr Speicher.
- ldd: kann verwendet werden, um die gemeinsam genutzten Bibliotheken anzuzeigen, von denen ein ausführbares Programm abhängt.
- objcopy: Übersetzen Sie eine Objektdatei in ein anderes Format, z. B. Konvertieren von .bin in .elf oder Konvertieren von .elf in .bin usw.
- objdump: Seine Hauptfunktion ist die Demontage. Eine ausführliche Einführung in die Demontage finden Sie im folgenden Artikel.
- readelf: Zeigt Informationen zu ELF-Dateien an. Weitere Informationen finden Sie später.
- Größe: Listen Sie die Größe und Gesamtgröße jedes Teils der ausführbaren Datei, des Codesegments, des Datensegments, der Gesamtgröße usw. auf. Spezifische Anwendungsbeispiele für die Verwendung der Größe finden Sie im folgenden Artikel.
C-Laufzeitbibliothek
Der C-Sprachstandard besteht hauptsächlich aus zwei Teilen: Ein Teil beschreibt die Syntax von C und der andere Teil beschreibt die C-Standardbibliothek. Die C-Standardbibliothek definiert eine Reihe von Standard-Header-Dateien. Jede Header-Datei enthält einige verwandte Funktionen, Variablen, Typdeklarationen und Makrodefinitionen. Beispielsweise ist die allgemeine printf-Funktion eine C-Standardbibliotheksfunktion, und ihr Prototyp ist in stdio definiert Header-Datei.
C语言标准仅仅定义了C标准库函数原型,并没有提供实现。因此,C语言编译器通常需要一个C运行时库(C Run Time Libray,CRT)的支持。C运行时库又常简称为C运行库。与C语言类似,C++也定义了自己的标准,同时提供相关支持库,称为C++运行时库。
准备工作
由于GCC工具链主要是在Linux环境中进行使用,因此本文也将以Linux系统作为工作环境。为了能够演示编译的整个过程,本节先准备一个C语言编写的简单Hello程序作为示例,其源代码如下所示:
#include
//此程序很简单,仅仅打印一个Hello World的字符串。
int main(void)
{
printf("Hello World! \n");
return 0;
}
“
编译过程
1.预处理
预处理的过程主要包括以下过程:
- 将所有的#define删除,并且展开所有的宏定义,并且处理所有的条件预编译指令,比如#if #ifdef #elif #else #endif等。
- 处理#include预编译指令,将被包含的文件插入到该预编译指令的位置。
- 删除所有注释“//”和“/* */”。
- 添加行号和文件标识,以便编译时产生调试用的行号及编译错误警告行号。
- 保留所有的#pragma编译器指令,后续编译过程需要使用它们。
使用gcc进行预处理的命令如下:
$ gcc -E hello.c -o hello.i // 将源文件hello.c文件预处理生成hello.i // GCC的选项-E使GCC在进行完预处理后即停止
hello.i文件可以作为普通文本文件打开进行查看,其代码片段如下所示:
// hello.i代码片段
extern void funlockfile (FILE *__stream) __attribute__ ((__nothrow__ , __leaf__));
# 942 "/usr/include/stdio.h" 3 4
# 2 "hello.c" 2
# 3 "hello.c"
int
main(void)
{
printf("Hello World!" "\n");
return 0;
}
2.编译
编译过程就是对预处理完的文件进行一系列的词法分析,语法分析,语义分析及优化后生成相应的汇编代码。
使用gcc进行编译的命令如下:
$ gcc -S hello.i -o hello.s // 将预处理生成的hello.i文件编译生成汇编程序hello.s // GCC的选项-S使GCC在执行完编译后停止,生成汇编程序
上述命令生成的汇编程序hello.s的代码片段如下所示,其全部为汇编代码。
// hello.s代码片段 main: .LFB0: .cfi_startproc pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 6 movl $.LC0, %edi call puts movl $0, %eax popq %rbp .cfi_def_cfa 7, 8 ret .cfi_endproc
3.汇编
汇编过程调用对汇编代码进行处理,生成处理器能识别的指令,保存在后缀为.o的目标文件中。由于每一个汇编语句几乎都对应一条处理器指令,因此,汇编相对于编译过程比较简单,通过调用Binutils中的汇编器as根据汇编指令和处理器指令的对照表一一翻译即可。
当程序由多个源代码文件构成时,每个文件都要先完成汇编工作,生成.o目标文件后,才能进入下一步的链接工作。注意:目标文件已经是最终程序的某一部分了,但是在链接之前还不能执行。
使用gcc进行汇编的命令如下:
$ gcc -c hello.s -o hello.o // 将编译生成的hello.s文件汇编生成目标文件hello.o // GCC的选项-c使GCC在执行完汇编后停止,生成目标文件 //或者直接调用as进行汇编 $ as -c hello.s -o hello.o //使用Binutils中的as将hello.s文件汇编生成目标文件
注意:hello.o目标文件为ELF(Executable and Linkable Format)格式的可重定向文件。
4.链接
链接也分为静态链接和动态链接,其要点如下:
- 静态链接是指在编译阶段直接把静态库加入到可执行文件中去,这样可执行文件会比较大。链接器将函数的代码从其所在地(不同的目标文件或静态链接库中)拷贝到最终的可执行程序中。为创建可执行文件,链接器必须要完成的主要任务是:符号解析(把目标文件中符号的定义和引用联系起来)和重定位(把符号定义和内存地址对应起来然后修改所有对符号的引用)。
- 动态链接则是指链接阶段仅仅只加入一些描述信息,而程序执行时再从系统中把相应动态库加载到内存中去。
- 在Linux系统中,gcc编译链接时的动态库搜索路径的顺序通常为:首先从gcc命令的参数-L指定的路径寻找;再从环境变量LIBRARY_PATH指定的路径寻址;再从默认路径/lib、/usr/lib、/usr/local/lib寻找。
- 在Linux系统中,执行二进制文件时的动态库搜索路径的顺序通常为:首先搜索编译目标代码时指定的动态库搜索路径;再从环境变量LD_LIBRARY_PATH指定的路径寻址;再从配置文件/etc/ld.so.conf中指定的动态库搜索路径;再从默认路径/lib、/usr/lib寻找。
- 在Linux系统中,可以用ldd命令查看一个可执行程序依赖的共享库。
由于链接动态库和静态库的路径可能有重合,所以如果在路径中有同名的静态库文件和动态库文件,比如libtest.a和libtest.so,gcc链接时默认优先选择动态库,会链接libtest.so,如果要让gcc选择链接libtest.a则可以指定gcc选项-static,该选项会强制使用静态库进行链接。以Hello World为例:
- 如果使用命令“gcc hello.c -o hello”则会使用动态库进行链接,生成的ELF可执行文件的大小(使用Binutils的size命令查看)和链接的动态库(使用Binutils的ldd命令查看)如下所示:
$ gcc hello.c -o hello $ size hello //使用size查看大小 text data bss dec hex filename 1183 552 8 1743 6cf hello $ ldd hello //可以看出该可执行文件链接了很多其他动态库,主要是Linux的glibc动态库 linux-vdso.so.1 => (0x00007fffefd7c000) libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fadcdd82000) /lib64/ld-linux-x86-64.so.2 (0x00007fadce14c000)
如果使用命令“gcc -static hello.c -o hello”则会使用静态库进行链接,生成的ELF可执行文件的大小(使用Binutils的size命令查看)和链接的动态库(使用Binutils的ldd命令查看)如下所示:
$ gcc -static hello.c -o hello $ size hello //使用size查看大小 text data bss dec hex filename 823726 7284 6360 837370 cc6fa hello //可以看出text的代码尺寸变得极大 $ ldd hello not a dynamic executable //说明没有链接动态库
链接器链接后生成的最终文件为ELF格式可执行文件,一个ELF可执行文件通常被链接为不同的段,常见的段譬如.text、.data、.rodata、.bss等段。
分析ELF文件
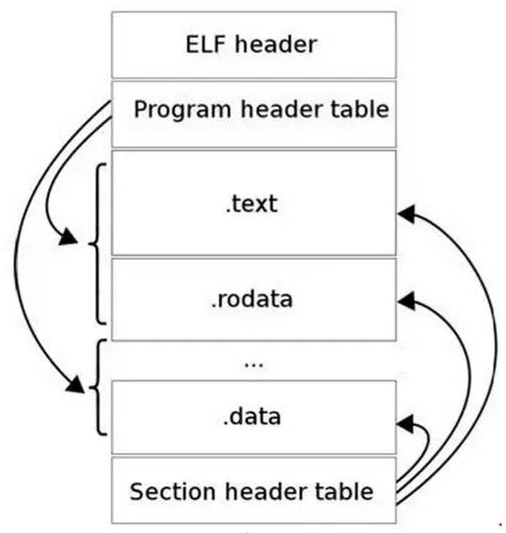
1.ELF文件的段
ELF文件格式如下图所示,位于ELF Header和Section Header Table之间的都是段(Section)。一个典型的ELF文件包含下面几个段:
- .text:已编译程序的指令代码段。
- .rodata:ro代表read only,即只读数据(譬如常数const)。
- .data:已初始化的C程序全局变量和静态局部变量。
- .bss:未初始化的C程序全局变量和静态局部变量。
- .debug:调试符号表,调试器用此段的信息帮助调试。
可以使用readelf -S查看其各个section的信息如下
$ readelf -S hello There are 31 section headers, starting at offset 0x19d8: Section Headers: [Nr] Name Type Address Offset Size EntSize Flags Link Info Align [ 0] NULL 0000000000000000 00000000 0000000000000000 0000000000000000 0 0 0 …… [11] .init PROGBITS 00000000004003c8 000003c8 000000000000001a 0000000000000000 AX 0 0 4 …… [14] .text PROGBITS 0000000000400430 00000430 0000000000000182 0000000000000000 AX 0 0 16 [15] .fini PROGBITS 00000000004005b4 000005b4 ……
2.反汇编ELF
由于ELF文件无法被当做普通文本文件打开,如果希望直接查看一个ELF文件包含的指令和数据,需要使用反汇编的方法。
使用objdump -D对其进行反汇编如下:
$ objdump -D hello …… 0000000000400526 : // main标签的PC地址 //PC地址:指令编码 指令的汇编格式 400526: 55 push %rbp 400527: 48 89 e5 mov %rsp,%rbp 40052a: bf c4 05 40 00 mov $0x4005c4,%edi 40052f: e8 cc fe ff ff callq 400400 400534: b8 00 00 00 00 mov $0x0,%eax 400539: 5d pop %rbp 40053a: c3 retq 40053b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
使用objdump -S将其反汇编并且将其C语言源代码混合显示出来:
$ gcc -o hello -g hello.c //要加上-g选项
$ objdump -S hello
……
0000000000400526 :
#include
int
main(void)
{
400526: 55 push %rbp
400527: 48 89 e5 mov %rsp,%rbp
printf("Hello World!" "\n");
40052a: bf c4 05 40 00 mov $0x4005c4,%edi
40052f: e8 cc fe ff ff callq 400400
return 0;
400534: b8 00 00 00 00 mov $0x0,%eax
}
400539: 5d pop %rbp
40053a: c3 retq
40053b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
……
Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung des Linux-Programmkompilierungsprozesses. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Wie löste ich das Problem der Berechtigungen beim Betrachten der Python -Version in Linux Terminal?
Apr 01, 2025 pm 05:09 PM
Wie löste ich das Problem der Berechtigungen beim Betrachten der Python -Version in Linux Terminal?
Apr 01, 2025 pm 05:09 PM
Lösung für Erlaubnisprobleme beim Betrachten der Python -Version in Linux Terminal Wenn Sie versuchen, die Python -Version in Linux Terminal anzuzeigen, geben Sie Python ein ...
 Warum tritt bei der Installation einer Erweiterung mit PECL in einer Docker -Umgebung ein Fehler auf? Wie löst ich es?
Apr 01, 2025 pm 03:06 PM
Warum tritt bei der Installation einer Erweiterung mit PECL in einer Docker -Umgebung ein Fehler auf? Wie löst ich es?
Apr 01, 2025 pm 03:06 PM
Ursachen und Lösungen für Fehler Bei der Verwendung von PECL zur Installation von Erweiterungen in der Docker -Umgebung, wenn die Docker -Umgebung verwendet wird, begegnen wir häufig auf einige Kopfschmerzen ...
 Wie kann man Node.js oder Python -Dienste in Lampenarchitektur effizient integrieren?
Apr 01, 2025 pm 02:48 PM
Wie kann man Node.js oder Python -Dienste in Lampenarchitektur effizient integrieren?
Apr 01, 2025 pm 02:48 PM
Viele Website -Entwickler stehen vor dem Problem der Integration von Node.js oder Python Services unter der Lampenarchitektur: Die vorhandene Lampe (Linux Apache MySQL PHP) Architekturwebsite benötigt ...
 Wie löste ich Berechtigungsprobleme bei der Verwendung von Python -Verssionsbefehl im Linux Terminal?
Apr 02, 2025 am 06:36 AM
Wie löste ich Berechtigungsprobleme bei der Verwendung von Python -Verssionsbefehl im Linux Terminal?
Apr 02, 2025 am 06:36 AM
Verwenden Sie Python im Linux -Terminal ...
 Wie konfigurieren Sie die Timing -Timing -Aufgabe von ApScheduler als Dienst auf macOS?
Apr 01, 2025 pm 06:09 PM
Wie konfigurieren Sie die Timing -Timing -Aufgabe von ApScheduler als Dienst auf macOS?
Apr 01, 2025 pm 06:09 PM
Konfigurieren Sie die Timing -Timing -Timing -Timing -Timing auf der MacOS -Plattform, wenn Sie die Timing -Timing -Timing -Timing von APScheduler als Service konfigurieren möchten, ähnlich wie bei NGIN ...
 Kann der Python -Dolmetscher im Linux -System gelöscht werden?
Apr 02, 2025 am 07:00 AM
Kann der Python -Dolmetscher im Linux -System gelöscht werden?
Apr 02, 2025 am 07:00 AM
In Bezug auf das Problem der Entfernung des Python -Dolmetschers, das mit Linux -Systemen ausgestattet ist, werden viele Linux -Verteilungen den Python -Dolmetscher bei der Installation vorinstallieren, und verwendet den Paketmanager nicht ...
 Vier Möglichkeiten zur Implementierung von Multithreading in C -Sprache
Apr 03, 2025 pm 03:00 PM
Vier Möglichkeiten zur Implementierung von Multithreading in C -Sprache
Apr 03, 2025 pm 03:00 PM
Multithreading in der Sprache kann die Programmeffizienz erheblich verbessern. Es gibt vier Hauptmethoden, um Multithreading in C -Sprache zu implementieren: Erstellen Sie unabhängige Prozesse: Erstellen Sie mehrere unabhängig laufende Prozesse. Jeder Prozess hat seinen eigenen Speicherplatz. Pseudo-MultitHhreading: Erstellen Sie mehrere Ausführungsströme in einem Prozess, der denselben Speicherplatz freigibt und abwechselnd ausführt. Multi-Thread-Bibliothek: Verwenden Sie Multi-Thread-Bibliotheken wie PThreads, um Threads zu erstellen und zu verwalten, wodurch reichhaltige Funktionen der Thread-Betriebsfunktionen bereitgestellt werden. Coroutine: Eine leichte Multi-Thread-Implementierung, die Aufgaben in kleine Unteraufgaben unterteilt und sie wiederum ausführt.
 So öffnen Sie Web.xml
Apr 03, 2025 am 06:51 AM
So öffnen Sie Web.xml
Apr 03, 2025 am 06:51 AM
Um eine Web.xml -Datei zu öffnen, können Sie die folgenden Methoden verwenden: Verwenden Sie einen Texteditor (z.
