

Anwendungshinweis zu Linux Pipes und FIFO

Übersicht
Der häufigste Platz für Rohre ist im Gehäuse, wie zum Beispiel:
$ ls | wc -l
Um den obigen Befehl auszuführen, erstellt die Shell zwei auszuführende Prozesse (ls 和 wc (通过 fork() 和 exec() Abgeschlossen), wie folgt:
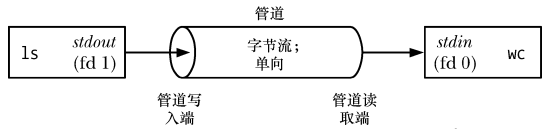
Wie Sie auf dem Bild oben sehen können, kann man sich eine Pipeline als eine Reihe von Wasserleitungen vorstellen, die den Datenfluss von einem Prozess zum anderen ermöglichen, daher der Name Pipe.
Wie Sie auf dem Bild oben sehen können, sind zwei Prozesse mit der Pipe verbunden, sodass der Schreibprozess ls 就将其标准输出(文件描述符为1)连接到来管道的写入段,读取进程 wc seinen Standardeingang (Dateideskriptor 0) mit dem Leseende der Pipe verbindet. Tatsächlich sind sich diese beiden Prozesse der Existenz der Pipe nicht bewusst, sie lesen und schreiben lediglich Daten aus dem Standarddateideskriptor. Die Shell muss die Arbeit erledigen.
Eine Pipe ist ein Bytestream
Eine Pipe ist ein Bytestream, das heißt, es gibt kein Konzept für Nachrichten oder Nachrichtengrenzen, wenn eine Pipe verwendet wird:
- Ein Prozess, der Daten aus einer Pipe liest, kann Datenblöcke jeder Größe lesen, unabhängig von der Größe der Datenblöcke, die vom Schreibprozess in die Pipe geschrieben werden
-
Die durch die Pipe geleiteten Daten sind sequentiell die gleiche wie die Reihenfolge, in der sie in die Pipe geschrieben wurden. Sie können
lseek()nicht verwenden, um zufällig auf Daten in der Pipe zuzugreifen Wenn Sie das Konzept diskreter Nachrichten in einer Pipeline implementieren müssen, müssen Sie diese Arbeit in der Anwendung abschließen. Obwohl dies möglich ist, ist es bei Bedarf besser, andere IPC-Mechanismen wie Nachrichtenwarteschlangen und Datagramm-Sockets zu verwenden.
Der Versuch, aus einer derzeit leeren Pipe zu lesen, wird blockiert, bis mindestens ein Byte in die Pipe geschrieben wurde.
Wenn das schreibende Ende der Pipe geschlossen ist, sieht der Prozess, der Daten aus der Pipe liest, das Ende der Datei (d. h.
gibt 0 zurück), nachdem er alle in der Pipe verbleibenden Daten gelesen hat.
read()
Die Übertragungsrichtung der Daten in der Pipeline ist unidirektional. Ein Ende der Pipe dient zum Schreiben und das andere Ende zum Lesen.
Bei einigen anderen UNIX-Implementierungen, insbesondere denen, die aus System V Release 4 entwickelt wurden, sind Pipes bidirektional (sogenannte Stream-Pipes). Bidirektionale Pipes sind in keinem UNIX-Standard spezifiziert, daher ist es am besten, sich nicht auf diese Semantik zu verlassen, selbst bei Implementierungen, die bidirektionale Pipes bereitstellen. Alternativ kann ein UNIX-Domänen-Stream-Socket-Paar (erstellt über den socketpair()-Systemaufruf) verwendet werden, das einen standardmäßigen bidirektionalen Kommunikationsmechanismus bereitstellt und dessen Semantik Stream-Pipes entspricht.
Stellt sicher, dass das Schreiben von nicht mehr als PIPE_BUF Bytes atomar ist
Wenn mehrere Prozesse in dieselbe Pipe schreiben und die Datenmenge, die sie gleichzeitig schreiben, die PIPE_BUF-Bytes nicht überschreitet, kann sichergestellt werden, dass die geschriebenen Daten nicht miteinander vermischt werden.
SUSv3 erfordert, dass PIPE_BUF mindestens _POSIX_PIPE_BUF(512)。一个实现应该定义 PIPE_BUF(在 <limits.h></limits.h> 中)并/或允许调用 fpathconf(fd,_PC_PIPE_BUF) ist, um die tatsächliche Obergrenze für atomare Schreibvorgänge zurückzugeben. PIPE_BUF variiert je nach UNIX-Implementierung. Unter FreeBSD 6.0 beträgt der Wert beispielsweise 512 Byte, unter Tru64 5.1 beträgt der Wert 4096 Byte und unter Solaris 8 beträgt der Wert 5120 Byte. Unter Linux beträgt der Wert von PIPE_BUF 4096.
-
Wenn die Größe des in die Pipe geschriebenen Datenblocks PIPE_BUF Bytes überschreitet, kann der Kernel die Daten zur Übertragung in mehrere kleinere Fragmente aufteilen und nachfolgende Daten anhängen, wenn der Leser die Daten aus der Pipe verbraucht (
write()Der Aufruf wird blockiert, bis alle Daten vorhanden sind wird in die Pipe geschrieben) - Wenn nur ein Prozess Daten in die Pipe schreibt (die übliche Situation), spielt der Wert von PIPE_BUF keine Rolle
- Wenn jedoch mehrere Schreibprozesse vorhanden sind, kann das Schreiben großer Datenblöcke in Segmente beliebiger Größe (die kleiner als PIPE_BUF-Bytes sein können) aufgeteilt werden und sich mit Daten überschneiden, die von anderen Prozessen geschrieben wurden
Das PIPE_BUF-Limit wird nur wirksam, wenn Daten an die Pipe übertragen werden. Wenn die geschriebenen Daten PIPE_BUF-Bytes erreichen, blockiert write() 会在必要的时候阻塞知道管道中的可用空间足以原子的完成此操作。如果写入的数据大于 PIPE_BUF 字节,那么 write() 会尽可能的多传输数据以充满整个管道,然后阻塞直到一些读取进程从管道中移除了数据。如果此类阻塞的 write() bei Bedarf, bis genügend freier Speicherplatz in der Pipe vorhanden ist, um den Vorgang atomar abzuschließen. Wenn die geschriebenen Daten größer als PIPE_BUF Bytes sind, überträgt
durch einen Signalhandler unterbrochen wird, wird der Aufruf entsperrt und die Anzahl der erfolgreich an die Pipe übertragenen Bytes zurückgegeben, die geringer ist als die Anzahl der zum Schreiben angeforderten Bytes (sogenanntes teilweise geschriebenes). .
Die Kapazität der Pipeline ist begrenztEine Pipe ist eigentlich ein Puffer, der im Kernel-Speicher verwaltet wird. Die Speicherkapazität dieses Puffers ist begrenzt. Sobald die Pipe gefüllt ist, werden nachfolgende Schreibvorgänge in die Pipe blockiert, bis der Leser einige Daten aus der Pipe entfernt.
🎜SUSv3 gibt nicht die Speicherkapazität der Pipeline an. In Linux-Kerneln vor 2.6.11 stimmt die Speicherkapazität der Pipe mit der Systemseitengröße überein (z. B. 4096 Byte auf x86-32), und ab Linux 2.6.11 beträgt die Speicherkapazität der Pipe 65.536 Byte. Die Speicherkapazitäten von Pipes in anderen UNIX-Implementierungen können variieren. 🎜一般来讲,一个应用程序无需知道管道的实际存储能力。如果需要防止写者进程阻塞,那么从管道中读取数据的进程应该被设计成以尽可能快的速度从管道中读取数据。
创建和使用管道
#include int pipe(int fd[2]);
-
pipe()创建一个新管道 -
成功的调用在数组
fd中返回两个打开的文件描述符,一个表示管道的读取端fd[0],一个表示管道的写入端fd[1]
调用 pipe() 函数时,首先在内核中开辟一块缓冲区用于通信,它有一个读端和一个写端,然后通过 fd 参数传出给用户进程两个文件描述符,fd[0] 指向管道的读端,fd[1] 指向管道的写段。
不要用 fd[0] 写数据,也不要用 fd[1] 读数据,其行为未定义的,但在有些系统上可能会返回 -1 表示调用失败。数据只能从 fd[0] 中读取,数据也只能写入到fd[1],不能倒过来。
与所有文件描述符一样,可以使用 read() 和 write() 系统调用来在管道上执行 IO,一旦向管道的写入端写入数据之后立即就能从管道的读取端读取数据。管道上的 read() 调用会读取的数据量为所请求的字节数与管道中当前存在的字节数两者之间的较小值。当管道为空时,读取操作阻塞。
Sie können stdio-Funktionen auch auf Pipes verwenden (printf()、scanf() 等),只需要首先使用 fdopen() 获取一个与 filedes 中的某个描述符对应的文件流即可。但在这样做的时候需要解决 stdio Pufferprobleme.
Pipes können für die interne Kommunikation innerhalb eines Prozesses verwendet werden:
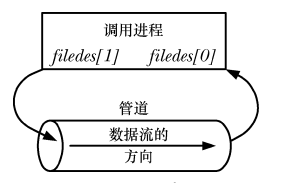
Pipes können für die prozessinterne Kommunikation in Verwandtschaftsbeziehungen verwendet werden (untergeordnete Prozesse erben eine Kopie des Dateideskriptors im übergeordneten Prozess):
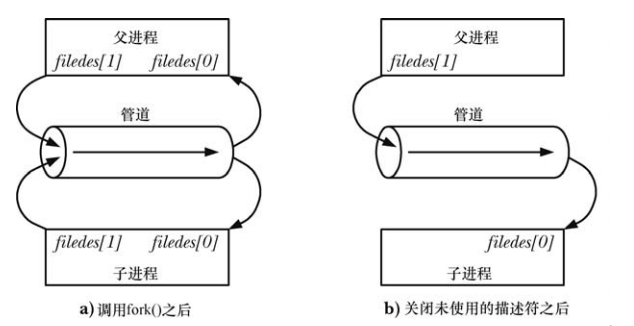
Es wird nicht empfohlen, eine einzelne Pipe als Vollduplex oder als Halbduplex zu verwenden, ohne das entsprechende Lese-/Schreibende zu schließen. Dies führt wahrscheinlich zu einem Deadlock: wenn zwei Prozesse versuchen, aus der Pipe zu lesen gleichzeitig Wenn die Daten abgerufen werden, ist es unmöglich zu bestimmen, welcher Prozess sie zuerst erfolgreich liest, was dazu führt, dass zwei Prozesse um die Daten konkurrieren. Um das Auftreten dieser Race-Bedingung zu verhindern, müssen Sie einen Synchronisierungsmechanismus verwenden. An dieser Stelle müssen Sie das Deadlock-Problem berücksichtigen, da ein Deadlock auftreten kann, wenn beide Prozesse versuchen, Daten aus einer leeren Pipe zu lesen oder Daten in eine volle Pipe zu schreiben.
Wenn wir einen bidirektionalen Datenfluss wünschen, können wir zwei Pipes erstellen, eine in jede Richtung.
Pipes ermöglichen die Kommunikation zwischen verwandten Prozessen
Tatsächlich können Pipes für die Kommunikation zwischen zwei oder sogar mehr verwandten Prozessen verwendet werden, solange die Pipe durch einen gemeinsamen Vorfahrenprozess erstellt wird, bevor die Reihe von fork() Aufrufen erfolgt, die den untergeordneten Prozess erstellen.
Schließen Sie nicht verwendete Pipe-Dateideskriptoren
Schließen Sie ungenutzte Pipe-Dateideskriptoren nicht nur, um sicherzustellen, dass ein Prozess sein Dateideskriptorlimit nicht erschöpft.
Der Prozess, der Daten aus der Pipe liest, schließt den Schreibdeskriptor der Pipe, die er enthält, sodass der Leser das Ende der Datei sehen kann, nachdem der andere Prozess die Ausgabe abgeschlossen und seinen Schreibdeskriptor geschlossen hat. Wenn andererseits der Lesevorgang das Schreibende der Pipe nicht schließt, sieht der Leser das Ende der Datei nicht, nachdem andere Prozesse den Schreibdeskriptor geschlossen haben, selbst wenn er alle Daten in der Pipe gelesen hat. Denn zu diesem Zeitpunkt weiß der Kernel, dass mindestens der Schreibdeskriptor einer Pipe geöffnet ist, was zu einer read()-Blockierung führt.
当一个进程视图向一个管道中写入数据但没有任何进程拥有该管道的打开着的读取描述符时,内核会向写入进程发送一个 SIGPIPE 信号,默认情况下,这个信号将会杀死进程,但进程可以选择忽略或者设置信号处理器,这样 write() 将因为 EPIPE 错误而失败。收到 SIGPIPE 信号和得到 EPIPE 错误对于标识管道的状态是有意义的,这就是为什么需要关闭管道的未使用读取描述符的原因。如果写入进程没有关闭管道的读取端,那么即使在其他进程已经关闭了管道的读取端之后,写入进程仍然能够向管道写入数据,最后写入进程会将数据充满整个管道,后续的写入请求会将永远阻塞。
使用管道连接过滤器
当管道被创建之后,为管道的两端分配的文件描述符是可用描述符中数值最小的两个,由于通常情况下,进程已经使用了描述符 0,1,2,因此会为管道分配一些数值更大的描述符。如果需要使用管道连接两个过滤器(即从 stdin 读取和写入到 stdout),使得一个程序的标准输出被重定向到管道中,就需要采用复制文件描述符技术。
int pfd[2]; pipe(pfd); close(STDOUT_FILENO); dup2(pfd[1],STDOUT_FILENO);
上面这些调用的最终结果是进程的标准输出被绑定到管道的写入端,而对应的一组调用可以用来将进程的标准的输入绑定到管道的读取端上。
通过管道与 shell 命令进行通信: popen()
#include FILE *popen (const char *command, const char *mode);
-
pipe()和close()是最底层的系统调用,它的进一步封装是popen()和pclose() -
popen()函数创建了一个管道,然后创建了一个子进程来执行 shell,而 shell 又创建了一个子进程来执行command字符串 -
mode参数是一个字符串: -
-
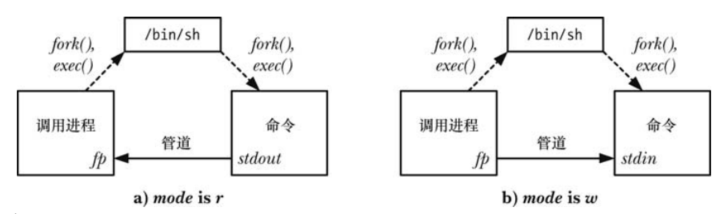
它确定调用进程是从管道中读取数据(
mode是r)还是将数据写入到管道中(mode是w) -
由于管道是向的,因此无法在执行的
command中进行双向通信 -
mode的取值确定了所执行的命令的标准输出是连接到管道的写入端还是将其标准输入连接到管道的读取端
-
它确定调用进程是从管道中读取数据(
-
popen()在成功时会返回可供stdio库函数使用的文件流指针。当发生错误时,popen()会返回NULL并设置errno以标示出发生错误的原因 -
在
popen()调用之后,调用进程使用管道来读取command的输出或使用管道向其发送输入。与使用pipe()创建的管道一样,当从管道中读取数据时,调用进程在command关闭管道的写入端之后会看到文件结束;当向管道写入数据时,如果command已经关闭了管道的读取端,那么调用进程就会收到SIGPIPE信号并得到EPIPE错误
#include int pclose ( FILE * stream);
-
一旦IO结束之后可以使用
pclose()函数关闭管道并等待子进程中的 shell 终止(不应该使用fclose()函数,因为它不会等待子进程。) -
pclose()Bei Erfolg wird der Beendigungsstatus der Shell im untergeordneten Prozess zurückgegeben (d. h. der Beendigungsstatus des letzten von der Shell ausgeführten Befehls, es sei denn, die Shell wurde durch ein Signal beendet) -
und
system (), wenn die Shell nicht ausgeführt werden kann, gibtsystem()一样,如果无法执行shell,那么pclose()会返回一个值就像子进程中的 shell 通过调用_exit(127)einen Wert zurück, genau wie die Shell im untergeordneten Prozess, indem_exit(127)um dasselbe zu beenden -
Wenn ein weiterer Fehler auftritt, gibt
pclose()−1 zurück. Einer der Fehler, die auftreten können, besteht darin, dass der Kündigungsstatus nicht abgerufen werden kann
Beim Warten, um den Status der Shell in einem untergeordneten Prozess abzurufen, erfordert SUSv3, dass pclose() 与 system() 一样,即在内部的 waitpid() mit system() ist gleich, d. h. intern waitpid() Startet einen Anruf automatisch neu, nachdem er beendet wurde durch einen Signalhandler unterbrochen.
und system() 一样,在特权进程中永远都不应该使用 popen().
popenVor- und Nachteile:
-
Vorteile: Die gesamte Parametererweiterung unter Linux erfolgt durch die Shell. Rufen Sie also beim Start
command命令之前程序先启动 shell 来分析command字符串,就可以使用各种 shell 扩展(比如通配符),这样我们可以通过popen()einen sehr komplexen Shell-Befehl auf -
Nachteil: Für jedes
popen()调用,不仅要启动一个被请求的程序,还需要启动一个 shell。即每一个popen()werden zwei Prozesse gestartet.从效率和资源的角度看,popen()函数的调用比正常方式要慢一些
pipe()` VS `popen()
-
pipe()是一个底层调用,popen()是一个高级的函数 -
pipe()单纯的创建管道,而popen()创建管道的同时fork()子进程 -
popen()在两个进程中传递数据时需要调用 shell 来解释请求命令;pipe()在两个进程中传递数据不需要启动 shell 来解释请求命令,同时提供了对读写数据的更多控制(popen()必须时 shell 命令,pipe()则无硬性要求) -
popen()函数是基于文件流(FILE)工作的,而pipe()是基于文件描述符工作的,所以在使用pipe()后,数据必须要用底层的read()和write()调用来读取和发送
管道和 stdio 缓冲
由于 popen() 调用返回的文件流指针没有引用一个终端,因此 stdio 库会对这种流应用块缓冲。这意味着当 mode 的值为 w 来调用 popen() 时,默认情况下只有当 stdio 缓冲区被充满或者使用 pclose() 关闭了管道之后才会被发送到管道的另一端的子进程。在很多情况下,这种处理方式是不存在问题的。Wenn Sie jedoch sicherstellen müssen, dass der untergeordnete Prozess sofort Daten von der Pipe empfangen kann, müssen Sie fflush() 或使用 setbuf(fp, NULL) 调用禁用 stdio 缓冲。当使用 pipe() 系统调用创建管道,然后使用 fdopen() regelmäßig aufrufen. Diese Technik kann auch verwendet werden, wenn Sie einen stdio-Stream erhalten, der dem schreibenden Ende der Pipe entspricht
Wenn gerufen wird popen() 的进程正在从管道中读取数据(即 mode 是 r),那么事情就不是那么简单了。在这样情况下如果子进程正在使用 stdio 库,那么——除非它显式地调用了 fflush() 或 setbuf() ,其输出只有在子进程填满 stdio 缓冲器或调用了 fclose() 之后才会对调用进程可用。(如果正在从使用 pipe() 创建的管道中读取数据并且向另一端写入数据的进程正在使用 stdio 库,那么同样的规则也是适用的。)如果这是一个问题,那么能采取的措施就比较有限的,除非能够修改在子进程中运行的程序的源代码使之包含对 setbuf() 或 fflush() gerufen wird.
Wenn Sie den Quellcode nicht ändern können, können Sie die Pipe durch ein Pseudo-Terminal ersetzen. Ein Pseudoterminal ist ein IPC-Kanal, der einem Prozess als Terminal erscheint. Das Ergebnis ist, dass die stdio-Bibliothek die Daten im Puffer Zeile für Zeile ausgibt.
Named Pipe (FIFO)
Obwohl die obige Pipeline die Kommunikation zwischen Prozessen implementiert, weist sie bestimmte Einschränkungen auf:
- Anonyme Pipes können nur zwischen Prozessen kommunizieren, die durch Blut miteinander verbunden sind
- Es kann nur einem Prozess das Schreiben und einem anderen Prozess das Lesen ermöglichen. Wenn Sie beides gleichzeitig tun müssen, müssen Sie eine Pipe erneut öffnen
Um die Kommunikation zwischen zwei beliebigen Prozessen zu ermöglichen, wurden benannte Pipes (Named Pipe oder FIFO) vorgeschlagen:
- FIFO 与管道的区别:FIFO 在文件系统中拥有一个名称,并且其打开方式与打开一个普通文件一样,能够实现任何两个进程之间通信。而匿名管道对于文件系统是不可见的,它仅限于在父子进程之间的通信
-
一旦打开了 FIFO,就能在它上面使用与操作管道和其他文件的系统调用一样的 IO 系统调用
read(),write(),close()。与管道一样,FIFO 也有一个写入端和读取端,并且总是遵循先进先出的原则,即第一个进来的数据会第一个被读走 - 与管道一样,当所有引用 FIFO 的描述符都关闭之后,所有未被读取的数据都将被丢弃
-
使用
mkfifo命令可以在 shell 中创建一个 FIFO:
mkfifo [-m mode] pathname
-
pathname是创建的 FIFO 的名称,-m选项指定权限mode,其工作方式与chmod命令一样 -
fstat()和stat()函数会在stat结构的st_mode字段返回S_IFIFO,使用ls -l列出文件时,FIFO 文件在第一列的类型为p,ls -F会在 FIFO 路径名后面附加管道符|
#include #include int mkfifo(const char *pathname,mode_t mode);
-
mode参数指定了新 FIFO 的权限,这些权限会按照进程的umask值来取掩码 - 一旦创建了 FIFO,任何进程都能够打开它,只要它通过常规的文件权限检测
-
使用 FIFO 时唯一明智的做法是在两端分别设置一个读取进程和一个写入进程。这样在默认情况下,打开一个 FIFO 以便读取数据(
open() O_RDONLY标记)将会阻塞直到另一个进程打开 FIFO 以写入数(open() O_WRONLY标记)为止。相应地,打开一个 FIFO 以写入数据将会阻塞直到另一个进程打开 FIFO 以读取数据为止。换句话说,打开一个 FIFO 会同步读取进程和写入进程。如果一个 FIFO 的另一端已经打开(可能是因为一对进程已经打开了 FIFO 的两端),那么open()调用会立即成功。
在大多数 Unix 实现上(包含 Linux),当打开一个 FIFO 时可以通过指定 O_RDWR 标记来绕过打开 FIFO 时的阻塞行为。这样,open() 会立即返回,但无法使用返回的文件描述符在 FIFO 上读取和写入数据。这种做法破坏了 FIFO 的 IO 模型,SUSv3 明确指出以 O_RDWR 标记打开一个 FIFO 的结果是未知的,因此出于可移植性的原因,开发人员不应该使用这项技术。对于那些需要避免在打开 FIFO 时发生阻塞的需求,open() 的 O_NONBLOCK 标记提供了一种标准化的方法来完成这个任务:
open(const char *path, O_RDONLY | O_NONBLOCK); open(const char *path, O_WRONLY | O_NONBLOCK);
在打开一个 FIFO 时避免使用 O_RDWR 标记还有另外一个原因,当采用那种方式调用 open() 之后,调用进程在从返回的文件描述符中读取数据时永远都不会看到文件结束,因为永远都至少存在一个文件描述符被打开着以等待数据被写入 FIFO,即进程从中读取数据的那个描述符。
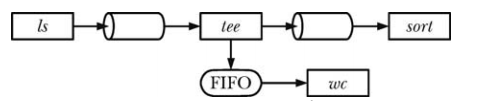
使用 FIFO 和 tee 创建双重管道线
shell 管道线的其中一个特征是它们是线性的,管道线中的每个进程都能读取前一个进程产生的数据并将数据发送到其后一个进程中,使用 FIFO 就能够在管道线中创建子进程,这样除了将一个进程的输出发送给管道线中的后面一个进程之外,还可以复制进程的输出并将数据发送到另一个进程中,要完成这个任务就需要使用 tee 命令,它将其从标准输入中读取到的数据复制两份并输出:一份写入标准输出,另一份写入到通过命令行参数指定的文件中。
mkfifo myfifo wc -l
非阻塞 IO
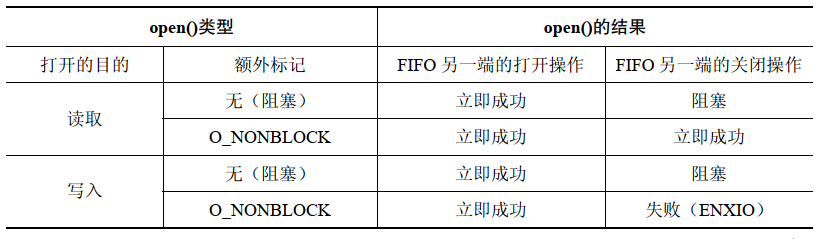
当一个进程打开一个 FIFO 的一端时,如果 FIFO 的另一端还没有被打开,那么该进程会被阻塞。但有些时候阻塞并不是期望的行为,而这可以通过在调用 open() 时指定 O_NONBLOCK 标记来实现。
如果 FIFO 的另一端已经被打开,那么 O_NONBLOCK 对 open() 调用不会产生任何影响,它会像往常一样立即成功地打开 FIFO。只有当 FIFO 的另一端还没有被打开的时候 O_NONBLOCK 标记才会起作用,而具体产生的影响则依赖于打开 FIFO 是用于读取还是用于写入的:
-
如果打开 FIFO 是为了读取,并且 FIFO 的写入端当前已经被打开,那么
open()调用会立即成功(就像 FIFO 的另一端已经被打开一样) -
如果打开 FIFO 是为了写入,并且还没有打开 FIFO 的另一端来读取数据,那么
open()调用会失败,并将errno设置为ENXIO
为读取而打开 FIFO 和为写入而打开 FIFO 时 O_NONBLOCK 标记所起的作用不同是有原因的。当 FIFO 的另一个端没有写者时打开一个 FIFO 以便读取数据是没有问题的,因为任何试图从 FIFO 读取数据的操作都不会返回任何数据。但当试图向没有读者的 FIFO 中写入数据时将会导致 SIGPIPE 信号的产生以及 write() 返回 EPIPE 错误。
在 FIFO 上调用 open() 的语义总结如下:
在打开一个 FIFO 时,使用 O_NOBLOCK 标记存在两个目的:
-
它允许单个进程打开一个 FIFO 的两端,这个进程首先会在打开 FIFO 时指定
O_NOBLOCK标记以便读取数据,接着打开 FIFO 以便写入数据 - 它防止打开两个 FIFO 的进程之间产生死锁
例如,下面的情况将会发生死锁:

非阻塞 read() 和 write()
O_NONBLOCK 标记不仅会影响 open() 的语义,而且还会影响——因为在打开的文件描述中这个标记仍然被设置着——后续的 read() 和 write() 调用的语义。
有些时候需要修改一个已经打开的 FIFO(或另一种类型的文件)的 O_NONBLOCK 标记的状态,具体存在这个需求的场景包括以下几种:
-
使用
O_NONBLOCK打开了一个 FIFO 但需要后续的read()和write()在阻塞模式下运行 -
需要启用从
pipe()返回的一个文件描述符的非阻塞模式。更一般地,可能需要更改从除open()调用之外的其他调用中,如每个由 shell 运行的新程序中自动被打开的三个标准描述符的其中一个或socket()返回的文件描述符,取得的任意文件描述符的非阻塞状态 -
出于一些应用程序的特殊需求,需要切换一个文件描述符的
O_NONBLOCK设置的开启和关闭状态
当碰到上面的需求时可以使用 fcntl() 启用或禁用打开着的文件的 O_NONBLOCK 状态标记。通过下面的代码(忽略的错误检查)可以启用这个标记:
int flags; flags = fcntl(fd, F_GETFL); flags != O_NONBLOCK; fcntl(fd, F_SETFL, flags);
通过下面的代码可以禁用这个标记:
flags = fcntl(fd, F_GETFL); flags &= ~O_NONBLOCK; fcntl(fd, F_SETFL, flags);
管道和 FIFO 中 read() 和 write() 的语义
FIFO 上的 read() 操作:
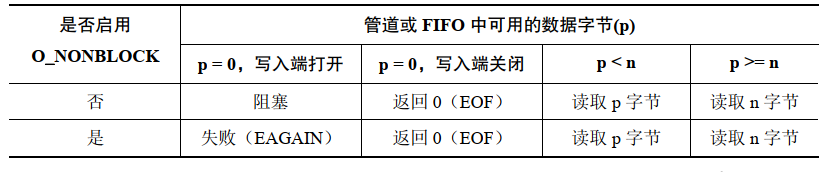
只有当没有数据并且写入端没有被打开时阻塞和非阻塞读取之间才存在差别。在这种情况下,普通的 read() 会被阻塞,而非阻塞 read() 会失败并返回 EAGAIN 错误。
当 O_NONBLOCK 标记与 PIPE_BUF 限制共同起作用时 O_NONBLOCK 标记对象管道或 FIFO 写入数据的影响会变得复杂。
FIFO 上的 write() 操作:
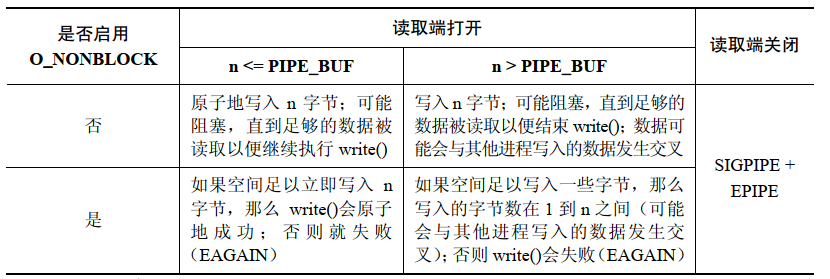
-
Wenn Daten nicht sofort übertragen werden können
O_NONBLOCK标记会导致在一个管道或 FIFO 上的write()失败(错误是EAGAIN)。这意味着当写入了PIPE_BUF字节之后,如果在管道或 FIFO 中没有足够的空间了,那么write()会失败,因为内核无法立即完成这个操作并且无法执行部分写入,否则就会破坏不超过PIPE_BUFAnforderungen an die Atomizität von Byte-Schreibvorgängen -
Wenn die Menge der gleichzeitig geschriebenen Daten den
PIPE_BUF字节时,该写入操作无需是原子的。因此,write()会尽可能多地传输字节(部分写)以充满管道或 FIFO。在这种情况下,从write()返回的值是实际传输的字节数,并且调用者随后必须要进行重试以写入剩余的字节。但如果管道或 FIFO 已经满了,从而导致哪怕连一个字节都无法传输了,那么write()会失败并返回EAGAINFehler überschreitet
Das obige ist der detaillierte Inhalt vonAnwendungshinweis zu Linux Pipes und FIFO. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1371
1371
 52
52

 Deepseek Web Version Eingang Deepseek Offizielle Website Eingang
Feb 19, 2025 pm 04:54 PM
Deepseek Web Version Eingang Deepseek Offizielle Website Eingang
Feb 19, 2025 pm 04:54 PM
Deepseek ist ein leistungsstarkes Intelligent -Such- und Analyse -Tool, das zwei Zugriffsmethoden bietet: Webversion und offizielle Website. Die Webversion ist bequem und effizient und kann ohne Installation verwendet werden. Unabhängig davon, ob Einzelpersonen oder Unternehmensnutzer, können sie massive Daten über Deepseek problemlos erhalten und analysieren, um die Arbeitseffizienz zu verbessern, die Entscheidungsfindung zu unterstützen und Innovationen zu fördern.
 So installieren Sie Deepseek
Feb 19, 2025 pm 05:48 PM
So installieren Sie Deepseek
Feb 19, 2025 pm 05:48 PM
Es gibt viele Möglichkeiten, Deepseek zu installieren, einschließlich: kompilieren Sie von Quelle (für erfahrene Entwickler) mit vorberechtigten Paketen (für Windows -Benutzer) mit Docker -Containern (für bequem am besten, um die Kompatibilität nicht zu sorgen), unabhängig von der Methode, die Sie auswählen, bitte lesen Die offiziellen Dokumente vorbereiten sie sorgfältig und bereiten sie voll und ganz vor, um unnötige Schwierigkeiten zu vermeiden.
 Wie löste ich das Problem der Berechtigungen beim Betrachten der Python -Version in Linux Terminal?
Apr 01, 2025 pm 05:09 PM
Wie löste ich das Problem der Berechtigungen beim Betrachten der Python -Version in Linux Terminal?
Apr 01, 2025 pm 05:09 PM
Lösung für Erlaubnisprobleme beim Betrachten der Python -Version in Linux Terminal Wenn Sie versuchen, die Python -Version in Linux Terminal anzuzeigen, geben Sie Python ein ...
 Bitget Offizielle Website -Installation (2025 Anfängerhandbuch)
Feb 21, 2025 pm 08:42 PM
Bitget Offizielle Website -Installation (2025 Anfängerhandbuch)
Feb 21, 2025 pm 08:42 PM
Bitget ist eine Kryptowährungsbörse, die eine Vielzahl von Handelsdienstleistungen anbietet, darunter Spot -Handel, Vertragshandel und Derivate. Der 2018 gegründete Austausch hat seinen Hauptsitz in Singapur und verpflichtet sich, den Benutzern eine sichere und zuverlässige Handelsplattform zu bieten. Bitget bietet eine Vielzahl von Handelspaaren, einschließlich BTC/USDT, ETH/USDT und XRP/USDT. Darüber hinaus hat der Austausch einen Ruf für Sicherheit und Liquidität und bietet eine Vielzahl von Funktionen wie Premium -Bestellarten, gehebelter Handel und Kundenunterstützung rund um die Uhr.
 Holen Sie sich das Installationspaket Gate.io kostenlos
Feb 21, 2025 pm 08:21 PM
Holen Sie sich das Installationspaket Gate.io kostenlos
Feb 21, 2025 pm 08:21 PM
Gate.io ist ein beliebter Kryptowährungsaustausch, den Benutzer verwenden können, indem sie sein Installationspaket herunterladen und auf ihren Geräten installieren. Die Schritte zum Abholen des Installationspakets sind wie folgt: Besuchen Sie die offizielle Website von Gate.io, klicken Sie auf "Download", wählen Sie das entsprechende Betriebssystem (Windows, Mac oder Linux) und laden Sie das Installationspaket auf Ihren Computer herunter. Es wird empfohlen, die Antiviren -Software oder -Firewall während der Installation vorübergehend zu deaktivieren, um eine reibungslose Installation zu gewährleisten. Nach Abschluss muss der Benutzer ein Gate.io -Konto erstellen, um es zu verwenden.
 Wie setze ich nach dem Neustart des Systems automatisch Berechtigungen von Unixsocket fest?
Mar 31, 2025 pm 11:54 PM
Wie setze ich nach dem Neustart des Systems automatisch Berechtigungen von Unixsocket fest?
Mar 31, 2025 pm 11:54 PM
So setzen Sie die Berechtigungen von Unixsocket automatisch nach dem Neustart des Systems. Jedes Mal, wenn das System neu startet, müssen wir den folgenden Befehl ausführen, um die Berechtigungen von Unixsocket: sudo ...
 Ouyi OKX Installationspaket ist direkt enthalten
Feb 21, 2025 pm 08:00 PM
Ouyi OKX Installationspaket ist direkt enthalten
Feb 21, 2025 pm 08:00 PM
Ouyi Okx, die weltweit führende digitale Asset Exchange, hat jetzt ein offizielles Installationspaket gestartet, um ein sicheres und bequemes Handelserlebnis zu bieten. Auf das OKX -Installationspaket von Ouyi muss nicht über einen Browser zugegriffen werden. Der Installationsprozess ist einfach und einfach zu verstehen.
 Ouyi Exchange Download Official Portal
Feb 21, 2025 pm 07:51 PM
Ouyi Exchange Download Official Portal
Feb 21, 2025 pm 07:51 PM
Ouyi, auch bekannt als OKX, ist eine weltweit führende Kryptowährungsplattform. Der Artikel enthält ein Download -Portal für das offizielle Installationspaket von Ouyi, mit dem Benutzer den Ouyi -Client auf verschiedenen Geräten installiert werden können. Dieses Installationspaket unterstützt Windows, Mac, Android und iOS -Systeme. Nach Abschluss der Installation können sich Benutzer registrieren oder sich beim Ouyi -Konto anmelden, Kryptowährungen mit dem Handel mit den von der Plattform erbrachten Diensten anmelden.
