

Schrams Sortieren – Sortieren nach Fairness lernen

Auf der internationalen akademischen Konferenz AIBT 2023 im Jahr 2023 veröffentlichte Ratidar Technologies LLC einen fairnessbasierten Ranking-Lernalgorithmus und gewann den Preis für den besten Papierbericht der Konferenz. Der Algorithmus mit dem Namen Skellam Rank nutzt statistische Prinzipien voll aus und kombiniert Pairwise Ranking und Matrixzerlegungstechnologie, um die Genauigkeits- und Fairnessprobleme im Empfehlungssystem zu lösen. Da es in Empfehlungssystemen nur wenige innovative Ranking-Lernalgorithmen gibt, schnitt der Ranking-Algorithmus von Schramam so gut ab, dass er auf der Konferenz einen Forschungspreis gewann. Im Folgenden werden die Grundprinzipien des Schram-Algorithmus vorgestellt:
Erinnern wir uns zunächst an die Poisson-Verteilung:
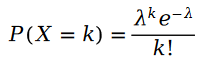
Die Berechnungsformel der Parameter der Poisson-Verteilung lautet wie folgt:
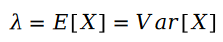
Zwei Der Unterschied zwischen Poisson-Variablen ist die Schram-Verteilung:
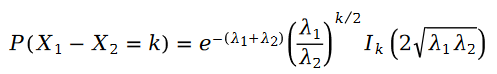
In der Formel gilt:
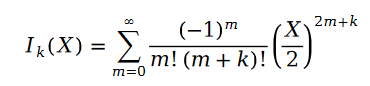
Die Funktion wird Bessel-Funktion erster Art genannt.
Lassen Sie uns mit diesen grundlegendsten Konzepten der Statistik ein Pairwise-Ranking-Ranking-Lernempfehlungssystem aufbauen!
Wir glauben zunächst, dass die Bewertung von Artikeln durch den Benutzer ein Poisson-Verteilungskonzept ist. Mit anderen Worten, der Bewertungswert des Benutzerelements folgt der folgenden Wahrscheinlichkeitsverteilung:
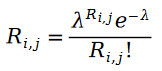
Der Grund, warum wir den Prozess der Benutzerbewertung von Elementen als Poisson-Prozess beschreiben können, liegt darin, dass es bei der Benutzerelementbewertung einen Matthew-Effekt gibt. Das heißt, Benutzer mit höheren Bewertungen haben mehr Bewertungen, sodass wir die Anzahl der Personen, die einen Artikel bewerten, verwenden können, um die Verteilung der Bewertungen für diesen Artikel anzunähern. Welchem zufälligen Prozess folgt die Anzahl der Personen, die einen Artikel bewerten? Natürlich werden wir an den Poisson-Prozess denken. Da die Wahrscheinlichkeit, dass ein Benutzer einen Artikel bewertet, der Wahrscheinlichkeit ähnelt, wie viele Personen den Artikel bewertet haben, können wir natürlich den Poisson-Prozess verwenden, um den Prozess der Benutzerbewertung eines Artikels anzunähern.
Wir werden die Parameter des Poisson-Prozesses durch die Statistiken der Beispieldaten ersetzen und die folgende Formel erhalten:
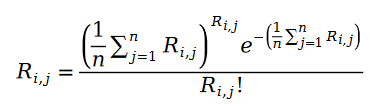
Wir werden unten die Maximum-Likelihood-Funktionsformel des Pariwise-Rankings definieren. Wie wir alle wissen, bedeutet das sogenannte Pairwise Ranking, dass wir die Maximum-Likelihood-Funktion zur Lösung der Modellparameter verwenden, sodass das Modell die Beziehung der bekannten Ranking-Paare in der Datenstichprobe weitestgehend aufrechterhalten kann:
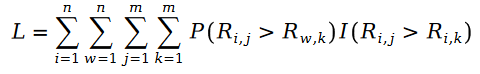
weil R in der Formel eine Poisson-Verteilung ist, ist ihr Unterschied also die Schramam-Verteilung, d Rufen Sie die Schramam-Verteilung auf. Die Formel wird in die Verlustfunktion L der Maximum-Likelihood-Funktion eingebracht und die folgende Formel erhalten:
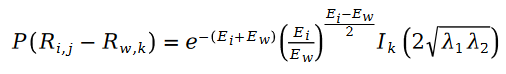
Im Benutzerbewertungswert R, der in der Variablen E erscheint, verwenden wir die Matrixzerlegung um es zu lösen. Verwenden Sie den Parameter Benutzermerkmalsvektor U und den Artikelmerkmalsvektor V in der Matrixzerlegung als zu lösende Variablen:
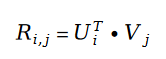
Hier überprüfen wir zunächst das Konzept der Matrixfaktorisierung. Das Konzept der Matrixfaktorisierung ist ein Empfehlungssystemalgorithmus, der um 2010 vorgeschlagen wurde. Dieser Algorithmus kann als einer der erfolgreichsten Empfehlungssystemalgorithmen in der Geschichte bezeichnet werden. Bis heute verwenden viele Empfehlungssystemunternehmen immer noch den Matrixzerlegungsalgorithmus als Basis für Online-Systeme, und Factorization Machine, eine wichtige Komponente im beliebten klassischen Empfehlungsalgorithmus DeepFM, ist auch eine nachfolgende Verbesserung des Matrixzerlegungsalgorithmus in der Die Version des Empfehlungssystems ist untrennbar mit der Matrixzerlegung verbunden. Es gibt eine wegweisende Arbeit zum Matrixfaktorisierungsalgorithmus, nämlich Probabilistic Matrix Factorization aus dem Jahr 2007. Der Autor nutzte ein statistisches Lernmodell, um das Konzept der Matrixfaktorisierung in der linearen Algebra umzugestalten und gab der Matrixfaktorisierung erstmals eine solide mathematisch-theoretische Grundlage.
Das Grundkonzept der Matrixzerlegung besteht darin, das Skalarprodukt von Vektoren zu verwenden, um unbekannte Benutzerbewertungen effizient vorherzusagen und gleichzeitig die Dimensionalität der Benutzerbewertungsmatrix zu reduzieren. Die Verlustfunktion der Matrixzerlegung lautet wie folgt:
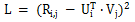
Es gibt viele Varianten des Matrixzerlegungsalgorithmus. Beispielsweise modelliert das von der Shanghai Jiao Tong University vorgeschlagene SVDFeature die Vektoren U und V in Form von Linearkombinationen , so dass das Matrixzerlegungsproblem zum Problem des Feature-Engineerings wird. SVDFeature ist auch ein wegweisendes Papier auf dem Gebiet der Matrixfaktorisierung. Die Matrixzerlegung kann beim Pairwise Ranking angewendet werden, um unbekannte Benutzerbewertungen zu ersetzen, um Modellierungszwecke zu erreichen. Zu den klassischen Anwendungsfällen gehört der BPR-MF-Algorithmus im Bayesian Pairwise Ranking, und der Schramam-Ranking-Algorithmus basiert auf denselben Ideen.
Wir verwenden den stochastischen Gradientenabstieg, um den Schramam-Sortieralgorithmus zu lösen. Da der stochastische Gradientenabstieg die Verlustfunktion im Lösungsprozess erheblich vereinfachen kann, um den Zweck der Lösung zu erreichen, wird unsere Verlustfunktion zu der folgenden Formel:
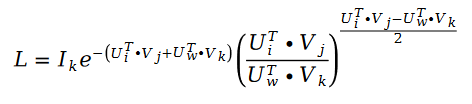
Verwenden Sie den stochastischen Gradientenabstieg, um die unbekannten Parameter U und Lösung nach V zu berechnen , erhalten wir die iterative Formel wie folgt:
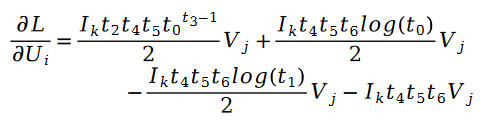
Unter ihnen:
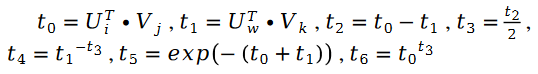
Zusätzlich:
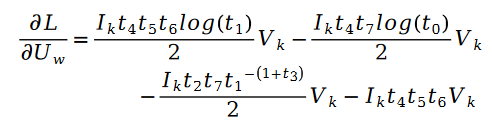
unter ihnen:
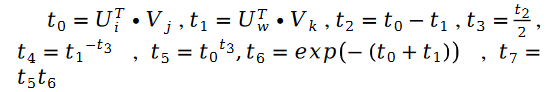
Für unbekannte Parametervariablen Die Lösung von V ist ähnlich, wir haben die folgende Formel:
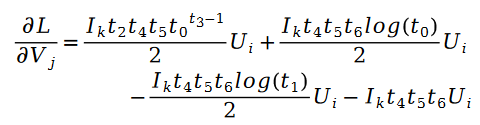
Darunter:
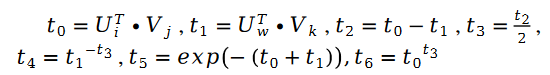
Zusätzlich:
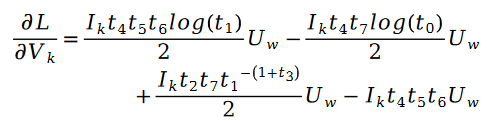
darunter:
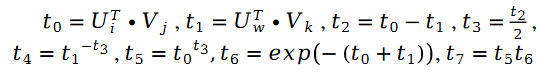
Den gesamten Algorithmusprozess verwenden wir zur Demonstration des folgenden Pseudocodes:

Um die Wirksamkeit des Algorithmus zu überprüfen, hat der Autor des Papiers ihn mit dem MovieLens 1 Million Dataset und dem LDOS-CoMoDa Dataset getestet. Der erste Datensatz enthält Bewertungen von 6040 Nutzern und 3706 Filmen. Der gesamte Bewertungsdatensatz umfasst ca. 1 Million Bewertungsdaten und ist eine der bekanntesten Bewertungsdatensammlungen im Bereich Empfehlungssysteme. Die zweite Datensammlung stammt aus Slowenien und ist eine im Internet seltene szenariobasierte Empfehlungssystem-Datensammlung. Der Datensatz enthält Bewertungen von 121 Nutzern und 1232 Filmen. Der Autor verglich Schrams Sortierung mit 9 anderen Empfehlungssystemalgorithmen. Die wichtigsten Bewertungsindikatoren sind MAE (mittlerer absoluter Fehler, verwendet zum Testen der Genauigkeit) und Grad des Matthew-Effekts (hauptsächlich verwendet zum Testen der Fairness):
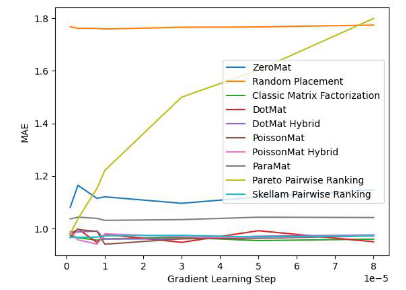
Abbildung 1 . MovieLens 1 Million Datensatz (MAE-Indikator)
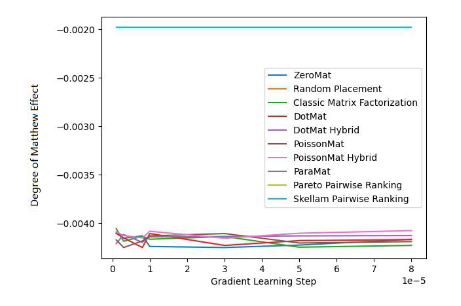
Abbildung 2. MovieLens 1 Million Datensatz (Grad des Matthew-Effekt-Indikators)
Anhand von Abbildung 1 und Abbildung 2 haben wir festgestellt, dass Schrams Sortierung beim MAE gut funktioniert Indikator, aber während des gesamten Experiments von Grid Search konnte nicht immer garantiert werden, dass die Leistung besser ist als bei anderen Algorithmen. Aber in Abbildung 2 stellen wir fest, dass Schrams Sortierung im Fairness-Index führend ist, weit vor den anderen 9 Empfehlungssystemalgorithmen.
Werfen wir einen Blick auf die Leistung dieses Algorithmus im LDOS-CoMoDa-Datensatz:
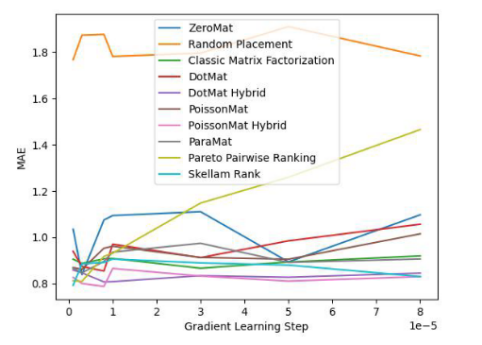
Abbildung 3. LDOS-CoMoDa-Datensatz (MAE-Indikator)
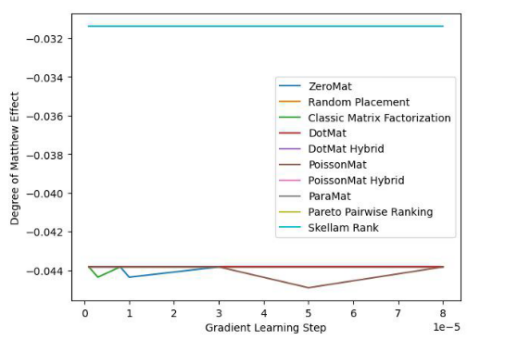
Abbildung 4. LDOS-CoMoDa-Datensatz (Grad des Matthew-Effekt-Indikators)
Anhand Abbildung 3 und Abbildung 4 verstehen wir, dass die Schillam-Sortierung beim Fairness-Indikator am besten ist und beim Genauigkeitsindikator gut abschneidet. Die Schlussfolgerung ähnelt dem vorherigen Experiment.
Schramm-Sortierung kombiniert Konzepte wie Poisson-Verteilung, Matrixzerlegung und paarweises Ranking und ist ein seltener Ranking-Lernalgorithmus für Empfehlungssysteme. Im technischen Bereich machen diejenigen, die die Ranking-Lerntechnologie beherrschen, nur 1/6 derjenigen aus, die Deep Learning beherrschen, sodass Ranking-Lernen eine knappe Technologie ist. Und es gibt noch weniger Talente, die originelles Ranking-Lernen im Bereich Empfehlungssysteme erfinden können. Der Ranking-Lernalgorithmus befreit Menschen von der engen Perspektive der Punktevorhersage und macht ihnen klar, dass das Wichtigste die Reihenfolge und nicht die Punktzahl ist. Auf Fairness basierendes Ranking-Lernen erfreut sich derzeit großer Beliebtheit im Bereich der Informationsbeschaffung, insbesondere auf Top-Konferenzen wie SIGIR. Beiträge zu Empfehlungssystemen auf Basis von Fairness sind sehr willkommen und hoffen, die Aufmerksamkeit der Leser zu erregen.
Über den Autor
Wang Hao, ehemaliger Leiter des Funplus Artificial Intelligence Laboratory. Er hatte Führungspositionen im Bereich Technologie und Technologie bei ThoughtWorks, Douban, Baidu, Sina und anderen Unternehmen inne. Da er 12 Jahre lang in Internetunternehmen, Finanztechnologie, Gaming und anderen Unternehmen gearbeitet hat, verfügt er über tiefe Einblicke und reiche Erfahrung in Bereichen wie künstliche Intelligenz, Computergrafik und Blockchain. Veröffentlichte 42 Artikel auf internationalen wissenschaftlichen Konferenzen und Fachzeitschriften und gewann den IEEE SMI 2008 Best Paper Award und den ICBDT 2020 / IEEE ICISCAE 2021 / AIBT 2023 Best Paper Report Award.
Das obige ist der detaillierte Inhalt vonSchrams Sortieren – Sortieren nach Fairness lernen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Wie rollen Sie Positionen in der digitalen Währung? Was sind die Plattformen für digitale Währung?
Mar 31, 2025 pm 07:36 PM
Wie rollen Sie Positionen in der digitalen Währung? Was sind die Plattformen für digitale Währung?
Mar 31, 2025 pm 07:36 PM
Digital Currency Rolling -Positionen ist eine Anlagestrategie, mit der die Kreditvergabe zur Erhöhung der Renditen zur Erhöhung der Rendite verwendet wird. In diesem Artikel wird der Prozess der digitalen Währung im Detail im Detail erläutert, einschließlich der wichtigsten Schritte wie der Auswahl von Handelsplattformen, die das Rolling (wie Binance, Okex, Gate.io, Huobi, Bitbit usw.), ein Hebelkonto eröffnen, ein Hebel mehrerer Hebelfunktionen für den Handel und die Anpassung des Marktes und die Anpassung der Markteinführungen oder die Hinzufügung von Flüssigkeitsfonds, um eine Flüssigkeitsanleihe anzupassen. Der Handel mit Rolling -Position ist jedoch äußerst riskant, und Anleger müssen mit Vorsicht vorgehen und vollständige Risikomanagementstrategien formulieren. Um mehr über Tipps zur Digitalwährung zu erfahren, lesen Sie bitte weiter.
 Wie berechnet ich die Transaktionsgebühr der Gate.io -Handelsplattform?
Mar 31, 2025 pm 09:15 PM
Wie berechnet ich die Transaktionsgebühr der Gate.io -Handelsplattform?
Mar 31, 2025 pm 09:15 PM
Die Handhabungsgebühren der Gate.IO -Handelsplattform variieren je nach Faktoren wie Transaktionstypen, Transaktionspaar und Benutzer -VIP -Ebene. Der Ausfallgebührenpreis für den Spot-Handel beträgt 0,15% (VIP0-Level, Hersteller und Taker). Die VIP-Ebene wird jedoch anhand des 30-tägigen Handelsvolumens und der GT-Position des Benutzers angepasst. Je höher das Niveau ist, desto niedriger wird der Gebührensatz. Es unterstützt die GT -Plattform -Münzabzug und Sie können einen Mindestrabatt von 55% Rabatt genießen. Die Ausfallrate für Vertragstransaktionen beträgt Maker 0,02%, Taker 0,05% (VIP0 -Niveau), was ebenfalls von VIP -Ebene und unterschiedlichen Vertragstypen und Hebelwerken beeinflusst wird
 Tutorial zur Registrierung, Verwendung und Stornierung von Ouyi Okex -Konto
Mar 31, 2025 pm 04:21 PM
Tutorial zur Registrierung, Verwendung und Stornierung von Ouyi Okex -Konto
Mar 31, 2025 pm 04:21 PM
In diesem Artikel wird ausführlich die Registrierungs-, Nutzungs- und Stornierungsverfahren von Ouyi Okex -Konto eingeführt. Um sich zu registrieren, müssen Sie die App herunterladen, Ihre Handynummer oder E-Mail-Adresse eingeben, um sich zu registrieren, und die authentifizierte Authentifizierung abschließen. Die Verwendung deckt die Betriebsschritte wie Anmeldung, Aufladung und Rückzug, Transaktion und Sicherheitseinstellungen ab. Um ein Konto zu kündigen, müssen Sie den Kundendienst von Ouyi Okex kontaktieren, die erforderlichen Informationen bereitstellen und auf die Bearbeitung warten und schließlich die Bestätigung des Konto -Stornierens erhalten. In diesem Artikel können Benutzer das vollständige Lebenszyklusmanagement von Ouyi Okex -Konto problemlos beherrschen und digitale Asset -Transaktionen sicher und bequem durchführen.
 Binance Binance Computer Version Eingang Binance Binance Computer Version PC Offizielle Website Anmeldeeingang
Mar 31, 2025 pm 04:36 PM
Binance Binance Computer Version Eingang Binance Binance Computer Version PC Offizielle Website Anmeldeeingang
Mar 31, 2025 pm 04:36 PM
Dieser Artikel enthält eine vollständige Anleitung zur Anmeldung und Registrierung in der Binance -PC -Version. Zunächst haben wir die Schritte zur Anmeldung in Binance PC -Version ausführlich erklärt: Suchen Sie nach "Binance Official Website" im Browser, klicken Sie auf die Schaltfläche Anmeldung und geben Sie die E -Mail und das Passwort ein (aktivieren Sie 2FA, um den Überprüfungscode einzugeben), um sich anzumelden. Zweitens erklärt der Artikel den Artikel: Klicken Sie auf die Schaltfläche "Registrieren", die E -Mail -Adresse, ein starkes Passwort festlegen, und verifizieren Sie die E -Mail -Adresse, um die Registrierung zu vervollständigen. Schließlich betont der Artikel auch die Kontosicherheit und erinnert die Benutzer daran, auf den offiziellen Domainnamen, die Netzwerkumgebung und die regelmäßige Aktualisierung von Kennwörtern zu achten, um die Sicherheit der Kontos und eine bessere Verwendung verschiedener Funktionen durch die Binance -PC -Version zu gewährleisten, z. B. die Ansicht der Marktbedingungen, die Durchführung von Transaktionen und die Verwaltung von Vermögenswerten.
 Was sind die empfohlenen Websites für die Software Virtual Currency App?
Mar 31, 2025 pm 09:06 PM
Was sind die empfohlenen Websites für die Software Virtual Currency App?
Mar 31, 2025 pm 09:06 PM
In diesem Artikel wird zehn bekannte Websites für die Empfehlungen im Zusammenhang mit der virtuellen Währung empfohlen, darunter Binance Academy, OKX Learn, Coingecko, Cryptoslate, Coindesk, Investopedia, Coinmarketcap, Huobi University, Coinbase Learn und Cryptocompare. Diese Websites liefern nicht nur Informationen wie Marktdaten für virtuelle Währungen, Preistrendanalyse usw., sondern auch umfangreiche Lernressourcen, einschließlich grundlegender Blockchain -Kenntnisse, Handelsstrategien sowie Tutorials und Überprüfungen verschiedener Handelsplattform -Apps, wodurch Benutzer dazu beitragen, sie besser zu verstehen und zu nutzen
 Currency Trading Network Offizielle Website -Sammlung 2025
Mar 31, 2025 pm 03:57 PM
Currency Trading Network Offizielle Website -Sammlung 2025
Mar 31, 2025 pm 03:57 PM
Es zählt zu den Top der Welt und unterstützt alle Kategorien von Transaktionen wie Spot, Verträgen und Web3 -Geldbörsen. Es hat hohe Sicherheits- und niedrige Handhabungsgebühren. Eine umfassende Handelsplattform mit einer langen Geschichte, die für ihre Einhaltung und hohe Liquidität bekannt ist, unterstützt mehrsprachige Dienstleistungen. Der Branchenführer deckt den Währungshandel, die Hebelwirkung, die Optionen usw. mit starker Liquidität ab und unterstützt die Gebühren für die BNB -Abzüge.
 Auf welcher Plattform handelt es sich um Web3 -Transaktion?
Mar 31, 2025 pm 07:54 PM
Auf welcher Plattform handelt es sich um Web3 -Transaktion?
Mar 31, 2025 pm 07:54 PM
Dieser Artikel listet die zehn bekannten Web3-Handelsplattformen auf, darunter Binance, OKX, Gate.io, Kraken, Bybit, Coinbase, Kucoin, Bitget, Gemini und Bitstamp. Der Artikel vergleicht die Merkmale jeder Plattform im Detail, z. B. die Anzahl der Währungen, Handelstypen (Spot, Futures, Optionen, NFT usw.), Handhabungsgebühren, Sicherheit, Compliance, Benutzergruppen usw., um den Anlegern dabei zu helfen, die am besten geeignete Handelsplattform auszuwählen. Egal, ob es sich um Hochfrequenzhändler, Vertragshandelsbegeisterte oder Investoren, die sich auf Compliance und Sicherheit konzentrieren, sie können Referenzinformationen daraus finden.
 Sesam Exchange Gate Web -Version Eingibt die offizielle Webversion von Sesam Exchange Offizielle Webversion Klicken Sie auf die Eingabe
Mar 31, 2025 pm 06:18 PM
Sesam Exchange Gate Web -Version Eingibt die offizielle Webversion von Sesam Exchange Offizielle Webversion Klicken Sie auf die Eingabe
Mar 31, 2025 pm 06:18 PM
Sesame Exchange Gate.io -Webversion ist bequem zu melden. Geben Sie einfach "Gate.io" in die Browseradressleiste ein und drücken Sie die Eingabetaste, um auf die offizielle Website zuzugreifen. Die Concise Homepage bietet klare Optionen "Anmeldung" und "Register", und Benutzer können sich für ein registriertes Konto anmelden oder ein neues Konto gemäß ihrer eigenen Situation registrieren. Nach der Registrierung oder Anmeldung können Sie die Haupthandelsschnittstelle eingeben, um den Handel mit Kryptowährungen durchzuführen, die Marktbedingungen und das Kontomanagement zu überprüfen. Gate.io verfügt über eine freundliche Schnittstelle und ist einfach zu bedienen, geeignet für Anfänger und professionelle Händler.
