
 Technologie-Peripheriegeräte
KI
Das von einem chinesischen Team erstellte Open-Source-Mathematikmodell 7B übertrifft Milliarden von GPT-4
Technologie-Peripheriegeräte
KI
Das von einem chinesischen Team erstellte Open-Source-Mathematikmodell 7B übertrifft Milliarden von GPT-4
Das von einem chinesischen Team erstellte Open-Source-Mathematikmodell 7B übertrifft Milliarden von GPT-4

7B Open-Source-Modell, die mathematische Leistung übertrifft den 100-Milliarden-GPT-4!
Man kann sagen, dass seine Leistung die Grenzen des Open-Source-Modells durchbrochen hat. Sogar Forscher von Alibaba Tongyi beklagten, ob das Skalierungsgesetz versagt hat.

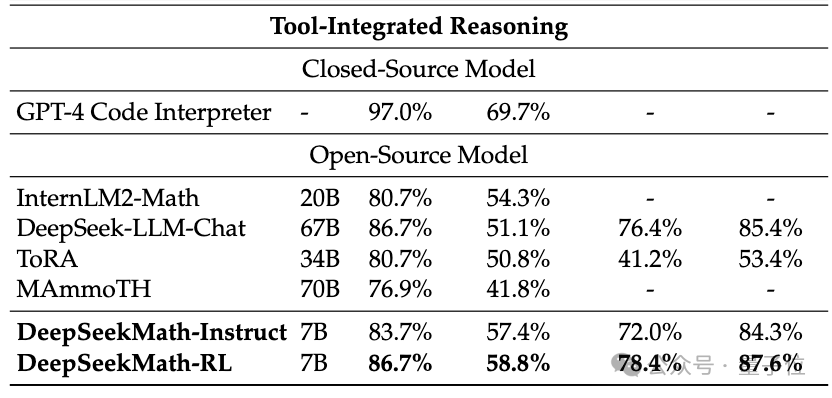
Ohne externe Tools kann eine Genauigkeit von 51,7 % im MATH-Datensatz auf Wettbewerbsebene erreicht werden.
Unter den Open-Source-Modellen ist es das erste, das bei diesem Datensatz die halbe Genauigkeit erreicht und damit sogar die frühen und API-Versionen von GPT-4 übertrifft.
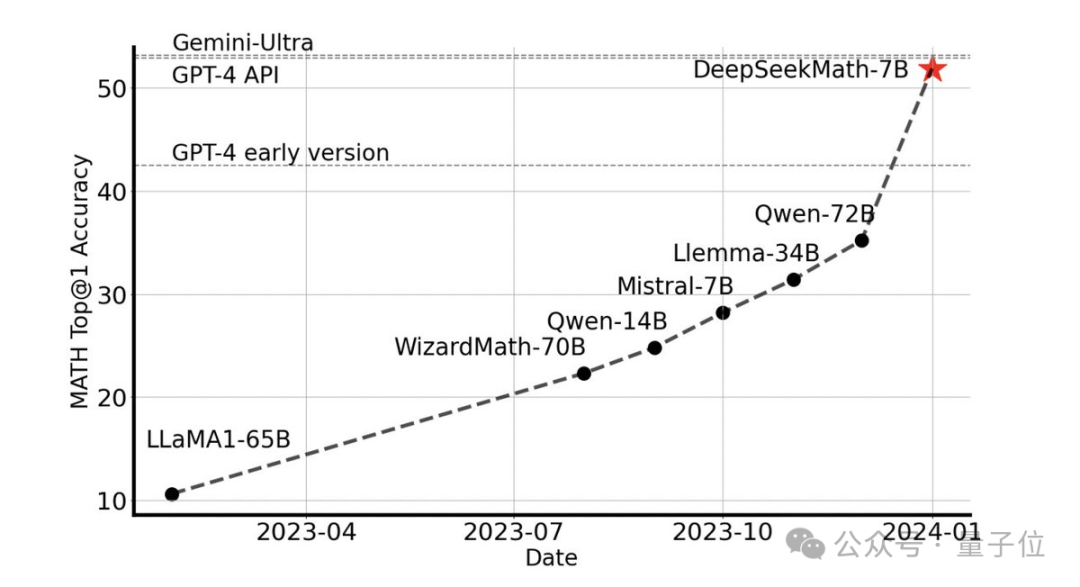
Diese Leistung schockierte die gesamte Open-Source-Community. Emad Mostaque, der Gründer von Stability AI, lobte das Forschungs- und Entwicklungsteam als beeindruckend und mit unterschätztem Potenzial.
Es ist das neueste Open-Source-7B-Mathematikmodell DeepSeekMath des Deep Search-Teams.
7B-Modell schlägt den Rest
Um die mathematischen Fähigkeiten von DeepSeekMath zu bewerten, verwendete das Forschungsteam zweisprachige Datensätze auf Chinesisch (MGSM-zh, CMATH) Englisch (GSM8K, MATH) zum Testen.
Ohne Hilfswerkzeuge zu verwenden und sich nur auf die Eingabeaufforderungen der Gedankenkette (CoT) zu verlassen, übertraf die Leistung von DeepSeekMath andere Open-Source-Modelle, einschließlich des 70B großen mathematischen Modells MetaMATH.
Verglichen mit dem selbst gestarteten 67B-Universal-Großmodell wurden auch die Ergebnisse von DeepSeekMath deutlich verbessert.
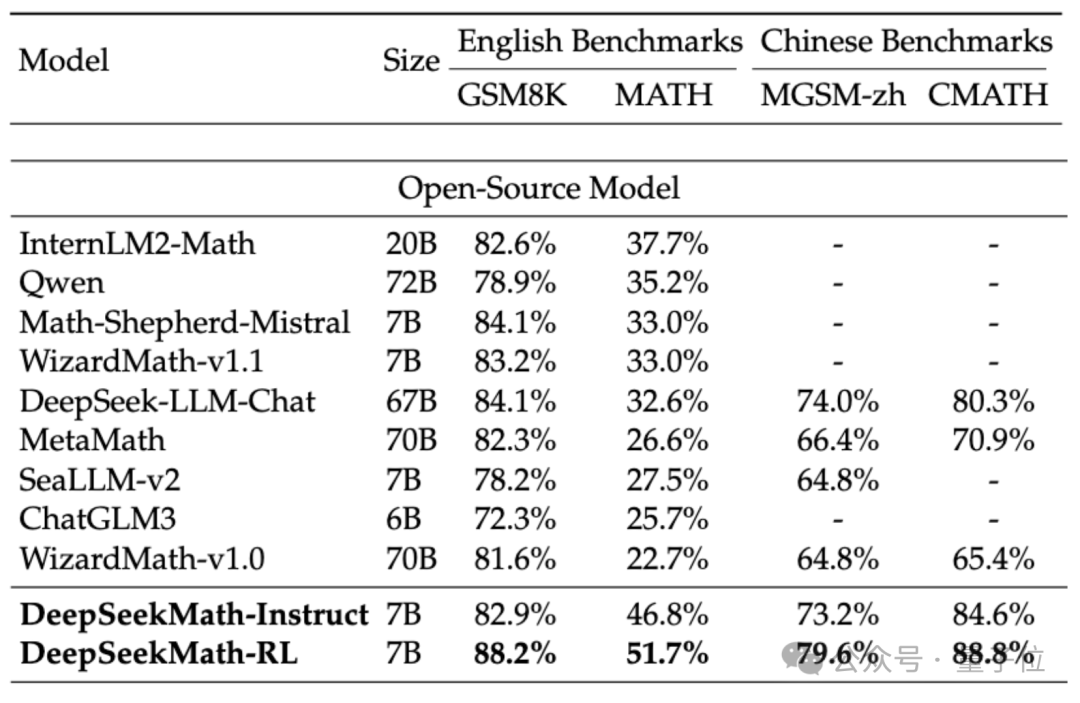
Wenn wir das Closed-Source-Modell betrachten, übertrifft DeepSeekMath auch Gemini Pro und GPT-3.5 bei mehreren Datensätzen, übertrifft GPT-4 bei chinesischem CMATH und seine Leistung bei MATH liegt ebenfalls nahe daran.
Aber es sollte beachtet werden, dass GPT-4 laut durchgesickerten Spezifikationen ein Gigant mit Hunderten von Milliarden Parametern ist, während DeepSeekMath nur 7B Parameter hat.
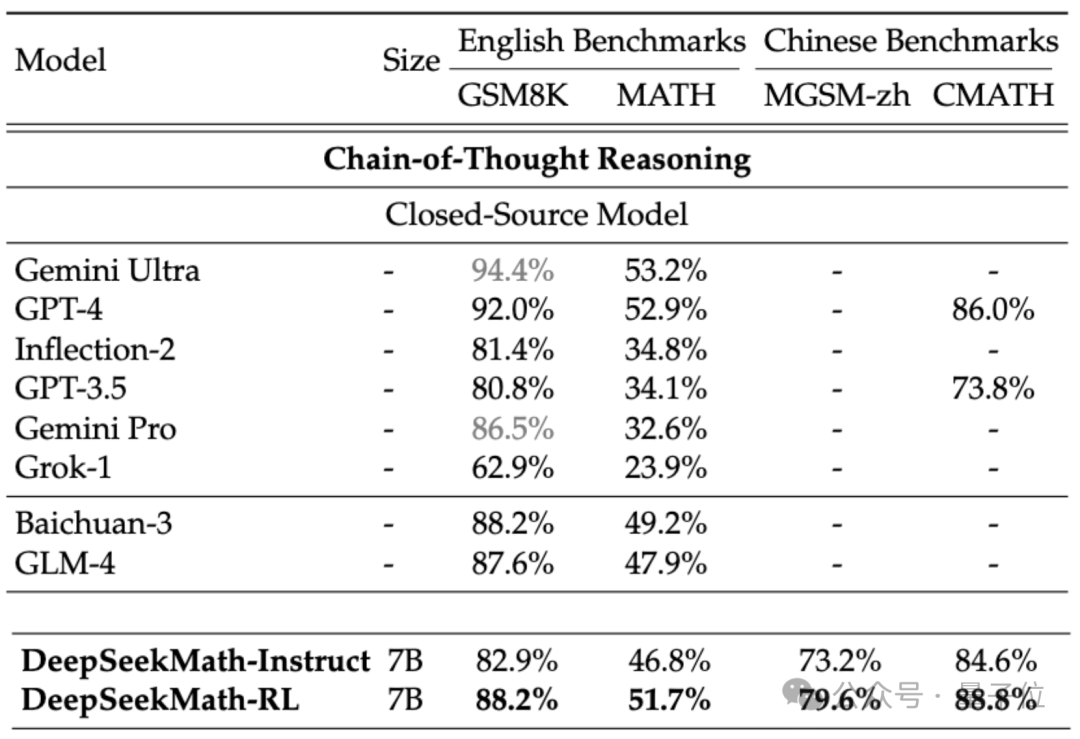
Wenn das Tool (Python) zur Unterstützung verwendet werden darf, kann die Leistung von DeepSeekMath auf dem Datensatz mit der Wettbewerbsschwierigkeit (MATH) um weitere 7 Prozentpunkte verbessert werden.
Welche Technologien werden also hinter der hervorragenden Leistung von DeepSeekMath eingesetzt?
Basierend auf dem Codemodell erstellt
Um bessere mathematische Fähigkeiten als mit dem allgemeinen Modell zu erhalten, verwendete das Forschungsteam das Codemodell DeepSeek-Coder-v1.5, um es zu initialisieren.
Weil das Team herausgefunden hat, dass Code-Training die mathematischen Fähigkeiten des Modells im Vergleich zu allgemeinem Datentraining verbessern kann, sei es in einem zweistufigen oder einstufigen Trainingsumfeld.
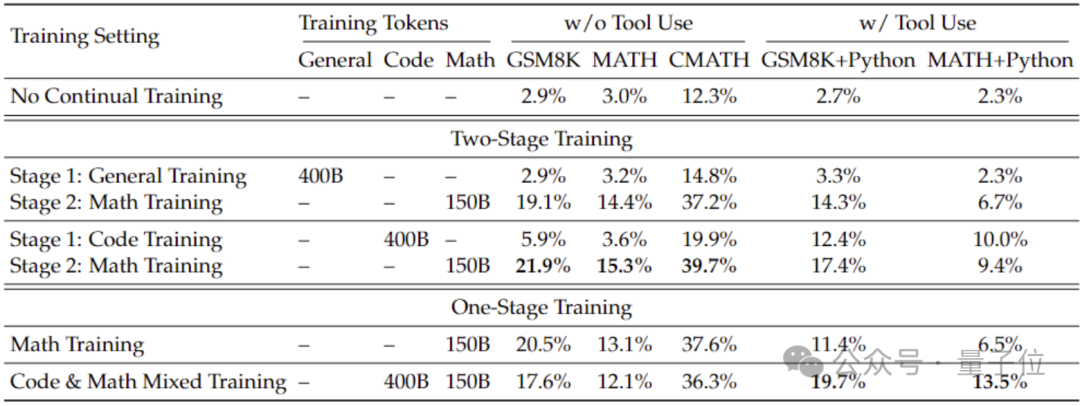
Basierend auf Coder trainierte das Forschungsteam weiterhin 500 Milliarden Token. Die Datenverteilung ist wie folgt:
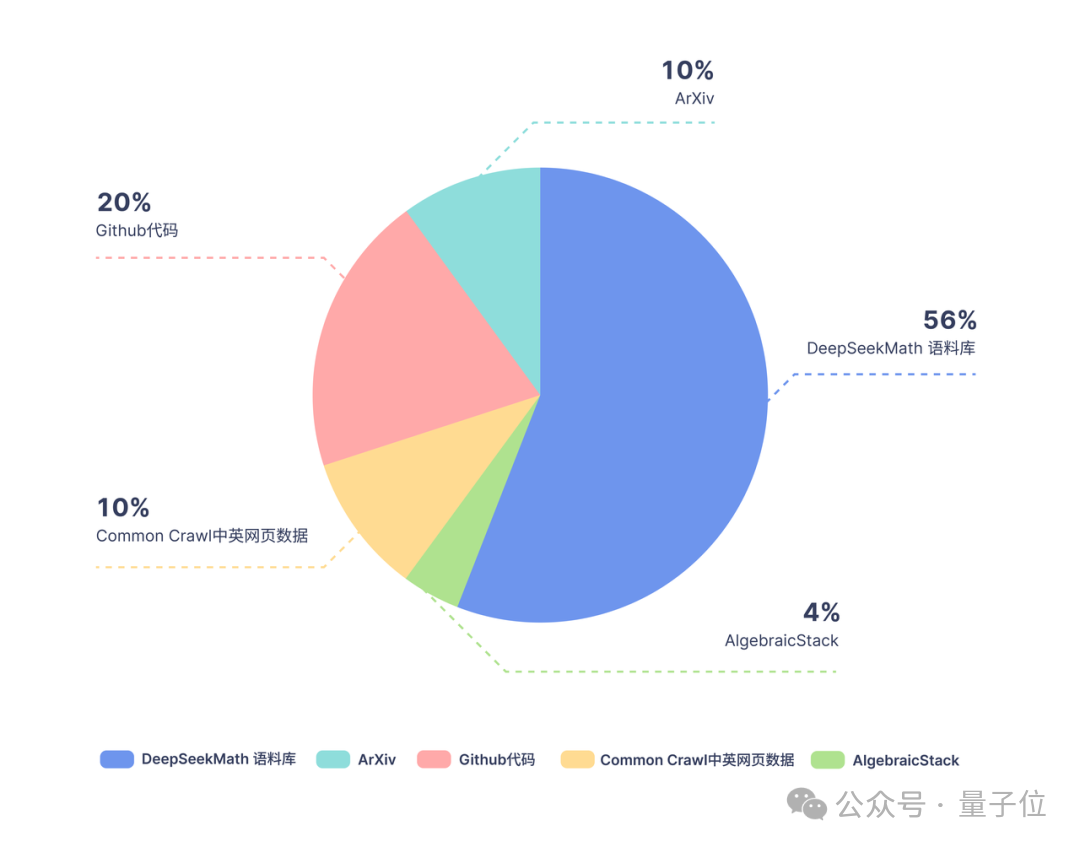
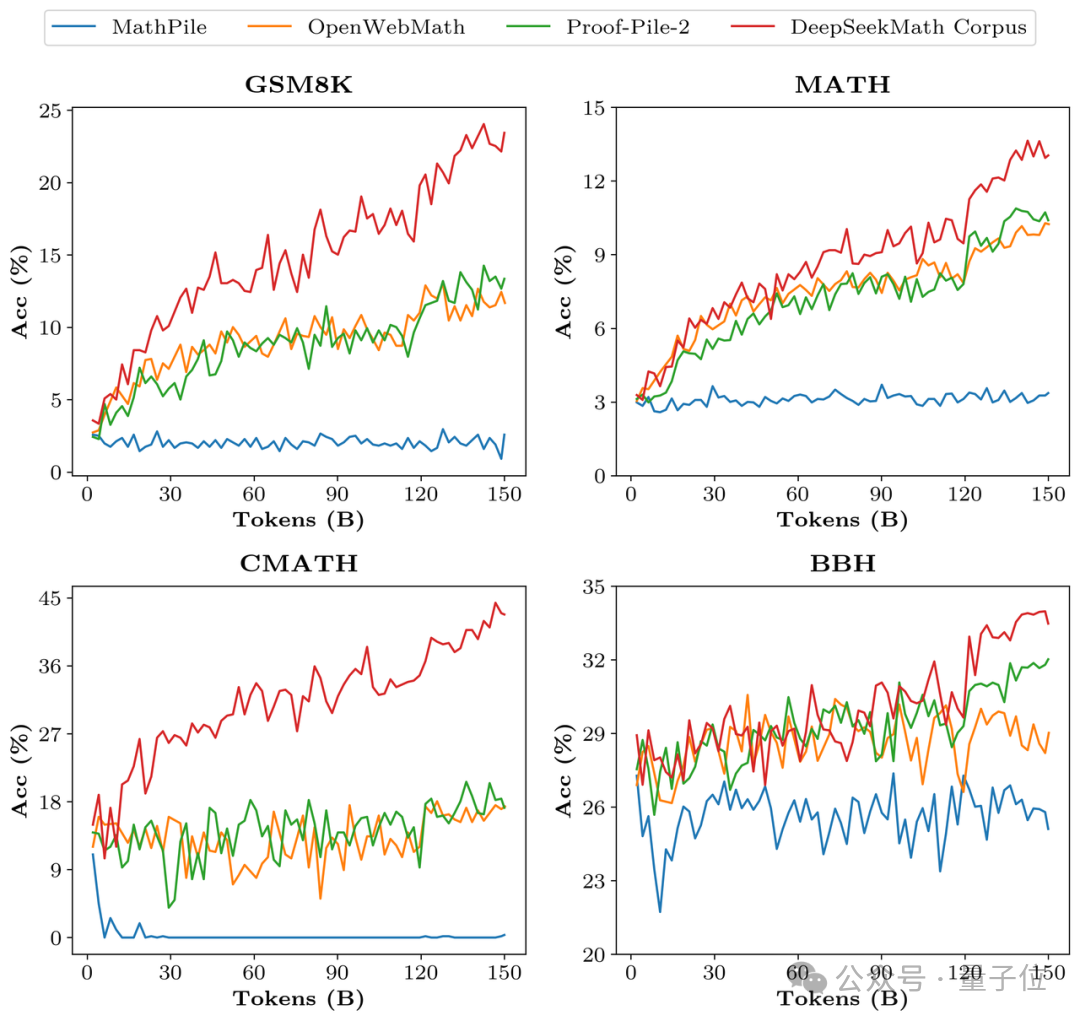
In Bezug auf Trainingsdaten verwendet DeepSeekMath 120 Milliarden hochwertige mathematische Webseitendaten, die aus Common Crawl extrahiert wurden Das DeepSeekMath-Korpus wurde erhalten und das Gesamtdatenvolumen beträgt das Neunfache des Open-Source-Datensatzes OpenWebMath.
Der Datenerfassungsprozess wird iterativ durchgeführt. Nach vier Iterationen sammelte das Forschungsteam mehr als 35 Millionen mathematische Webseiten und die Anzahl der Token erreichte 120 Milliarden.
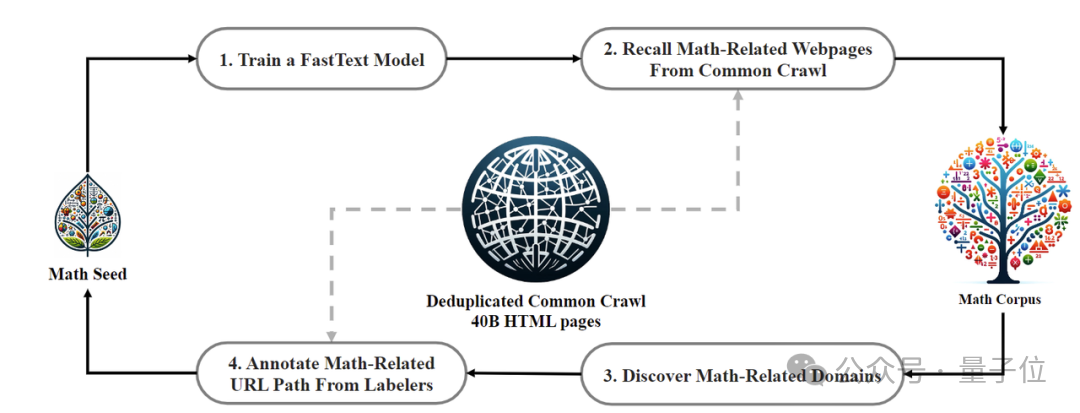
Um sicherzustellen, dass die Trainingsdaten nicht den Inhalt des Testsatzes enthalten (da der Inhalt in GSM8K und MATH in großen Mengen im Internet vorhanden ist), führte das Forschungsteam auch eine spezielle Filterung durch.
Um die Datenqualität von DeepSeekMath Corpus zu überprüfen, trainierte das Forschungsteam 150 Milliarden Token mit mehreren Datensätzen wie MathPile. Dadurch lag Corpus bei mehreren mathematischen Benchmarks deutlich vorne.
In der Ausrichtungsphase erstellte das Forschungsteam zunächst einen 776.000 Stichprobendatensatz für die überwachte Feinabstimmung (SFT) der chinesischen und englischen Mathematik, der drei Formate umfasst: CoT, PoT und werkzeugintegrierte Inferenz.
In der Phase des verstärkenden Lernens (RL) verwendete das Forschungsteam einen effizienten Algorithmus namens „Group Relative Policy Optimization (GRPO) “.
GRPO ist eine Variante der Proximal Policy Optimization(PPO) , bei der die traditionelle Wertfunktion durch eine gruppenbasierte relative Belohnungsschätzung ersetzt wird, die den Rechen- und Speicherbedarf während des Trainings reduzieren kann.
Gleichzeitig wird GRPO durch einen iterativen Prozess trainiert und das Belohnungsmodell wird basierend auf der Ausgabe des Richtlinienmodells kontinuierlich aktualisiert, um eine kontinuierliche Verbesserung der Richtlinie sicherzustellen.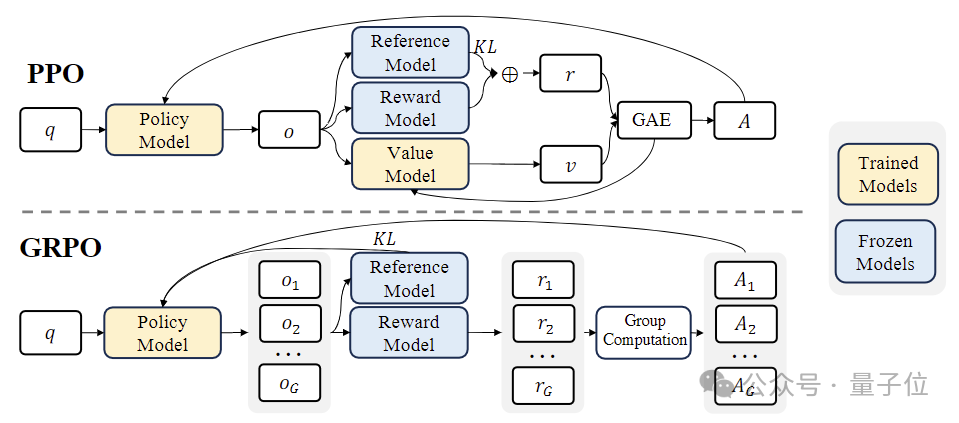

Papieradresse: https://arxiv.org/abs/2402.03300
Das obige ist der detaillierte Inhalt vonDas von einem chinesischen Team erstellte Open-Source-Mathematikmodell 7B übertrifft Milliarden von GPT-4. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
Der Befehl centOS stilldown wird heruntergefahren und die Syntax wird von [Optionen] ausgeführt [Informationen]. Zu den Optionen gehören: -h das System sofort stoppen; -P schalten Sie die Leistung nach dem Herunterfahren aus; -r neu starten; -t Wartezeit. Zeiten können als unmittelbar (jetzt), Minuten (Minuten) oder als bestimmte Zeit (HH: MM) angegeben werden. Hinzugefügten Informationen können in Systemmeldungen angezeigt werden.
 Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Backup- und Wiederherstellungsrichtlinie von GitLab im Rahmen von CentOS -System Um die Datensicherheit und Wiederherstellung der Daten zu gewährleisten, bietet GitLab on CentOS eine Vielzahl von Sicherungsmethoden. In diesem Artikel werden mehrere gängige Sicherungsmethoden, Konfigurationsparameter und Wiederherstellungsprozesse im Detail eingeführt, um eine vollständige GitLab -Sicherungs- und Wiederherstellungsstrategie aufzubauen. 1. Manuell Backup Verwenden Sie den GitLab-RakegitLab: Backup: Befehl erstellen, um die manuelle Sicherung auszuführen. Dieser Befehl unterstützt wichtige Informationen wie GitLab Repository, Datenbank, Benutzer, Benutzergruppen, Schlüssel und Berechtigungen. Die Standardsicherungsdatei wird im Verzeichnis/var/opt/gitlab/backups gespeichert. Sie können /etc /gitlab ändern
 So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
Vollständige Anleitung zur Überprüfung der HDFS -Konfiguration in CentOS -Systemen In diesem Artikel wird die Konfiguration und den laufenden Status von HDFS auf CentOS -Systemen effektiv überprüft. Die folgenden Schritte helfen Ihnen dabei, das Setup und den Betrieb von HDFs vollständig zu verstehen. Überprüfen Sie die Hadoop -Umgebungsvariable: Stellen Sie zunächst sicher, dass die Hadoop -Umgebungsvariable korrekt eingestellt ist. Führen Sie im Terminal den folgenden Befehl aus, um zu überprüfen, ob Hadoop ordnungsgemäß installiert und konfiguriert ist: Hadoopsion-Check HDFS-Konfigurationsdatei: Die Kernkonfigurationsdatei von HDFS befindet sich im/etc/hadoop/conf/verzeichnis, wobei core-site.xml und hdfs-site.xml von entscheidender Bedeutung sind. verwenden
 Was sind die Methoden zur Abstimmung der Leistung von Zookeeper auf CentOS
Apr 14, 2025 pm 03:18 PM
Was sind die Methoden zur Abstimmung der Leistung von Zookeeper auf CentOS
Apr 14, 2025 pm 03:18 PM
Die Zookeper -Leistungsstimmung auf CentOS kann von mehreren Aspekten beginnen, einschließlich Hardwarekonfiguration, Betriebssystemoptimierung, Konfigurationsparameteranpassung, Überwachung und Wartung usw. Hier finden Sie einige spezifische Tuning -Methoden: SSD wird für die Hardwarekonfiguration: Da die Daten von Zookeeper an Disk geschrieben werden, wird empfohlen, SSD zu verbessern, um die I/O -Leistung zu verbessern. Genug Memory: Zookeeper genügend Speicherressourcen zuweisen, um häufige Lesen und Schreiben von häufigen Festplatten zu vermeiden. Multi-Core-CPU: Verwenden Sie Multi-Core-CPU, um sicherzustellen, dass Zookeeper es parallel verarbeiten kann.
 Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Aktivieren Sie die Pytorch -GPU -Beschleunigung am CentOS -System erfordert die Installation von CUDA-, CUDNN- und GPU -Versionen von Pytorch. Die folgenden Schritte führen Sie durch den Prozess: Cuda und Cudnn Installation Bestimmen Sie die CUDA-Version Kompatibilität: Verwenden Sie den Befehl nvidia-smi, um die von Ihrer NVIDIA-Grafikkarte unterstützte CUDA-Version anzuzeigen. Beispielsweise kann Ihre MX450 -Grafikkarte CUDA11.1 oder höher unterstützen. Download und installieren Sie Cudatoolkit: Besuchen Sie die offizielle Website von Nvidiacudatoolkit und laden Sie die entsprechende Version gemäß der höchsten CUDA -Version herunter und installieren Sie sie, die von Ihrer Grafikkarte unterstützt wird. Installieren Sie die Cudnn -Bibliothek:
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
Die Installation von MySQL auf CentOS umfasst die folgenden Schritte: Hinzufügen der entsprechenden MySQL Yum -Quelle. Führen Sie den Befehl mySQL-server aus, um den MySQL-Server zu installieren. Verwenden Sie den Befehl mySQL_SECURE_INSTALLATION, um Sicherheitseinstellungen vorzunehmen, z. B. das Festlegen des Stammbenutzerkennworts. Passen Sie die MySQL -Konfigurationsdatei nach Bedarf an. Tune MySQL -Parameter und optimieren Sie Datenbanken für die Leistung.
 CentOS8 startet SSH
Apr 14, 2025 pm 09:00 PM
CentOS8 startet SSH
Apr 14, 2025 pm 09:00 PM
Der Befehl zum Neustart des SSH -Dienstes lautet: SystemCTL Neustart SSHD. Detaillierte Schritte: 1. Zugriff auf das Terminal und eine Verbindung zum Server; 2. Geben Sie den Befehl ein: SystemCTL Neustart SSHD; 1. Überprüfen Sie den Dienststatus: SystemCTL -Status SSHD.
