
 Technologie-Peripheriegeräte
KI
OccNeRF: Es ist überhaupt keine Lidar-Datenüberwachung erforderlich
Technologie-Peripheriegeräte
KI
OccNeRF: Es ist überhaupt keine Lidar-Datenüberwachung erforderlich
OccNeRF: Es ist überhaupt keine Lidar-Datenüberwachung erforderlich

Oben geschrieben & persönliche Zusammenfassung des Autors
In den letzten Jahren hat die 3D-Belegungsvorhersageaufgabe im Bereich des autonomen Fahrens aufgrund ihrer einzigartigen Vorteile große Aufmerksamkeit in Wissenschaft und Industrie erhalten. Diese Aufgabe liefert detaillierte Informationen für die autonome Fahrplanung und Navigation, indem sie die 3D-Struktur der Umgebung rekonstruiert. Die meisten aktuellen Mainstream-Methoden basieren jedoch auf Etiketten, die auf der Grundlage von LiDAR-Punktwolken generiert werden, um das Netzwerktraining zu überwachen. In einer aktuellen OccNeRF-Studie schlugen die Autoren eine selbstüberwachte Multikamera-Belegungsvorhersagemethode namens „Parameterized Occupancy Fields“ vor. Diese Methode löst das Problem der Grenzenlosigkeit in Außenszenen und organisiert die Sampling-Strategie neu. Anschließend wird das besetzte Feld mithilfe der Volumenrendering-Technologie (Volume Rendering) in eine Multikamera-Tiefenkarte umgewandelt und durch photometrische Konsistenz mehrerer Bilder (photometrischer Fehler) überwacht. Darüber hinaus nutzt die Methode auch ein vorab trainiertes semantisches Segmentierungsmodell mit offenem Vokabular, um 2D-semantische Beschriftungen zu generieren und das Berufsfeld mit semantischen Informationen auszustatten. Dieses semantische Segmentierungsmodell mit offenem Lexikon ist in der Lage, verschiedene Objekte in einer Szene zu segmentieren und jedem Objekt semantische Bezeichnungen zuzuweisen. Durch die Kombination dieser semantischen Bezeichnungen mit Belegungsfeldern können Modelle die Umgebung besser verstehen und genauere Vorhersagen treffen. Zusammenfassend erreicht die OccNeRF-Methode eine hochpräzise Belegungsvorhersage in autonomen Fahrszenarien durch die kombinierte Verwendung von parametrisierten Belegungsfeldern, Volumenrendering und fotometrischer Konsistenz mit mehreren Bildern sowie mit einem semantischen Segmentierungsmodell mit offenem Vokabular. Diese Methode stellt dem autonomen Fahrsystem mehr Umgebungsinformationen zur Verfügung und soll die Sicherheit und Zuverlässigkeit des autonomen Fahrens verbessern.

- Papier-Link: https://arxiv.org/pdf/2312.09243.pdf
- Code-Link: https://github.com/LinShan-Bin/OccNeRF
OccNeRF-Problemhintergrund
In den letzten Jahren wurden mit der rasanten Entwicklung der Technologie der künstlichen Intelligenz große Fortschritte im Bereich des autonomen Fahrens erzielt. Die 3D-Wahrnehmung ist die Grundlage für autonomes Fahren und liefert notwendige Informationen für spätere Planungen und Entscheidungen. Bei herkömmlichen Methoden kann Lidar genaue 3D-Daten direkt erfassen, aber die hohen Kosten des Sensors und die spärlichen Scanpunkte schränken seine praktische Anwendung ein. Im Gegensatz dazu sind bildbasierte 3D-Erfassungsmethoden kostengünstig und effektiv und finden zunehmend Beachtung. Die Multikamera Die 3D-Objekterkennung ist seit einiger Zeit der Mainstream für 3D-Szenenverständnisaufgaben, kann jedoch die unbegrenzten Kategorien in der realen Welt nicht bewältigen und leidet unter der Long-Tail-Verteilung von Daten .
Die 3D-Belegungsvorhersage kann diese Mängel gut ausgleichen, indem sie die Geometrie der umgebenden Szene durch Multi-View-Eingabe direkt rekonstruiert. Die meisten vorhandenen Methoden konzentrieren sich auf Modelldesign und Leistungsoptimierung und stützen sich auf von LiDAR-Punktwolken generierte Beschriftungen zur Überwachung des Netzwerktrainings, was in bildbasierten Systemen nicht verfügbar ist. Mit anderen Worten: Wir müssen immer noch teure Datenerfassungsfahrzeuge verwenden, um Trainingsdaten zu sammeln und eine große Menge realer Daten ohne LiDAR-Punktwolken-gestützte Annotation zu verschwenden, was die Entwicklung der 3D-Belegungsvorhersage bis zu einem gewissen Grad einschränkt. Daher ist die Erforschung der selbstüberwachten 3D-Belegungsvorhersage eine sehr wertvolle Richtung.Detaillierte Erläuterung des OccNeRF-Algorithmus
Die folgende Abbildung zeigt den grundlegenden Prozess der OccNeRF-Methode. Das Modell verwendet Bilder mit mehreren Kameras
als Eingabe, verwendet zunächst das 2D-Backbone, um Merkmalevon N Bildern zu extrahieren, und erhält dann direkt 3D-Merkmale durch einfache Projektion und bilineare Interpolation (unter parametrisiertem Raum ) und schließlich durch 3D Das CNN-Netzwerk optimiert 3D-Funktionen und gibt Vorhersagen aus. Um das Modell zu trainieren, generiert die OccNeRF-Methode durch Volumenrendering eine Tiefenkarte des aktuellen Frames und führt den vorherigen und nächsten Frame ein, um den photometrischen Verlust zu berechnen. Um weitere Timing-Informationen einzuführen, verwendet OccNeRF ein Belegungsfeld, um Multi-Frame-Tiefenkarten zu rendern und die Verlustfunktion zu berechnen. Gleichzeitig rendert OccNeRF gleichzeitig auch zweidimensionale semantische Karten und wird vom „Open Lexicon Semantic Segmentation Model“ überwacht. Parameterisierte Belegungsfelder
Parameterisierte Belegungsfelder werden vorgeschlagen, um das Problem der „Wahrnehmungsbereichslücke“ zwischen der Kamera und dem belegten Raster zu lösen. Theoretisch können Kameras Objekte in unendlicher Entfernung erfassen, während bisherige Belegungsvorhersagemodelle nur nähere Räume berücksichtigen (z. B. innerhalb von 40 m). Bei überwachten Methoden kann das Modell anhand von Überwachungssignalen lernen, entfernte Objekte zu ignorieren. Wenn bei unüberwachten Methoden nur noch der Nahraum berücksichtigt wird, wirkt sich das Vorhandensein einer großen Anzahl von Objekten außerhalb der Reichweite im Bild negativ aus Einfluss auf den Optimierungsprozess. Auf dieser Grundlage verwendet OccNeRF parametrisierte Belegungsfelder, um eine unbegrenzte Auswahl an Außenszenen zu modellieren. 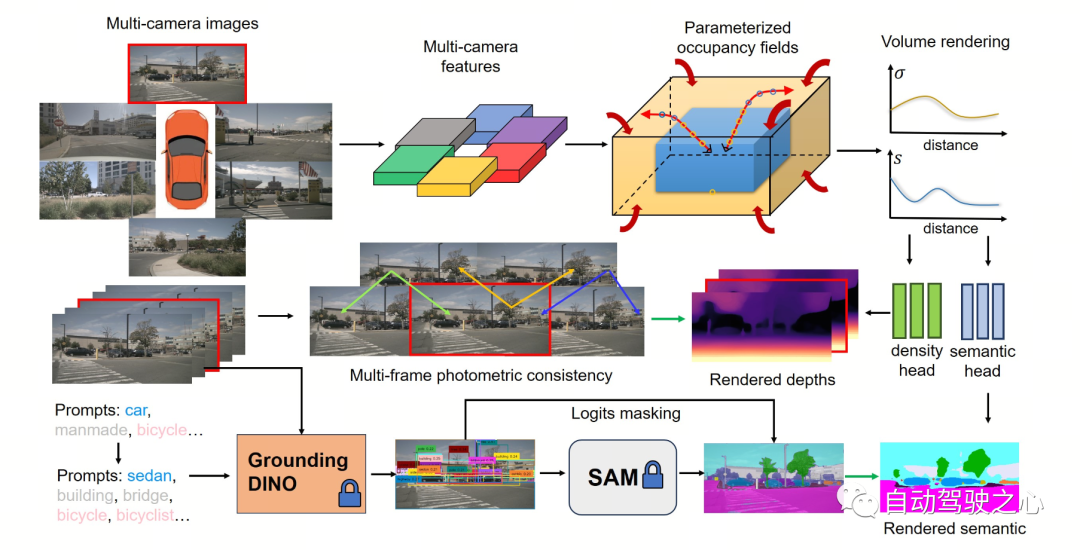
Der Parametrisierungsraum in OccNeRF ist in interne und externe unterteilt. Der innere Raum ist eine lineare Abbildung der ursprünglichen Koordinaten unter Beibehaltung einer hohen Auflösung, während der äußere Raum einen unendlichen Bereich darstellt. Konkret nimmt OccNeRF die folgenden Änderungen an den Koordinaten des Mittelpunkts im 3D-Raum vor:
wobei die Koordinate ist, ein einstellbarer Parameter ist, der den entsprechenden Grenzwert des Innenraums angibt, ist ebenfalls einstellbar. Der angepasste Parameter stellt den Anteil des belegten Innenraums dar. Beim Generieren parametrisierter Belegungsfelder tastet OccNeRF zunächst den parametrisierten Raum ab, erhält die ursprünglichen Koordinaten durch inverse Transformation, projiziert dann die ursprünglichen Koordinaten auf die Bildebene und erhält schließlich das Belegungsfeld durch Abtastung und dreidimensionale Faltung.
Multi-Frame-Tiefenschätzung
Um das Belegungsnetzwerk zu trainieren, wählt OccNeRF die Verwendung von Volumenrendering, um die Belegung in eine Tiefenkarte umzuwandeln und diese durch eine photometrische Verlustfunktion zu überwachen. Die Sampling-Strategie ist beim Rendern von Tiefenkarten wichtig. Wenn Sie im parametrisierten Raum direkt eine gleichmäßige Abtastung basierend auf Tiefe oder Parallaxe durchführen, sind die Abtastpunkte im Innen- oder Außenraum ungleichmäßig verteilt, was sich auf den Optimierungsprozess auswirkt. Daher schlägt OccNeRF eine direkte, gleichmäßige Abtastung im parametrisierten Raum unter der Voraussetzung vor, dass sich die Kameramitte nahe am Ursprung befindet. Darüber hinaus rendert und überwacht OccNeRF während des Trainings Multi-Frame-Tiefenkarten.
Die folgende Abbildung veranschaulicht visuell die Vorteile der Verwendung parametrischer räumlicher Darstellung. (Die dritte Zeile verwendet den parametrisierten Raum, die zweite Zeile nicht.)

Semantische Label-Generierung
OccNeRF verwendet vorab trainiertes GroundedSAM (Grounding DINO + SAM), um 2D-semantische Labels zu generieren. Um qualitativ hochwertige Etiketten zu generieren, wendet OccNeRF zwei Strategien an: Die eine ist die „prompte Wortoptimierung“, die vage Kategorien in nuScenes durch präzise Beschreibungen ersetzt. In OccNeRF werden drei Strategien verwendet, um Aufforderungswörter zu optimieren: mehrdeutige Wortersetzung (Auto wird durch Limousine ersetzt), Wort-zu-Wort-Mehrwort-Ersetzung (künstlich gemacht wird durch Gebäude, Werbetafel und Brücke ersetzt) und zusätzliche Informationen werden eingeführt (Fahrrad ist). ersetzt durch Fahrrad, Radfahrer). Die zweite Möglichkeit besteht darin, die Kategorie anhand der Konfidenz des Erkennungsrahmens in Grounding DINO anstelle der pixelweisen Konfidenz von SAM zu bestimmen. Der von OccNeRF erzeugte semantische Etiketteneffekt ist wie folgt:
OccNeRF-Versuchsergebnisse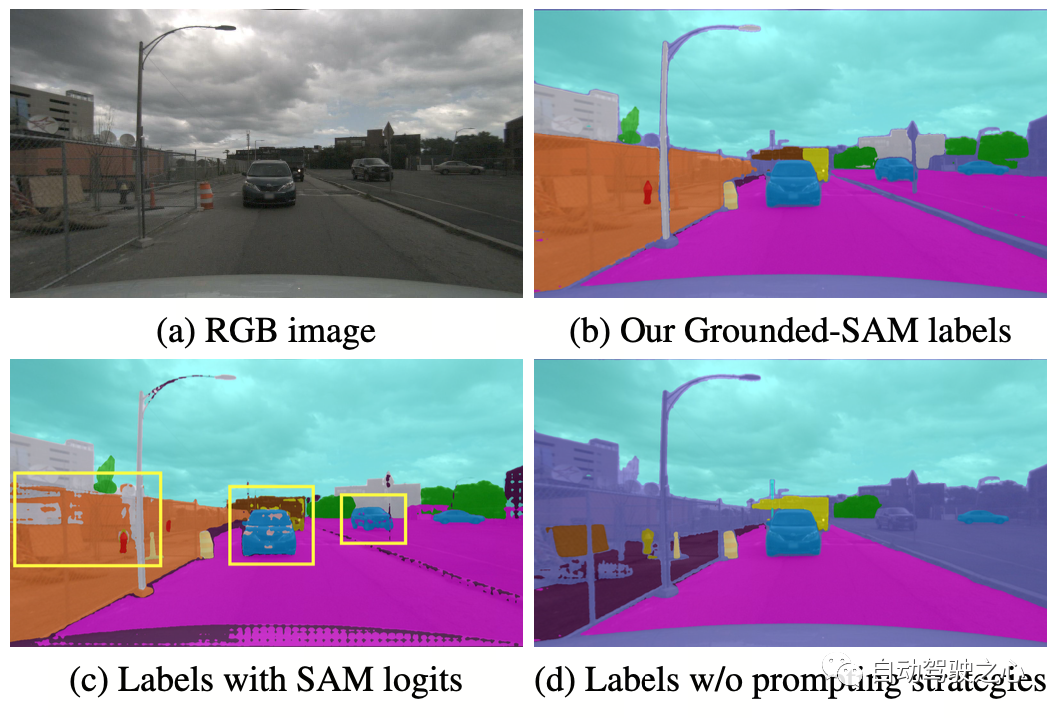
OccNeRF führte Experimente mit nuScenes durch und führte hauptsächlich selbstüberwachte Tiefenschätzungs- und 3D-Belegungsvorhersageaufgaben mit mehreren Ansichten durch. Selbstüberwachte Tiefenschätzung mit mehreren Ansichten
Die Leistung der selbstüberwachten Tiefenschätzung mit mehreren Ansichten von OccNeRF auf nuScenes ist in der folgenden Tabelle dargestellt. Es ist ersichtlich, dass OccNeRF basierend auf der 3D-Modellierung die 2D-Methode deutlich übertrifft und auch SimpleOcc übertrifft, was vor allem auf den unbegrenzten räumlichen Bereich zurückzuführen ist, den OccNeRF für Außenszenen modelliert.
Einige Visualisierungen im Papier sind wie folgt: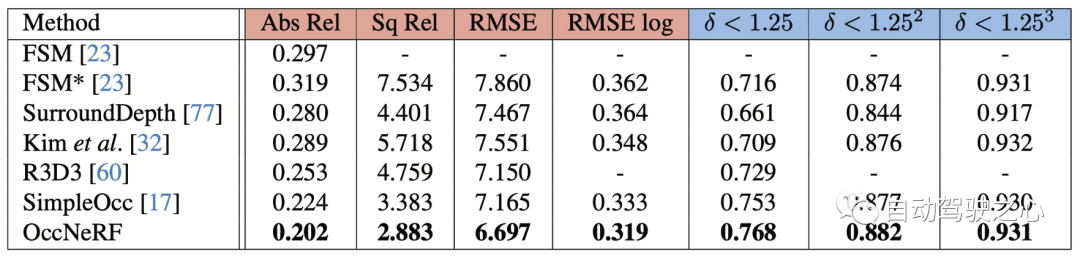
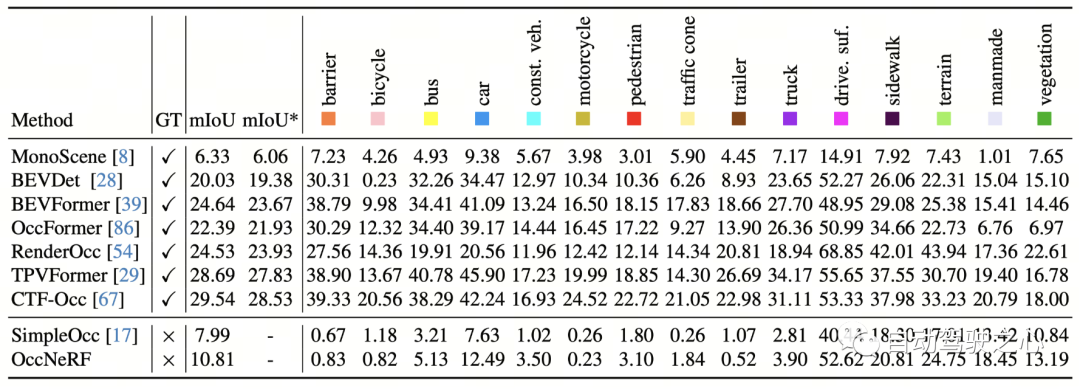
 Die 3D-Belegungsvorhersageleistung von OccNeRF auf nuScenes ist in der folgenden Tabelle dargestellt. Da OccNeRF überhaupt keine annotierten Daten verwendet, bleibt seine Leistung immer noch hinter überwachten Methoden zurück. Allerdings haben einige Kategorien, wie zum Beispiel befahrbare Oberflächen und künstliche, eine vergleichbare Leistung wie überwachte Methoden erzielt.
Die 3D-Belegungsvorhersageleistung von OccNeRF auf nuScenes ist in der folgenden Tabelle dargestellt. Da OccNeRF überhaupt keine annotierten Daten verwendet, bleibt seine Leistung immer noch hinter überwachten Methoden zurück. Allerdings haben einige Kategorien, wie zum Beispiel befahrbare Oberflächen und künstliche, eine vergleichbare Leistung wie überwachte Methoden erzielt.
Zusammenfassung 
In einer Zeit, in der viele Automobilhersteller versuchen, LiDAR-Sensoren zu entfernen, wie können Tausende unbeschrifteter Bilder sinnvoll genutzt werden? Daten sind ein wichtiges Thementhema. Und OccNeRF hat uns einen wertvollen Versuch beschert.
Originallink: https://mp.weixin.qq.com/s/UiYEeauAGVtT0c5SB2tHEA
Das obige ist der detaillierte Inhalt vonOccNeRF: Es ist überhaupt keine Lidar-Datenüberwachung erforderlich. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Oben geschrieben und persönliches Verständnis des Autors. Dreidimensionales Gaussplatting (3DGS) ist eine transformative Technologie, die in den letzten Jahren in den Bereichen explizite Strahlungsfelder und Computergrafik entstanden ist. Diese innovative Methode zeichnet sich durch die Verwendung von Millionen von 3D-Gaußkurven aus, was sich stark von der Neural Radiation Field (NeRF)-Methode unterscheidet, die hauptsächlich ein implizites koordinatenbasiertes Modell verwendet, um räumliche Koordinaten auf Pixelwerte abzubilden. Mit seiner expliziten Szenendarstellung und differenzierbaren Rendering-Algorithmen garantiert 3DGS nicht nur Echtzeit-Rendering-Fähigkeiten, sondern führt auch ein beispielloses Maß an Kontrolle und Szenenbearbeitung ein. Dies positioniert 3DGS als potenziellen Game-Changer für die 3D-Rekonstruktion und -Darstellung der nächsten Generation. Zu diesem Zweck geben wir erstmals einen systematischen Überblick über die neuesten Entwicklungen und Anliegen im Bereich 3DGS.
 Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Gestern wurde ich während des Interviews gefragt, ob ich irgendwelche Long-Tail-Fragen gestellt hätte, also dachte ich, ich würde eine kurze Zusammenfassung geben. Das Long-Tail-Problem des autonomen Fahrens bezieht sich auf Randfälle bei autonomen Fahrzeugen, also mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Das wahrgenommene Long-Tail-Problem ist einer der Hauptgründe, die derzeit den betrieblichen Designbereich intelligenter autonomer Einzelfahrzeugfahrzeuge einschränken. Die zugrunde liegende Architektur und die meisten technischen Probleme des autonomen Fahrens wurden gelöst, und die verbleibenden 5 % der Long-Tail-Probleme wurden nach und nach zum Schlüssel zur Einschränkung der Entwicklung des autonomen Fahrens. Zu diesen Problemen gehören eine Vielzahl fragmentierter Szenarien, Extremsituationen und unvorhersehbares menschliches Verhalten. Der „Long Tail“ von Randszenarien beim autonomen Fahren bezieht sich auf Randfälle in autonomen Fahrzeugen (AVs). Randfälle sind mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. diese seltenen Ereignisse
 Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
0. Vorab geschrieben&& Persönliches Verständnis, dass autonome Fahrsysteme auf fortschrittlichen Wahrnehmungs-, Entscheidungs- und Steuerungstechnologien beruhen, indem sie verschiedene Sensoren (wie Kameras, Lidar, Radar usw.) verwenden, um die Umgebung wahrzunehmen, und Algorithmen und Modelle verwenden für Echtzeitanalysen und Entscheidungsfindung. Dies ermöglicht es Fahrzeugen, Verkehrszeichen zu erkennen, andere Fahrzeuge zu erkennen und zu verfolgen, das Verhalten von Fußgängern vorherzusagen usw. und sich so sicher an komplexe Verkehrsumgebungen anzupassen. Diese Technologie erregt derzeit große Aufmerksamkeit und gilt als wichtiger Entwicklungsbereich für die Zukunft des Transportwesens . eins. Aber was autonomes Fahren schwierig macht, ist herauszufinden, wie man dem Auto klarmachen kann, was um es herum passiert. Dies erfordert, dass der dreidimensionale Objekterkennungsalgorithmus im autonomen Fahrsystem Objekte in der Umgebung, einschließlich ihrer Standorte, genau wahrnehmen und beschreiben kann.
 CLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern
Mar 26, 2024 pm 12:41 PM
Oben geschrieben und das persönliche Verständnis des Autors: Derzeit spielt das Wahrnehmungsmodul im gesamten autonomen Fahrsystem eine entscheidende Rolle Das Steuermodul im autonomen Fahrsystem trifft zeitnahe und korrekte Urteile und Verhaltensentscheidungen. Derzeit sind Autos mit autonomen Fahrfunktionen in der Regel mit einer Vielzahl von Dateninformationssensoren ausgestattet, darunter Rundumsichtkamerasensoren, Lidar-Sensoren und Millimeterwellenradarsensoren, um Informationen in verschiedenen Modalitäten zu sammeln und so genaue Wahrnehmungsaufgaben zu erfüllen. Der auf reinem Sehen basierende BEV-Wahrnehmungsalgorithmus wird von der Industrie aufgrund seiner geringen Hardwarekosten und einfachen Bereitstellung bevorzugt, und seine Ausgabeergebnisse können problemlos auf verschiedene nachgelagerte Aufgaben angewendet werden.
 Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Die Trajektorienvorhersage spielt eine wichtige Rolle beim autonomen Fahren. Unter autonomer Fahrtrajektorienvorhersage versteht man die Vorhersage der zukünftigen Fahrtrajektorie des Fahrzeugs durch die Analyse verschiedener Daten während des Fahrvorgangs. Als Kernmodul des autonomen Fahrens ist die Qualität der Trajektorienvorhersage von entscheidender Bedeutung für die nachgelagerte Planungssteuerung. Die Trajektorienvorhersageaufgabe verfügt über einen umfangreichen Technologie-Stack und erfordert Vertrautheit mit der dynamischen/statischen Wahrnehmung des autonomen Fahrens, hochpräzisen Karten, Fahrspurlinien, Fähigkeiten in der neuronalen Netzwerkarchitektur (CNN&GNN&Transformer) usw. Der Einstieg ist sehr schwierig! Viele Fans hoffen, so schnell wie möglich mit der Flugbahnvorhersage beginnen zu können und Fallstricke zu vermeiden. Heute werde ich eine Bestandsaufnahme einiger häufiger Probleme und einführender Lernmethoden für die Flugbahnvorhersage machen! Einführungsbezogenes Wissen 1. Sind die Vorschaupapiere in Ordnung? A: Schauen Sie sich zuerst die Umfrage an, S
 SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
Originaltitel: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper-Link: https://arxiv.org/pdf/2402.02519.pdf Code-Link: https://github.com/HKUST-Aerial-Robotics/SIMPL Autor: Hong Kong University of Science und Technologie DJI-Papieridee: Dieses Papier schlägt eine einfache und effiziente Bewegungsvorhersagebasislinie (SIMPL) für autonome Fahrzeuge vor. Im Vergleich zum herkömmlichen Agent-Cent
 nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
Vorab geschrieben und Ausgangspunkt Das End-to-End-Paradigma verwendet ein einheitliches Framework, um Multitasking in autonomen Fahrsystemen zu erreichen. Trotz der Einfachheit und Klarheit dieses Paradigmas bleibt die Leistung von End-to-End-Methoden für das autonome Fahren bei Teilaufgaben immer noch weit hinter Methoden für einzelne Aufgaben zurück. Gleichzeitig erschweren die in früheren End-to-End-Methoden weit verbreiteten Funktionen der dichten Vogelperspektive (BEV) die Skalierung auf mehr Modalitäten oder Aufgaben. Hier wird ein Sparse-Search-zentriertes End-to-End-Paradigma für autonomes Fahren (SparseAD) vorgeschlagen, bei dem die Sparse-Suche das gesamte Fahrszenario, einschließlich Raum, Zeit und Aufgaben, ohne dichte BEV-Darstellung vollständig abbildet. Insbesondere ist eine einheitliche, spärliche Architektur für die Aufgabenerkennung einschließlich Erkennung, Verfolgung und Online-Zuordnung konzipiert. Zudem schwer
 Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Im vergangenen Monat hatte ich aus bekannten Gründen einen sehr intensiven Austausch mit verschiedenen Lehrern und Mitschülern der Branche. Ein unvermeidliches Thema im Austausch ist natürlich End-to-End und der beliebte Tesla FSDV12. Ich möchte diese Gelegenheit nutzen, einige meiner aktuellen Gedanken und Meinungen als Referenz und Diskussion darzulegen. Wie definiert man ein durchgängiges autonomes Fahrsystem und welche Probleme sollten voraussichtlich durchgängig gelöst werden? Gemäß der traditionellsten Definition bezieht sich ein End-to-End-System auf ein System, das Rohinformationen von Sensoren eingibt und für die Aufgabe relevante Variablen direkt ausgibt. Bei der Bilderkennung kann CNN beispielsweise als End-to-End bezeichnet werden, verglichen mit der herkömmlichen Methode zum Extrahieren von Merkmalen + Klassifizieren. Bei autonomen Fahraufgaben werden Eingabedaten verschiedener Sensoren (Kamera/LiDAR) benötigt
