
 Technologie-Peripheriegeräte
KI
Verzichten Sie auf die Encoder-Decoder-Architektur und verwenden Sie das Diffusionsmodell zur Kantenerkennung, das effektiver ist. Die National University of Defense Technology hat DiffusionEdge vorgeschlagen
Technologie-Peripheriegeräte
KI
Verzichten Sie auf die Encoder-Decoder-Architektur und verwenden Sie das Diffusionsmodell zur Kantenerkennung, das effektiver ist. Die National University of Defense Technology hat DiffusionEdge vorgeschlagen
Verzichten Sie auf die Encoder-Decoder-Architektur und verwenden Sie das Diffusionsmodell zur Kantenerkennung, das effektiver ist. Die National University of Defense Technology hat DiffusionEdge vorgeschlagen

Aktuelle Deep-Edge-Erkennungsnetzwerke verwenden normalerweise eine Encoder-Decoder-Architektur, die Up- und Down-Sampling-Module enthält, um mehrstufige Funktionen besser zu extrahieren. Diese Struktur schränkt jedoch die Ausgabe genauer und detaillierter Kantenerkennungsergebnisse des Netzwerks ein.
Als Antwort auf dieses Problem bietet ein Vortrag auf der AAAI 2024 eine neue Lösung.

- Papiertitel: DiffusionEdge: Diffusion Probabilistic Model for Crisp Edge Detection
- Autoren: Ye Yunfan (National University of Defense Technology), Xu Kai (National University of Defense Technology), Huang Yuxing (Nationale Universität für Verteidigungstechnologie), Yi Renjiao (Nationale Universität für Verteidigungstechnologie), Cai Zhiping (Nationale Universität für Verteidigungstechnologie)
- Link zum Papier: https://arxiv.org/abs/2401.02032
- Open-Source-Code: https://github.com/ GuHuangAI/DiffusionEdge
Das iGRAPE Lab der National University of Defense Technology hat eine neue Methode für 2D-Kantenerkennungsaufgaben vorgeschlagen. Diese Methode nutzt ein Diffusionswahrscheinlichkeitsmodell, um Kantenergebniskarten während eines lernenden iterativen Entrauschungsprozesses zu generieren. Um den Verbrauch von Rechenressourcen zu reduzieren, nutzt diese Methode latenten Raum zum Trainieren des Netzwerks und führt ein Modul zur Unsicherheitsdestillation ein, um die Leistung zu optimieren. Gleichzeitig verwendet diese Methode auch eine entkoppelte Architektur, um den Entrauschungsprozess zu beschleunigen, und führt einen adaptiven Fourier-Filter zur Anpassung der Merkmale ein. Mit diesen Designs ist die Methode in der Lage, mit begrenzten Ressourcen stabil zu trainieren und mit weniger Erweiterungsstrategien klare und genaue Kantenkarten vorherzusagen. Experimentelle Ergebnisse zeigen, dass diese Methode andere Methoden in Bezug auf Genauigkeit und Präzision bei vier öffentlichen Benchmark-Datensätzen deutlich übertrifft.
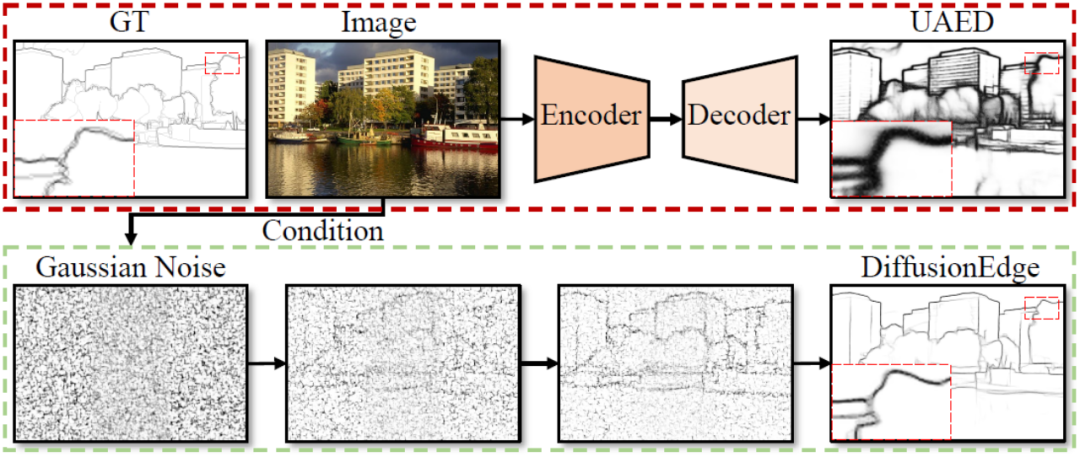
Abbildung 1 Beispiel eines Kantenerkennungsprozesses und Vorteile basierend auf dem Diffusionswahrscheinlichkeitsmodell
Zu den Innovationspunkten dieses Artikels gehören:
Vorgeschlagenes Diffusionsmodell DiffusionEdge für Kantenerkennungsaufgaben, was nicht der Fall ist erfordern eine Nachbearbeitung. Dadurch können Sie dünnere und genauere Kantenkarten vorhersagen.
Um die Schwierigkeiten bei der Anwendung des Diffusionsmodells zu lösen, haben wir verschiedene Techniken entwickelt, um sicherzustellen, dass die Methode im latenten Raum stabil lernt. Gleichzeitig behalten wir auch das Vorwissen zur Unsicherheit auf Pixelebene bei und filtern latente Merkmale im Fourier-Raum adaptiv.
3. Umfangreiche Vergleichsexperimente, die an vier öffentlichen Benchmark-Datensätzen zur Kantenerkennung durchgeführt wurden, zeigen, dass DiffusionEdge hervorragende Leistungsvorteile in Bezug auf Genauigkeit und Feinheit aufweist.
Verwandte Arbeiten
Auf Deep Learning basierende Methoden verwenden normalerweise eine Kodierungs- und Dekodierungsstruktur einschließlich Up- und Down-Sampling, um mehrschichtige Merkmale zu integrieren [1-2], oder integrieren Unsicherheitsinformationen aus mehreren Annotationen, um die Kantenerkennung zu verbessern . Genauigkeit[3]. Aufgrund einer solchen Struktur ist die generierte Kantenergebniskarte jedoch zu umfangreich für nachgelagerte Aufgaben und hängt stark von der Nachbearbeitung ab. Das Problem muss noch gelöst werden. Obwohl viele Arbeiten zu Verlustfunktionen [4-5] und Etikettenkorrekturstrategien [6] untersucht wurden, um dem Netzwerk die Ausgabe feinerer Kanten zu ermöglichen, ist dieser Artikel der Ansicht, dass dieses Feld immer noch eine Methode benötigt, die ohne zusätzliche Module verwendet werden kann Detektoren, die ohne Nachbearbeitungsschritte direkt Genauigkeit und Feinheit erreichen.
Das Diffusionsmodell ist eine Art generatives Modell, das auf der Markov-Kette basiert und Zieldatenproben durch den lernenden Rauschunterdrückungsprozess schrittweise wiederherstellt. Diffusionsmodelle haben in Bereichen wie Computer Vision, Verarbeitung natürlicher Sprache und Audioerzeugung hervorragende Leistungen gezeigt. Durch die Verwendung von Bildern oder anderen modalen Eingaben als zusätzliche Bedingungen zeigt es nicht nur ein großes Potenzial für Wahrnehmungsaufgaben wie Bildsegmentierung [7], Zielerkennung [8] und Lageschätzung [9] usw. .
Methodenbeschreibung
Der Gesamtrahmen der in diesem Artikel vorgeschlagenen DiffusionEdge-Methode ist in Abbildung 2 dargestellt. Inspiriert durch frühere Arbeiten trainiert diese Methode ein Diffusionsmodell mit entkoppelter Struktur im latenten Raum und gibt Bilder als zusätzliche bedingte Hinweise ein. Diese Methode führt einen adaptiven Fourier-Filter für die Frequenzanalyse ein. Um Unsicherheitsinformationen auf Pixelebene von mehreren Annotatoren beizubehalten und den Bedarf an Rechenressourcen zu reduzieren, wird auch direkt die Kreuzentropieverlustoptimierung in destillierter Weise verwendet.
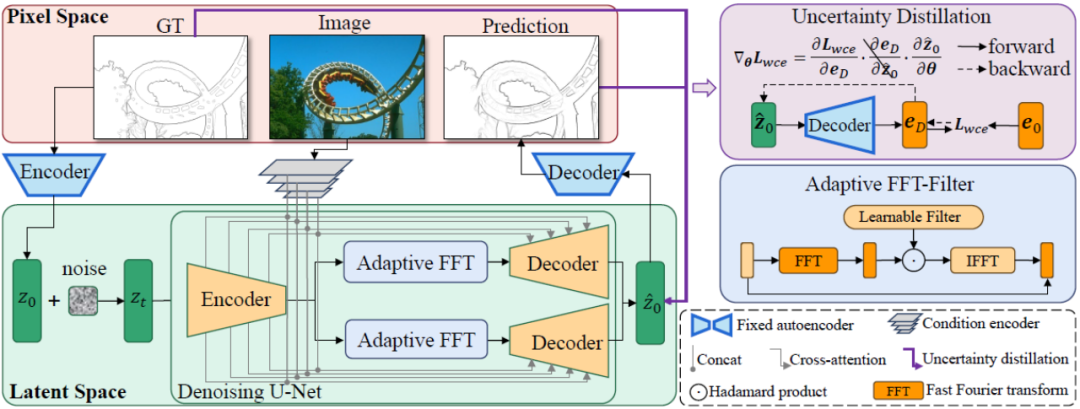
Abbildung 2 Schematische Darstellung der Gesamtstruktur von DiffusionEdge
Da das aktuelle Diffusionsmodell mit Problemen wie zu vielen Abtastschritten und zu langen Inferenzzeiten behaftet ist, ist diese Methode von DDM [10] inspiriert und verwendet auch entkoppelte Methoden Diffusion. Modellarchitektur zur Beschleunigung des Sampling-Inferenzprozesses. Unter diesen wird der entkoppelte Vorwärtsdiffusionsprozess durch eine Kombination aus expliziter Übergangswahrscheinlichkeit und Standard-Wiener-Prozess gesteuert:
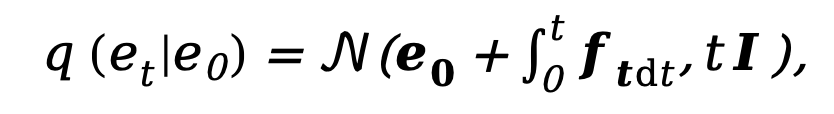
wobei 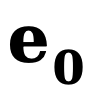 und
und 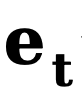 die Anfangskante bzw. Rauschkante darstellen,
die Anfangskante bzw. Rauschkante darstellen, 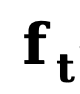 sich auf die Rückwärtskante bezieht Ein expliziter Übertragungsfunktion für Gradienten. Ähnlich wie DDM verwendet diese Methode standardmäßig die konstante Funktion
sich auf die Rückwärtskante bezieht Ein expliziter Übertragungsfunktion für Gradienten. Ähnlich wie DDM verwendet diese Methode standardmäßig die konstante Funktion 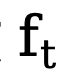 , und der entsprechende umgekehrte Prozess kann ausgedrückt werden als:
, und der entsprechende umgekehrte Prozess kann ausgedrückt werden als:
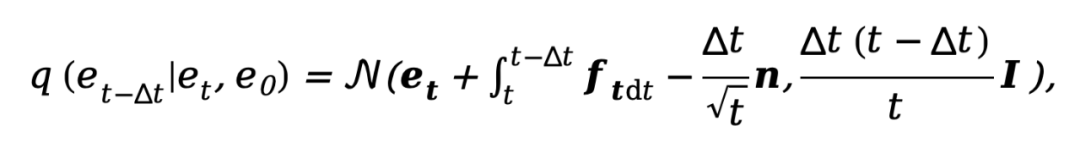
wobei 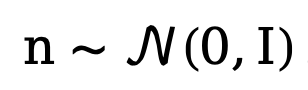 . Um das entkoppelte Diffusionsmodell zu trainieren, erfordert die Methode eine gleichzeitige Überwachung der Daten- und Rauschkomponenten. Daher kann das Trainingsziel wie folgt parametrisiert werden:
. Um das entkoppelte Diffusionsmodell zu trainieren, erfordert die Methode eine gleichzeitige Überwachung der Daten- und Rauschkomponenten. Daher kann das Trainingsziel wie folgt parametrisiert werden:
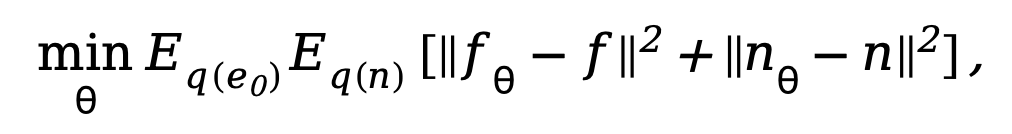
wobei 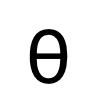 der Parameter im Entrauschungsnetzwerk ist. Da das Diffusionsmodell zu viel Rechenaufwand erfordert, wenn es im ursprünglichen Bildraum trainiert wird, überträgt die in diesem Artikel vorgeschlagene Methode unter Bezugnahme auf die Idee von [11] den Trainingsprozess auf einen latenten Raum mit dem Vierfachen Größe des Downsampling-Raums.
der Parameter im Entrauschungsnetzwerk ist. Da das Diffusionsmodell zu viel Rechenaufwand erfordert, wenn es im ursprünglichen Bildraum trainiert wird, überträgt die in diesem Artikel vorgeschlagene Methode unter Bezugnahme auf die Idee von [11] den Trainingsprozess auf einen latenten Raum mit dem Vierfachen Größe des Downsampling-Raums.
Wie in Abbildung 2 gezeigt, trainiert diese Methode zunächst ein Paar Autoencoder- und Decoder-Netzwerke. Der Encoder komprimiert die Kantenanmerkung in eine latente Variable und der Decoder wird verwendet, um die ursprüngliche Kantenanmerkung wiederherzustellen . Auf diese Weise legt diese Methode während der Trainingsphase des Entrauschungsnetzwerks basierend auf der U-Net-Struktur das Gewicht des Paares von Autoencoder- und Decoder-Netzwerken fest und trainiert den Entrauschungsprozess im latenten Raum, was den Rechenaufwand erheblich reduzieren kann Kosten des Netzwerkressourcenverbrauchs bei gleichzeitiger Aufrechterhaltung einer guten Leistung.
Um die endgültige Leistung des Netzwerks zu verbessern, führt die in diesem Artikel vorgeschlagene Methode ein Modul ein, das verschiedene Frequenzmerkmale im Entkopplungsvorgang adaptiv herausfiltern kann. Wie in der unteren linken Ecke von Abbildung 2 dargestellt, integriert diese Methode den adaptiven Fast-Fourier-Transformationsfilter (Adaptive FFT-Filter) vor der Entkopplungsoperation in das Entrauschungsnetzwerk, um die Out-Edge-Map und das Rauschen adaptiv zu filtern und zu trennen Komponenten. Insbesondere führt die Methode angesichts des Encodermerkmals 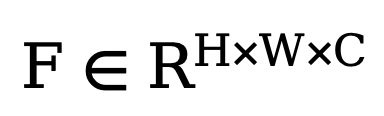 zunächst eine zweidimensionale Fourier-Transformation (FFT) entlang der räumlichen Dimension durch und stellt das transformierte Merkmal als
zunächst eine zweidimensionale Fourier-Transformation (FFT) entlang der räumlichen Dimension durch und stellt das transformierte Merkmal als 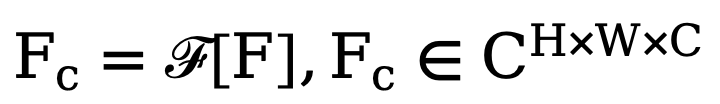 dar. Als nächstes wird zum Trainieren dieses adaptiven Spektrumfiltermoduls eine lernbare Gewichtskarte
dar. Als nächstes wird zum Trainieren dieses adaptiven Spektrumfiltermoduls eine lernbare Gewichtskarte 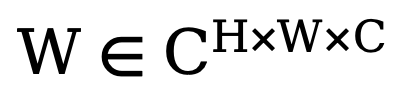 erstellt und ihr W mit Fc multipliziert. Spektralfilter können bestimmte Frequenzen global anpassen und die erlernten Gewichte können an unterschiedliche Häufigkeitsfälle von Zielverteilungen in verschiedenen Datensätzen angepasst werden. Durch das adaptive Herausfiltern unerwünschter Komponenten ordnet diese Methode mithilfe einer inversen schnellen Fourier-Transformationsoperation (IFFT) Merkmale aus dem Frequenzbereich zurück in den räumlichen Bereich. Schließlich vermeiden wir durch die zusätzliche Einführung der Restverbindung aus, dass alle nützlichen Informationen vollständig herausgefiltert werden. Der obige Prozess kann durch die folgende Formel beschrieben werden:
erstellt und ihr W mit Fc multipliziert. Spektralfilter können bestimmte Frequenzen global anpassen und die erlernten Gewichte können an unterschiedliche Häufigkeitsfälle von Zielverteilungen in verschiedenen Datensätzen angepasst werden. Durch das adaptive Herausfiltern unerwünschter Komponenten ordnet diese Methode mithilfe einer inversen schnellen Fourier-Transformationsoperation (IFFT) Merkmale aus dem Frequenzbereich zurück in den räumlichen Bereich. Schließlich vermeiden wir durch die zusätzliche Einführung der Restverbindung aus, dass alle nützlichen Informationen vollständig herausgefiltert werden. Der obige Prozess kann durch die folgende Formel beschrieben werden:
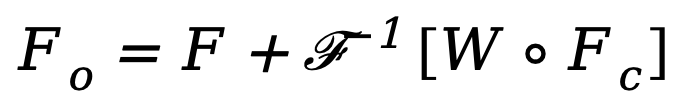
wobei 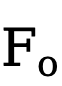 das Ausgabemerkmal ist und o das Hadamard-Produkt darstellt.
das Ausgabemerkmal ist und o das Hadamard-Produkt darstellt.
Aufgrund des hohen Ungleichgewichts in der Anzahl der Kanten- und Nichtkantenpixel (die meisten Pixel sind Nichtkantenhintergrund) führen wir unter Bezugnahme auf frühere Arbeiten auch eine unsichere Verlustfunktion für das Training ein. Da der Wert der wahren Wertkantenwahrscheinlichkeit des i-ten Pixels für das i-te Pixel in der j-ten Kantenkarte 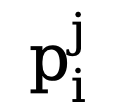 ist, wird der unsichere WCE-Verlust wie folgt berechnet:
ist, wird der unsichere WCE-Verlust wie folgt berechnet:
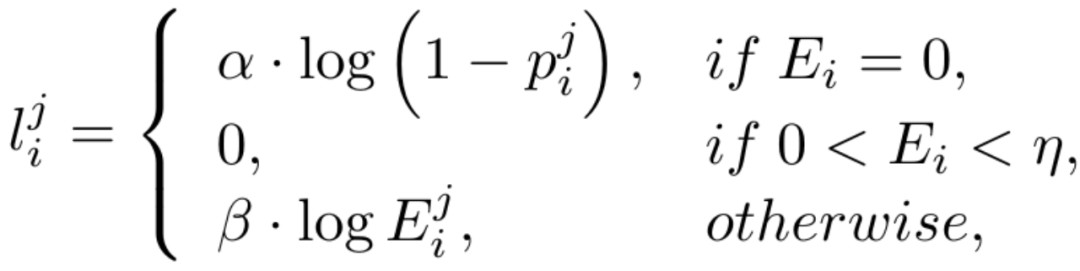
wobei 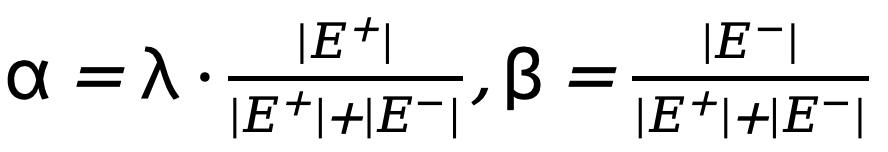 , wobei
, wobei 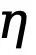 der Schwellenwert ist, der die unsicheren Kantenpixel in der wahren Wertanmerkung bestimmt. Wenn der Pixelwert größer als 0 und kleiner als dieser Schwellenwert ist, werden solche unscharfen Pixelproben mit unzureichender Zuverlässigkeit in der nachfolgenden Optimierung verwendet Prozess wird ignoriert (die Verlustfunktion ist 0).
der Schwellenwert ist, der die unsicheren Kantenpixel in der wahren Wertanmerkung bestimmt. Wenn der Pixelwert größer als 0 und kleiner als dieser Schwellenwert ist, werden solche unscharfen Pixelproben mit unzureichender Zuverlässigkeit in der nachfolgenden Optimierung verwendet Prozess wird ignoriert (die Verlustfunktion ist 0). 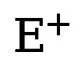 und
und 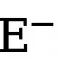 stellen jeweils die Anzahl der Kanten- und Nichtkantenpixel in der mit der Grundwahrheit kommentierten Kantenkarte dar. ist das Gewicht, das zum Ausbalancieren von
stellen jeweils die Anzahl der Kanten- und Nichtkantenpixel in der mit der Grundwahrheit kommentierten Kantenkarte dar. ist das Gewicht, das zum Ausbalancieren von 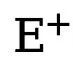 und
und 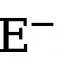 verwendet wird (auf 1,1 eingestellt). Daher wird die endgültige Verlustfunktion für jede Kantenkarte als
verwendet wird (auf 1,1 eingestellt). Daher wird die endgültige Verlustfunktion für jede Kantenkarte als 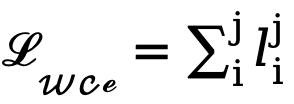 berechnet.
berechnet.
Das Ignorieren verschwommener Pixel mit geringer Konfidenz während des Optimierungsprozesses kann Netzwerkverwirrungen vermeiden, die Konvergenz des Trainingsprozesses stabiler machen und die Leistung des Modells verbessern. Es ist jedoch nahezu unmöglich, den binären Kreuzentropieverlust direkt auf einen latenten Raum anzuwenden, der sowohl numerisch als auch räumlich falsch ausgerichtet ist. Insbesondere verwendet der unsicherheitsbewusste Kreuzentropieverlust einen Schwellenwert 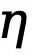 (im Allgemeinen von 0 bis 1), um zu bestimmen, ob ein Pixel eine Kante ist, die aus dem Bildraum definiert ist, während die latenten Variablen einer Normalverteilung folgen und vollständig sind unterschiedlicher Umfang und praktischer Bedeutung. Darüber hinaus lässt sich die Unsicherheit auf Pixelebene nur schwer mit unterschiedlichen Größen codierter und heruntergetasteter latenter Merkmale in Einklang bringen, und beide sind nicht direkt kompatibel. Daher führt die direkte Anwendung des Kreuzentropieverlusts zur Optimierung latenter Variablen zwangsläufig zu einer falschen Wahrnehmung der Unsicherheit.
(im Allgemeinen von 0 bis 1), um zu bestimmen, ob ein Pixel eine Kante ist, die aus dem Bildraum definiert ist, während die latenten Variablen einer Normalverteilung folgen und vollständig sind unterschiedlicher Umfang und praktischer Bedeutung. Darüber hinaus lässt sich die Unsicherheit auf Pixelebene nur schwer mit unterschiedlichen Größen codierter und heruntergetasteter latenter Merkmale in Einklang bringen, und beide sind nicht direkt kompatibel. Daher führt die direkte Anwendung des Kreuzentropieverlusts zur Optimierung latenter Variablen zwangsläufig zu einer falschen Wahrnehmung der Unsicherheit.
Andererseits kann man sich dafür entscheiden, die latenten Variablen zurück auf die Bildebene zu dekodieren und so die vorhergesagte Kantenergebniskarte mithilfe eines unsicherheitsbewussten Kreuzentropieverlusts direkt zu überwachen. Leider ermöglicht diese Implementierung, dass die rückwärts propagierten Parametergradienten das redundante Autoencoder-Netzwerk durchlaufen, was eine effektive Übertragung der Gradienten erschwert. Darüber hinaus führen zusätzliche Gradientenberechnungen im Autoencoder-Netzwerk zu enormen Kosten für den GPU-Speicherverbrauch, was der ursprünglichen Absicht dieser Methode, einen praktischen Kantendetektor zu entwerfen, zuwiderläuft und sich nur schwer auf praktische Anwendungen übertragen lässt. Daher schlägt diese Methode einen Unsicherheitsdestillationsverlust vor, der den Gradienten im latenten Raum direkt optimieren kann. Die rekonstruierte latente Variable sei  , der Decoder des Autoencoder-Netzwerks sei D und das decodierte Kantenergebnis sei eD Erwägt die direkte Berechnung des Gradienten des unsicherheitsbewussten binären Kreuzentropieverlusts
, der Decoder des Autoencoder-Netzwerks sei D und das decodierte Kantenergebnis sei eD Erwägt die direkte Berechnung des Gradienten des unsicherheitsbewussten binären Kreuzentropieverlusts 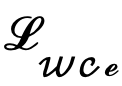 basierend auf der Kettenregel. Die spezifische Berechnungsmethode lautet:
basierend auf der Kettenregel. Die spezifische Berechnungsmethode lautet:
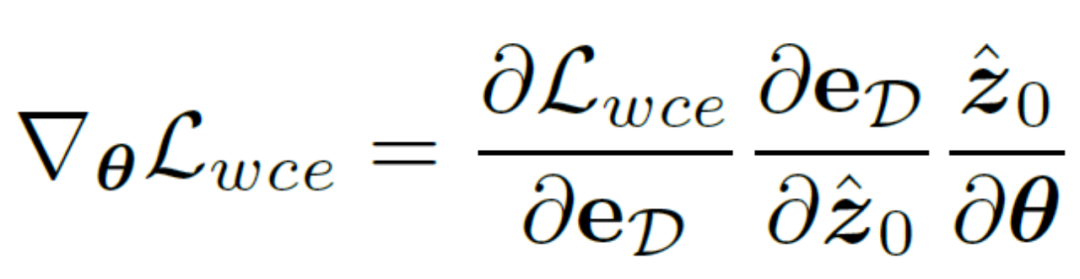
Um die negativen Auswirkungen des Autoencoder-Netzwerks zu beseitigen, wird diese Methode verwendet Der Autoencoder 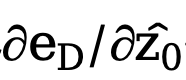 wird direkt übersprungen, um den Gradienten zu übergeben, und die Berechnungsmethode des Gradienten
wird direkt übersprungen, um den Gradienten zu übergeben, und die Berechnungsmethode des Gradienten 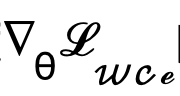 wird geändert und angepasst an:
wird geändert und angepasst an:
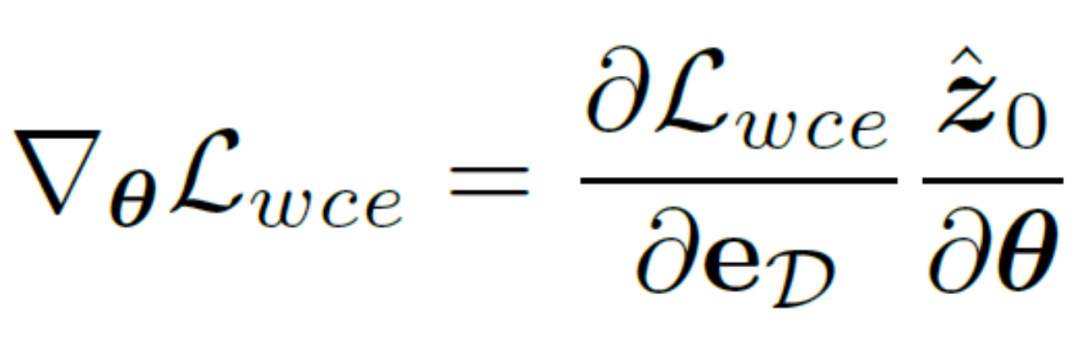
Eine solche Implementierung reduziert den Rechenaufwand erheblich und ermöglicht die direkte Optimierung latenter Variablen mithilfe unsicherheitsbewusster Verlustfunktionen. Auf diese Weise kann das endgültige Trainingsoptimierungsziel dieser Methode in Kombination mit einem zeitlich variierenden Verlustgewicht 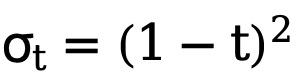 , das sich adaptiv mit der Anzahl der Schritte t ändert, wie folgt ausgedrückt werden:
, das sich adaptiv mit der Anzahl der Schritte t ändert, wie folgt ausgedrückt werden:
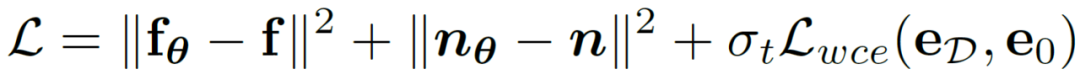
Experimentelle Ergebnisse
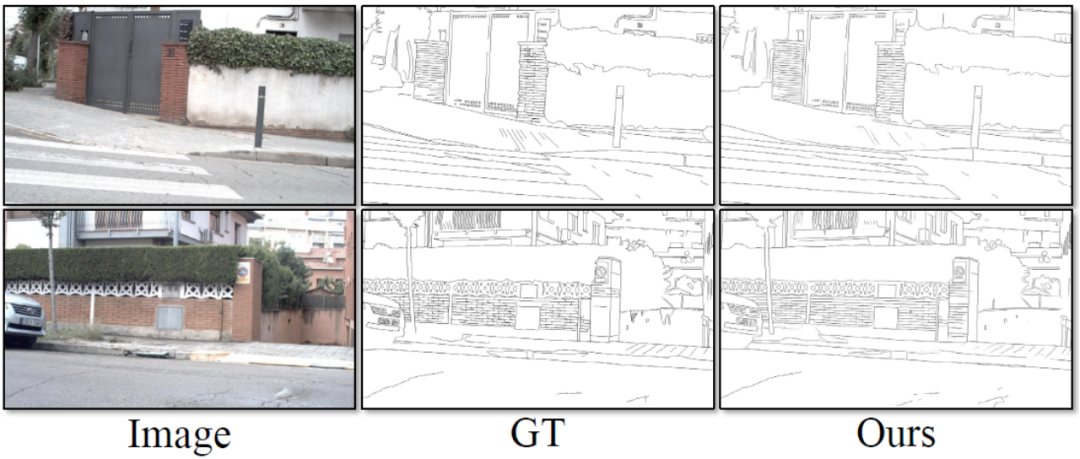
Dies Die Methode umfasst vier Experimente, die mit öffentlichen Standarddatensätzen zur Kantenerkennung durchgeführt wurden, die in diesem Bereich weit verbreitet sind: BSDS, NYUDv2, Multicue und BIPED. Da es schwierig ist, Kantenerkennungsdaten zu kennzeichnen und die Menge der gekennzeichneten Daten relativ gering ist, verwenden frühere Methoden normalerweise verschiedene Strategien, um den Datensatz zu verbessern. Beispielsweise werden Bilder in BSDS durch horizontales Spiegeln (2×), Skalieren (3×) und Drehen (16×) verbessert, was zu einem Trainingssatz führt, der 96-mal größer ist als die Originalversion. Gängige Verbesserungsstrategien, die von früheren Methoden für andere Datensätze verwendet wurden, sind in Tabelle 1 zusammengefasst, wobei F für horizontales Umdrehen, S für Skalierung, R für Rotation, C für Zuschneiden und G für Gammakorrektur steht. Der Unterschied besteht darin, dass diese Methode nur zufällig zugeschnittene Bildfelder von 320320 verwenden muss, um alle Daten zu trainieren. Im BSDS-Datensatz verwendet diese Methode nur zufälliges Umdrehen und Skalieren. Die Ergebnisse des quantitativen Vergleichs sind in Tabelle 2 aufgeführt. In den NYUDv2-, Multicue- und BIPED-Datensätzen muss die Methode nur mit zufälligen Flips trainiert werden. Mit weniger Verbesserungsstrategien schneidet diese Methode bei verschiedenen Datensätzen und verschiedenen Indikatoren besser ab als frühere Methoden. Anhand der Vorhersageergebnisse in Abbildung 3-5 können wir erkennen, dass DiffusionEdge Kantenerkennungsergebnisse erlernen und vorhersagen kann, die nahezu mit denen der GT-Verteilung übereinstimmen. Der Vorteil genauer und klarer Vorhersageergebnisse ist für nachgelagerte Aufgaben, die einer Verfeinerung bedürfen, sehr wichtig . und zeigte auch sein großes Potenzial, direkt auf nachfolgende Aufgaben angewendet zu werden.

Tabelle 1: Verbesserungsstrategien, die von früheren Methoden für vier Kantenerkennungsdatensätze verwendet wurden.
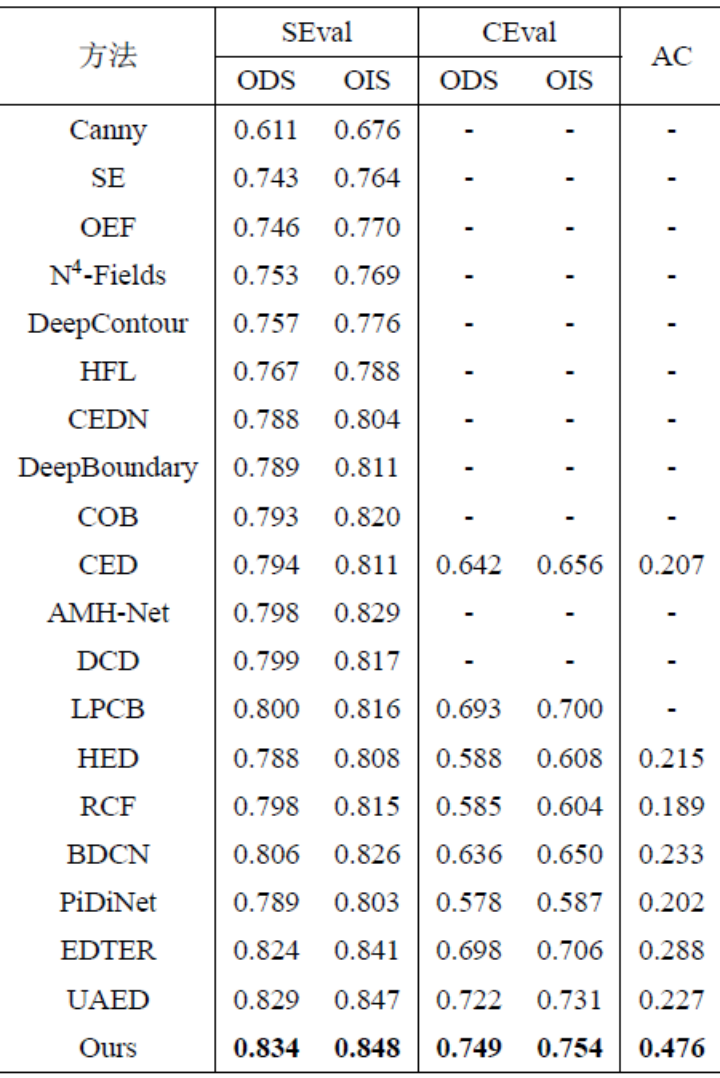
Tabelle 2: Quantitativer Vergleich verschiedener Methoden für den BSDS-Datensatz Abb. 3 Qualitativer Vergleich verschiedener Methoden am BSDS-Datensatz
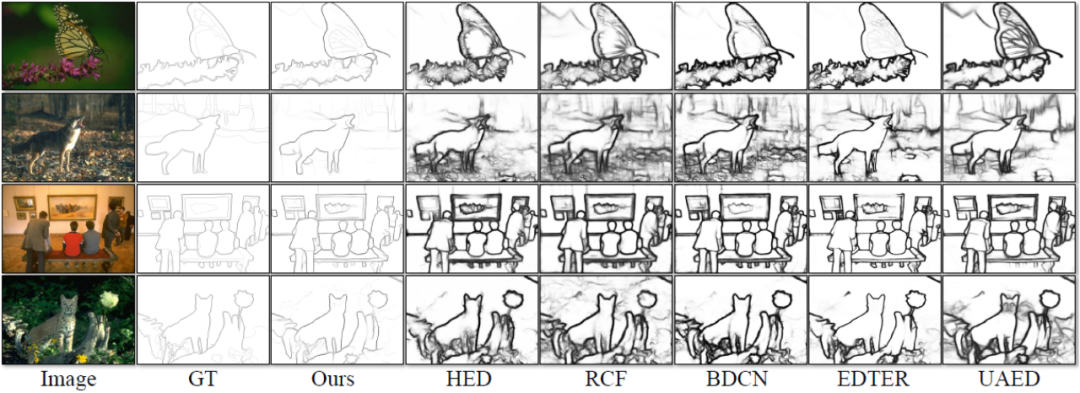
Abbildung 4 Qualitativer Vergleich verschiedener Methoden am NYUDv2-Datensatz
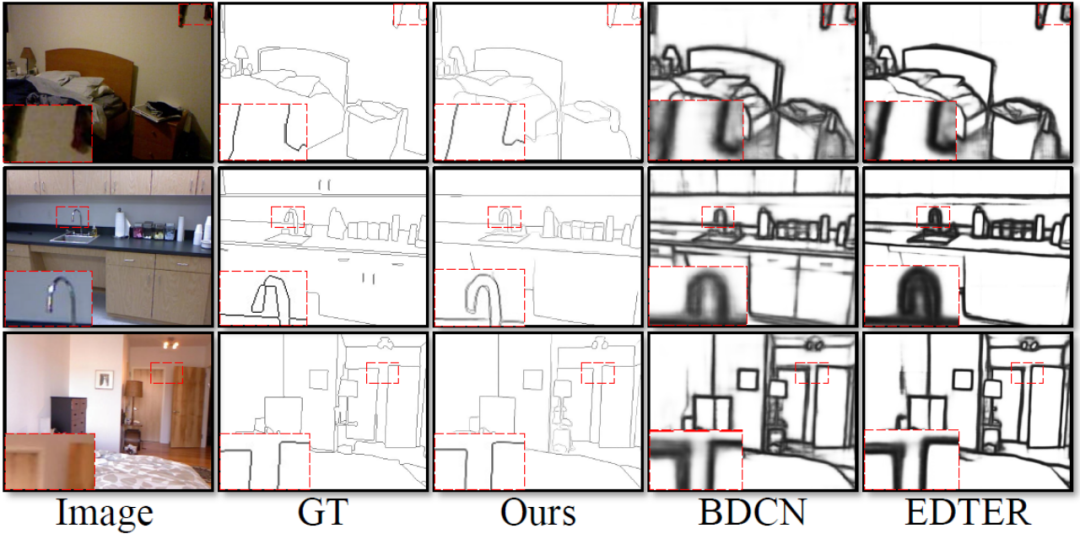
Abbildung 5 Qualitativer Vergleich verschiedener Methoden am BIPED-Datensatz
Das obige ist der detaillierte Inhalt vonVerzichten Sie auf die Encoder-Decoder-Architektur und verwenden Sie das Diffusionsmodell zur Kantenerkennung, das effektiver ist. Die National University of Defense Technology hat DiffusionEdge vorgeschlagen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
Um die Zeitüberschreitung für Vue Axios festzulegen, können wir eine Axios -Instanz erstellen und die Zeitleitungsoption angeben: in globalen Einstellungen: vue.Prototyp. $ Axios = axios.create ({Timeout: 5000}); In einer einzigen Anfrage: this. $ axios.get ('/api/user', {timeout: 10000}).
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
MySQL kann JSON -Daten zurückgeben. Die JSON_EXTRACT -Funktion extrahiert Feldwerte. Über komplexe Abfragen sollten Sie die Where -Klausel verwenden, um JSON -Daten zu filtern, aber auf die Leistungsauswirkungen achten. Die Unterstützung von MySQL für JSON nimmt ständig zu, und es wird empfohlen, auf die neuesten Versionen und Funktionen zu achten.
 So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
Die MySQL -Leistungsoptimierung muss von drei Aspekten beginnen: Installationskonfiguration, Indexierung und Abfrageoptimierung, Überwachung und Abstimmung. 1. Nach der Installation müssen Sie die my.cnf -Datei entsprechend der Serverkonfiguration anpassen, z. 2. Erstellen Sie einen geeigneten Index, um übermäßige Indizes zu vermeiden und Abfrageanweisungen zu optimieren, z. B. den Befehl Erklärung zur Analyse des Ausführungsplans; 3. Verwenden Sie das eigene Überwachungstool von MySQL (ShowProcessList, Showstatus), um die Datenbankgesundheit zu überwachen und die Datenbank regelmäßig zu sichern und zu organisieren. Nur durch kontinuierliche Optimierung dieser Schritte kann die Leistung der MySQL -Datenbank verbessert werden.
 Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Detaillierte Erläuterung von Datenbanksäureattributen Säureattribute sind eine Reihe von Regeln, um die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen sicherzustellen. Sie definieren, wie Datenbanksysteme Transaktionen umgehen, und sorgen dafür, dass die Datenintegrität und -genauigkeit auch im Falle von Systemabstürzen, Leistungsunterbrechungen oder mehreren Benutzern gleichzeitiger Zugriff. Säureattributübersicht Atomizität: Eine Transaktion wird als unteilbare Einheit angesehen. Jeder Teil schlägt fehl, die gesamte Transaktion wird zurückgerollt und die Datenbank behält keine Änderungen bei. Wenn beispielsweise eine Banküberweisung von einem Konto abgezogen wird, jedoch nicht auf ein anderes erhöht wird, wird der gesamte Betrieb widerrufen. begintransaktion; updateAccountsSetBalance = Balance-100WH
