

Verarbeitung von Streaming-HTTP-Antworten


Der PHP-Editor Zimo führt Sie in die Methode zur Verarbeitung von Streaming-HTTP-Antworten ein. Bei der Entwicklung von Webanwendungen müssen wir uns häufig mit dem Herunterladen großer Dateien oder der Übertragung von Echtzeit-Streaming-Medien befassen. Die herkömmliche Methode, den gesamten Antwortinhalt auf einmal zu laden, führt zu einer übermäßigen Speichernutzung und beeinträchtigt die Leistung. Um dieses Problem zu lösen, können wir Streaming-HTTP-Antworten verwenden. Durch Streaming von HTTP-Antworten können Antwortinhalte in Blöcken übertragen werden, wodurch die Speichernutzung reduziert und die Benutzererfahrung verbessert wird. In PHP können wir einige Bibliotheken oder benutzerdefinierte Methoden verwenden, um Streaming-HTTP-Antworten zu implementieren und so unsere Webanwendungen zu optimieren.
Frageninhalt
Ich habe das folgende Beispiel, das eine Verbindung zu einem HTTP-Dienst herstellt, der die Antwort in Blöcken zurückstreamt, um eine JSON-Struktur zu erstellen. Für jeden Block hängt mein Code nach Fertigstellung ein Byte rb 数组和各个行。但是,我的问题是尝试在 rb an, damit ich ihn dekodieren kann.
Übersehe ich hier etwas Offensichtliches?
package main
import (
"bufio"
"bytes"
"fmt"
"io"
"net/http"
)
func main() {
body := []byte("test")
resp, err := http.Post("http://localhost:8281/tap", "application/json", bytes.NewReader(body))
if err != nil {
fmt.Printf("%v\n", err)
return
}
defer resp.Body.Close()
fmt.Printf("Status: [%s]\n", resp.Status)
fmt.Println()
//var rb []byte
reader := bufio.NewReader(resp.Body)
var rb []byte
for {
line, err := reader.ReadBytes('\n')
if err != nil {
if err == io.EOF {
break
}
fmt.Printf("Error reading streamed bytes %v", err)
}
rb = append(rb, line...)
fmt.Println(rb)
}
}Die Lösung
den Fehler im Programm ignorieren und rbabschließen, nachdem die Schleife unterbrochen wurde.
Dieses Programm hat Fehler:
- Das Programm bricht erst bei EOF aus der Schleife aus. Wenn ein anderer Fehler auftritt, dreht sich das Programm für immer.
- Das Programm bewältigt nicht die Situation, in der ReadBytes Daten und Fehler zurückgibt. Dies kann beispielsweise passieren, wenn die Antwort nicht mit einem Trennzeichen endet.
Es sieht so aus, als ob Ihr Ziel darin besteht, die gesamte Reaktion auf rb aufzunehmen. Verwenden Sie dazu io.ReadAll:
resp, err := http.Post("http://localhost:8281/tap", "application/json", bytes.NewReader(body))
if err != nil {
fmt.Printf("%v\n", err)
return
}
defer resp.Body.Close()
rb, err := io.ReadAll(resp.Body)
if err != nil {
// handle error
}
var data SomeType
err = json.Unmarshal(rb, &data)
if err != nil {
// handle error
}Wenn Sie den Antworttext in JSON dekodieren möchten, ist es besser, den JSON-Decoder den Antworttext lesen zu lassen:
resp, err := http.Post("http://localhost:8281/tap", "application/json", bytes.NewReader(body))
if err != nil {
fmt.Printf("%v\n", err)
return
}
defer resp.Body.Close()
var data SomeType
err := json.NewDecoder(resp.Body).Decode(&data)Das obige ist der detaillierte Inhalt vonVerarbeitung von Streaming-HTTP-Antworten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Detaillierte Schritte zum Bereinigen des Speichers in Xiaohongshu
Apr 26, 2024 am 10:43 AM
Detaillierte Schritte zum Bereinigen des Speichers in Xiaohongshu
Apr 26, 2024 am 10:43 AM
1. Öffnen Sie Xiaohongshu, klicken Sie unten rechts auf „Ich“. 2. Klicken Sie auf das Einstellungssymbol und dann auf „Allgemein“. 3. Klicken Sie auf „Cache leeren“.
 Was tun, wenn Ihr Huawei-Telefon nicht über genügend Speicher verfügt (Praktische Methoden zur Lösung des Problems des unzureichenden Speichers)
Apr 29, 2024 pm 06:34 PM
Was tun, wenn Ihr Huawei-Telefon nicht über genügend Speicher verfügt (Praktische Methoden zur Lösung des Problems des unzureichenden Speichers)
Apr 29, 2024 pm 06:34 PM
Unzureichender Speicher auf Huawei-Mobiltelefonen ist mit der Zunahme mobiler Anwendungen und Mediendateien zu einem häufigen Problem geworden, mit dem viele Benutzer konfrontiert sind. Um Benutzern zu helfen, den Speicherplatz ihres Mobiltelefons voll auszunutzen, werden in diesem Artikel einige praktische Methoden vorgestellt, um das Problem des unzureichenden Speichers auf Huawei-Mobiltelefonen zu lösen. 1. Cache bereinigen: Verlaufsdatensätze und ungültige Daten, um Speicherplatz freizugeben und von Anwendungen generierte temporäre Dateien zu löschen. Suchen Sie in den Huawei-Telefoneinstellungen nach „Speicher“, klicken Sie auf die Schaltfläche „Cache löschen“ und löschen Sie dann die Cache-Dateien der Anwendung. 2. Deinstallieren Sie selten verwendete Anwendungen: Um Speicherplatz freizugeben, löschen Sie einige selten verwendete Anwendungen. Ziehen Sie es an den oberen Rand des Telefonbildschirms, drücken Sie lange auf das Symbol „Deinstallieren“ der Anwendung, die Sie löschen möchten, und klicken Sie dann auf die Bestätigungsschaltfläche, um die Deinstallation abzuschließen. 3.Mobile Anwendung auf
 Wie man Deepseek vor Ort fein abgestimmt
Feb 19, 2025 pm 05:21 PM
Wie man Deepseek vor Ort fein abgestimmt
Feb 19, 2025 pm 05:21 PM
Die lokale Feinabstimmung von Deepseek-Klasse-Modellen steht vor der Herausforderung unzureichender Rechenressourcen und Fachkenntnisse. Um diese Herausforderungen zu bewältigen, können die folgenden Strategien angewendet werden: Modellquantisierung: Umwandlung von Modellparametern in Ganzzahlen mit niedriger Präzision und Reduzierung des Speicherboots. Verwenden Sie kleinere Modelle: Wählen Sie ein vorgezogenes Modell mit kleineren Parametern für eine einfachere lokale Feinabstimmung aus. Datenauswahl und Vorverarbeitung: Wählen Sie hochwertige Daten aus und führen Sie eine geeignete Vorverarbeitung durch, um eine schlechte Datenqualität zu vermeiden, die die Modelleffizienz beeinflusst. Batch -Training: Laden Sie für große Datensätze Daten in Stapel für das Training, um den Speicherüberlauf zu vermeiden. Beschleunigung mit GPU: Verwenden Sie unabhängige Grafikkarten, um den Schulungsprozess zu beschleunigen und die Trainingszeit zu verkürzen.
 nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
Vorab geschrieben und Ausgangspunkt Das End-to-End-Paradigma verwendet ein einheitliches Framework, um Multitasking in autonomen Fahrsystemen zu erreichen. Trotz der Einfachheit und Klarheit dieses Paradigmas bleibt die Leistung von End-to-End-Methoden für das autonome Fahren bei Teilaufgaben immer noch weit hinter Methoden für einzelne Aufgaben zurück. Gleichzeitig erschweren die in früheren End-to-End-Methoden weit verbreiteten Funktionen der dichten Vogelperspektive (BEV) die Skalierung auf mehr Modalitäten oder Aufgaben. Hier wird ein Sparse-Search-zentriertes End-to-End-Paradigma für autonomes Fahren (SparseAD) vorgeschlagen, bei dem die Sparse-Suche das gesamte Fahrszenario, einschließlich Raum, Zeit und Aufgaben, ohne dichte BEV-Darstellung vollständig abbildet. Insbesondere ist eine einheitliche, spärliche Architektur für die Aufgabenerkennung einschließlich Erkennung, Verfolgung und Online-Zuordnung konzipiert. Zudem schwer
 Was tun, wenn der Edge-Browser zu viel Speicher beansprucht? Was tun, wenn der Edge-Browser zu viel Speicher beansprucht?
May 09, 2024 am 11:10 AM
Was tun, wenn der Edge-Browser zu viel Speicher beansprucht? Was tun, wenn der Edge-Browser zu viel Speicher beansprucht?
May 09, 2024 am 11:10 AM
1. Rufen Sie zunächst den Edge-Browser auf und klicken Sie auf die drei Punkte in der oberen rechten Ecke. 2. Wählen Sie dann in der Taskleiste [Erweiterungen] aus. 3. Schließen oder deinstallieren Sie als Nächstes die Plug-Ins, die Sie nicht benötigen.
 Für nur 250 US-Dollar zeigt Ihnen der technische Leiter von Hugging Face Schritt für Schritt, wie Sie Llama 3 verfeinern
May 06, 2024 pm 03:52 PM
Für nur 250 US-Dollar zeigt Ihnen der technische Leiter von Hugging Face Schritt für Schritt, wie Sie Llama 3 verfeinern
May 06, 2024 pm 03:52 PM
Die bekannten großen Open-Source-Sprachmodelle wie Llama3 von Meta, Mistral- und Mixtral-Modelle von MistralAI und Jamba von AI21 Lab sind zu Konkurrenten von OpenAI geworden. In den meisten Fällen müssen Benutzer diese Open-Source-Modelle anhand ihrer eigenen Daten verfeinern, um das Potenzial des Modells voll auszuschöpfen. Es ist nicht schwer, ein großes Sprachmodell (wie Mistral) im Vergleich zu einem kleinen mithilfe von Q-Learning auf einer einzelnen GPU zu optimieren, aber die effiziente Feinabstimmung eines großen Modells wie Llama370b oder Mixtral blieb bisher eine Herausforderung . Deshalb Philipp Sch, technischer Leiter von HuggingFace
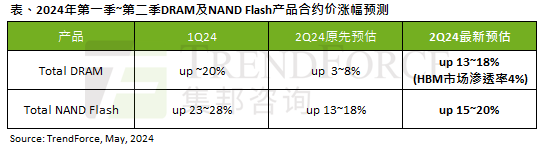 Die Auswirkungen der KI-Welle sind offensichtlich. TrendForce hat seine Prognose für Preiserhöhungen bei DRAM-Speicher und NAND-Flash-Speicher in diesem Quartal nach oben korrigiert.
May 07, 2024 pm 09:58 PM
Die Auswirkungen der KI-Welle sind offensichtlich. TrendForce hat seine Prognose für Preiserhöhungen bei DRAM-Speicher und NAND-Flash-Speicher in diesem Quartal nach oben korrigiert.
May 07, 2024 pm 09:58 PM
Laut einem TrendForce-Umfragebericht hat die KI-Welle erhebliche Auswirkungen auf die Märkte für DRAM-Speicher und NAND-Flash-Speicher. In den Nachrichten dieser Website vom 7. Mai sagte TrendForce heute in seinem neuesten Forschungsbericht, dass die Agentur die Vertragspreiserhöhungen für zwei Arten von Speicherprodukten in diesem Quartal erhöht habe. Konkret schätzte TrendForce ursprünglich, dass der DRAM-Speichervertragspreis im zweiten Quartal 2024 um 3 bis 8 % steigen wird, und schätzt ihn nun auf 13 bis 18 %, bezogen auf NAND-Flash-Speicher, die ursprüngliche Schätzung wird um 13 bis 18 % steigen 18 %, und die neue Schätzung liegt bei 15 %, nur eMMC/UFS weist einen geringeren Anstieg von 10 % auf. ▲Bildquelle TrendForce TrendForce gab an, dass die Agentur ursprünglich damit gerechnet hatte, dies auch weiterhin zu tun
 Benötigt Win11 weniger Speicher als Win10?
Apr 18, 2024 am 12:57 AM
Benötigt Win11 weniger Speicher als Win10?
Apr 18, 2024 am 12:57 AM
Ja, insgesamt benötigt Win11 weniger Speicher als Win10. Zu den Optimierungen gehören ein leichterer Systemkernel, eine bessere Speicherverwaltung, neue Optionen für den Ruhezustand und weniger Hintergrundprozesse. Tests zeigen, dass der Speicherbedarf von Win11 in ähnlichen Konfigurationen typischerweise 5–10 % geringer ist als der von Win10. Die Speichernutzung wird aber auch von der Hardwarekonfiguration, den Anwendungen und den Systemeinstellungen beeinflusst.
