

In Linux-Systemen ist die Speicherverwaltung einer der wichtigsten Teile des Betriebssystems. Es ist dafür verantwortlich, mehreren Prozessen begrenzten physischen Speicher zuzuweisen und eine Abstraktion des virtuellen Speichers bereitzustellen, sodass jeder Prozess über seinen eigenen Adressraum verfügt und Speicher schützen und gemeinsam nutzen kann. In diesem Artikel werden die Prinzipien und Methoden der Linux-Speicherverwaltung vorgestellt, einschließlich Konzepte wie virtueller Speicher, physischer Speicher, logischer Speicher und linearer Speicher sowie das Grundmodell, Systemaufrufe und Implementierungsmethoden der Linux-Speicherverwaltung.
Dieser Artikel basiert auf 32-Bit-Maschinen und behandelt einige Wissenspunkte zur Speicherverwaltung.
Virtuelle Adresse wird auch lineare Adresse genannt. Linux verwendet keinen Segmentierungsmechanismus, daher sind logische Adresse und virtuelle Adresse (lineare Adresse) (Im Benutzermodus bezieht sich die logische Adresse im Kernelmodus speziell auf die Adresse vor dem unten erwähnten linearen Offset) auf dasselbe Konzept. Die Angabe der physischen Adresse ist nicht erforderlich. Die meisten virtuellen Adressen und physikalischen Adressen des Kernels unterscheiden sich nur durch einen linearen Versatz. Die virtuellen Adressen und physischen Adressen im Benutzerbereich werden mithilfe von mehrstufigen Seitentabellen abgebildet, sie werden jedoch weiterhin als lineare Adressen bezeichnet.
In der x86-Struktur ist der virtuelle Adressraum des Linux-Kernels in 0 bis 3 GB als Benutzerbereich und 3 bis 4 GB als Kernelbereich unterteilt (beachten Sie, dass die lineare Adresse, die der Kernel verwenden kann, nur 1 GB beträgt). Der virtuelle Kernelraum (3G~4G) ist in drei Arten von Bereichen unterteilt:
ZONE_DMA beginnt bei 16 MB nach 3G
ZONE_NORMAL 16 MB ~ 896 MB
ZONE_HIGHMEM 896 MB ~1G
Da sich die virtuellen und physikalischen Adressen des Kernels nur um einen Offset unterscheiden: physikalische Adresse = logische Adresse – 0xC0000000. Wenn daher der 1G-Kernelraum vollständig für die lineare Zuordnung genutzt wird, kann der physische Speicher offensichtlich nur auf den 1G-Bereich zugreifen, was offensichtlich unvernünftig ist. HIGHMEM soll dieses Problem lösen. Es hat speziell einen Bereich geöffnet, der keine lineare Zuordnung erfordert und flexibel angepasst werden kann, um auf einen Bereich des physischen Speichers über 1G zuzugreifen. Ich habe mir ein Bild aus dem Internet geholt,
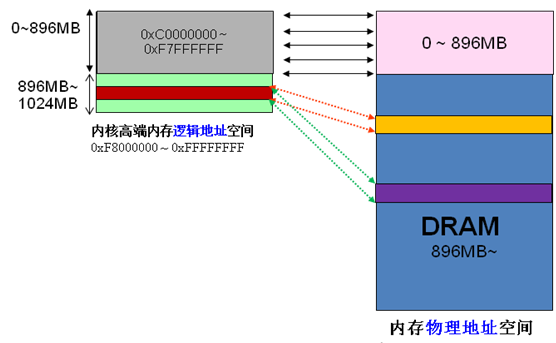 Der Kernel bildet den Speicherplatz PAGE_OFFSET~VMALLOC_START direkt ab, kmalloc und __get_free_page() weisen hier die Seiten zu. Beide verwenden den Slab-Allokator, um physische Seiten direkt zuzuweisen und sie dann in logische Adressen umzuwandeln (physische Adressen sind fortlaufend). Geeignet für die Zuweisung kleiner Speichersegmente. Dieser Bereich enthält Ressourcen wie das Kernel-Image und die physische Seitenrahmentabelle mem_map.
Der Kernel bildet den Speicherplatz PAGE_OFFSET~VMALLOC_START direkt ab, kmalloc und __get_free_page() weisen hier die Seiten zu. Beide verwenden den Slab-Allokator, um physische Seiten direkt zuzuweisen und sie dann in logische Adressen umzuwandeln (physische Adressen sind fortlaufend). Geeignet für die Zuweisung kleiner Speichersegmente. Dieser Bereich enthält Ressourcen wie das Kernel-Image und die physische Seitenrahmentabelle mem_map. 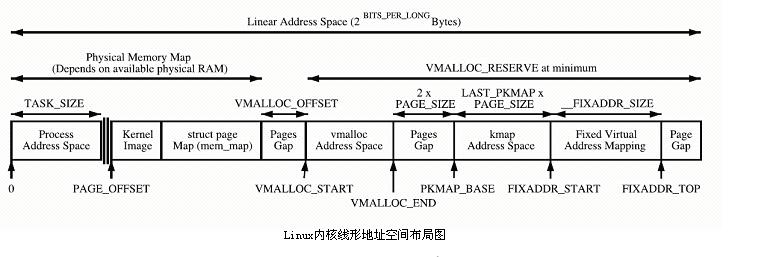
Der von vmalloc verwendete dynamische Kernel-Zuordnungsraum VMALLOC_START~VMALLOC_END verfügt über einen großen darstellbaren Raum.
Permanenter Kernel-Zuordnungsbereich PKMAP_BASE ~ FIXADDR_START, kmap
Temporärer Kernel-Zuordnungsbereich FIXADDR_START~FIXADDR_TOP, kmap_atomic
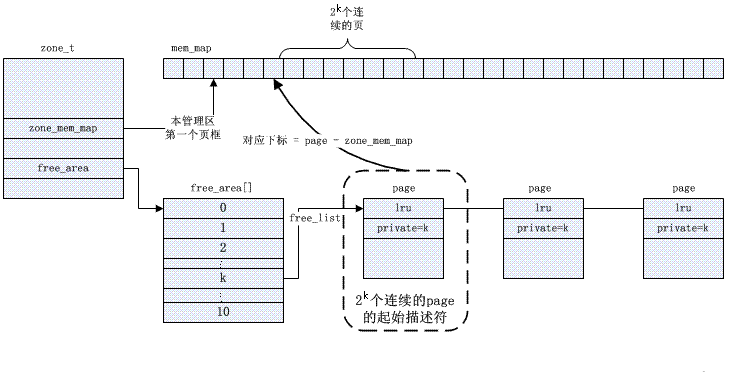
Buddy-Algorithmus-Beispielbeschreibung:
Angenommen, unser Systemspeicher verfügt nur über ***16****** Seiten*****
RAM*. Da der RAM nur 16 Seiten hat, müssen wir nur vier Ebenen (Reihenfolgen) von Partner-Bitmaps verwenden (weil die maximale zusammenhängende Speichergröße ******16****** Seiten*** beträgt), As unten dargestellt.
 order(0) Bimap hat 8 Bits (*** Seiten können bis zu ******16****** Seiten haben, also ******16/2***)
order(0) Bimap hat 8 Bits (*** Seiten können bis zu ******16****** Seiten haben, also ******16/2***)
order(1) Bimap hat 4 Bits (***order******(******0******)******bimap****** Es gibt ******8***************Bit******Ziffern***, also 8/2);
Das heißt, der erste Auftragsblock (1) besteht aus *** zwei Seitenrahmen ****Seite1* *** und ******Seite2***** und besteht aus * Reihenfolge (1) Block 2 besteht aus zwei Seitenrahmen ****Seite3* *** und ******Seite4******, zwischen diesen beiden steht ein **** blockiert **bit****bit*
order(2) Bimap hat 2 Bits (***order******(******1******)******bimap****** Es gibt ******4***************Bit******Ziffern***, also 4/2)
order(3) Bimap hat 1 Bit (***order******(******2******)******bimap****** Es gibt ******4***************Bit******Ziffern***, also 2/2)
In order(0) repräsentiert das erste Bit die ersten ****2****** Seiten*** und das zweite Bit repräsentiert die nächsten 2 Seiten. Da Seite 4 zugewiesen wurde und Seite 5 frei ist, ist das dritte Bit 1.
Ähnlich in Reihenfolge (1) liegt der Grund dafür, dass Bit3 1 ist, darin, dass ein Partner völlig frei ist (Seiten 8 und 9), der entsprechende Partner (Seiten 10 und 11) jedoch nicht. Wenn die Seiten also in Zukunft recycelt werden, sie können zusammengeführt werden.
Zuteilungsprozess
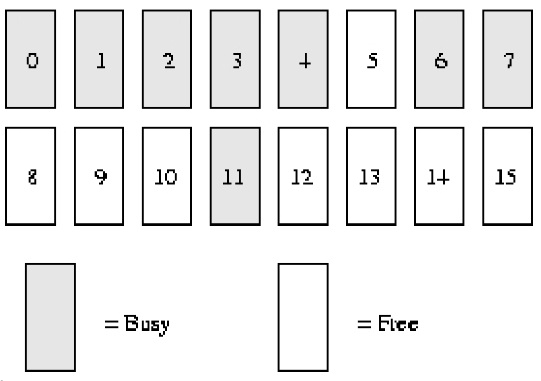
***Wenn wir den kostenlosen Seitenblock ******order****** (******1******), *** benötigen, führen Sie die folgenden Schritte aus:
1. Die erste kostenlose verlinkte Liste ist:
Reihenfolge(0): 5, 10
Reihenfolge(1): 8 [8,9]
Reihenfolge(2): 12 [12,13,14,15]
Bestellung(3):
2. Aus der kostenlosen verknüpften Liste oben können wir ersehen, dass es in der verknüpften Liste „Bestellung“ (1) einen kostenlosen Seitenblock gibt. Ordnen Sie ihn dem Benutzer zu und löschen Sie ihn aus der verknüpften Liste. *
3. Wenn wir einen weiteren Order(1)-Block benötigen, beginnen wir ebenfalls mit dem Scannen aus der Order(1)-Freiliste.4. Wenn bei ***Bestellung****** (******1******) kein freier Seitenblock*** vorhanden ist, gehen wir zu einer höheren Ebene (Bestellung). ) Oben finden, bestellen(2).
5. Zu diesem Zeitpunkt (es gibt keinen kostenlosen Seitenblock auf ***Bestellung****** (******1*****
)*) gibt es einen kostenlosen Seitenblock, der Ist der Slave Seite 12 beginnt. Der Seitenblock ist in zwei etwas kleinere Seitenblöcke der Ordnung (1) aufgeteilt, [12, 13] und [14, 15]. [14, 15] Der Seitenblock wird zur freien Liste order****** (******1*****)* hinzugefügt und gleichzeitig [12 ****** ,******13]****Der Seitenblock wird an den Benutzer zurückgegeben. *
6. Die endgültige kostenlose verlinkte Liste ist:
Reihenfolge(0): 5, 10
Reihenfolge(1): 14 [14,15]
Bestellung(2):
Bestellung(3):
Recyclingprozess
***Wenn wir Seite ******11****** (******Bestellung 0****) recyceln, werden die folgenden Schritte ausgeführt: *
***1******, ****** hat einen Partner gefunden in ******order****** (******0******) Das Bild stellt das Bit ****der Seite ******11****** dar und die Berechnung verwendet die folgenden öffentlichen Informationen: *
*index =* *page_idx >> (Reihenfolge + 1)*
*= 11 >> (0 + 1)*
*= 5*
2. Überprüfen Sie den obigen Schritt, um den Wert des entsprechenden Bits in der Bitmap zu berechnen. Wenn der Bitwert 1 ist, befindet sich in unserer Nähe ein ungenutzter Partner. Der Wert von Bit5 ist 1 (beachten Sie, dass es bei Bit0 beginnt, Bit5 ist das 6. Bit), da seine Partnerseite 10 frei ist.3. Nun setzen wir den Wert dieses Bits auf 0 zurück, da die beiden Partner (Seite 10 und Seite 11) zu diesem Zeitpunkt völlig untätig sind.
4. Wir entfernen Seite 10 aus der kostenlosen Bestellliste (0).
5. Zu diesem Zeitpunkt führen wir weitere Operationen auf den 2 freien Seiten durch (Seiten 10 und 11, Reihenfolge (1)).
6. Die neue freie Seite beginnt auf Seite 10, daher finden wir ihren Index in der Partner-Bitmap von order(1), um zu sehen, ob es einen freien Partner für weitere Zusammenführungsvorgänge gibt. Unter Verwendung der berechneten Firma aus Schritt eins erhalten wir Bit 2 (Ziffer 3).
7. Bit 2 (Order(1)-Bitmap) ist ebenfalls 1, da seine Partnerseitenblöcke (Seiten 8 und 9) frei sind.
8. Setzen Sie den Wert von Bit2 (Bitmap order(1)) zurück und löschen Sie dann den freien Seitenblock in der verknüpften Liste order(1).
9. Jetzt verschmelzen wir zu freien Blöcken mit 4 Seitengrößen (ab Seite 8) und betreten so eine weitere Ebene. Suchen Sie den Bitwert, der der Partner-Bitmap in der Reihenfolge (2) entspricht, also Bit1, und der Wert ist 1. Er muss weiter zusammengeführt werden (der Grund ist der gleiche wie oben).
10. Entfernen Sie den freien Seitenblock (ab Seite 12) aus der verknüpften Liste oder(2) und führen Sie diesen Seitenblock dann weiter mit dem durch die vorherige Zusammenführung erhaltenen Seitenblock zusammen. Jetzt erhalten wir einen Block freier Seiten ab Seite 8 und einer Seitengröße von 8 Seiten.
11. Wir betreten eine weitere Ebene, Bestellung (3). Sein Bitindex ist 0 und sein Wert ist ebenfalls 0. Dies bedeutet, dass die entsprechenden Partner nicht alle frei sind, sodass keine Möglichkeit einer weiteren Fusion besteht. Wir setzen dieses Bit nur auf 1 und fügen dann die zusammengeführten freien Seitenblöcke in die freie verknüpfte Liste order(3) ein.
12. Endlich bekommen wir einen kostenlosen Block mit 8 Seiten,

Buddys Bemühungen, innere Ablagerungen zu vermeiden
Die Fragmentierung des physischen Speichers war schon immer eine der Schwächen des Linux-Betriebssystems. Obwohl viele Lösungen vorgeschlagen wurden, ist keine Methode eine der Lösungen, die dieses Problem vollständig lösen kann. Wir wissen, dass auch Festplattendateien Fragmentierungsprobleme haben, aber die Fragmentierung von Festplattendateien verlangsamt nur die Lese- und Schreibgeschwindigkeit des Systems und verursacht keine Funktionsfehler. Darüber hinaus können wir die Festplatte auch fragmentieren, ohne die Funktion der Festplatte zu beeinträchtigen. ordentlich. Die Fragmentierung des physischen Speichers ist völlig unterschiedlich. Der physische Speicher und das Betriebssystem sind so eng miteinander verbunden, dass es für uns schwierig ist, den physischen Speicher während der Laufzeit zu verschieben (zu diesem Zeitpunkt ist die Fragmentierung der Festplatte viel einfacher; tatsächlich hat Mel Gorman den Speicherkomprimierungs-Patch gesendet wurde, aber noch nicht vom Mainline-Kernel empfangen wurde). Daher konzentriert sich die Lösungsrichtung hauptsächlich auf die Vermeidung von Ablagerungen. Während der Entwicklung des 2.6.24-Kernels wurde dem Hauptkernel eine Kernelfunktionalität zur Verhinderung einer Fragmentierung hinzugefügt. Bevor Sie die Grundprinzipien der Antifragmentierung verstehen, klassifizieren Sie zunächst die Speicherseiten:
1. Nicht verschiebbare Seiten: Der Speicherort muss festgelegt sein und kann nicht an andere Orte verschoben werden. Die meisten vom Kernel zugewiesenen Seiten fallen in diese Kategorie.
2. Zurückgewinnbare Seite: Sie kann nicht direkt verschoben, aber recycelt werden, da die Seite beispielsweise auch aus bestimmten Quellen wiederhergestellt werden kann nach bestimmten Regeln.
3. Bewegliche Seite beweglich: kann nach Belieben verschoben werden. Zu dieser Art von Seite gehören Seiten, die zu Benutzerbereichsanwendungen gehören. Sie werden über die Seitentabelle zugeordnet, daher müssen wir nur die Seitentabelleneinträge aktualisieren und die Daten an den neuen Speicherort kopieren Kann von mehreren Prozessen verwendet werden. Die gemeinsame Nutzung entspricht mehreren Seitentabelleneinträgen.
Die Möglichkeit, Fragmentierung zu verhindern, besteht darin, diese drei Seitentypen in verschiedene verknüpfte Listen aufzunehmen, um zu verhindern, dass verschiedene Seitentypen einander stören. Stellen Sie sich die Situation vor, in der sich eine unbewegliche Seite in der Mitte einer beweglichen Seite befindet. Nachdem wir diese Seiten verschoben oder recycelt haben, verhindert diese unbewegliche Seite, dass wir einen größeren kontinuierlichen physischen freien Speicherplatz erhalten.
Darüber hinaus verfügt Jede Zone über eine eigene deaktivierte Clean-Page-Warteschlange, die zwei zonenübergreifenden globalen Warteschlangen entspricht, der deaktivierten Dirty-Page-Warteschlange und der aktiven Warteschlange. Diese Warteschlangen sind über den LRU-Zeiger der Seitenstruktur verknüpft.
Nachdenken: Was bedeutet die Deaktivierungswarteschlange (siehe
Plattenzuteiler: internes Fragmentierungsproblem lösen
Der Kernel ist häufig auf die Zuweisung kleiner Objekte angewiesen, die während der Systemlebensdauer mehrmals zugewiesen werden. Der Slab-Cache-Allocator bietet diese Funktionalität, indem er Objekte ähnlicher Größe (viel kleiner als 1 Seite) zwischenspeichert und so das häufige interne Fragmentierungsproblem vermeidet. Hier ist vorerst ein Bild. Bezüglich des Prinzips sehen Sie sich bitte die allgemeine Referenz 3 an. Offensichtlich basiert der Slab-Mechanismus auf dem Buddy-Algorithmus, und ersterer ist eine Weiterentwicklung des letzteren.
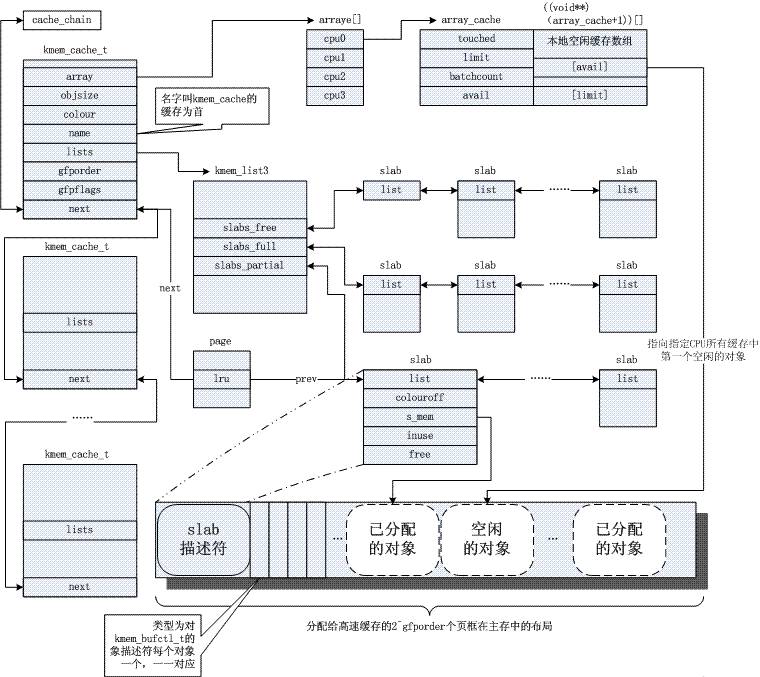
4. Seitenrecycling-/Fokussierungsmechanismus
Verwenden der About-Seite
In einigen früheren Artikeln haben wir erfahren, dass der Linux-Kernel in vielen Situationen Seiten zuweist.
1. Der Kernel-Code kann Funktionen wie alloc_pages aufrufen, um Seiten direkt vom Partnersystem zuzuweisen, das physische Seiten verwaltet (die freie Liste free_area in der Verwaltungszone) (siehe „Eine kurze Analyse der Linux-Kernel-Speicherverwaltung“). Beispielsweise kann der Treiber auf diese Weise Cache zuweisen; beim Erstellen eines Prozesses weist der Kernel auf diese Weise auch zwei aufeinanderfolgende Seiten als Thread_Info-Struktur und Kernel-Stack des Prozesses zu. Die Zuweisung von Seiten vom Partnersystem ist die einfachste Methode zur Seitenzuweisung, und andere Speicherzuweisungen basieren auf dieser Methode
2. Viele Objekte im Kernel werden mithilfe des Slab-Mechanismus verwaltet (siehe „Eine kurze Analyse des Linux Slub Allocator“). Slab entspricht einem Objektpool, der Seiten in „Objekte“ „formatiert“ und sie für den menschlichen Gebrauch im Pool speichert. Wenn nicht genügend Objekte in der Platte vorhanden sind, weist der Plattenmechanismus automatisch Seiten vom Partnersystem zu und „formatiert“ sie in neue Objekte
3. Festplatten-Cache (siehe „Eine kurze Analyse des Lesens und Schreibens von Linux-Kernel-Dateien“). Beim Lesen und Schreiben von Dateien werden Seiten vom Partnersystem zugewiesen und für den Festplatten-Cache verwendet. Anschließend werden die Dateidaten auf der Festplatte in die entsprechende Festplatten-Cache-Seite geladen
4. Speicherzuordnung. Die sogenannte Speicherzuordnung bezieht sich hier tatsächlich auf die Zuordnung von Speicherseiten zum Benutzerbereich zur Verwendung durch Benutzerprozesse. Jede VMA in der Struktur task_struct-> mm des Prozesses stellt eine Zuordnung dar. Die eigentliche Implementierung der Zuordnung besteht darin, dass nach dem Zugriff des Benutzerprogramms auf die entsprechende Speicheradresse die durch die Seitenfehlerausnahme verursachte Seite zugewiesen und die Seitentabelle zugeordnet wird aktualisiert. (Siehe „Eine kurze Analyse der Linux-Kernel-Speicherverwaltung“);
Wenn eine Seitenzuweisung erfolgt, erfolgt ein Seitenrecycling. Seitenrecyclingmethoden können grob in zwei Typen unterteilt werden:
Eine davon ist die aktive Freigabe. So wie das Benutzerprogramm den über die Malloc-Funktion zugewiesenen Speicher über die Free-Funktion freigibt, weiß der Benutzer der Seite genau, wann die Seite verwendet wird und wann sie nicht mehr benötigt wird.
Die ersten beiden oben genannten Zuordnungsmethoden werden im Allgemeinen vom Kernelprogramm aktiv freigegeben. Direkt vom Partnersystem zugewiesene Seiten werden vom Benutzer mithilfe von Funktionen wie „free_pages“ aktiv freigegeben. Nach der Freigabe der Seite werden auch vom Slab zugewiesene Objekte direkt freigegeben Vom Benutzer freigegeben (mithilfe der Funktion kmem_cache_free).
Eine weitere Möglichkeit des Seitenrecyclings ist der vom Linux-Kernel bereitgestellte Page Frame Recycling-Algorithmus (PFRA). Benutzer der Seite behandeln die Seite im Allgemeinen als eine Art Cache, um die Betriebseffizienz des Systems zu verbessern. Es ist gut, dass der Cache immer vorhanden ist. Wenn der Cache jedoch nicht mehr vorhanden ist, verursacht dies keine Fehler, sondern beeinträchtigt lediglich die Effizienz. Der Benutzer der Seite weiß nicht genau, wann diese zwischengespeicherten Seiten am besten aufbewahrt und wann sie am besten recycelt werden, was der PFRA überlassen bleibt.
Die beiden oben genannten Zuweisungsmethoden werden im Allgemeinen von PFRA recycelt (oder synchron von Prozessen wie dem Löschen von Dateien und Prozessexits recycelt).
Für die ersten beiden oben genannten Seitenzuweisungsmethoden (direkte Seitenzuweisung und Objektzuweisung über Slab) kann es auch erforderlich sein, über PFRA zu recyceln.
Benutzer der Seite können eine Callback-Funktion bei PFRA registrieren (mithilfe der Funktion register_shrink). Diese Rückruffunktionen werden dann von PFRA zu geeigneten Zeitpunkten aufgerufen, um die Wiederverwendung der entsprechenden Seiten oder Objekte auszulösen.
Eine der typischeren ist das Recycling von Zahnersatz. Dentry ist ein von Slab zugewiesenes Objekt, das zur Darstellung der Verzeichnisstruktur des virtuellen Dateisystems verwendet wird. Wenn der Referenzzähler des Dentry auf 0 reduziert wird, wird der Dentry nicht direkt freigegeben, sondern zur späteren Verwendung in einer LRU-verknüpften Liste zwischengespeichert. (Siehe „Eine kurze Analyse des virtuellen Dateisystems des Linux-Kernels“.)
Der Eintrag in dieser LRU-verknüpften Liste muss schließlich recycelt werden. Wenn das virtuelle Dateisystem initialisiert wird, wird register_shrinker aufgerufen, um die Recyclingfunktion Shrink_dcache_memory zu registrieren.
Die Superblock-Objekte aller Dateisysteme im System werden in einer verknüpften Liste gespeichert. Die Funktion „shrink_dcache_memory“ durchsucht diese verknüpfte Liste, ruft die LRU des ungenutzten Dentry jedes Superblocks ab und fordert dann einige der ältesten Dentry daraus zurück. Wenn der Dentry freigegeben wird, wird der entsprechende Inode dereferenziert, was ebenfalls dazu führen kann, dass der Inode freigegeben wird.
Nachdem der Inode freigegeben wurde, wird er auch in eine nicht verwendete verknüpfte Liste eingefügt. Während der Initialisierung ruft das virtuelle Dateisystem auch register_shrinker auf, um die Rückruffunktion „shrink_icache_memory“ zu registrieren und diese nicht verwendeten Inodes wiederzuverwenden, sodass auch der mit dem Inode verknüpfte Festplatten-Cache vorhanden ist freigegeben.
Außerdem kann es während der Ausführung des Systems viele inaktive Objekte in der Platte geben (z. B. nachdem die Spitzenauslastung eines bestimmten Objekts vorüber ist). Die Funktion „cache_reap“ in PFRA wird verwendet, um diese redundanten inaktiven Objekte wiederzuverwenden. Wenn einige inaktive Objekte auf einer Seite wiederhergestellt werden können, kann die Seite wieder für das Partnersystem freigegeben werden
Was die Funktion „cache_reap“ bewirkt, ist einfach zu sagen. Alle kmem_cache-Strukturen, die Objektpools im System speichern, sind zu einer verknüpften Liste verbunden. Die Funktion „cache_reap“ durchsucht jeden Objektpool, sucht dann nach Seiten, die recycelt werden können, und recycelt sie. (Der eigentliche Prozess ist natürlich etwas komplizierter.)
Über Speicherzuordnung
Wie bereits erwähnt, werden Festplatten-Cache und Speicherzuordnung im Allgemeinen von PFRA recycelt. Das Recycling der beiden durch PFRA ist sehr ähnlich. Tatsächlich wird der Festplatten-Cache wahrscheinlich dem Benutzerbereich zugeordnet. Hier ist eine kurze Einführung in die Speicherzuordnung:
Dateizuordnung bedeutet, dass die VMA, die diese Zuordnung darstellt, einem bestimmten Bereich in einer Datei entspricht. Diese Zuordnungsmethode wird von Programmen im Benutzermodus relativ selten explizit verwendet. Programme im Benutzermodus sind im Allgemeinen daran gewöhnt, eine Datei zu öffnen und sie dann zu lesen/schreiben.
Tatsächlich kann das Benutzerprogramm auch den mmap-Systemaufruf verwenden, um einen bestimmten Teil einer Datei dem Speicher zuzuordnen (entsprechend einer VMA) und dann die Datei durch Zugriff auf den Speicher zu lesen und zu schreiben. Obwohl Benutzerprogramme diese Methode selten verwenden, sind Benutzerprozesse voll von solchen Zuordnungen: Der vom Prozess ausgeführte ausführbare Code (einschließlich ausführbarer Dateien und lib-Bibliotheksdateien) wird auf diese Weise zugeordnet.
Im Artikel „Eine kurze Analyse des Lesens und Schreibens von Dateien im Linux-Kernel“ haben wir die Implementierung der Dateizuordnung nicht besprochen. Tatsächlich ordnet die Dateizuordnung die Seiten im Festplatten-Cache der Datei direkt dem Benutzerbereich zu (es ist ersichtlich, dass die von der Datei zugeordneten Seiten eine Teilmenge der Festplatten-Cache-Seiten sind), und Benutzer können sie mit 0 lesen und schreiben Kopien. Bei Verwendung von Lese-/Schreibzugriff erfolgt eine Kopie zwischen dem Benutzerspeicher und dem Festplatten-Cache.
Die anonyme Zuordnung ist relativ zur Dateizuordnung, was bedeutet, dass die VMA dieser Zuordnung keiner Datei entspricht. Für die normale Speicherzuweisung im Benutzerbereich (Heap-Speicherplatz, Stapelspeicherplatz) gehören sie alle zur anonymen Zuordnung.
Offensichtlich können mehrere Prozesse über ihre eigenen Dateizuordnungen auf dieselbe Datei abgebildet werden (die meisten Prozesse ordnen beispielsweise die so-Datei der libc-Bibliothek zu). Tatsächlich können mehrere Prozesse über ihre eigenen anonymen Zuordnungen demselben physischen Speicher zugeordnet werden. Diese Situation wird dadurch verursacht, dass der übergeordnete und untergeordnete Prozess nach der Verzweigung den ursprünglichen physischen Speicher gemeinsam nutzt (Kopie beim Schreiben).
Welche Seiten sollten recycelt werden
Beim Recycling können Festplatten-Cache-Seiten (einschließlich dateizugeordneter Seiten) verworfen und recycelt werden. Wenn die Seite jedoch fehlerhaft ist, muss sie vor dem Verwerfen auf die Festplatte zurückgeschrieben werden.
Die anonym zugeordneten Seiten können nicht verworfen werden, da die Seiten Daten enthalten, die vom Benutzerprogramm verwendet werden, und die Daten nach dem Verwerfen nicht wiederhergestellt werden können. Im Gegensatz dazu werden die Daten in den Festplatten-Cache-Seiten selbst auf der Festplatte gespeichert und können reproduziert werden.
Wenn Sie anonym zugeordnete Seiten recyceln möchten, müssen Sie daher zuerst die Daten auf den Seiten auf die Festplatte übertragen. Dies ist ein Seitenaustausch (Swap). Offensichtlich sind die Kosten für den Seitenwechsel relativ höher.
Anonym zugeordnete Seiten können in eine Auslagerungsdatei oder Auslagerungspartition auf der Festplatte ausgelagert werden (eine Partition ist ein Gerät und ein Gerät ist auch eine Datei. Daher wird sie im Folgenden zusammenfassend als Auslagerungsdatei bezeichnet).
Obwohl es viele Seiten gibt, die recycelt werden können, ist es offensichtlich, dass PFRA so wenig wie möglich recyceln/austauschen sollte (da diese Seiten von der Festplatte wiederhergestellt werden müssen, was mit hohen Kosten verbunden ist). Daher fordert PFRA bei Bedarf nur einen Teil der selten genutzten Seiten zurück bzw. tauscht sie aus. Die Anzahl der jedes Mal zurückgewonnenen Seiten ist ein empirischer Wert: 32.
Alle diese Festplatten-Cache-Seiten und anonymen zugeordneten Seiten werden also in einer Reihe von LRUs platziert. (Tatsächlich verfügt jede Zone über einen Satz solcher LRUs, und Seiten werden in den LRUs ihrer entsprechenden Zonen platziert.)
Eine Gruppe von LRUs besteht aus mehreren Paaren verknüpfter Listen, einschließlich verknüpfter Listen von Festplatten-Cache-Seiten (einschließlich Dateizuordnungsseiten), verknüpfter Listen anonymer Zuordnungsseiten usw. Ein Paar verknüpfter Listen besteht eigentlich aus zwei verknüpften Listen: einer aktiven und einer inaktiven. Erstere ist die zuletzt verwendete Seite und letztere ist die kürzlich nicht verwendete Seite.
Beim Recycling von Seiten muss PFRA zum einen die am längsten verwendete Seite in der aktiven verknüpften Liste verschieben und zum anderen versuchen, die am längsten nicht verwendete Seite in der inaktiven verknüpften Liste zu recyceln.
Bestimmen Sie die zuletzt verwendete Version
Nun stellt sich die Frage: Wie kann festgestellt werden, welche Seiten in der Aktiv-/Inaktiv-Liste am längsten nicht verwendet wurden?
Ein Ansatz besteht darin, eine Seite zu sortieren und sie beim Zugriff an das Ende der verknüpften Liste zu verschieben (vorausgesetzt, das Recycling beginnt am Kopf). Dies bedeutet jedoch, dass die Position der Seite in der verknüpften Liste häufig verschoben werden kann und vor dem Verschieben gesperrt werden muss (möglicherweise greifen mehrere CPUs gleichzeitig darauf zu), was einen großen Einfluss auf die Effizienz hat.
Der Linux-Kernel übernimmt die Methode des Markierens und Ordnens. Wenn eine Seite zwischen der aktiven und der inaktiven verknüpften Liste wechselt, wird sie immer am Ende der verknüpften Liste platziert (wie oben, vorausgesetzt, das Recycling beginnt am Kopf).
Wenn Seiten nicht zwischen verknüpften Listen verschoben werden, wird ihre Reihenfolge nicht angepasst. Stattdessen wird das Zugriffstag verwendet, um anzuzeigen, ob die Seite gerade aufgerufen wurde. Wenn erneut auf eine Seite zugegriffen wird, für die in der inaktiven verknüpften Liste ein Zugriffs-Tag festgelegt ist, wird sie in die aktive verknüpfte Liste verschoben und das Zugriffs-Tag wird gelöscht. (Um Zugriffskonflikte zu vermeiden, wird die Seite tatsächlich nicht direkt von der inaktiven verknüpften Liste zur aktiven verknüpften Liste verschoben, sondern es gibt eine Pagevec-Zwischenstruktur, die als Puffer verwendet wird, um ein Sperren der verknüpften Liste zu vermeiden.)
Es gibt zwei Arten von Zugriffs-Tags auf der Seite. Das eine ist das PG_referenced-Tag, das in page->flags platziert wird. Dieses Tag wird gesetzt, wenn auf die Seite zugegriffen wird. Auf Seiten im Festplatten-Cache (nicht zugeordnet) greift der Benutzerprozess über Systemaufrufe wie Lesen und Schreiben zu. Der Systemaufrufcode setzt das PG_referenced-Flag der entsprechenden Seite.
Auf speicherzugeordnete Seiten können Benutzerprozesse direkt darauf zugreifen (ohne den Kernel zu durchlaufen), sodass das Zugriffsflag in diesem Fall nicht vom Kernel, sondern von mmu gesetzt wird. Nach der Zuordnung der virtuellen Adresse zu einer physischen Adresse setzt mmu ein Zugriffsflag für den entsprechenden Seitentabelleneintrag, um anzuzeigen, dass auf die Seite zugegriffen wurde. (Auf die gleiche Weise platziert mmu ein Dirty-Flag auf dem Seitentabelleneintrag, der der Seite entspricht, die geschrieben wird, was anzeigt, dass es sich bei der Seite um eine Dirty-Seite handelt.)
Das Zugriffs-Tag der Seite (einschließlich der beiden oben genannten Tags) wird während des Seitenrecyclingvorgangs durch PFRA gelöscht, da das Zugriffs-Tag offensichtlich eine Gültigkeitsdauer haben sollte und der laufende Zyklus von PFRA diese Gültigkeitsdauer darstellt. Die PG_referenced-Markierung in page->flags kann direkt gelöscht werden, während das Zugriffsbit im Seitentabelleneintrag nur gelöscht werden kann, nachdem der entsprechende Seitentabelleneintrag über die Seite gefunden wurde (siehe „Reverse Mapping“ unten).
Wie scannt der Recyclingprozess also die verknüpfte LRU-Liste?
Da es mehrere Gruppen von LRUs gibt (es gibt mehrere Zonen im System und jede Zone hat mehrere Gruppen von LRUs), erhöht sich die Effizienz des Recyclings, wenn PFRA alle LRUs für jedes Recycling durchsucht, um die Seiten zu finden, die es am meisten wert sind, recycelt zu werden Der Algorithmus wird offensichtlich nicht ideal sein.
Die von der Linux-Kernel-PFRA verwendete Scanmethode besteht darin, eine Scanpriorität zu definieren und anhand dieser Priorität die Anzahl der Seiten zu berechnen, die auf jeder LRU gescannt werden sollen. Der gesamte Recycling-Algorithmus beginnt mit der niedrigsten Priorität, scannt die zuletzt verwendeten Seiten in jeder LRU und versucht dann, sie zurückzugewinnen. Wenn nach einem Scan eine ausreichende Anzahl von Seiten recycelt wurde, endet der Recyclingprozess. Andernfalls erhöhen Sie die Priorität und scannen Sie erneut, bis eine ausreichende Anzahl von Seiten wiederhergestellt wurde. Und wenn nicht genügend Seiten recycelt werden können, wird die Priorität auf das Maximum erhöht, d. h. alle Seiten werden gescannt. Zu diesem Zeitpunkt wird der Recyclingprozess beendet, auch wenn die Anzahl der recycelten Seiten noch nicht ausreicht.
Jedes Mal, wenn eine LRU gescannt wird, wird die Anzahl der Seiten, die der aktuellen Priorität entsprechen, aus der aktiven verknüpften Liste und der inaktiven verknüpften Liste abgerufen. Anschließend werden diese Seiten verarbeitet: Wenn die Seite nicht recycelt werden kann (z. B. beibehalten oder gesperrt). ), wird es entsprechend dem Kopf der verknüpften Liste zurückgesetzt (wie oben, vorausgesetzt, das Recycling beginnt am Kopf); andernfalls wird das Flag gelöscht und die Seite an das Ende zurückgesetzt, wenn das Zugriffsflag der Seite gesetzt ist die entsprechende verknüpfte Liste (wie oben, vorausgesetzt, das Recycling beginnt am Kopf); andernfalls wird die Seite von der aktiven verknüpften Liste in die inaktive verknüpfte Liste verschoben oder von der inaktiven verknüpften Liste recycelt.
Die gescannten Seiten werden basierend darauf bestimmt, ob das Zugriffsflag gesetzt ist oder nicht. Wie wird dieses Zugriffstag festgelegt? Es gibt zwei Möglichkeiten: Wenn der Benutzer über Systemaufrufe wie Lesen/Schreiben auf die Datei zugreift, bearbeitet der Kernel die Seiten im Festplatten-Cache und setzt die Zugriffsflags dieser Seiten (in der Seitenstruktur festgelegt). ist, dass der Prozess direkt auf die Datei zugreift. Wenn die Seite zugeordnet ist, fügt mmu automatisch ein Zugriffstag (im PTE der Seitentabelle festgelegt) zum entsprechenden Seitentabelleneintrag hinzu. Die Beurteilung des Access-Tags basiert auf diesen beiden Informationen. (Auf eine Seite verweisen möglicherweise mehrere PTEs. Woher wissen Sie, ob für diese PTEs Zugriffstags festgelegt sind? Dann müssen Sie diese PTEs durch umgekehrte Zuordnung finden. Wir werden weiter unten darüber sprechen.)
PFRA neigt nicht dazu, anonym zugeordnete Seiten aus der aktiven verknüpften Liste zu recyceln, da der von Benutzerprozessen verwendete Speicher im Allgemeinen relativ klein ist und die Wiederverwendung einen Austausch erfordert, was kostspielig ist. Daher werden die Seiten in der aktiven verknüpften Liste, die der anonymen Zuordnung entsprechen, nicht recycelt, wenn viel verbleibender Speicher und ein kleiner Anteil an anonymer Zuordnung vorhanden sind. (Und wenn die Seite in die inaktive Liste aufgenommen wurde, müssen Sie sich darüber keine Sorgen mehr machen.)
Reverse-Mapping
So kann es sein, dass während des von PFRA durchgeführten Seitenrecyclingvorgangs einige Seiten in der inaktiven Liste der LRU kurz davor stehen, recycelt zu werden.
Wenn die Seite nicht zugeordnet ist, kann sie direkt zum Partnersystem recycelt werden (schreiben Sie schmutzige Seiten zuerst zurück und recyceln Sie sie dann). Ansonsten gibt es immer noch eine problematische Sache, mit der man sich befassen muss. Da ein bestimmter Seitentabelleneintrag des Benutzerprozesses auf diese Seite verweist, muss vor dem Recycling der Seite dem Seitentabelleneintrag, der darauf verweist, eine Erklärung gegeben werden.
Es stellt sich also die Frage: Woher weiß der Kernel, auf welche Seitentabelleneinträge diese Seite verweist? Zu diesem Zweck erstellt der Kernel eine umgekehrte Zuordnung von Seiten zu Seitentabelleneinträgen.
Die einer zugeordneten Seite entsprechende VMA kann durch umgekehrte Zuordnung gefunden werden, und die entsprechende Seitentabelle kann über vma->vm_mm->pgd gefunden werden. Rufen Sie dann die virtuelle Adresse der Seite über page->index ab. Suchen Sie dann den entsprechenden Seitentabelleneintrag aus der Seitentabelle über die virtuelle Adresse. (Der Zugriff auf das Tag im zuvor erwähnten Seitentabelleneintrag wird durch umgekehrte Zuordnung erreicht.)
Wenn in der Seitenstruktur, die der Seite entspricht, das unterste Bit von page->mapping festgelegt ist, handelt es sich um eine anonyme Zuordnungsseite, und page->mapping verweist auf eine anon_vma-Struktur. Andernfalls handelt es sich um eine Dateizuordnungsseite page->mapping ist die Adressraumstruktur, die der Datei entspricht. (Wenn die anon_vma-Struktur und die address_space-Struktur zugewiesen werden, müssen die Adressen natürlich ausgerichtet sein, mindestens das niedrigste Bit muss 0 sein.)
Für anonym zugeordnete Seiten dient die anon_vma-Struktur als Header einer verknüpften Liste und verbindet alle VMAS, die diese Seite über den verknüpften Listenzeiger vma->anon_vma_node abbilden. Immer wenn eine Seite (anonym) einem Benutzerbereich zugeordnet wird, wird die entsprechende VMA zu dieser verknüpften Liste hinzugefügt.
Für dateizugeordnete Seiten verwaltet die Struktur „adress_space“ nicht nur einen Basisbaum zum Speichern von Festplatten-Cache-Seiten, sondern auch einen Prioritätssuchbaum für alle der Datei zugeordneten VMAS. Da diese von Dateien zugeordneten VMAs nicht unbedingt die gesamte Datei abbilden, ist es möglich, dass nur ein Teil der Datei abgebildet wird. Daher muss dieser Prioritätssuchbaum zusätzlich zur Indizierung aller zugeordneten VMAS auch wissen, welche Bereiche der Datei welchen VMAS zugeordnet sind. Immer wenn eine Seite (Datei) einem Benutzerbereich zugeordnet wird, wird die entsprechende VMA diesem Prioritätssuchbaum hinzugefügt. Daher kann bei einer gegebenen Seite im Festplatten-Cache die Position der Seite in der Datei über page->index ermittelt werden, und alle dieser Seite zugeordneten VMAS können über den Prioritätssuchbaum gefunden werden.
In den beiden oben genannten Schritten führt der magische Seiten->Index zwei Dinge aus: Er ruft die virtuelle Adresse der Seite ab und ruft den Speicherort der Seite im Datei-Festplatten-Cache ab.
vma->vm_start zeichnet die erste virtuelle Adresse der vma auf, vma->vm_pgoff zeichnet den Offset der vma in der entsprechenden Zuordnungsdatei (oder im gemeinsam genutzten Speicher) auf und page->index zeichnet die Seite in der Datei (oder im gemeinsam genutzten Speicher) auf. versetzt in .
Der Offset der Seite in vma kann über vma->vm_pgoff und page->index erhalten werden, und die virtuelle Adresse der Seite kann durch Hinzufügen von vma->vm_start und die Seite im Dateifestplatten-Cache erhalten werden Seite->Indexposition.
Seitenwechsel ein- und ausblenden
Nachdem der Seitentabelleneintrag gefunden wurde, der auf die Seite verweist, die recycelt werden soll, kann der Seitentabelleneintrag, der auf die Seite verweist, für die Dateizuordnung direkt gelöscht werden. Wenn der Benutzer erneut auf diese Adresse zugreift, wird eine Seitenfehlerausnahme ausgelöst. Der Ausnahmebehandlungscode weist dann eine Seite neu zu und liest die entsprechenden Daten von der Festplatte (möglicherweise befindet sich die Seite bereits im entsprechenden Festplattencache. Weil andere Prozesse darauf zugegriffen haben Erste). Dies entspricht dem ersten Zugriff auf die Seite nach der Zuordnung;
Für die anonyme Zuordnung wird die Seite zunächst in die Auslagerungsdatei zurückgeschrieben und anschließend muss der Index der Seite in der Auslagerungsdatei im Seitentabelleneintrag aufgezeichnet werden.
Im Seitentabelleneintrag ist ein „Present“-Bit vorhanden. Wenn dieses Bit gelöscht wird, betrachtet die MMU den Seitentabelleneintrag als ungültig. Wenn der Seitentabelleneintrag ungültig ist, werden andere Bits von mmu nicht berücksichtigt und können zum Speichern anderer Informationen verwendet werden. Sie werden hier verwendet, um den Index der Seite in der Auslagerungsdatei zu speichern (eigentlich die Nummer der Auslagerungsdatei + die Indexnummer in der Auslagerungsdatei).
Der Prozess des Austauschens anonym zugeordneter Seiten in die Auslagerungsdatei (der Auslagerungsprozess) ist dem Prozess des Zurückschreibens schmutziger Seiten im Festplatten-Cache in die Datei sehr ähnlich.
Die Auslagerungsdatei verfügt auch über die entsprechende Adressraumstruktur. Beim Auslagern werden anonym zugeordnete Seiten zunächst im Festplattencache abgelegt, der diesem Adressraum entspricht, und dann in die Auslagerungsdatei zurückgeschrieben, genau wie schmutzige Seiten. Nachdem das Zurückschreiben abgeschlossen ist, wird die Seite freigegeben (denken Sie daran, dass unser Zweck darin besteht, die Seite freizugeben).
Warum also nicht einfach die Seite zurück in die Auslagerungsdatei schreiben, anstatt den Festplatten-Cache zu durchsuchen? Da diese Seite möglicherweise mehrmals zugeordnet wurde, ist es nicht möglich, die entsprechenden Seitentabelleneinträge in den Seitentabellen aller Benutzerprozesse gleichzeitig zu ändern (sie in den Index der Seite in der Auslagerungsdatei zu ändern), also während des Prozesses von Wenn die Seite freigegeben wird, wird die Seite vorübergehend im Festplatten-Cache abgelegt.
Nicht alle Prozesse zur Änderung von Seitentabelleneinträgen sind erfolgreich (z. B. wurde vor der Änderung erneut auf die Seite zugegriffen, sodass die Seite jetzt nicht erneut recycelt werden muss). Daher kann es auch länger dauern, bis die Seite im Festplattencache abgelegt wird sehr lang sein.
In ähnlicher Weise ist auch der Prozess des Lesens anonym zugeordneter Seiten aus der Auslagerungsdatei (der Swap-In-Prozess) dem Prozess des Lesens von Dateidaten sehr ähnlich.
Gehen Sie zuerst zum entsprechenden Festplatten-Cache, um zu sehen, ob die Seite dort ist. Wenn nicht, lesen Sie sie in der Auslagerungsdatei. Die Daten in der Datei werden auch in den Festplatten-Cache gelesen, und dann wird der entsprechende Seitentabelleneintrag in der Seitentabelle des Benutzerprozesses neu geschrieben, um direkt auf diese Seite zu verweisen.
Diese Seite wird möglicherweise nicht sofort aus dem Festplattencache abgerufen, da andere Benutzerprozesse, die dieser Seite ebenfalls zugeordnet sind (ihre entsprechenden Seitentabelleneinträge wurden so geändert, dass sie in die Auslagerungsdatei indiziert werden), auch hier darauf verweisen können. . Die Seite kann erst dann aus dem Festplattencache abgerufen werden, wenn keine anderen Seitentabelleneinträge auf den Auslagerungsdateiindex verweisen.
Der letzte sichere Kill
Wie bereits erwähnt, hat PFRA möglicherweise alle LRUs gescannt und konnte die erforderlichen Seiten immer noch nicht zurückfordern. Ebenso dürfen Seiten nicht in Slab, Dentry-Cache, Inode-Cache usw. recycelt werden.
Was ist zu diesem Zeitpunkt, wenn ein bestimmter Teil des Kernelcodes eine Seite abrufen muss (ohne Seite kann das System abstürzen)? PFRA hatte keine andere Wahl, als auf den letzten Ausweg zurückzugreifen – OOM (out of Memory). Beim sogenannten OOM geht es darum, den unwichtigsten Prozess zu finden und ihn dann zu beenden. Entlasten Sie den Systemdruck, indem Sie die von diesem Prozess belegten Speicherseiten freigeben.
5. Speicherverwaltungsarchitektur
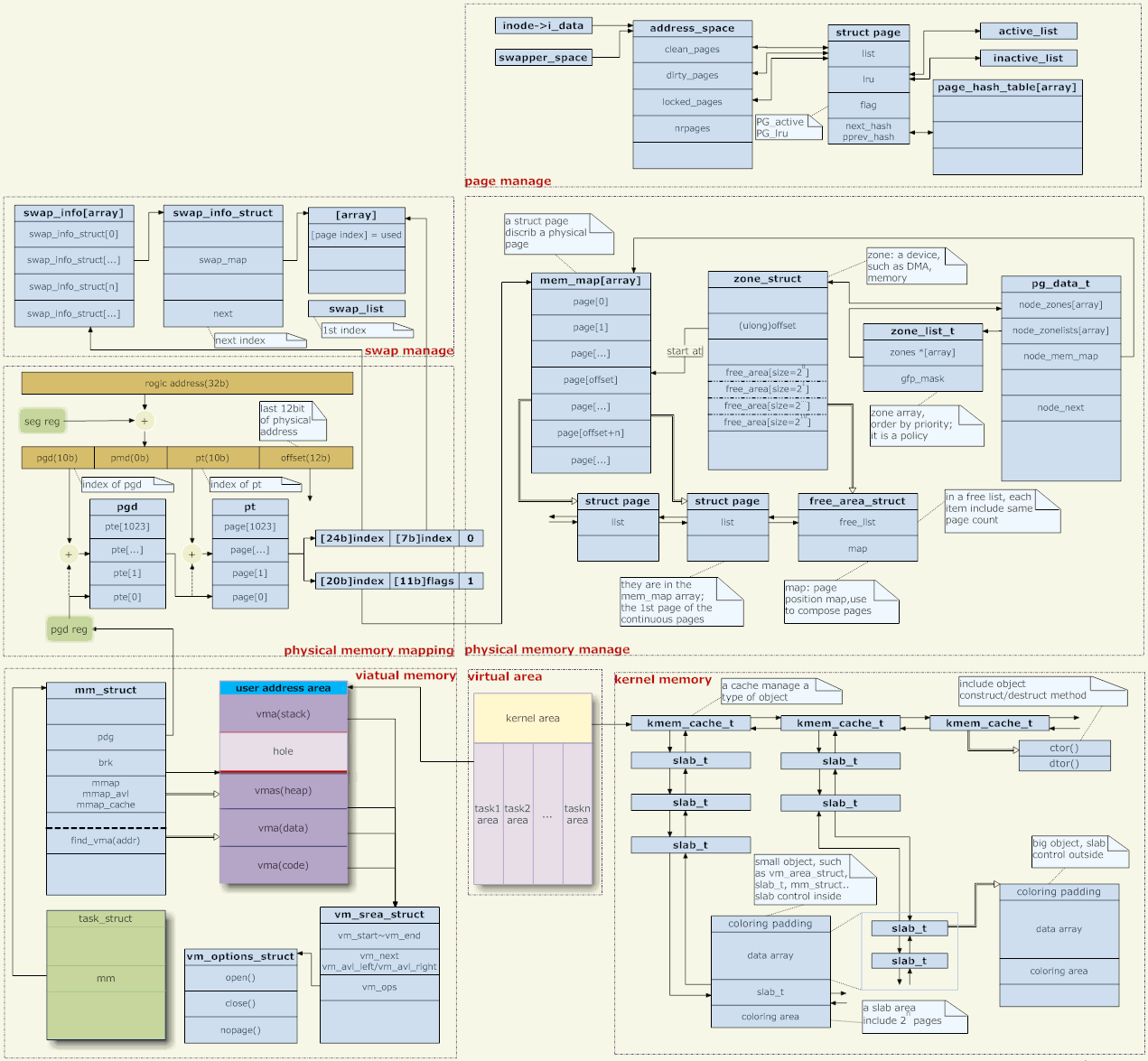
Ein paar Worte zum Bild oben,
Adresszuordnung
Der Linux-Kernel verwendet die Seitenspeicherverwaltung. Die von der Anwendung angegebene Speicheradresse ist eine virtuelle Adresse, die Ebene für Ebene durch mehrere Ebenen von Seitentabellen transformiert werden muss, bevor sie zu einer echten physischen Adresse wird.
Denken Sie darüber nach, die Adresszuordnung ist immer noch eine beängstigende Sache. Beim Zugriff auf einen durch eine virtuelle Adresse repräsentierten Speicherplatz sind mehrere Speicherzugriffe erforderlich, um die für die Konvertierung verwendeten Seitentabelleneinträge in jeder Ebene der Seitentabelle zu erhalten (die Seitentabelle wird im Speicher gespeichert), bevor die Zuordnung abgeschlossen werden kann. Das heißt, um einen Speicherzugriff zu erreichen, wird tatsächlich N+1 Mal auf den Speicher zugegriffen (N=Seitentabellenebene) und es müssen N Additionsoperationen ausgeführt werden.
Daher muss die Adresszuordnung von der Hardware unterstützt werden, und mmu (Speicherverwaltungseinheit) ist diese Hardware. Und zum Speichern der Seitentabelle wird ein Cache benötigt. Dieser Cache ist der TLB (Translation Lookaside Buffer).
Trotzdem ist die Adresszuordnung immer noch mit einem erheblichen Aufwand verbunden. Unter der Annahme, dass die Cache-Zugriffsgeschwindigkeit zehnmal so hoch ist wie die des Speichers, die Trefferquote 40 % beträgt und die Seitentabelle drei Ebenen hat, verbraucht ein Zugriff auf eine virtuelle Adresse im Durchschnitt etwa zwei Zugriffszeiten auf den physischen Speicher.
Daher verzichtet einige eingebettete Hardware möglicherweise auf die Verwendung von mmu. Auf dieser Hardware können VxWorks (ein sehr effizientes eingebettetes Echtzeitbetriebssystem), Linux (Linux verfügt auch über eine Kompilierungsoption zum Deaktivieren von mmu) und andere Systeme ausgeführt werden.
Aber auch die Vorteile der Verwendung von mmu sind groß, der wichtigste sind Sicherheitsaspekte. Jeder Prozess verfügt über einen unabhängigen virtuellen Adressraum und stört sich nicht gegenseitig. Nachdem die Adresszuordnung aufgegeben wurde, werden alle Programme im selben Adressraum ausgeführt. Daher kann der Speicherzugriff eines Prozesses außerhalb der Grenzen auf einer Maschine ohne mmu unerklärliche Fehler in anderen Prozessen verursachen oder sogar zum Absturz des Kernels führen.
In Bezug auf die Adresszuordnung stellt der Kernel nur Seitentabellen bereit und die eigentliche Konvertierung wird von der Hardware durchgeführt. Wie generiert der Kernel diese Seitentabellen? Dies hat zwei Aspekte: die Verwaltung des virtuellen Adressraums und die Verwaltung des physischen Speichers. (Tatsächlich muss nur die Adresszuordnung im Benutzermodus verwaltet werden, und die Adresszuordnung im Kernelmodus ist fest codiert.)
Virtuelle Adressverwaltung
Jeder Prozess entspricht einer Aufgabenstruktur, die auf eine mm-Struktur verweist, die der Speichermanager des Prozesses ist. (Bei Threads hat jeder Thread auch eine Aufgabenstruktur, aber alle zeigen auf denselben mm, sodass der Adressraum gemeinsam genutzt wird.)
mm->pgd zeigt auf den Speicher, der die Seitentabelle enthält. Jeder Prozess hat seinen eigenen mm und jeder mm hat seine eigene Seitentabelle. Wenn der Prozess geplant ist, wird daher die Seitentabelle umgeschaltet (im Allgemeinen gibt es ein CPU-Register zum Speichern der Adresse der Seitentabelle, z. B. CR3 unter X86, und das Umschalten der Seitentabelle dient zum Ändern des Werts des Registers). Daher wirken sich die Adressräume der einzelnen Prozesse nicht gegenseitig aus (da die Seitentabellen unterschiedlich sind, können Sie natürlich nicht auf die Adressräume anderer Personen zugreifen. Mit Ausnahme des gemeinsam genutzten Speichers ist dies absichtlich so, dass verschiedene Seitentabellen auf dieselbe physische Adresse zugreifen können . ).
Die Vorgänge des Benutzerprogramms im Speicher (Zuweisung, Wiederverwendung, Zuordnung usw.) sind alle Vorgänge auf mm, insbesondere Vorgänge auf dem VMA (virtueller Speicherplatz) auf mm. Diese VMA stellen verschiedene Bereiche des Prozessraums dar, z. B. Heap, Stapel, Codebereich, Datenbereich, verschiedene Zuordnungsbereiche usw.
Die Vorgänge des Benutzerprogramms im Speicher wirken sich nicht direkt auf die Seitentabelle aus, geschweige denn auf die Zuweisung von physischem Speicher. Wenn Malloc beispielsweise erfolgreich ist, ändert sich nur eine bestimmte VMA. Die Seitentabelle ändert sich nicht und die Zuweisung des physischen Speichers ändert sich nicht.
Angenommen, der Benutzer reserviert Speicher und greift dann auf diesen Speicher zu. Da die entsprechende Zuordnung nicht in der Seitentabelle aufgezeichnet ist, generiert die CPU eine Seitenfehlerausnahme. Der Kernel fängt die Ausnahme ab und prüft, ob die Adresse, an der die Ausnahme aufgetreten ist, in einer legalen VMA vorhanden ist. Wenn dies nicht der Fall ist, weisen Sie dem Prozess einen „Segmentierungsfehler“ zu und lassen Sie ihn abstürzen. Wenn dies der Fall ist, weisen Sie eine physische Seite zu und erstellen Sie eine Zuordnung dafür.
Physische Speicherverwaltung
Wie wird also der physische Speicher zugewiesen?
Erstens unterstützt Linux NUMA (nicht homogene Speicherarchitektur), und die erste Ebene der physischen Speicherverwaltung ist die Medienverwaltung. Die Struktur pg_data_t beschreibt das Medium. Im Allgemeinen besteht unser Speicherverwaltungsmedium nur aus Speicher und ist einheitlich, sodass einfach davon ausgegangen werden kann, dass es nur ein pg_data_t-Objekt im System gibt.
Unter jedem Medium gibt es mehrere Zonen. Im Allgemeinen gibt es drei: DMA, NORMAL und HOCH.
DMA: Da der DMA-Bus einiger Hardwaresysteme schmaler ist als der Systembus, kann nur ein Teil des Adressraums für DMA verwendet werden. Dieser Teil der Adresse wird im DMA-Bereich verwaltet (dies ist ein High-End-Produkt). ;
HOCH: High-End-Speicher. In einem 32-Bit-System beträgt der Adressraum 4G. Der Kernel legt fest, dass der Bereich von 3 bis 4G der Kernelraum und 0 bis 3G der Benutzerraum ist (jeder Benutzerprozess verfügt über einen so großen virtuellen Raum) (Abbildung: Mitte unten). Wie bereits erwähnt, ist die Adresszuordnung des Kernels hartcodiert, was bedeutet, dass die entsprechende Seitentabelle von 3 bis 4G hartcodiert ist und der physischen Adresse 0 bis 1G zugeordnet ist. (Tatsächlich wird 1G nicht zugeordnet, sondern nur 896 MB. Der verbleibende Platz bleibt für die Zuordnung physischer Adressen größer als 1G übrig, und dieser Teil ist offensichtlich nicht fest codiert.) Daher verfügen physische Adressen mit mehr als 896 MB nicht über fest codierte Seitentabellen, die ihnen entsprechen, und der Kernel kann nicht direkt auf sie zugreifen (eine Zuordnung muss erstellt werden). Sie werden als High-End-Speicher bezeichnet (natürlich, wenn es sich um Maschinenspeicher handelt). ist kleiner als 896 MB, es gibt keinen High-End-Speicher. Wenn es sich um eine 64-Bit-Maschine handelt, gibt es keinen High-End-Speicher, da der Adressraum sehr groß ist und der zum Kernel gehörende Speicherplatz mehr als 1 GB beträgt. ;
NORMAL: Speicher, der nicht zu DMA oder HIGH gehört, wird als NORMAL bezeichnet.
Die Zonenliste über der Zone stellt die Zuweisungsstrategie dar, dh die Zonenpriorität bei der Speicherzuweisung. Eine Art Speicherzuweisung wird häufig nicht nur in einer Zone zugewiesen. Wenn Sie beispielsweise eine Seite für die Verwendung im Kernel zuweisen, besteht die höchste Priorität darin, sie von NORMAL aus zuzuweisen. Wenn das nicht funktioniert, weisen Sie sie von DMA (HIGH) zu funktioniert nicht, da es noch nicht zugewiesen wurde. (Zuweisung erstellen), was eine Zuweisungsstrategie ist.
Jedes Speichermedium verwaltet eine mem_map, und für jede physische Seite im Medium wird eine entsprechende Seitenstruktur eingerichtet, um den physischen Speicher zu verwalten.
Jede Zone zeichnet ihre Startposition auf mem_map auf. Und die kostenlosen Seiten in dieser Zone sind über free_area verbunden. Die Zuweisung des physischen Speichers erfolgt von hier aus. Wenn Sie die Seite aus free_area entfernen, wird sie zugewiesen. (Die Speicherzuweisung des Kernels unterscheidet sich von der des Benutzerprozesses. Die Speichernutzung des Benutzers wird vom Kernel überwacht, und eine unsachgemäße Verwendung führt zu einem „Segmentierungsfehler“, während der Kernel unbeaufsichtigt ist und sich nur auf das Bewusstsein verlassen kann . Verwenden Sie keine Seiten, die Sie nicht aus free_area ausgewählt haben
[Adresszuordnung erstellen]
Wenn der Kernel physischen Speicher benötigt, wird in vielen Fällen die gesamte Seite zugewiesen. Wählen Sie dazu einfach eine Seite aus der mem_map oben aus. Beispielsweise erfasst der zuvor erwähnte Kernel Seitenfehlerausnahmen und muss dann eine Seite zuweisen, um eine Zuordnung einzurichten.
Apropos: Wenn der Kernel Seiten zuweist und eine Adresszuordnung herstellt, stellt sich die Frage, ob der Kernel virtuelle Adressen oder physische Adressen verwendet. Erstens sind die Adressen, auf die der Kernel-Code zugreift, virtuelle Adressen, da die CPU-Anweisungen virtuelle Adressen erhalten (die Adresszuordnung ist für CPU-Anweisungen transparent). Beim Einrichten der Adresszuordnung ist jedoch der vom Kernel in die Seitentabelle eingefügte Inhalt die physische Adresse, da das Ziel der Adresszuordnung darin besteht, die physische Adresse zu erhalten.
Wie erhält der Kernel diese physische Adresse? Tatsächlich werden die Seiten in mem_map, wie oben erwähnt, auf der Grundlage des physischen Speichers erstellt, und jede Seite entspricht einer physischen Seite.
Wir können also sagen, dass die Zuordnung virtueller Adressen hier durch die Seitenstruktur abgeschlossen wird und sie die endgültige physische Adresse ergeben. Allerdings wird die Seitenstruktur offensichtlich über virtuelle Adressen verwaltet (wie bereits erwähnt, erhalten CPU-Anweisungen virtuelle Adressen). Die Seitenstruktur implementiert also die virtuelle Adresszuordnung anderer Personen. Wer implementiert die eigene virtuelle Adresszuordnung der Seitenstruktur? Niemand kann es erreichen.
Dies führt zu einem bereits erwähnten Problem. Die Seitentabelleneinträge im Kernelbereich sind fest codiert. Bei der Initialisierung des Kernels wurde die Adresszuordnung im Adressraum des Kernels fest codiert. Die Seitenstruktur existiert offensichtlich im Kernelraum, daher wurde das Problem der Adresszuordnung durch „Hardcodierung“ gelöst.
Da die Seitentabelleneinträge im Kernel-Bereich fest codiert sind, entsteht ein weiteres Problem. Der Speicher im NORMAL-Bereich (oder DMA-Bereich) kann sowohl dem Kernel-Bereich als auch dem Benutzerbereich zugeordnet werden. Die Zuordnung zum Kernelraum ist offensichtlich, da diese Zuordnung fest codiert ist. Diese Seiten können auch dem Benutzerbereich zugeordnet werden, was in dem zuvor erwähnten Ausnahmeszenario für fehlende Seiten möglich ist. Dem Benutzerbereich zugeordnete Seiten sollten zuerst aus dem HIGH-Bereich abgerufen werden, da der Zugriff auf diese Speicher für den Kernel unbequem ist. Daher ist es am besten, sie dem Benutzerbereich zuzuweisen. Der HIGH-Bereich ist jedoch möglicherweise erschöpft oder es gibt keinen HIGH-Bereich im System, da der physische Speicher auf dem Gerät nicht ausreicht. Daher ist die Zuordnung des NORMAL-Bereichs zum Benutzerbereich unvermeidlich.
Es stellt jedoch kein Problem dar, dass der Speicher im NORMAL-Bereich sowohl dem Kernel-Space als auch dem User-Space zugeordnet ist, denn wenn eine Seite vom Kernel verwendet wird, sollte die entsprechende Seite aus dem free_area entfernt worden sein, also die Seitenfehlerausnahme Der Code wird nicht mehr verarbeitet. Diese Seite ist dem Benutzerbereich zugeordnet. Dasselbe gilt auch umgekehrt. Die dem Benutzerbereich zugeordnete Seite wurde natürlich aus free_area entfernt und der Kernel wird diese Seite nicht mehr verwenden.
Kernel-Speicherplatzverwaltung
Zusätzlich zur Nutzung der gesamten Speicherseite muss der Kernel manchmal auch einen Speicherplatz beliebiger Größe zuweisen, genau wie das Benutzerprogramm malloc verwendet. Diese Funktion wird durch das Plattensystem umgesetzt.
Slab entspricht der Einrichtung eines Objektpools für einige im Kernel häufig verwendete Strukturobjekte, z. B. den Pool, der der Aufgabenstruktur entspricht, den Pool, der der mm-Struktur entspricht usw.
Slab verwaltet auch allgemeine Objektpools, z. B. den Objektpool „32-Byte-Größe“, den Objektpool „64-Byte-Größe“ usw. Die im Kernel häufig verwendete kmalloc-Funktion (ähnlich malloc im Benutzermodus) wird in diesen allgemeinen Objektpools zugewiesen.
Zusätzlich zum tatsächlich vom Objekt genutzten Speicherplatz verfügt Slab auch über eine entsprechende Kontrollstruktur. Es gibt zwei Möglichkeiten, es zu organisieren. Wenn das Objekt kleiner ist, verwendet die Kontrollstruktur dieselbe Seite wie der Objektbereich.
Zusätzlich zu Slab führte Linux 2.6 auch Mempool (Speicherpool) ein. Die Absicht ist: Wir möchten nicht, dass die Zuweisung bestimmter Objekte aufgrund von unzureichendem Speicher fehlschlägt. Deshalb weisen wir mehrere Objekte im Voraus zu und speichern sie im Mempool. Unter normalen Umständen werden die Ressourcen im Mempool bei der Zuweisung von Objekten nicht berührt und wie gewohnt über die Platte zugewiesen. Wenn der Systemspeicher knapp ist und der Speicher nicht über Slab zugewiesen werden kann, wird der Inhalt des Mempools verwendet.
Seitenwechsel(Bild: oben rechts)
Das Ein- und Auswechseln von Seiten ist ein weiteres sehr komplexes System. Das Auslagern von Speicherseiten auf die Festplatte und das Zuordnen von Festplattendateien zum Speicher sind zwei sehr ähnliche Prozesse (die Motivation hinter dem Auslagern von Speicherseiten auf die Festplatte besteht darin, sie in Zukunft wieder von der Festplatte in den Speicher zu laden). Daher verwendet Swap einige Mechanismen des Dateisubsystems wieder.
Das Ein- und Auslagern von Seiten ist eine sehr CPU- und E/A-intensive Angelegenheit, aber aufgrund der historischen Tatsache, dass Speicher teuer ist, müssen wir Festplatten verwenden, um den Speicher zu erweitern. Aber jetzt, wo Speicher immer günstiger wird, können wir problemlos mehrere Gigabyte Speicher einbauen und dann das Swap-System abschalten. Daher ist die Implementierung von Swap wirklich schwierig zu erforschen, daher werde ich hier nicht auf Details eingehen. (Siehe auch: „Eine kurze Analyse des Seitenrecyclings im Linux-Kernel“)
[Benutzerspeicherplatzverwaltung]
Malloc ist eine Bibliotheksfunktion von libc, und Benutzerprogramme verwenden sie (oder ähnliche Funktionen) im Allgemeinen, um Speicherplatz zuzuweisen.
Es gibt zwei Möglichkeiten für libc, Speicher zuzuweisen. Eine besteht darin, die Größe des Heaps anzupassen, und die andere darin, einen neuen virtuellen Speicherbereich zuzuordnen (der Heap ist auch ein VMA).
Im Kernel ist der Heap ein VMA mit einem festen Ende und einem einziehbaren Ende (Bild: Mitte links). Das skalierbare Ende wird über den brk-Systemaufruf angepasst. Libc verwaltet den Heap-Speicherplatz. Wenn der Benutzer malloc aufruft, um Speicher zuzuweisen, versucht libc, ihn vom vorhandenen Heap zuzuweisen. Wenn der Heap-Speicherplatz nicht ausreicht, erhöhen Sie den Heap-Speicherplatz über brk.
Wenn der Benutzer den zugewiesenen Speicherplatz freigibt, kann libc den Heap-Speicherplatz über brk reduzieren. Es ist jedoch einfach, den Heap-Speicherplatz zu vergrößern, es ist jedoch schwierig, ihn zu reduzieren. Stellen Sie sich eine Situation vor, in der dem Benutzerspeicher kontinuierlich 10 Speicherblöcke zugewiesen wurden und die ersten 9 Blöcke freigegeben wurden. Selbst wenn der 10. Block, der nicht frei ist, nur 1 Byte groß ist, kann libc zu diesem Zeitpunkt die Heap-Größe nicht reduzieren. Weil nur ein Ende des Pfahls ausgedehnt und zusammengezogen werden kann und die Mitte nicht ausgehöhlt werden kann. Der 10. Speicherblock belegt das skalierbare Ende des Heaps. Die Größe des Heaps kann nicht reduziert werden und die zugehörigen Ressourcen können nicht an den Kernel zurückgegeben werden.
Wenn der Benutzer einen großen Speicher mallociert, ordnet libc über den mmap-Systemaufruf eine neue VMA zu. Da die Anpassung der Heap-Größe und die Speicherplatzverwaltung immer noch problematisch sind, ist es bequemer, eine VMA neu zu erstellen (das oben erwähnte kostenlose Problem ist auch einer der Gründe).
Warum also nicht während Malloc immer eine neue VMA mmapieren? Erstens kann der von libc verwaltete Heap-Speicherplatz für die Zuweisung und Wiederverwertung kleiner Räume bereits den Bedarf decken, und es ist nicht jedes Mal erforderlich, Systemaufrufe durchzuführen. Und VMA basiert auf der Seite, und das Minimum besteht darin, eine Seite zuzuweisen. Zweitens verringert eine zu große Anzahl an VMA die Systemleistung. Seitenfehlerausnahmen, Erstellung und Zerstörung von VMA, Größenänderung des Heap-Speicherplatzes usw. erfordern alle Vorgänge auf VMA. Sie müssen die VMA (oder diejenigen) finden, die unter allen VMA im aktuellen Prozess ausgeführt werden muss. Zu viele VMAS führen unweigerlich zu Leistungseinbußen. (Wenn der Prozess weniger VMAs hat, verwendet der Kernel eine verknüpfte Liste zum Verwalten von VMAs; wenn mehr VMAs vorhanden sind, wird stattdessen ein rot-schwarzer Baum verwendet.)
[Benutzerstapel]
Wie der Heap ist auch der Stapel ein VMA (Bild: Mitte links). Dieser VMA ist an einem Ende fest und am anderen Ende erweiterbar (beachten Sie, dass er nicht zusammengezogen werden kann). Diese VMA ist etwas Besonderes. Es gibt keinen Systemaufruf wie brk, um diese VMA zu dehnen.
Wenn die vom Benutzer aufgerufene virtuelle Adresse diese VMA überschreitet, erhöht der Kernel die VMA automatisch, wenn er Seitenfehlerausnahmen behandelt. Der Kernel überprüft das aktuelle Stapelregister (z. B. ESP) und die virtuelle Adresse, auf die zugegriffen wird, darf ESP plus n nicht überschreiten (n ist die maximale Anzahl von Bytes, die der CPU-Push-Befehl gleichzeitig auf den Stapel verschieben kann). Mit anderen Worten: Der Kernel verwendet ESP als Benchmark, um zu prüfen, ob der Zugriff außerhalb der Grenzen liegt.
Der Wert von ESP kann jedoch von Programmen im Benutzermodus frei gelesen und geschrieben werden. Was passiert, wenn das Benutzerprogramm ESP anpasst und den Stapel sehr groß macht? Es gibt eine Reihe von Konfigurationen zu Prozessbeschränkungen im Kernel, einschließlich der Konfiguration der Stapelgröße. Der Stapel kann nur so groß sein, und wenn er größer ist, tritt ein Fehler auf.
Für einen Prozess kann der Stapel im Allgemeinen relativ groß gestreckt werden (z. B. 8 MB). Aber was ist mit Threads?
Erstens: Was ist mit dem Stapel des Threads los? Wie bereits erwähnt, teilt sich der mm eines Threads seinen übergeordneten Prozess. Obwohl der Stapel eine VMA in mm ist, kann der Thread diese VMA nicht mit seinem übergeordneten Prozess teilen (zwei laufende Entitäten müssen sich offensichtlich keinen Stapel teilen). Wenn der Thread erstellt wird, erstellt die Thread-Bibliothek daher über mmap eine neue VMA als Thread-Stack (im Allgemeinen größer als: 2 MB).
Es ist ersichtlich, dass der Stapel des Threads in gewisser Weise kein echter Stapel ist. Er ist ein fester Bereich und hat eine sehr begrenzte Kapazität.
Durch diesen Artikel sollten Sie über ein grundlegendes Verständnis der Linux-Speicherverwaltung verfügen. Dies ist eine effektive Methode zum Konvertieren und Zuweisen von virtuellem Speicher und physischem Speicher und kann an die unterschiedlichen Anforderungen von Linux-Systemen angepasst werden. Natürlich ist die Speicherverwaltung nicht statisch, sie muss entsprechend der spezifischen Hardwareplattform und Kernelversion angepasst und geändert werden. Kurz gesagt, die Speicherverwaltung ist eine unverzichtbare Komponente im Linux-System und verdient Ihr eingehendes Studium und Ihre Beherrschung.
Das obige ist der detaillierte Inhalt vonLinux-Speicherverwaltung: Konvertieren und Zuweisen von virtuellem und physischem Speicher. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



