

In der Linux-Multithread-Programmierung sind Sperren ein sehr wichtiger Mechanismus, der Konkurrenz und Deadlocks zwischen Threads vermeiden kann. Wenn Sperren jedoch falsch verwendet werden, kann es zu Leistungseinbußen und unberechenbarem Verhalten kommen. In diesem Artikel werden gängige Sperrtypen unter Linux vorgestellt, wie man sie richtig verwendet und wie man Probleme wie Konflikte und Deadlocks vermeidet.
In der Programmierung wird das Konzept der Objekt-Mutex-Sperre eingeführt, um die Integrität gemeinsam genutzter Datenoperationen sicherzustellen. Jedem Objekt entspricht eine Markierung namens „Mutex-Sperre“, mit der sichergestellt wird, dass jeweils nur ein Thread auf das Objekt zugreifen kann. Der von Linux implementierte Mutex-Sperrmechanismus umfasst POSIX-Mutex-Sperren und Kernel-Mutex-Sperren. In diesem Artikel geht es hauptsächlich um POSIX-Mutex-Sperren, also Inter-Thread-Mutex-Sperren.
Semaphore werden für die Multi-Thread- und Multi-Task-Synchronisation verwendet. Wenn ein Thread eine bestimmte Aktion abschließt, teilt er dies anderen Threads über das Semaphor mit und die anderen Threads führen dann bestimmte Aktionen aus (wenn sich alle in sem_wait befinden, werden sie dort blockiert). . Mutex-Sperren werden für den gegenseitigen Ausschluss mehrerer Threads und mehrerer Aufgaben verwendet. Wenn ein Thread eine bestimmte Ressource belegt, können andere Threads nicht darauf zugreifen, bis dieser Thread entsperrt ist. Beispielsweise erfordert der Zugriff auf globale Variablen manchmal das Sperren und Entsperren nach Abschluss des Vorgangs. Manchmal werden Schlösser und Semaphore gleichzeitig verwendet“
Mit anderen Worten, ein Semaphor sperrt nicht unbedingt eine bestimmte Ressource, sondern ein Prozesskonzept. Beispiel: Es gibt zwei Threads A und B. Thread B muss warten, bis Thread A eine bestimmte Aufgabe abgeschlossen hat, bevor er mit den folgenden Schritten fortfährt Diese Aufgabe erfordert nicht unbedingt das Sperren einer bestimmten Ressource, sondern kann auch die Durchführung einiger Berechnungen oder Datenverarbeitungen umfassen. Der Thread-Mutex ist das Konzept des „Sperrens einer bestimmten Ressource“. Während des Sperrzeitraums können andere Threads die geschützten Daten nicht bearbeiten. In einigen Fällen sind die beiden austauschbar.
Der Unterschied zwischen den beiden:
Umfang
Semaphor: Interprozess oder Inter-Thread (Linux nur Inter-Thread)
Mutex-Sperre: zwischen Threads
Im gesperrten Zustand
Semaphor: Solange der Wert des Semaphors größer als 0 ist, können andere Threads erfolgreich sem_wait sein. Nach Erfolg wird der Wert des Semaphors um eins reduziert. Wenn der Wert nicht größer als 0 ist, blockiert sem_wait, bis der Wert nach der Freigabe von sem_post um eins erhöht wird. Mit einem Wort, der Wert des Semaphors>=0.
Mutex-Sperre: Solange sie gesperrt ist, kann kein anderer Thread auf die geschützte Ressource zugreifen. Wenn keine Sperre vorhanden ist, wird die Ressource erfolgreich abgerufen. Andernfalls wird blockiert und darauf gewartet, dass die Ressource verfügbar ist. Kurz gesagt, der Wert eines Thread-Mutex kann negativ sein.
Multi-Threading
Ein Thread ist die kleinste Einheit, die unabhängig in einem Computer läuft und bei der Ausführung nur sehr wenig Systemressourcen beansprucht. Im Vergleich zu Multiprozessen bietet Multiprozess einige Vorteile, die Multiprozess nicht bietet. Das Wichtigste ist: Bei Multithreading können mehr Ressourcen eingespart werden als bei Multiprozessen.
Thread-Erstellung
Unter Linux befindet sich der neu erstellte Thread nicht im ursprünglichen Prozess, sondern das System ruft clone() über einen Systemaufruf auf. Das System kopiert einen Prozess, der genau dem ursprünglichen Prozess entspricht, und führt in diesem Prozess die Thread-Funktion aus.
Unter Linux wird die Thread-Erstellung durch die Funktion pthread_create() erreicht:
pthread_create()
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,void *(*st
Unter ihnen:
thread stellt einen Zeiger vom Typ pthread_t;
darattr wird verwendet, um einige Attribute des Threads anzugeben;
start_routine stellt einen Funktionszeiger dar, bei dem es sich um eine Thread-Aufruffunktion handelt;
arg stellt die Parameter dar, die an die Thread-Aufruffunktion übergeben werden.
Wenn der Thread erfolgreich erstellt wurde, gibt die Funktion pthread_create() 0 zurück. Wenn der Rückgabewert nicht 0 ist, bedeutet dies, dass die Thread-Erstellung fehlgeschlagen ist. Für Thread-Attribute werden diese in der Struktur pthread_attr_t definiert.
Der Prozess der Thread-Erstellung ist wie folgt:
#include
#include
#include
#include
void* thread(void *id){
pthread_t newthid;
newthid = pthread_self();
printf("this is a new thread, thread ID is %u\n", newthid);
return NULL;
}
int main(){
int num_thread = 5;
pthread_t *pt = (pthread_t *)malloc(sizeof(pthread_t) * num_thread);
printf("main thread, ID is %u\n", pthread_self());
for (int i = 0; i if (pthread_create(&pt[i], NULL, thread, NULL) != 0){
printf("thread create failed!\n");
return 1;
}
}
sleep(2);
free(pt);
return 0;
}
Im obigen Code wird die Funktion pthread_self() verwendet. Die Funktion dieser Funktion besteht darin, die Thread-ID dieses Threads abzurufen. Sleep() in der Hauptfunktion wird verwendet, um den Hauptprozess in einen Wartezustand zu versetzen, damit die Thread-Ausführung abgeschlossen werden kann. Der endgültige Ausführungseffekt ist wie folgt:
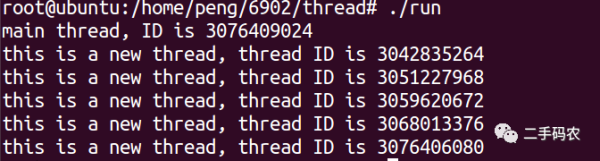
Wie verwendet man arg, um Parameter an Unterthreads zu übergeben? Die spezifische Implementierung lautet wie folgt:
#include
#include
#include
#include
void* thread(void *id){
pthread_t newthid;
newthid = pthread_self();
int num = *(int *)id;
printf("this is a new thread, thread ID is %u,id:%d\n", newthid, num);
return NULL;
}
int main(){
//pthread_t thid;
int num_thread = 5;
pthread_t *pt = (pthread_t *)malloc(sizeof(pthread_t) * num_thread);
int * id = (int *)malloc(sizeof(int) * num_thread);
printf("main thread, ID is %u\n", pthread_self());
for (int i = 0; i if (pthread_create(&pt[i], NULL, thread, &id[i]) != 0){
printf("thread create failed!\n");
return 1;
}
}
sleep(2);
free(pt);
free(id);
return 0;
}
Der endgültige Ausführungseffekt ist in der folgenden Abbildung dargestellt:
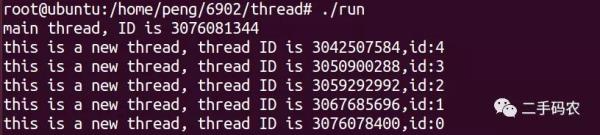
Was passiert, wenn der Hauptprozess vorzeitig endet? Wie im folgenden Code gezeigt:
#include
#include
#include
#include
void* thread(void *id){
pthread_t newthid;
newthid = pthread_self();
int num = *(int *)id;
printf("this is a new thread, thread ID is %u,id:%d\n", newthid, num);
sleep(2);
printf("thread %u is done!\n", newthid);
return NULL;
}
int main(){
//pthread_t thid;
int num_thread = 5;
pthread_t *pt = (pthread_t *)malloc(sizeof(pthread_t) * num_thread);
int * id = (int *)malloc(sizeof(int) * num_thread);
printf("main thread, ID is %u\n", pthread_self());
for (int i = 0; i if (pthread_create(&pt[i], NULL, thread, &id[i]) != 0){
printf("thread create failed!\n");
return 1;
}
}
//sleep(2);
free(pt);
free(id);
return 0;
}
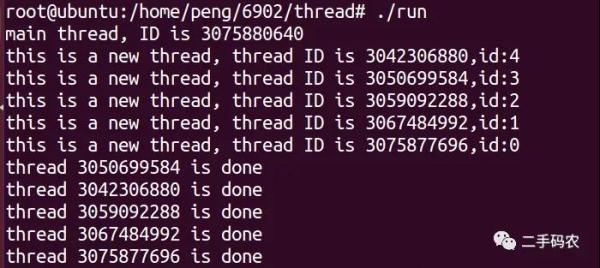
Zu diesem Zeitpunkt wird der Hauptprozess vorzeitig beendet und die Threads werden die Ausführung beenden. Die laufenden Ergebnisse sind wie folgt:

Thread hängt
Um es dem Hauptthread zu ermöglichen, vor dem Beenden auf den Abschluss jedes Unterthreads zu warten, wird im Linux-Multithreading auch die Funktion pthread_join() verwendet Warten Sie auf andere Threads, die spezifische Form der Funktion ist:
int pthread_join(pthread_t thread, void **retval);
Die Funktion pthread_join() wird verwendet, um auf das Ende eines Threads zu warten, und ihr Aufruf wird angehalten.
一个线程仅允许一个线程使用pthread_join()等待它的终止。
如需要在主线程中等待每一个子线程的结束,如下述代码所示:
#include
#include
#include
#include
void* thread(void *id){
pthread_t newthid;
newthid = pthread_self();
int num = *(int *)id;
printf("this is a new thread, thread ID is %u,id:%d\n", newthid, num);
printf("thread %u is done\n", newthid);
return NULL;
}
int main(){
int num_thread = 5;
pthread_t *pt = (pthread_t *)malloc(sizeof(pthread_t) * num_thread);
int * id = (int *)malloc(sizeof(int) * num_thread);
printf("main thread, ID is %u\n", pthread_self());
for (int i = 0; i if (pthread_create(&pt[i], NULL, thread, &id[i]) != 0){
printf("thread create failed!\n");
return 1;
}
}
for (int i = 0; i return 0;
}
最终的执行效果如下所示:
注:在编译的时候需要链接libpthread.a:
g++ xx.c -lpthread -o xx
互斥锁mutex
多线程的问题引入
多线程的最大的特点是资源的共享,但是,当多个线程同时去操作(同时去改变)一个临界资源时,会破坏临界资源。如利用多线程同时写一个文件:
#include
#include
const char filename[] = "hello";
void* thread(void *id){
int num = *(int *)id;
// 写文件的操作
FILE *fp = fopen(filename, "a+");
int start = *((int *)id);
int end = start + 1;
setbuf(fp, NULL);// 设置缓冲区的大小
fprintf(stdout, "%d\n", start);
for (int i = (start * 10); i "%d\t", i);
}
fprintf(fp, "\n");
fclose(fp);
return NULL;
}
int main(){
int num_thread = 5;
pthread_t *pt = (pthread_t *)malloc(sizeof(pthread_t) * num_thread);
int * id = (int *)malloc(sizeof(int) * num_thread);
for (int i = 0; i if (pthread_create(&pt[i], NULL, thread, &id[i]) != 0){
printf("thread create failed!\n");
return 1;
}
}
for (int i = 0; i return 0;
}
执行以上的代码,我们会发现,得到的结果是混乱的,出现上述的最主要的原因是,我们在编写多线程代码的过程中,每一个线程都尝试去写同一个文件,这样便出现了上述的问题,这便是共享资源的同步问题,在Linux编程中,线程同步的处理方法包括:信号量,互斥锁和条件变量。
互斥锁
互斥锁是通过锁的机制来实现线程间的同步问题。互斥锁的基本流程为:
初始化一个互斥锁:pthread_mutex_init()函数
加锁:pthread_mutex_lock()函数或者pthread_mutex_trylock()函数
对共享资源的操作
解锁:pthread_mutex_unlock()函数
注销互斥锁:pthread_mutex_destory()函数
其中,在加锁过程中,pthread_mutex_lock()函数和pthread_mutex_trylock()函数的过程略有不同:
当使用pthread_mutex_lock()函数进行加锁时,若此时已经被锁,则尝试加锁的线程会被阻塞,直到互斥锁被其他线程释放,当pthread_mutex_lock()函数有返回值时,说明加锁成功;
而使用pthread_mutex_trylock()函数进行加锁时,若此时已经被锁,则会返回EBUSY的错误码。
同时,解锁的过程中,也需要满足两个条件:
解锁前,互斥锁必须处于锁定状态;
必须由加锁的线程进行解锁。
当互斥锁使用完成后,必须进行清除。
有了以上的准备,我们重新实现上述的多线程写操作,其实现代码如下所示:
#include
#include
pthread_mutex_t mutex;
const char filename[] = "hello";
void* thread(void *id){
int num = *(int *)id;
// 加锁
if (pthread_mutex_lock(&mutex) != 0){
fprintf(stdout, "lock error!\n");
}
// 写文件的操作
FILE *fp = fopen(filename, "a+");
int start = *((int *)id);
int end = start + 1;
setbuf(fp, NULL);// 设置缓冲区的大小
fprintf(stdout, "%d\n", start);
for (int i = (start * 10); i "%d\t", i);
}
fprintf(fp, "\n");
fclose(fp);
// 解锁
pthread_mutex_unlock(&mutex);
return NULL;
}
int main(){
int num_thread = 5;
pthread_t *pt = (pthread_t *)malloc(sizeof(pthread_t) * num_thread);
int * id = (int *)malloc(sizeof(int) * num_thread);
// 初始化互斥锁
if (pthread_mutex_init(&mutex, NULL) != 0){
// 互斥锁初始化失败
free(pt);
free(id);
return 1;
}
for (int i = 0; i if (pthread_create(&pt[i], NULL, thread, &id[i]) != 0){
printf("thread create failed!\n");
return 1;
}
}
for (int i = 0; i return 0;
}
最终的结果为:
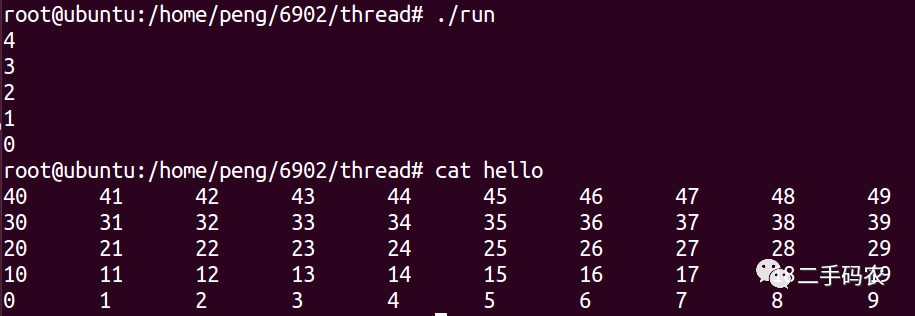
通过本文的介绍,您应该已经了解了Linux多线程编程中的常见锁类型、正确使用锁的方法以及如何避免竞争和死锁等问题。锁机制是多线程编程中必不可少的一部分,掌握它们可以使您的代码更加健壮和可靠。在实际应用中,应该根据具体情况选择合适的锁类型,并遵循最佳实践,以确保程序的高性能和可靠性。
Das obige ist der detaillierte Inhalt vonAusführliche Erläuterung der Linux-Multithread-Programmiersperren: So vermeiden Sie Konflikte und Deadlocks. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



