

Linux CFS: So erreichen Sie vollständige Fairness bei der Prozessplanung

Prozessplanung ist eine der Kernfunktionen des Betriebssystems. Sie bestimmt, welche Prozesse CPU-Ausführungszeit erhalten können und wie viel Zeit sie erhalten. In Linux-Systemen gibt es viele Prozessplanungsalgorithmen. Der wichtigste und am häufigsten verwendete ist der Completely Fair Scheduling Algorithm (CFS), der ab Linux Version 2.6.23 eingeführt wurde. Das Ziel von CFS besteht darin, jedem Prozess eine angemessene und faire Zuweisung von CPU-Zeit entsprechend seinem eigenen Gewicht und Bedarf zu ermöglichen und so die Gesamtleistung und Reaktionsgeschwindigkeit des Systems zu verbessern. In diesem Artikel werden die Grundprinzipien, die Datenstruktur, Implementierungsdetails sowie die Vor- und Nachteile von CFS vorgestellt und Ihnen dabei geholfen, die vollständige Fairness der Linux-Prozessplanung besser zu verstehen.
Eine kurze Geschichte des Linux-Schedulers
Frühe Linux-Scheduler verwendeten ein minimalistisches Design, das offensichtlich nicht auf große Architekturen mit vielen Prozessoren ausgerichtet war, geschweige denn auf Hyper-Threading. 1.2 Der Linux-Scheduler verwendet eine Ringwarteschlange für die Verwaltung ausführbarer Aufgaben und verwendet eine Round-Robin-Planungsstrategie. Dieser Scheduler fügt Prozesse sehr effizient hinzu und entfernt sie (mit Sperren, die die Struktur schützen). Kurz gesagt, der Scheduler ist nicht komplex, sondern einfach und schnell.
Linux Version 2.2 führte das Konzept der Planungsklassen ein und ermöglichte Planungsstrategien für Echtzeitaufgaben, nicht präemptive Aufgaben und Nicht-Echtzeitaufgaben. Der 2.2-Scheduler bietet außerdem Unterstützung für symmetrisches Multiprocessing (SMP).
Der 2.4-Kernel enthält einen relativ einfachen Scheduler, der in O(N)-Intervallen ausgeführt wird (er durchläuft jede Aufgabe während des Planungsereignisses). 2.4 Der Scheduler unterteilt die Zeit in Epochen. In jeder Epoche darf jede Aufgabe ausgeführt werden, bis ihre Zeitscheibe erschöpft ist. Wenn eine Aufgabe nicht alle Zeitscheiben nutzt, wird die Hälfte der verbleibenden Zeitscheiben zur neuen Zeitscheibe hinzugefügt, sodass sie in der nächsten Epoche länger ausgeführt werden kann. Der Scheduler iteriert einfach über Aufgaben und wendet eine Gütefunktion (Metrik) an, um zu entscheiden, welche Aufgabe als nächstes ausgeführt werden soll. Obwohl diese Methode relativ einfach ist, ist sie relativ ineffizient, nicht skalierbar und nicht für den Einsatz in Echtzeitsystemen geeignet. Es fehlt auch die Fähigkeit, die Vorteile neuer Hardware-Architekturen wie Multi-Core-Prozessoren zu nutzen.
Der frühe 2.6-Scheduler, genannt O(1)-Scheduler, wurde entwickelt, um ein Problem mit dem 2.4-Scheduler zu lösen – der Scheduler musste nicht die gesamte Aufgabenliste durchlaufen, um die nächste zu planende Aufgabe zu bestimmen (daher der Name O( 1), was bedeutet, dass es effizienter und skalierbarer ist. Der O(1)-Scheduler verfolgt die ausführbaren Aufgaben in der Ausführungswarteschlange (eigentlich gibt es zwei Ausführungswarteschlangen pro Prioritätsstufe – eine für aktive Aufgaben und eine für abgelaufene Aufgaben), was bedeutet, dass der Planer bestimmt, welche Aufgaben als nächste Aufgabe ausgeführt werden sollen Entnimmt einfach die nächste Aufgabe aus der Ausführungswarteschlange einer bestimmten Aktivität nach Priorität. Der O(1)-Scheduler lässt sich besser skalieren und bietet Interaktivität, wodurch eine Fülle von Erkenntnissen zur Bestimmung, ob eine Aufgabe E/A-gebunden oder prozessorgebunden ist, bereitgestellt wird. Aber der O(1)-Scheduler im Kernel ist ungeschickt. Die Berechnung von Offenbarungen erfordert viel Code, ist schwierig zu verwalten und erfasst für Puristen nicht das Wesentliche des Algorithmus.
Um die Probleme des O(1)-Schedulers zu lösen und mit anderen externen Belastungen umzugehen, muss etwas geändert werden. Diese Änderung stammt aus dem Kernel-Patch von Con Kolivas, der seinen Rotating Staircase Deadline Scheduler (RSDL) enthält, der seine frühen Arbeiten am Treppenplaner beinhaltet. Das Ergebnis dieser Arbeit ist ein einfach gestalteter Scheduler, der Fairness und begrenzte Latenz berücksichtigt. Der Scheduler von Kolivas hat viel Aufmerksamkeit erregt (und viele fordern, ihn in den aktuellen Mainstream-Kernel 2.6.21 aufzunehmen), und es ist klar, dass Änderungen am Scheduler bevorstehen. Ingo Molnar, der Erfinder des O(1)-Schedulers, entwickelte daraufhin einen CFS-basierten Scheduler auf der Grundlage einiger Ideen von Kolivas. Lassen Sie uns CFS genauer untersuchen und sehen, wie es auf hohem Niveau funktioniert.
———————————————————————————————————————
CFS-Übersicht
Die Hauptidee von CFS besteht darin, ein Gleichgewicht (Fairness) in Bezug auf die Bereitstellung von Prozessorzeit für Aufgaben aufrechtzuerhalten. Dies bedeutet, dass Prozessen eine erhebliche Anzahl von Prozessoren zugewiesen werden sollte. Wenn die einer Aufgabe zugewiesene Zeit nicht im Gleichgewicht ist (was bedeutet, dass einer oder mehreren Aufgaben im Vergleich zu anderen Aufgaben nicht viel Zeit eingeräumt wird), sollte der nicht im Gleichgewicht befindlichen Aufgabe Zeit zur Ausführung gegeben werden.
Um ein Gleichgewicht zu erreichen, verwaltet CFS die für eine Aufgabe bereitgestellte Zeit in einer sogenannten virtuellen Laufzeit. Je kleiner die virtuelle Laufzeit einer Aufgabe ist, desto kürzer ist die Zeit, die der Aufgabe erlaubt ist, auf den Server zuzugreifen – desto höher ist die Belastung des Prozessors. CFS beinhaltet auch das Konzept der Sleep-Fairness, um sicherzustellen, dass Aufgaben, die derzeit nicht ausgeführt werden (z. B. auf E/A warten), einen angemessenen Anteil des Prozessors erhalten, wenn sie ihn schließlich benötigen.
Aber im Gegensatz zu früheren Linux-Schedulern, die Aufgaben nicht in einer Ausführungswarteschlange verwalteten, verwaltete CFS einen zeitlich geordneten Rot-Schwarz-Baum (siehe Abbildung 1). Ein rotschwarzer Baum ist ein Baum mit vielen interessanten und nützlichen Eigenschaften. Erstens ist es selbstausgleichend, was bedeutet, dass kein Pfad im Baum mehr als doppelt so lang ist wie jeder andere Pfad. Zweitens erfolgt die Ausführung im Baum in O(log n) Zeit (wobei n die Anzahl der Knoten im Baum ist). Dadurch können Sie Aufgaben schnell und effizient einfügen oder löschen.
Abbildung 1. Beispiel eines rot-schwarzen Baumes
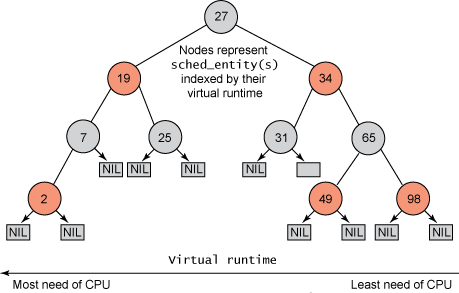
Aufgaben werden in einem zeitlich geordneten rot-schwarzen Baum (dargestellt durch sched_entity Objekte) gespeichert, wobei die prozessorintensivsten Aufgaben (geringste virtuelle Laufzeit) auf der linken Seite des Baums und die prozessorintensivsten Aufgaben ( Die höchste virtuelle Laufzeit) wird auf der rechten Seite des Baums gespeichert. Aus Gründen der Fairness wählt der Planer dann den am weitesten links stehenden Knoten des rot-schwarzen Baums aus, der als nächstes geplant werden soll, um die Fairness aufrechtzuerhalten. Eine Aufgabe berücksichtigt ihre CPU-Zeit, indem sie ihre Laufzeit zur virtuellen Laufzeit hinzufügt und sie dann, sofern sie ausführbar ist, wieder in den Baum einfügt. Auf diese Weise wird den Aufgaben auf der linken Seite des Baums Zeit zum Ausführen gegeben, und der Inhalt des Baums wird von rechts nach links migriert, um die Fairness zu gewährleisten. Daher holt jede ausführbare Aufgabe andere Aufgaben ein, um die Ausführungsbalance über den gesamten Satz ausführbarer Aufgaben hinweg aufrechtzuerhalten.
———————————————————————————————————————
CFS-interne Prinzipien
Alle Aufgaben innerhalb von Linux sind organisiert nach task_structs Darstellung der Aufgabenstruktur. Diese Struktur (und andere verwandte Inhalte) beschreibt die Aufgabe vollständig und umfasst den aktuellen Status der Aufgabe, ihren Stapel, ihre Prozessidentität, ihre Priorität (statisch und dynamisch) usw. Sie finden diese und verwandte Strukturen in ./linux/include/linux/sched.h. Da aber nicht alle Aufgaben ausführbar sind, werden Sie, Menlo, monospace;color: #10f5d6c">task_struct keine CFS-bezogenen Felder finden. Stattdessen wird eine neue Struktur namens task_struct 的任务结构表示。该结构(以及其他相关内容)完整地描述了任务并包括了任务的当前状态、其堆栈、进程标识、优先级(静态和动态)等等。您可以在 ./linux/include/linux/sched.h 中找到这些内容以及相关结构。 但是因为不是所有任务都是可运行的,您在 task_struct 中不会发现任何与 CFS 相关的字段。 相反,会创建一个名为 sched_entity erstellt, um Planungsinformationen zu verfolgen (siehe Abbildung 2).
Abbildung 2. Strukturelle Hierarchie von Aufgaben und rot-schwarzen Bäumen
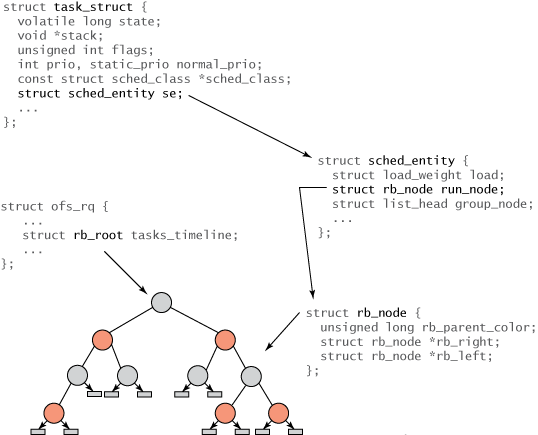
Die Beziehung zwischen verschiedenen Strukturen ist in Abbildung 2 dargestellt. Die Wurzel des Baumes verläuft durch die rb_root 元素通过 cfs_rq 结构(在 ./kernel/sched.c 中)引用。红黑树的叶子不包含信息,但是内部节点代表一个或多个可运行的任务。红黑树的每个节点都由 rb_node 表示,它只包含子引用和父对象的颜色。 rb_node 包含在sched_entity 结构中,该结构包含 rb_node 引用、负载权重以及各种统计数据。最重要的是, sched_entity 包含 vruntime(64 位字段),它表示任务运行的时间量,并作为红黑树的索引。 最后,task_struct 位于顶端,它完整地描述任务并包含 sched_entity-Struktur.
Was den CFS-Teil betrifft, ist die Planungsfunktion sehr einfach. In ./kernel/sched.c sehen Sie die generische schedule() 函数,它会先抢占当前运行任务(除非它通过yield() 代码先抢占自己)。注意 CFS 没有真正的时间切片概念用于抢占,因为抢占时间是可变的。 当前运行任务(现在被抢占的任务)通过对 put_prev_task 调用(通过调度类)返回到红黑树。 当 schedule 函数开始确定下一个要调度的任务时,它会调用 pick_next_task函数。此函数也是通用的(在 ./kernel/sched.c 中),但它会通过调度器类调用 CFS 调度器。 CFS 中的 pick_next_task 函数可以在 ./kernel/sched_fair.c(称为 pick_next_task_fair())中找到。 此函数只是从红黑树中获取最左端的任务并返回相关 sched_entity。通过此引用,一个简单的 task_of() 调用确定返回的 task_struct-Referenz. Der Universal Scheduler stellt schließlich den Prozessor für diese Aufgabe bereit.
———————————————————————————————————————
Priorität und CFS
CFS verwendet die Priorität nicht direkt, sondern als Abklingfaktor für die Zeit, die eine Aufgabe ausführen darf. Aufgaben mit niedriger Priorität haben einen höheren Abklingkoeffizienten, während Aufgaben mit hoher Priorität einen niedrigeren Abklingkoeffizienten haben. Dies bedeutet, dass die für die Aufgabenausführung vorgesehene Zeit bei Aufgaben mit niedriger Priorität schneller verbraucht wird als bei Aufgaben mit hoher Priorität. Dies ist eine praktische Lösung, um die Aufrechterhaltung einer nach Priorität geplanten Ausführungswarteschlange zu vermeiden.
CFS-Gruppenplanung
Ein weiterer interessanter Aspekt von CFS ist das Gruppenplanungskonzept (eingeführt im Kernel 2.6.24). Die Gruppenplanung ist eine weitere Möglichkeit, die Planung fairer zu gestalten, insbesondere wenn es um Aufgaben geht, die viele andere Aufgaben nach sich ziehen. Angenommen, ein Server, der viele Aufgaben auslöst, möchte eingehende Verbindungen parallelisieren (eine typische Architektur für HTTP-Server). Nicht alle Aufgaben werden einheitlich und fair behandelt, und CFS führt Gruppen ein, um mit diesem Verhalten umzugehen. Die Serverprozesse, die Aufgaben erzeugen, teilen ihre virtuellen Laufzeiten innerhalb der Gruppe (in einer Hierarchie), während einzelne Aufgaben ihre eigenen unabhängigen virtuellen Laufzeiten verwalten. Auf diese Weise erhalten einzelne Aufgaben ungefähr die gleiche Planungszeit wie die Gruppe. Sie werden feststellen, dass die /proc-Schnittstelle zum Verwalten der Prozesshierarchie verwendet wird, sodass Sie die vollständige Kontrolle darüber haben, wie Gruppen gebildet werden. Mit dieser Konfiguration können Sie Fairness auf Benutzer, Prozesse oder Variationen davon verteilen.
Kurse und Domänen planen
Zusammen mit CFS wurde das Konzept der Unterrichtsplanung eingeführt (siehe Abbildung 2). Jede Aufgabe gehört zu einer Planungsklasse, die bestimmt, wie die Aufgabe geplant wird. Die Scheduling-Klasse definiert einen allgemeinen Satz von Funktionen (über sched_class),函数集定义调度器的行为。例如,每个调度器提供一种方式, 添加要调度的任务、调出要运行的下一个任务、提供给调度器等等。每个调度器类都在一对一连接的列表中彼此相连,使类可以迭代(例如, 要启用给定处理器的禁用)。一般结构如图 3 所示。注意,将任务函数加入队列或脱离队列只需从特定调度结构中加入或移除任务。 函数 pick_next_task, um die nächste auszuführende Aufgabe auszuwählen (abhängig von der spezifischen Strategie der Scheduling-Klasse).
Abbildung 3. Grafische Ansicht der Planung

Aber vergessen Sie nicht, dass die Scheduling-Klasse Teil der Aufgabenstruktur selbst ist (siehe Abbildung 2). Dies vereinfacht die Bedienung von Aufgaben unabhängig von ihrer Planungsklasse. Beispielsweise setzt die folgende Funktion die aktuell laufende Aufgabe (wobei curr 定义了当前运行任务, rq 代表 CFS 红黑树而 p die nächste zu planende Aufgabe ist) durch eine neue Aufgabe in ./kernel/sched.c vorweg:
static inline void check_preempt( struct rq *rq, struct task_struct *p )
{
rq->curr->sched_class->check_preempt_curr( rq, p );
}
Wenn diese Aufgabe die Fair Scheduling-Klasse verwendet, dann check_preempt_curr() 将解析为 check_preempt_wakeup(). Sie können diese Beziehungen in ./kernel/sched_rt.c, ./kernel/sched_fair.c und ./kernel/sched_idle.c anzeigen.
Scheduling-Klassen sind ein weiterer interessanter Ort, an dem sich die Terminplanung ändert, aber mit zunehmender Planungsdomäne wächst auch die Funktionalität. Mit diesen Domänen können Sie einen oder mehrere Prozessoren für Lastausgleichs- und Isolationszwecke hierarchisch gruppieren. Ein oder mehrere Prozessoren können eine Planungsrichtlinie gemeinsam nutzen (und den Lastausgleich zwischen ihnen aufrechterhalten) oder unabhängige Planungsrichtlinien implementieren, um Aufgaben absichtlich zu isolieren.
Andere Planer
Wenn Sie sich weiter mit der Planung befassen, werden Sie feststellen, dass sich in der Entwicklung befindliche Planer befinden, die die Grenzen von Leistung und Skalierbarkeit erweitern. Unbeeindruckt von seiner Linux-Erfahrung entwickelte Con Kolivas einen weiteren Linux-Scheduler, abgekürzt: BFS. Der Scheduler soll auf NUMA-Systemen und Mobilgeräten eine bessere Leistung haben und wurde in einer Ableitung des Android-Betriebssystems eingeführt.
Durch diesen Artikel sollten Sie über ein grundlegendes Verständnis von CFS verfügen. Es handelt sich um einen der fortschrittlichsten und effizientesten Prozessplanungsalgorithmen in Linux-Systemen. Er verwendet Rot-Schwarz-Bäume, um ausführbare Prozesswarteschlangen zu speichern und die virtuelle Laufzeit zu berechnen Fairness des Prozesses: Die Reaktionsgeschwindigkeit des interaktiven Prozesses wird durch die Implementierung der Wake-up-Preemption-Funktion verbessert, wodurch vollständige Fairness bei der Prozessplanung erreicht wird. Natürlich ist CFS nicht perfekt und weist einige potenzielle Probleme und Einschränkungen auf, die behoben werden müssen, z. B. eine Überkompensation aktiver Schlafprozesse, eine unzureichende Unterstützung von Echtzeitprozessen usw zukünftige Versionen. Nehmen Sie Verbesserungen und Optimierungen vor. Kurz gesagt, CFS ist eine unverzichtbare Komponente im Linux-System und verdient Ihr gründliches Studium und Ihre Beherrschung.
Das obige ist der detaillierte Inhalt vonLinux CFS: So erreichen Sie vollständige Fairness bei der Prozessplanung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1386
1386
 52
52

 So verwenden Sie Docker Desktop
Apr 15, 2025 am 11:45 AM
So verwenden Sie Docker Desktop
Apr 15, 2025 am 11:45 AM
Wie benutze ich Docker Desktop? Docker Desktop ist ein Werkzeug zum Ausführen von Docker -Containern auf lokalen Maschinen. Zu den zu verwendenden Schritten gehören: 1.. Docker Desktop installieren; 2. Start Docker Desktop; 3.. Erstellen Sie das Docker -Bild (mit Dockerfile); 4. Build Docker Image (mit Docker Build); 5. Docker -Container ausführen (mit Docker Run).
 Unterschied zwischen CentOS und Ubuntu
Apr 14, 2025 pm 09:09 PM
Unterschied zwischen CentOS und Ubuntu
Apr 14, 2025 pm 09:09 PM
Die wichtigsten Unterschiede zwischen CentOS und Ubuntu sind: Ursprung (CentOS stammt von Red Hat, für Unternehmen; Ubuntu stammt aus Debian, für Einzelpersonen), Packungsmanagement (CentOS verwendet yum, konzentriert sich auf Stabilität; Ubuntu verwendet apt, für hohe Aktualisierungsfrequenz), Support Cycle (Centos) (CENTOS bieten 10 Jahre. Tutorials und Dokumente), Verwendungen (CentOS ist auf Server voreingenommen, Ubuntu ist für Server und Desktops geeignet). Weitere Unterschiede sind die Einfachheit der Installation (CentOS ist dünn)
 Was tun, wenn das Docker -Bild fehlschlägt?
Apr 15, 2025 am 11:21 AM
Was tun, wenn das Docker -Bild fehlschlägt?
Apr 15, 2025 am 11:21 AM
Fehlerbehebung Schritte für fehlgeschlagene Docker -Bild Build: Überprüfen Sie die Dockerfile -Syntax und die Abhängigkeitsversion. Überprüfen Sie, ob der Build -Kontext den erforderlichen Quellcode und die erforderlichen Abhängigkeiten enthält. Sehen Sie sich das Build -Protokoll für Fehlerdetails an. Verwenden Sie die Option -Target -Option, um eine hierarchische Phase zu erstellen, um Fehlerpunkte zu identifizieren. Verwenden Sie die neueste Version von Docker Engine. Erstellen Sie das Bild mit--t [Bildname]: Debugg-Modus, um das Problem zu debuggen. Überprüfen Sie den Speicherplatz und stellen Sie sicher, dass dies ausreicht. Deaktivieren Sie Selinux, um eine Störung des Build -Prozesses zu verhindern. Fragen Sie Community -Plattformen um Hilfe, stellen Sie Dockerfiles an und erstellen Sie Protokollbeschreibungen für genauere Vorschläge.
 So sehen Sie den Docker -Prozess
Apr 15, 2025 am 11:48 AM
So sehen Sie den Docker -Prozess
Apr 15, 2025 am 11:48 AM
Docker Process Viewing -Methode: 1. Docker Cli -Befehl: Docker PS; 2. SYSTEMD CLI -Befehl: SystemCTL Status Docker; 3.. Docker Compose CLI Command: Docker-Compose PS; 4. Process Explorer (Windows); 5. /proc -Verzeichnis (Linux).
 So installieren Sie CentOs
Apr 14, 2025 pm 09:03 PM
So installieren Sie CentOs
Apr 14, 2025 pm 09:03 PM
CentOS -Installationsschritte: Laden Sie das ISO -Bild herunter und verbrennen Sie bootfähige Medien. Starten und wählen Sie die Installationsquelle; Wählen Sie das Layout der Sprache und Tastatur aus. Konfigurieren Sie das Netzwerk; Partition die Festplatte; Setzen Sie die Systemuhr; Erstellen Sie den Root -Benutzer; Wählen Sie das Softwarepaket aus; Starten Sie die Installation; Starten Sie nach Abschluss der Installation von der Festplatte neu und starten Sie von der Festplatte.
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 Welche Computerkonfiguration ist für VSCODE erforderlich?
Apr 15, 2025 pm 09:48 PM
Welche Computerkonfiguration ist für VSCODE erforderlich?
Apr 15, 2025 pm 09:48 PM
VS Code system requirements: Operating system: Windows 10 and above, macOS 10.12 and above, Linux distribution processor: minimum 1.6 GHz, recommended 2.0 GHz and above memory: minimum 512 MB, recommended 4 GB and above storage space: minimum 250 MB, recommended 1 GB and above other requirements: stable network connection, Xorg/Wayland (Linux)
 VSCODE kann die Erweiterung nicht installieren
Apr 15, 2025 pm 07:18 PM
VSCODE kann die Erweiterung nicht installieren
Apr 15, 2025 pm 07:18 PM
Die Gründe für die Installation von VS -Code -Erweiterungen können sein: Netzwerkinstabilität, unzureichende Berechtigungen, Systemkompatibilitätsprobleme, VS -Code -Version ist zu alt, Antiviren -Software oder Firewall -Interferenz. Durch Überprüfen von Netzwerkverbindungen, Berechtigungen, Protokolldateien, Aktualisierungen von VS -Code, Deaktivieren von Sicherheitssoftware und Neustart von Code oder Computern können Sie Probleme schrittweise beheben und beheben.
