
 System-Tutorial
LINUX
Trockenes Zeug! 9 technische Architekturen mit hoher Leistung und hoher Parallelität
System-Tutorial
LINUX
Trockenes Zeug! 9 technische Architekturen mit hoher Leistung und hoher Parallelität
Trockenes Zeug! 9 technische Architekturen mit hoher Leistung und hoher Parallelität

Layering ist das häufigste Architekturmuster in Unternehmensanwendungssystemen. Es unterteilt das System in mehrere Teile in der horizontalen Dimension. Jeder Teil ist für eine relativ einfache und einzelne Verantwortung verantwortlich und stützt sich dann auf die unteren Schichten und plant diese .bilden ein Gesamtsystem.
In der Schichtarchitektur einer Website gibt es drei gemeinsame Schichten, nämlich Anwendungsschicht, Serviceschicht und Datenschicht. Die Anwendungsschicht ist speziell für die Anzeige von Geschäftsdaten und -ansichten verantwortlich. Die Serviceschicht bietet Serviceunterstützung für die Datenbank, die Zugriffsdienste für die Datenspeicherung bereitstellt, z. B. Datenbanken, Caches, Dateien, Suchmaschinen usw.
Die geschichtete Architektur ist logisch, da die dreistufige Architektur auf derselben physischen Maschine bereitgestellt werden kann. Bei der Entwicklung des Website-Geschäfts ist es jedoch erforderlich, die bereits geschichteten Module separat bereitzustellen Da die dreistufige Struktur separat auf verschiedenen Servern bereitgestellt wird, verfügt die Website über mehr Rechenressourcen, um immer mehr Benutzerbesuche bewältigen zu können.
Obwohl der ursprüngliche Zweck des Schichtarchitekturmodells darin besteht, eine klare logische Struktur der Software zu planen, um Entwicklung und Wartung zu erleichtern, ist die Schichtstruktur im Entwicklungsprozess der Website von entscheidender Bedeutung, damit die Website die Entwicklung einer hohen Parallelität unterstützt und verteilte Richtung.
Die Website muss 7×24 Stunden lang ununterbrochen laufen, daher muss sie über einen entsprechenden Redundanzmechanismus verfügen, um zu verhindern, dass sie beim Ausfall einer bestimmten Maschine verfügbar ist. Durch Redundanz kann eine hohe Dienstverfügbarkeit erreicht werden, indem mindestens zwei Server zur Bildung eines Clusters eingesetzt werden. Neben regelmäßigen Backups muss die Datenbank auch Hot- und Cold-Backups implementieren. Disaster-Recovery-Rechenzentren können sogar weltweit eingesetzt werden.
Wenn beim Layering die horizontale Aufteilung der Software erfolgt, dann beim Partitionieren die vertikale Aufteilung der Software.
Je größer die Website, desto komplexer die Funktionen und desto mehr Arten von Diensten und Datenverarbeitung. Die Trennung dieser verschiedenen Funktionen und Dienste und deren Paketierung in modulare Einheiten mit hoher Kohäsion und geringer Kopplung wird nicht nur die Entwicklung und Wartung der Website erleichtern Software Es erleichtert auch die verteilte Bereitstellung verschiedener Module und verbessert die gleichzeitigen Verarbeitungsfähigkeiten und Funktionserweiterungsmöglichkeiten der Website.
Die Granularität der Trennung kann bei großen Websites gering sein. Auf der Anwendungsebene sind beispielsweise verschiedene Geschäftsbereiche wie Einkaufen, Foren, Suche und Werbung in verschiedene Anwendungen unterteilt. Gegensätzliche Teams sind für sie verantwortlich und werden auf verschiedenen Servern bereitgestellt.
Bei der Verwendung von Asynchronität handelt es sich bei der Nachrichtenübermittlung zwischen Unternehmen nicht um einen synchronen Aufruf, sondern um einen Geschäftsvorgang, der in mehrere Phasen unterteilt ist und jede Phase zur Zusammenarbeit durch Datenaustausch asynchron ausgeführt wird.
Die spezifische Implementierung kann innerhalb eines einzelnen Servers durch Multithread-Shared-Memory verarbeitet werden, in einem verteilten System kann eine asynchrone Implementierung durch verteilte Nachrichtenwarteschlangen erreicht werden.
Die typische asynchrone Architektur ist die Producer-Consumer-Methode, und es gibt keinen direkten Aufruf zwischen den beiden.
Bei großen Websites besteht einer der Hauptzwecke der Schichtung und Trennung darin, die verteilte Bereitstellung geteilter Module zu erleichtern, d. h. die Bereitstellung verschiedener Module auf verschiedenen Servern und die Zusammenarbeit über Remote-Aufrufe. Verteilung bedeutet, dass mehr Computer verwendet werden können, um die gleiche Arbeit zu erledigen. Je mehr Computer, desto mehr CPU-, Speicher- und Speicherressourcen und desto mehr gleichzeitige Zugriffe und Daten können verarbeitet werden, wodurch mehr Benutzer bereitgestellt werden können.
In Website-Anwendungen gibt es mehrere häufig verwendete verteilte Lösungen.
Verteilte Anwendungen und Dienste: Die verteilte Bereitstellung mehrschichtiger und getrennter Anwendungs- und Dienstmodule kann die Leistung und Parallelität der Website verbessern, die Entwicklung und Veröffentlichung beschleunigen und den Ressourcenverbrauch der Datenbankverbindung reduzieren.
Verteilte statische Ressourcen: Die statischen Ressourcen der Website, wie JS, CSS, Logobilder und andere Ressourcen, werden verteilt bereitgestellt und verwenden unabhängige Domänennamen, was oft als Trennung von statischen und dynamischen Ressourcen bezeichnet wird. Die verteilte Bereitstellung statischer Ressourcen kann den Lastdruck auf dem Anwendungsserver verringern; das gleichzeitige Laden des Browsers wird durch die Verwendung unabhängiger Domänennamen beschleunigt.
Verteilte Daten und Speicherung: Große Websites müssen riesige Datenmengen verarbeiten, gemessen in P. Ein einzelner Computer kann keinen so großen Speicherplatz bereitstellen. Diese Datenbanken erfordern verteilten Speicher.
Verteiltes Computing: Derzeit verwenden Websites für solche Batch-Berechnungen im Allgemeinen die Distributed-Computing-Frameworks Hadoop und MapReduce, die eher durch mobiles Computing als durch mobile Daten gekennzeichnet sind.
Websites verfügen über viele Modi in Bezug auf die Sicherheitsarchitektur: Die Identitätsauthentifizierung durch Passwörter und Mobiltelefon-Verifizierungscodes muss für die Anmeldung und Transaktionen verschlüsselt werden. Um zu verhindern, dass Roboter Ressourcen missbrauchen, müssen Bestätigungscodes zur Identifizierung verwendet werden. Häufige XSS-Angriffe, SQL-Injection erfordert eine Codierungskonvertierung; Spam-Informationen müssen gefiltert werden usw.
Im Einzelnen umfasst es einen automatisierten Freigabeprozess, eine automatisierte Codeverwaltung, automatisierte Tests, eine automatisierte Sicherheitserkennung, eine automatisierte Bereitstellung, eine automatisierte Überwachung, automatisierte Alarme, ein automatisiertes Failover, eine automatisierte Wiederherstellung nach Fehlern usw.
Für Module mit zentralisiertem Benutzerzugriff müssen unabhängig bereitgestellte Server geclustert werden, d. h. mehrere Server stellen dieselbe Anwendung bereit, um einen Cluster zu bilden, und stellen gemeinsam externe Dienste über Lastausgleichsgeräte bereit.
Der Servercluster kann mehr gleichzeitige Unterstützung für denselben Dienst bieten. Wenn also mehr Benutzer darauf zugreifen, müssen Sie nur neue Maschinen zum Cluster hinzufügen. Außerdem kann der Lastausgleichs-Failover-Mechanismus verwendet werden um Anfragen an andere Server im Cluster weiterzuleiten und so die Systemverfügbarkeit zu verbessern.
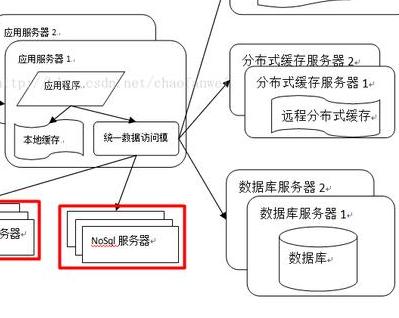
Der Zweck des Caching besteht darin, die Berechnung des Servers zu reduzieren, sodass die Daten direkt an den Benutzer zurückgegeben werden können. Im heutigen Softwaredesign ist Caching allgegenwärtig. Zu den spezifischen Implementierungen gehören CDN, Reverse-Proxy, lokaler Cache, verteilter Cache usw.
Es gibt zwei Bedingungen für die Verwendung des Caches: Unausgeglichener Zugriff auf Daten-Hotspots, d aufgrund des Datenablaufs, was sich auf die Richtigkeit der Daten auswirkt.
Das obige ist der detaillierte Inhalt vonTrockenes Zeug! 9 technische Architekturen mit hoher Leistung und hoher Parallelität. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1379
1379
 52
52

 Unterschied zwischen CentOS und Ubuntu
Apr 14, 2025 pm 09:09 PM
Unterschied zwischen CentOS und Ubuntu
Apr 14, 2025 pm 09:09 PM
Die wichtigsten Unterschiede zwischen CentOS und Ubuntu sind: Ursprung (CentOS stammt von Red Hat, für Unternehmen; Ubuntu stammt aus Debian, für Einzelpersonen), Packungsmanagement (CentOS verwendet yum, konzentriert sich auf Stabilität; Ubuntu verwendet apt, für hohe Aktualisierungsfrequenz), Support Cycle (Centos) (CENTOS bieten 10 Jahre. Tutorials und Dokumente), Verwendungen (CentOS ist auf Server voreingenommen, Ubuntu ist für Server und Desktops geeignet). Weitere Unterschiede sind die Einfachheit der Installation (CentOS ist dünn)
 So installieren Sie CentOs
Apr 14, 2025 pm 09:03 PM
So installieren Sie CentOs
Apr 14, 2025 pm 09:03 PM
CentOS -Installationsschritte: Laden Sie das ISO -Bild herunter und verbrennen Sie bootfähige Medien. Starten und wählen Sie die Installationsquelle; Wählen Sie das Layout der Sprache und Tastatur aus. Konfigurieren Sie das Netzwerk; Partition die Festplatte; Setzen Sie die Systemuhr; Erstellen Sie den Root -Benutzer; Wählen Sie das Softwarepaket aus; Starten Sie die Installation; Starten Sie nach Abschluss der Installation von der Festplatte neu und starten Sie von der Festplatte.
 CentOS stoppt die Wartung 2024
Apr 14, 2025 pm 08:39 PM
CentOS stoppt die Wartung 2024
Apr 14, 2025 pm 08:39 PM
CentOS wird 2024 geschlossen, da seine stromaufwärts gelegene Verteilung RHEL 8 geschlossen wurde. Diese Abschaltung wirkt sich auf das CentOS 8 -System aus und verhindert, dass es weiterhin Aktualisierungen erhalten. Benutzer sollten eine Migration planen, und empfohlene Optionen umfassen CentOS Stream, Almalinux und Rocky Linux, um das System sicher und stabil zu halten.
 Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Backup- und Wiederherstellungsrichtlinie von GitLab im Rahmen von CentOS -System Um die Datensicherheit und Wiederherstellung der Daten zu gewährleisten, bietet GitLab on CentOS eine Vielzahl von Sicherungsmethoden. In diesem Artikel werden mehrere gängige Sicherungsmethoden, Konfigurationsparameter und Wiederherstellungsprozesse im Detail eingeführt, um eine vollständige GitLab -Sicherungs- und Wiederherstellungsstrategie aufzubauen. 1. Manuell Backup Verwenden Sie den GitLab-RakegitLab: Backup: Befehl erstellen, um die manuelle Sicherung auszuführen. Dieser Befehl unterstützt wichtige Informationen wie GitLab Repository, Datenbank, Benutzer, Benutzergruppen, Schlüssel und Berechtigungen. Die Standardsicherungsdatei wird im Verzeichnis/var/opt/gitlab/backups gespeichert. Sie können /etc /gitlab ändern
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 So verwenden Sie Docker Desktop
Apr 15, 2025 am 11:45 AM
So verwenden Sie Docker Desktop
Apr 15, 2025 am 11:45 AM
Wie benutze ich Docker Desktop? Docker Desktop ist ein Werkzeug zum Ausführen von Docker -Containern auf lokalen Maschinen. Zu den zu verwendenden Schritten gehören: 1.. Docker Desktop installieren; 2. Start Docker Desktop; 3.. Erstellen Sie das Docker -Bild (mit Dockerfile); 4. Build Docker Image (mit Docker Build); 5. Docker -Container ausführen (mit Docker Run).
 Wie man in CentOS fester Festplatten montiert
Apr 14, 2025 pm 08:15 PM
Wie man in CentOS fester Festplatten montiert
Apr 14, 2025 pm 08:15 PM
CentOS -Festplattenhalterung ist in die folgenden Schritte unterteilt: Bestimmen Sie den Namen der Festplattengeräte (/dev/sdx); Erstellen Sie einen Mountspunkt (es wird empfohlen, /mnt /newDisk zu verwenden). Führen Sie den Befehl montage (mont /dev /sdx1 /mnt /newdisk) aus; Bearbeiten Sie die Datei /etc /fstab, um eine permanente Konfiguration des Montings hinzuzufügen. Verwenden Sie den Befehl uMount, um das Gerät zu deinstallieren, um sicherzustellen, dass kein Prozess das Gerät verwendet.
 Was zu tun ist, nachdem CentOS die Wartung gestoppt hat
Apr 14, 2025 pm 08:48 PM
Was zu tun ist, nachdem CentOS die Wartung gestoppt hat
Apr 14, 2025 pm 08:48 PM
Nachdem CentOS gestoppt wurde, können Benutzer die folgenden Maßnahmen ergreifen, um sich damit zu befassen: Wählen Sie eine kompatible Verteilung aus: wie Almalinux, Rocky Linux und CentOS Stream. Migrieren Sie auf kommerzielle Verteilungen: wie Red Hat Enterprise Linux, Oracle Linux. Upgrade auf CentOS 9 Stream: Rolling Distribution und bietet die neueste Technologie. Wählen Sie andere Linux -Verteilungen aus: wie Ubuntu, Debian. Bewerten Sie andere Optionen wie Container, virtuelle Maschinen oder Cloud -Plattformen.
