

MySQL ist eine häufig verwendete Datenbank in Projekten und wird auch sehr häufig in Abfragen verwendet. Beim letzten Debuggen des Projekts bin ich auf eine unerwartete Auswahlabfrage gestoßen, die tatsächlich 33 Sekunden dauerte!
1. Benutzerinfotabelle

2. Artikeltabelle
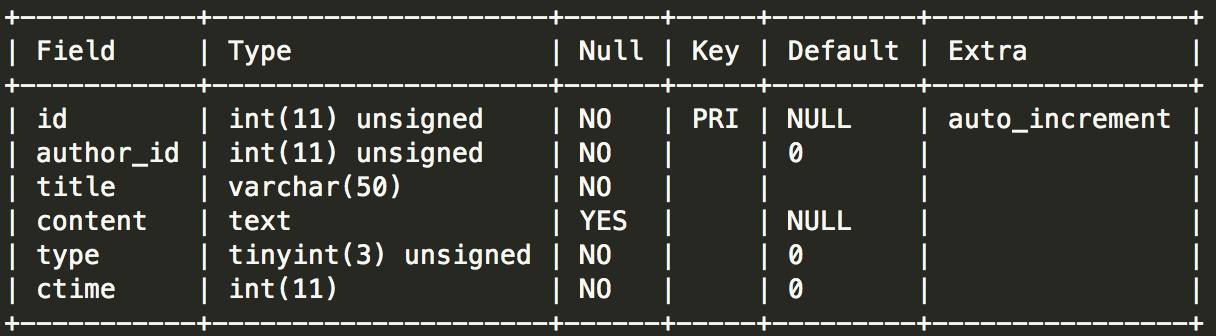
select*fromuserinfowhereidin(selectauthor_idfromartilcewheretype=1);
Wenn Sie das obige SQL zum ersten Mal sehen, denken Sie vielleicht, dass es sich um eine sehr einfache Unterabfrage handelt. Ermitteln Sie zuerst die Autor_ID und fragen Sie sie dann mit in ab.
Wenn ein relevanter Index vorhanden ist, erfolgt die Demontage wie folgt:
1.selectauthor_idfromartilcewheretype=1; 2.select*fromuserinfowhereidin(1,2,3);
Aber Fakt ist:
mysql> select count(*) from userinfo;
mysql> select count(*) from article;

mysql> select id,username from userinfo where id in (select author_id from article where type = 1);

33 Sekunden! Warum ist es so langsam?
Offizielle Dokumenterklärung: Die in-Klausel wird bei Abfragen manchmal in „exists“ konvertiert und Datensatz für Datensatz durchlaufen (vorhanden in Version 5.5, optimiert in 5.6).

Referenz:
https://dev.mysql.com/doc/refman/5.5/en/subquery-optimization.html
1. Verwenden Sie eine temporäre Tabelle
select id,username from userinfo where id in (select author_id from (select author_id from article where type = 1) as tb);
2. Verwenden Sie Join
select a.id,a.username from userinfo a, article b where a.id = b.author_id and b.type = 1;
Version 5.6 wurde für Unterabfragen auf die gleiche Weise optimiert wie die temporäre Tabelle in [4]. Bitte beachten Sie die offizielle Dokumentation:
Wenn keine Materialisierung verwendet wird, schreibt der Optimierer manchmal eine nicht korrelierte Unterabfrage in eine korrelierte Unterabfrage um.
Zum Beispiel ist die folgende IN-Unterabfrage nicht korreliert (wobei_bedingung nur Spalten von t2 und nicht von t1 betrifft):
wählen Sie * aus t1
where t1.a in (wählen Sie t2.b aus t2 where where_condition aus);
Der Optimierer könnte dies als EXISTS-korrelierte Unterabfrage umschreiben:
wählen Sie * aus t1
wo existiert (wählen Sie t2.b aus t2 aus, wobei where_condition und t1.a=t2.b);
Die Materialisierung von Unterabfragen die Verwendung einer temporären Tabelle vermeidet solche Umschreibungen und ermöglicht es, die Unterabfrage nur einmal und nicht einmal pro Zeile der äußeren Abfrage auszuführen.
https://dev.mysql.com/doc/refman/5.6/en/subquery-materialization.html
Der Artikel stammt aus dem öffentlichen WeChat-Konto: HULK technische Gespräche an vorderster Front
Das obige ist der detaillierte Inhalt vonDenken Sie daran, in der Unterabfrage auf die „Grube' von MySQL zu treten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



