
 System-Tutorial
LINUX
Lassen Sie mich gehen, die CPU des Linux-Systems ist zu 100 % ausgelastet!
System-Tutorial
LINUX
Lassen Sie mich gehen, die CPU des Linux-Systems ist zu 100 % ausgelastet!
Lassen Sie mich gehen, die CPU des Linux-Systems ist zu 100 % ausgelastet!

Gestern Nachmittag erhielt ich plötzlich eine E-Mail-Benachrichtigung von der Betriebs- und Wartungsabteilung, die zeigte, dass die CPU-Auslastung des Datenplattformservers bis zu 98,94 % betrug. In jüngster Zeit liegt dieser Auslastungsgrad weiterhin über 70 %. Auf den ersten Blick scheint es, dass die Hardware-Ressourcen einen Engpass erreicht haben und erweitert werden müssen. Aber nachdem ich sorgfältig darüber nachgedacht hatte, stellte ich fest, dass unser Geschäftssystem keine hochgradig gleichzeitige oder CPU-intensive Anwendung ist. Diese Auslastung ist zu hoch und der Hardware-Engpass kann nicht so schnell erreicht werden. Irgendwo muss ein Problem mit der Geschäftscodelogik vorliegen.
2. Ideen zur Fehlerbehebung
2.1 Prozess-PID mit hoher Auslastung ermitteln
Melden Sie sich zuerst beim Server an und verwenden Sie den oberen Befehl, um die spezifische Situation des Servers zu bestätigen, und analysieren und beurteilen Sie dann anhand der spezifischen Situation.

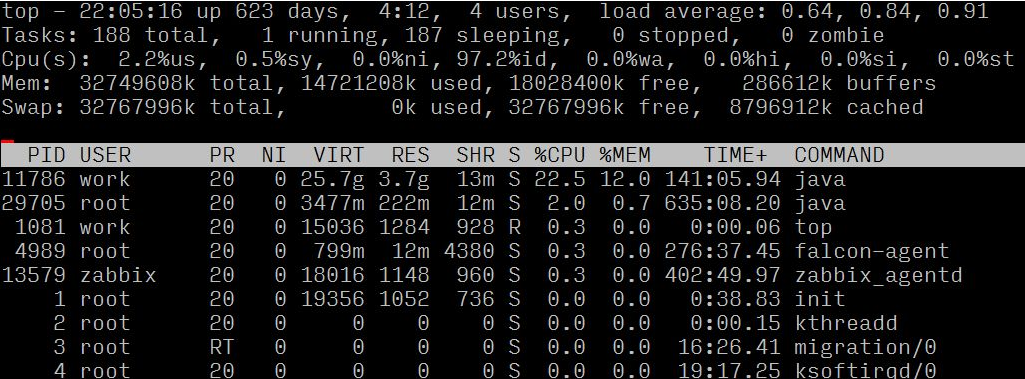
Durch Beobachtung des Lastdurchschnitts und des Lastbewertungsstandards (8 Kerne) kann bestätigt werden, dass der Server eine hohe Last hat
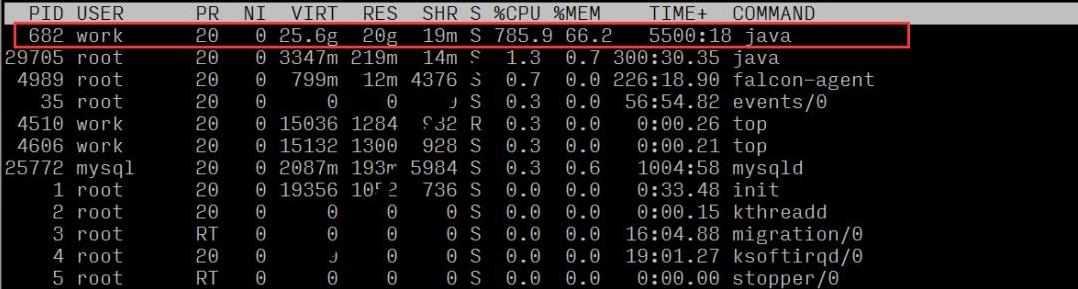
Wenn wir die Ressourcennutzung jedes Prozesses beobachten, können wir sehen, dass der Prozess mit der Prozess-ID 682 ein höheres CPU-Verhältnis aufweist
2.2 Lokalisieren Sie bestimmte ungewöhnliche Geschäfte
Hier können wir den Befehl pwdx verwenden, um den Geschäftsprozesspfad basierend auf der PID zu finden und dann die verantwortliche Person und das Projekt zu lokalisieren:

Daraus lässt sich schließen, dass dieser Prozess dem Webservice der Datenplattform entspricht.
2.3 Suchen Sie den abnormalen Thread und bestimmte Codezeilen
Die traditionelle Lösung besteht im Allgemeinen aus 4 Schritten:
1. Top-Reihenfolge mit P: 1040 // Zuerst nach Prozesslast sortieren, um maxLoad(pid) zu finden
2. top -Hp-Prozess-PID: 1073 // Finden Sie die relevante Last-Thread-PID
3. printf „0x%x“ Thread-PID: 0x431 // Konvertieren Sie die Thread-PID in Hexadezimalzahl, um die spätere Suche im Jstack-Protokoll vorzubereiten
4. jstack-Prozess-PID |. vim +/hex Thread-PID – // Zum Beispiel: jstack 1040|vim +/0x431 –
Aber für die Online-Problemlokalisierung zählt jede Sekunde, und die oben genannten 4 Schritte sind immer noch zu umständlich und zeitaufwändig. Oldratlee, der Taobao zuvor eingeführt hat, hat den obigen Prozess in einem Tool zusammengefasst: show-busy-java-threads.sh. Sie können diese Art von Problem ganz einfach online finden:
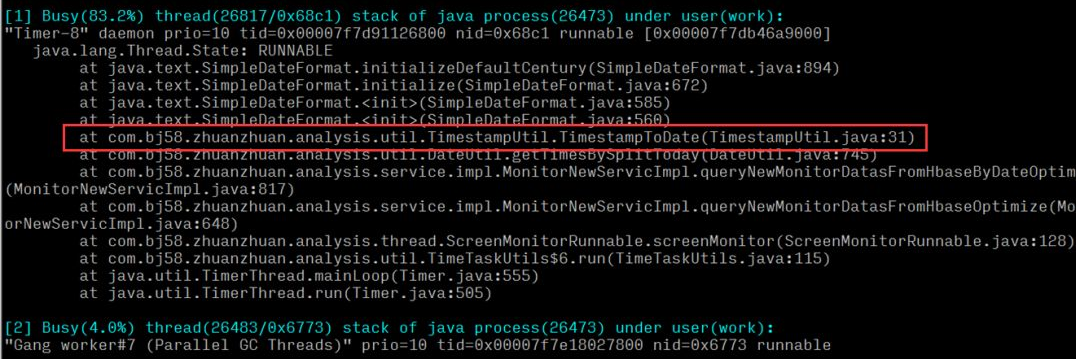
Daraus kann geschlossen werden, dass die Ausführungs-CPU einer Zeitwerkzeugmethode im System relativ hoch ist. Überprüfen Sie nach dem Auffinden der spezifischen Methode, ob Leistungsprobleme in der Codelogik vorliegen.
※ Wenn das Online-Problem dringender ist, können Sie 2.1 und 2.2 weglassen und 2.3 direkt ausführen. Die Analyse erfolgt hier aus mehreren Blickwinkeln, um Ihnen eine vollständige Analyseidee zu präsentieren.
3. Ursachenanalyse
Nach der vorherigen Analyse und Fehlerbehebung haben wir schließlich ein Problem mit den Zeittools gefunden, das zu einer übermäßigen Serverlast und CPU-Auslastung führte.
- Ausnahmemethodenlogik: besteht darin, den Zeitstempel in das entsprechende spezifische Datums- und Uhrzeitformat umzuwandeln
- Aufruf der oberen Ebene: Berechnen Sie alle Sekunden vom frühen Morgen bis zur aktuellen Zeit, konvertieren Sie sie in das entsprechende Format und fügen Sie sie in den Satz ein, um das Ergebnis zurückzugeben
- Logikschicht: Entspricht der Abfragelogik des Echtzeitberichts der Datenplattform. Der Echtzeitbericht erfolgt in einem festen Zeitintervall und es gibt mehrere (n) Methodenaufrufe in einer Abfrage.
Dann kann gefolgert werden, dass, wenn die aktuelle Zeit 10 Uhr morgens ist, die Anzahl der Berechnungen für eine Abfrage 106060n Mal = 36.000n Berechnungen beträgt und dass die Anzahl mit zunehmender Zeit zunimmt Anzahl einzelner Abfragen nähert sich Mitternacht und nimmt linear zu. Da eine große Anzahl von Abfrageanforderungen von Modulen wie Echtzeitabfragen und Echtzeitalarmen den mehrmaligen Aufruf dieser Methode erfordern, werden große Mengen an CPU-Ressourcen belegt und verschwendet.
4. Lösung
Nachdem das Problem lokalisiert wurde, besteht die erste Überlegung darin, die Anzahl der Berechnungen zu reduzieren und die Ausnahmemethode zu optimieren. Nach einer Untersuchung wurde festgestellt, dass bei Verwendung auf der Logikebene nicht der Inhalt der von dieser Methode zurückgegebenen Mengensammlung verwendet wurde, sondern einfach der Größenwert der Menge verwendet wurde. Verwenden Sie nach Bestätigung der Logik eine neue Methode, um die Berechnung zu vereinfachen (aktuelle Sekunden - Sekunden am frühen Morgen des Tages), ersetzen Sie die aufgerufene Methode und lösen Sie das Problem übermäßiger Berechnungen. Nachdem wir online gegangen waren, beobachteten wir, dass die Serverlast und die CPU-Auslastung im Vergleich zum ungewöhnlichen Zeitraum um das 30-fache zurückgingen. Zu diesem Zeitpunkt wurde das Problem behoben.

Durch Beobachtung des Lastdurchschnitts und des Lastbewertungsstandards (8 Kerne) kann bestätigt werden, dass der Server eine hohe Last hat
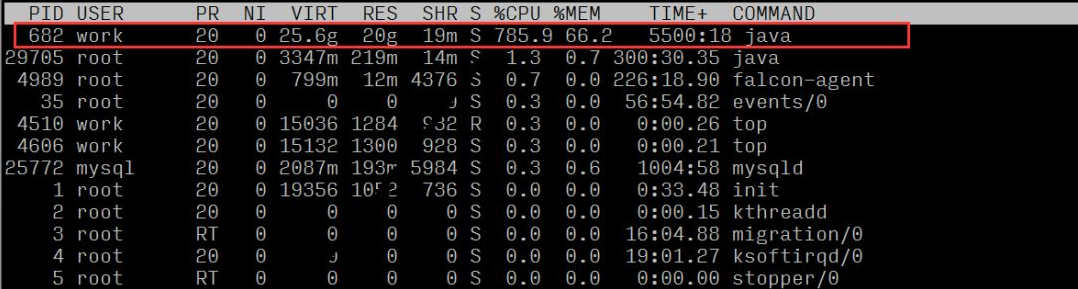
Wenn wir die Ressourcennutzung jedes Prozesses beobachten, können wir sehen, dass der Prozess mit der Prozess-ID 682 ein höheres CPU-Verhältnis aufweist
2.2 Lokalisieren Sie bestimmte ungewöhnliche Geschäfte
Hier können wir den Befehl pwdx verwenden, um den Geschäftsprozesspfad basierend auf der PID zu finden und dann die verantwortliche Person und das Projekt zu lokalisieren:

Daraus lässt sich schließen, dass dieser Prozess dem Webservice der Datenplattform entspricht.
2.3 Suchen Sie den abnormalen Thread und bestimmte Codezeilen
Die traditionelle Lösung besteht im Allgemeinen aus 4 Schritten:
1. Top-Reihenfolge mit P: 1040 // Zuerst nach Prozesslast sortieren, um maxLoad(pid) zu finden
2. top -Hp-Prozess-PID: 1073 // Finden Sie die relevante Last-Thread-PID
3. printf „0x%x“ Thread-PID: 0x431 // Konvertieren Sie die Thread-PID in Hexadezimalzahl, um die spätere Suche im Jstack-Protokoll vorzubereiten
4. jstack-Prozess-PID |. vim +/hex Thread-PID – // Zum Beispiel: jstack 1040|vim +/0x431 –
Aber für die Online-Problemlokalisierung zählt jede Sekunde, und die oben genannten 4 Schritte sind immer noch zu umständlich und zeitaufwändig. Oldratlee, der Taobao zuvor eingeführt hat, hat den obigen Prozess in einem Tool zusammengefasst: show-busy-java-threads.sh. Sie können diese Art von Problem ganz einfach online finden:
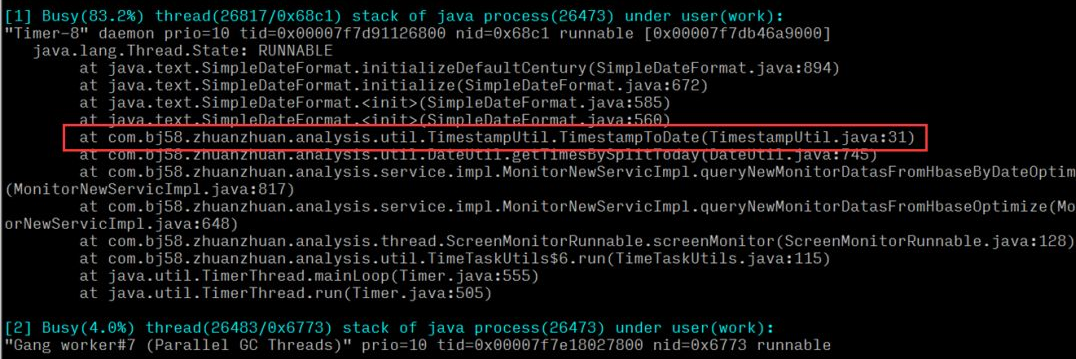
Daraus kann geschlossen werden, dass die Ausführungs-CPU einer Zeitwerkzeugmethode im System relativ hoch ist. Überprüfen Sie nach dem Auffinden der spezifischen Methode, ob Leistungsprobleme in der Codelogik vorliegen.
※ Wenn das Online-Problem dringender ist, können Sie 2.1 und 2.2 weglassen und 2.3 direkt ausführen. Die Analyse erfolgt hier aus mehreren Blickwinkeln, um Ihnen eine vollständige Analyseidee zu präsentieren.
3. Ursachenanalyse
Nach der vorherigen Analyse und Fehlerbehebung haben wir schließlich ein Problem mit den Zeittools gefunden, das zu einer übermäßigen Serverlast und CPU-Auslastung führte.
- Ausnahmemethodenlogik: besteht darin, den Zeitstempel in das entsprechende spezifische Datums- und Uhrzeitformat umzuwandeln
- Aufruf der oberen Ebene: Berechnen Sie alle Sekunden vom frühen Morgen bis zur aktuellen Zeit, konvertieren Sie sie in das entsprechende Format und fügen Sie sie in den Satz ein, um das Ergebnis zurückzugeben
- Logikschicht: Entspricht der Abfragelogik des Echtzeitberichts der Datenplattform. Der Echtzeitbericht erfolgt in einem festen Zeitintervall und es gibt mehrere (n) Methodenaufrufe in einer Abfrage.
Dann kann gefolgert werden, dass, wenn die aktuelle Zeit 10 Uhr morgens ist, die Anzahl der Berechnungen für eine Abfrage 106060n Mal = 36.000n Berechnungen beträgt und dass die Anzahl mit zunehmender Zeit zunimmt Anzahl einzelner Abfragen nähert sich Mitternacht und nimmt linear zu. Da eine große Anzahl von Abfrageanforderungen von Modulen wie Echtzeitabfragen und Echtzeitalarmen den mehrmaligen Aufruf dieser Methode erfordern, werden große Mengen an CPU-Ressourcen belegt und verschwendet.
4. Lösung
Nachdem das Problem lokalisiert wurde, besteht die erste Überlegung darin, die Anzahl der Berechnungen zu reduzieren und die Ausnahmemethode zu optimieren. Nach einer Untersuchung wurde festgestellt, dass bei Verwendung auf der Logikebene nicht der Inhalt der von dieser Methode zurückgegebenen Mengensammlung verwendet wurde, sondern einfach der Größenwert der Menge verwendet wurde. Verwenden Sie nach Bestätigung der Logik eine neue Methode, um die Berechnung zu vereinfachen (aktuelle Sekunden - Sekunden am frühen Morgen des Tages), ersetzen Sie die aufgerufene Methode und lösen Sie das Problem übermäßiger Berechnungen. Nachdem wir online gegangen waren, beobachteten wir, dass die Serverlast und die CPU-Auslastung im Vergleich zum ungewöhnlichen Zeitraum um das 30-fache zurückgingen. Zu diesem Zeitpunkt wurde das Problem behoben.
5. Zusammenfassung
- Während des Codierungsprozesses müssen wir uns neben der Implementierung der Geschäftslogik auch auf die Optimierung der Codeleistung konzentrieren. Die Fähigkeit, eine Geschäftsanforderung zu realisieren, und die Fähigkeit, diese effizienter und eleganter zu erreichen, sind eigentlich zwei völlig unterschiedliche Ausdrucksformen der Fähigkeiten und Bereiche von Ingenieuren, und letzteres ist auch die zentrale Wettbewerbsfähigkeit von Ingenieuren.
- Führen Sie nach dem Schreiben des Codes weitere Überprüfungen durch und überlegen Sie, ob er besser implementiert werden kann.
- Verpassen Sie bei Online-Fragen kein kleines Detail! Details sind der Teufel. Technische Studenten müssen den Wissensdurst und den Geist des Strebens nach Exzellenz haben. Nur so können sie weiter wachsen und sich verbessern.
Das obige ist der detaillierte Inhalt vonLassen Sie mich gehen, die CPU des Linux-Systems ist zu 100 % ausgelastet!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
52

 Welche Computerkonfiguration ist für VSCODE erforderlich?
Apr 15, 2025 pm 09:48 PM
Welche Computerkonfiguration ist für VSCODE erforderlich?
Apr 15, 2025 pm 09:48 PM
VS Code system requirements: Operating system: Windows 10 and above, macOS 10.12 and above, Linux distribution processor: minimum 1.6 GHz, recommended 2.0 GHz and above memory: minimum 512 MB, recommended 4 GB and above storage space: minimum 250 MB, recommended 1 GB and above other requirements: stable network connection, Xorg/Wayland (Linux)
 VSCODE kann die Erweiterung nicht installieren
Apr 15, 2025 pm 07:18 PM
VSCODE kann die Erweiterung nicht installieren
Apr 15, 2025 pm 07:18 PM
Die Gründe für die Installation von VS -Code -Erweiterungen können sein: Netzwerkinstabilität, unzureichende Berechtigungen, Systemkompatibilitätsprobleme, VS -Code -Version ist zu alt, Antiviren -Software oder Firewall -Interferenz. Durch Überprüfen von Netzwerkverbindungen, Berechtigungen, Protokolldateien, Aktualisierungen von VS -Code, Deaktivieren von Sicherheitssoftware und Neustart von Code oder Computern können Sie Probleme schrittweise beheben und beheben.
 Kann VSCODE für MAC verwendet werden
Apr 15, 2025 pm 07:36 PM
Kann VSCODE für MAC verwendet werden
Apr 15, 2025 pm 07:36 PM
VS -Code ist auf Mac verfügbar. Es verfügt über leistungsstarke Erweiterungen, GIT -Integration, Terminal und Debugger und bietet auch eine Fülle von Setup -Optionen. Für besonders große Projekte oder hoch berufliche Entwicklung kann VS -Code jedoch Leistung oder funktionale Einschränkungen aufweisen.
 Wofür ist VSCODE Wofür ist VSCODE?
Apr 15, 2025 pm 06:45 PM
Wofür ist VSCODE Wofür ist VSCODE?
Apr 15, 2025 pm 06:45 PM
VS Code ist der vollständige Name Visual Studio Code, der eine kostenlose und open-Source-plattformübergreifende Code-Editor und Entwicklungsumgebung von Microsoft ist. Es unterstützt eine breite Palette von Programmiersprachen und bietet Syntax -Hervorhebung, automatische Codebettel, Code -Snippets und intelligente Eingabeaufforderungen zur Verbesserung der Entwicklungseffizienz. Durch ein reiches Erweiterungs -Ökosystem können Benutzer bestimmte Bedürfnisse und Sprachen wie Debugger, Code -Formatierungs -Tools und Git -Integrationen erweitern. VS -Code enthält auch einen intuitiven Debugger, mit dem Fehler in Ihrem Code schnell gefunden und behoben werden können.
 So verwenden Sie VSCODE
Apr 15, 2025 pm 11:21 PM
So verwenden Sie VSCODE
Apr 15, 2025 pm 11:21 PM
Visual Studio Code (VSCODE) ist ein plattformübergreifender, Open-Source-Editor und kostenloser Code-Editor, der von Microsoft entwickelt wurde. Es ist bekannt für seine leichte, Skalierbarkeit und Unterstützung für eine Vielzahl von Programmiersprachen. Um VSCODE zu installieren, besuchen Sie bitte die offizielle Website, um das Installateur herunterzuladen und auszuführen. Bei der Verwendung von VSCODE können Sie neue Projekte erstellen, Code bearbeiten, Code bearbeiten, Projekte navigieren, VSCODE erweitern und Einstellungen verwalten. VSCODE ist für Windows, MacOS und Linux verfügbar, unterstützt mehrere Programmiersprachen und bietet verschiedene Erweiterungen über den Marktplatz. Zu den Vorteilen zählen leicht, Skalierbarkeit, umfangreiche Sprachunterstützung, umfangreiche Funktionen und Versionen
 So führen Sie Java -Code in Notepad aus
Apr 16, 2025 pm 07:39 PM
So führen Sie Java -Code in Notepad aus
Apr 16, 2025 pm 07:39 PM
Obwohl Notepad den Java -Code nicht direkt ausführen kann, kann er durch Verwendung anderer Tools erreicht werden: Verwenden des Befehlszeilencompilers (JAVAC), um eine Bytecode -Datei (Dateiname.class) zu generieren. Verwenden Sie den Java Interpreter (Java), um Bytecode zu interpretieren, den Code auszuführen und das Ergebnis auszugeben.
 Was ist der Hauptzweck von Linux?
Apr 16, 2025 am 12:19 AM
Was ist der Hauptzweck von Linux?
Apr 16, 2025 am 12:19 AM
Zu den Hauptanwendungen von Linux gehören: 1. Server -Betriebssystem, 2. Eingebettes System, 3. Desktop -Betriebssystem, 4. Entwicklungs- und Testumgebung. Linux zeichnet sich in diesen Bereichen aus und bietet Stabilität, Sicherheits- und effiziente Entwicklungstools.
 So überprüfen Sie die Lageradresse von Git
Apr 17, 2025 pm 01:54 PM
So überprüfen Sie die Lageradresse von Git
Apr 17, 2025 pm 01:54 PM
Um die Git -Repository -Adresse anzuzeigen, führen Sie die folgenden Schritte aus: 1. Öffnen Sie die Befehlszeile und navigieren Sie zum Repository -Verzeichnis; 2. Führen Sie den Befehl "git remote -v" aus; 3.. Zeigen Sie den Repository -Namen in der Ausgabe und der entsprechenden Adresse an.
