

Als Grundlage aller Programme hat das Betriebssystem einen wichtigen Einfluss auf die Leistung von Anwendungen. Allerdings sind die Geschwindigkeitsunterschiede zwischen den verschiedenen Komponenten eines Computers sehr groß. Beispielsweise ist der Geschwindigkeitsunterschied zwischen einer CPU und einer Festplatte größer als der Geschwindigkeitsunterschied zwischen einem Kaninchen und einer Schildkröte.
Im Folgenden stellen wir kurz die Grundlagen von CPU, Speicher und E/A vor und stellen einige Befehle vor, um deren Leistung zu bewerten.
Stellen Sie zunächst die wichtigste Computerkomponente im Computer vor: die Zentraleinheit. Im Allgemeinen können wir seine Leistung über den oberen Befehl beobachten.
top命令可用于观测CPU的一些运行指标。如图,进入top命令之后,按1, um den detaillierten Status jeder Kern-CPU anzuzeigen.
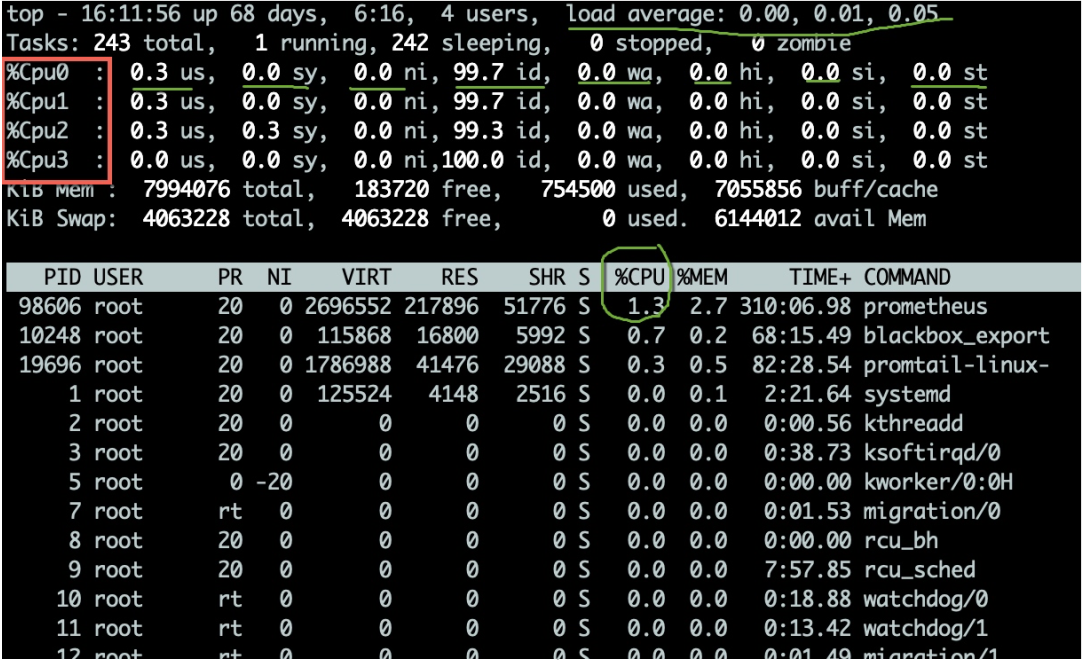
Die CPU-Auslastung weist mehrere Indikatoren auf, die im Folgenden erläutert werden:
Im Allgemeinen achten wir mehr auf den Prozentsatz der CPU im Leerlauf, der die gesamte CPU-Auslastung widerspiegeln kann.
Wir müssen auch die Warteschlangensituation bei der Ausführung von CPU-Aufgaben bewerten. Diese Werte sind 负载(Last). Die vom oberen Befehl angezeigte CPU-Auslastung entspricht den Werten der letzten 1 Minute, 5 Minuten bzw. 15 Minuten.
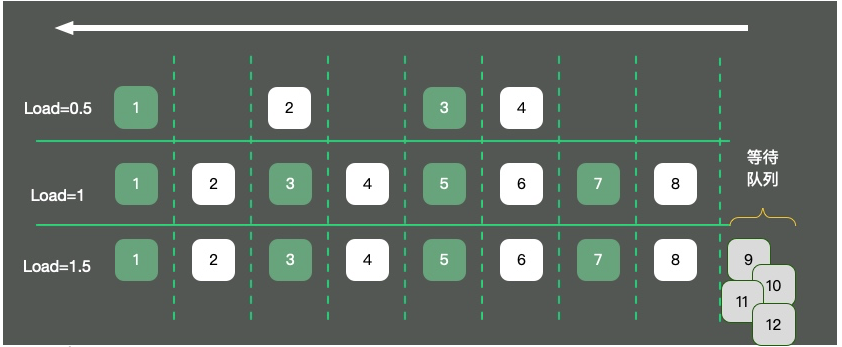
Wie in der Abbildung gezeigt, werden die CPU-Ressourcen am Beispiel eines Single-Core-Betriebssystems in eine Einbahnstraße abstrahiert. Es treten drei Situationen auf:
4 Autos auf der Straße, der Verkehr ist ruhig und die Belastung beträgt etwa 0,5. Was bedeutet Ladung 1? Es gibt immer noch viele Missverständnisse zu diesem Thema.
Viele Studenten glauben, dass das System einen Engpass erreicht, wenn die Last 1 erreicht. Das ist nicht ganz richtig. Der Wert der Auslastung hängt eng mit der Anzahl der CPU-Kerne zusammen. Beispiele sind wie folgt:
Für eine 16-Kern-Maschine mit einer Auslastung von 10 ist Ihr System also noch lange nicht am Auslastungslimit. Über den Uptime-Befehl können Sie auch den Ladestatus sehen.
Um zu sehen, wie ausgelastet die CPU ist, können Sie auch den Befehl vmstat verwenden. Im Folgenden finden Sie einige Ausgabeinformationen des Befehls vmstat.
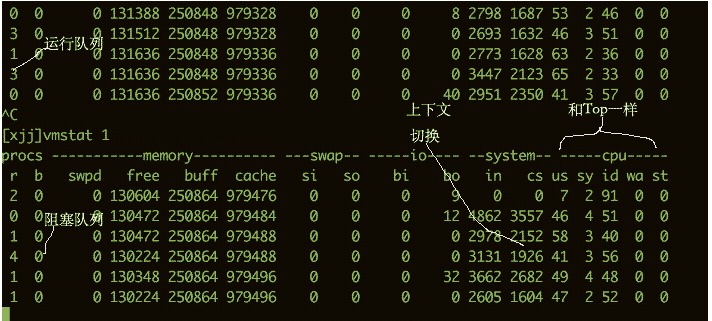
Die folgenden Spalten machen uns mehr Sorgen:
b Die Anzahl der Kernel-Threads, die in der Warteschlange vorhanden sind, z. B. beim Warten auf E/A usw. Wenn die Zahl zu groß ist, ist die CPU zu beschäftigt. cs stellt die Anzahl der Kontextwechsel dar. Wenn häufig Kontextwechsel durchgeführt werden, müssen Sie überlegen, ob die Anzahl der Threads zu hoch ist. si/so Zeigt, dass die Verwendung von Swap-Partitionen einen größeren Einfluss auf die Leistung hat und besondere Aufmerksamkeit erfordert. $ vmstat 1 procs ---------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 34 0 0 200889792 73708 591828 0 0 0 5 6 10 96 1 3 0 0 32 0 0 200889920 73708 591860 0 0 0 592 13284 4282 98 1 1 0 0 32 0 0 200890112 73708 591860 0 0 0 0 9501 2154 99 1 0 0 0 32 0 0 200889568 73712 591856 0 0 0 48 11900 2459 99 0 0 0 0 32 0 0 200890208 73712 591860 0 0 0 0 15898 4840 98 1 1 0 0 ^C
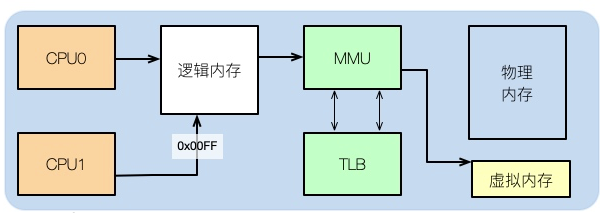
Um die Auswirkungen des Arbeitsspeichers auf die Leistung zu verstehen, müssen Sie sich die Verteilung des Arbeitsspeichers auf Betriebssystemebene ansehen.
Nachdem wir mit dem Schreiben des Codes fertig sind, wenn wir beispielsweise ein C++-Programm schreiben und dessen Assembly betrachten, können wir erkennen, dass die darin enthaltene Speicheradresse nicht die tatsächliche physische Speicheradresse ist.
Dann nutzt die Anwendung das logische Gedächtnis. Das wissen alle Studenten, die sich mit der Struktur von Computern beschäftigt haben.
Logische Adressen können dem physischen Speicher und dem virtuellen Speicher zugeordnet werden. Wenn Ihr physischer Speicher beispielsweise 8 GB groß ist und eine 16 GB große SWAP-Partition zugewiesen ist, beträgt der für die Anwendung verfügbare Gesamtspeicher 24 GB.
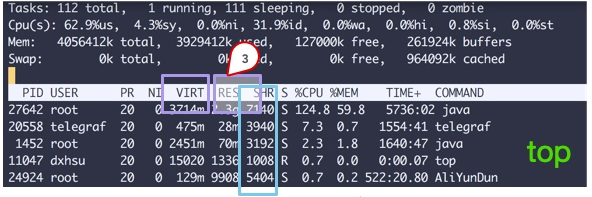
Sie können mehrere Datenspalten im oberen Befehl sehen. Achten Sie auf die drei von den Quadraten eingeschlossenen Bereiche. Die Erklärung lautet wie folgt:
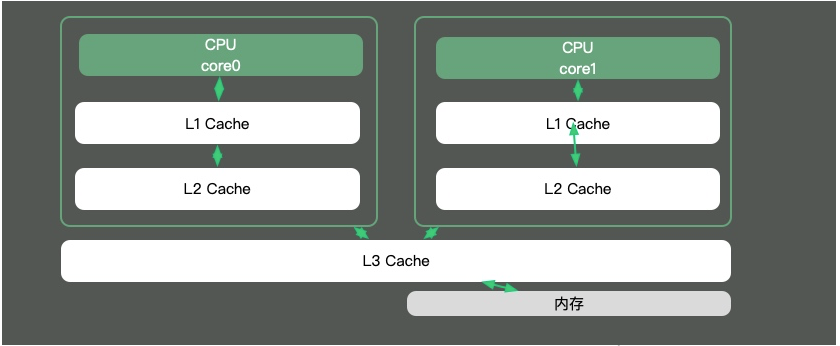
Da der Geschwindigkeitsunterschied zwischen CPU-Kernen und Speicher sehr groß ist, besteht die Lösung darin, Cache hinzuzufügen. Tatsächlich bestehen diese Caches häufig aus mehreren Ebenen, wie in der folgenden Abbildung dargestellt.
Die meisten Wissenspunkte in Java beziehen sich auf Multithreading. Das liegt daran, dass es Synchronisationsprobleme gibt, wenn sich die Zeitscheibe eines Threads über mehrere CPUs erstreckt.
在Java中,最典型的和CPU缓存相关的知识点,就是并发编程中,针对Cache line的伪共享(false sharing)问题。
伪共享是指:在这些高速缓存中,是以缓存行为单位进行存储的。哪怕你修改了缓存行中一个很小很小的数据,它都会整个的刷新。所以,当多线程修改一些变量的值时,如果这些变量在同一个缓存行里,就会造成频繁刷新,无意中影响彼此的性能。
通过以下命令即可看到当前操作系统的缓存行大小。
cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
通过以下命令可以看到不同层次的缓存大小。
[root@localhost ~]# cat /sys/devices/system/cpu/cpu0/cache/index1/size 32K [root@localhost ~]# cat /sys/devices/system/cpu/cpu0/cache/index2/size 256K [root@localhost ~]# cat /sys/devices/system/cpu/cpu0/cache/index3/size 20480K
在JDK8以上的版本,通过开启参数-XX:-RestrictContended,就可以使用注解@sun.misc.Contended进行补齐,来避免伪共享的问题。在并发优化中,我们再详细讲解。
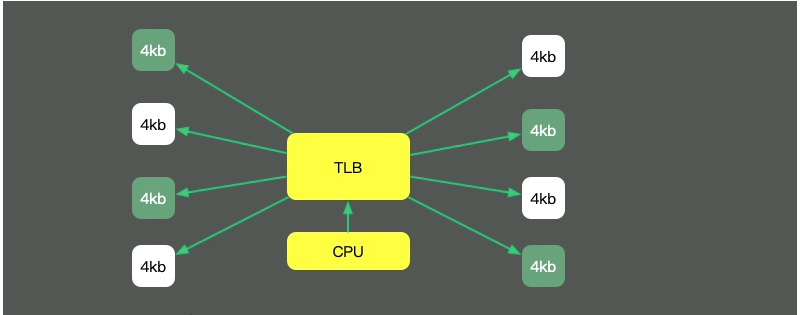
回头看我们最长的那副图,上面有一个叫做TLB的组件,它的速度虽然高,但容量也是有限的。这就意味着,如果物理内存很大,那么映射表的条目将会非常多,会影响CPU的检索效率。
默认内存是以4K的page来管理的。如图,为了减少映射表的条目,可采取的办法只有增加页的尺寸。像这种将Page Size加大的技术,就是Huge Page。
HugePage有一些副作用,比如竞争加剧,Redis还有专门的研究(https://redis.io/topics/latency) ,但在一些大内存的机器上,开启后会一定程度上增加性能。
另外,一些程序的默认行为,也会对性能有所影响。比如JVM的-XX:+AlwaysPreTouch参数。默认情况下,JVM虽然配置了Xmx、Xms等参数,但它的内存在真正用到时,才会分配。
但如果加上这个参数,JVM就会在启动的时候,把所有的内存预先分配。这样,启动时虽然慢了些,但运行时的性能会增加。
I/O设备可能是计算机里速度最差的组件了。它指的不仅仅是硬盘,还包括外围的所有设备。
硬盘有多慢呢?我们不去探究不同设备的实现细节,直接看它的写入速度(数据未经过严格测试,仅作参考)。
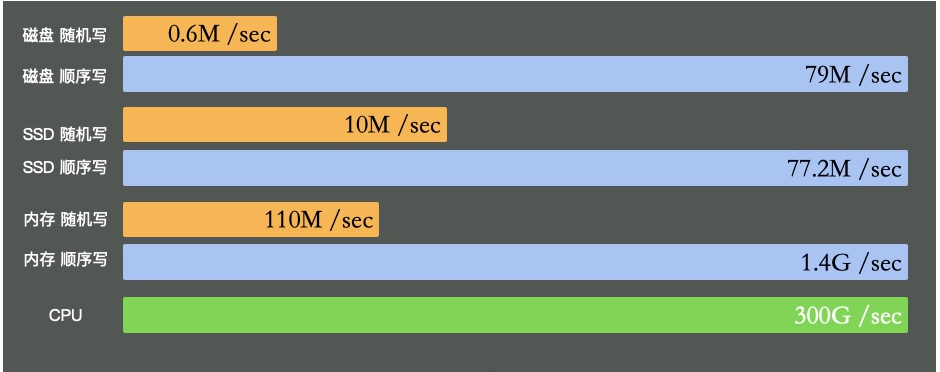
可以看到普通磁盘的随机写和顺序写相差是非常大的。而随机写完全和cpu内存不在一个数量级。
缓冲区依然是解决速度差异的唯一工具,在极端情况比如断电等,就产生了太多的不确定性。这些缓冲区,都容易丢。
Der beste Weg, die Geschäftigkeit von I/O widerzuspiegeln, ist der obere Befehl und vmstat命令中的wa%. Wenn Ihre Anwendung viele Protokolle schreibt, kann die E/A-Wartezeit sehr hoch sein.
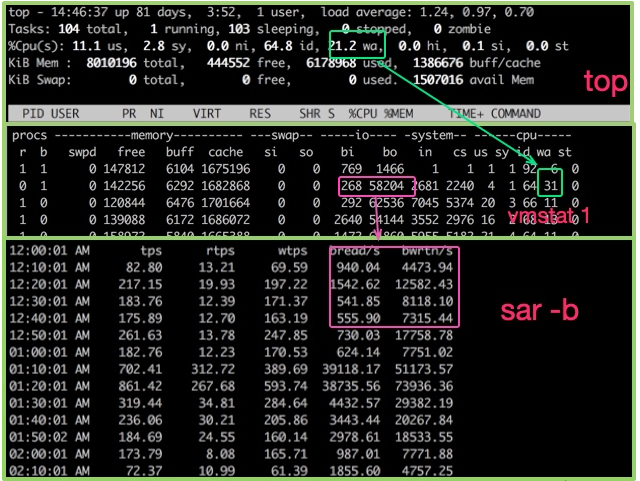
Für Festplatten können Sie den Befehl iostat verwenden, um die spezifische Hardwarenutzung anzuzeigen. Solange %util 80 % überschreitet, ist Ihr System grundsätzlich nicht lauffähig.
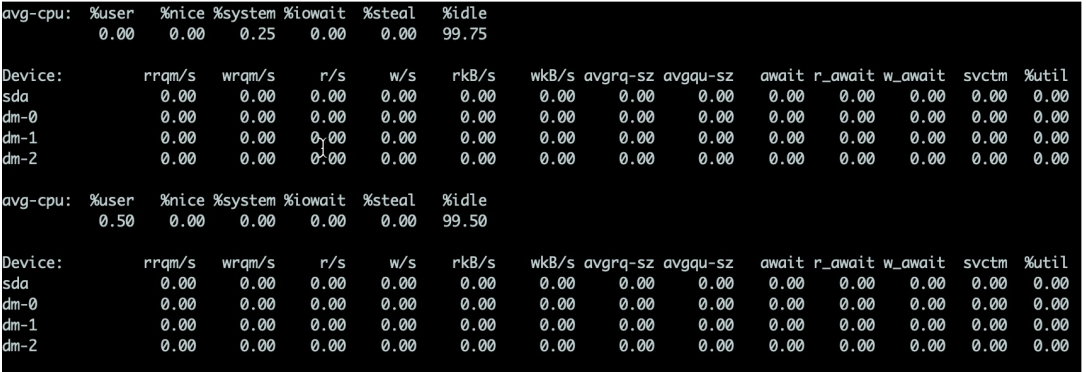
Details sind wie folgt:
I/O操作的服务时间。如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,如果await的值远高于svctm的值,则表示I/O zu lang ist und auf dem System ausgeführte Anwendungen langsamer werden. Ein Grund, warum Kafka schneller ist, ist, dass es keine Kopie verwendet. Die sogenannte Nullkopie bedeutet, dass beim Betrieb von Daten kein Kopieren des Datenpuffers von einem Speicherbereich in einen anderen erforderlich ist. Da eine Kopie des Speichers weniger vorhanden ist, wird die Effizienz der CPU verbessert.
Werfen wir einen Blick auf die Unterschiede zwischen ihnen:
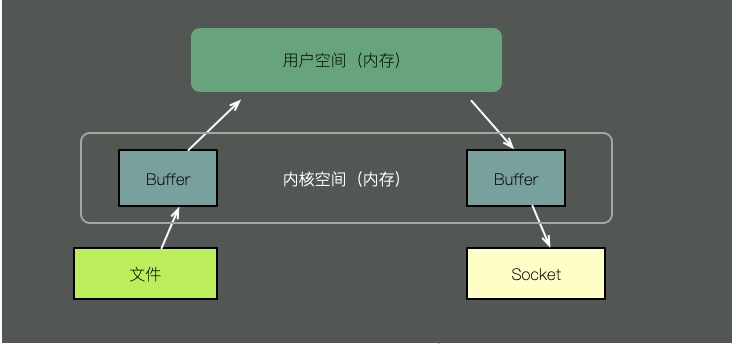
Um den Inhalt einer Datei über einen Socket zu senden, sind bei der herkömmlichen Methode die folgenden Schritte erforderlich:
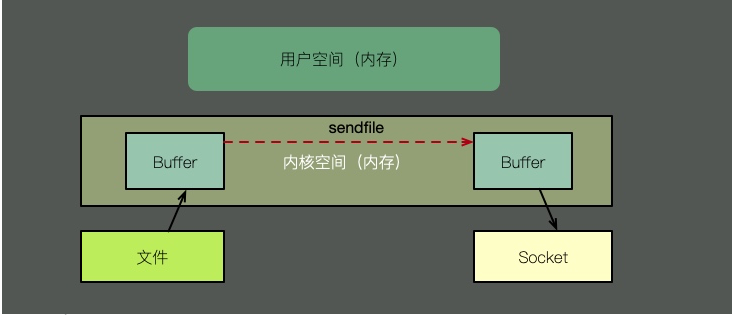
Keine Kopie und mehrere Modi, verwenden wir zur Veranschaulichung sendfile. Wie in der Abbildung oben gezeigt, erfordert die Nullkopie mit Unterstützung des Kernels einen Schritt weniger, nämlich das Kopieren des Kernel-Cache in den Benutzerbereich. Das heißt, es spart Speicher und CPU-Planungszeit, was sehr effizient ist.
除了iotop、iostat这些命令外,sar命令可以方便的看到网络运行状况,下面是一个简单的示例,用于描述入网流量和出网流量。
$ sar -n DEV 1 Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU) 12:16:48 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil 12:16:49 AM eth0 18763.00 5032.00 20686.42 478.30 0.00 0.00 0.00 0.00 12:16:49 AM lo 14.00 14.00 1.36 1.36 0.00 0.00 0.00 0.00 12:16:49 AM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 12:16:49 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil 12:16:50 AM eth0 19763.00 5101.00 21999.10 482.56 0.00 0.00 0.00 0.00 12:16:50 AM lo 20.00 20.00 3.25 3.25 0.00 0.00 0.00 0.00 12:16:50 AM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 ^C
当然,我们可以选择性的只看TCP的一些状态。
$ sar -n TCP,ETCP 1 Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU) 12:17:19 AM active/s passive/s iseg/s oseg/s 12:17:20 AM 1.00 0.00 10233.00 18846.00 12:17:19 AM atmptf/s estres/s retrans/s isegerr/s orsts/s 12:17:20 AM 0.00 0.00 0.00 0.00 0.00 12:17:20 AM active/s passive/s iseg/s oseg/s 12:17:21 AM 1.00 0.00 8359.00 6039.00 12:17:20 AM atmptf/s estres/s retrans/s isegerr/s orsts/s 12:17:21 AM 0.00 0.00 0.00 0.00 0.00 ^C
不要寄希望于这些指标,能够立刻帮助我们定位性能问题。这些工具,只能够帮我们大体猜测发生问题的地方,它对性能问题的定位,只是起到辅助作用。想要分析这些bottleneck,需要收集更多的信息。
想要获取更多的性能数据,就不得不借助更加专业的工具,比如基于eBPF的BCC工具,这些牛x的工具我们将在其他文章里展开。读完本文,希望你能够快速的了解Linux的运行状态,对你的系统多一些掌控。
Das obige ist der detaillierte Inhalt vonVerstehen Sie den Gesundheitszustand von Linux in 61 Sekunden!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



