
 Technologie-Peripheriegeräte
KI
RAG oder Feintuning? Microsoft hat einen Leitfaden zum Erstellungsprozess großer Modellanwendungen in bestimmten Bereichen veröffentlicht
Technologie-Peripheriegeräte
KI
RAG oder Feintuning? Microsoft hat einen Leitfaden zum Erstellungsprozess großer Modellanwendungen in bestimmten Bereichen veröffentlicht
RAG oder Feintuning? Microsoft hat einen Leitfaden zum Erstellungsprozess großer Modellanwendungen in bestimmten Bereichen veröffentlicht

Retrieval Augmented Generation (RAG) und Feinabstimmung (Fine-Tuning) sind zwei gängige Methoden zur Verbesserung der Leistung großer Sprachmodelle. Welche Methode ist also besser? Was ist beim Erstellen von Anwendungen in einer bestimmten Domäne effizienter? Dieses Dokument von Microsoft dient als Referenz bei der Auswahl.
Beim Erstellen großer Sprachmodellanwendungen werden häufig zwei Ansätze verwendet, um proprietäre und domänenspezifische Daten zu integrieren: Generierung von Abrufverbesserungen und Feinabstimmung. Die abrufgestützte Generierung verbessert die Generierungsfähigkeiten des Modells durch die Einführung externer Daten, während die Feinabstimmung zusätzliches Wissen in das Modell selbst einbezieht. Unser Verständnis der Vor- und Nachteile dieser beiden Ansätze ist jedoch unzureichend.
In diesem Artikel wird ein von Microsoft-Forschern vorgeschlagener neuer Schwerpunkt vorgestellt, der darin besteht, KI-Assistenten mit spezifischem Kontext und adaptiven Reaktionsfähigkeiten für die Agrarindustrie zu entwickeln. Durch die Einführung eines umfassenden Large-Language-Model-Prozesses können qualitativ hochwertige, branchenspezifische Fragen und Antworten generiert werden. Der Prozess besteht aus einer systematischen Reihe von Schritten, beginnend mit der Identifizierung und Sammlung relevanter Dokumente zu einem breiten Spektrum landwirtschaftlicher Themen. Diese Dokumente werden dann bereinigt und strukturiert, um mithilfe des grundlegenden GPT-Modells aussagekräftige Frage-Antwort-Paare zu generieren. Abschließend werden die generierten Frage-Antwort-Paare nach ihrer Qualität bewertet und gefiltert. Dieser Ansatz stellt der Agrarindustrie ein leistungsstarkes Tool zur Verfügung, das genaue und praktische Informationen liefern kann, um Landwirten und verwandten Praktikern dabei zu helfen, verschiedene Probleme und Herausforderungen besser zu bewältigen.
Dieser Artikel zielt darauf ab, wertvolle Wissensressourcen für die Agrarindustrie zu schaffen, wobei die Landwirtschaft als Fallstudie dient. Ihr oberstes Ziel ist es, zur Entwicklung von LLM im Agrarsektor beizutragen.

Papieradresse: https://arxiv.org/pdf/2401.08406.pdf
Papiertitel: RAG vs Fine-tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture
Das Ziel des Prozesses dieses Dokuments besteht darin, domänenspezifische Fragen und Antworten zu generieren, die den Bedürfnissen spezifischer Branchenexperten und Interessengruppen gerecht werden. In dieser Branche sollten die von KI-Assistenten erwarteten Antworten auf relevanten branchenspezifischen Faktoren basieren.
In diesem Artikel geht es um Agrarforschung und das Ziel ist es, Antworten in diesem speziellen Bereich zu generieren. Ausgangspunkt der Forschung ist daher ein landwirtschaftlicher Datensatz, der in drei Hauptkomponenten eingespeist wird: Frage- und Antwortgenerierung, Retrieval-Enhancement-Generierung und der Fine-Tuning-Prozess. Bei der Frage-Antwort-Generierung werden Frage-Antwort-Paare auf der Grundlage der Informationen im Agrardatensatz erstellt, und bei der abrufgestützten Generierung werden diese als Wissensquelle verwendet. Die generierten Daten werden verfeinert und zur Feinabstimmung mehrerer Modelle verwendet, deren Qualität anhand einer Reihe vorgeschlagener Metriken bewertet wird. Nutzen Sie durch diesen umfassenden Ansatz die Leistungsfähigkeit großer Sprachmodelle zum Nutzen der Agrarindustrie und anderer Interessengruppen.
Dieses Papier leistet einige besondere Beiträge zum Verständnis großer Sprachmodelle im Agrarbereich. Diese Beiträge können wie folgt zusammengefasst werden:
1, Umfassende Bewertung von LLMs: Dieses Papier führt eine umfassende Bewertung großer Sprachmodelle durch. einschließlich LlaMa2-13B, GPT-4 und Vicuna zur Beantwortung landwirtschaftlicher Fragen. Für die Auswertung wurde ein Benchmark-Datensatz aus großen Agrarproduktionsländern herangezogen. In dieser Analyse übertrifft GPT-4 durchweg andere Modelle, allerdings müssen die mit seiner Feinabstimmung und Schlussfolgerung verbundenen Kosten berücksichtigt werden.
2. Der Einfluss von Retrieval-Technologie und Feinabstimmung auf die Leistung: In diesem Artikel wird der Einfluss von Retrieval-Technologie und Feinabstimmung auf die Leistung von LLMs untersucht. Untersuchungen haben ergeben, dass sowohl die Generierung der Abrufverbesserung als auch die Feinabstimmung wirksame Techniken zur Verbesserung der Leistung von LLMs sind.
3. Auswirkungen potenzieller Anwendungen von LLMs in verschiedenen Branchen: Für Prozesse, die RAG etablieren und die Technologie für die Anwendung in LLMs optimieren möchten, geht dieser Artikel einen bahnbrechenden Schritt und fördert die Zusammenarbeit zwischen mehreren Branchen.
Methodik
Teil 2 dieses Artikels beschreibt die angewandte Methodik, einschließlich des Datenerfassungsprozesses, des Informationsextraktionsprozesses, der Frage- und Antwortgenerierung und der Feinabstimmung des Modells. Die Methodik dreht sich um einen Prozess zur Generierung und Bewertung von Frage-Antwort-Paaren zum Aufbau domänenspezifischer Assistenten, wie in Abbildung 1 unten dargestellt.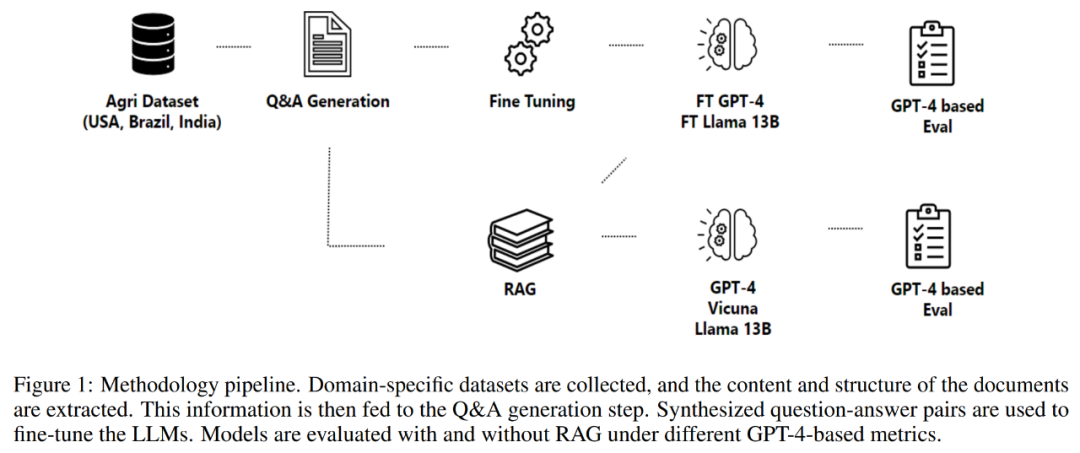

Die nächste Komponente des Prozesses ist die Generierung von Fragen und Antworten. Ziel ist es, kontextbasierte, qualitativ hochwertige Fragen zu generieren, die den Inhalt des extrahierten Textes genau wiedergeben. Diese Methode verwendet einen Rahmen zur Steuerung der strukturellen Zusammensetzung von Eingabe und Ausgabe und verbessert so den Gesamteffekt der vom Sprachmodell generierten Antwort.
Der Prozess generiert dann Antworten auf die formulierten Fragen. Der hier gewählte Ansatz nutzt die abrufgestützte Generierung und kombiniert die Fähigkeiten von Abruf- und Generierungsmechanismen, um qualitativ hochwertige Antworten zu erstellen.
Abschließend erfolgt die Feinabstimmung des Modells durch Fragen und Antworten. Der Optimierungsprozess nutzt Methoden wie Low-Rank Adjustment (LoRA), um ein umfassendes Verständnis des Inhalts und Kontexts wissenschaftlicher Literatur zu gewährleisten und sie so zu einer wertvollen Ressource in verschiedenen Bereichen oder Branchen zu machen.
Datensätze
Die Studie bewertet ein durch Feinabstimmung und Abrufverbesserung generiertes Sprachmodell unter Verwendung eines Datensatzes kontextrelevanter Fragen und Antworten aus drei großen Pflanzenanbauländern: den Vereinigten Staaten, Brasilien und Indien. Im Falle dieses Artikels wird die Landwirtschaft als industrieller Hintergrund herangezogen. Die verfügbaren Daten variieren stark in Format und Inhalt und reichen von regulatorischen Dokumenten über wissenschaftliche Berichte und agronomische Untersuchungen bis hin zu Wissensdatenbanken.
In diesem Artikel wurden Informationen aus öffentlich zugänglichen Online-Dokumenten, Handbüchern und Berichten des US-Landwirtschaftsministeriums, staatlicher Agrar- und Verbraucherschutzbehörden und anderer zusammengetragen.
Zu den verfügbaren Dokumenten gehören bundesstaatliche Regulierungs- und Richtlinieninformationen zum Pflanzen- und Viehmanagement, zu Krankheiten und bewährten Verfahren, zu Qualitätssicherungs- und Exportbestimmungen, Einzelheiten zu Hilfsprogrammen sowie Versicherungs- und Preisrichtlinien. Die gesammelten Daten umfassen insgesamt über 23.000 PDF-Dateien mit über 50 Millionen Token und decken 44 US-Bundesstaaten ab. Die Forscher haben diese Dateien heruntergeladen und vorverarbeitet, um Textinformationen zu extrahieren, die als Eingabe für den Frage- und Antwortgenerierungsprozess verwendet werden könnten.
Um das Modell zu vergleichen und zu bewerten, verwendet dieser Artikel Dokumente zum Bundesstaat Washington, darunter 573 Dateien mit mehr als 2 Millionen Token. Listing 5 unten zeigt ein Beispiel für den Inhalt dieser Dateien.

Metriken
Der Hauptzweck dieses Abschnitts besteht darin, einen umfassenden Satz von Metriken zu erstellen, mit dem Ziel, die Qualitätsbewertung des Frage- und Antwortgenerierungsprozesses zu leiten, insbesondere die Bewertung der Feinabstimmung und Abrufverbesserung Generierungsmethoden.
Bei der Entwicklung von Metriken müssen mehrere Schlüsselfaktoren berücksichtigt werden. Erstens stellt die der Fragequalität innewohnende Subjektivität erhebliche Herausforderungen dar.
Zweitens müssen Metriken die Relevanz des Problems und die Abhängigkeit der Praktikabilität vom Kontext berücksichtigen.
Drittens müssen die Vielfalt und Neuheit der generierten Fragen bewertet werden. Ein leistungsfähiges Fragengenerierungssystem sollte in der Lage sein, eine breite Palette von Fragen zu generieren, die alle Aspekte eines bestimmten Inhalts abdecken. Die Quantifizierung von Vielfalt und Neuheit kann jedoch eine Herausforderung sein, da es darum geht, die Einzigartigkeit von Fragen und ihre Ähnlichkeit mit Inhalten und anderen generierten Fragen zu bewerten.
Schließlich sollen gute Fragen anhand der bereitgestellten Inhalte beantwortet werden können. Um zu beurteilen, ob eine Frage mithilfe der verfügbaren Informationen genau beantwortet werden kann, ist ein tiefes Verständnis des Inhalts und die Fähigkeit erforderlich, relevante Informationen zur Beantwortung der Frage zu identifizieren.
Diese Metriken spielen eine wesentliche Rolle dabei, sicherzustellen, dass die vom Modell bereitgestellten Antworten die Frage genau, relevant und effektiv beantworten. Es besteht jedoch ein erheblicher Mangel an Metriken, die speziell zur Bewertung der Fragenqualität entwickelt wurden.
Im Bewusstsein dieses Mangels konzentriert sich dieses Papier auf die Entwicklung von Metriken zur Bewertung der Fragenqualität. Angesichts der entscheidenden Rolle von Fragen bei der Förderung sinnvoller Gespräche und der Generierung nützlicher Antworten ist die Sicherstellung der Qualität Ihrer Fragen ebenso wichtig wie die Sicherstellung der Qualität Ihrer Antworten.
Die in diesem Artikel entwickelte Metrik zielt darauf ab, die Lücke in der bisherigen Forschung in diesem Bereich zu schließen und ein Mittel zur umfassenden Bewertung der Fragenqualität bereitzustellen, was einen erheblichen Einfluss auf den Fortschritt des Frage- und Antwortgenerierungsprozesses haben wird.
Problembewertung
Die in diesem Dokument entwickelten Metriken zur Bewertung des Problems lauten wie folgt:
Relevanz
Globale Relevanz
Abdeckung
Überlappung
-
Verschiedene Sexualität
Details
Flüssigkeit
Antwortauswertung
Da große Sprachmodelle dazu neigen, lange, detaillierte, informative und gesprächige Antworten zu generieren, ist die Auswertung der von ihnen generierten Antworten eine Herausforderung.
Dieser Artikel verwendet die AzureML-Modellbewertung und verwendet die folgenden Metriken, um die generierten Antworten mit der tatsächlichen Situation zu vergleichen:
Konsistenz: Vergleicht die Konsistenz zwischen der tatsächlichen Situation und der Vorhersage unter Berücksichtigung des Kontexts.
Relevanz: Misst, wie effektiv eine Antwort die Hauptaspekte der Frage im Kontext beantwortet.
Authentizität: Definiert, ob die Antwort logisch zu den im Kontext enthaltenen Informationen passt und stellt einen ganzzahligen Wert zur Bestimmung der Authentizität der Antwort bereit.
Modellbewertung
Um verschiedene fein abgestimmte Modelle zu bewerten, verwendet dieser Artikel GPT-4 als Evaluator. Etwa 270 Frage-Antwort-Paare wurden aus landwirtschaftlichen Dokumenten generiert, wobei GPT-4 als realer Datensatz verwendet wurde. Für jedes fein abgestimmte Modell und jedes abruferweiterte generative Modell werden Antworten auf diese Fragen generiert.
Dieses Papier bewertet LLMs anhand mehrerer verschiedener Metriken:
Bewertung mit Richtlinien: Für jedes reale Frage-Antwort-Paar fordert dieses Papier GPT-4 auf, einen Bewertungsleitfaden zu erstellen, der die richtige Antwort auflistet. Was ist enthalten? . GPT-4 wurde dann aufgefordert, jede Antwort auf einer Skala von 0 bis 1 zu bewerten, basierend auf den Kriterien im Bewertungsleitfaden. Hier ist ein Beispiel:
Prägnanz: Erstellen Sie eine Rubrik, die beschreibt, was prägnante und lange Antworten beinhalten könnten. Basierend auf dieser Rubrik, Antworten auf tatsächliche Situationen und LLM-Antwortaufforderungen wird GPT-4 gebeten, auf einer Skala von 1 bis 5 bewertet zu werden.
Richtigkeit: Dieser Artikel erstellt eine Rubrik, die beschreibt, was eine vollständige, teilweise richtige oder falsche Antwort enthalten sollte. Basierend auf dieser Rubrik, tatsächlichen Situationsantworten und LLM-Antwortaufforderungen wird GPT-4 um eine richtige, falsche oder teilweise richtige Bewertung gebeten.
Experimente
Die Experimente dieses Artikels sind in mehrere unabhängige Experimente unterteilt, die sich jeweils auf spezifische Aspekte der Generierung und Bewertung von Fragen und Antworten, der Generierung von Abrufverbesserungen und der Feinabstimmung konzentrieren.
Diese Experimente untersuchen die folgenden Bereiche:
Q&A-Qualität
Kontextstudien
Modell-zu-metrische Berechnungen
Kombinierte Generation vs. separate Generation
Retrieval-Ablationsstudien
Feinabstimmung
Frage- und Antwortqualität
Dieses Experiment bewertet die Qualität von Frage- und Antwortpaaren, die von drei großen Sprachmodellen, nämlich GPT-3, GPT-3.5 und GPT-4, unter verschiedenen Kontexteinstellungen generiert werden. Die Qualitätsbewertung basiert auf mehreren Metriken, darunter Relevanz, Abdeckung, Überschneidung und Vielfalt.
Kontextstudie
Dieses Experiment untersucht die Auswirkungen verschiedener Kontexteinstellungen auf die Leistung modellgenerierter Fragen und Antworten. Es wertet die generierten Frage-Antwort-Paare unter drei Kontexteinstellungen aus: kein Kontext, Kontext und externer Kontext. Ein Beispiel finden Sie in Tabelle 12.

In der kontextfreien Einstellung weist GPT-4 die höchste Abdeckung und Größe von Hinweisen unter den drei Modellen auf, was darauf hindeutet, dass es mehr Textteile abdecken kann, aber längere Fragen generiert. Allerdings weisen die drei Modelle ähnliche numerische Werte für Diversität, Überlappung, Relevanz und Geläufigkeit auf.
Wenn der Kontext einbezogen wird, weist GPT-3.5 im Vergleich zu GPT-3 einen leichten Anstieg der Abdeckung auf, während GPT-4 die höchste Abdeckung beibehält. Für die Eingabeaufforderung zur Größe hat GPT-4 den größten Wert, was darauf hindeutet, dass es in der Lage ist, längere Fragen und Antworten zu generieren.
In Bezug auf Diversität und Überschneidung schneiden die drei Modelle ähnlich ab. In Bezug auf Relevanz und Sprachkompetenz weist GPT-4 im Vergleich zu anderen Modellen eine leichte Steigerung auf.
In externen Kontexteinstellungen gibt es eine ähnliche Situation.
Darüber hinaus scheint bei Betrachtung jedes Modells die kontextfreie Einstellung die beste Balance für GPT-4 in Bezug auf durchschnittliche Abdeckung, Diversität, Überlappung, Relevanz und Sprachkompetenz zu bieten, erzeugt jedoch kürzere Frage-Antwort-Paare. Die Kontexteinstellung führte zu längeren Frage-Antwort-Paaren und einem leichten Rückgang anderer Metriken außer der Größe. Die externe Kontexteinstellung erzeugte die längsten Frage-Antwort-Paare, behielt jedoch die durchschnittliche Abdeckung bei und erhöhte die durchschnittliche Relevanz und Sprachkompetenz leicht.
Insgesamt scheint für GPT-4 die kontextfreie Einstellung das beste Gleichgewicht in Bezug auf durchschnittliche Abdeckung, Vielfalt, Überschneidung, Relevanz und Sprachkompetenz zu bieten, führt jedoch zu kürzeren Antworten. Kontextbezogene Einstellungen führten zu längeren Eingabeaufforderungen und leichten Rückgängen bei anderen Messwerten. Die externe Kontexteinstellung generierte die längsten Eingabeaufforderungen, behielt aber die durchschnittliche Abdeckung bei, mit leichten Steigerungen der durchschnittlichen Relevanz und Sprachkompetenz.
Die Wahl zwischen diesen drei hängt also von den spezifischen Anforderungen der Aufgabe ab. Wenn die Länge der Eingabeaufforderung nicht berücksichtigt wird, kann der externe Kontext aufgrund höherer Relevanz- und Sprachkompetenz-Werte die beste Wahl sein.
Modell-zu-Metrik-Berechnung
Dieses Experiment vergleicht die Leistung von GPT-3.5 und GPT-4 bei der Berechnung einer Metrik, die zur Bewertung der Qualität von Frage-Antwort-Paaren verwendet wird.
Obwohl GPT-4 die generierten Frage-Antwort-Paare im Allgemeinen als flüssiger und kontextuell authentischer bewertet, sind sie insgesamt weniger vielfältig und weniger relevant als die Bewertungen von GPT-3.5. Diese Perspektiven sind entscheidend für das Verständnis, wie verschiedene Modelle die Qualität generierter Inhalte wahrnehmen und bewerten.
Vergleich zwischen kombinierter Generation und individueller Generation
Dieses Experiment untersucht die Vor- und Nachteile zwischen der individuellen Generierung von Fragen und Antworten und der kombinierten Generierung von Fragen und Antworten und konzentriert sich auf den Vergleich im Hinblick auf die Effizienz der Token-Nutzung.
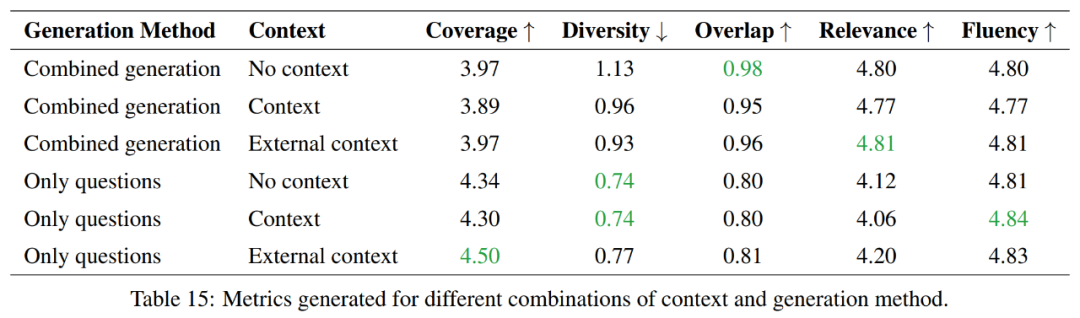
Insgesamt bieten reine Fragengenerierungsmethoden eine bessere Abdeckung und geringere Diversität, während kombinierte Generierungsmethoden in Bezug auf Überlappung und Korrelation besser abschneiden. In Bezug auf die Sprachkompetenz sind beide Methoden ähnlich. Die Wahl zwischen diesen beiden Methoden hängt daher von den spezifischen Anforderungen der Aufgabe ab.
Wenn das Ziel darin besteht, mehr Informationen abzudecken und mehr Vielfalt aufrechtzuerhalten, wird der Ansatz, der nur Fragen generiert, bevorzugt. Wenn jedoch ein hoher Grad an Überlappung mit dem Quellmaterial aufrechterhalten werden soll, wäre ein kombinierter Generierungsansatz die bessere Wahl.
Retrieval-Ablation-Studie
Dieses Experiment bewertet die Retrieval-Fähigkeiten der Retrieval-Enhancement-Generierung, einer Methode, die das inhärente Wissen von LLMs erweitert, indem sie während der Beantwortung von Fragen zusätzlichen Kontext bereitstellt.
Dieses Papier untersucht den Einfluss der Anzahl der abgerufenen Fragmente (d. h. Top-k) auf die Ergebnisse und präsentiert die Ergebnisse in Tabelle 16. Durch die Berücksichtigung weiterer Fragmente ist die abrufgestützte Generierung in der Lage, die ursprünglichen Auszüge konsistenter wiederherzustellen.
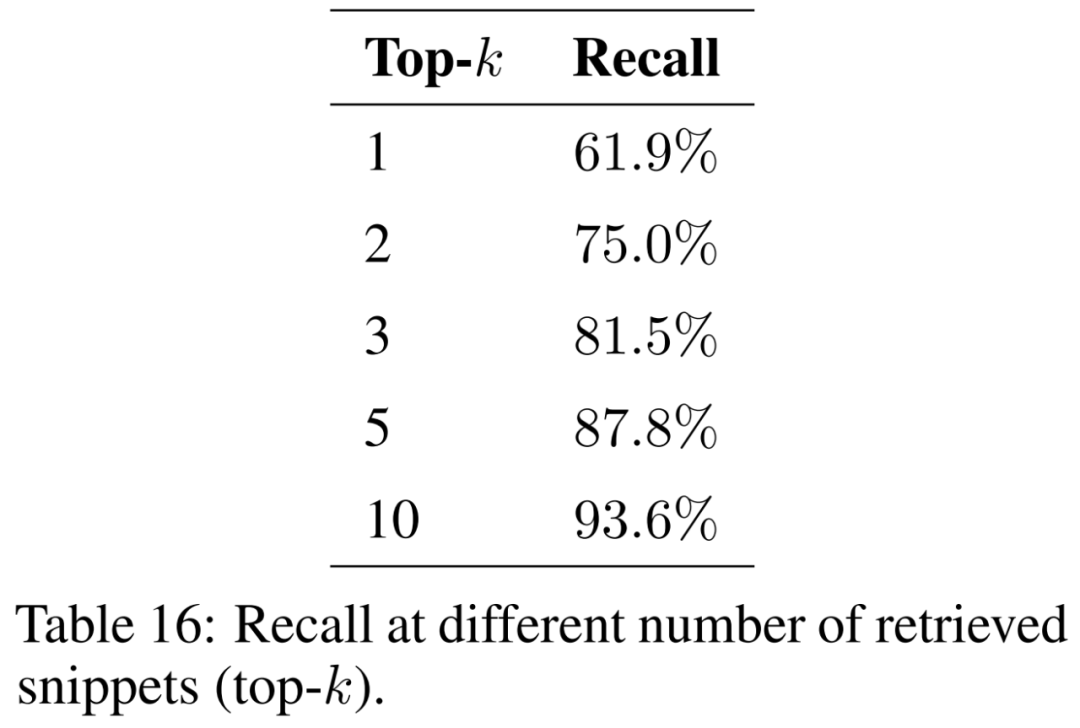
Um sicherzustellen, dass das Modell Probleme aus verschiedenen geografischen Kontexten und Phänomenen bewältigen kann, muss der Korpus der unterstützenden Dokumente erweitert werden, um eine Vielzahl von Themen abzudecken. Es wird erwartet, dass die Größe des Index zunimmt, je mehr Dokumente berücksichtigt werden. Dies kann die Anzahl der Kollisionen zwischen ähnlichen Segmenten während des Abrufs erhöhen, was die Wiederherstellung relevanter Informationen für die Eingabefrage erschwert und den Abruf verringert.
Feinabstimmung
Dieses Experiment bewertet den Leistungsunterschied zwischen dem feinabgestimmten Modell und dem feinabgestimmten Basisanweisungsmodell. Ziel ist es, das Potenzial der Feinabstimmung zu verstehen, um Modellen dabei zu helfen, neues Wissen zu erlernen.
Für das Basismodell bewertet dieser Artikel die Open-Source-Modelle Llama2-13B-chat und Vicuna-13B-v1.5-16k. Diese beiden Modelle sind relativ klein und stellen einen interessanten Kompromiss zwischen Berechnung und Leistung dar. Bei beiden Modellen handelt es sich um fein abgestimmte Versionen von Llama2-13B, die unterschiedliche Methoden verwenden.
Llama2-13B-Chat ist eine durch überwachte Feinabstimmung und Verstärkungslernen verfeinerte Anleitung. Vicuna-13B-v1.5-16k ist eine fein abgestimmte Version der Anweisung durch überwachte Feinabstimmung des ShareGPT-Datensatzes. Darüber hinaus bewertet dieser Artikel die Basis-GPT-4 als größere, teurere und leistungsfähigere Alternative.
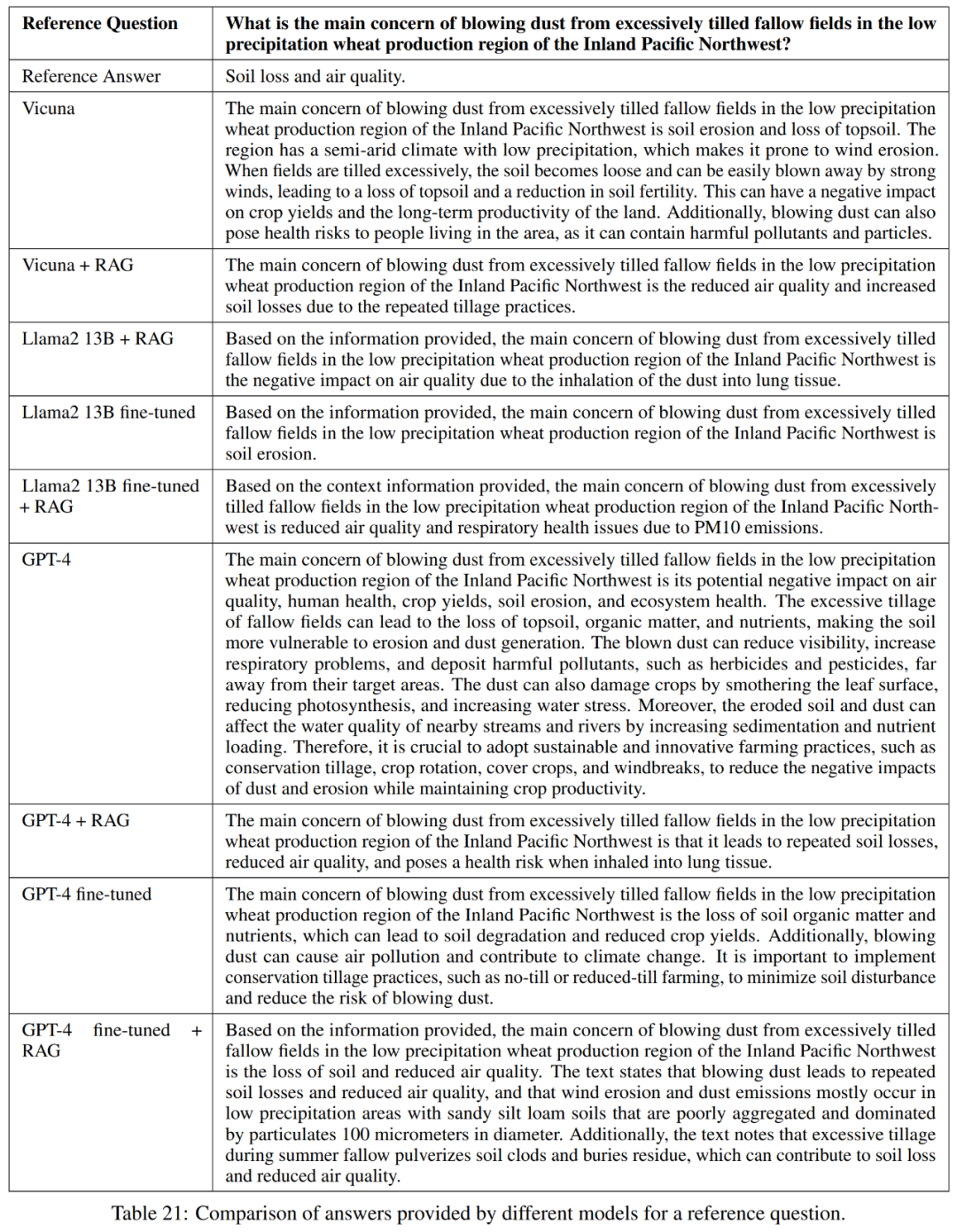
Für das feinabgestimmte Modell optimiert dieser Artikel Llama2-13B direkt anhand landwirtschaftlicher Daten, um seine Leistung mit ähnlichen Modellen zu vergleichen, die für allgemeinere Aufgaben feinabgestimmt wurden. In diesem Dokument wird auch die Feinabstimmung von GPT-4 durchgeführt, um zu bewerten, ob die Feinabstimmung bei sehr großen Modellen noch hilfreich ist. Die Ergebnisse der Bewertung mit Leitlinien sind in Tabelle 18 dargestellt.
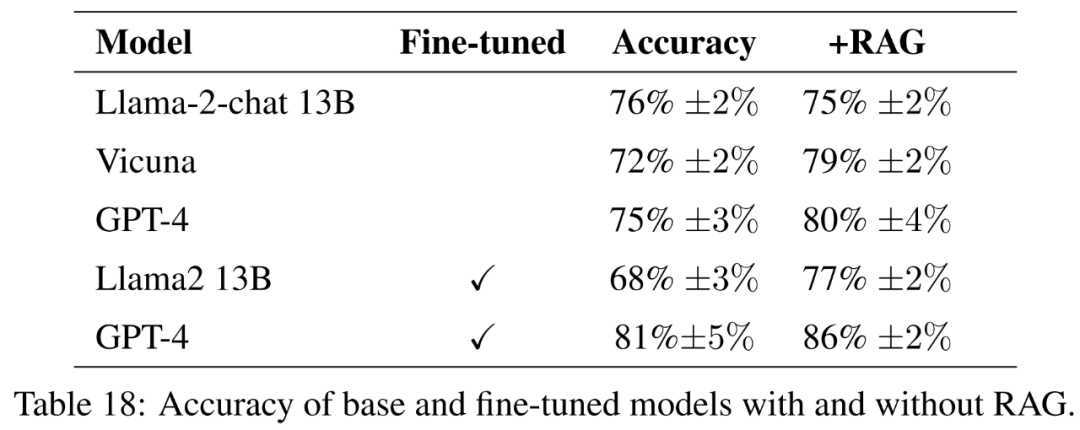
Um die Qualität der Antworten vollständig zu messen, wird in diesem Artikel neben der Genauigkeit auch die Prägnanz der Antworten bewertet.
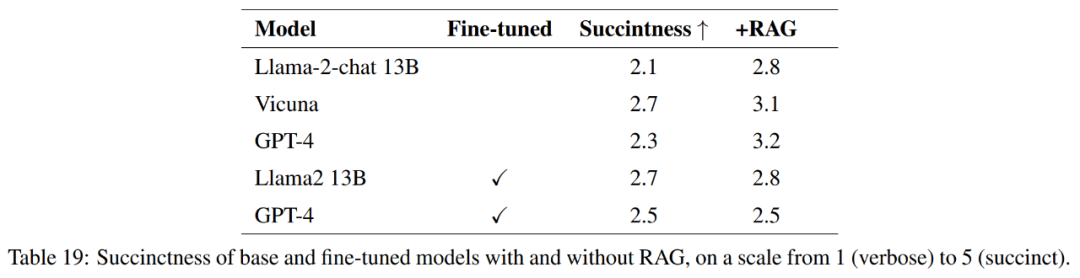
Wie in Tabelle 21 dargestellt, liefern diese Modelle nicht immer eine vollständige Antwort auf die Frage. In einigen Antworten wurde beispielsweise die Bodenerosion als Problem erwähnt, die Luftqualität jedoch nicht erwähnt.
Insgesamt sind Vicuna + Retrieval-Enhanced Generation, GPT-4 + Retrieval-Enhanced Generation, GPT-4 Fine-Tuning und GPT-4 Fine-Tuning die leistungsstärksten Modelle im Hinblick auf die genaue und prägnante Beantwortung der Referenzantworten + Abrufverbesserung generieren. Diese Modelle bieten eine ausgewogene Mischung aus Genauigkeit, Einfachheit und Informationstiefe.
Wissensentdeckung
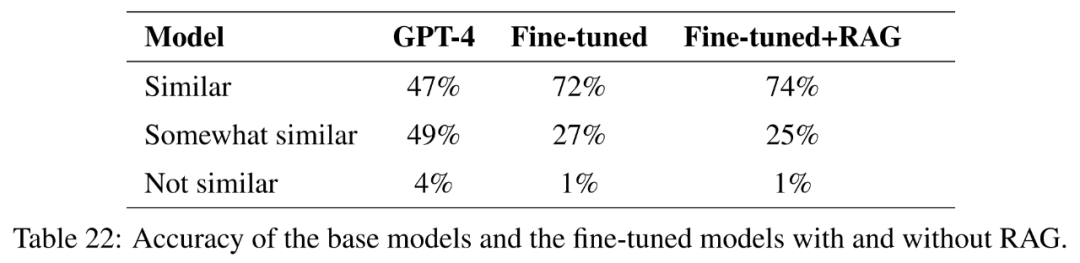
Das Forschungsziel dieser Arbeit besteht darin, das Potenzial der Feinabstimmung zu untersuchen, um GPT-4 dabei zu helfen, neues Wissen zu erlernen, was für die angewandte Forschung von entscheidender Bedeutung ist.
Um dies zu testen, wählt dieser Artikel Fragen aus, die in mindestens drei der 50 Bundesstaaten der USA ähnlich sind. Anschließend wurde die Kosinusähnlichkeit der Einbettungen berechnet und eine Liste von 1000 solcher Fragen identifiziert. Diese Fragen werden aus dem Trainingssatz entfernt und durch Feinabstimmung und Feinabstimmung mit abrufverstärkter Generierung bewertet, ob GPT-4 in der Lage ist, neues Wissen basierend auf den Ähnlichkeiten zwischen verschiedenen Zuständen zu erlernen.
Weitere experimentelle Ergebnisse finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonRAG oder Feintuning? Microsoft hat einen Leitfaden zum Erstellungsprozess großer Modellanwendungen in bestimmten Bereichen veröffentlicht. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Der DeepMind-Roboter spielt Tischtennis und seine Vor- und Rückhand rutschen in die Luft, wodurch menschliche Anfänger völlig besiegt werden
Aug 09, 2024 pm 04:01 PM
Der DeepMind-Roboter spielt Tischtennis und seine Vor- und Rückhand rutschen in die Luft, wodurch menschliche Anfänger völlig besiegt werden
Aug 09, 2024 pm 04:01 PM
Aber vielleicht kann er den alten Mann im Park nicht besiegen? Die Olympischen Spiele in Paris sind in vollem Gange und Tischtennis hat viel Aufmerksamkeit erregt. Gleichzeitig haben Roboter auch beim Tischtennisspielen neue Durchbrüche erzielt. Gerade hat DeepMind den ersten lernenden Roboteragenten vorgeschlagen, der das Niveau menschlicher Amateurspieler im Tischtennis-Wettkampf erreichen kann. Papieradresse: https://arxiv.org/pdf/2408.03906 Wie gut ist der DeepMind-Roboter beim Tischtennisspielen? Vermutlich auf Augenhöhe mit menschlichen Amateurspielern: Sowohl Vorhand als auch Rückhand: Der Gegner nutzt unterschiedliche Spielstile, und auch der Roboter hält aus: Aufschlagannahme mit unterschiedlichem Spin: Allerdings scheint die Intensität des Spiels nicht so intensiv zu sein wie Der alte Mann im Park. Für Roboter, Tischtennis
 Die erste mechanische Klaue! Yuanluobao trat auf der Weltroboterkonferenz 2024 auf und stellte den ersten Schachroboter vor, der das Haus betreten kann
Aug 21, 2024 pm 07:33 PM
Die erste mechanische Klaue! Yuanluobao trat auf der Weltroboterkonferenz 2024 auf und stellte den ersten Schachroboter vor, der das Haus betreten kann
Aug 21, 2024 pm 07:33 PM
Am 21. August fand in Peking die Weltroboterkonferenz 2024 im großen Stil statt. Die Heimrobotermarke „Yuanluobot SenseRobot“ von SenseTime hat ihre gesamte Produktfamilie vorgestellt und kürzlich den Yuanluobot AI-Schachspielroboter – Chess Professional Edition (im Folgenden als „Yuanluobot SenseRobot“ bezeichnet) herausgebracht und ist damit der weltweit erste A-Schachroboter für heim. Als drittes schachspielendes Roboterprodukt von Yuanluobo hat der neue Guoxiang-Roboter eine Vielzahl spezieller technischer Verbesserungen und Innovationen in den Bereichen KI und Maschinenbau erfahren und erstmals die Fähigkeit erkannt, dreidimensionale Schachfiguren aufzunehmen B. durch mechanische Klauen an einem Heimroboter, und führen Sie Mensch-Maschine-Funktionen aus, z. B. Schach spielen, jeder spielt Schach, Überprüfung der Notation usw.
 Microsoft veröffentlicht das kumulative August-Update für Win11: Verbesserung der Sicherheit, Optimierung des Sperrbildschirms usw.
Aug 14, 2024 am 10:39 AM
Microsoft veröffentlicht das kumulative August-Update für Win11: Verbesserung der Sicherheit, Optimierung des Sperrbildschirms usw.
Aug 14, 2024 am 10:39 AM
Laut Nachrichten dieser Website vom 14. August veröffentlichte Microsoft während des heutigen August-Patch-Dienstags kumulative Updates für Windows 11-Systeme, darunter das Update KB5041585 für 22H2 und 23H2 sowie das Update KB5041592 für 21H2. Nachdem das oben genannte Gerät mit dem kumulativen Update vom August installiert wurde, sind die mit dieser Site verbundenen Versionsnummernänderungen wie folgt: Nach der Installation des 21H2-Geräts wurde die Versionsnummer auf Build22000.314722H2 erhöht. Die Versionsnummer wurde auf Build22621.403723H2 erhöht. Nach der Installation des Geräts wurde die Versionsnummer auf Build22631.4037 erhöht. Die Hauptinhalte des KB5041585-Updates für Windows 1121H2 sind wie folgt: Verbesserung: Verbessert
 Claude ist auch faul geworden! Netizen: Lernen Sie, sich einen Urlaub zu gönnen
Sep 02, 2024 pm 01:56 PM
Claude ist auch faul geworden! Netizen: Lernen Sie, sich einen Urlaub zu gönnen
Sep 02, 2024 pm 01:56 PM
Der Schulstart steht vor der Tür und nicht nur die Schüler, die bald ins neue Semester starten, sollten auf sich selbst aufpassen, sondern auch die großen KI-Modelle. Vor einiger Zeit war Reddit voller Internetnutzer, die sich darüber beschwerten, dass Claude faul werde. „Sein Niveau ist stark gesunken, es kommt oft zu Pausen und sogar die Ausgabe wird sehr kurz. In der ersten Woche der Veröffentlichung konnte es ein komplettes 4-seitiges Dokument auf einmal übersetzen, aber jetzt kann es nicht einmal eine halbe Seite ausgeben.“ !
 Auf der Weltroboterkonferenz wurde dieser Haushaltsroboter, der „die Hoffnung auf eine zukünftige Altenpflege' in sich trägt, umzingelt
Aug 22, 2024 pm 10:35 PM
Auf der Weltroboterkonferenz wurde dieser Haushaltsroboter, der „die Hoffnung auf eine zukünftige Altenpflege' in sich trägt, umzingelt
Aug 22, 2024 pm 10:35 PM
Auf der World Robot Conference in Peking ist die Präsentation humanoider Roboter zum absoluten Mittelpunkt der Szene geworden. Am Stand von Stardust Intelligent führte der KI-Roboterassistent S1 drei große Darbietungen mit Hackbrett, Kampfkunst und Kalligraphie auf Ein Ausstellungsbereich, der sowohl Literatur als auch Kampfkunst umfasst, zog eine große Anzahl von Fachpublikum und Medien an. Durch das elegante Spiel auf den elastischen Saiten demonstriert der S1 eine feine Bedienung und absolute Kontrolle mit Geschwindigkeit, Kraft und Präzision. CCTV News führte einen Sonderbericht über das Nachahmungslernen und die intelligente Steuerung hinter „Kalligraphie“ durch. Firmengründer Lai Jie erklärte, dass hinter den seidenweichen Bewegungen die Hardware-Seite die beste Kraftkontrolle und die menschenähnlichsten Körperindikatoren (Geschwindigkeit, Belastung) anstrebt. usw.), aber auf der KI-Seite werden die realen Bewegungsdaten von Menschen gesammelt, sodass der Roboter stärker werden kann, wenn er auf eine schwierige Situation stößt, und lernen kann, sich schnell weiterzuentwickeln. Und agil
 Bekanntgabe der ACL 2024 Awards: Eines der besten Papers zum Thema Oracle Deciphering von HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
Bekanntgabe der ACL 2024 Awards: Eines der besten Papers zum Thema Oracle Deciphering von HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
Bei dieser ACL-Konferenz haben die Teilnehmer viel gewonnen. Die sechstägige ACL2024 findet in Bangkok, Thailand, statt. ACL ist die führende internationale Konferenz im Bereich Computerlinguistik und Verarbeitung natürlicher Sprache. Sie wird von der International Association for Computational Linguistics organisiert und findet jährlich statt. ACL steht seit jeher an erster Stelle, wenn es um akademischen Einfluss im Bereich NLP geht, und ist außerdem eine von der CCF-A empfohlene Konferenz. Die diesjährige ACL-Konferenz ist die 62. und hat mehr als 400 innovative Arbeiten im Bereich NLP eingereicht. Gestern Nachmittag gab die Konferenz den besten Vortrag und weitere Auszeichnungen bekannt. Diesmal gibt es 7 Best Paper Awards (zwei davon unveröffentlicht), 1 Best Theme Paper Award und 35 Outstanding Paper Awards. Die Konferenz verlieh außerdem drei Resource Paper Awards (ResourceAward) und einen Social Impact Award (
 Hongmeng Smart Travel S9 und die umfassende Einführungskonferenz für neue Produkte wurden gemeinsam mit einer Reihe neuer Blockbuster-Produkte veröffentlicht
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 und die umfassende Einführungskonferenz für neue Produkte wurden gemeinsam mit einer Reihe neuer Blockbuster-Produkte veröffentlicht
Aug 08, 2024 am 07:02 AM
Heute Nachmittag begrüßte Hongmeng Zhixing offiziell neue Marken und neue Autos. Am 6. August veranstaltete Huawei die Hongmeng Smart Xingxing S9 und die Huawei-Konferenz zur Einführung neuer Produkte mit umfassendem Szenario und brachte die Panorama-Smart-Flaggschiff-Limousine Xiangjie S9, das neue M7Pro und Huawei novaFlip, MatePad Pro 12,2 Zoll, das neue MatePad Air und Huawei Bisheng mit Mit vielen neuen Smart-Produkten für alle Szenarien, darunter die Laserdrucker der X1-Serie, FreeBuds6i, WATCHFIT3 und der Smart Screen S5Pro, von Smart Travel über Smart Office bis hin zu Smart Wear baut Huawei weiterhin ein Smart-Ökosystem für alle Szenarien auf, um Verbrauchern ein Smart-Erlebnis zu bieten Internet von allem. Hongmeng Zhixing: Huawei arbeitet mit chinesischen Partnern aus der Automobilindustrie zusammen, um die Modernisierung der Smart-Car-Industrie voranzutreiben
 Das Team von Li Feifei schlug ReKep vor, um Robotern räumliche Intelligenz zu verleihen und GPT-4o zu integrieren
Sep 03, 2024 pm 05:18 PM
Das Team von Li Feifei schlug ReKep vor, um Robotern räumliche Intelligenz zu verleihen und GPT-4o zu integrieren
Sep 03, 2024 pm 05:18 PM
Tiefe Integration von Vision und Roboterlernen. Wenn zwei Roboterhände reibungslos zusammenarbeiten, um Kleidung zu falten, Tee einzuschenken und Schuhe zu packen, gepaart mit dem humanoiden 1X-Roboter NEO, der in letzter Zeit für Schlagzeilen gesorgt hat, haben Sie vielleicht das Gefühl: Wir scheinen in das Zeitalter der Roboter einzutreten. Tatsächlich sind diese seidigen Bewegungen das Produkt fortschrittlicher Robotertechnologie + exquisitem Rahmendesign + multimodaler großer Modelle. Wir wissen, dass nützliche Roboter oft komplexe und exquisite Interaktionen mit der Umgebung erfordern und die Umgebung als Einschränkungen im räumlichen und zeitlichen Bereich dargestellt werden kann. Wenn Sie beispielsweise möchten, dass ein Roboter Tee einschenkt, muss der Roboter zunächst den Griff der Teekanne ergreifen und sie aufrecht halten, ohne den Tee zu verschütten, und ihn dann sanft bewegen, bis die Öffnung der Kanne mit der Öffnung der Tasse übereinstimmt , und neigen Sie dann die Teekanne in einem bestimmten Winkel. Das
