
 Technologie-Peripheriegeräte
KI
Um Rauschen in Fluoreszenzbildern auf selbstüberwachte Weise zu entfernen, entwickelte das Tsinghua-Team die Transformer-Methode zur räumlichen Redundanz-Entrauschung
Technologie-Peripheriegeräte
KI
Um Rauschen in Fluoreszenzbildern auf selbstüberwachte Weise zu entfernen, entwickelte das Tsinghua-Team die Transformer-Methode zur räumlichen Redundanz-Entrauschung
Um Rauschen in Fluoreszenzbildern auf selbstüberwachte Weise zu entfernen, entwickelte das Tsinghua-Team die Transformer-Methode zur räumlichen Redundanz-Entrauschung

Das hohe Signal-Rausch-Verhältnis der Fluoreszenzbildgebung ist entscheidend für die genaue Visualisierung biologischer Phänomene. Das Rauschproblem bleibt jedoch eine der größten Herausforderungen für die Bildempfindlichkeit.
Das Forschungsteam der Tsinghua-Universität stellt den Spatial Redundancy Denoising Transformer (SRDTrans) zur Verfügung, um Rauschen in Fluoreszenzbildern auf selbstüberwachte Weise zu entfernen.
Das Team schlug eine neue Sampling-Strategie vor, um benachbarte orthogonale Trainingspaare basierend auf räumlicher Redundanz zu extrahieren und die Abhängigkeit von einer hohen Bildgebungsgeschwindigkeit zu beseitigen. Darüber hinaus entwickelten sie eine leichte raumzeitliche Transformer-Architektur, die in der Lage ist, entfernte Abhängigkeiten und hochauflösende Merkmale bei geringem Rechenaufwand zu erfassen.
SRDTrans ist in der Lage, Hochfrequenzinformationen zu bewahren, ohne dass es zu einer übermäßigen Glättung von Strukturen oder einer Verzerrung von Fluoreszenzspuren kommt. Darüber hinaus ist SRDTrans nicht auf spezifische Bildgebungsverfahren und Probenannahmen angewiesen, sodass es für die Erweiterung auf verschiedene Bildgebungsmodalitäten und biologische Anwendungen geeignet ist.
Die Studie trug den Titel „Spatial Redundancy Transformer for Self-Supervised Fluoreszenz Image Denoising“ und wurde am 11. Dezember 2023 in „Nature Computational Science“ veröffentlicht.

Die rasante Entwicklung der In-vivo-Bildgebungstechnologie ermöglicht es Forschern, biologische Strukturen und Aktivitäten im Mikrometer- und sogar Nanobereich zu beobachten. Die Fluoreszenzmikroskopie als beliebte bildgebende Methode hilft mit ihrer hohen räumlich-zeitlichen Auflösung und molekularen Spezifität dabei, neue physiologische und pathologische Mechanismen aufzudecken. Das Hauptziel der Fluoreszenzmikroskopie besteht darin, saubere, klare Bilder zu erhalten, die ausreichend Probeninformationen enthalten, um die Genauigkeit der nachgelagerten Analyse sicherzustellen und sichere Schlussfolgerungen zu ermöglichen.
Aufgrund des Einflusses verschiedener biophysikalischer und biochemischer Faktoren unterliegt die Fluoreszenzbildgebung jedoch verschiedenen Einschränkungen im praktischen Betrieb. Beispielsweise können Helligkeit, Phototoxizität und Photobleichung von Fluorophoren einen negativen Einfluss auf die Bildgebungsergebnisse haben. Im Falle einer Photonenlimitierung kann das inhärente Photonenschussrauschen das Signal-Rausch-Verhältnis (SNR) des Bildes erheblich reduzieren, insbesondere bei geringer Beleuchtung und Hochgeschwindigkeitsbeobachtungsbedingungen. Diese Faktoren machen die Qualität und Zuverlässigkeit der Fluoreszenzbildgebung zu einer Herausforderung und müssen in der Praxis überwunden und optimiert werden.
Es wurden verschiedene Methoden vorgeschlagen, um Rauschen in Fluoreszenzbildern zu entfernen. Herkömmliche Rauschunterdrückungsalgorithmen, die auf numerischer Filterung und mathematischer Optimierung basieren, weisen eine unbefriedigende Leistung und eine begrenzte Anwendbarkeit auf. In den letzten Jahren hat Deep Learning bemerkenswerte Erfolge auf dem Gebiet der Bildrauschunterdrückung erzielt.
Durch iteratives Training mithilfe von Ground-Truth-Datensätzen (GT) können tiefe neuronale Netze die Zuordnungsbeziehung zwischen verrauschten Bildern und ihren sauberen Gegenstücken lernen. Die Wirksamkeit dieser Überwachungsmethode hängt hauptsächlich von den gepaarten GT-Bildern ab.
Saubere Bilder mit Pixel-für-Pixel-Registrierung zu erhalten, ist eine große Herausforderung bei der Beobachtung der Aktivität lebender Organismen, da Proben oft schnelle dynamische Veränderungen durchlaufen. Um diesen Widerspruch zu mildern, wurden einige selbstüberwachte Methoden vorgeschlagen, um eine anwendbarere und praktischere Rauschunterdrückung in der Fluoreszenzbildgebung zu erreichen.
Um eine bessere Rauschunterdrückungsleistung zu erzielen, ist die Fähigkeit, gleichzeitig globale räumliche Informationen und zeitliche Korrelation über große Entfernungen zu extrahieren, von entscheidender Bedeutung, was in Faltungs-Neuronalen Netzen (CNN) aufgrund der Lokalität des Faltungskerns fehlt. Darüber hinaus tendiert CNN aufgrund der inhärenten spektralen Verzerrung dazu, vorzugsweise niederfrequente Merkmale anzupassen, während hochfrequente Merkmale ignoriert werden, was unweigerlich zu übermäßig glatten Rauschunterdrückungsergebnissen führt.
Das Forschungsteam der Tsinghua-Universität schlug den Spatial Redundancy Denoising Transformer (SRDTrans) vor, um diese Dilemmata zu lösen.
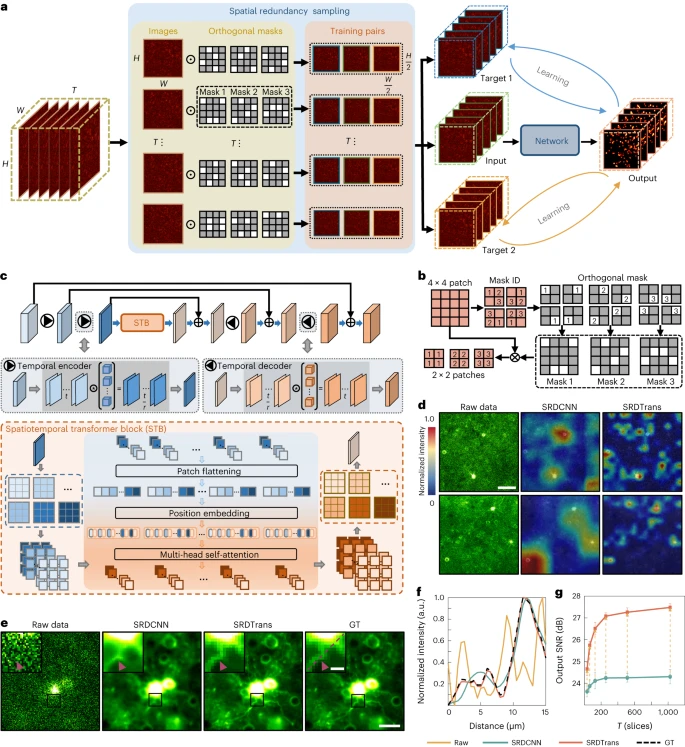
Abbildung: SRDTrans-Prinzip und Leistungsbewertung. (Quelle: Papier)
Einerseits schlugen die Forscher eine räumlich redundante Sampling-Strategie vor, um dreidimensionale (3D) Trainingspaare aus rohen Zeitrafferdaten in zwei orthogonalen Richtungen zu extrahieren.
Dieses Schema basiert nicht auf der Ähnlichkeit zwischen zwei benachbarten Bildern, daher eignet sich SRDTrans für sehr schnelle Aktivitäten und extrem niedrige Bildgeschwindigkeiten, was eine Ergänzung zu DeepCAD ist, das zuvor vom Team vorgeschlagen wurde, um zeitliche Redundanz auszunutzen.
Da SRDTrans nicht auf Annahmen über Kontrastmechanismen, Rauschmodelle, Probendynamik und Bildgebungsgeschwindigkeit angewiesen ist. Daher kann es problemlos auf andere biologische Proben und Bildgebungsmodalitäten ausgeweitet werden, wie z. B. Membranspannungsbildgebung, Einzelproteindetektion, Lichtblattmikroskopie, konfokale Mikroskopie, Lichtfeldmikroskopie und hochauflösende Mikroskopie.
Andererseits entwarfen die Forscher ein leichtes räumlich-zeitliches Transformationsnetzwerk, um die langfristige Korrelation voll auszunutzen. Der optimierte Feature-Interaktionsmechanismus ermöglicht es dem Modell, hochauflösende Features mit einer kleinen Anzahl von Parametern zu erhalten. Im Vergleich zum klassischen CNN verfügt das vorgeschlagene SRDTrans über eine stärkere globale Wahrnehmung und Hochfrequenzwartungsfähigkeiten und ist in der Lage, feinkörnige raumzeitliche Muster aufzudecken, die bisher schwer zu erkennen waren.
Das Team demonstrierte die überlegene Lärmreduzierungsleistung von SRDTrans in zwei repräsentativen Anwendungen. Die erste ist die Einzelmolekül-Lokalisierungsmikroskopie (SMLM), bei der benachbarte Rahmen zufällige Teilmengen von Fluorophoren sind.
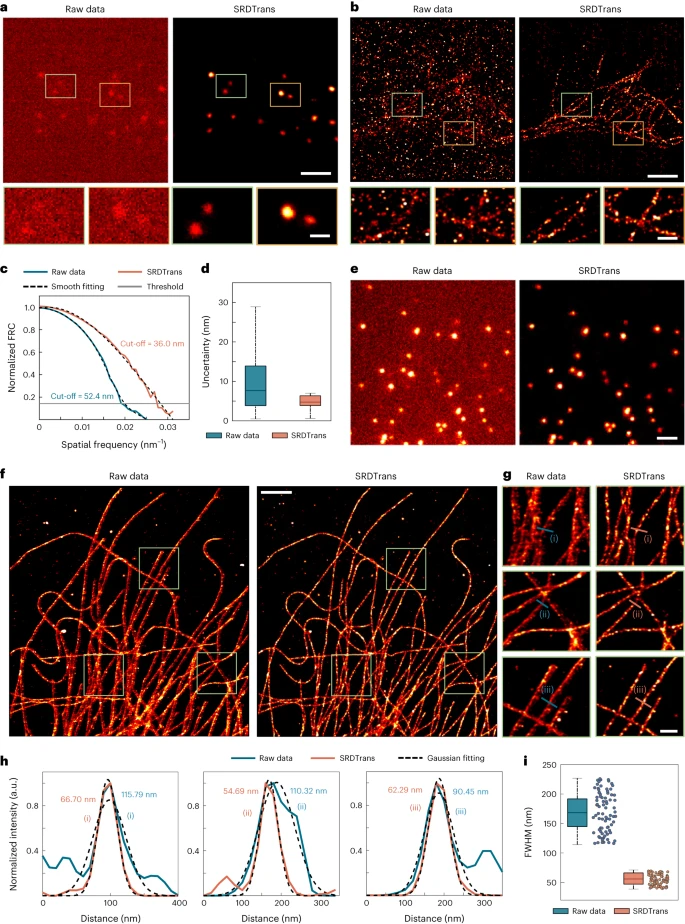
Abbildung: Anwendung von SRDTrans auf experimentelle SMLM-Daten. (Quelle: Paper)
Das andere ist die Zwei-Photonen-Kalzium-Bildgebung großer 3D-Neuronenpopulationen bei Volumengeschwindigkeiten von nur 0,3 Hz. Umfangreiche qualitative und quantitative Ergebnisse zeigen, dass SRDTrans als wesentliches Entrauschungswerkzeug für die Fluoreszenzbildgebung dienen kann, um eine Vielzahl zellulärer und subzellulärer Phänomene zu beobachten.
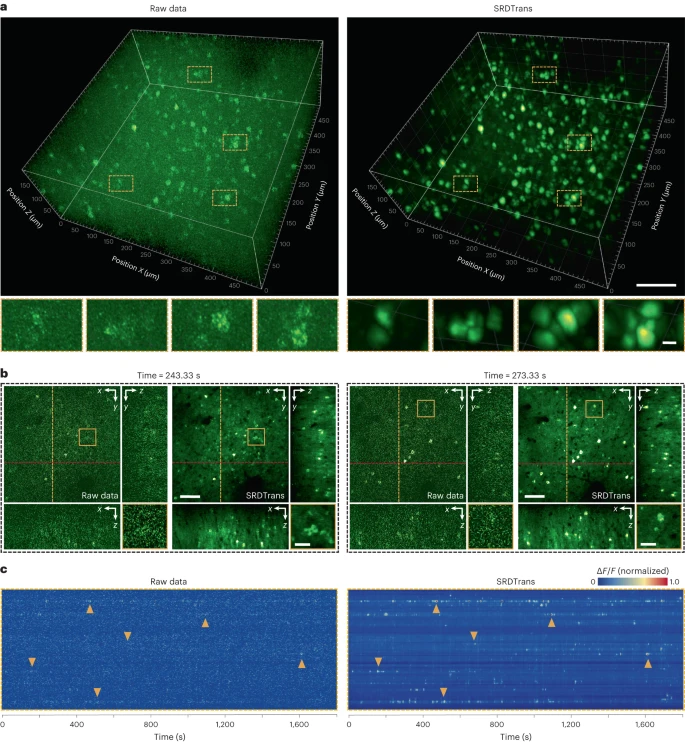
Abbildung: Hochempfindliche Kalzium-Bildgebung großer neuronaler Volumina. (Quelle: Papier)
SRDTrans hat auch einige Einschränkungen, hauptsächlich in der Grundannahme, dass benachbarte Pixel eine ungefähre Struktur haben sollten. SRDTrans schlägt fehl, wenn die räumliche Abtastrate zu niedrig ist, um ausreichende Redundanz bereitzustellen. Ein weiteres potenzielles Risiko ist die Fähigkeit zur Verallgemeinerung, da die leichtgewichtige Netzwerkarchitektur von SRDTrans besser für bestimmte Aufgaben geeignet ist.
Glauben Sie, dass das Training eines bestimmten Modells für bestimmte Daten die zuverlässigste Methode ist, Deep Learning für die Rauschunterdrückung von Fluoreszenzbildern zu nutzen. Daher sollten neue Modelle trainiert werden, um optimale Ergebnisse zu gewährleisten, wenn sich Bildgebungsparameter, Modalitäten und Proben ändern.
Da sich die Entwicklung von Fluoreszenzindikatoren in Richtung einer schnelleren Kinetik bewegt, nimmt die Bildgebungsgeschwindigkeit, die zur Überwachung der biologischen Dynamik auf Millisekundenebene erforderlich ist, um diese schnellen Aktivitäten aufzuzeichnen, weiter zu. Für Entrauschungsmethoden, die auf zeitlicher Redundanz basieren, wird es immer schwieriger, ausreichende Abtastraten zu erzielen. Die Perspektive des Teams besteht darin, diese Lücke zu schließen, indem versucht wird, räumliche Redundanz als Alternative zu nutzen, um eine selbstüberwachte Rauschunterdrückung in mehr Bildgebungsanwendungen zu ermöglichen.
Obwohl der perfekte Fall für eine räumlich redundante Abtastung eine doppelt so hohe räumliche Abtastrate ist wie die beugungsbegrenzte Nyquist-Abtastung, wodurch sichergestellt wird, dass zwei benachbarte Pixel in den meisten Fällen nahezu identische optische Signale aufweisen, wird die endogene Ähnlichkeit zwischen den beiden räumlich herunterabgetastet Teilsequenzen reichen aus, um das Training des Netzwerks zu steuern.
Dies bedeutet jedoch nicht, dass die vorgeschlagene räumlich redundante Sampling-Strategie die zeitlich redundante Sampling vollständig ersetzen kann, denn Ablationsstudien haben gezeigt, dass zeitlich redundante Sampling bei Ausstattung mit der gleichen Netzwerkarchitektur bessere Ergebnisse in der Hochgeschwindigkeitsbildgebung erzielen kann. gute Leistung. Der Vorteil von SRDTrans gegenüber DeepCAD bei hohen Bildgeschwindigkeiten liegt tatsächlich an der Transformer-Architektur.
Im Allgemeinen sind räumliche Redundanz und zeitliche Redundanz zwei komplementäre Abtaststrategien, mit denen ein selbstüberwachtes Training von Netzwerken zur Rauschunterdrückung durch Fluoreszenz-Zeitraffer-Bildgebung erreicht werden kann. Welche Stichprobenstrategie verwendet wird, hängt davon ab, welche Redundanz in den Daten größer ist. Es ist erwähnenswert, dass in vielen Fällen keine der beiden Redundanzen ausreicht, um aktuelle Stichprobenstrategien zu unterstützen. Die Entwicklung spezifischer oder allgemeinerer selbstüberwachter Rauschunterdrückungsmethoden wird für die Fluoreszenzbildgebung von bleibendem Wert sein.
Papierlink: https://www.nature.com/articles/s43588-023-00568-2
Das obige ist der detaillierte Inhalt vonUm Rauschen in Fluoreszenzbildern auf selbstüberwachte Weise zu entfernen, entwickelte das Tsinghua-Team die Transformer-Methode zur räumlichen Redundanz-Entrauschung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
Um die Zeitüberschreitung für Vue Axios festzulegen, können wir eine Axios -Instanz erstellen und die Zeitleitungsoption angeben: in globalen Einstellungen: vue.Prototyp. $ Axios = axios.create ({Timeout: 5000}); In einer einzigen Anfrage: this. $ axios.get ('/api/user', {timeout: 10000}).
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
MySQL kann JSON -Daten zurückgeben. Die JSON_EXTRACT -Funktion extrahiert Feldwerte. Über komplexe Abfragen sollten Sie die Where -Klausel verwenden, um JSON -Daten zu filtern, aber auf die Leistungsauswirkungen achten. Die Unterstützung von MySQL für JSON nimmt ständig zu, und es wird empfohlen, auf die neuesten Versionen und Funktionen zu achten.
 Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Detaillierte Erläuterung von Datenbanksäureattributen Säureattribute sind eine Reihe von Regeln, um die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen sicherzustellen. Sie definieren, wie Datenbanksysteme Transaktionen umgehen, und sorgen dafür, dass die Datenintegrität und -genauigkeit auch im Falle von Systemabstürzen, Leistungsunterbrechungen oder mehreren Benutzern gleichzeitiger Zugriff. Säureattributübersicht Atomizität: Eine Transaktion wird als unteilbare Einheit angesehen. Jeder Teil schlägt fehl, die gesamte Transaktion wird zurückgerollt und die Datenbank behält keine Änderungen bei. Wenn beispielsweise eine Banküberweisung von einem Konto abgezogen wird, jedoch nicht auf ein anderes erhöht wird, wird der gesamte Betrieb widerrufen. begintransaktion; updateAccountsSetBalance = Balance-100WH
 Der Hauptschlüssel von MySQL kann null sein
Apr 08, 2025 pm 03:03 PM
Der Hauptschlüssel von MySQL kann null sein
Apr 08, 2025 pm 03:03 PM
Der MySQL -Primärschlüssel kann nicht leer sein, da der Primärschlüssel ein Schlüsselattribut ist, das jede Zeile in der Datenbank eindeutig identifiziert. Wenn der Primärschlüssel leer sein kann, kann der Datensatz nicht eindeutig identifiziert werden, was zu Datenverwirrung führt. Wenn Sie selbstsinkrementelle Ganzzahlsspalten oder UUIDs als Primärschlüssel verwenden, sollten Sie Faktoren wie Effizienz und Raumbelegung berücksichtigen und eine geeignete Lösung auswählen.
