
 Computer-Tutorials
Computerwissen
Wie großartig ist Pingora! Super beliebter Webserver übertrifft Nginx
Computer-Tutorials
Computerwissen
Wie großartig ist Pingora! Super beliebter Webserver übertrifft Nginx
Wie großartig ist Pingora! Super beliebter Webserver übertrifft Nginx

Wir freuen uns, Pingora vorzustellen, unseren neuen HTTP-Proxy, der auf Rust basiert. Verarbeitet mehr als 1 Billion Anfragen pro Tag, verbessert die Leistung und bietet Cloudflare-Kunden neue Funktionen und benötigt dabei nur ein Drittel der CPU- und Speicherressourcen der ursprünglichen Proxy-Infrastruktur.
Während Cloudflare weiter skaliert, haben wir festgestellt, dass die Rechenleistung von NGINX unsere Anforderungen nicht mehr erfüllen kann. Obwohl es im Laufe der Jahre eine gute Leistung erbrachte, wurde uns im Laufe der Zeit klar, dass es bei der Bewältigung der Herausforderungen unserer Größenordnung nur an Grenzen stößt. Daher hielten wir es für notwendig, einige neue Lösungen zu entwickeln, um unseren Leistungs- und Funktionalitätsanforderungen gerecht zu werden.
Cloudflare-Kunden und -Benutzer nutzen das globale Cloudflare-Netzwerk als Proxy zwischen HTTP-Clients und -Servern. Wir haben viele Diskussionen geführt, viele Technologien entwickelt und neue Protokolle wie QUIC und HTTP/2-Optimierungen implementiert, um die Effizienz von Browsern und anderen Benutzeragenten zu verbessern, die sich mit unserem Netzwerk verbinden.
Heute konzentrieren wir uns auf einen weiteren verwandten Aspekt dieser Gleichung: Proxy-Dienste, die für die Verwaltung des Datenverkehrs zwischen unserem Netzwerk und den Internetservern verantwortlich sind. Dieser Proxy-Dienst bietet Unterstützung und Leistung für unser CDN, Workers Fetch, Tunnel, Stream, R2 und viele andere Funktionen und Produkte.
Lassen Sie uns untersuchen, warum wir uns entschieden haben, unseren alten Service zu aktualisieren, und den Entwicklungsprozess des Pingora-Systems erkunden. Dieses System wurde speziell für die Anwendungsfälle und Skalierungen der Kunden von Cloudflare entwickelt.
Warum einen anderen Agenten aufbauen
In den letzten Jahren sind wir bei der Verwendung von NGINX auf einige Einschränkungen gestoßen. Für einige Einschränkungen haben wir Methoden optimiert oder eingeführt, um diese zu umgehen. Es gibt jedoch einige Einschränkungen, die eine größere Herausforderung darstellen.
Architektonische Einschränkungen beeinträchtigen die Leistung
Die Worker-(Prozess-)Architektur von NGINX [4] weist betriebliche Mängel für unseren Anwendungsfall auf, die unsere Leistung und Effizienz beeinträchtigen.
Erstens kann in NGINX jede Anfrage nur von einem einzigen Mitarbeiter bearbeitet werden. Dies führt zu einem Lastungleichgewicht zwischen allen CPU-Kernen [5] und damit zu Verlangsamungen [6].
Aufgrund dieses Sperreffekts für den Anforderungsprozess können Anforderungen, die CPU-intensive oder blockierende E/A-Aufgaben ausführen, andere Anforderungen verlangsamen. Wie diese Blogbeiträge zeigen, haben wir viel Zeit in die Lösung dieser Probleme investiert.
Das kritischste Problem für unseren Anwendungsfall ist die Wiederverwendung von Verbindungen, wenn unser Computer eine TCP-Verbindung mit dem Ursprungsserver aufbaut, der die HTTP-Anfrage weiterleitet. Durch die Wiederverwendung von Verbindungen aus einem Verbindungspool können Sie die für neue Verbindungen erforderlichen TCP- und TLS-Handshakes überspringen und so die TTFB (Zeit bis zum ersten Byte) von Anforderungen beschleunigen.
Der NGINX-Verbindungspool [9] entspricht jedoch einem einzelnen Worker. Wenn eine Anfrage einen Worker erreicht, können nur Verbindungen innerhalb dieses Workers wiederverwendet werden. Je mehr NGINX-Worker zur Skalierung hinzugefügt werden, desto schlechter wird die Wiederverwendung unserer Verbindungen, da die Verbindungen über alle Prozesse hinweg auf mehr isolierte Pools verteilt sind. Dies führt zu einer langsameren TTFB und mehr Verbindungen, die aufrechterhalten werden müssen, was unsere Ressourcen (und Geld) und die unserer Kunden verbraucht. 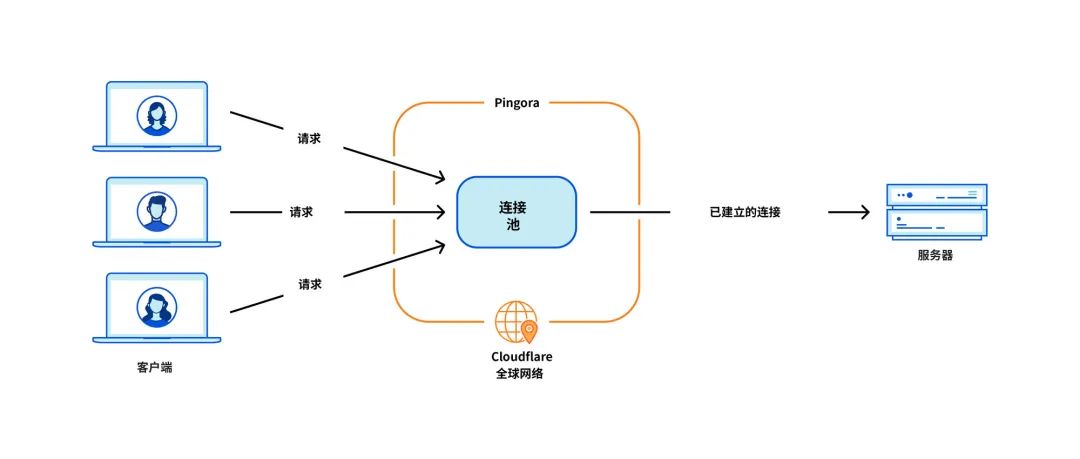
Wie bereits in früheren Blogbeiträgen erwähnt, haben wir Problemumgehungen für einige dieser Probleme. Aber wenn wir das grundlegende Problem lösen können: das Arbeiter-/Prozessmodell, werden wir alle diese Probleme auf natürliche Weise lösen.
Einige Arten von Funktionen sind schwierig hinzuzufügen
NGINX ist ein großartiger Webserver, Load Balancer oder einfaches Gateway. Aber Cloudflare kann noch viel mehr. Früher haben wir alle benötigten Funktionen rund um NGINX entwickelt, aber es war nicht einfach, zu viele Abweichungen von der NGINX-Upstream-Codebasis zu vermeiden.
Beim erneuten Versuch einer Anfrage/eines Anfragefehlers[10] möchten wir die Anfrage manchmal mit einem anderen Satz von Anfrageheadern an einen anderen Ursprungsserver senden. Aber NGINX erlaubt dies nicht. In diesem Fall müssen wir Zeit und Mühe aufwenden, um die Einschränkungen von NGINX zu umgehen.
Gleichzeitig helfen die Programmiersprachen, die wir verwenden müssen, nicht, diese Schwierigkeiten zu lindern. NGINX ist ausschließlich in C geschrieben, was von Natur aus nicht speichersicher ist. Die Verwendung einer solchen Codebasis eines Drittanbieters ist sehr fehleranfällig. Selbst erfahrene Ingenieure geraten leicht in Speichersicherheitsprobleme [11], und wir möchten diese Probleme so weit wie möglich vermeiden.
Eine weitere Sprache, die wir als Ergänzung zu C verwenden, ist Lua. Es ist weniger riskant, aber auch weniger leistungsfähig. Darüber hinaus fehlt uns beim Umgang mit komplexem Lua-Code und Geschäftslogik häufig die statische Typisierung [12].
Und die NGINX-Community ist nicht sehr aktiv und die Entwicklung findet oft „hinter verschlossenen Türen“ statt [13].
Entscheiden Sie sich, unser eigenes zu bauen
Da unser Kundenstamm und unser Funktionsumfang in den letzten Jahren weiter gewachsen sind, haben wir weiterhin drei Optionen evaluiert:
In den letzten Jahren haben wir diese Optionen vierteljährlich evaluiert. Es gibt keine eindeutige Formel für die Entscheidung, welche Option die beste ist. Im Laufe einiger Jahre sind wir weiterhin den Weg des geringsten Widerstands gegangen und haben NGINX weiter weiterentwickelt. In manchen Fällen scheint der ROI des Aufbaus einer eigenen Agentur jedoch lohnender zu sein. Wir forderten die Entwicklung eines Agenten von Grund auf und begannen mit der Entwicklung unserer Traum-Agentenanwendung.
Pingora-Projekt
Designentscheidung
Um einen schnellen, effizienten und sicheren Proxy zu erstellen, der Millionen von Anfragen pro Sekunde verarbeiten kann, mussten wir zunächst einige wichtige Designentscheidungen treffen.
Wir haben Rust[16] als Sprache für das Projekt gewählt, weil es das, was C kann, auf speichersichere Weise tun kann, ohne die Leistung zu beeinträchtigen.
Obwohl es einige großartige Standard-HTTP-Bibliotheken von Drittanbietern gibt, wie zum Beispiel hyper[17], haben wir uns entschieden, unsere eigene zu erstellen, weil wir unsere Flexibilität bei der Handhabung des HTTP-Verkehrs maximieren und sicherstellen wollten, dass wir ihn in unserem eigenen Tempo erledigen können Innovation.
Bei Cloudflare kümmern wir uns um den Datenverkehr für das gesamte Internet. Wir müssen viele seltsame und nicht RFC-konforme Fälle von HTTP-Verkehr unterstützen. Dies ist ein häufiges Dilemma in der HTTP-Community und im Web, wo schwierige Entscheidungen zwischen der strikten Einhaltung der HTTP-Spezifikation und der Anpassung an die Nuancen des breiteren Ökosystems potenzieller Legacy-Clients oder -Server getroffen werden müssen.
Der HTTP-Statuscode ist in RFC 9110 als dreistellige Ganzzahl [18] definiert und liegt voraussichtlich im Bereich von 100 bis 599. Hyper ist eine solche Implementierung. Viele Server unterstützen jedoch die Verwendung von Statuscodes zwischen 599 und 999. Wir haben für diese Funktion eine Frage [19] erstellt, die verschiedene Seiten der Debatte untersucht. Obwohl das Hyper-Team diese Änderung schließlich akzeptierte, hatte es gute Gründe, einen solchen Antrag abzulehnen, und dies war nur einer von vielen Fällen von Nichteinhaltung, die wir unterstützen mussten.
Um die Position von Cloudflare im HTTP-Ökosystem zu erfüllen, benötigen wir eine robuste, tolerante und anpassbare HTTP-Bibliothek, die den verschiedenen Risikoumgebungen des Internets standhalten und eine Vielzahl nicht konformer Anwendungsfälle unterstützen kann. Der beste Weg, dies zu gewährleisten, ist die Implementierung einer eigenen Architektur.
Die nächste Designentscheidung betrifft unser Workload-Planungssystem. Wir wählen Multithreading gegenüber Multiprocessing [20], um Ressourcen, insbesondere Verbindungspooling, einfach zu teilen. Wir glauben, dass Arbeitsdiebstahl [21] ebenfalls implementiert werden muss, um bestimmte Kategorien von oben genannten Leistungsproblemen zu vermeiden. Die asynchrone Laufzeit von Tokio passt perfekt [22] zu unseren Anforderungen.
Schließlich möchten wir, dass unsere Projekte intuitiv und entwicklerfreundlich sind. Was wir entwickeln, ist kein Endprodukt, sondern sollte als Plattform erweiterbar sein, da weitere Funktionen darauf aufbauen. Wir haben uns entschieden, eine programmierbare Schnittstelle zu implementieren, die auf „Request-Lifecycle“-Ereignissen basiert, ähnlich wie NGINX/OpenResty[23]. Die Phase „Anfragefilter“ ermöglicht es Entwicklern beispielsweise, Code auszuführen, um Anfragen zu ändern oder abzulehnen, wenn Anfrageheader empfangen werden. Mit diesem Design können wir unsere Geschäftslogik und die gemeinsame Proxy-Logik klar trennen. Entwickler, die bisher mit NGINX gearbeitet haben, können problemlos zu Pingora wechseln und schnell produktiver werden.
Pingora ist schneller in der Produktion
Lassen Sie uns schnell bis jetzt vorspulen. Pingora verarbeitet fast alle HTTP-Anfragen, die eine Interaktion mit dem Ursprungsserver erfordern (z. B. Cache-Fehler), und wir sammeln dabei viele Leistungsdaten.
Sehen wir uns zunächst an, wie Pingora den Datenverkehr unserer Kunden beschleunigt. Der Gesamtverkehr auf Pingora zeigt eine mittlere TTFB-Reduktion von 5 ms und eine 95. Perzentil-Reduktion von 80 ms. Das liegt nicht daran, dass wir den Code schneller ausführen. Selbst unser alter Dienst kann Anfragen im Sub-Millisekundenbereich bearbeiten.
Zeiteinsparungen ergeben sich aus unserer neuen Architektur, die Verbindungen über alle Threads hinweg gemeinsam nutzt. Dies bedeutet eine bessere Wiederverwendung von Verbindungen und einen geringeren Zeitaufwand für TCP- und TLS-Handshakes.
Über alle Kunden hinweg verzeichnet Pingora im Vergleich zum alten Dienst nur ein Drittel neue Verbindungen pro Sekunde. Bei einem Großkunden konnte die Wiederverwendung von Verbindungen von 87,1 % auf 99,92 % gesteigert werden, was die Anzahl neuer Verbindungen um das 160-fache reduzierte. Um es ins rechte Licht zu rücken: Durch den Wechsel zu Pingora haben wir unseren Kunden und Benutzern jeden Tag 434 Jahre Händeschütteln erspart.
Weitere Funktionen
Verfügt über eine entwicklerfreundliche Benutzeroberfläche, mit der Ingenieure vertraut sind, und beseitigt gleichzeitig frühere Einschränkungen, sodass wir mehr Funktionen schneller entwickeln können. Kernfunktionen wie neue Protokolle dienen als Bausteine dafür, wie wir unseren Kunden mehr bieten können.
Zum Beispiel konnten wir Pingora ohne größere Hindernisse HTTP/2-Upstream-Unterstützung hinzufügen. Dies ermöglicht es uns, gRPC in Kürze für unsere Kunden verfügbar zu machen[24]. Das Hinzufügen der gleichen Funktionalität zu NGINX würde mehr technischen Aufwand erfordern und ist möglicherweise nicht möglich [25].
Kürzlich haben wir die Einführung von Cache Reserve[26] angekündigt, bei dem Pingora R2-Speicher als Caching-Schicht verwendet. Da wir Pingora um weitere Funktionen erweitern, können wir neue Produkte anbieten, die bisher nicht möglich waren.
Effizienter
In der Produktion verbraucht Pingora bei gleicher Verkehrslast etwa 70 % weniger CPU und 67 % weniger Speicher als unser alter Dienst. Die Einsparungen ergeben sich aus mehreren Faktoren.
Unser Rust-Code läuft effizienter [28] als der alte Lua-Code [27]. Darüber hinaus gibt es auch Effizienzunterschiede in ihrer Architektur. Wenn Lua-Code beispielsweise in NGINX/OpenResty auf einen HTTP-Header zugreifen möchte, muss er diesen aus einer NGINX-C-Struktur lesen, einen Lua-String zuweisen und ihn dann in einen Lua-String kopieren. Anschließend sammelt Lua auch seine neuen Saiten im Müll ein. In Pingora ist es nur ein direkter String-Zugriff.
Das Multithreading-Modell macht auch den Datenaustausch über mehrere Anfragen hinweg effizienter. NGINX verfügt auch über einen gemeinsam genutzten Speicher, aber aufgrund von Implementierungsbeschränkungen muss jeder Zugriff auf den gemeinsam genutzten Speicher einen Mutex verwenden und es können nur Zeichenfolgen und Zahlen in den gemeinsam genutzten Speicher abgelegt werden. In Pingora kann auf die meisten gemeinsam genutzten Elemente direkt über gemeinsame Referenzen hinter atomaren Referenzzählern zugegriffen werden [29].
Wie oben erwähnt, ist ein weiterer wichtiger Teil der CPU-Einsparung die Reduzierung neuer Verbindungen. Der TLS-Handshake ist offensichtlich teurer als nur das Senden und Empfangen von Daten über eine bestehende Verbindung.
sicherer
Bei unserer Größenordnung ist es schwierig, Funktionen schnell und sicher freizugeben. Es ist schwierig, jeden Randfall vorherzusagen, der in einer verteilten Umgebung auftreten kann, die Millionen von Anfragen pro Sekunde verarbeitet. Fuzz-Tests und statische Analysen können nur begrenzt Abhilfe schaffen. Die speichersichere Semantik von Rust schützt uns vor undefiniertem Verhalten und gibt uns die Gewissheit, dass unsere Dienste ordnungsgemäß ausgeführt werden.
Mit diesen Garantien können wir uns stärker darauf konzentrieren, wie Änderungen an unserem Service mit anderen Services oder Kundenquellen interagieren. Wir konnten Funktionen in einem höheren Tempo entwickeln, ohne mit der Speichersicherheit und schwer diagnostizierbaren Abstürzen zu kämpfen zu haben.
Wenn es zu einem Absturz kommt, müssen sich die Ingenieure die Zeit nehmen, um zu diagnostizieren, wie es passiert ist und was ihn verursacht hat. Seit der Gründung von Pingora haben wir Hunderte Milliarden Anfragen bearbeitet und es ist noch nie zu einem Absturz aufgrund unseres Servicecodes gekommen.
Tatsächlich sind Pingora-Abstürze so selten, dass wir, wenn wir auf einen solchen stoßen, meist auf nicht zusammenhängende Probleme stoßen. Kürzlich haben wir kurz nach dem Absturz unseres Dienstes einen Kernel-Fehler [30] entdeckt. Wir haben auf einigen Rechnern auch Hardwareprobleme entdeckt, die in der Vergangenheit seltene, durch unsere Software verursachte Speicherfehler ausschlossen, selbst nachdem ein umfassendes Debuggen nahezu unmöglich war.
Zusammenfassung
Zusammenfassend lässt sich sagen, dass wir einen schnelleren, effizienteren und vielseitigeren internen Agenten aufgebaut haben, der als Plattform für unsere aktuellen und zukünftigen Produkte dient.
Wir werden später auf weitere technische Details zu den Problemen und Anwendungsoptimierungen eingehen, mit denen wir konfrontiert waren, sowie auf die Lehren, die wir aus der Entwicklung und Einführung von Pingora zur Unterstützung wichtiger Teile des Internets gezogen haben. Außerdem werden wir unsere Open-Source-Initiativen vorstellen.
Dieser Artikel stammt aus dem CloudFlare-Blog, geschrieben von Yuchen Wu und Andrew Hauck
Link: https://blog.cloudflare.com/zh-cn/how-we-built-pingora-the-proxy-that-connects-cloudflare-to-the-internet-zh-cn/
Das obige ist der detaillierte Inhalt vonWie großartig ist Pingora! Super beliebter Webserver übertrifft Nginx. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 So erlauben Sie den externen Netzwerkzugriff auf den Tomcat-Server
Apr 21, 2024 am 07:22 AM
So erlauben Sie den externen Netzwerkzugriff auf den Tomcat-Server
Apr 21, 2024 am 07:22 AM
Um dem Tomcat-Server den Zugriff auf das externe Netzwerk zu ermöglichen, müssen Sie Folgendes tun: Ändern Sie die Tomcat-Konfigurationsdatei, um externe Verbindungen zuzulassen. Fügen Sie eine Firewallregel hinzu, um den Zugriff auf den Tomcat-Server-Port zu ermöglichen. Erstellen Sie einen DNS-Eintrag, der den Domänennamen auf die öffentliche IP des Tomcat-Servers verweist. Optional: Verwenden Sie einen Reverse-Proxy, um Sicherheit und Leistung zu verbessern. Optional: Richten Sie HTTPS für mehr Sicherheit ein.
 So führen Sie thinkphp aus
Apr 09, 2024 pm 05:39 PM
So führen Sie thinkphp aus
Apr 09, 2024 pm 05:39 PM
Schritte zum lokalen Ausführen von ThinkPHP Framework: Laden Sie ThinkPHP Framework herunter und entpacken Sie es in ein lokales Verzeichnis. Erstellen Sie einen virtuellen Host (optional), der auf das ThinkPHP-Stammverzeichnis verweist. Konfigurieren Sie Datenbankverbindungsparameter. Starten Sie den Webserver. Initialisieren Sie die ThinkPHP-Anwendung. Greifen Sie auf die URL der ThinkPHP-Anwendung zu und führen Sie sie aus.
 Willkommen bei Nginx! Wie kann ich es lösen?
Apr 17, 2024 am 05:12 AM
Willkommen bei Nginx! Wie kann ich es lösen?
Apr 17, 2024 am 05:12 AM
Um den Fehler „Willkommen bei Nginx!“ zu beheben, müssen Sie die Konfiguration des virtuellen Hosts überprüfen, den virtuellen Host aktivieren, Nginx neu laden. Wenn die Konfigurationsdatei des virtuellen Hosts nicht gefunden werden kann, erstellen Sie eine Standardseite und laden Sie Nginx neu. Anschließend wird die Fehlermeldung angezeigt verschwindet und die Website wird normal angezeigt.
 So generieren Sie eine URL aus einer HTML-Datei
Apr 21, 2024 pm 12:57 PM
So generieren Sie eine URL aus einer HTML-Datei
Apr 21, 2024 pm 12:57 PM
Für die Konvertierung einer HTML-Datei in eine URL ist ein Webserver erforderlich. Dazu sind die folgenden Schritte erforderlich: Besorgen Sie sich einen Webserver. Richten Sie einen Webserver ein. Laden Sie eine HTML-Datei hoch. Erstellen Sie einen Domainnamen. Leiten Sie die Anfrage weiter.
 So stellen Sie das NodeJS-Projekt auf dem Server bereit
Apr 21, 2024 am 04:40 AM
So stellen Sie das NodeJS-Projekt auf dem Server bereit
Apr 21, 2024 am 04:40 AM
Serverbereitstellungsschritte für ein Node.js-Projekt: Bereiten Sie die Bereitstellungsumgebung vor: Erhalten Sie Serverzugriff, installieren Sie Node.js, richten Sie ein Git-Repository ein. Erstellen Sie die Anwendung: Verwenden Sie npm run build, um bereitstellbaren Code und Abhängigkeiten zu generieren. Code auf den Server hochladen: über Git oder File Transfer Protocol. Abhängigkeiten installieren: Stellen Sie eine SSH-Verbindung zum Server her und installieren Sie Anwendungsabhängigkeiten mit npm install. Starten Sie die Anwendung: Verwenden Sie einen Befehl wie node index.js, um die Anwendung zu starten, oder verwenden Sie einen Prozessmanager wie pm2. Konfigurieren Sie einen Reverse-Proxy (optional): Verwenden Sie einen Reverse-Proxy wie Nginx oder Apache, um den Datenverkehr an Ihre Anwendung weiterzuleiten
 Was sind die häufigsten Anweisungen in einer Docker-Datei?
Apr 07, 2024 pm 07:21 PM
Was sind die häufigsten Anweisungen in einer Docker-Datei?
Apr 07, 2024 pm 07:21 PM
Die am häufigsten verwendeten Anweisungen in Dockerfile sind: FROM: Neues Image erstellen oder neues Image ableiten RUN: Befehle ausführen (Software installieren, System konfigurieren) COPY: Lokale Dateien in das Image kopieren ADD: Ähnlich wie COPY kann es automatisch dekomprimiert werden tar-Archive oder URL-Dateien abrufen CMD: Geben Sie den Befehl an, wenn der Container gestartet wird. EXPOSE: Deklarieren Sie den Container-Überwachungsport (aber nicht öffentlich). ENV: Legen Sie die Umgebungsvariable fest. VOLUME: Mounten Sie das Hostverzeichnis oder das anonyme Volume. WORKDIR: Legen Sie das Arbeitsverzeichnis im fest Container ENTRYPOINT: Geben Sie an, was beim Start des Containers ausgeführt werden soll. Ausführbare Datei (ähnlich wie CMD, kann aber nicht überschrieben werden)
 Kann von außen auf Nodejs zugegriffen werden?
Apr 21, 2024 am 04:43 AM
Kann von außen auf Nodejs zugegriffen werden?
Apr 21, 2024 am 04:43 AM
Ja, auf Node.js kann von außen zugegriffen werden. Sie können die folgenden Methoden verwenden: Verwenden Sie Cloud Functions, um die Funktion bereitzustellen und öffentlich zugänglich zu machen. Verwenden Sie das Express-Framework, um Routen zu erstellen und Endpunkte zu definieren. Verwenden Sie Nginx, um Proxy-Anfragen an Node.js-Anwendungen umzukehren. Verwenden Sie Docker-Container, um Node.js-Anwendungen auszuführen und sie über Port-Mapping verfügbar zu machen.
 So stellen Sie eine Website mit PHP bereit und pflegen sie
May 03, 2024 am 08:54 AM
So stellen Sie eine Website mit PHP bereit und pflegen sie
May 03, 2024 am 08:54 AM
Um eine PHP-Website erfolgreich bereitzustellen und zu warten, müssen Sie die folgenden Schritte ausführen: Wählen Sie einen Webserver (z. B. Apache oder Nginx). Installieren Sie PHP. Erstellen Sie eine Datenbank und verbinden Sie PHP. Laden Sie Code auf den Server hoch. Richten Sie den Domänennamen und die DNS-Überwachung der Website-Wartung ein Zu den Schritten gehören die Aktualisierung von PHP und Webservern sowie die Sicherung der Website, die Überwachung von Fehlerprotokollen und die Aktualisierung von Inhalten.
