
 Backend-Entwicklung
Python-Tutorial
Lernen Sie die einfache Installationsmethode von Scrapy kennen und entwickeln Sie schnell Crawler-Programme
Backend-Entwicklung
Python-Tutorial
Lernen Sie die einfache Installationsmethode von Scrapy kennen und entwickeln Sie schnell Crawler-Programme
Lernen Sie die einfache Installationsmethode von Scrapy kennen und entwickeln Sie schnell Crawler-Programme


Scrapy-Installations-Tutorial: Einfache und schnelle Entwicklung von Crawler-Programmen
Einführung:
Mit der rasanten Entwicklung des Internets werden kontinuierlich große Datenmengen generiert und aktualisiert. So können Sie die erforderlichen Daten effizient aus dem Internet crawlen ist zu einem Problem geworden. Ein Thema, das viele Entwickler beschäftigt. Als effizientes, flexibles und Open-Source-Python-Crawler-Framework bietet Scrapy Entwicklern eine Lösung für die schnelle Entwicklung von Crawler-Programmen. In diesem Artikel werden die Installation und Verwendung von Scrapy ausführlich vorgestellt und spezifische Codebeispiele gegeben.
1. Scrapy-Installation
Um Scrapy zu verwenden, müssen Sie zunächst die Abhängigkeiten von Scrapy in Ihrer lokalen Umgebung installieren. Hier sind die Schritte zur Installation von Scrapy:
- Python installieren
Scrapy ist ein Open-Source-Framework, das auf der Python-Sprache basiert, daher müssen Sie zuerst Python installieren. Sie können die neueste Version von Python von der offiziellen Website (https://www.python.org/downloads/) herunterladen und entsprechend dem Betriebssystem installieren. -
Scrapy installieren
Nachdem die Python-Umgebung eingerichtet ist, können Sie Scrapy mit dem Befehl pip installieren. Öffnen Sie ein Befehlszeilenfenster und führen Sie den folgenden Befehl aus, um Scrapy zu installieren:pip install scrapy
Nach dem Login kopierenWenn die Netzwerkumgebung schlecht ist, können Sie die Spiegelquelle von Python für die Installation verwenden, z. B. Douban-Quelle:
pip install scrapy -i https://pypi.douban.com/simple/
Nach dem Login kopierenNach Abschluss der Installation können Sie dies tun Führen Sie den folgenden Befehl aus. Überprüfen Sie, ob Scrapy erfolgreich installiert wurde:
scrapy version
Nach dem Login kopierenWenn Sie die Versionsinformationen von Scrapy sehen, bedeutet dies, dass Scrapy erfolgreich installiert wurde.
2. Schritte zur Verwendung von Scrapy zum Entwickeln eines Crawler-Programms
Erstellen eines Scrapy-Projekts
Verwenden Sie den folgenden Befehl, um ein Scrapy-Projekt im angegebenen Verzeichnis zu erstellen:scrapy startproject myspider
Nach dem Login kopierenDadurch wird ein Projekt mit dem Namen „myspider“ erstellt. im aktuellen Verzeichnisordner, mit der folgenden Struktur:
myspider/
- scrapy.cfg
- myspider/
- __init__.py
- items.py
- middlewares.py
- pipelines .py
- settings.py
spiders/
- __init__.py
Define Item
In Scrapy wird Item verwendet, um die Datenstruktur zu definieren, die gecrawlt werden muss. Öffnen Sie die Datei „myspider/items.py“ und Sie können die Felder definieren, die gecrawlt werden müssen, zum Beispiel:import scrapy class MyItem(scrapy.Item): title = scrapy.Field() content = scrapy.Field() url = scrapy.Field()
Nach dem Login kopierenWriting Spider
Spider ist eine Komponente, die im Scrapy-Projekt verwendet wird, um zu definieren, wie Daten gecrawlt werden. Öffnen Sie das Verzeichnis „myspider/spiders“, erstellen Sie eine neue Python-Datei, z. B. „my_spider.py“, und schreiben Sie den folgenden Code:import scrapy from myspider.items import MyItem class MySpider(scrapy.Spider): name = 'myspider' start_urls = ['https://www.example.com'] def parse(self, response): for item in response.xpath('//div[@class="content"]'): my_item = MyItem() my_item['title'] = item.xpath('.//h2/text()').get() my_item['content'] = item.xpath('.//p/text()').get() my_item['url'] = response.url yield my_itemNach dem Login kopieren- Pipeline konfigurieren
Pipeline wird zum Verarbeiten der vom Crawler erfassten Daten verwendet, z Speichern in einer Datenbank oder Schreiben in Dateien usw. In die Datei „myspider/pipelines.py“ können Sie die Logik zur Datenverarbeitung schreiben. - Einstellungen konfigurieren
In der Datei „myspider/settings.py“ können Sie einige Parameter von Scrapy konfigurieren, wie z. B. User-Agent, Download-Verzögerung usw. Führen Sie das Crawler-Programm aus.
Gehen Sie in der Befehlszeile zum Verzeichnis „myspider“ und führen Sie den folgenden Befehl aus, um das Crawler-Programm auszuführen:scrapy crawl myspider
Nach dem Login kopierenWarten Sie, bis das Crawler-Programm abgeschlossen ist. Anschließend können Sie die erfassten Daten abrufen.
Fazit:
Scrapy bietet als leistungsstarkes Crawler-Framework eine Lösung für die schnelle, flexible und effiziente Entwicklung von Crawler-Programmen. Ich glaube, dass Leser durch die Einführung und die spezifischen Codebeispiele dieses Artikels leicht einsteigen und schnell ihre eigenen Crawler-Programme entwickeln können. In praktischen Anwendungen können Sie je nach Bedarf auch tiefergehendes Lernen und fortgeschrittene Anwendungen von Scrapy durchführen.
Das obige ist der detaillierte Inhalt vonLernen Sie die einfache Installationsmethode von Scrapy kennen und entwickeln Sie schnell Crawler-Programme. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1207
24
52
1207
24

 Gründe und Lösungen für einen Fehler bei der Installation der Scipy-Bibliothek
Feb 22, 2024 pm 06:27 PM
Gründe und Lösungen für einen Fehler bei der Installation der Scipy-Bibliothek
Feb 22, 2024 pm 06:27 PM
Gründe und Lösungen für einen Fehler bei der Installation der Scipy-Bibliothek. Es sind spezifische Codebeispiele erforderlich. Bei der Durchführung wissenschaftlicher Berechnungen in Python ist Scipy eine sehr häufig verwendete Bibliothek, die viele Funktionen für numerische Berechnungen, Optimierung, Statistik und Signalverarbeitung bereitstellt. Bei der Installation der Scipy-Bibliothek treten jedoch manchmal Probleme auf, die dazu führen, dass die Installation fehlschlägt. In diesem Artikel werden die Hauptgründe untersucht, warum die Installation der Scipy-Bibliothek fehlschlägt, und entsprechende Lösungen bereitgestellt. Die Installation abhängiger Pakete ist fehlgeschlagen. Die Scipy-Bibliothek ist von einigen anderen Python-Bibliotheken abhängig, z. B. nu.
 Download-Adressen und Versionsbeschreibungen für verschiedene Versionen von CentOS7-Images (einschließlich der Everything-Version)
Feb 29, 2024 am 09:20 AM
Download-Adressen und Versionsbeschreibungen für verschiedene Versionen von CentOS7-Images (einschließlich der Everything-Version)
Feb 29, 2024 am 09:20 AM
Beim Laden von CentOS-7.0-1406 gibt es viele optionale Versionen. Für normale Benutzer wissen sie nicht, welche sie wählen sollen. Hier ist eine kurze Einführung: (1) CentOS-xxxx-LiveCD.ios und CentOS-xxxx-Was ist der Unterschied zwischen bin-DVD.iso? Ersteres hat nur 700 MB und letzteres 3,8 GB. Der Unterschied besteht nicht nur in der Größe, sondern der wesentlichere Unterschied besteht darin, dass CentOS-xxxx-LiveCD.ios nur in den Speicher geladen und ausgeführt und nicht installiert werden kann. Auf der Festplatte kann nur CentOS-xxx-bin-DVD1.iso installiert werden. (2) CentOS-xxx-bin-DVD1.iso, Ce
 Wie kann das Problem eines Installationsfehlers der Scipy-Bibliothek gelöst werden? Schnelle Methodenfreigabe
Feb 19, 2024 pm 08:02 PM
Wie kann das Problem eines Installationsfehlers der Scipy-Bibliothek gelöst werden? Schnelle Methodenfreigabe
Feb 19, 2024 pm 08:02 PM
Was soll ich tun, wenn die Installation der Scipy-Bibliothek fehlschlägt? Schnelle Lösungsfreigabe, spezifische Codebeispiele sind erforderlich. scipy ist eine leistungsstarke Python-Bibliothek, die häufig im wissenschaftlichen Rechnen verwendet wird und viele Funktionen für mathematische, wissenschaftliche und technische Berechnungen bereitstellt. Bei der Installation von scipy treten jedoch manchmal Probleme auf, die dazu führen, dass die Installation fehlschlägt. In diesem Artikel werden einige häufig auftretende Probleme bei der Installation von Scipy vorgestellt und entsprechende Lösungen sowie spezifische Beispielcodes bereitgestellt. Problem 1: Fehlende abhängige Bibliotheken. Bevor Sie scipy installieren, müssen Sie es zuerst installieren.
 Tutorial zur Installation von PyCharm mit PyTorch
Feb 24, 2024 am 10:09 AM
Tutorial zur Installation von PyCharm mit PyTorch
Feb 24, 2024 am 10:09 AM
Als leistungsstarkes Deep-Learning-Framework wird PyTorch häufig in verschiedenen maschinellen Lernprojekten eingesetzt. Als leistungsstarke integrierte Python-Entwicklungsumgebung kann PyCharm auch bei der Umsetzung von Deep-Learning-Aufgaben eine gute Unterstützung bieten. In diesem Artikel wird die Installation von PyTorch in PyCharm ausführlich vorgestellt und spezifische Codebeispiele bereitgestellt, um den Lesern den schnellen Einstieg in die Verwendung von PyTorch für Deep-Learning-Aufgaben zu erleichtern. Schritt 1: Installieren Sie PyCharm. Zuerst müssen wir sicherstellen, dass wir es haben
 Effiziente Installation: Tipps und Tricks zur schnellen Installation der Pandas-Bibliothek
Feb 21, 2024 am 09:45 AM
Effiziente Installation: Tipps und Tricks zur schnellen Installation der Pandas-Bibliothek
Feb 21, 2024 am 09:45 AM
Effiziente Installation: Tipps und Tricks für die schnelle Installation der Pandas-Bibliothek, die spezifische Codebeispiele erfordert. Übersicht: Pandas ist ein leistungsstarkes Datenverarbeitungs- und Analysetool, das bei Python-Entwicklern sehr beliebt ist. Allerdings kann die Installation der Pandas-Bibliothek manchmal mit einigen Herausforderungen verbunden sein, insbesondere wenn die Netzwerkbedingungen schlecht sind. In diesem Artikel werden einige Tipps und Tricks vorgestellt, die Ihnen bei der schnellen Installation der Pandas-Bibliothek helfen, und es werden spezifische Codebeispiele bereitgestellt. Mit pip installieren: pip ist der offizielle Paketmanager für Python
 OpenCV-Installations-Tutorial: Ein Muss für PyCharm-Benutzer
Feb 22, 2024 pm 09:21 PM
OpenCV-Installations-Tutorial: Ein Muss für PyCharm-Benutzer
Feb 22, 2024 pm 09:21 PM
OpenCV ist eine Open-Source-Bibliothek für Computer Vision und Bildverarbeitung, die in den Bereichen maschinelles Lernen, Bilderkennung, Videoverarbeitung und anderen Bereichen weit verbreitet ist. Bei der Entwicklung mit OpenCV entscheiden sich viele Entwickler für die Verwendung von PyCharm, einer leistungsstarken integrierten Python-Entwicklungsumgebung, um Programme besser debuggen und ausführen zu können. Dieser Artikel bietet PyCharm-Benutzern ein Installations-Tutorial für OpenCV mit spezifischen Codebeispielen. Schritt eins: Python installieren Stellen Sie zunächst sicher, dass Python installiert ist
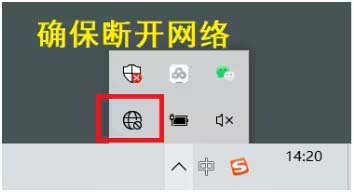 So installieren Sie solidworks2016 – Solidworks2016-Installations-Tutorial
Mar 05, 2024 am 11:25 AM
So installieren Sie solidworks2016 – Solidworks2016-Installations-Tutorial
Mar 05, 2024 am 11:25 AM
Kürzlich haben mich viele Freunde gefragt, wie man SolidWorks2016 installiert. Lassen Sie uns als nächstes das Installations-Tutorial von SolidWorks2016 lernen. 1. Beenden Sie zunächst die Antivirensoftware und stellen Sie sicher, dass Sie die Verbindung zum Netzwerk trennen (wie im Bild gezeigt). 2. Klicken Sie dann mit der rechten Maustaste auf das Installationspaket und wählen Sie „Extrahieren“ in das SW2016-Installationspaket (wie im Bild gezeigt). 3. Doppelklicken Sie, um den dekomprimierten Ordner aufzurufen. Klicken Sie mit der rechten Maustaste auf setup.exe und klicken Sie auf Als Administrator ausführen (wie im Bild gezeigt). 4. Klicken Sie dann auf OK (wie im Bild gezeigt). 5. Aktivieren Sie dann [Einzelmaschineninstallation (auf diesem Computer)] und klicken Sie auf [Weiter] (wie im Bild gezeigt). 6. Geben Sie dann die Seriennummer ein und klicken Sie auf [Weiter] (wie im Bild gezeigt). 7.
 So installieren Sie NeXus Desktop Beautification – Tutorial zur Installation von NeXus Desktop Beautification
Mar 04, 2024 am 11:30 AM
So installieren Sie NeXus Desktop Beautification – Tutorial zur Installation von NeXus Desktop Beautification
Mar 04, 2024 am 11:30 AM
Freunde, wissen Sie, wie man die NeXus-Desktop-Verschönerung installiert? Wenn Sie interessiert sind, schauen Sie sich das an. 1. Laden Sie die neueste Version des Nexus-Desktop-Verschönerungs-Plug-in-Softwarepakets von dieser Website herunter (wie im Bild gezeigt). 2. Entpacken Sie die Nexus-Desktop-Verschönerungs-Plugin-Software und führen Sie die Datei aus (wie im Bild gezeigt). 3. Doppelklicken Sie, um die Benutzeroberfläche der Nexus-Desktop-Verschönerungssoftware zu öffnen und zu öffnen. Bitte lesen Sie die Installationslizenzvereinbarung unten sorgfältig durch, um festzustellen, ob Sie alle Bedingungen der oben genannten Lizenzvereinbarung akzeptieren in dem Bild). 4. Wählen Sie den Zielort aus. Die Software wird im unten aufgeführten Ordner installiert. Um einen anderen Ort auszuwählen und einen neuen Pfad zu erstellen, klicken Sie auf Weiter
