
 Backend-Entwicklung
C++
Wie implementiert man chinesische Eingabe und Ausgabe in einem C-Sprachprogramm?
Backend-Entwicklung
C++
Wie implementiert man chinesische Eingabe und Ausgabe in einem C-Sprachprogramm?
Wie implementiert man chinesische Eingabe und Ausgabe in einem C-Sprachprogramm?


Wie gehe ich mit chinesischen Eingaben und Ausgaben in Programmiersoftware in C-Sprache um?
Mit der weiteren Entwicklung der Globalisierung wird der Anwendungsbereich der chinesischen Sprache immer umfangreicher. Wenn Sie in der C-Sprachprogrammierung chinesische Eingaben und Ausgaben verarbeiten müssen, müssen Sie die Codierung chinesischer Zeichen und die damit verbundenen Verarbeitungsmethoden berücksichtigen. In diesem Artikel werden einige gängige Methoden zur Verarbeitung chinesischer Eingaben und Ausgaben in Programmiersoftware in C-Sprache vorgestellt.
Zunächst müssen wir verstehen, wie chinesische Schriftzeichen kodiert werden. In Computern ist die Unicode-Kodierung die am häufigsten verwendete Methode zur Kodierung chinesischer Zeichen. Die Unicode-Kodierung kann fast alle Zeichen der Welt darstellen, einschließlich chinesischer Zeichen. Bei der Unicode-Codierung werden mehrere Bytes zur Darstellung eines Zeichens verwendet. Zu den spezifischen Codierungsmethoden gehören UTF-8, UTF-16 und UTF-32.
Bei der C-Sprachprogrammierung müssen wir zur Verarbeitung chinesischer Zeichen sicherstellen, dass die Kompilierungsumgebung die Unicode-Codierung unterstützt. Die meisten modernen Compiler und Betriebssysteme unterstützen bereits die Unicode-Kodierung. Sobald wir die Unterstützung der Kompilierungsumgebung sichergestellt haben, können wir den Breitzeichentyp (wchar_t) verwenden, um chinesische Zeichen zu verarbeiten.
Für chinesische Eingaben können wir die wscanf-Funktion verwenden, um breite Zeicheneingaben zu lesen. Die Funktion wscanf kann wie andere Eingabefunktionen eine Formatzeichenfolge verwenden, um das Eingabeformat anzugeben. Der folgende Code zeigt beispielsweise, wie die Funktion wscanf zum Lesen chinesischer Eingaben und Ausgaben verwendet wird:
#include <stdio.h>
#include <wchar.h>
int main() {
wchar_t name[50];
wprintf(L"请输入您的姓名:");
wscanf(L"%ls", name);
wprintf(L"您好,%ls!
", name);
return 0;
}Im obigen Code verwenden wir %ls als Formatzeichenfolge von wscanf, was das Lesen einer breiten Zeichenfolge bedeutet. Ebenso können wir die Funktion wprintf zur Ausgabe chinesischer Zeichen verwenden. Beachten Sie, dass Sie bei der Ausgabe chinesischer Zeichen das Präfix L vor der Zeichenfolge hinzufügen müssen.
Zusätzlich zur Verwendung breiter Zeichentypen zur Verarbeitung chinesischer Ein- und Ausgaben können wir auch einige andere Bibliotheken zur Verarbeitung chinesischer Zeichen verwenden. Beispielsweise bietet die Open-Source-Bibliothek ICU (International Components for Unicode) viele Funktionen zur Verarbeitung von Unicode-Zeichen und kann als Werkzeugbibliothek zur Verarbeitung chinesischer Ein- und Ausgaben verwendet werden.
Bei Verwendung der ICU-Bibliothek müssen wir die ICU-Header-Datei und einen Link zur ICU-Bibliothek verwenden. Das Folgende ist ein Beispielcode, der die ICU-Bibliothek zur Verarbeitung chinesischer Eingaben und Ausgaben verwendet:
#include <stdio.h>
#include <unicode/ustdio.h>
#include <unicode/ustring.h>
int main() {
UChar name[50];
u_printf(u"请输入您的姓名:");
u_scanf(u"%ls", name);
u_printf(u"您好,%ls!
", name);
return 0;
}Im obigen Code verwenden wir den UChar-Typ zur Darstellung von Unicode-Zeichen und verwenden die Funktionen u_printf und u_scanf für chinesische Eingaben und Ausgaben.
Es ist zu beachten, dass Sie bei der Verarbeitung chinesischer Eingaben und Ausgaben unabhängig davon, ob Sie Breitzeichentypen oder andere Bibliotheken verwenden, die Konsistenz der Codierungsmethode sicherstellen müssen. Wenn die Eingabe beispielsweise die UTF-8-Kodierung verwendet, müssen Sie sie bei der Verarbeitung chinesischer Zeichen in die entsprechende Kodierung konvertieren.
Kurz gesagt, bei der Verarbeitung chinesischer Ein- und Ausgaben in der C-Sprachprogrammierung müssen Sie die Kodierung chinesischer Zeichen und die entsprechenden Verarbeitungsmethoden berücksichtigen. Die Verwendung von Breitzeichentypen oder anderen Bibliotheken zur Verarbeitung chinesischer Ein- und Ausgaben ist ein gängiger Ansatz. Ich hoffe, dass dieser Artikel bei der Verarbeitung chinesischer Eingaben und Ausgaben in C-Programmiersoftware hilfreich sein wird.
Das obige ist der detaillierte Inhalt vonWie implementiert man chinesische Eingabe und Ausgabe in einem C-Sprachprogramm?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Empfehlen Sie fünf praktische C-Programmiersoftware
Feb 18, 2024 pm 09:51 PM
Empfehlen Sie fünf praktische C-Programmiersoftware
Feb 18, 2024 pm 09:51 PM
Als weit verbreitete Programmiersprache war die Sprache C schon immer bei Entwicklern beliebt. Beim Programmieren in der Sprache C ist es sehr wichtig, die richtige Programmiersoftware auszuwählen. In diesem Artikel werden fünf praktische C-Programmiertools vorgestellt, mit denen Sie die Programmiereffizienz und Entwicklungsqualität verbessern können. VisualStudioCode (VSCode) VisualStudioCode ist ein leichter plattformübergreifender Code-Editor mit einem leistungsstarken Plug-in-Ökosystem, das mehrere Sprachen und Frameworks unterstützt. VS
 Unverzichtbare Software für die C-Sprachprogrammierung: Fünf gute Helfer, die Einsteigern empfohlen werden
Feb 20, 2024 pm 08:18 PM
Unverzichtbare Software für die C-Sprachprogrammierung: Fünf gute Helfer, die Einsteigern empfohlen werden
Feb 20, 2024 pm 08:18 PM
Die Sprache C ist eine grundlegende und wichtige Programmiersprache. Für Anfänger ist es sehr wichtig, die richtige Programmiersoftware auszuwählen. Es gibt viele verschiedene Optionen für C-Programmiersoftware auf dem Markt, aber für Anfänger kann es etwas verwirrend sein, sich für die richtige zu entscheiden. In diesem Artikel werden Anfängern fünf C-Programmiersoftware empfohlen, um ihnen den schnellen Einstieg zu erleichtern und ihre Programmierkenntnisse zu verbessern. Dev-C++Dev-C++ ist eine kostenlose und quelloffene integrierte Entwicklungsumgebung (IDE), die sich besonders für Anfänger eignet. Es ist einfach und benutzerfreundlich und integriert einen Editor,
 Wie implementiert man chinesische Eingabe und Ausgabe in einem C-Sprachprogramm?
Feb 19, 2024 pm 08:22 PM
Wie implementiert man chinesische Eingabe und Ausgabe in einem C-Sprachprogramm?
Feb 19, 2024 pm 08:22 PM
Wie gehe ich mit der chinesischen Ein- und Ausgabe in C-Programmiersoftware um? Mit der weiteren Entwicklung der Globalisierung wird der Anwendungsbereich der chinesischen Sprache immer umfangreicher. Wenn Sie in der C-Sprachprogrammierung chinesische Eingaben und Ausgaben verarbeiten müssen, müssen Sie die Codierung chinesischer Zeichen und die damit verbundenen Verarbeitungsmethoden berücksichtigen. In diesem Artikel werden einige gängige Methoden zur Verarbeitung chinesischer Eingaben und Ausgaben in Programmiersoftware in C-Sprache vorgestellt. Zuerst müssen wir verstehen, wie chinesische Schriftzeichen kodiert werden. In Computern ist die Unicode-Kodierung die am häufigsten verwendete Methode zur Kodierung chinesischer Zeichen. Unicode-Kodierung kann darstellen
 Fünf Programmiersoftware für den Einstieg in das Erlernen der C-Sprache
Feb 19, 2024 pm 04:51 PM
Fünf Programmiersoftware für den Einstieg in das Erlernen der C-Sprache
Feb 19, 2024 pm 04:51 PM
Als weit verbreitete Programmiersprache ist die C-Sprache eine der grundlegenden Sprachen, die für diejenigen erlernt werden müssen, die sich mit Computerprogrammierung befassen möchten. Für Anfänger kann das Erlernen einer neuen Programmiersprache jedoch etwas schwierig sein, insbesondere aufgrund des Mangels an entsprechenden Lernwerkzeugen und Lehrmaterialien. In diesem Artikel werde ich fünf Programmiersoftware vorstellen, die Anfängern den Einstieg in die C-Sprache erleichtert und Ihnen einen schnellen Einstieg ermöglicht. Die erste Programmiersoftware war Code::Blocks. Code::Blocks ist eine kostenlose integrierte Open-Source-Entwicklungsumgebung (IDE) für
 Analysieren Sie häufige Eingabeformatprobleme der Scanf-Funktion der C-Sprache
Feb 19, 2024 am 09:30 AM
Analysieren Sie häufige Eingabeformatprobleme der Scanf-Funktion der C-Sprache
Feb 19, 2024 am 09:30 AM
Analyse häufig gestellter Fragen zum C-Sprach-Scanf-Eingabeformat Beim Programmieren in C-Sprache ist die Eingabefunktion für die Ausführung des Programms sehr wichtig. Wir verwenden häufig die Scanf-Funktion, um Benutzereingaben zu empfangen. Aufgrund der Vielfalt und Komplexität der Eingabe können jedoch einige häufige Probleme bei der Verwendung der Scanf-Funktion auftreten. In diesem Artikel werden einige häufig auftretende Probleme mit dem Scanf-Eingabeformat analysiert und spezifische Codebeispiele bereitgestellt. Die eingegebenen Zeichen stimmen nicht mit dem Format überein. Bei Verwendung der scanf-Funktion müssen wir das Eingabeformat angeben. Beispiel: „%d
 Wie implementiert man die Kodierung und Dekodierung chinesischer Zeichen in der C-Sprachprogrammierung?
Feb 19, 2024 pm 02:15 PM
Wie implementiert man die Kodierung und Dekodierung chinesischer Zeichen in der C-Sprachprogrammierung?
Feb 19, 2024 pm 02:15 PM
In der modernen Computerprogrammierung ist die Sprache C eine der am häufigsten verwendeten Programmiersprachen. Obwohl die C-Sprache selbst die chinesische Kodierung und Dekodierung nicht direkt unterstützt, können wir einige Technologien und Bibliotheken verwenden, um diese Funktion zu erreichen. In diesem Artikel wird erläutert, wie die chinesische Kodierung und Dekodierung in C-Sprachprogrammiersoftware implementiert wird. Um die chinesische Kodierung und Dekodierung zu implementieren, müssen wir zunächst die Grundkonzepte der chinesischen Kodierung verstehen. Derzeit ist das am häufigsten verwendete chinesische Codierungsschema die Unicode-Codierung. Die Unicode-Kodierung weist jedem Zeichen einen eindeutigen numerischen Wert zu, sodass bei der Berechnung
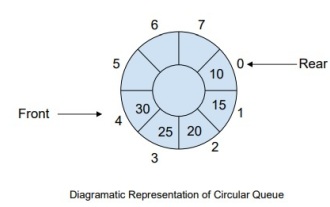 Wie verwalte ich eine vollständige kreisförmige Ereigniswarteschlange in C++?
Sep 04, 2023 pm 06:41 PM
Wie verwalte ich eine vollständige kreisförmige Ereigniswarteschlange in C++?
Sep 04, 2023 pm 06:41 PM
Einführung CircularQueue ist eine Verbesserung linearer Warteschlangen, die eingeführt wurde, um das Problem der Speicherverschwendung in linearen Warteschlangen zu lösen. Zirkuläre Warteschlangen nutzen das FIFO-Prinzip, um Elemente daraus einzufügen und daraus zu löschen. In diesem Tutorial besprechen wir den Betrieb einer zirkulären Warteschlange und deren Verwaltung. Was ist eine kreisförmige Warteschlange? Eine kreisförmige Warteschlange ist eine andere Art von Warteschlange in der Datenstruktur, bei der das Front-End und das Back-End miteinander verbunden sind. Er wird auch als Ringpuffer bezeichnet. Sie funktioniert ähnlich wie eine lineare Warteschlange. Warum müssen wir also eine neue Warteschlange in die Datenstruktur einführen? Wenn Sie eine lineare Warteschlange verwenden und die Warteschlange ihr maximales Limit erreicht, ist möglicherweise etwas Speicherplatz vor dem Endzeiger vorhanden. Dies führt zu Speicherverlust und ein guter Algorithmus sollte in der Lage sein, die Ressourcen voll auszunutzen. Um die Speicherverschwendung zu lösen
 Wie sortiere ich chinesische Zeichen in einer C-Sprachumgebung?
Feb 18, 2024 pm 02:10 PM
Wie sortiere ich chinesische Zeichen in einer C-Sprachumgebung?
Feb 18, 2024 pm 02:10 PM
Wie implementiert man die Sortierfunktion für chinesische Zeichen in C-Programmiersoftware? In der modernen Gesellschaft ist die Sortierfunktion für chinesische Zeichen eine der wesentlichen Funktionen in vielen Softwareprogrammen. Ob in Textverarbeitungsprogrammen, Suchmaschinen oder Datenbanksystemen: Chinesische Schriftzeichen müssen sortiert werden, um chinesische Textdaten besser anzeigen und verarbeiten zu können. Wie implementiert man in der C-Sprachprogrammierung die Sortierfunktion für chinesische Zeichen? Eine Methode wird im Folgenden kurz vorgestellt. Um die Sortierfunktion für chinesische Zeichen in der C-Sprache zu implementieren, müssen wir zunächst die Zeichenfolgenvergleichsfunktion verwenden. Ran
