
 Technologie-Peripheriegeräte
KI
Das RNN-Modell fordert die Transformer-Hegemonie heraus! 1 % Kosten und Leistung vergleichbar mit Mistral-7B, unterstützt mehr als 100 Sprachen, die meisten auf der Welt
Technologie-Peripheriegeräte
KI
Das RNN-Modell fordert die Transformer-Hegemonie heraus! 1 % Kosten und Leistung vergleichbar mit Mistral-7B, unterstützt mehr als 100 Sprachen, die meisten auf der Welt
Das RNN-Modell fordert die Transformer-Hegemonie heraus! 1 % Kosten und Leistung vergleichbar mit Mistral-7B, unterstützt mehr als 100 Sprachen, die meisten auf der Welt

Während große Modelle auf den Markt kommen, wird auch der Status von Transformer nach und nach in Frage gestellt.
Kürzlich hat RWKV das Eagle 7B-Modell veröffentlicht, das auf der neuesten RWKV-v5-Architektur basiert.
Eagle 7B glänzt in mehrsprachigen Benchmarks und liegt in englischen Tests auf Augenhöhe mit Topmodellen.
Gleichzeitig verwendet Eagle 7B eine RNN-Architektur, wodurch die Inferenzkosten um mehr als das 10- bis 100-fache reduziert werden. Es kann als das umweltfreundlichste 7B bezeichnet werden Modell der Welt.
Da das Papier zu RWKV-v5 möglicherweise erst im nächsten Monat veröffentlicht wird, stellen wir zunächst das Papier zu RWKV zur Verfügung, der ersten Nicht-Transformer-Architektur, die Parameter auf mehrere zehn Milliarden skaliert.
 Bilder
Bilder
Papieradresse: https://arxiv.org/pdf/2305.13048.pdf
EMNLP 2023 hat diese Arbeit von führenden Universitäten, Forschungseinrichtungen und Technologieunternehmen angenommen Welt.
Das Folgende ist das offizielle Bild von Eagle 7B, das zeigt, dass dieser Adler über Transformers fliegt.
 Bilder
Bilder
Eagle 7B
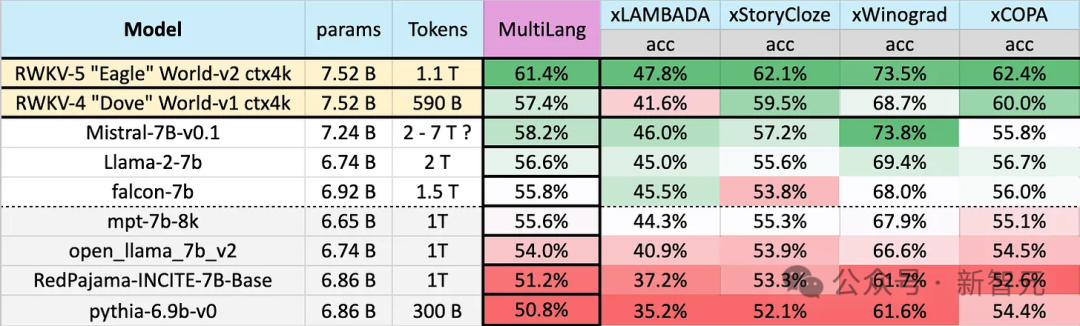
Eagle 7B verwendet Trainingsdaten von 1,1T (Billionen) Token aus mehr als 100 Sprachen. Im untenstehenden mehrsprachigen Benchmark-Test belegt Eagle 7B im Durchschnitt den ersten Platz.
Benchmarks umfassen xLAMBDA, xStoryCloze, xWinograd und xCopa, die 23 Sprachen abdecken, sowie vernünftiges Denken in ihren jeweiligen Sprachen.
Eagle 7B gewann in drei von ihnen den ersten Platz. Obwohl einer von ihnen Mistral-7B nicht besiegte und den zweiten Platz belegte, waren die vom Gegner verwendeten Trainingsdaten viel höher als die von Eagle.
 Bilder
Bilder
Der unten abgebildete Englischtest enthält 12 separate Benchmarks, gesundes Menschenverstandsdenken und Weltwissen.
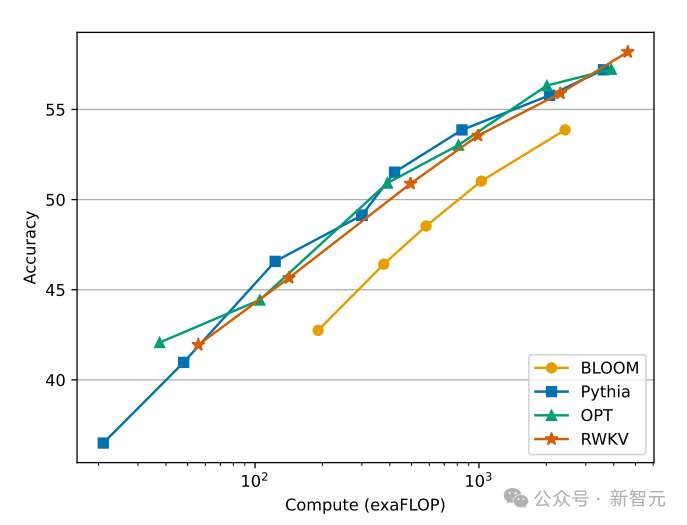
Im englischen Leistungstest liegt das Niveau von Eagle 7B nahe bei Falcon (1,5T), LLaMA2 (2T), Mistral (>2T) und ist vergleichbar mit MPT-7B, das ebenfalls etwa 1T-Training verwendet Daten.
 Bilder
Bilder
Und in beiden Tests hat die neue v5-Architektur im Vergleich zur vorherigen v4 insgesamt einen großen Sprung gemacht.
Eagle 7B wird derzeit von der Linux Foundation gehostet und ist unter der Apache 2.0-Lizenz für die uneingeschränkte persönliche oder kommerzielle Nutzung lizenziert.
Mehrsprachige Unterstützung
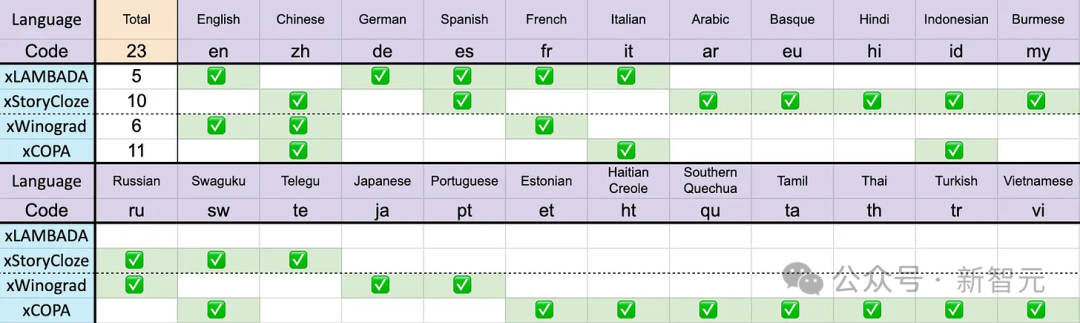
Wie bereits erwähnt, stammen die Trainingsdaten von Eagle 7B aus mehr als 100 Sprachen, während die 4 oben verwendeten mehrsprachigen Benchmarks nur 23 Sprachen umfassen.
 Bilder
Bilder
Obwohl es den ersten Platz erreichte, musste Eagle 7B insgesamt einen Verlust einstecken. Schließlich kann der Benchmark-Test die Leistung des Modells in mehr als 70 anderen Sprachen nicht direkt bewerten.
Die zusätzlichen Schulungskosten werden Ihnen nicht dabei helfen, Ihr Ranking zu verbessern. Wenn Sie sich auf Englisch konzentrieren, erzielen Sie möglicherweise bessere Ergebnisse als jetzt.
——Warum macht RWKV das? Der Beamte sagte:
Inklusive KI für alle auf dieser Welt aufbauen – nicht nur für die Engländer
Unter den vielen Rückmeldungen zum RWKV-Modell ist das häufigste:
Der mehrsprachige Ansatz schadet Die englische Bewertung des Modells hat die Entwicklung des linearen Transformators verlangsamt.
Es ist unfair, die mehrsprachige Leistung mit einem rein englischen Modell zu vergleichen. Offiziell heißt es: „In den meisten Fällen stimmen wir diesen zu.“ Meinungen,"
„Aber wir haben nicht vor, das zu ändern, denn wir bauen KI für die Welt – und es ist nicht nur eine englischsprachige Welt.“ Die Weltbevölkerung spricht Englisch (ungefähr 1,3 Milliarden Menschen), aber durch die Unterstützung der 25 wichtigsten Sprachen der Welt kann das Modell ungefähr 4 Milliarden Menschen oder 50 % der Weltbevölkerung erreichen.
 Das Team hofft, dass die künstliche Intelligenz der Zukunft allen helfen kann, indem sie beispielsweise die Ausführung von Modellen auf Low-End-Hardware zu einem niedrigen Preis ermöglicht und beispielsweise mehr Sprachen unterstützt.
Das Team hofft, dass die künstliche Intelligenz der Zukunft allen helfen kann, indem sie beispielsweise die Ausführung von Modellen auf Low-End-Hardware zu einem niedrigen Preis ermöglicht und beispielsweise mehr Sprachen unterstützt.
Das Team wird den mehrsprachigen Datensatz schrittweise erweitern, um ein breiteres Spektrum an Sprachen zu unterstützen und die Abdeckung langsam auf 100 % der Regionen der Welt auszudehnen – um sicherzustellen, dass keine Sprache übersehen wird.
Datensatz + skalierbare Architektur
Während des Trainingsprozesses des Modells gibt es ein bemerkenswertes Phänomen:
Da der Umfang der Trainingsdaten weiter zunimmt, verbessert sich die Leistung des Modells allmählich. Wenn die Trainingsdaten etwa 300 B erreichen, zeigt das Modell eine ähnliche Leistung wie Python-6.9b mit einer Trainingsdatengröße von 300 B.
Bild
Dieses Phänomen ist das gleiche wie bei einem zuvor mit der RWKV-v4-Architektur durchgeführten Experiment – das heißt, wenn die Trainingsdatengröße gleich ist, ist die Leistung eines linearen Transformators wie RWKV gleich ähnlich wie Transformer.
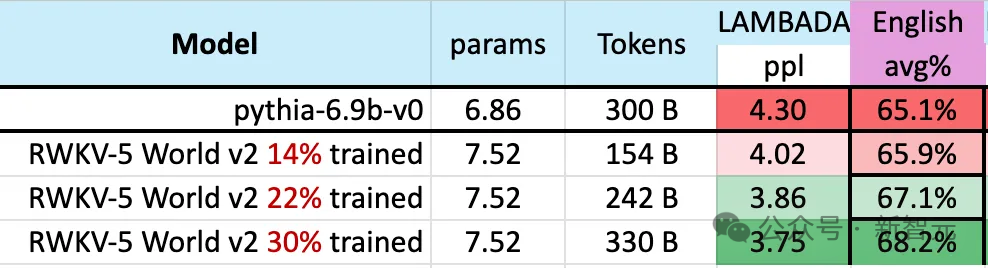 Wir kommen also nicht umhin zu fragen: Wenn dies tatsächlich der Fall ist, sind die Daten für die Leistungsverbesserung des Modells wichtiger als die genaue Architektur?
Wir kommen also nicht umhin zu fragen: Wenn dies tatsächlich der Fall ist, sind die Daten für die Leistungsverbesserung des Modells wichtiger als die genaue Architektur?
Bild
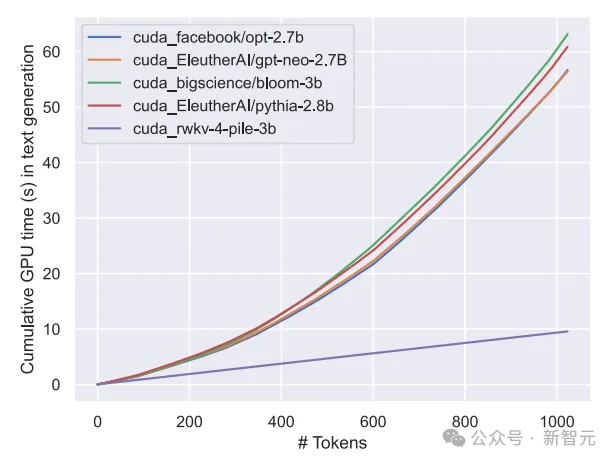
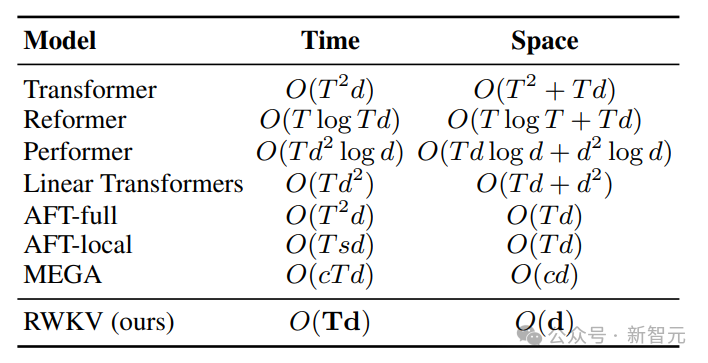
Wir wissen, dass die Berechnungs- und Speicherkosten des Transformer-Klassenmodells quadratisch sind, während in der Abbildung oben die Berechnungskosten der RWKV-Architektur nur linear mit der Anzahl der Token ansteigen.
 Vielleicht sollten wir nach effizienteren und skalierbaren Architekturen suchen, um die Zugänglichkeit zu verbessern, die Kosten von KI für alle zu senken und die Umweltbelastung zu verringern.
Vielleicht sollten wir nach effizienteren und skalierbaren Architekturen suchen, um die Zugänglichkeit zu verbessern, die Kosten von KI für alle zu senken und die Umweltbelastung zu verringern.
RWKV
Die RWKV-Architektur ist ein RNN mit LLM-Leistung auf GPT-Ebene und kann gleichzeitig wie Transformer parallel trainiert werden.
RWKV vereint die Vorteile von RNN und Transformer – hervorragende Leistung, schnelle Inferenz, schnelles Training, Einsparung von VRAM, „unbegrenzte“ Kontextlänge und freie Satzeinbettung. RWKV nutzt den Aufmerksamkeitsmechanismus nicht.
Die folgende Abbildung zeigt den Vergleich der Rechenkosten zwischen RWKV- und Transformer-Modellen:
Bilder
Um die zeitlichen und räumlichen Komplexitätsprobleme von Transformer zu lösen, haben Forscher verschiedene Architekturen vorgeschlagen:
 Bild
Bild
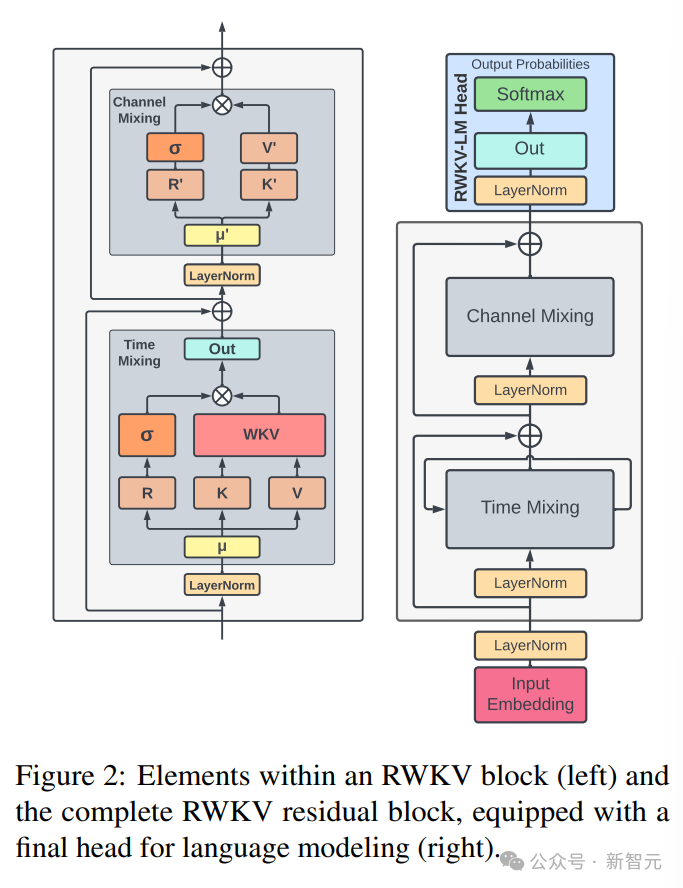
Die RWKV-Architektur besteht aus einer Reihe gestapelter Restblöcke. Jeder Restblock besteht aus einem zeitlichen Misch- und einem Kanalmisch-Unterblock mit einer Schleifenstruktur.
 Die linke Seite des Das Bild unten zeigt RWKV-Blockelemente, rechts der RWKV-Restblock und der letzte Header für die Sprachmodellierung.
Die linke Seite des Das Bild unten zeigt RWKV-Blockelemente, rechts der RWKV-Restblock und der letzte Header für die Sprachmodellierung.
Bild
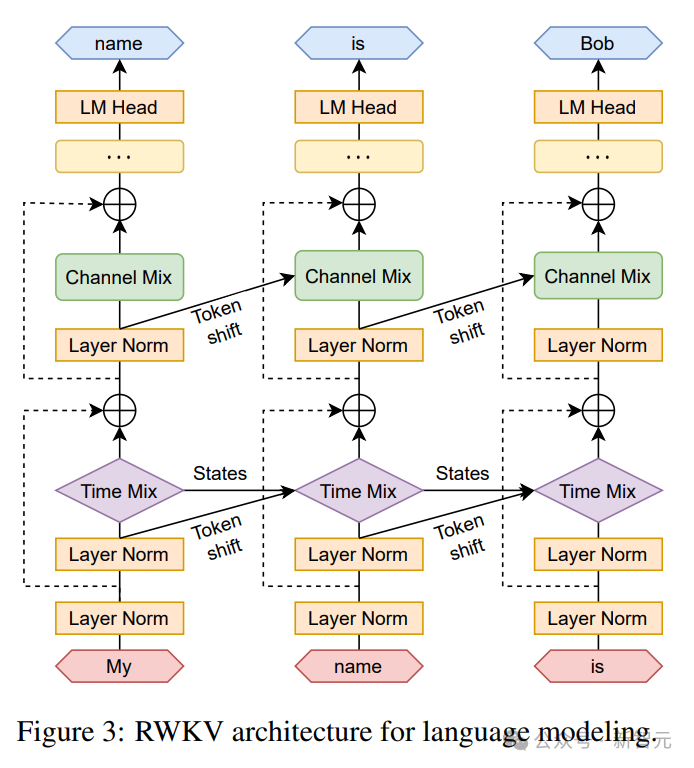
Rekursion kann als lineare Interpolation zwischen der aktuellen Eingabe und der Eingabe des vorherigen Zeitschritts ausgedrückt werden (wie durch die diagonale Linie in der Abbildung unten dargestellt), die für jede Linearität unabhängig sein kann Projektion der Eingabeeinbettungsanpassung.
 Hier wird auch ein Vektor eingeführt, der den aktuellen Token separat verwaltet, um mögliche Verschlechterungen auszugleichen.
Hier wird auch ein Vektor eingeführt, der den aktuellen Token separat verwaltet, um mögliche Verschlechterungen auszugleichen.
 Bilder
Bilder
RWKV kann im sogenannten zeitlichen Parallelitätsmodus effizient parallelisiert werden (Matrixmultiplikation).
In einem wiederkehrenden Netzwerk wird normalerweise die Ausgabe des vorherigen Moments als Eingabe des aktuellen Moments verwendet. Dies zeigt sich insbesondere bei der autoregressiven Decodierungsinferenz für Sprachmodelle, bei der jedes Token berechnet werden muss, bevor der nächste Schritt eingegeben wird, sodass RWKV seine RNN-ähnliche Struktur, den sogenannten temporalen Modus, nutzen kann.
In diesem Fall kann RWKV für die Dekodierung während der Inferenz bequem rekursiv formuliert werden. Dabei wird jedes Ausgabetoken nur auf der Grundlage des neuesten Status genutzt. Die Größe des Status ist konstant, im Gegensatz dazu ist die Sequenzlänge irrelevant.
fungiert dann als RNN-Decoder und sorgt für konstante Geschwindigkeit und Speicherbedarf im Verhältnis zur Sequenzlänge, sodass längere Sequenzen effizienter verarbeitet werden können.
Im Gegensatz dazu wächst der KV-Cache der Selbstaufmerksamkeit kontinuierlich im Verhältnis zur Sequenzlänge, was zu einer geringeren Effizienz und einem erhöhten Speicherbedarf und einer höheren Zeit führt, wenn die Sequenz länger wird.
Referenz:
Das obige ist der detaillierte Inhalt vonDas RNN-Modell fordert die Transformer-Hegemonie heraus! 1 % Kosten und Leistung vergleichbar mit Mistral-7B, unterstützt mehr als 100 Sprachen, die meisten auf der Welt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1385
1385
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Wie man Deepseek vor Ort fein abgestimmt
Feb 19, 2025 pm 05:21 PM
Wie man Deepseek vor Ort fein abgestimmt
Feb 19, 2025 pm 05:21 PM
Die lokale Feinabstimmung von Deepseek-Klasse-Modellen steht vor der Herausforderung unzureichender Rechenressourcen und Fachkenntnisse. Um diese Herausforderungen zu bewältigen, können die folgenden Strategien angewendet werden: Modellquantisierung: Umwandlung von Modellparametern in Ganzzahlen mit niedriger Präzision und Reduzierung des Speicherboots. Verwenden Sie kleinere Modelle: Wählen Sie ein vorgezogenes Modell mit kleineren Parametern für eine einfachere lokale Feinabstimmung aus. Datenauswahl und Vorverarbeitung: Wählen Sie hochwertige Daten aus und führen Sie eine geeignete Vorverarbeitung durch, um eine schlechte Datenqualität zu vermeiden, die die Modelleffizienz beeinflusst. Batch -Training: Laden Sie für große Datensätze Daten in Stapel für das Training, um den Speicherüberlauf zu vermeiden. Beschleunigung mit GPU: Verwenden Sie unabhängige Grafikkarten, um den Schulungsprozess zu beschleunigen und die Trainingszeit zu verkürzen.
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 Für nur 250 US-Dollar zeigt Ihnen der technische Leiter von Hugging Face Schritt für Schritt, wie Sie Llama 3 verfeinern
May 06, 2024 pm 03:52 PM
Für nur 250 US-Dollar zeigt Ihnen der technische Leiter von Hugging Face Schritt für Schritt, wie Sie Llama 3 verfeinern
May 06, 2024 pm 03:52 PM
Die bekannten großen Open-Source-Sprachmodelle wie Llama3 von Meta, Mistral- und Mixtral-Modelle von MistralAI und Jamba von AI21 Lab sind zu Konkurrenten von OpenAI geworden. In den meisten Fällen müssen Benutzer diese Open-Source-Modelle anhand ihrer eigenen Daten verfeinern, um das Potenzial des Modells voll auszuschöpfen. Es ist nicht schwer, ein großes Sprachmodell (wie Mistral) im Vergleich zu einem kleinen mithilfe von Q-Learning auf einer einzelnen GPU zu optimieren, aber die effiziente Feinabstimmung eines großen Modells wie Llama370b oder Mixtral blieb bisher eine Herausforderung . Deshalb Philipp Sch, technischer Leiter von HuggingFace
 Was tun, wenn der Edge-Browser zu viel Speicher beansprucht? Was tun, wenn der Edge-Browser zu viel Speicher beansprucht?
May 09, 2024 am 11:10 AM
Was tun, wenn der Edge-Browser zu viel Speicher beansprucht? Was tun, wenn der Edge-Browser zu viel Speicher beansprucht?
May 09, 2024 am 11:10 AM
1. Rufen Sie zunächst den Edge-Browser auf und klicken Sie auf die drei Punkte in der oberen rechten Ecke. 2. Wählen Sie dann in der Taskleiste [Erweiterungen] aus. 3. Schließen oder deinstallieren Sie als Nächstes die Plug-Ins, die Sie nicht benötigen.
 Übertrifft DPO umfassend: Das Team von Chen Danqi schlug eine einfache Präferenzoptimierung (SimPO) vor und verfeinerte außerdem das stärkste 8B-Open-Source-Modell
Jun 01, 2024 pm 04:41 PM
Übertrifft DPO umfassend: Das Team von Chen Danqi schlug eine einfache Präferenzoptimierung (SimPO) vor und verfeinerte außerdem das stärkste 8B-Open-Source-Modell
Jun 01, 2024 pm 04:41 PM
Um große Sprachmodelle (LLMs) an menschlichen Werten und Absichten auszurichten, ist es wichtig, menschliches Feedback zu lernen, um sicherzustellen, dass sie nützlich, ehrlich und harmlos sind. Im Hinblick auf die Ausrichtung von LLM ist Reinforcement Learning basierend auf menschlichem Feedback (RLHF) eine wirksame Methode. Obwohl die Ergebnisse der RLHF-Methode ausgezeichnet sind, gibt es einige Herausforderungen bei der Optimierung. Dazu gehört das Training eines Belohnungsmodells und die anschließende Optimierung eines Richtlinienmodells, um diese Belohnung zu maximieren. Kürzlich haben einige Forscher einfachere Offline-Algorithmen untersucht, darunter die direkte Präferenzoptimierung (Direct Preference Optimization, DPO). DPO lernt das Richtlinienmodell direkt auf der Grundlage von Präferenzdaten, indem es die Belohnungsfunktion in RLHF parametrisiert, wodurch die Notwendigkeit eines expliziten Belohnungsmodells entfällt. Diese Methode ist einfach und stabil
 Keine OpenAI-Daten erforderlich, schließen Sie sich der Liste der großen Codemodelle an! UIUC veröffentlicht StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Keine OpenAI-Daten erforderlich, schließen Sie sich der Liste der großen Codemodelle an! UIUC veröffentlicht StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
An der Spitze der Softwaretechnologie kündigte die Gruppe von UIUC Zhang Lingming zusammen mit Forschern der BigCode-Organisation kürzlich das StarCoder2-15B-Instruct-Großcodemodell an. Diese innovative Errungenschaft erzielte einen bedeutenden Durchbruch bei Codegenerierungsaufgaben, übertraf erfolgreich CodeLlama-70B-Instruct und erreichte die Spitze der Codegenerierungsleistungsliste. Die Einzigartigkeit von StarCoder2-15B-Instruct liegt in seiner reinen Selbstausrichtungsstrategie. Der gesamte Trainingsprozess ist offen, transparent und völlig autonom und kontrollierbar. Das Modell generiert über StarCoder2-15B Tausende von Anweisungen als Reaktion auf die Feinabstimmung des StarCoder-15B-Basismodells, ohne auf teure manuelle Annotationen angewiesen zu sein.
