
 Java
javaLernprogramm
Erweiterung und Anpassung von Java Map: Erstellen Sie Ihre eigene Datenstruktur, um Ihren Anpassungsanforderungen gerecht zu werden
Java
javaLernprogramm
Erweiterung und Anpassung von Java Map: Erstellen Sie Ihre eigene Datenstruktur, um Ihren Anpassungsanforderungen gerecht zu werden
Erweiterung und Anpassung von Java Map: Erstellen Sie Ihre eigene Datenstruktur, um Ihren Anpassungsanforderungen gerecht zu werden


In diesem vom PHP-Editor Xigua verfassten Artikel geht es um die Erweiterung und Anpassung von Java Map, sodass Sie eine exklusive Datenstruktur erstellen können, die Ihren individuellen Anforderungen entspricht. Durch angepasste Vorgänge können Sie eine flexiblere und effizientere Datenverwaltung erreichen, um verschiedene Anpassungsanforderungen zu erfüllen. Werfen wir einen genaueren Blick darauf, wie Sie die leistungsstarken Funktionen von Java Map nutzen können, um bessere Datenverarbeitungslösungen für Ihre Projekte bereitzustellen.
1. Java-Karte erweitern
Der einfachste Weg, Java Map zu erweitern, besteht darin, eine neue Klasse zu erstellen, die von der java.util.Map-Schnittstelle erbt. Diese neue Klasse kann neue Methoden oder Eigenschaften hinzufügen und auch Methoden in der Map-Schnittstelle überschreiben. Beispielsweise können wir eine neue Map-Klasse erstellen und eine neue Methode hinzufügen, um die Summe von Schlüssel-Wert-Paaren zu berechnen:
public class SummingMap<K, V extends Number> extends HashMap<K, V> {
public double sumValues() {
double sum = 0;
for (V value : values()) {
sum += value.doubleValue();
}
return sum;
}
}Diese neue Map-Klasse kann wie eine normale Map verwendet werden, verfügt aber auch über die neue Funktionalität, die Summe von Schlüssel-Wert-Paaren zu berechnen.
2. Passen Sie die Durchlaufreihenfolge von Java Map an
Standardmäßig durchläuft Java Map den Hashwert des Schlüssels. Aber manchmal müssen wir die Karte möglicherweise in einer anderen Reihenfolge durchlaufen, beispielsweise in der natürlichen Reihenfolge der Schlüssel oder der Einfügereihenfolge. Wir können die Durchlaufreihenfolge der Karte anpassen, indem wir die Methode keySet() in der Kartenschnittstelle überschreiben. Beispielsweise können wir eine neue Map-Klasse erstellen, die die Schlüssel in ihrer natürlichen Reihenfolge durchläuft:
public class TreeMap<K extends Comparable<K>, V> extends HashMap<K, V> {
@Override
public Set<K> keySet() {
return new TreeSet<>(super.keySet());
}
}Diese neue Map-Klasse kann wie eine normale Map verwendet werden, durchläuft die Schlüssel jedoch in ihrer natürlichen Reihenfolge.
3. Erstellen Sie einen benutzerdefinierten Serialisierer
Standardmäßig werden Java Maps mithilfe des in Java integrierten Serialisierungsmechanismus serialisiert. Aber manchmal müssen wir möglicherweise einen benutzerdefinierten Serialisierer verwenden, um die Karte zu serialisieren. Wir können einen benutzerdefinierten Serialisierer erstellen, indem wir die Schnittstelle java.io.Serializable implementieren und eine writeObject()-Methode in der Klasse definieren. Beispielsweise können wir eine neue Map-Klasse erstellen und einen benutzerdefinierten Serialisierer verwenden, um die Map zu serialisieren:
public class CustomMap<K, V> extends HashMap<K, V> implements Serializable {
private static final long serialVersionUID = 1L;
@Override
private void writeObject(ObjectOutputStream out) throws IOException {
out.writeInt(size());
for (Entry<K, V> entry : entrySet()) {
out.writeObject(entry.geTKEy());
out.writeObject(entry.getValue());
}
}
}Diese neue Map-Klasse kann wie eine normale Map verwendet werden, verwendet jedoch einen benutzerdefinierten Serialisierer, um die Map zu serialisieren.
4. Verwenden Sie Bibliotheken von Drittanbietern, um Java Map zu erweitern und anzupassen
Zusätzlich zu den oben genannten Methoden können wir auch Bibliotheken von Drittanbietern verwenden, um Java Map zu erweitern und anzupassen. Beispielsweise können wir die Guava-Bibliothek verwenden, um eine „gleichzeitige“ Karte zu erstellen, die Apache Commons Collections-Bibliothek, um eine „sortierte“ Karte zu erstellen, oder die Jackson-Bibliothek, um eine „JSON“-formatierte Karte zu erstellen. 5. Vorsichtsmaßnahmen Beim Erweitern und Anpassen von Java Map müssen Sie die folgenden Punkte beachten:
Stellen Sie sicher, dass die erweiterte oder angepasste Map-Klasse weiterhin dem Vertrag der Map-Schnittstelle entspricht.
Berücksichtigen Sie beim Erweitern oder Anpassen der Map-Klasse die Leistung und Speichernutzung.Wenn Sie die erweiterte oder angepasste Map-Klasse mit anderen Anwendungen teilen müssen, müssen Sie sicherstellen, dass diese Anwendungen auch dieselbe Erweiterung oder angepasste Bibliothek installiert haben.
- Ich hoffe, dieser Artikel ist hilfreich für Sie, vielen Dank fürs Lesen!
Das obige ist der detaillierte Inhalt vonErweiterung und Anpassung von Java Map: Erstellen Sie Ihre eigene Datenstruktur, um Ihren Anpassungsanforderungen gerecht zu werden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Wie man Deepseek vor Ort fein abgestimmt
Feb 19, 2025 pm 05:21 PM
Wie man Deepseek vor Ort fein abgestimmt
Feb 19, 2025 pm 05:21 PM
Die lokale Feinabstimmung von Deepseek-Klasse-Modellen steht vor der Herausforderung unzureichender Rechenressourcen und Fachkenntnisse. Um diese Herausforderungen zu bewältigen, können die folgenden Strategien angewendet werden: Modellquantisierung: Umwandlung von Modellparametern in Ganzzahlen mit niedriger Präzision und Reduzierung des Speicherboots. Verwenden Sie kleinere Modelle: Wählen Sie ein vorgezogenes Modell mit kleineren Parametern für eine einfachere lokale Feinabstimmung aus. Datenauswahl und Vorverarbeitung: Wählen Sie hochwertige Daten aus und führen Sie eine geeignete Vorverarbeitung durch, um eine schlechte Datenqualität zu vermeiden, die die Modelleffizienz beeinflusst. Batch -Training: Laden Sie für große Datensätze Daten in Stapel für das Training, um den Speicherüberlauf zu vermeiden. Beschleunigung mit GPU: Verwenden Sie unabhängige Grafikkarten, um den Schulungsprozess zu beschleunigen und die Trainingszeit zu verkürzen.
 Was tun, wenn der Edge-Browser zu viel Speicher beansprucht? Was tun, wenn der Edge-Browser zu viel Speicher beansprucht?
May 09, 2024 am 11:10 AM
Was tun, wenn der Edge-Browser zu viel Speicher beansprucht? Was tun, wenn der Edge-Browser zu viel Speicher beansprucht?
May 09, 2024 am 11:10 AM
1. Rufen Sie zunächst den Edge-Browser auf und klicken Sie auf die drei Punkte in der oberen rechten Ecke. 2. Wählen Sie dann in der Taskleiste [Erweiterungen] aus. 3. Schließen oder deinstallieren Sie als Nächstes die Plug-Ins, die Sie nicht benötigen.
 Für nur 250 US-Dollar zeigt Ihnen der technische Leiter von Hugging Face Schritt für Schritt, wie Sie Llama 3 verfeinern
May 06, 2024 pm 03:52 PM
Für nur 250 US-Dollar zeigt Ihnen der technische Leiter von Hugging Face Schritt für Schritt, wie Sie Llama 3 verfeinern
May 06, 2024 pm 03:52 PM
Die bekannten großen Open-Source-Sprachmodelle wie Llama3 von Meta, Mistral- und Mixtral-Modelle von MistralAI und Jamba von AI21 Lab sind zu Konkurrenten von OpenAI geworden. In den meisten Fällen müssen Benutzer diese Open-Source-Modelle anhand ihrer eigenen Daten verfeinern, um das Potenzial des Modells voll auszuschöpfen. Es ist nicht schwer, ein großes Sprachmodell (wie Mistral) im Vergleich zu einem kleinen mithilfe von Q-Learning auf einer einzelnen GPU zu optimieren, aber die effiziente Feinabstimmung eines großen Modells wie Llama370b oder Mixtral blieb bisher eine Herausforderung . Deshalb Philipp Sch, technischer Leiter von HuggingFace
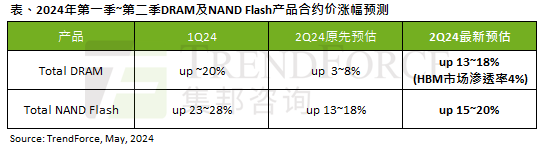 Die Auswirkungen der KI-Welle sind offensichtlich. TrendForce hat seine Prognose für Preiserhöhungen bei DRAM-Speicher und NAND-Flash-Speicher in diesem Quartal nach oben korrigiert.
May 07, 2024 pm 09:58 PM
Die Auswirkungen der KI-Welle sind offensichtlich. TrendForce hat seine Prognose für Preiserhöhungen bei DRAM-Speicher und NAND-Flash-Speicher in diesem Quartal nach oben korrigiert.
May 07, 2024 pm 09:58 PM
Laut einem TrendForce-Umfragebericht hat die KI-Welle erhebliche Auswirkungen auf die Märkte für DRAM-Speicher und NAND-Flash-Speicher. In den Nachrichten dieser Website vom 7. Mai sagte TrendForce heute in seinem neuesten Forschungsbericht, dass die Agentur die Vertragspreiserhöhungen für zwei Arten von Speicherprodukten in diesem Quartal erhöht habe. Konkret schätzte TrendForce ursprünglich, dass der DRAM-Speichervertragspreis im zweiten Quartal 2024 um 3 bis 8 % steigen wird, und schätzt ihn nun auf 13 bis 18 %, bezogen auf NAND-Flash-Speicher, die ursprüngliche Schätzung wird um 13 bis 18 % steigen 18 %, und die neue Schätzung liegt bei 15 %, nur eMMC/UFS weist einen geringeren Anstieg von 10 % auf. ▲Bildquelle TrendForce TrendForce gab an, dass die Agentur ursprünglich damit gerechnet hatte, dies auch weiterhin zu tun
 Auf welche Fallstricke sollten wir beim Entwurf verteilter Systeme mit Golang-Technologie achten?
May 07, 2024 pm 12:39 PM
Auf welche Fallstricke sollten wir beim Entwurf verteilter Systeme mit Golang-Technologie achten?
May 07, 2024 pm 12:39 PM
Fallstricke in der Go-Sprache beim Entwurf verteilter Systeme Go ist eine beliebte Sprache für die Entwicklung verteilter Systeme. Allerdings gibt es bei der Verwendung von Go einige Fallstricke zu beachten, die die Robustheit, Leistung und Korrektheit Ihres Systems beeinträchtigen können. In diesem Artikel werden einige häufige Fallstricke untersucht und praktische Beispiele für deren Vermeidung gegeben. 1. Übermäßiger Gebrauch von Parallelität Go ist eine Parallelitätssprache, die Entwickler dazu ermutigt, Goroutinen zu verwenden, um die Parallelität zu erhöhen. Eine übermäßige Nutzung von Parallelität kann jedoch zu Systeminstabilität führen, da zu viele Goroutinen um Ressourcen konkurrieren und einen Mehraufwand beim Kontextwechsel verursachen. Praktischer Fall: Übermäßiger Einsatz von Parallelität führt zu Verzögerungen bei der Dienstantwort und Ressourcenkonkurrenz, was sich in einer hohen CPU-Auslastung und einem hohen Aufwand für die Speicherbereinigung äußert.
 Welche Warnungen oder Vorbehalte sollten in der Golang-Funktionsdokumentation enthalten sein?
May 04, 2024 am 11:39 AM
Welche Warnungen oder Vorbehalte sollten in der Golang-Funktionsdokumentation enthalten sein?
May 04, 2024 am 11:39 AM
Die Go-Funktionsdokumentation enthält Warnungen und Vorbehalte, die für das Verständnis potenzieller Probleme und die Vermeidung von Fehlern unerlässlich sind. Dazu gehören: Parametervalidierungswarnung: Überprüfen Sie die Parametergültigkeit. Überlegungen zur Parallelitätssicherheit: Geben Sie die Thread-Sicherheit einer Funktion an. Leistungsaspekte: Heben Sie den hohen Rechenaufwand oder Speicherbedarf einer Funktion hervor. Anmerkung zum Rückgabetyp: Beschreibt den von der Funktion zurückgegebenen Fehlertyp. Abhängigkeitshinweis: Listet externe Bibliotheken oder Pakete auf, die für die Funktion erforderlich sind. Veraltungswarnung: Zeigt an, dass eine Funktion veraltet ist, und schlägt eine Alternative vor.
 Detaillierte Erläuterung der JVM-Befehlszeilenparameter: die Geheimwaffe zur Steuerung des JVM-Betriebs
May 09, 2024 pm 01:33 PM
Detaillierte Erläuterung der JVM-Befehlszeilenparameter: die Geheimwaffe zur Steuerung des JVM-Betriebs
May 09, 2024 pm 01:33 PM
Mit JVM-Befehlszeilenparametern können Sie das JVM-Verhalten auf einer feinkörnigen Ebene anpassen. Zu den allgemeinen Parametern gehören: Festlegen der Java-Heap-Größe (-Xms, -Xmx), Festlegen der Größe der neuen Generation (-Xmn), Aktivieren des parallelen Garbage Collectors (-XX:+UseParallelGC), Reduzieren der Speichernutzung des Survivor-Bereichs (-XX: -ReduceSurvivorSetInMemory) Redundanz eliminieren Garbage Collection eliminieren (-XX:-EliminateRedundantGCs) Informationen zur Garbage Collection drucken (-XX:+PrintGC) Den G1 Garbage Collector verwenden (-XX:-UseG1GC) Die maximale Pausenzeit für die Garbage Collection festlegen (-XX:MaxGCPau
 Java-Datenstrukturen und -Algorithmen: ausführliche Erklärung
May 08, 2024 pm 10:12 PM
Java-Datenstrukturen und -Algorithmen: ausführliche Erklärung
May 08, 2024 pm 10:12 PM
Datenstrukturen und Algorithmen sind die Grundlage der Java-Entwicklung. In diesem Artikel werden die wichtigsten Datenstrukturen (wie Arrays, verknüpfte Listen, Bäume usw.) und Algorithmen (wie Sortier-, Such-, Diagrammalgorithmen usw.) ausführlich untersucht. Diese Strukturen werden anhand praktischer Beispiele veranschaulicht, darunter die Verwendung von Arrays zum Speichern von Bewertungen, verknüpfte Listen zum Verwalten von Einkaufslisten, Stapel zum Implementieren von Rekursionen, Warteschlangen zum Synchronisieren von Threads sowie Bäume und Hash-Tabellen für schnelle Suche und Authentifizierung. Wenn Sie diese Konzepte verstehen, können Sie effizienten und wartbaren Java-Code schreiben.
