
 Technologie-Peripheriegeräte
KI
Großes Multi-View-Gauß-Modell LGM: Erzeugt hochwertige 3D-Objekte in 5 Sekunden, verfügbar zum Testen
Technologie-Peripheriegeräte
KI
Großes Multi-View-Gauß-Modell LGM: Erzeugt hochwertige 3D-Objekte in 5 Sekunden, verfügbar zum Testen
Großes Multi-View-Gauß-Modell LGM: Erzeugt hochwertige 3D-Objekte in 5 Sekunden, verfügbar zum Testen

Als Reaktion auf die weiterhin wachsende Nachfrage nach 3D-Kreativwerkzeugen im Metaverse zeigten die Menschen in letzter Zeit großes Interesse an der dreidimensionalen Inhaltsgenerierung (3D AIGC). Gleichzeitig hat die Erstellung von 3D-Inhalten erhebliche Fortschritte in Qualität und Geschwindigkeit gemacht.
Obwohl aktuelle generative Feed-Forward-Modelle 3D-Objekte in Sekundenschnelle generieren können, ist ihre Auflösung durch die intensive Berechnung, die während des Trainings erforderlich ist, begrenzt, was zur Generierung von Inhalten von geringer Qualität führt. Da stellt sich die Frage: Kann ein hochauflösendes, qualitativ hochwertiges 3D-Objekt in nur 5 Sekunden generiert werden?

In diesem Artikel schlugen Forscher der Peking-Universität, des S-Lab der Nanyang Technological University und des Shanghai Artificial Intelligence Laboratory ein „neues LGM-Framework“ vor, nämlich das Large Gaussian Model, das die Transformation von Einzelansichtsbildern realisiert Oder Texteingabe, um in nur 5 Sekunden hochauflösende und hochwertige dreidimensionale Objekte zu generieren.
Derzeit sind sowohl der Code als auch die Modellgewichte Open Source. Die Forscher stellen außerdem eine Online-Demo zur Verfügung, die jeder ausprobieren kann.

- Papiertitel: LGM: Large Multi-View Gaussian Model for High-Resolution 3D Content Creation
- Projekthomepage: https://me.kiui.moe/lgm/
- Code : https://github.com/3DTopia/LGM
- Papier: https://arxiv.org/abs/2402.05054
- Online-Demo: https://huggingface.co/spaces/ashawkey/LGM
- Effiziente 3D-Darstellung bei begrenztem Rechenaufwand: Bestehende 3D-Generierungsarbeiten verwenden NeRF basierend auf drei Ebenen als 3D-Darstellung und Rendering Pipeline, die intensive Modellierung von Szenen und die Raytracing-Volumenrendering-Technologie schränken die Trainingsauflösung (128 x 128) erheblich ein, wodurch die Textur des endgültig generierten Inhalts verschwommen und von schlechter Qualität ist.
- 3D-Backbone-Generierungsnetzwerk mit hoher Auflösung: Bestehende 3D-Generierungsarbeiten verwenden dichte Transformatoren als Backbone-Netzwerk, um sicherzustellen, dass die Parametermenge dicht genug ist, um universelle Objekte zu modellieren, was jedoch bis zu einem gewissen Grad geopfert wird Die Trainingsauflösung Dies führt zu einer geringen Qualität des endgültigen dreidimensionalen Objekts.
vorhandenen Text für Mehransichtsbilder oder einzelne Bilder für Mehransichtsbildmodelle zu verwenden . Unterstützt hochwertige Text-zu-3D- und Bild-zu-3D-Aufgaben .
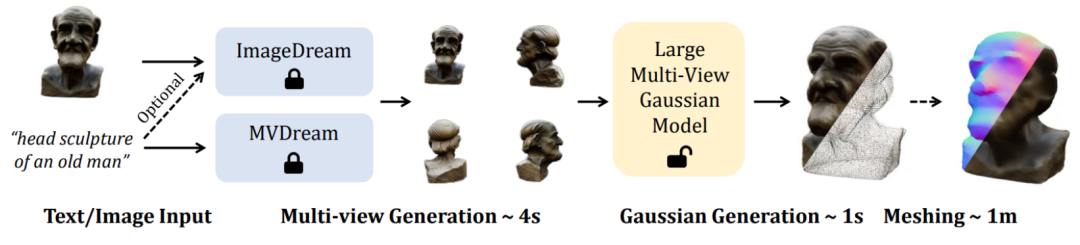
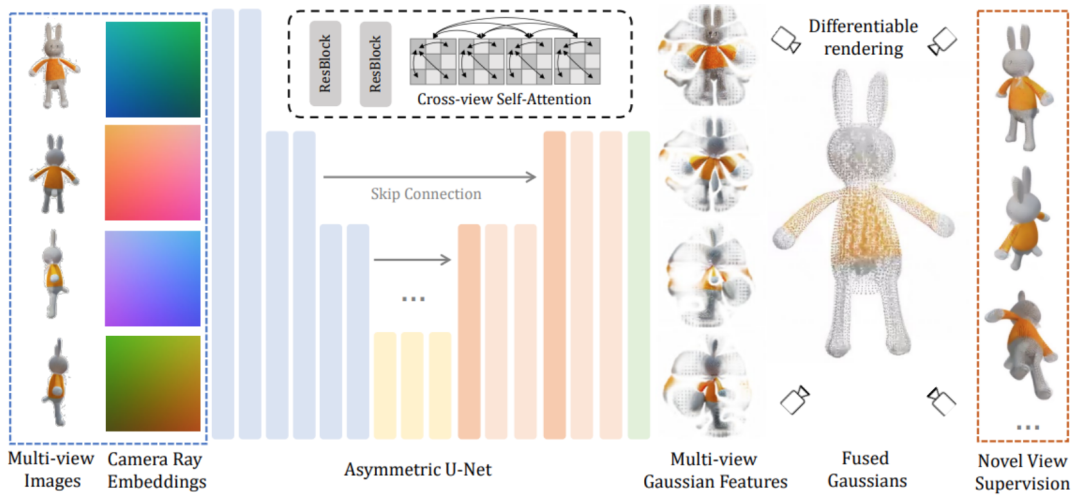
LGM-Kernmodul ein großes Multi-View-Gauß-Modell. Inspiriert durch Gaußsches Sputtern verwendet diese Methode ein effizientes und leichtes asymmetrisches U-Net als Backbone-Netzwerk, um hochauflösende Gaußsche Grundelemente aus Bildern mit vier Ansichten direkt vorherzusagen und schließlich Bilder aus jedem Blickwinkel zu rendern.
Konkret akzeptiert das Backbone-Netzwerk U-Net Bilder aus vier Perspektiven und entsprechenden Plucker-Koordinaten und gibt eine feste Anzahl von Gaußschen Merkmalen aus mehreren Perspektiven aus. Dieser Satz Gaußscher Merkmale wird direkt mit dem endgültigen Gaußschen Element verschmolzen und durch differenzierbares Rendern werden Bilder aus verschiedenen Betrachtungswinkeln erhalten.In diesem Prozess wird ein ansichtsübergreifender Selbstaufmerksamkeitsmechanismus verwendet, um eine Korrelationsmodellierung zwischen verschiedenen Ansichten auf Feature-Maps mit niedriger Auflösung zu implementieren und gleichzeitig einen geringen Rechenaufwand aufrechtzuerhalten.
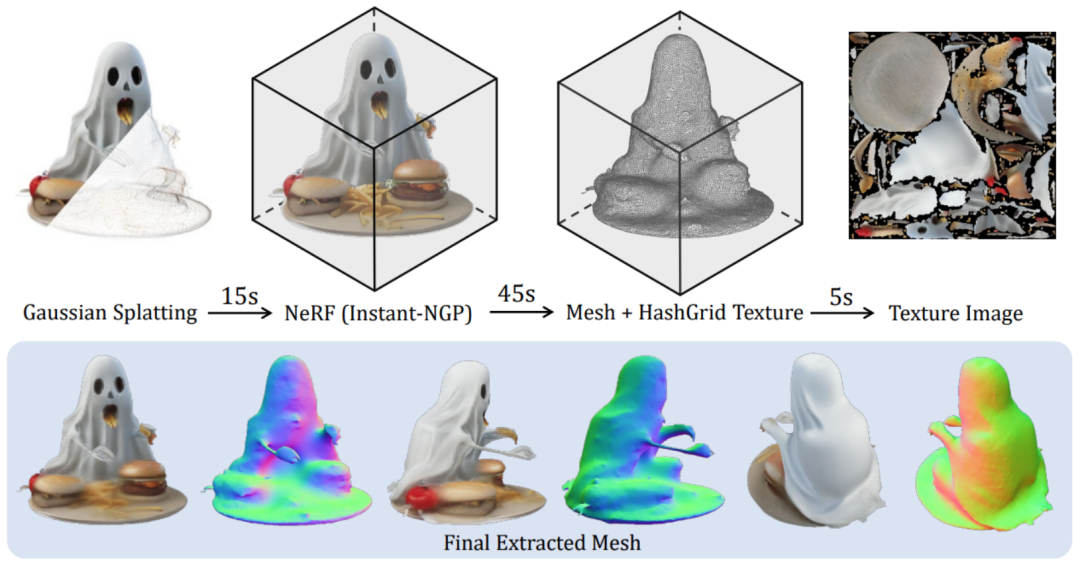
Zuerst werden die im objaversen Datensatz gerenderten dreidimensionalen konsistenten Mehransichtsbilder in der Trainingsphase verwendet, während in der Inferenzphase vorhandene Modelle direkt verwendet werden, um Mehrperspektivenbilder aus Text oder Bildern zu synthetisieren. Da auf der Grundlage des Modells synthetisierte Multi-View-Bilder immer das Problem der Multi-View-Inkonsistenz haben, wird in diesem Artikel eine auf Gitterverzerrung basierende Datenverbesserungsstrategie vorgeschlagen, um die Lücke in diesem Bereich zu schließen: Anwenden von Randomisierung auf die Bilder aus drei Ansichten im Bildraum Verzerrung, um Multi-View-Inkonsistenz zu simulieren. Zweitens: Da die in der Inferenzphase erzeugten Mehransichtsbilder die Konsistenz der dreidimensionalen Geometrie der Kameraperspektive nicht unbedingt garantieren, werden in diesem Artikel auch die Kamerapositionen der drei Perspektiven zufällig gestört, um dieses Phänomen zu simulieren , damit das Modell beim Denken eine bessere Leistung erbringen kann. Die Bühne ist stabiler . Nach Abschluss des Trainings kann LGM mithilfe des vorhandenen Bild-zu-Mehrfachansicht- oder Text-zu-Mehrfachansicht-Diffusionsmodells qualitativ hochwertige Text-zu-3D- und Bild-zu-3D-Aufgaben erfüllen.


Das obige ist der detaillierte Inhalt vonGroßes Multi-View-Gauß-Modell LGM: Erzeugt hochwertige 3D-Objekte in 5 Sekunden, verfügbar zum Testen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1374
1374
 52
52

 Welche Methode wird verwendet, um Strings in Objekte in Vue.js umzuwandeln?
Apr 07, 2025 pm 09:39 PM
Welche Methode wird verwendet, um Strings in Objekte in Vue.js umzuwandeln?
Apr 07, 2025 pm 09:39 PM
Bei der Konvertierung von Zeichenfolgen in Objekte in Vue.js wird JSON.Parse () für Standard -JSON -Zeichenfolgen bevorzugt. Bei nicht standardmäßigen JSON-Zeichenfolgen kann die Zeichenfolge durch Verwendung regelmäßiger Ausdrücke verarbeitet und Methoden gemäß dem Format oder dekodierten URL-kodiert reduziert werden. Wählen Sie die entsprechende Methode gemäß dem String -Format aus und achten Sie auf Sicherheits- und Codierungsprobleme, um Fehler zu vermeiden.
 So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
Um die Zeitüberschreitung für Vue Axios festzulegen, können wir eine Axios -Instanz erstellen und die Zeitleitungsoption angeben: in globalen Einstellungen: vue.Prototyp. $ Axios = axios.create ({Timeout: 5000}); In einer einzigen Anfrage: this. $ axios.get ('/api/user', {timeout: 10000}).
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 VUE.JS Wie kann man ein Array von String -Typ in ein Array von Objekten umwandeln?
Apr 07, 2025 pm 09:36 PM
VUE.JS Wie kann man ein Array von String -Typ in ein Array von Objekten umwandeln?
Apr 07, 2025 pm 09:36 PM
Zusammenfassung: Es gibt die folgenden Methoden zum Umwandeln von VUE.JS -String -Arrays in Objektarrays: Grundlegende Methode: Verwenden Sie die Kartenfunktion, um regelmäßige formatierte Daten zu entsprechen. Erweitertes Gameplay: Die Verwendung regulärer Ausdrücke kann komplexe Formate ausführen, müssen jedoch sorgfältig geschrieben und berücksichtigt werden. Leistungsoptimierung: In Betracht ziehen die große Datenmenge, asynchrone Operationen oder effiziente Datenverarbeitungsbibliotheken können verwendet werden. Best Practice: Clear Code -Stil, verwenden Sie sinnvolle variable Namen und Kommentare, um den Code präzise zu halten.
 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
Die MySQL -Leistungsoptimierung muss von drei Aspekten beginnen: Installationskonfiguration, Indexierung und Abfrageoptimierung, Überwachung und Abstimmung. 1. Nach der Installation müssen Sie die my.cnf -Datei entsprechend der Serverkonfiguration anpassen, z. 2. Erstellen Sie einen geeigneten Index, um übermäßige Indizes zu vermeiden und Abfrageanweisungen zu optimieren, z. B. den Befehl Erklärung zur Analyse des Ausführungsplans; 3. Verwenden Sie das eigene Überwachungstool von MySQL (ShowProcessList, Showstatus), um die Datenbankgesundheit zu überwachen und die Datenbank regelmäßig zu sichern und zu organisieren. Nur durch kontinuierliche Optimierung dieser Schritte kann die Leistung der MySQL -Datenbank verbessert werden.
