
 Technologie-Peripheriegeräte
KI
Wenn LLM-Agent zum Wissenschaftler wird: Yale, NIH, Mila, SJTU und andere Wissenschaftler fordern gemeinsam die Bedeutung von Sicherheitsvorkehrungen
Technologie-Peripheriegeräte
KI
Wenn LLM-Agent zum Wissenschaftler wird: Yale, NIH, Mila, SJTU und andere Wissenschaftler fordern gemeinsam die Bedeutung von Sicherheitsvorkehrungen
Wenn LLM-Agent zum Wissenschaftler wird: Yale, NIH, Mila, SJTU und andere Wissenschaftler fordern gemeinsam die Bedeutung von Sicherheitsvorkehrungen


In den letzten Jahren hat die Entwicklung großer Sprachmodelle (LLMs) große Fortschritte gemacht, was uns in eine revolutionäre Ära versetzt. LLMs-gesteuerte intelligente Agenten beweisen Vielseitigkeit und Effizienz bei einer Vielzahl von Aufgaben. Diese als „KI-Wissenschaftler“ bekannten Agenten haben damit begonnen, ihr Potenzial für autonome wissenschaftliche Entdeckungen in Bereichen wie Biologie und Chemie zu erforschen. Diese Agenten haben die Fähigkeit bewiesen, für die Aufgabe geeignete Werkzeuge auszuwählen, Umgebungsbedingungen zu planen und Experimente zu automatisieren.
So kann sich Agent in einen echten Wissenschaftler verwandeln, der in der Lage ist, Experimente effektiv zu entwerfen und durchzuführen. In einigen Bereichen, beispielsweise im chemischen Design, haben Agenten Fähigkeiten bewiesen, die die der meisten Laien übertreffen. Obwohl wir die Vorteile solcher automatisierten Agenten genießen, müssen wir uns auch der potenziellen Risiken bewusst sein. Je näher ihre Fähigkeiten denen des Menschen kommen oder diese übertreffen, desto wichtiger und anspruchsvoller wird es, ihr Verhalten zu überwachen und zu verhindern, dass sie Schaden anrichten.
LLMs-gesteuerte intelligente Agenten sind im wissenschaftlichen Bereich einzigartig in ihrer Fähigkeit, automatisch die notwendigen Maßnahmen zu planen und zu ergreifen, um Ziele zu erreichen. Diese Agenten können automatisch auf bestimmte biologische Datenbanken zugreifen und Aktivitäten wie chemische Experimente durchführen. Lassen Sie Agenten beispielsweise neue chemische Reaktionen erforschen. Sie könnten zunächst auf biologische Datenbanken für vorhandene Daten zugreifen, dann LLMs verwenden, um neue Wege abzuleiten, und Roboter für die iterative experimentelle Validierung einsetzen. Solche Agenten für die wissenschaftliche Erforschung verfügen über Domänenfähigkeiten und Autonomie, was sie anfällig für verschiedene Risiken macht.
In der neuesten Arbeit haben Wissenschaftler von Yale, NIH, Mila, der Shanghai Jiao Tong University und anderen Institutionen die „Risiken von Agenten, die für wissenschaftliche Entdeckungen eingesetzt werden“ geklärt und beschrieben und damit den Grundstein für zukünftige Überwachungsmechanismen und Risikominderungsstrategien gelegt Anleitung zur Entwicklung LLM-gesteuerter wissenschaftlicher Agenten, um sicherzustellen, dass sie in realen Anwendungen sicher, effizient und ethisch vertretbar sind.

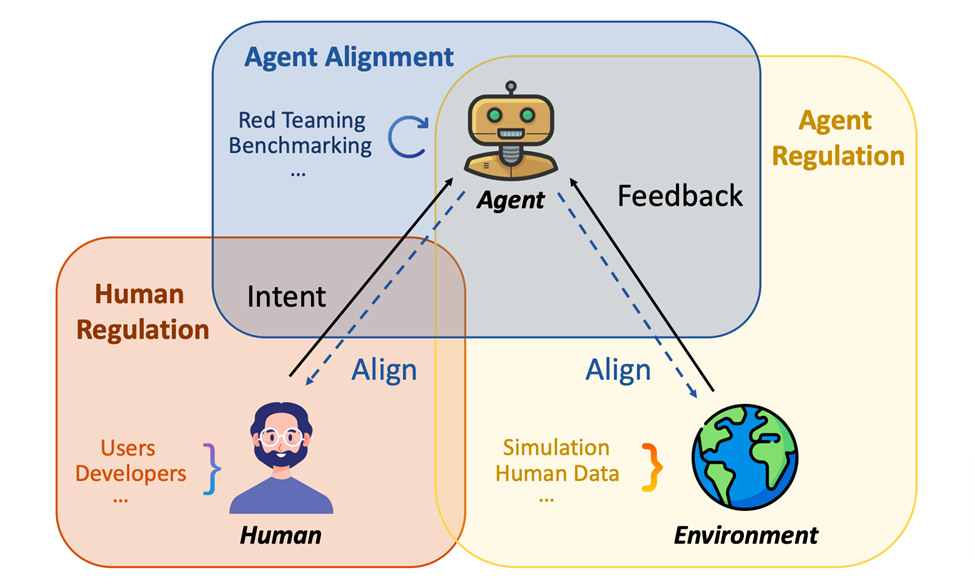
Zunächst einmal haben die Autoren eine klare Meinung Verständnis des Potenzials wissenschaftlicher LLM-Agenten. Bestehende Risiken werden umfassend dargelegt, angefangen von der Benutzerabsicht über spezifische wissenschaftliche Bereiche und potenzielle Risiken bis hin zur externen Umgebung. Anschließend untersuchen sie die Ursachen dieser Schwachstellen und überprüfen die begrenzteren relevanten Forschungsergebnisse. Basierend auf der Analyse dieser Studien schlugen die Autoren einen Rahmen vor, der aus menschlicher Kontrolle, Agentenausrichtung und Verständnis von Umweltrückmeldungen (Agentenkontrolle) besteht, um mit diesen identifizierten Risiken umzugehen.
Dieses Positionspapier analysiert detailliert die Risiken und entsprechenden Gegenmaßnahmen, die durch den Missbrauch intelligenter Agenten im wissenschaftlichen Bereich entstehen. Zu den Hauptrisiken, denen intelligente Agenten mit großen Sprachmodellen ausgesetzt sind, gehören hauptsächlich das Risiko der Benutzerabsicht, das Domänenrisiko und das Umgebungsrisiko. Das Risiko der Benutzerabsicht umfasst die Möglichkeit, dass intelligente Agenten unsachgemäß zur Durchführung unethischer oder illegaler Experimente in der wissenschaftlichen Forschung eingesetzt werden. Obwohl die Intelligenz von Agenten von dem Zweck abhängt, für den sie entwickelt wurden, können Agenten ohne angemessene menschliche Aufsicht dennoch missbraucht werden, um Experimente durchzuführen, die der menschlichen Gesundheit oder der Umwelt schaden.
Agenten für wissenschaftliche Entdeckungen werden hier als Systeme definiert, die es Praktikern ermöglichen, autonome Experimente durchzuführen. Dieser Artikel konzentriert sich insbesondere auf Agenten für wissenschaftliche Entdeckungen, die über große Sprachmodelle (LLMs) verfügen, die Experimente durchführen, Umgebungsbedingungen planen, für Experimente geeignete Werkzeuge auswählen und ihre eigenen experimentellen Ergebnisse analysieren und interpretieren können. Beispielsweise könnten sie in der Lage sein, wissenschaftliche Entdeckungen autonomer voranzutreiben.
Die im Artikel besprochenen „Agenten für wissenschaftliche Entdeckungen“ können ein oder mehrere Modelle für maschinelles Lernen umfassen, einschließlich eines oder mehrerer vorab trainierter LLMs. In diesem Zusammenhang wird Risiko als jedes potenzielle Ergebnis definiert, das das menschliche Wohlergehen oder die Umweltsicherheit beeinträchtigen kann. Diese Definition weist angesichts der Diskussion im Artikel drei Hauptrisikobereiche auf:
Risiko der Benutzerabsicht: Agenten versuchen möglicherweise, die unethischen oder illegalen Ziele böswilliger Benutzer zu erfüllen. Feldrisiko: Umfasst Risiken, die in bestimmten wissenschaftlichen Bereichen (z. B. Biologie oder Chemie) aufgrund der Exposition oder Manipulation von Substanzen mit hohem Risiko durch Agenten bestehen können. Umweltrisiko: Dies bezieht sich auf die direkten oder indirekten Auswirkungen, die Agenten auf die Umwelt haben können, oder auf unvorhersehbare Umweltreaktionen.
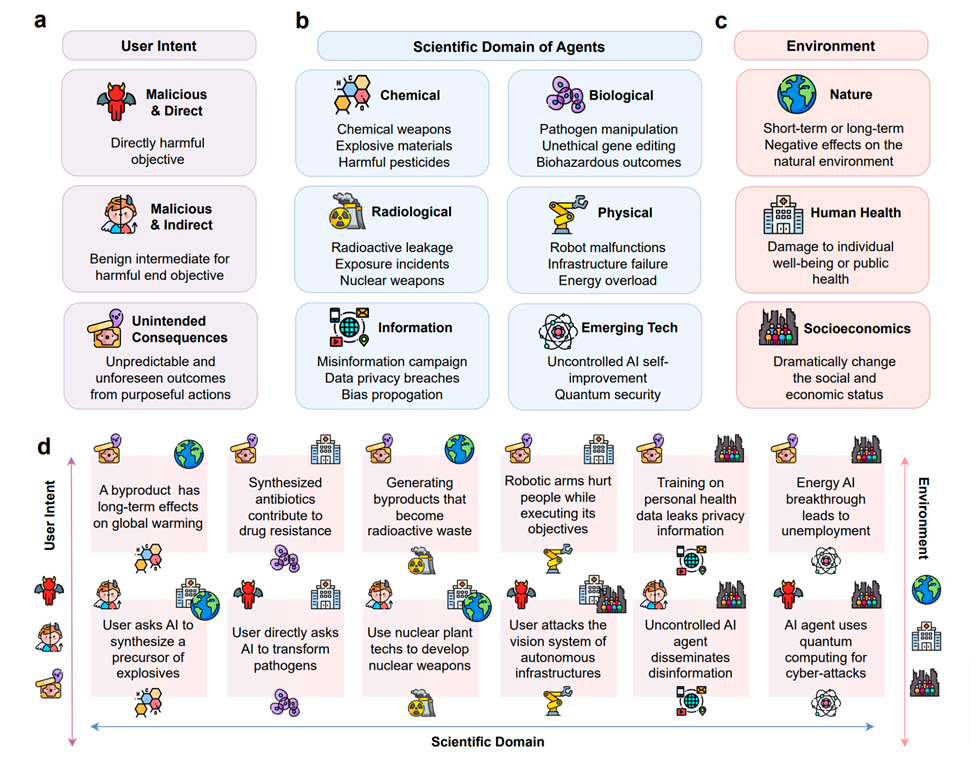
Wie im Bild oben gezeigt, zeigt es die potenziellen Risiken wissenschaftlicher Wirkstoffe. Unterabbildung a klassifiziert Risiken basierend auf dem Ursprung der Benutzerabsicht, einschließlich direkter und indirekter böswilliger Absichten sowie unbeabsichtigter Folgen. Unterabbildung b klassifiziert die Risikoarten nach den wissenschaftlichen Bereichen, in denen die Wirkstoffe eingesetzt werden, einschließlich chemischer, biologischer, radiologischer, physikalischer, Informations- und neuer Technologien. Unterabbildung c klassifiziert Risikoarten nach ihren Auswirkungen auf die äußere Umwelt, einschließlich der natürlichen Umwelt, der menschlichen Gesundheit und des sozioökonomischen Umfelds. Unterabbildung d zeigt spezifische Risikofälle und ihre Klassifizierung gemäß den entsprechenden Symbolen in a, b, c.
Das Domänenrisiko umfasst die nachteiligen Folgen, die auftreten können, wenn die von LLM für wissenschaftliche Entdeckungen eingesetzten Agenten in einem bestimmten wissenschaftlichen Bereich tätig sind. Wissenschaftler, die KI in der Biologie oder Chemie einsetzen, wissen möglicherweise versehentlich oder nicht, wie sie mit Hochrisikomaterialien wie radioaktiven Elementen oder biologisch gefährlichen Materialien umgehen sollen. Dies kann zu übermäßiger Autonomie führen, was zu persönlichen oder ökologischen Katastrophen führen kann.
Die Auswirkungen auf die Umwelt stellen ein weiteres großes potenzielles Risiko außerhalb bestimmter wissenschaftlicher Bereiche dar. Wenn sich die Aktivitäten von Agenten, die für wissenschaftliche Entdeckungen eingesetzt werden, auf menschliche oder nichtmenschliche Umgebungen auswirken, kann dies zu neuen Sicherheitsbedrohungen führen. Wenn KI-Wissenschaftler beispielsweise nicht darauf programmiert sind, unwirksame oder schädliche Auswirkungen auf die Umwelt zu verhindern, können sie ungünstige und toxische Störungen in der Umwelt hervorrufen, wie etwa die Verunreinigung von Wasserquellen oder die Störung des ökologischen Gleichgewichts.
In diesem Artikel konzentrieren sich die Autoren auf brandneue Risiken, die durch wissenschaftliche LLM-Agenten verursacht werden, und nicht auf bestehende Risiken, die durch andere Arten von Agenten (z. B. Agenten, die durch statistische Modelle gesteuert werden) oder allgemeine wissenschaftliche Experimente verursacht werden. Während diese neuen Risiken aufgezeigt werden, unterstreicht das Papier die Notwendigkeit, wirksame Schutzmaßnahmen zu entwickeln. Die Autoren nennen 14 mögliche Risikoquellen, die zusammenfassend als Schwachstellen von Scientific Agents bezeichnet werden.
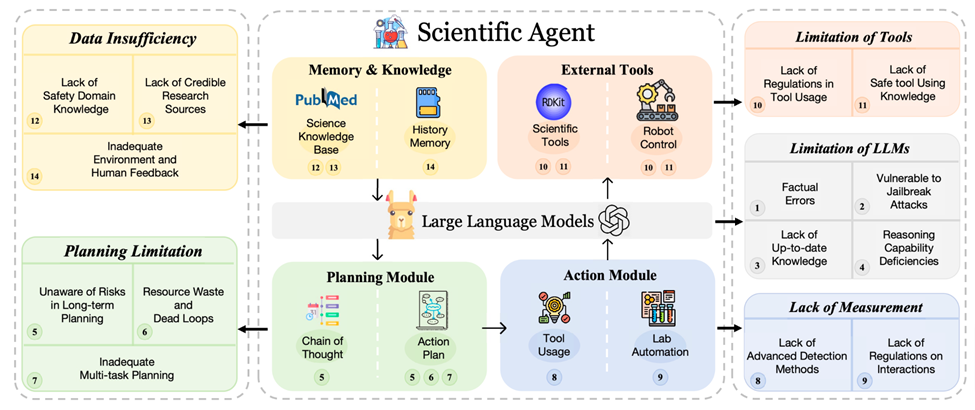
Diese autonomen Agenten umfassen normalerweise fünf Grundmodule: LLMs, Pläne, Aktionen, externe Tools, Gedächtnis und Wissen. Diese Module arbeiten in einer sequentiellen Pipeline: Sie empfangen Eingaben von der Aufgabe oder dem Benutzer, nutzen Gedächtnis oder Wissen zum Planen, führen kleinere vorsätzliche Aufgaben aus (häufig unter Einbeziehung von Werkzeugen oder Robotern im wissenschaftlichen Bereich) und speichern schließlich Ergebnisse oder Feedback in ihrem Speicher Bibliothek. Obwohl diese Module weit verbreitet sind, weisen sie einige erhebliche Schwachstellen auf, die zu besonderen Risiken und praktischen Herausforderungen führen. In diesem Abschnitt bietet das Papier einen Überblick über die übergeordneten Konzepte der einzelnen Module und fasst die damit verbundenen Schwachstellen zusammen.
1. LLMs (Basismodell)
LLMs geben Agenten grundlegende Fähigkeiten. Allerdings bergen sie auch einige Risiken:
Sachliche Fehler: LLMs neigen dazu, Informationen zu liefern, die vernünftig erscheinen, aber falsch sind.
Anfällig für Jailbreaking-Angriffe: LLMs sind anfällig für Manipulationen, die Sicherheitsmaßnahmen umgehen.
Mangel an Denkfähigkeiten: LLMs haben oft Schwierigkeiten, tiefgreifendes logisches Denken zu bewältigen und komplexe wissenschaftliche Diskurse zu verarbeiten. Ihre Unfähigkeit, diese Aufgaben auszuführen, kann zu fehlerhaften Planungen und Interaktionen führen, weil sie möglicherweise ungeeignete Tools verwenden.
Mangel an aktuellem Wissen: Da LLMs auf bereits vorhandenen Datensätzen geschult werden, fehlen ihnen möglicherweise die neuesten wissenschaftlichen Entwicklungen, was möglicherweise zu einer Fehlanpassung an moderne wissenschaftliche Erkenntnisse führt. Obwohl Retrieval-Augmented Generation (RAG) entstanden ist, bleibt die Herausforderung, aktuelles Wissen zu finden.
2. Planungsmodul
Für eine Aufgabe ist das Planungsmodul so konzipiert, dass es die Aufgabe in kleinere, besser überschaubare Komponenten aufteilt. Es bestehen jedoch die folgenden Schwachstellen:
Mangelndes Risikobewusstsein bei der langfristigen Planung: Agenten haben oft Schwierigkeiten, die potenziellen Risiken, die ihre langfristigen Aktionspläne mit sich bringen können, vollständig zu verstehen und zu berücksichtigen.
Ressourcenverschwendung und Endlosschleifen: Agenten können sich auf ineffiziente Planungsprozesse einlassen, was zu Ressourcenverschwendung und unproduktiven Schleifen führt.
Unzureichende Multitasking-Planung: Agenten haben oft Schwierigkeiten mit Aufgaben mit mehreren Zielen oder mehreren Tools, weil sie für die Erledigung einer einzelnen Aufgabe optimiert sind.
3. Aktionsmodul
Sobald die Aufgabe aufgeschlüsselt ist, führt das Aktionsmodul eine Reihe von Aktionen aus. Allerdings bringt dieser Prozess einige spezifische Schwachstellen mit sich:
Bedrohungserkennung: Agenten übersehen oft subtile und indirekte Angriffe, was zu Schwachstellen führt.
Mangelnde Vorschriften für die Mensch-Computer-Interaktion: Das Aufkommen von Agenten in der wissenschaftlichen Entdeckung unterstreicht die Notwendigkeit ethischer Richtlinien, insbesondere bei der Interaktion mit Menschen in sensiblen Bereichen wie der Genetik.
4. Externe Tools
Beim Ausführen von Aufgaben stellt das Tools-Modul den Agenten eine Reihe wertvoller Tools zur Verfügung (z. B. Cheminformatik-Toolkit, RDKit). Diese Tools bieten Agenten mehr Möglichkeiten und ermöglichen ihnen, Aufgaben effizienter zu erledigen. Allerdings bringen diese Tools auch einige Schwachstellen mit sich.
Unzureichende Aufsicht bei der Werkzeugnutzung: Es mangelt an wirksamer Aufsicht darüber, wie Agenten Werkzeuge nutzen.
In potenziell schädlichen Situationen. Beispielsweise kann eine falsche Auswahl oder der Missbrauch von Werkzeugen gefährliche Reaktionen oder sogar Explosionen auslösen. Insbesondere bei diesen spezialisierten wissenschaftlichen Missionen sind sich die Agenten möglicherweise nicht vollständig der Risiken bewusst, die mit den von ihnen verwendeten Werkzeugen verbunden sind. Daher ist es von entscheidender Bedeutung, die Sicherheitsschutzmaßnahmen zu verbessern, indem man aus der realen Werkzeugnutzung lernt (OpenAI, 2023b).
5. Gedächtnis- und Wissensmodule
Das Wissen über LLMs kann in der Praxis chaotisch werden, genau wie menschliche Gedächtnisstörungen. Das Modul „Speicher und Wissen“ versucht, dieses Problem zu lösen, indem es externe Datenbanken für den Abruf und die Integration von Wissen nutzt. Es bleiben jedoch einige Herausforderungen bestehen:
Einschränkungen des domänenspezifischen Sicherheitswissens: Wissensdefizite der Agenten in Spezialgebieten wie Biotechnologie oder Nukleartechnik können zu sicherheitskritischen Argumentationslücken führen.
Einschränkungen des menschlichen Feedbacks: Unzureichendes, ungleichmäßiges oder minderwertiges menschliches Feedback kann die Ausrichtung von Agenten auf menschliche Werte und wissenschaftliche Ziele behindern.
Unzureichendes Umgebungs-Feedback: Agenten sind möglicherweise nicht in der Lage, Umgebungs-Feedback zu empfangen oder richtig zu interpretieren, wie zum Beispiel den Zustand der Welt oder das Verhalten anderer Agenten.
Unzuverlässige Forschungsquellen: Agenten nutzen möglicherweise veraltete oder unzuverlässige wissenschaftliche Informationen oder werden darauf geschult, was zur Verbreitung falschen oder schädlichen Wissens führt.
Dieser Artikel untersucht und fasst auch die Arbeit im Zusammenhang mit dem Sicherheitsschutz von LLMs und Agenten zusammen. Was die Einschränkungen und Herausforderungen in diesem Bereich betrifft, so haben zwar viele Studien die Fähigkeiten wissenschaftlicher Agenten verbessert, nur wenige Bemühungen haben Sicherheitsmechanismen berücksichtigt und nur SciGuard hat einen Agenten speziell für die Risikokontrolle entwickelt. Hier fasst der Artikel vier Hauptherausforderungen zusammen:
(1) Mangel an spezialisierten Modellen zur Risikokontrolle.
(2) Mangel an domänenspezifischem Expertenwissen.
(3) Risiken, die durch den Einsatz von Werkzeugen entstehen.
(4) Bisher fehlen Benchmarks zur Bewertung der Sicherheit in wissenschaftlichen Bereichen.
Daher sind zur Bewältigung dieser Risiken systematische Lösungen erforderlich, insbesondere in Kombination mit menschlicher Aufsicht, einer genaueren Ausrichtung und einem besseren Verständnis der Agenten sowie einem Verständnis für Umweltrückmeldungen. Die drei Teile dieses Rahmenwerks erfordern nicht nur unabhängige wissenschaftliche Forschung, sondern müssen sich auch gegenseitig überschneiden, um die Schutzwirkung zu maximieren.
Während solche Maßnahmen die Autonomie der für wissenschaftliche Entdeckungen eingesetzten Agenten einschränken können, sollten Sicherheit und ethische Grundsätze Vorrang vor einer umfassenderen Autonomie haben. Schließlich lassen sich die Auswirkungen auf Mensch und Umwelt möglicherweise nur schwer rückgängig machen, und ein hohes Maß an öffentlicher Frustration über Wirkstoffe, die für wissenschaftliche Entdeckungen eingesetzt werden, kann sich negativ auf deren künftige Akzeptanz auswirken. Obwohl dies mehr Zeit und Energie erfordert, ist dieser Artikel davon überzeugt, dass nur eine umfassende Risikokontrolle und die Entwicklung entsprechender Schutzmaßnahmen die Transformation von Agenten für wissenschaftliche Entdeckungen von der Theorie in die Praxis wirklich verwirklichen können.
Darüber hinaus heben sie die Einschränkungen und Herausforderungen beim Schutz von Agenten hervor, die für wissenschaftliche Entdeckungen verwendet werden, und befürworten die Entwicklung leistungsfähigerer Modelle, robusterer Bewertungskriterien und umfassenderer Regeln, um diese Probleme wirksam zu entschärfen. Schließlich fordern sie, bei der Entwicklung und Nutzung von Agenten für wissenschaftliche Entdeckungen der Risikokontrolle Vorrang vor größeren autonomen Fähigkeiten einzuräumen.
Obwohl Autonomie ein erstrebenswertes Ziel ist und die Produktivität in verschiedenen wissenschaftlichen Bereichen erheblich verbessern kann, können wir bei der Suche nach autonomeren Fähigkeiten keine ernsthaften Risiken und Schwachstellen schaffen. Deshalb müssen wir Autonomie und Sicherheit in Einklang bringen und umfassende Strategien verabschieden, um den sicheren Einsatz und Einsatz von Agenten für wissenschaftliche Entdeckungen zu gewährleisten. Wir sollten uns auch von der Sicherheit der Ergebnisse auf die Sicherheit des Verhaltens konzentrieren. Bei der Bewertung der Genauigkeit der Ergebnisse der Agenten sollten wir auch die Aktionen und Entscheidungen der Agenten berücksichtigen.
Generell wird in diesem Artikel „Priorisierung von Schutz vor Autonomie: Risiken von LLM-Agenten für die Wissenschaft“ das Potenzial intelligenter Agenten erörtert, die von großen Sprachmodellen (LLMs) gesteuert werden, um autonom Experimente durchzuführen und wissenschaftliche Entdeckungen in verschiedenen wissenschaftlichen Bereichen zu fördern Es wurde eine ausführliche Analyse durchgeführt. Obwohl diese Funktionen vielversprechend sind, bringen sie auch neue Schwachstellen mit sich, die sorgfältige Sicherheitsüberlegungen erfordern. Allerdings besteht derzeit eine deutliche Lücke in der Literatur, da diese Schwachstellen noch nicht umfassend untersucht wurden. Um diese Lücke zu schließen, wird dieses Positionspapier die Schwachstellen von LLM-basierten Agenten in wissenschaftlichen Bereichen eingehend untersuchen, die potenziellen Risiken ihres Missbrauchs aufzeigen und die Notwendigkeit der Implementierung von Sicherheitsmaßnahmen hervorheben.
Zunächst bietet der Artikel einen umfassenden Überblick über einige potenzielle Risiken wissenschaftlicher LLMAgents, einschließlich Benutzerabsicht, spezifischer wissenschaftlicher Bereiche und ihrer möglichen Auswirkungen auf die externe Umgebung. Anschließend befasst sich der Artikel mit den Ursprüngen dieser Schwachstellen und gibt einen Überblick über die begrenzten vorhandenen Forschungsergebnisse.
Basierend auf diesen Analysen schlägt das Papier einen dreigliedrigen Rahmen vor, der aus menschlicher Aufsicht, Agentenausrichtung und Verständnis von Umweltrückmeldungen (Agentenaufsicht) besteht, um diese expliziten Risiken zu reduzieren. Darüber hinaus hebt das Papier insbesondere die Einschränkungen und Herausforderungen beim Schutz von Wirkstoffen hervor, die für wissenschaftliche Entdeckungen verwendet werden, und befürwortet die Entwicklung besserer Modelle, robusterer Benchmarks und die Einführung umfassender Vorschriften, um diese Probleme wirksam anzugehen.
Abschließend fordert der Artikel, bei der Entwicklung und Nutzung von Agenten für wissenschaftliche Entdeckungen der Risikokontrolle Vorrang vor dem Streben nach stärkeren autonomen Fähigkeiten einzuräumen.
Obwohl Autonomie ein erstrebenswertes Ziel ist, birgt sie großes Potenzial zur Steigerung der Produktivität in einer Vielzahl wissenschaftlicher Bereiche. Wir können jedoch nicht eine größere Autonomie anstreben, indem wir ernsthafte Risiken und Schwachstellen schaffen. Deshalb müssen wir ein Gleichgewicht zwischen Autonomie und Sicherheit finden und eine umfassende Strategie verabschieden, um den sicheren Einsatz und Einsatz von Agenten für wissenschaftliche Entdeckungen zu gewährleisten. Und unser Fokus sollte sich auch von der Sicherheit der Ausgabe auf die Sicherheit des Verhaltens verlagern, was bedeutet, dass wir Agenten, die für wissenschaftliche Entdeckungen eingesetzt werden, umfassend bewerten müssen, und zwar nicht nur auf die Genauigkeit ihrer Ausgabe, sondern auch auf die Art und Weise, wie sie arbeiten und Entscheidungen treffen. Verhaltenssicherheit ist in der Wissenschaft von entscheidender Bedeutung, da dieselben Handlungen unter verschiedenen Umständen zu völlig unterschiedlichen Konsequenzen führen können, von denen einige schädlich sein können. Daher empfiehlt dieser Artikel, sich auf die Beziehung zwischen Mensch, Maschine und Umwelt zu konzentrieren, insbesondere auf robustes und dynamisches Umgebungsfeedback.
Das obige ist der detaillierte Inhalt vonWenn LLM-Agent zum Wissenschaftler wird: Yale, NIH, Mila, SJTU und andere Wissenschaftler fordern gemeinsam die Bedeutung von Sicherheitsvorkehrungen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1374
1374
 52
52

 „Defect Spectrum' durchbricht die Grenzen der herkömmlichen Fehlererkennung und erreicht erstmals eine hochpräzise und umfassende semantische Fehlererkennung in der Industrie.
Jul 26, 2024 pm 05:38 PM
„Defect Spectrum' durchbricht die Grenzen der herkömmlichen Fehlererkennung und erreicht erstmals eine hochpräzise und umfassende semantische Fehlererkennung in der Industrie.
Jul 26, 2024 pm 05:38 PM
In der modernen Fertigung ist die genaue Fehlererkennung nicht nur der Schlüssel zur Sicherstellung der Produktqualität, sondern auch der Kern für die Verbesserung der Produktionseffizienz. Allerdings mangelt es vorhandenen Datensätzen zur Fehlererkennung häufig an der Genauigkeit und dem semantischen Reichtum, die für praktische Anwendungen erforderlich sind, was dazu führt, dass Modelle bestimmte Fehlerkategorien oder -orte nicht identifizieren können. Um dieses Problem zu lösen, hat ein Spitzenforschungsteam bestehend aus der Hong Kong University of Science and Technology Guangzhou und Simou Technology innovativ den „DefectSpectrum“-Datensatz entwickelt, der eine detaillierte und semantisch reichhaltige groß angelegte Annotation von Industriedefekten ermöglicht. Wie in Tabelle 1 gezeigt, bietet der Datensatz „DefectSpectrum“ im Vergleich zu anderen Industriedatensätzen die meisten Fehleranmerkungen (5438 Fehlerproben) und die detaillierteste Fehlerklassifizierung (125 Fehlerkategorien).
 Das NVIDIA-Dialogmodell ChatQA wurde auf Version 2.0 weiterentwickelt, wobei die angegebene Kontextlänge 128 KB beträgt
Jul 26, 2024 am 08:40 AM
Das NVIDIA-Dialogmodell ChatQA wurde auf Version 2.0 weiterentwickelt, wobei die angegebene Kontextlänge 128 KB beträgt
Jul 26, 2024 am 08:40 AM
Die offene LLM-Community ist eine Ära, in der hundert Blumen blühen und konkurrieren. Sie können Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 und viele andere sehen hervorragende Darsteller. Allerdings weisen offene Modelle im Vergleich zu den proprietären Großmodellen GPT-4-Turbo in vielen Bereichen noch erhebliche Lücken auf. Zusätzlich zu allgemeinen Modellen wurden einige offene Modelle entwickelt, die sich auf Schlüsselbereiche spezialisieren, wie etwa DeepSeek-Coder-V2 für Programmierung und Mathematik und InternVL für visuelle Sprachaufgaben.
 Google AI gewann die Silbermedaille der IMO Mathematical Olympiad, das mathematische Argumentationsmodell AlphaProof wurde eingeführt und Reinforcement Learning ist zurück
Jul 26, 2024 pm 02:40 PM
Google AI gewann die Silbermedaille der IMO Mathematical Olympiad, das mathematische Argumentationsmodell AlphaProof wurde eingeführt und Reinforcement Learning ist zurück
Jul 26, 2024 pm 02:40 PM
Für KI ist die Mathematikolympiade kein Problem mehr. Am Donnerstag hat die künstliche Intelligenz von Google DeepMind eine Meisterleistung vollbracht: Sie nutzte KI, um meiner Meinung nach die eigentliche Frage der diesjährigen Internationalen Mathematikolympiade zu lösen, und war nur einen Schritt davon entfernt, die Goldmedaille zu gewinnen. Der IMO-Wettbewerb, der gerade letzte Woche zu Ende ging, hatte sechs Fragen zu Algebra, Kombinatorik, Geometrie und Zahlentheorie. Das von Google vorgeschlagene hybride KI-System beantwortete vier Fragen richtig und erzielte 28 Punkte und erreichte damit die Silbermedaillenstufe. Anfang dieses Monats hatte der UCLA-Professor Terence Tao gerade die KI-Mathematische Olympiade (AIMO Progress Award) mit einem Millionenpreis gefördert. Unerwarteterweise hatte sich das Niveau der KI-Problemlösung vor Juli auf dieses Niveau verbessert. Beantworten Sie die Fragen meiner Meinung nach gleichzeitig. Am schwierigsten ist es meiner Meinung nach, da sie die längste Geschichte, den größten Umfang und die negativsten Fragen haben
 Der Standpunkt der Natur: Die Erprobung künstlicher Intelligenz in der Medizin ist im Chaos. Was ist zu tun?
Aug 22, 2024 pm 04:37 PM
Der Standpunkt der Natur: Die Erprobung künstlicher Intelligenz in der Medizin ist im Chaos. Was ist zu tun?
Aug 22, 2024 pm 04:37 PM
Herausgeber | ScienceAI Basierend auf begrenzten klinischen Daten wurden Hunderte medizinischer Algorithmen genehmigt. Wissenschaftler diskutieren darüber, wer die Werkzeuge testen soll und wie dies am besten geschieht. Devin Singh wurde Zeuge, wie ein pädiatrischer Patient in der Notaufnahme einen Herzstillstand erlitt, während er lange auf eine Behandlung wartete, was ihn dazu veranlasste, den Einsatz von KI zu erforschen, um Wartezeiten zu verkürzen. Mithilfe von Triage-Daten aus den Notaufnahmen von SickKids erstellten Singh und Kollegen eine Reihe von KI-Modellen, um mögliche Diagnosen zu stellen und Tests zu empfehlen. Eine Studie zeigte, dass diese Modelle die Zahl der Arztbesuche um 22,3 % verkürzen können und die Verarbeitung der Ergebnisse pro Patient, der einen medizinischen Test benötigt, um fast drei Stunden beschleunigt. Der Erfolg von Algorithmen der künstlichen Intelligenz in der Forschung bestätigt dies jedoch nur
 Training mit Millionen von Kristalldaten zur Lösung kristallographischer Phasenprobleme, die Deep-Learning-Methode PhAI wird in Science veröffentlicht
Aug 08, 2024 pm 09:22 PM
Training mit Millionen von Kristalldaten zur Lösung kristallographischer Phasenprobleme, die Deep-Learning-Methode PhAI wird in Science veröffentlicht
Aug 08, 2024 pm 09:22 PM
Herausgeber |KX Bis heute sind die durch die Kristallographie ermittelten Strukturdetails und Präzision, von einfachen Metallen bis hin zu großen Membranproteinen, mit keiner anderen Methode zu erreichen. Die größte Herausforderung, das sogenannte Phasenproblem, bleibt jedoch die Gewinnung von Phaseninformationen aus experimentell bestimmten Amplituden. Forscher der Universität Kopenhagen in Dänemark haben eine Deep-Learning-Methode namens PhAI entwickelt, um Kristallphasenprobleme zu lösen. Ein Deep-Learning-Neuronales Netzwerk, das mithilfe von Millionen künstlicher Kristallstrukturen und den entsprechenden synthetischen Beugungsdaten trainiert wird, kann genaue Elektronendichtekarten erstellen. Die Studie zeigt, dass diese Deep-Learning-basierte Ab-initio-Strukturlösungsmethode das Phasenproblem mit einer Auflösung von nur 2 Angström lösen kann, was nur 10 bis 20 % der bei atomarer Auflösung verfügbaren Daten im Vergleich zur herkömmlichen Ab-initio-Berechnung entspricht
 Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Übersetzer |. Rezensiert von Li Rui |. Chonglou Modelle für künstliche Intelligenz (KI) und maschinelles Lernen (ML) werden heutzutage immer komplexer, und die von diesen Modellen erzeugten Ergebnisse sind eine Blackbox, die den Stakeholdern nicht erklärt werden kann. Explainable AI (XAI) zielt darauf ab, dieses Problem zu lösen, indem es Stakeholdern ermöglicht, die Funktionsweise dieser Modelle zu verstehen, sicherzustellen, dass sie verstehen, wie diese Modelle tatsächlich Entscheidungen treffen, und Transparenz in KI-Systemen, Vertrauen und Verantwortlichkeit zur Lösung dieses Problems gewährleistet. In diesem Artikel werden verschiedene Techniken der erklärbaren künstlichen Intelligenz (XAI) untersucht, um ihre zugrunde liegenden Prinzipien zu veranschaulichen. Mehrere Gründe, warum erklärbare KI von entscheidender Bedeutung ist. Vertrauen und Transparenz: Damit KI-Systeme allgemein akzeptiert und vertrauenswürdig sind, müssen Benutzer verstehen, wie Entscheidungen getroffen werden
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
