

Es ist bekannt, dass die Inferenz großer Sprachmodelle (LLM) normalerweise die Verwendung einer autoregressiven Stichprobe erfordert und dieser Inferenzprozess ziemlich langsam ist. Um dieses Problem zu lösen, ist die spekulative Dekodierung zu einer neuen Stichprobenmethode für die LLM-Inferenz geworden. In jedem Stichprobenschritt wird diese Methode zunächst mehrere mögliche Token vorhersagen und dann parallel überprüfen, ob sie korrekt sind. Im Gegensatz zur autoregressiven Dekodierung kann die spekulative Dekodierung mehrere Token in einem einzigen Schritt dekodieren und so die Inferenz beschleunigen.
Obwohl die spekulative Dekodierung in vielerlei Hinsicht großes Potenzial aufweist, wirft sie auch einige Schlüsselfragen auf, die eingehender Forschung bedürfen. Zunächst müssen wir darüber nachdenken, wie wir ein geeignetes Näherungsmodell auswählen oder entwerfen können, um ein Gleichgewicht zwischen der Genauigkeit der Vermutung und der Effizienz der Generierung herzustellen. Zweitens muss sichergestellt werden, dass die Bewertungskriterien sowohl die Vielfalt als auch die Qualität der erzielten Ergebnisse wahren. Schließlich muss die Ausrichtung des Inferenzprozesses zwischen dem Näherungsmodell und dem großen Zielmodell sorgfältig geprüft werden, um die Genauigkeit der Inferenz zu verbessern.
Forscher der Hong Kong Polytechnic University, der Peking University, MSRA und Alibaba haben eine umfassende Umfrage zur spekulativen Dekodierung durchgeführt, und Machine Heart hat eine umfassende Zusammenfassung davon erstellt. Titel der U-Arbeit: Effizienz bei der Inferenz großer Sprachmodelle freischalten: Ein umfassender Überblick über die spekulative Dekodierung
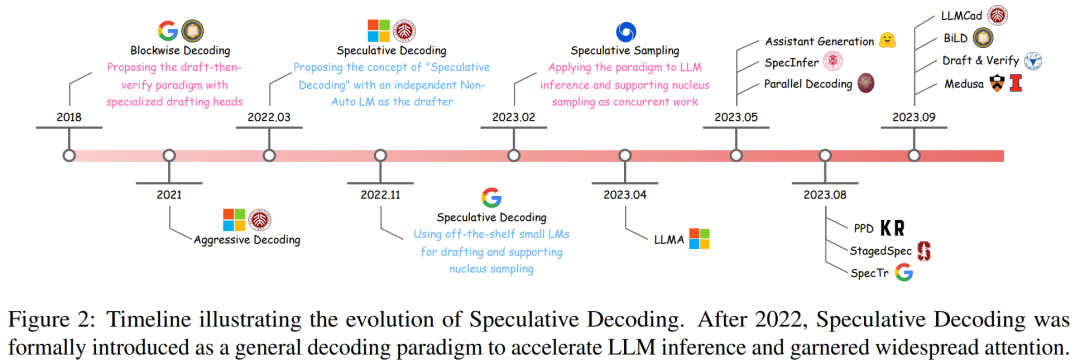
und zeigt seinen Entwicklungsprozess anhand einer Zeitleiste (siehe Abbildung 2). 
Blockwise Decoding ist eine Methode zur Integration zusätzlicher Feedforward Neural (FFN)-Köpfe in den Transformer-Decoder, die mehrere Token in einem einzigen Schritt generieren können.
Basierend auf der vorherigen Arbeit definiert dieser Artikel noch einmal formal den „spekulativen Dekodierungsalgorithmus“:
Der spekulative Dekodierungsalgorithmus ist ein Dekodierungsmodus, der zuerst generiert und dann überprüft wird. Es muss zunächst in der Lage sein, mehrere mögliche Token zu generieren und dann das große Zielsprachenmodell zu verwenden, um alle diese Token parallel auszuwerten, um die Schlussfolgerung zu beschleunigen. Algorithmustabelle 2 ist ein detaillierter spekulativer Decodierungsprozess.
Dann befasst sich dieser Artikel mit den beiden grundlegenden Teilschritten, die für dieses Paradigma von wesentlicher Bedeutung sind – Generierung und Bewertung.
 Generieren
Generieren
Bei jedem Dekodierungsschritt generiert der spekulative Dekodierungsalgorithmus zunächst mehrere mögliche Token als Spekulationen über den Ausgabeinhalt des großen Zielsprachenmodells.
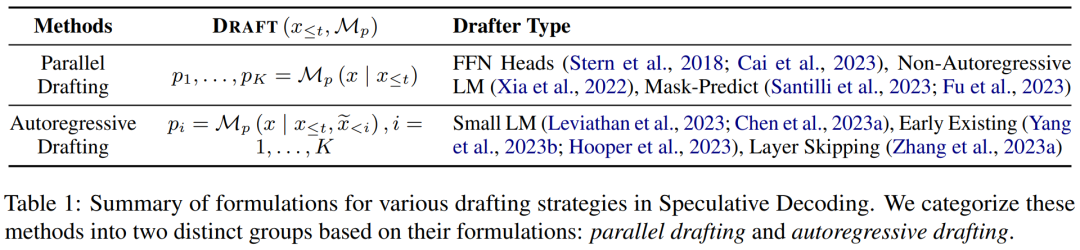
Dieser Artikel unterteilt den generierten Inhalt in zwei Kategorien: unabhängiges Verfassen und selbstverfassendes Dokument und fasst seine Formeln in der folgenden Tabelle 1 zusammen.
Validierung
In jedem Decodierungsschritt werden die vom Näherungsmodell generierten Token parallel überprüft, um sicherzustellen, dass die Ausgabequalität in hohem Maße mit dem großen Zielsprachenmodell übereinstimmt. Dieser Prozess bestimmt auch die Anzahl der bei jedem Schritt zulässigen Token, ein wichtiger Faktor, der sich auf die Geschwindigkeit auswirken kann.
Eine Zusammenfassung verschiedener Validierungskriterien ist in Tabelle 2 unten dargestellt, einschließlich derjenigen, die gierige Dekodierung und Kernel-Sampling bei der Inferenz großer Sprachmodelle unterstützen.

Die Unterschritte der Generierung und Überprüfung werden so lange iteriert, bis die Beendigungsbedingung erfüllt ist, d. h. das [EOS]-Token dekodiert wird oder der Satz die maximale Länge erreicht.
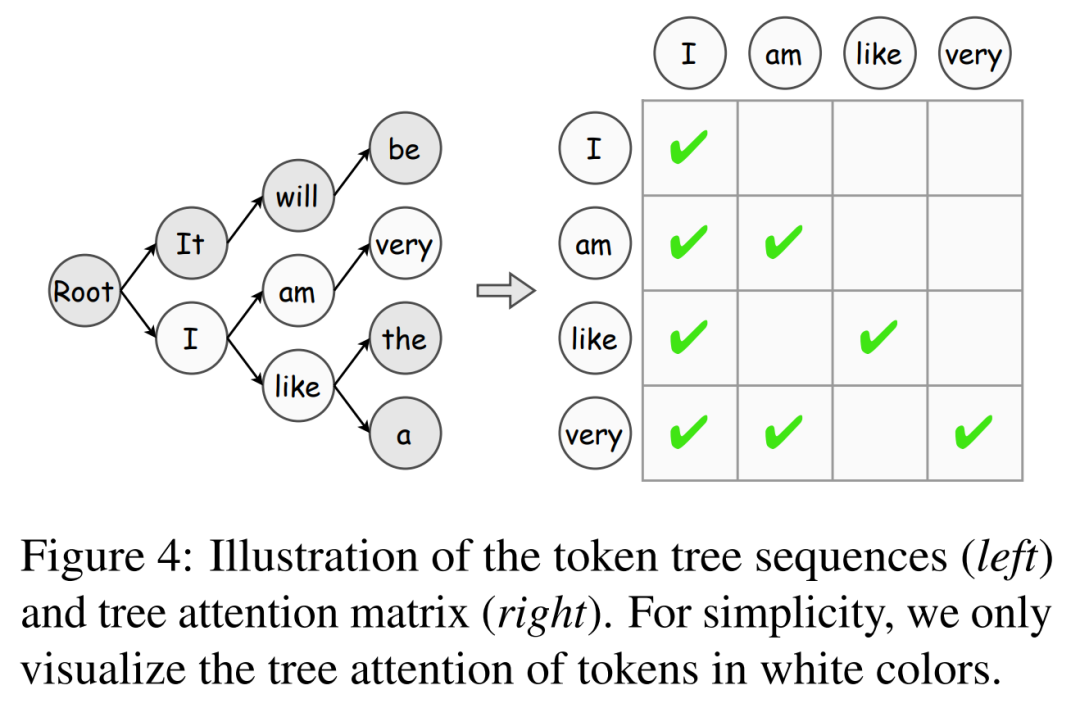
Darüber hinaus stellt dieser Artikel den Token-Tree-Verifizierungsalgorithmus vor, der eine wirksame Strategie zur schrittweisen Erhöhung der Token-Akzeptanz darstellt.
Die Verbesserung der Spekulationsgenauigkeit ist der Schlüssel zur Beschleunigung der spekulativen Dekodierung: Je näher das vorhergesagte Verhalten des Näherungsmodells am großen Zielsprachenmodell liegt, desto höher ist die Akzeptanzrate seiner generierten Token. Zu diesem Zweck untersuchen bestehende Arbeiten verschiedene Wissensextraktionsstrategien (KD), um den Ausgabeinhalt des Näherungsmodells mit dem des großen Zielsprachenmodells in Einklang zu bringen.
Die blockierte Dekodierung nutzt zunächst die Wissensextraktion auf Sequenzebene (Seq-KD) für die Modellausrichtung und trainiert das Näherungsmodell mit Sätzen, die vom großen Zielsprachenmodell generiert werden.
Darüber hinaus ist Seq-KD auch eine wirksame Strategie zur Verbesserung der Qualität der parallelen Decodierungsgenerierung und verbessert die Generierungsleistung der parallelen Decodierung.
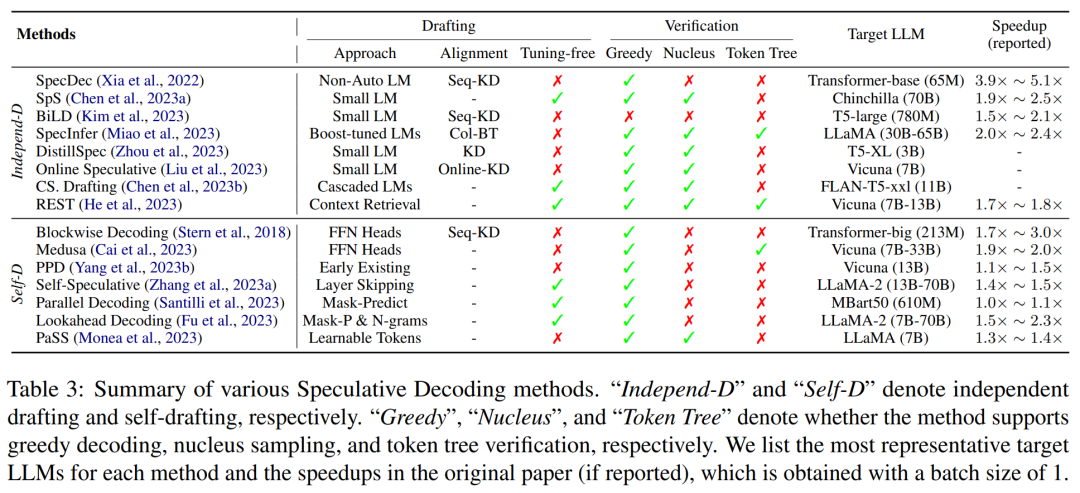
Die Hauptmerkmale bestehender spekulativer Decodierungsmethoden sind in der folgenden Tabelle 3 zusammengefasst, einschließlich der Art des Näherungsmodells oder der Generierungsstrategie, der Modellausrichtungsmethode, der unterstützten Bewertungsstrategie und des Beschleunigungsgrads.
Neuere Arbeiten sind nicht nur ein allgemeines Paradigma, sondern haben auch gezeigt, dass einige Varianten der spekulativen Dekodierung bei bestimmten Aufgaben eine außerordentliche Wirksamkeit aufweisen. Darüber hinaus haben andere Forschungsarbeiten dieses Paradigma angewendet, um Latenzprobleme zu lösen, die für bestimmte Anwendungsszenarien spezifisch sind, und so eine Inferenzbeschleunigung zu erreichen.
Einige Wissenschaftler glauben beispielsweise, dass die spekulative Dekodierung besonders für Aufgaben geeignet ist, bei denen die Modelleingabe und -ausgabe sehr ähnlich sind, wie z. B. die Korrektur grammatikalischer Fehler und die Generierung von Abrufverbesserungen.
Zusätzlich zu diesen Arbeiten verwendet RaLMSpec (Zhang et al., 2023b) spekulative Dekodierung, um den Abruf erweiterter Sprachmodelle (RaLMs) zu beschleunigen.
Frage 1: Wie sind die Genauigkeit und die Generierungseffizienz vorhergesagter Inhalte abzuwägen? Obwohl bei diesem Problem einige Fortschritte erzielt wurden, gibt es immer noch erheblichen Raum für Verbesserungen bei der Ausrichtung von Näherungsmodellen an dem, was das große Zielsprachenmodell generiert. Neben der Modellausrichtung beeinflussen auch andere Faktoren wie die Generierungsqualität und die Bestimmung der Vorhersagelänge die Genauigkeit der Vorhersagen und verdienen eine weitere Untersuchung.
Frage 2: Wie lässt sich spekulative Dekodierung mit anderen führenden Technologien kombinieren? Als allgemeiner Dekodierungsmodus wurde die spekulative Dekodierung mit anderen fortschrittlichen Technologien kombiniert, um ihr Potenzial zu demonstrieren. Neben der Beschleunigung großer Sprachmodelle für Klartext ist auch die Anwendung der spekulativen Dekodierung im multimodalen Denken, wie z. B. Bildsynthese, Text-zu-Sprache-Synthese und Videogenerierung, eine interessante und wertvolle Richtung für zukünftige Forschung.
Weitere Einzelheiten finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonWas ist die spekulative Dekodierung, die GPT-4 möglicherweise auch verwendet? Ein Artikel, der Vergangenheit, Gegenwart und Anwendungssituationen zusammenfasst. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



