

Die verbrauchten Rechenressourcen betragen nur 2/25 des herkömmlichen Stable Video Diffusion(SVD)Modells!
AnimateLCM-SVD-xt wird veröffentlicht und ändert das Videodiffusionsmodell für wiederholte Rauschunterdrückung, was zeitaufwändig ist und viele Berechnungen erfordert.
Sehen wir uns zunächst den erzeugten Animationseffekt an.
Cyberpunk-Stil ist leicht zu kontrollieren, der Junge trägt Kopfhörer und steht in der neonfarbenen Stadtstraße:
 Bilder
Bilder
Realistischer Stil kann auch verwendet werden, ein frisch verheiratetes Paar kuschelt zusammen und hält einen exquisiten Blumenstrauß in der Hand Erleben Sie die Liebe unter der alten Steinmauer:
 Bild
Bild
Science-Fiction-Stil und spüren Sie auch die Invasion der Erde durch Außerirdische:
 Bild
Bild
AnimateLCM-SVD-xt von MMLab, The Chinese Universität Hongkong, gemeinsam vorgeschlagen von Forschern von Avolution AI, Shanghai Artificial Intelligence Laboratory und SenseTime Research Institute.
 Bilder
Bilder
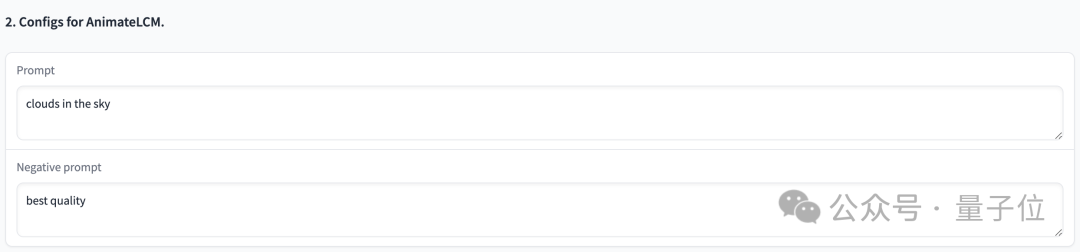
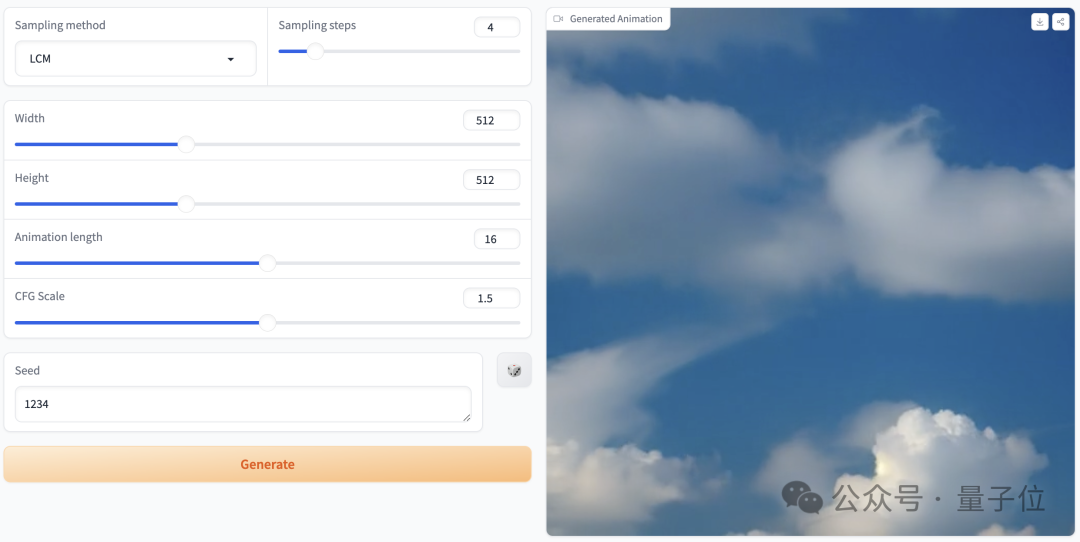
Sie können hochwertige Animationen mit 25 Bildern und einer Auflösung von 576 x 1024 in 2 bis 8 Schritten generieren, und ohne Klassifikatorführung
kann das in 4 Schritten generierte Video eine hohe Wiedergabetreue erreichen, d. h besser als herkömmliches SVD Schneller und effizienter: Bilder
Bilder
 Bilder
Bilder
 Bilder
Bilder
 Bilder
Bilder
 Bilder
Bilder
 Bild
Bild
 Bilder
Bilder
 Bilder
Bilder
 Bilder
Bilder
 Bilder
Bilder
 Bilder
Bilder
Beachten Sie, dass Videodiffusionsmodelle aufgrund ihrer Fähigkeit, kohärente und hochauflösende Videos zu erzeugen, zwar zunehmend Beachtung finden, eine der Schwierigkeiten jedoch darin besteht, dass der iterative Entrauschungsprozess nicht nur zeitaufwändig, sondern auch rechenintensiv ist, was ihn einschränkt Geltungsbereich.
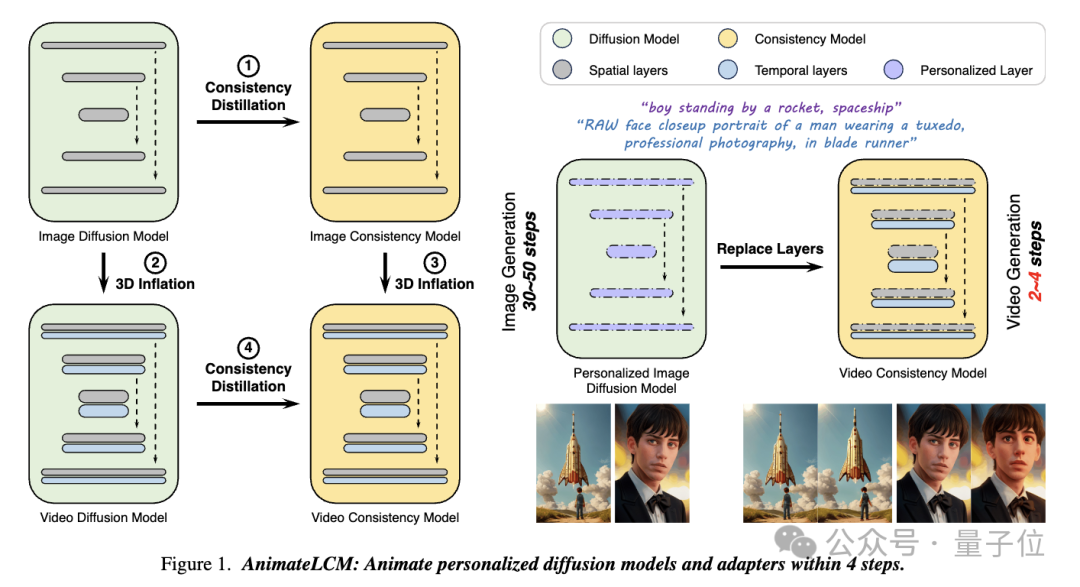
In dieser Arbeit AnimateLCM ließen sich die Forscher vom Konsistenzmodell (CM) inspirieren, das das vorab trainierte Bilddiffusionsmodell vereinfacht, um die für das Sampling erforderlichen Schritte zu reduzieren und erfolgreich auf das Latent Consistency Model (LCM) für die bedingte Bilderzeugung zu skalieren ) .
 Bild
Bild
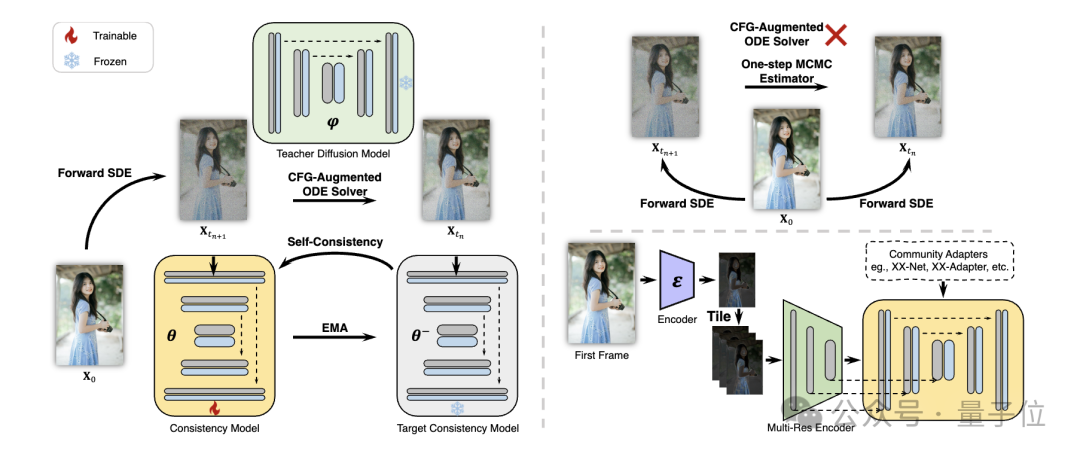
Konkret schlugen die Forscher eine Strategie des Entkoppelten Konsistenzlernens(Entkoppeltes Konsistenzlernen) vor.
Destillieren Sie zunächst das stabile Diffusionsmodell in ein Bildkonsistenzmodell für einen hochwertigen Bild-Text-Datensatz und führen Sie dann eine Konsistenzdestillation für Videodaten durch, um ein Videokonsistenzmodell zu erhalten. Diese Strategie verbessert die Trainingseffizienz durch getrenntes Training auf räumlicher und zeitlicher Ebene.
 Bilder
Bilder
Um verschiedene Funktionen von Plug-and-Play-Adaptern (z. B. Verwendung von ControlNet zur Erzielung einer steuerbaren Erzeugung) in der Stable Diffusion-Community zu implementieren, schlugen die Forscher außerdem Lehrer- vor Kostenlose Anpassung der Strategie (Lehrerfreie Anpassung), um den vorhandenen Steuerungsadapter konsistenter mit dem Konsistenzmodell zu machen und eine besser kontrollierbare Videogenerierung zu erreichen.
 Bilder
Bilder
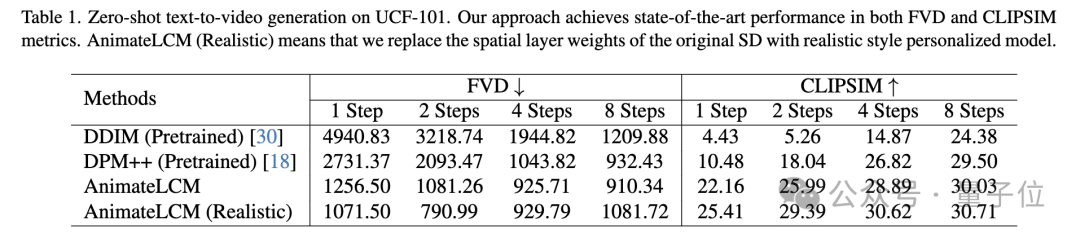
Sowohl quantitative als auch qualitative Experimente belegen die Wirksamkeit der Methode.
Bei der Zero-Shot-Text-zu-Video-Generierung auf dem UCF-101-Datensatz erzielt AnimateLCM die beste Leistung sowohl bei FVD- als auch bei CLIPSIM-Metriken. „Bild“ imatelcm. github.io/
 [2]https://huggingface.co/wangfuyun/AnimateLCM-SVD-xt
[2]https://huggingface.co/wangfuyun/AnimateLCM-SVD-xt
Das obige ist der detaillierte Inhalt vonErzeugen Sie in zwei Schritten 25 Frames hochwertiger Animationen, berechnet als 8 % der SVD | Online spielbar. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So lösen Sie das Problem „Berechtigung verweigert'.
So lösen Sie das Problem „Berechtigung verweigert'.
 iPad-Spiele haben keinen Ton
iPad-Spiele haben keinen Ton
 So implementieren Sie h5, um nach oben zu rutschen und die nächste Seite auf der Webseite zu laden
So implementieren Sie h5, um nach oben zu rutschen und die nächste Seite auf der Webseite zu laden
 Verwendung der Snoopy-Klasse in PHP
Verwendung der Snoopy-Klasse in PHP
 Schritte zum Löschen eines Dualsystems
Schritte zum Löschen eines Dualsystems
 Orakel-Kobold
Orakel-Kobold
 So verwenden Sie die Rundungsfunktion
So verwenden Sie die Rundungsfunktion
 So erstellen Sie HTML mit Webstorm
So erstellen Sie HTML mit Webstorm
 So verbergen Sie Dateierweiterungen
So verbergen Sie Dateierweiterungen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



