
 Technologie-Peripheriegeräte
KI
Die Technologie hinter der Explosion von Sora, ein Artikel, der die neueste Entwicklungsrichtung von Diffusionsmodellen zusammenfasst
Technologie-Peripheriegeräte
KI
Die Technologie hinter der Explosion von Sora, ein Artikel, der die neueste Entwicklungsrichtung von Diffusionsmodellen zusammenfasst
Die Technologie hinter der Explosion von Sora, ein Artikel, der die neueste Entwicklungsrichtung von Diffusionsmodellen zusammenfasst

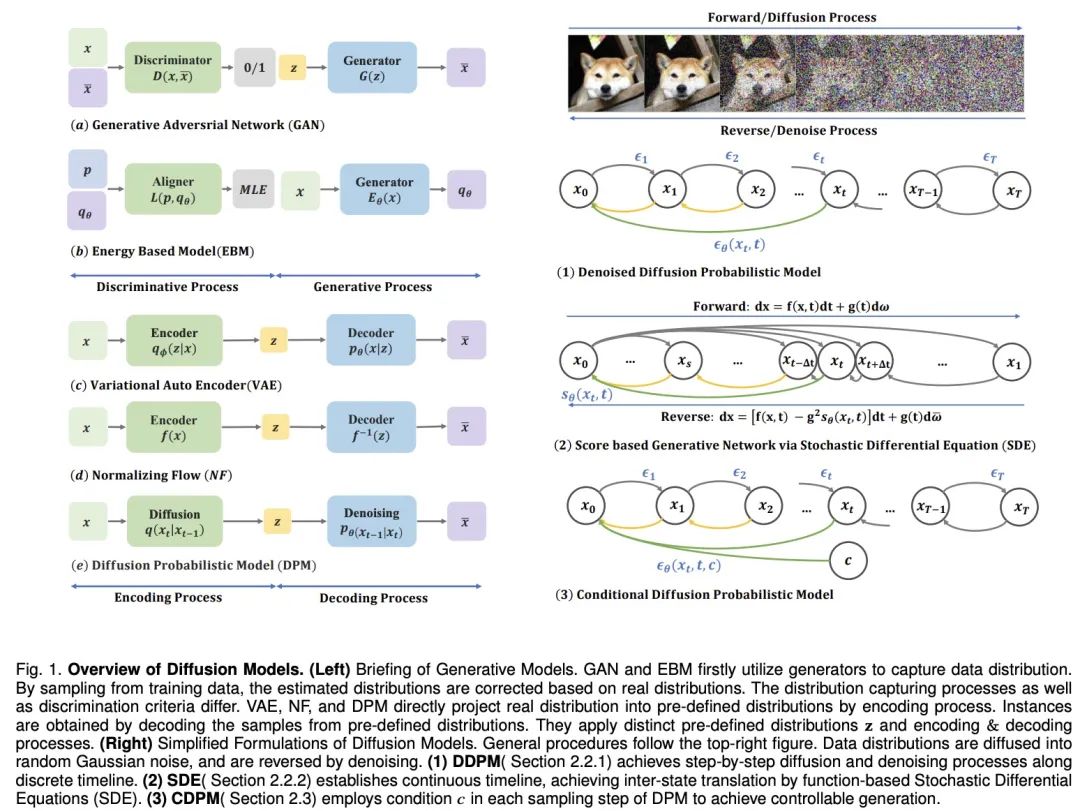

Papieradresse: https://arxiv.org/pdf/2209.02646.pdf Projektadresse: https://github.com/chq1155/A-Survey-on-Generative-Diffusion-Model?tab= readme-ov-file
-
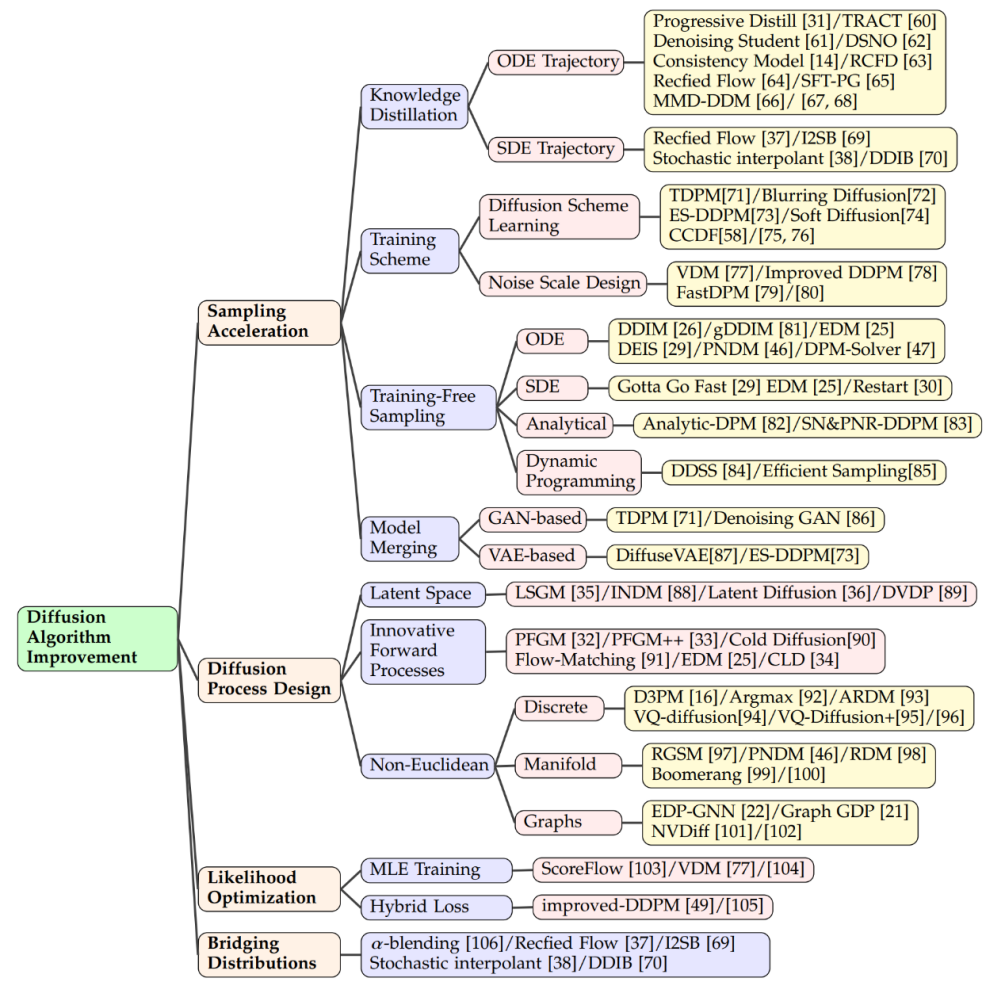
Wissensdestillation
Trainingsmethode
Trainingsfreie Probenahme
In Kombination mit anderen generativen Modellen
Latentraum-Diffusionsmodelle wie LSGM und INDM kombinieren VAE oder normalisierte Strömungsmodelle zur Entrauschung Die geteilte Gewichtung ist ein fraktionierter Matching-Verlust Wird zur Optimierung des Codecs und des Diffusionsmodells verwendet, sodass die Optimierung von ELBO oder Log-Likelihood darauf abzielt, einen latenten Raum aufzubauen, der leicht zu erlernen und Proben zu generieren ist. Beispielsweise verwendet Stable Diffusion zunächst eine VAE, um einen latenten Raum zu erlernen, und trainiert dann ein Diffusionsmodell, um Texteingaben zu akzeptieren. DVDP passt die orthogonalen Komponenten des Pixelraums während einer Bildstörung dynamisch an.
Um die Effizienz und Stärke des generativen Modells zu verbessern, haben Forscher neue Vorwärtsprozessdesigns erforscht. Das Poisson-Felderzeugungsmodell behandelt die Daten als Ladungen und lenkt eine einfache Verteilung auf die Datenverteilung entlang der elektrischen Feldlinien, was eine leistungsfähigere Rückabtastung als herkömmliche Diffusionsmodelle ermöglicht. PFGM++ führt dieses Konzept weiter auf hochdimensionale Variablen aus. Das kritisch gedämpfte Langevin-Diffusionsmodell von Dockhorn et al. vereinfacht das Lernen gebrochener Funktionen bedingter Geschwindigkeitsverteilungen mithilfe von Geschwindigkeitsvariablen in der Hamilton-Dynamik.
Im Diffusionsmodell diskreter räumlicher Daten (z. B. Text, kategoriale Daten) definiert D3PM den Vorwärtsprozess des diskreten Raums. Basierend auf dieser Methode wurde die Forschung auf die Generierung von Sprachtexten, die Segmentierung von Diagrammen und die verlustfreie Komprimierung ausgeweitet. Bei multimodalen Herausforderungen werden vektorquantisierte Daten in Codes umgewandelt, die bessere Ergebnisse liefern. Mannigfaltige Daten in Riemannschen Mannigfaltigkeiten, wie z. B. Robotik und Proteinmodellierung, erfordern die Integration von Diffusionsproben in die Riemannsche Mannigfaltigkeit. Kombinationen aus graphischen neuronalen Netzen und Diffusionstheorie, wie etwa EDP-GNN und GraphGDP, verarbeiten Graphendaten, um die Permutationsinvarianz zu erfassen.
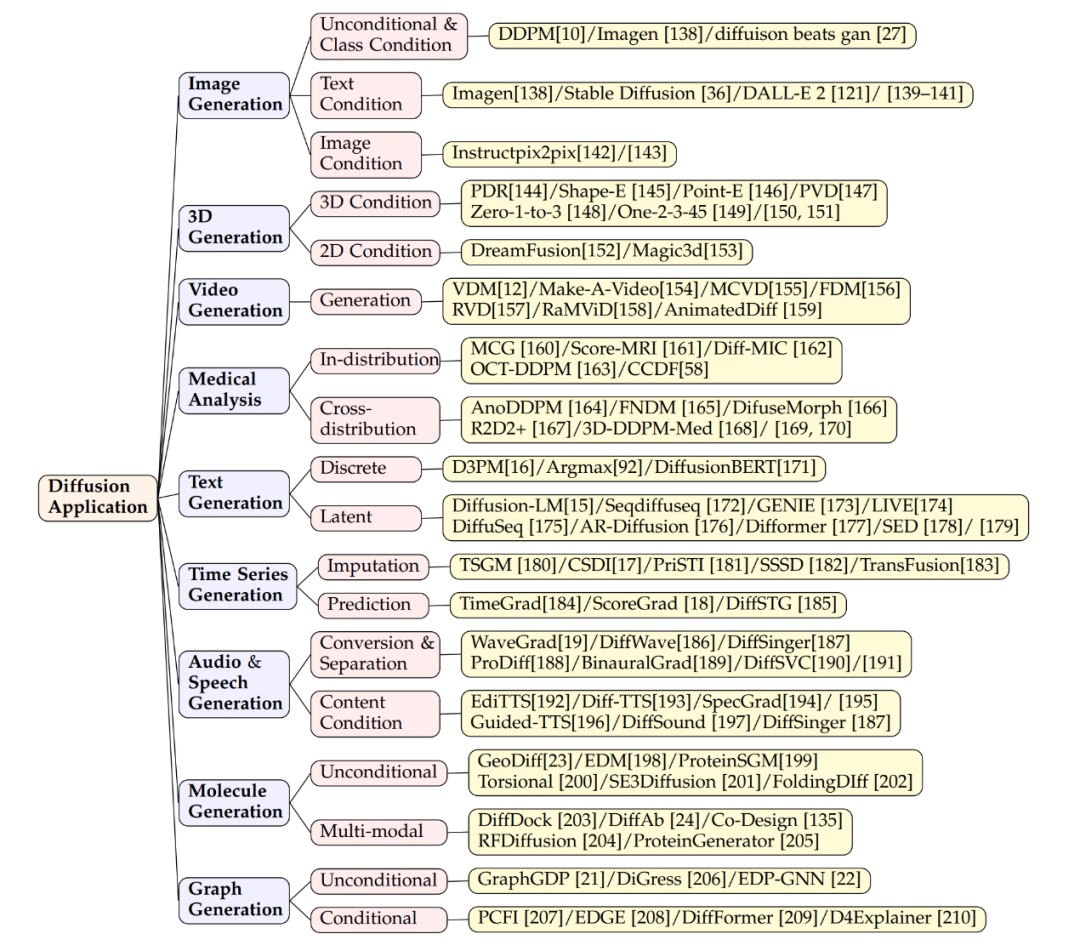
Kontrollierbare verteilungsbasierte Generierung
Erweiterte multimodale Generierung unter Verwendung großer Sprachmodelle
Integration mit dem Bereich des maschinellen Lernens
Feldanwendungsmethode (Anhang)
Das obige ist der detaillierte Inhalt vonDie Technologie hinter der Explosion von Sora, ein Artikel, der die neueste Entwicklungsrichtung von Diffusionsmodellen zusammenfasst. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Was sind die zehn besten Handelsplattformen für virtuelle Währung?
Feb 20, 2025 pm 02:15 PM
Was sind die zehn besten Handelsplattformen für virtuelle Währung?
Feb 20, 2025 pm 02:15 PM
Mit der Popularität von Kryptowährungen sind virtuelle Währungshandelsplattformen entstanden. Die zehn besten Handelsplattformen der virtuellen Währung der Welt werden nach dem Transaktionsvolumen und dem Marktanteil wie folgt eingestuft: Binance, Coinbase, FTX, Kucoin, Crypto.com, Kraken, Huobi, Gate.io, Bitfinex, Gemini. Diese Plattformen bieten eine breite Palette von Dienstleistungen, die von einer Vielzahl von Kryptowährungsauswahl bis hin zu Derivatenhandel reichen und für Händler unterschiedlicher Ebene geeignet sind.
 Einführung in PEPU-Währungstypen
Dec 12, 2024 am 11:43 AM
Einführung in PEPU-Währungstypen
Dec 12, 2024 am 11:43 AM
PEPU Coin ist ein ERC-20-Token, der auf der Ethereum-Blockchain basiert, von PEPU.io betrieben und als nativer Token in seiner PEPU-Anwendung verwendet wird.
 So passen Sie den Sesam offenen Austausch in Chinesisch an
Mar 04, 2025 pm 11:51 PM
So passen Sie den Sesam offenen Austausch in Chinesisch an
Mar 04, 2025 pm 11:51 PM
Wie kann ich den Sesam offenen Austausch an Chinesisch anpassen? Dieses Tutorial behandelt detaillierte Schritte zu Computern und Android -Mobiltelefonen, von der vorläufigen Vorbereitung bis hin zu operativen Prozessen und dann bis zur Lösung gemeinsamer Probleme, um die Sesam -Open Exchange -Schnittstelle auf Chinesisch zu wechseln und schnell mit der Handelsplattform zu beginnen.
 Was sind die sicheren und zuverlässigen digitalen Währungsplattformen?
Mar 17, 2025 pm 05:42 PM
Was sind die sicheren und zuverlässigen digitalen Währungsplattformen?
Mar 17, 2025 pm 05:42 PM
Eine sichere und zuverlässige Plattform für digitale Währung: 1. OKX, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. Kucoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini. Sicherheit, Liquidität, Handhabungsgebühren, Währungsauswahl, Benutzeroberfläche und Kundensupport sollten bei der Auswahl einer Plattform berücksichtigt werden.
 Top 10 Top -Currency -Handelsplattformen 2025 Cryptocurrency Trading Apps, die die Top Ten ringen
Mar 17, 2025 pm 05:54 PM
Top 10 Top -Currency -Handelsplattformen 2025 Cryptocurrency Trading Apps, die die Top Ten ringen
Mar 17, 2025 pm 05:54 PM
Top Ten Ten Virtual Currency Trading Platforms 2025: 1. OKX, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. Kucoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini. Sicherheit, Liquidität, Handhabungsgebühren, Währungsauswahl, Benutzeroberfläche und Kundensupport sollten bei der Auswahl einer Plattform berücksichtigt werden.
 Top 10 Cryptocurrency -Handelsplattformen, Top Ten empfohlene Apps für Währungshandelsplattformen
Mar 17, 2025 pm 06:03 PM
Top 10 Cryptocurrency -Handelsplattformen, Top Ten empfohlene Apps für Währungshandelsplattformen
Mar 17, 2025 pm 06:03 PM
Zu den zehn Top -Kryptowährungsplattformen gehören: 1. OKX, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. Kucoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini. Sicherheit, Liquidität, Handhabungsgebühren, Währungsauswahl, Benutzeroberfläche und Kundensupport sollten bei der Auswahl einer Plattform berücksichtigt werden.
 Welcher der zehn besten Apps für virtuelle Währung ist die besten?
Mar 19, 2025 pm 05:00 PM
Welcher der zehn besten Apps für virtuelle Währung ist die besten?
Mar 19, 2025 pm 05:00 PM
Top 10 Apps Rankings von Virtual Currency Trading: 1. OKX, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. Kucoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini. Sicherheit, Liquidität, Handhabungsgebühren, Währungsauswahl, Benutzeroberfläche und Kundenbetreuung sollten bei der Auswahl einer Plattform berücksichtigt werden.
 Empfohlene sichere Apps mit sicheren Virtual Currency Software Top 10 Top 10 Digital Currency Trading Apps Ranking 2025
Mar 17, 2025 pm 05:48 PM
Empfohlene sichere Apps mit sicheren Virtual Currency Software Top 10 Top 10 Digital Currency Trading Apps Ranking 2025
Mar 17, 2025 pm 05:48 PM
Empfohlene Safe Virtual Currency Software Apps: 1. OKX, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. Kucoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini. Sicherheit, Liquidität, Handhabungsgebühren, Währungsauswahl, Benutzeroberfläche und Kundensupport sollten bei der Auswahl einer Plattform berücksichtigt werden.
