
 Technologie-Peripheriegeräte
KI
Neues SOTA zur Zielerkennung: YOLOv9 erscheint und die neue Architektur erweckt die traditionelle Faltung wieder zum Leben
Technologie-Peripheriegeräte
KI
Neues SOTA zur Zielerkennung: YOLOv9 erscheint und die neue Architektur erweckt die traditionelle Faltung wieder zum Leben
Neues SOTA zur Zielerkennung: YOLOv9 erscheint und die neue Architektur erweckt die traditionelle Faltung wieder zum Leben

Im Bereich der Zielerkennung macht YOLOv9 weiterhin Fortschritte im Implementierungsprozess. Durch die Einführung neuer Architekturen und Methoden wird die Parameternutzung der herkömmlichen Faltung effektiv verbessert, wodurch die Leistung den Produkten der vorherigen Generation weit überlegen ist.
Nach der offiziellen Veröffentlichung von YOLOv8 im Januar 2023, mehr als ein Jahr später, ist YOLOv9 endlich da!
Seit Joseph Redmon, Ali Farhadi und andere im Jahr 2015 das YOLO-Modell der ersten Generation vorgeschlagen haben, haben Forscher auf dem Gebiet der Zielerkennung es viele Male aktualisiert und iteriert. YOLO ist ein Vorhersagesystem, das auf globalen Bildinformationen basiert und dessen Modellleistung kontinuierlich verbessert wird. Durch die kontinuierliche Verbesserung von Algorithmen und Technologien haben Forscher bemerkenswerte Ergebnisse erzielt und YOLO bei Zielerkennungsaufgaben immer leistungsfähiger gemacht. Diese kontinuierlichen Verbesserungen und Optimierungen haben neue Chancen und Herausforderungen für die Entwicklung der Zielerkennungstechnologie mit sich gebracht und gleichzeitig den Fortschritt und die Innovation in diesem Bereich gefördert. Der Erfolg von YOLO hat auch Forscher dazu inspiriert, ihre Bemühungen fortzusetzen
Dieses Mal wurde YOLOv9 gemeinsam von der Academia Sinica in Taiwan, der Taipei University of Technology und anderen Institutionen entwickelt " wurde veröffentlicht.

Papieradresse: https://arxiv.org/pdf/2402.13616.pdf
GitHub-Adresse: https://github.com/WongKinYiu/yolov9
Die heutigen Deep-Learning-Methoden konzentrieren sich darauf, wie man am meisten entwirft geeignete Zielfunktion, sodass die Vorhersageergebnisse des Modells der realen Situation am nächsten kommen können. Gleichzeitig muss eine geeignete Architektur entworfen werden, die dabei helfen kann, ausreichend Informationen für die Vorhersage zu erhalten. Bestehende Methoden ignorieren jedoch die Tatsache, dass bei der schichtweisen Merkmalsextraktion und räumlichen Transformation der Eingabedaten eine große Menge an Informationen verloren geht.
Daher untersucht YOLOv9 eingehend die wichtigen Probleme des Datenverlusts, wenn Daten über tiefe Netzwerke übertragen werden, nämlich Informationsengpässe und umkehrbare Funktionen.
Forscher schlugen das Konzept der „programmierbaren Gradienteninformation (PGI)“ vor, um die verschiedenen Änderungen zu bewältigen, die tiefe Netzwerke zum Erreichen mehrerer Ziele erfordern. PGI kann vollständige Eingabeinformationen für die Zielaufgabe zur Berechnung der Zielfunktion bereitstellen und so zuverlässige Gradienteninformationen zur Aktualisierung der Netzwerkgewichte erhalten. Darüber hinaus entwarfen Forscher eine neue, leichtgewichtige Netzwerkarchitektur, die auf der Gradientenpfadplanung basiert, nämlich
Generalized Efficient Layer Aggregation Network (GELAN). Diese Architektur bestätigt, dass PGI bei leichten Modellen hervorragende Ergebnisse erzielen kann. Die Forscher überprüften das vorgeschlagene GELAN und die PGI für die Zielerkennungsaufgabe basierend auf dem MS COCO-Datensatz. Die Ergebnisse zeigen, dass GELAN im Vergleich zu SOTA-Methoden, die auf der Grundlage tiefer Faltungen entwickelt wurden, eine bessere Parameterausnutzung erreicht, wenn nur herkömmliche Faltungsoperatoren verwendet werden.
Für PGI ist es sehr anpassungsfähig und kann auf verschiedenen Modellen von leicht bis groß verwendet werden. Wir können dies nutzen, um vollständige Informationen zu erhalten, sodass
ein von Grund auf trainiertes Modell bessere Ergebnisse erzielen kannals ein SOTA-Modell, das mit einem großen Datensatz vorab trainiert wurde. Abbildung 1 unten zeigt einige Vergleichsergebnisse.
 Alexey Bochkovskiy, der an der Entwicklung von YOLOv7, YOLOv4, Scaled-YOLOv4 und DPT beteiligt war, lobte das neu veröffentlichte YOLOv9 und sagte, dass YOLOv9 besser sei als jeder auf Faltung oder Transformator basierende Objektdetektor .
Alexey Bochkovskiy, der an der Entwicklung von YOLOv7, YOLOv4, Scaled-YOLOv4 und DPT beteiligt war, lobte das neu veröffentlichte YOLOv9 und sagte, dass YOLOv9 besser sei als jeder auf Faltung oder Transformator basierende Objektdetektor . 
Quelle: https://twitter.com/alexeyab84/status/1760685626247250342Einige Internetnutzer sagten: Scheint der neue SOTA-Echtzeit-Objektdetektor zu sein, der über ein eigenes benutzerdefiniertes Schulungs-Tutorial verfügt auch der Weg.


Quelle: https://twitter.com/skalskip92/status/1760717291593834648S Einige „fleißige“ Internetnutzer haben dem YOLOv9-Modell Pip-Unterstützung hinzugefügt. P Quelle: https://twitter.com/kadirnar_ai/status/1760716187896283635
In den Details von YOLOV9. Problemstellung
Normalerweise führen Menschen das Konvergenzschwierigkeitsproblem tiefer
neuronaler Netzeauf Faktoren wie das Verschwinden des Gradienten oder die Gradientensättigung zurück, und diese Phänomene gibt es in traditionellen tiefen neuronalen Netzen. Moderne tiefe
neuronale Netzehaben die oben genannten Probleme jedoch grundsätzlich gelöst, indem sie verschiedene Normalisierungs- und Aktivierungsfunktionen entworfen haben. Dennoch gibt es immer noch Probleme mit einer langsamen Konvergenzgeschwindigkeit oder einem schlechten Konvergenzeffekt in tiefen neuronalen Netzen. Was ist also der Kern dieses Problems? Durch eine eingehende Analyse des Informationsengpasses leiteten die Forscher die Grundursache des Problems ab: Kurz nachdem der Gradient zunächst aus dem sehr tiefen Netzwerk herausgegeben wurde, gehen viele der zum Erreichen des Ziels erforderlichen Informationen verloren. Um diese Schlussfolgerung zu überprüfen, führten die Forscher eine Feedforward-Verarbeitung in tiefen Netzwerken unterschiedlicher Architektur mit Anfangsgewichten durch. Abbildung 2 veranschaulicht dies visuell. Offensichtlich verliert PlainNet viele wichtige Informationen, die für die Objekterkennung in tiefen Schichten erforderlich sind. Der Anteil wichtiger Informationen, den ResNet, CSPNet und GELAN behalten können, steht in der Tat in einem positiven Zusammenhang mit der Genauigkeit, die nach dem Training erreicht werden kann. Darüber hinaus entwickelten die Forscher eine auf reversiblen Netzwerken basierende Methode, um die Ursachen der oben genannten Probleme zu lösen. Einführung in die Methode
Programmierbare Gradienteninformationen (PGI)Diese Studie schlägt einen neuen Hilfsüberwachungsrahmen vor: Programmierbare Gradienteninformationen (PGI), wie in Abbildung 3(d) gezeigt.
PGI besteht hauptsächlich aus drei Teilen, nämlich (1) Hauptzweig, (2) umkehrbarer Hilfszweig, (3) mehrstufige Hilfsinformationen.
Der Inferenzprozess von PGI verwendet nur den Hauptzweig, sodass keine zusätzlichen Argumentationskosten anfallen.
- Der umkehrbare Hilfszweig dient der Bewältigung der durch die Vertiefung des neuronalen Netzwerks verursachten Probleme und zu Verlustfunktionen führen. Es ist nicht möglich, zuverlässige Gradienten zu generieren.
- GELAN-Netzwerk Darüber hinaus schlug die Studie auch eine neue Netzwerkarchitektur GELAN vor (wie in der Abbildung unten gezeigt). Konkret kombinierten die Forscher die beiden neuronalen Netzwerkarchitekturen CSPNet und ELAN und entwarfen so eine verallgemeinerte Effizienz Layer Aggregation Network (GELAN), das Leichtgewichtigkeit, Inferenzgeschwindigkeit und Genauigkeit berücksichtigt. Die Forscher verallgemeinerten die Fähigkeiten von ELAN, das ursprünglich nur Stapel von Faltungsschichten nutzte, auf eine neue Architektur, die jeden Rechenblock nutzen kann.
Experimentelle Ergebnisse
Um die Leistung von YOLOv9 zu bewerten, verglich diese Studie YOLOv9 zunächst umfassend mit anderen von Grund auf trainierten Echtzeit-Objektdetektoren. Die Ergebnisse sind in Tabelle 1 unten aufgeführt.
Ablationsexperimente


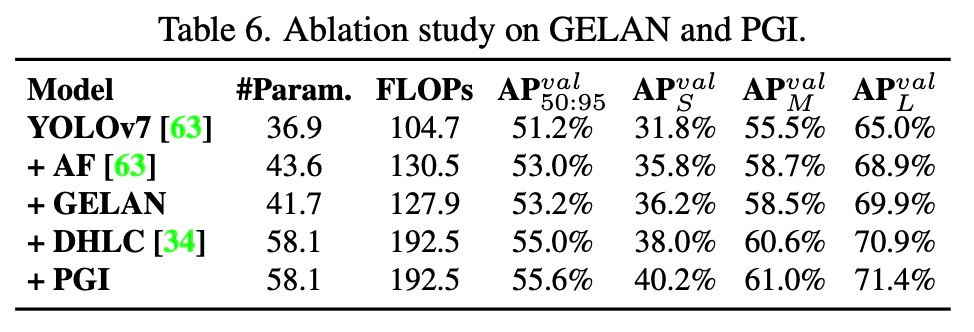
Dann führte die Studie Ablationsexperimente an GELAN unterschiedlicher Größe für ELAN-Blocktiefe und CSP-Blocktiefe durch. Die Ergebnisse sind in Tabelle 3 unten aufgeführt. 
In Bezug auf PGI führten die Forscher Ablationsstudien zu reversiblen Hilfszweigen und mehrstufigen Hilfsinformationen zum Rückgratnetzwerk bzw. zum Hals durch. Tabelle 4 listet die Ergebnisse aller Experimente auf. Wie aus Tabelle 4 ersichtlich ist, ist PFH nur für tiefe Modelle wirksam, während das in diesem Artikel vorgeschlagene PGI die Genauigkeit bei verschiedenen Kombinationen verbessern kann.

Die Forscher implementierten außerdem PGI und Tiefenüberwachung an Modellen unterschiedlicher Größe und verglichen die Ergebnisse. Die Ergebnisse sind in Tabelle 5 dargestellt.

Abbildung 6 zeigt die Ergebnisse des schrittweisen Hinzufügens von Komponenten von der Basislinie YOLOv7 zu YOLOv9-E.
Visualisierung
Die Forscher untersuchten das Problem des Informationsengpasses und visualisierten es. Abbildung 6 zeigt die Visualisierungsergebnisse der Feature-Maps, die mit zufälligen Anfangsgewichten als Feedforward unter verschiedenen Architekturen erhalten wurden.

Abbildung 7 zeigt, ob PGI während des Trainings zuverlässigere Gradienten liefern kann, sodass die zur Aktualisierung verwendeten Parameter die Beziehung zwischen den Eingabedaten und dem Ziel effektiv erfassen können.

Für weitere technische Details lesen Sie bitte den Originalartikel.
Das obige ist der detaillierte Inhalt vonNeues SOTA zur Zielerkennung: YOLOv9 erscheint und die neue Architektur erweckt die traditionelle Faltung wieder zum Leben. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 So verwenden Sie SQL DateTime
Apr 09, 2025 pm 06:09 PM
So verwenden Sie SQL DateTime
Apr 09, 2025 pm 06:09 PM
Der Datentyp der DateTime wird verwendet, um Datum und Uhrzeitinformationen mit hoher Präzision zu speichern, zwischen 0001-01-01 00:00:00 bis 9999-12-31 23: 59: 59.9999999999999999999999999999999999999999999. Zonenkonvertierungsfunktionen, müssen sich jedoch potenzielle Probleme bewusst sein, wenn sie Präzision, Reichweite und Zeitzonen umwandeln.
 Kann ich das Datenbankkennwort in Navicat abrufen?
Apr 08, 2025 pm 09:51 PM
Kann ich das Datenbankkennwort in Navicat abrufen?
Apr 08, 2025 pm 09:51 PM
Navicat selbst speichert das Datenbankkennwort nicht und kann das verschlüsselte Passwort nur abrufen. Lösung: 1. Überprüfen Sie den Passwort -Manager. 2. Überprüfen Sie Navicats "Messnot Password" -Funktion; 3.. Setzen Sie das Datenbankkennwort zurück; 4. Kontaktieren Sie den Datenbankadministrator.
 Wie kann ich das Datenbankkennwort in Navicat für Mariadb anzeigen?
Apr 08, 2025 pm 09:18 PM
Wie kann ich das Datenbankkennwort in Navicat für Mariadb anzeigen?
Apr 08, 2025 pm 09:18 PM
Navicat für MariADB kann das Datenbankkennwort nicht direkt anzeigen, da das Passwort in verschlüsselter Form gespeichert ist. Um die Datenbanksicherheit zu gewährleisten, gibt es drei Möglichkeiten, Ihr Passwort zurückzusetzen: Setzen Sie Ihr Passwort über Navicat zurück und legen Sie ein komplexes Kennwort fest. Zeigen Sie die Konfigurationsdatei an (nicht empfohlen, ein hohes Risiko). Verwenden Sie Systembefehlsleitungs -Tools (nicht empfohlen, Sie müssen die Befehlszeilen -Tools beherrschen).
 Die Methode von Navicat zum Anzeigen von PostgreSQL -Datenbankkennwort
Apr 08, 2025 pm 09:57 PM
Die Methode von Navicat zum Anzeigen von PostgreSQL -Datenbankkennwort
Apr 08, 2025 pm 09:57 PM
Es ist unmöglich, Postgresql -Passwörter direkt von Navicat anzuzeigen, da Navicat Passwörter aus Sicherheitsgründen gespeichert sind. Um das Passwort zu bestätigen, versuchen Sie, eine Verbindung zur Datenbank herzustellen. Um das Kennwort zu ändern, verwenden Sie bitte die grafische Schnittstelle von PSQL oder Navicat. Für andere Zwecke müssen Sie die Verbindungsparameter im Code konfigurieren, um hartcodierte Passwörter zu vermeiden. Um die Sicherheit zu verbessern, wird empfohlen, starke Passwörter, regelmäßige Änderungen zu verwenden und die Authentifizierung von Multi-Faktoren zu aktivieren.
 Kann MySQL und MariadB auf demselben Server installiert werden?
Apr 08, 2025 pm 05:00 PM
Kann MySQL und MariadB auf demselben Server installiert werden?
Apr 08, 2025 pm 05:00 PM
MySQL und MariADB können gleichzeitig auf einem einzigen Server installiert werden, um die Anforderungen verschiedener Projekte für bestimmte Datenbankversionen oder -funktionen zu erfüllen. Die folgenden Details müssen beachtet werden: verschiedene Portnummern; verschiedene Datenverzeichnisse; angemessene Allokation von Ressourcen; Überwachung der Versionskompatibilität.
 So löschen Sie Zeilen, die bestimmte Kriterien in SQL erfüllen
Apr 09, 2025 pm 12:24 PM
So löschen Sie Zeilen, die bestimmte Kriterien in SQL erfüllen
Apr 09, 2025 pm 12:24 PM
Verwenden Sie die Anweisung Löschen, um Daten aus der Datenbank zu löschen und die Löschkriterien über die WHERE -Klausel anzugeben. Beispielsyntax: löschen aus table_name wobei Bedingung; HINWEIS: Sicherung von Daten, bevor Sie Löschvorgänge ausführen, Anweisungen in der Testumgebung überprüfen, mit der Grenzklausel die Anzahl der gelöschten Zeilen einschränken, die Where -Klausel sorgfältig überprüfen, um Fehld) zu vermeiden, und die Indizes zur Optimierung der Löschwirkungsgrad großer Tabellen verwenden.
 Wie füge ich Spalten in PostgreSQL hinzu?
Apr 09, 2025 pm 12:36 PM
Wie füge ich Spalten in PostgreSQL hinzu?
Apr 09, 2025 pm 12:36 PM
PostgreSQL Die Methode zum Hinzufügen von Spalten besteht darin, den Befehl zur Änderungstabelle zu verwenden und die folgenden Details zu berücksichtigen: Datentyp: Wählen Sie den Typ, der für die neue Spalte geeignet ist, um Daten wie int oder varchar zu speichern. Standardeinstellung: Geben Sie den Standardwert der neuen Spalte über das Standard -Schlüsselwort an und vermeiden Sie den Wert von NULL. Einschränkungen: Fügen Sie nicht null, eindeutig hinzu oder überprüfen Sie die Einschränkungen bei Bedarf. Gleichzeitige Operationen: Verwenden Sie Transaktionen oder andere Parallelitätskontrollmechanismen, um Sperrkonflikte beim Hinzufügen von Spalten zu verarbeiten.
 Kann MySQL mit dem SQL -Server eine Verbindung herstellen?
Apr 08, 2025 pm 05:54 PM
Kann MySQL mit dem SQL -Server eine Verbindung herstellen?
Apr 08, 2025 pm 05:54 PM
Nein, MySQL kann keine direkt zu SQL Server herstellen. Sie können jedoch die folgenden Methoden verwenden, um die Dateninteraktion zu implementieren: Verwenden Sie Middleware: Exportieren Sie Daten von MySQL in das Zwischenformat und importieren sie dann über Middleware in SQL Server. Verwenden von Datenbank -Linker: Business -Tools bieten eine freundlichere Oberfläche und erweiterte Funktionen, die im Wesentlichen weiterhin über Middleware implementiert werden.
