
 Technologie-Peripheriegeräte
KI
Die Tsinghua University und Ideal schlugen DriveVLM vor, ein visuelles großes Sprachmodell zur Verbesserung der autonomen Fahrfähigkeiten
Technologie-Peripheriegeräte
KI
Die Tsinghua University und Ideal schlugen DriveVLM vor, ein visuelles großes Sprachmodell zur Verbesserung der autonomen Fahrfähigkeiten
Die Tsinghua University und Ideal schlugen DriveVLM vor, ein visuelles großes Sprachmodell zur Verbesserung der autonomen Fahrfähigkeiten

Im Bereich des autonomen Fahrens untersuchen Forscher auch die Richtung großer Modelle wie GPT/Sora.
Im Vergleich zur generativen KI ist das autonome Fahren auch einer der aktivsten Forschungs- und Entwicklungsbereiche in der jüngsten KI. Eine große Herausforderung beim Aufbau eines vollständig autonomen Fahrsystems ist das Szenenverständnis der KI, das komplexe, unvorhersehbare Szenarien wie Unwetter, komplexe Straßenführungen und unvorhersehbares menschliches Verhalten umfasst.
Das aktuelle autonome Fahrsystem besteht normalerweise aus drei Teilen: 3D-Wahrnehmung, Bewegungsvorhersage und Planung. Insbesondere wird die 3D-Wahrnehmung hauptsächlich zum Erkennen und Verfolgen bekannter Objekte verwendet, ihre Fähigkeit, seltene Objekte und ihre Eigenschaften zu identifizieren, ist jedoch begrenzt, während sich die Bewegungsvorhersage und -planung hauptsächlich auf die Flugbahnaktionen von Objekten konzentriert, die Beziehung zwischen Objekten und Fahrzeugen jedoch normalerweise ignoriert . Interaktionen auf Entscheidungsebene zwischen Diese Einschränkungen können die Genauigkeit und Sicherheit autonomer Fahrsysteme bei der Bewältigung komplexer Verkehrsszenarien beeinträchtigen. Daher muss die zukünftige autonome Fahrtechnologie weiter verbessert werden, um verschiedene Arten von Objekten besser zu identifizieren und vorherzusagen und den Fahrweg des Fahrzeugs effektiver zu planen, um die Intelligenz und Zuverlässigkeit des Systems zu verbessern
Der Schlüssel zum Erreichen des autonomen Fahrens Das Ziel ist um einen datengesteuerten Ansatz in einen wissensgesteuerten Ansatz umzuwandeln, der das Training großer Modelle mit logischen Argumentationsfähigkeiten erfordert. Nur so kann das autonome Fahrsystem das Long-Tail-Problem wirklich lösen und sich den L4-Fähigkeiten nähern. Da große Modelle wie GPT4 und Sora weiterhin auf dem Vormarsch sind, hat der Skaleneffekt auch leistungsstarke Wenig-Schuss-/Null-Schuss-Fähigkeiten gezeigt, was die Menschen dazu veranlasst hat, über eine neue Entwicklungsrichtung nachzudenken.
Die neueste Forschungsarbeit stammt vom Cross Information Institute der Tsinghua University und Li Auto und stellt ein neues Modell namens DriveVLM vor. Dieses Modell ist vom Visual Language Model (VLM) inspiriert, das im Bereich der generativen künstlichen Intelligenz auftaucht. DriveVLM hat hervorragende Fähigkeiten im visuellen Verständnis und Argumentation bewiesen.
Diese Arbeit ist die erste in der Branche, die ein autonomes Fahrgeschwindigkeitskontrollsystem vorschlägt. Ihre Methode kombiniert den gängigen autonomen Fahrprozess vollständig mit einem groß angelegten Modellprozess mit logischen Denkfähigkeiten und ist das erste Mal, dass ein großes System erfolgreich eingesetzt wird maßstabsgetreues Modell zum Testen auf ein Terminal übertragen (basierend auf der Orin-Plattform).
DriveVLM deckt einen Chain-of-Though (CoT)-Prozess ab, der drei Hauptmodule umfasst: Szenariobeschreibung, Szenarioanalyse und hierarchische Planung. Im Szenenbeschreibungsmodul wird Sprache verwendet, um die Fahrumgebung zu beschreiben und Schlüsselobjekte in der Szene zu identifizieren. Das Szenenanalysemodul untersucht eingehend die Eigenschaften dieser Schlüsselobjekte und ihre Auswirkungen auf autonome Fahrzeuge, während das hierarchische Planungsmodul schrittweise Pläne formuliert Die Elemente Aktionen und Entscheidungen werden zu Wegpunkten beschrieben.
Diese Module entsprechen den Wahrnehmungs-, Vorhersage- und Planungsschritten herkömmlicher autonomer Fahrsysteme. Der Unterschied besteht jedoch darin, dass sie die Objektwahrnehmung, die Vorhersage auf Absichtsebene und die Planung auf Aufgabenebene abwickeln, was in der Vergangenheit eine große Herausforderung darstellte.
Obwohl VLMs beim visuellen Verständnis gute Leistungen erbringen, weisen sie Einschränkungen bei der räumlichen Basis und beim Denken auf, und ihre Anforderungen an die Rechenleistung stellen eine Herausforderung für die Geschwindigkeit des endseitigen Denkens dar. Daher schlagen die Autoren weiterhin DriveVLMDual vor, ein Hybridsystem, das die Vorteile von DriveVLM und traditionellen Systemen vereint. DriveVLM-Dual integriert DriveVLM optional mit herkömmlichen 3D-Wahrnehmungs- und Planungsmodulen wie 3D-Objektdetektoren, Belegungsnetzwerken und Bewegungsplanern, wodurch das System 3D-Erdungs- und Hochfrequenzplanungsfunktionen erreichen kann. Dieses Dual-System-Design ähnelt den langsamen und schnellen Denkprozessen des menschlichen Gehirns und kann sich effektiv an unterschiedliche Komplexitäten in Fahrszenarien anpassen.
Die neue Forschung klärt außerdem die Definition von Szenenverständnis- und Planungsaufgaben (SUP) weiter und schlägt einige neue Bewertungsmetriken vor, um die Fähigkeiten von DriveVLM und DriveVLM-Dual bei der Szenenanalyse und Metaaktionsplanung zu bewerten. Darüber hinaus führten die Autoren umfangreiche Data-Mining- und Annotationsarbeiten durch, um einen internen SUP-AD-Datensatz für die SUP-Aufgabe zu erstellen.
Umfangreiche Experimente mit dem nuScenes-Datensatz und unseren eigenen Datensätzen zeigen die Überlegenheit von DriveVLM, insbesondere bei einer geringen Anzahl von Aufnahmen. Darüber hinaus übertrifft DriveVLM-Dual modernste End-to-End-Bewegungsplanungsmethoden.
Paper „DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models“

Paper-Link: https://arxiv.org/abs/2402.12289
Projekt-Link: https://tsinghua-mars- lab.github.io/DriveVLM/
Der Gesamtprozess von DriveVLM ist in Abbildung 1 dargestellt:
Kontinuierliche Bildbilder kodieren, mit LMM über das Feature-Alignment-Modul interagieren
Beginnen Sie mit der Szenenbeschreibung Denken Sie an das VLM-Modell und steuern Sie zunächst die statischen Szenen wie Zeit, Szene, Fahrspurumgebung usw. und dann die wichtigsten Hindernisse, die sich auf Fahrentscheidungen auswirken.
Analysieren Sie die wichtigsten Hindernisse und gleichen Sie sie durch herkömmliche 3D-Erkennung ab Von VLM verstandene Hindernisse bestätigen die Wirksamkeit von Hindernissen und beseitigen Illusionen und beschreiben die Eigenschaften der wichtigsten Hindernisse in diesem Szenario und ihre Auswirkungen auf unser Fahrverhalten
Gibt wichtige „Meta-Entscheidungen“ wie Verlangsamen, Parken, Links- und Rechtsabbiegen usw. und gibt dann eine Beschreibung der Fahrstrategie basierend auf den Meta-Entscheidungen und schließlich die zukünftige Fahrroute von das Trägerfahrzeug.
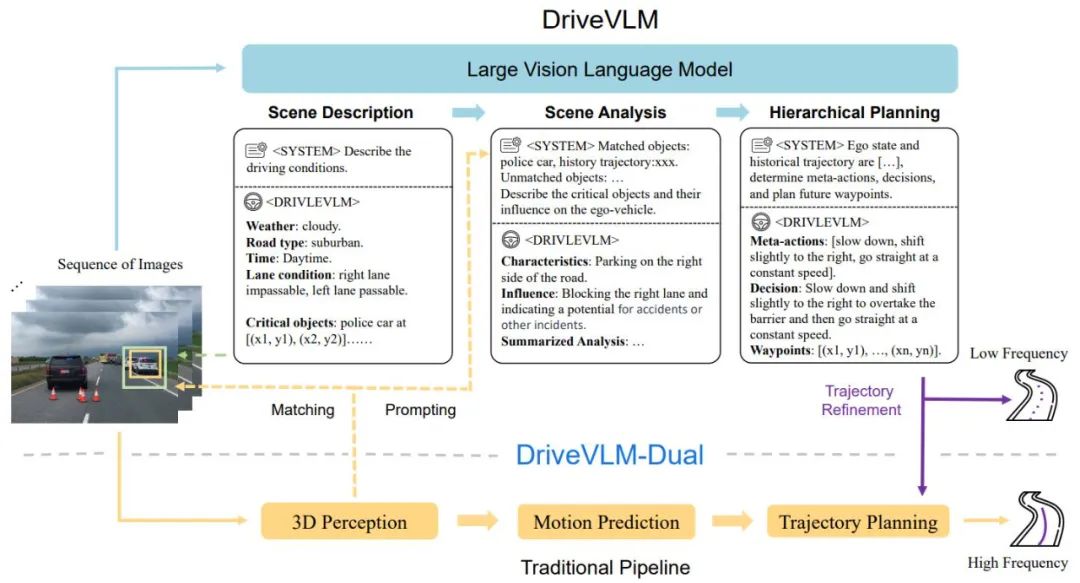
Abbildung 1. DriveVLM- und DriveVLM-Dual-Modellpipeline. Eine Bildsequenz wird von einem großen visuellen Sprachmodell (VLM) verarbeitet, um eine spezielle Gedankenkette (CoT) durchzuführen und daraus Fahrplanungsergebnisse abzuleiten. Großes VLM umfasst einen visuellen Transformator-Encoder und ein großes Sprachmodell (LLM). Ein visueller Encoder erzeugt Bild-Tags; ein aufmerksamkeitsbasierter Extraktor gleicht diese Tags dann mit einem LLM ab und schließlich führt der LLM eine CoT-Inferenz durch. Der CoT-Prozess kann in drei Module unterteilt werden: Szenariobeschreibung, Szenarioanalyse und hierarchische Planung.
DriveVLM-Dual ist ein Hybridsystem, das das umfassende Verständnis der Umgebung von DriveVLM und Vorschläge für Entscheidungsverläufe nutzt, um die Entscheidungs- und Planungsfähigkeiten der traditionellen Pipeline für autonomes Fahren zu verbessern. Es integriert 3D-Wahrnehmungsergebnisse in verbale Hinweise, um das Verständnis von 3D-Szenen zu verbessern, und verfeinert Flugbahn-Wegpunkte mit einem Echtzeit-Bewegungsplaner weiter.
Obwohl VLMs gut darin sind, Long-Tail-Objekte zu identifizieren und komplexe Szenen zu verstehen, haben sie oft Schwierigkeiten, die räumliche Position und den detaillierten Bewegungsstatus von Objekten genau zu verstehen, ein Mangel, der eine erhebliche Herausforderung darstellt. Erschwerend kommt hinzu, dass die enorme Modellgröße von VLM zu einer hohen Latenz führt und die Echtzeit-Reaktionsfähigkeit des autonomen Fahrens beeinträchtigt. Um diese Herausforderungen anzugehen, schlägt der Autor DriveVLM-Dual vor, das die Zusammenarbeit von DriveVLM und herkömmlichen autonomen Fahrsystemen ermöglicht. Dieser neue Ansatz umfasst zwei Schlüsselstrategien: Schlüsselobjektanalyse in Kombination mit 3D-Wahrnehmung, um hochdimensionale Fahrentscheidungsinformationen zu liefern, und Hochfrequenzverfeinerung der Flugbahn.
Um das Potenzial von DriveVLM und DriveVLMDual bei der Bewältigung komplexer und langwieriger Fahrszenarien voll auszuschöpfen, definierten die Forscher außerdem offiziell eine Aufgabe namens Szenenverständnisplanung sowie eine Reihe von Bewertungsmetriken. Darüber hinaus schlagen die Autoren ein Data-Mining- und Annotationsprotokoll vor, um das Szenenverständnis und die Planung von Datensätzen zu verwalten.
Um das Modell vollständig zu trainieren, hat der Autor eine Reihe von Drive LLM-Annotationstools und Annotationslösungen neu entwickelt. Durch eine Kombination aus automatisiertem Mining, Wahrnehmungsalgorithmus-Pre-Brushing, GPT-4-Zusammenfassung großer Modelle und manueller Annotation Mit diesem effizienten Annotationsschema wurde ein aktuelles Modell erstellt, in dem alle Clip-Daten Dutzende von Annotationsinhalten enthalten.

Der Autor schlug außerdem eine umfassende Data-Mining- und Annotations-Pipeline vor, wie in Abbildung 3 dargestellt, um einen SUP-AD-Datensatz (Scene Understanding for Planning in Autonomous Driving) für die vorgeschlagene Aufgabe zu erstellen, der mehr als 100.000 Bilder und mehr als 1.000 Bilder enthält. Textpaare. Insbesondere führen die Autoren zunächst Long-Tail-Objekt-Mining und anspruchsvolles Szenen-Mining aus einer großen Datenbank durch, um Proben zu sammeln. Anschließend wählen sie aus jeder Probe einen Keyframe aus und führen anschließend Szenenanmerkungen durch.
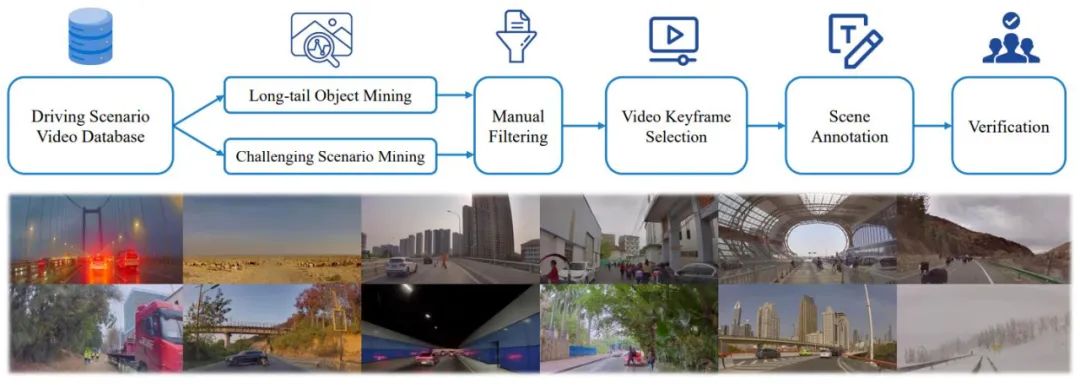
Abbildung 3. Data Mining- und Annotationspipeline zum Aufbau von Szenarioverständnissen und Planungsdatensätzen (oben). Beispiele für zufällig aus dem Datensatz (unten) entnommene Szenarien veranschaulichen die Vielfalt und Komplexität des Datensatzes.
SUP-AD ist in Trainings-, Verifizierungs- und Testteile im Verhältnis 7,5:1:1,5 unterteilt. Die Autoren trainieren das Modell auf der Trainingsaufteilung und verwenden neu vorgeschlagene Szenenbeschreibungen und Metaaktionsmetriken, um die Modellleistung auf der Validierungs-/Testaufteilung zu bewerten.
nuScenes-Datensatz ist ein groß angelegter Datensatz zum Fahren städtischer Szenen mit 1000 Szenen, die jeweils etwa 20 Sekunden dauern. Keyframes werden im gesamten Datensatz gleichmäßig mit 2 Hz annotiert. Hier verwenden die Autoren den Verschiebungsfehler (DE) und die Kollisionsrate (CR) als Indikatoren, um die Leistung des Modells bei der Verifizierungssegmentierung zu bewerten.
Die Autoren demonstrieren die Leistung von DriveVLM mit mehreren großen visuellen Sprachmodellen und vergleichen sie mit GPT-4V, wie in Tabelle 1 dargestellt. DriveVLM nutzt Qwen-VL als Rückgrat, das im Vergleich zu anderen Open-Source-VLMs die beste Leistung erzielt und sich durch Reaktionsfähigkeit und flexible Interaktion auszeichnet. Die ersten beiden großen Modelle waren Open-Source-Modelle und nutzten dieselben Daten für die Feinabstimmung des Trainings. GPT-4V nutzt komplexe Eingabeaufforderungen für die schnelle Entwicklung.
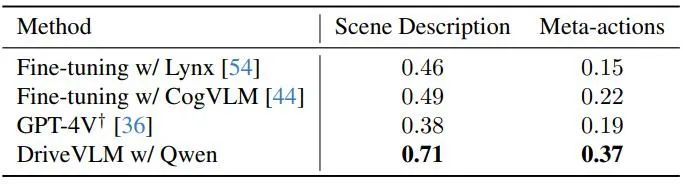
Tabelle 1. Testsatzergebnisse für den SUP-AD-Datensatz. Hier wird die offizielle API von GPT-4V verwendet und für Lynx und CogVLM werden Trainingssplits zur Feinabstimmung verwendet.
Wie in Tabelle 2 gezeigt, erreicht DriveVLM-Dual in Kombination mit VAD die Leistung auf dem neuesten Stand der Technik bei nuScenes-Planungsaufgaben. Dies zeigt, dass die neue Methode, obwohl sie auf das Verständnis komplexer Szenen zugeschnitten ist, auch in gewöhnlichen Szenen gut funktioniert. Beachten Sie, dass sich DriveVLM-Dual gegenüber UniAD erheblich verbessert: Der durchschnittliche Planungsverschiebungsfehler wird um 0,64 Meter und die Kollisionsrate um 51 % reduziert.
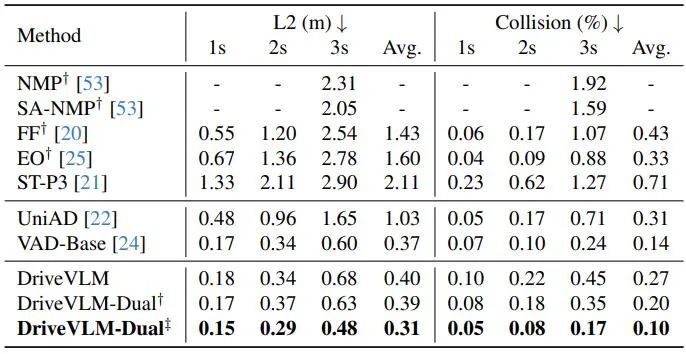
Tabelle 2. Planungsergebnisse für den nuScenes-Validierungsdatensatz. DriveVLM-Dual erreicht optimale Leistung. †Stellt Wahrnehmungs- und Belegungsvorhersageergebnisse mit Uni-AD dar. ‡ Zeigt die Arbeit mit VAD an, wobei alle Modelle Ego-Zustände als Eingabe verwenden. Abbildung 4. Qualitative Ergebnisse von DriveVLM. Die orangefarbene Kurve stellt die geplante zukünftige Flugbahn des Modells für die nächsten 3 Sekunden dar. 
Das obige ist der detaillierte Inhalt vonDie Tsinghua University und Ideal schlugen DriveVLM vor, ein visuelles großes Sprachmodell zur Verbesserung der autonomen Fahrfähigkeiten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Der DeepMind-Roboter spielt Tischtennis und seine Vor- und Rückhand rutschen in die Luft, wodurch menschliche Anfänger völlig besiegt werden
Aug 09, 2024 pm 04:01 PM
Der DeepMind-Roboter spielt Tischtennis und seine Vor- und Rückhand rutschen in die Luft, wodurch menschliche Anfänger völlig besiegt werden
Aug 09, 2024 pm 04:01 PM
Aber vielleicht kann er den alten Mann im Park nicht besiegen? Die Olympischen Spiele in Paris sind in vollem Gange und Tischtennis hat viel Aufmerksamkeit erregt. Gleichzeitig haben Roboter auch beim Tischtennisspielen neue Durchbrüche erzielt. Gerade hat DeepMind den ersten lernenden Roboteragenten vorgeschlagen, der das Niveau menschlicher Amateurspieler im Tischtennis-Wettkampf erreichen kann. Papieradresse: https://arxiv.org/pdf/2408.03906 Wie gut ist der DeepMind-Roboter beim Tischtennisspielen? Vermutlich auf Augenhöhe mit menschlichen Amateurspielern: Sowohl Vorhand als auch Rückhand: Der Gegner nutzt unterschiedliche Spielstile, und auch der Roboter hält aus: Aufschlagannahme mit unterschiedlichem Spin: Allerdings scheint die Intensität des Spiels nicht so intensiv zu sein wie Der alte Mann im Park. Für Roboter, Tischtennis
 Die erste mechanische Klaue! Yuanluobao trat auf der Weltroboterkonferenz 2024 auf und stellte den ersten Schachroboter vor, der das Haus betreten kann
Aug 21, 2024 pm 07:33 PM
Die erste mechanische Klaue! Yuanluobao trat auf der Weltroboterkonferenz 2024 auf und stellte den ersten Schachroboter vor, der das Haus betreten kann
Aug 21, 2024 pm 07:33 PM
Am 21. August fand in Peking die Weltroboterkonferenz 2024 im großen Stil statt. Die Heimrobotermarke „Yuanluobot SenseRobot“ von SenseTime hat ihre gesamte Produktfamilie vorgestellt und kürzlich den Yuanluobot AI-Schachspielroboter – Chess Professional Edition (im Folgenden als „Yuanluobot SenseRobot“ bezeichnet) herausgebracht und ist damit der weltweit erste A-Schachroboter für heim. Als drittes schachspielendes Roboterprodukt von Yuanluobo hat der neue Guoxiang-Roboter eine Vielzahl spezieller technischer Verbesserungen und Innovationen in den Bereichen KI und Maschinenbau erfahren und erstmals die Fähigkeit erkannt, dreidimensionale Schachfiguren aufzunehmen B. durch mechanische Klauen an einem Heimroboter, und führen Sie Mensch-Maschine-Funktionen aus, z. B. Schach spielen, jeder spielt Schach, Überprüfung der Notation usw.
 Claude ist auch faul geworden! Netizen: Lernen Sie, sich einen Urlaub zu gönnen
Sep 02, 2024 pm 01:56 PM
Claude ist auch faul geworden! Netizen: Lernen Sie, sich einen Urlaub zu gönnen
Sep 02, 2024 pm 01:56 PM
Der Schulstart steht vor der Tür und nicht nur die Schüler, die bald ins neue Semester starten, sollten auf sich selbst aufpassen, sondern auch die großen KI-Modelle. Vor einiger Zeit war Reddit voller Internetnutzer, die sich darüber beschwerten, dass Claude faul werde. „Sein Niveau ist stark gesunken, es kommt oft zu Pausen und sogar die Ausgabe wird sehr kurz. In der ersten Woche der Veröffentlichung konnte es ein komplettes 4-seitiges Dokument auf einmal übersetzen, aber jetzt kann es nicht einmal eine halbe Seite ausgeben.“ !
 Auf der Weltroboterkonferenz wurde dieser Haushaltsroboter, der „die Hoffnung auf eine zukünftige Altenpflege' in sich trägt, umzingelt
Aug 22, 2024 pm 10:35 PM
Auf der Weltroboterkonferenz wurde dieser Haushaltsroboter, der „die Hoffnung auf eine zukünftige Altenpflege' in sich trägt, umzingelt
Aug 22, 2024 pm 10:35 PM
Auf der World Robot Conference in Peking ist die Präsentation humanoider Roboter zum absoluten Mittelpunkt der Szene geworden. Am Stand von Stardust Intelligent führte der KI-Roboterassistent S1 drei große Darbietungen mit Hackbrett, Kampfkunst und Kalligraphie auf Ein Ausstellungsbereich, der sowohl Literatur als auch Kampfkunst umfasst, zog eine große Anzahl von Fachpublikum und Medien an. Durch das elegante Spiel auf den elastischen Saiten demonstriert der S1 eine feine Bedienung und absolute Kontrolle mit Geschwindigkeit, Kraft und Präzision. CCTV News führte einen Sonderbericht über das Nachahmungslernen und die intelligente Steuerung hinter „Kalligraphie“ durch. Firmengründer Lai Jie erklärte, dass hinter den seidenweichen Bewegungen die Hardware-Seite die beste Kraftkontrolle und die menschenähnlichsten Körperindikatoren (Geschwindigkeit, Belastung) anstrebt. usw.), aber auf der KI-Seite werden die realen Bewegungsdaten von Menschen gesammelt, sodass der Roboter stärker werden kann, wenn er auf eine schwierige Situation stößt, und lernen kann, sich schnell weiterzuentwickeln. Und agil
 Bekanntgabe der ACL 2024 Awards: Eines der besten Papers zum Thema Oracle Deciphering von HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
Bekanntgabe der ACL 2024 Awards: Eines der besten Papers zum Thema Oracle Deciphering von HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
Bei dieser ACL-Konferenz haben die Teilnehmer viel gewonnen. Die sechstägige ACL2024 findet in Bangkok, Thailand, statt. ACL ist die führende internationale Konferenz im Bereich Computerlinguistik und Verarbeitung natürlicher Sprache. Sie wird von der International Association for Computational Linguistics organisiert und findet jährlich statt. ACL steht seit jeher an erster Stelle, wenn es um akademischen Einfluss im Bereich NLP geht, und ist außerdem eine von der CCF-A empfohlene Konferenz. Die diesjährige ACL-Konferenz ist die 62. und hat mehr als 400 innovative Arbeiten im Bereich NLP eingereicht. Gestern Nachmittag gab die Konferenz den besten Vortrag und weitere Auszeichnungen bekannt. Diesmal gibt es 7 Best Paper Awards (zwei davon unveröffentlicht), 1 Best Theme Paper Award und 35 Outstanding Paper Awards. Die Konferenz verlieh außerdem drei Resource Paper Awards (ResourceAward) und einen Social Impact Award (
 Hongmeng Smart Travel S9 und die umfassende Einführungskonferenz für neue Produkte wurden gemeinsam mit einer Reihe neuer Blockbuster-Produkte veröffentlicht
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 und die umfassende Einführungskonferenz für neue Produkte wurden gemeinsam mit einer Reihe neuer Blockbuster-Produkte veröffentlicht
Aug 08, 2024 am 07:02 AM
Heute Nachmittag begrüßte Hongmeng Zhixing offiziell neue Marken und neue Autos. Am 6. August veranstaltete Huawei die Hongmeng Smart Xingxing S9 und die Huawei-Konferenz zur Einführung neuer Produkte mit umfassendem Szenario und brachte die Panorama-Smart-Flaggschiff-Limousine Xiangjie S9, das neue M7Pro und Huawei novaFlip, MatePad Pro 12,2 Zoll, das neue MatePad Air und Huawei Bisheng mit Mit vielen neuen Smart-Produkten für alle Szenarien, darunter die Laserdrucker der X1-Serie, FreeBuds6i, WATCHFIT3 und der Smart Screen S5Pro, von Smart Travel über Smart Office bis hin zu Smart Wear baut Huawei weiterhin ein Smart-Ökosystem für alle Szenarien auf, um Verbrauchern ein Smart-Erlebnis zu bieten Internet von allem. Hongmeng Zhixing: Huawei arbeitet mit chinesischen Partnern aus der Automobilindustrie zusammen, um die Modernisierung der Smart-Car-Industrie voranzutreiben
 Das Team von Li Feifei schlug ReKep vor, um Robotern räumliche Intelligenz zu verleihen und GPT-4o zu integrieren
Sep 03, 2024 pm 05:18 PM
Das Team von Li Feifei schlug ReKep vor, um Robotern räumliche Intelligenz zu verleihen und GPT-4o zu integrieren
Sep 03, 2024 pm 05:18 PM
Tiefe Integration von Vision und Roboterlernen. Wenn zwei Roboterhände reibungslos zusammenarbeiten, um Kleidung zu falten, Tee einzuschenken und Schuhe zu packen, gepaart mit dem humanoiden 1X-Roboter NEO, der in letzter Zeit für Schlagzeilen gesorgt hat, haben Sie vielleicht das Gefühl: Wir scheinen in das Zeitalter der Roboter einzutreten. Tatsächlich sind diese seidigen Bewegungen das Produkt fortschrittlicher Robotertechnologie + exquisitem Rahmendesign + multimodaler großer Modelle. Wir wissen, dass nützliche Roboter oft komplexe und exquisite Interaktionen mit der Umgebung erfordern und die Umgebung als Einschränkungen im räumlichen und zeitlichen Bereich dargestellt werden kann. Wenn Sie beispielsweise möchten, dass ein Roboter Tee einschenkt, muss der Roboter zunächst den Griff der Teekanne ergreifen und sie aufrecht halten, ohne den Tee zu verschütten, und ihn dann sanft bewegen, bis die Öffnung der Kanne mit der Öffnung der Tasse übereinstimmt , und neigen Sie dann die Teekanne in einem bestimmten Winkel. Das
 Getestet 7 Artefakte zur Videogenerierung auf „Sora-Ebene'. Wer hat die Fähigkeit, den „Eisernen Thron' zu besteigen?
Aug 05, 2024 pm 07:19 PM
Getestet 7 Artefakte zur Videogenerierung auf „Sora-Ebene'. Wer hat die Fähigkeit, den „Eisernen Thron' zu besteigen?
Aug 05, 2024 pm 07:19 PM
Herausgeber des Machine Power Report: Yang Wen Wer kann der King of AI-Videokreis werden? In der amerikanischen Fernsehserie „Game of Thrones“ gibt es einen „Eisernen Thron“. Der Legende nach wurde es vom riesigen Drachen „Schwarzer Tod“ erschaffen, der Tausende von von Feinden weggeworfenen Schwertern zum Schmelzen brachte und so höchste Autorität symbolisierte. Um auf diesem eisernen Stuhl zu sitzen, begannen die großen Familien zu kämpfen und zu kämpfen. Seit der Entstehung von Sora wurde im KI-Videokreis ein energisches „Game of Thrones“ gestartet. Zu den Hauptakteuren in diesem Spiel zählen RunwayGen-3 und Luma von der anderen Seite des Ozeans sowie die einheimischen Kuaishou Keling, ByteDream, und Zhimo. Spectrum Qingying, Vidu, PixVerseV2 usw. Heute werden wir bewerten und sehen, wer qualifiziert ist, auf dem „Eisernen Thron“ des KI-Videokreises zu sitzen. -1- Vincent Video
