
 Technologie-Peripheriegeräte
KI
Brechen Sie in die unterste Schicht der KI ein! Das Team von NUS Youyang verwendet ein Diffusionsmodell, um neuronale Netzwerkparameter zu konstruieren, LeCun gefällt es
Technologie-Peripheriegeräte
KI
Brechen Sie in die unterste Schicht der KI ein! Das Team von NUS Youyang verwendet ein Diffusionsmodell, um neuronale Netzwerkparameter zu konstruieren, LeCun gefällt es
Brechen Sie in die unterste Schicht der KI ein! Das Team von NUS Youyang verwendet ein Diffusionsmodell, um neuronale Netzwerkparameter zu konstruieren, LeCun gefällt es

Das Diffusionsmodell hat eine wichtige neue Anwendung eröffnet –
Genau wie Sora Videos generiert, generiert es Parameter für neuronale Netze und dringt direkt in die unterste Schicht der KI ein!
Dies ist das neueste Open-Source-Forschungsergebnis des Teams von Professor You Yang an der National University of Singapore zusammen mit UCB, Meta AI Laboratory und anderen Institutionen.

Konkret schlug das Forschungsteam ein Diffusionsmodell p(arameter)-diff zur Generierung neuronaler Netzwerkparameter vor.
Verwenden Sie es zum Generieren von Netzwerkparametern. Die Geschwindigkeit ist bis zu 44-mal schneller als beim direkten Training und die Leistung ist nicht minderwertig.
Nachdem das Modell veröffentlicht wurde, löste es schnell hitzige Diskussionen in der KI-Community aus. Experten im Kreis zeigten die gleiche erstaunliche Einstellung wie normale Menschen, als sie Sora sahen.
Einige Leute behaupteten sogar direkt, dies sei im Grunde gleichbedeutend mit der Schaffung neuer KI durch KI.

Sogar der KI-Riese LeCun lobte diese Leistung, nachdem er sie gesehen hatte, und sagte, dass es wirklich eine nette Idee sei.
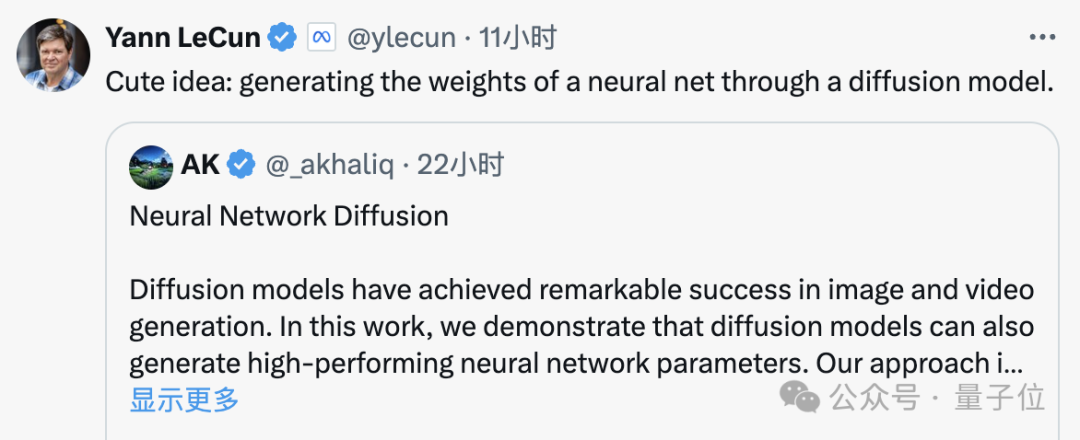
Tatsächlich hat p-diff die gleiche Bedeutung wie Sora macht Sora zu einem Weltsimulator (der AGI aus einer Dimension annähert).
Und diese Arbeit, die Diffusion neuronaler Netze, kann Parameter im Modell generieren und hat das Potenzial, ein Meta-Weltklasse-Lerner/Optimierer zu werden, der sich von einer anderen neuen wichtigen Dimension in Richtung AGI bewegt.
 Zurück zum Thema: Wie generiert p-diff neuronale Netzwerkparameter?
Zurück zum Thema: Wie generiert p-diff neuronale Netzwerkparameter?
Kombination des Autoencoders mit dem Diffusionsmodell
Um dieses Problem zu verstehen, müssen wir zunächst die Arbeitseigenschaften des Diffusionsmodells und des neuronalen Netzwerks verstehen.
Der Diffusionserzeugungsprozess ist die Umwandlung von einer Zufallsverteilung in eine hochspezifische Verteilung. Durch die Hinzufügung von zusammengesetztem Rauschen werden die visuellen Informationen auf eine einfache Rauschverteilung reduziert.
Das Training neuronaler Netze folgt ebenfalls diesem Transformationsprozess und kann durch Hinzufügen von Rauschen ebenfalls beeinträchtigt werden. Inspiriert durch diese Funktion schlugen Forscher die p-diff-Methode vor.
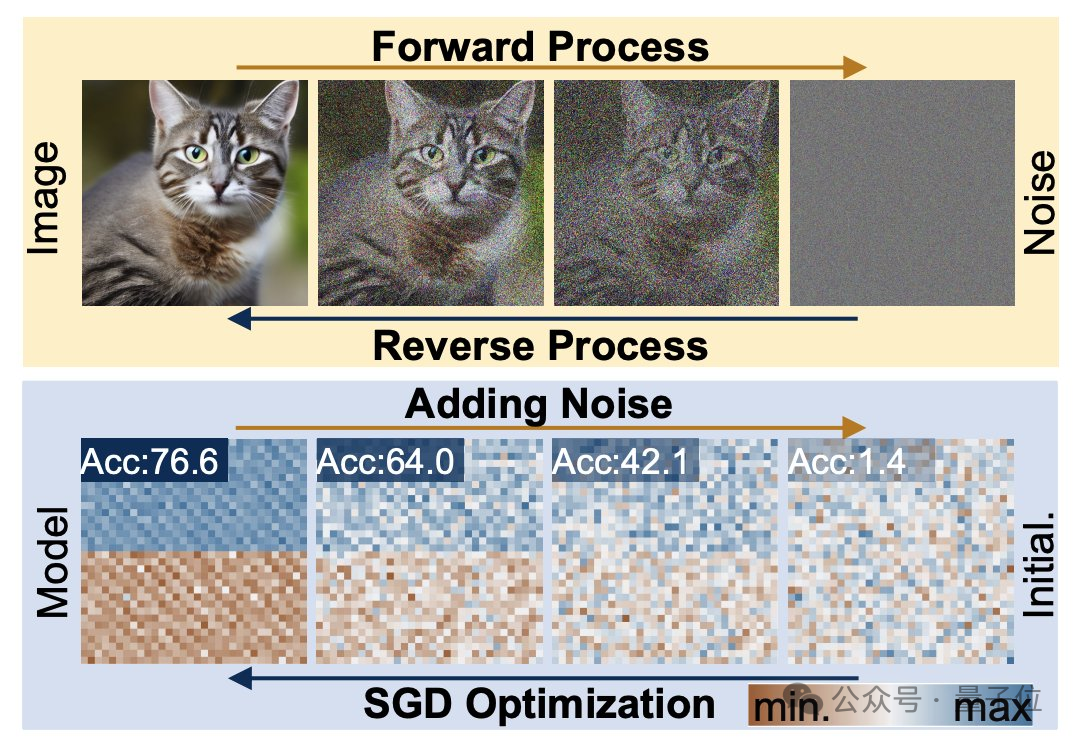 Aus struktureller Sicht wurde p-diff vom Forschungsteam auf der Grundlage des Standardmodells der latenten Diffusion entworfen und mit dem Autoencoder kombiniert.
Aus struktureller Sicht wurde p-diff vom Forschungsteam auf der Grundlage des Standardmodells der latenten Diffusion entworfen und mit dem Autoencoder kombiniert.
Der Forscher wählt zunächst einen Teil der Netzwerkparameter aus, die gut trainiert und ausgeführt wurden, und erweitert sie in eine eindimensionale Vektorform.
Dann verwenden Sie den Autoencoder, um die latente Darstellung aus dem eindimensionalen Vektor als Trainingsdaten für das Diffusionsmodell zu extrahieren. Dadurch können die Schlüsselmerkmale der ursprünglichen Parameter erfasst werden.
Während des Trainingsprozesses ließen die Forscher p-diff die Verteilung von Parametern durch Vorwärts- und Rückwärtsprozesse erlernen. Nach Abschluss synthetisiert das Diffusionsmodell diese potenziellen Darstellungen aus zufälligem Rauschen, ähnlich dem Prozess der Generierung visueller Informationen.
Schließlich wird die neu generierte latente Darstellung durch den dem Encoder entsprechenden Decoder auf Netzwerkparameter zurückgesetzt und zum Erstellen eines neuen Modells verwendet.
 Die folgende Abbildung zeigt die Parameterverteilung des von Grund auf trainierten ResNet-18-Modells unter Verwendung von 3 zufälligen Startwerten durch p-diff und zeigt das Verteilungsmuster zwischen verschiedenen Schichten und zwischen verschiedenen Parametern in derselben Schicht.
Die folgende Abbildung zeigt die Parameterverteilung des von Grund auf trainierten ResNet-18-Modells unter Verwendung von 3 zufälligen Startwerten durch p-diff und zeigt das Verteilungsmuster zwischen verschiedenen Schichten und zwischen verschiedenen Parametern in derselben Schicht.
 Um die Qualität der von p-diff generierten Parameter zu bewerten, testeten die Forscher es an 8 Datensätzen unter Verwendung von 3 Arten neuronaler Netze mit jeweils zwei Größen.
Um die Qualität der von p-diff generierten Parameter zu bewerten, testeten die Forscher es an 8 Datensätzen unter Verwendung von 3 Arten neuronaler Netze mit jeweils zwei Größen.
In der folgenden Tabelle stellen die drei Zahlen in jeder Gruppe die Bewertungsergebnisse des Originalmodells, des integrierten Modells und des mit p-diff generierten Modells dar.
Wie Sie den Ergebnissen entnehmen können, liegt die Leistung des mit p-diff generierten Modells grundsätzlich nahe bei oder sogar besser als die Leistung des manuell trainierten Originalmodells.
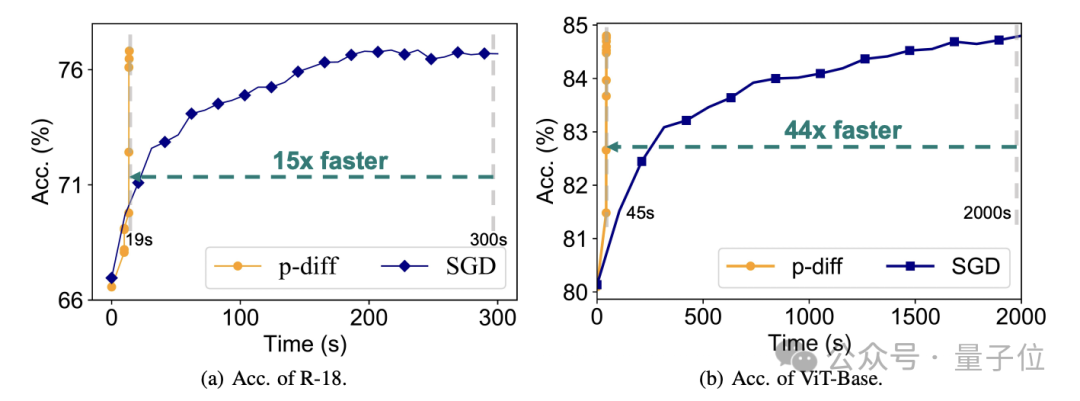
Was die Effizienz betrifft, ohne an Genauigkeit zu verlieren, generiert p-diff das ResNet-18-Netzwerk 15-mal schneller als herkömmliches Training und generiert Vit-Base 44-mal schneller.
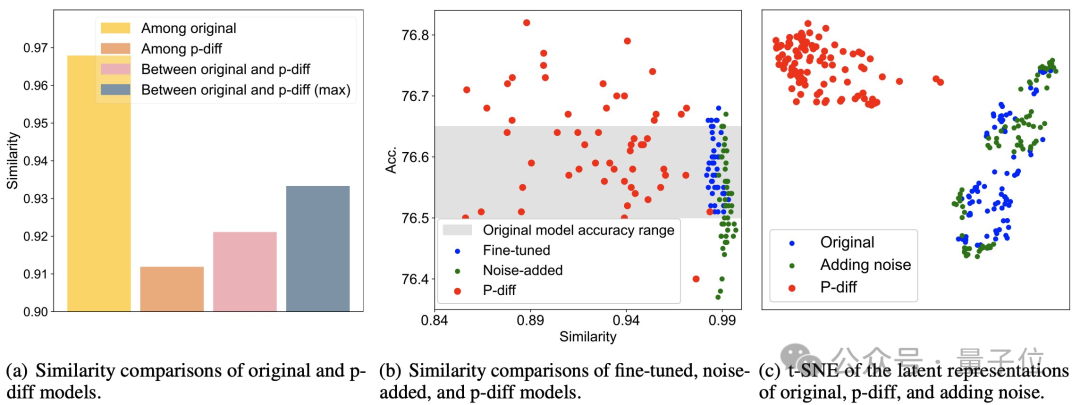
Zusätzliche Testergebnisse belegen, dass sich das von p-diff generierte Modell deutlich von den Trainingsdaten unterscheidet.
Wie Sie der Abbildung (a) unten entnehmen können, ist die Ähnlichkeit zwischen den von p-diff generierten Modellen geringer als die Ähnlichkeit zwischen den Originalmodellen sowie die Ähnlichkeit zwischen p-diff und dem Originalmodell.
Wie aus (b) und (c) ersichtlich ist, ist die Ähnlichkeit von p-diff im Vergleich zu Feinabstimmungs- und Rauschadditionsmethoden ebenfalls geringer.
Diese Ergebnisse zeigen, dass p-diff tatsächlich ein neues Modell generiert, anstatt nur Trainingsbeispiele zu speichern. Es zeigt auch, dass es über eine gute Generalisierungsfähigkeit verfügt und neue Modelle generieren kann, die sich von den Trainingsdaten unterscheiden.
Derzeit ist der Code von p-diff Open Source. Wenn Sie interessiert sind, können Sie ihn auf GitHub ausprobieren.
Papieradresse: https://arxiv.org/abs/2402.13144
GitHub: https://github.com/NUS-HPC-AI-Lab/Neural-Network-Diffusion
Das obige ist der detaillierte Inhalt vonBrechen Sie in die unterste Schicht der KI ein! Das Team von NUS Youyang verwendet ein Diffusionsmodell, um neuronale Netzwerkparameter zu konstruieren, LeCun gefällt es. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Detaillierte Erläuterung von Datenbanksäureattributen Säureattribute sind eine Reihe von Regeln, um die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen sicherzustellen. Sie definieren, wie Datenbanksysteme Transaktionen umgehen, und sorgen dafür, dass die Datenintegrität und -genauigkeit auch im Falle von Systemabstürzen, Leistungsunterbrechungen oder mehreren Benutzern gleichzeitiger Zugriff. Säureattributübersicht Atomizität: Eine Transaktion wird als unteilbare Einheit angesehen. Jeder Teil schlägt fehl, die gesamte Transaktion wird zurückgerollt und die Datenbank behält keine Änderungen bei. Wenn beispielsweise eine Banküberweisung von einem Konto abgezogen wird, jedoch nicht auf ein anderes erhöht wird, wird der gesamte Betrieb widerrufen. begintransaktion; updateAccountsSetBalance = Balance-100WH
 Master SQL Limit -Klausel: Steuern Sie die Anzahl der Zeilen in einer Abfrage
Apr 08, 2025 pm 07:00 PM
Master SQL Limit -Klausel: Steuern Sie die Anzahl der Zeilen in einer Abfrage
Apr 08, 2025 pm 07:00 PM
SQllimit -Klausel: Steuern Sie die Anzahl der Zeilen in Abfrageergebnissen. Die Grenzklausel in SQL wird verwendet, um die Anzahl der von der Abfrage zurückgegebenen Zeilen zu begrenzen. Dies ist sehr nützlich, wenn große Datensätze, paginierte Anzeigen und Testdaten verarbeitet werden und die Abfrageeffizienz effektiv verbessern können. Grundlegende Syntax der Syntax: SelectColumn1, Spalte2, ... Fromtable_Namelimitnumber_of_rows; number_of_rows: Geben Sie die Anzahl der zurückgegebenen Zeilen an. Syntax mit Offset: SelectColumn1, Spalte2, ... Fromtable_NamelimitOffset, Number_of_rows; Offset: Skip überspringen
 Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Es ist unmöglich, das MongoDB -Passwort direkt über Navicat anzuzeigen, da es als Hash -Werte gespeichert ist. So rufen Sie verlorene Passwörter ab: 1. Passwörter zurücksetzen; 2. Überprüfen Sie die Konfigurationsdateien (können Hash -Werte enthalten). 3. Überprüfen Sie Codes (May Hardcode -Passwörter).
 Beherrschen Sie die Reihenfolge nach Klausel in SQL: Daten effektiv sortieren
Apr 08, 2025 pm 07:03 PM
Beherrschen Sie die Reihenfolge nach Klausel in SQL: Daten effektiv sortieren
Apr 08, 2025 pm 07:03 PM
Detaillierte Erläuterung der SQLORDSBY -Klausel: Die effiziente Sortierung der Datenreihenfolge -Klausel ist eine Schlüsselanweisung in SQL, die zur Sortierung von Abfrageergebnissen verwendet wird. Es kann in einzelnen Spalten oder mehreren Spalten in den Aufstieg (ASC) oder absteigender Reihenfolge (Desc) angeordnet werden, wodurch die Datenlesbarkeit und die Effizienz der Datenverwaltung erheblich verbessert werden. OrderBy syntax SelectColumn1, Spalte2, ... fromTable_NameOrDByColumn_Name [ASC | Desc]; Column_Name: Sortieren nach Spalte. ASC: Ascending Order Sort (Standard). Desc: Sortieren Sie in absteigender Reihenfolge. OrderBy Hauptmerkmale: Multi-Sortier-Sortierung: Unterstützt mehrere Spaltensortierungen, und die Reihenfolge der Spalten bestimmt die Priorität der Sortierung. seit
 Navicat stellt eine Verbindung zu Datenbankfehlercode und Lösung her
Apr 08, 2025 pm 11:06 PM
Navicat stellt eine Verbindung zu Datenbankfehlercode und Lösung her
Apr 08, 2025 pm 11:06 PM
Häufige Fehler und Lösungen beim Anschließen mit Datenbanken: Benutzername oder Kennwort (Fehler 1045) Firewall -Blocks -Verbindungsverbindung (Fehler 2003) Timeout (Fehler 10060) Die Verwendung von Socket -Verbindung kann nicht verwendet werden (Fehler 1042).
 So schreiben Sie das neueste Tutorial zur SQL Insertion -Erklärung
Apr 09, 2025 pm 01:48 PM
So schreiben Sie das neueste Tutorial zur SQL Insertion -Erklärung
Apr 09, 2025 pm 01:48 PM
Mit der SQL -Insert -Anweisung wird eine Datenbanktabelle neue Zeilen hinzufügen, und ihre Syntax ist: Intable_Name (Spalte1, Spalte2, ..., Columnn) Werte (Value1, Value2, ..., Valuen);. Diese Anweisung unterstützt das Einfügen mehrerer Werte und ermöglicht es, Nullwerte in Spalten eingefügt zu werden. Es ist jedoch erforderlich, sicherzustellen, dass die eingefügten Werte mit dem Datentyp der Spalte kompatibel sind, um zu vermeiden, dass Einzigartigkeitsbeschränkungen verstoßen.
 So fügen Sie eine neue Spalte in SQL hinzu
Apr 09, 2025 pm 02:09 PM
So fügen Sie eine neue Spalte in SQL hinzu
Apr 09, 2025 pm 02:09 PM
Fügen Sie einer vorhandenen Tabelle in SQL neue Spalten hinzu, indem Sie die Anweisung für die Änderung Tabelle verwenden. Zu den spezifischen Schritten gehören: Ermittlung des Tabellennamens und Spalteninformationen, Schreiben von Alter Tabellenanweisungen und Ausführungsanweisungen. Fügen Sie beispielsweise eine E -Mail -Spalte in die Tabelle der Kunden hinzu (VARCHAR (50)): Änderung der Tabelle Kunden addieren Sie E -Mail -Varchar (50).
 Navicat -Verbindungs -Zeitüberschreitung: So lösen Sie sich
Apr 08, 2025 pm 11:03 PM
Navicat -Verbindungs -Zeitüberschreitung: So lösen Sie sich
Apr 08, 2025 pm 11:03 PM
Gründe für die Navicat -Verbindungszeitüberschreitung: Netzwerkinstabilität, geschäftige Datenbank, Firewall -Blockierung, Serverkonfigurationsprobleme und unsachgemäße Navicat -Einstellungen. Lösungsschritte: Überprüfen Sie die Netzwerkverbindung, den Datenbankstatus, die Firewall -Einstellungen, die Serverkonfiguration, prüfen Sie die Navicat -Einstellungen, starten Sie die Software und den Server neu und wenden Sie sich an den Administrator, um Hilfe zu erhalten.
