
 Technologie-Peripheriegeräte
KI
YOLO ist unsterblich! YOLOv9 wird veröffentlicht: Leistung und Geschwindigkeit SOTA~
Technologie-Peripheriegeräte
KI
YOLO ist unsterblich! YOLOv9 wird veröffentlicht: Leistung und Geschwindigkeit SOTA~
YOLO ist unsterblich! YOLOv9 wird veröffentlicht: Leistung und Geschwindigkeit SOTA~

Heutige Deep-Learning-Methoden konzentrieren sich auf den Entwurf der am besten geeigneten Zielfunktion, damit die Vorhersageergebnisse des Modells der tatsächlichen Situation am nächsten kommen. Gleichzeitig muss eine geeignete Architektur entworfen werden, um ausreichend Informationen für die Vorhersage zu erhalten. Bestehende Methoden ignorieren die Tatsache, dass bei der schichtweisen Merkmalsextraktion und räumlichen Transformation der Eingabedaten eine große Menge an Informationen verloren geht. Dieser Artikel befasst sich mit wichtigen Themen bei der Datenübertragung über tiefe Netzwerke, nämlich Informationsengpässen und umkehrbaren Funktionen. Darauf aufbauend wird das Konzept der programmierbaren Gradienteninformation (PGI) vorgeschlagen, um die verschiedenen Änderungen zu bewältigen, die tiefe Netzwerke zur Erreichung mehrerer Ziele erfordern. PGI kann vollständige Eingabeinformationen für die Zielaufgabe zur Berechnung der Zielfunktion bereitstellen und so zuverlässige Gradienteninformationen zur Aktualisierung der Netzwerkgewichte erhalten. Darüber hinaus wird eine neue, leichtgewichtige Netzwerkarchitektur entwickelt – ein Generalized Efficient Layer Aggregation Network (GELAN), das auf der Gradientenpfadplanung basiert.
Die Verifizierungsergebnisse zeigen, dass die GELAN-Architektur durch PGI bei leichten Modellen erhebliche Vorteile erzielt. Experimente mit dem MS COCO-Datensatz zeigen, dass GELAN in Kombination mit PGI eine bessere Parameterausnutzung erreichen kann als die hochmodernen Methoden, die auf tiefer Faltung basieren und nur herkömmliche Faltungsoperatoren verwenden. Aufgrund seiner Vielseitigkeit eignet sich PGI für eine Vielzahl von Modellen, von leichten bis hin zu großen Modellen. Mit PGI ist das Modell vollständig informiert, sodass mit einem von Grund auf trainierten Modell bessere Ergebnisse erzielt werden können als mit einem hochmodernen Modell, das anhand eines großen Datensatzes vorab trainiert wurde.
Artikeladresse: https://arxiv.org/pdf/2402.13616
Code-Link: https://github.com/WongKinYiu/yolov9
Hervorragende Leistung
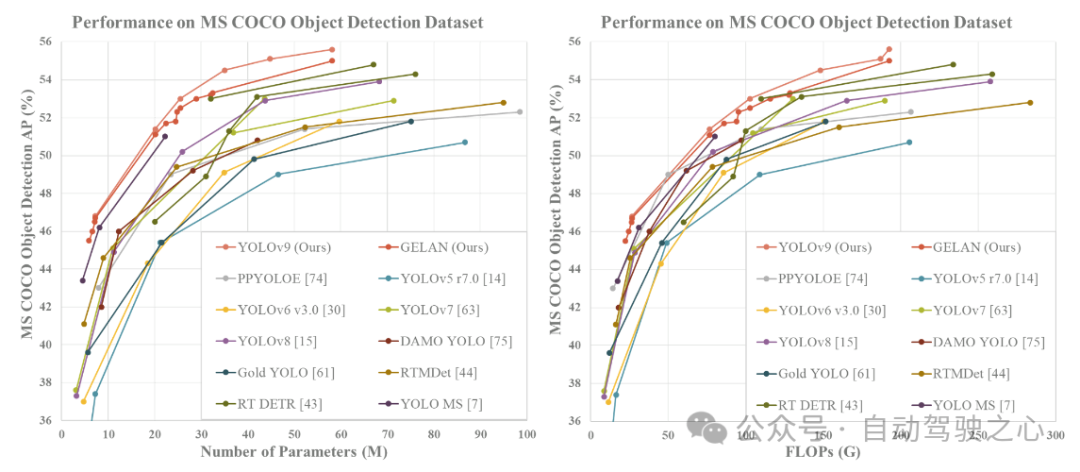
Laut Echtzeitziel im MS COCO-Datensatz Die Ergebnisse des Detektorvergleichs zeigen, dass die auf GELAN und PGI basierenden Zielerkennungsmethoden hinsichtlich der Zielerkennungsleistung den vorherigen, von Grund auf neu trainierten Methoden deutlich voraus sind. Die neue Methode übertrifft RT DETR, das auf einem Vortraining großer Datensätze basiert, hinsichtlich der Genauigkeit und übertrifft auch YOLO MS, das auf einem tiefen Faltungsdesign basiert, hinsichtlich der Parameternutzung. Diese Ergebnisse deuten darauf hin, dass GELAN- und PGI-Methoden potenzielle Vorteile im Bereich der Zielerkennung bieten und zu wichtigen Technologieoptionen für zukünftige Forschungen und Anwendungen werden könnten.
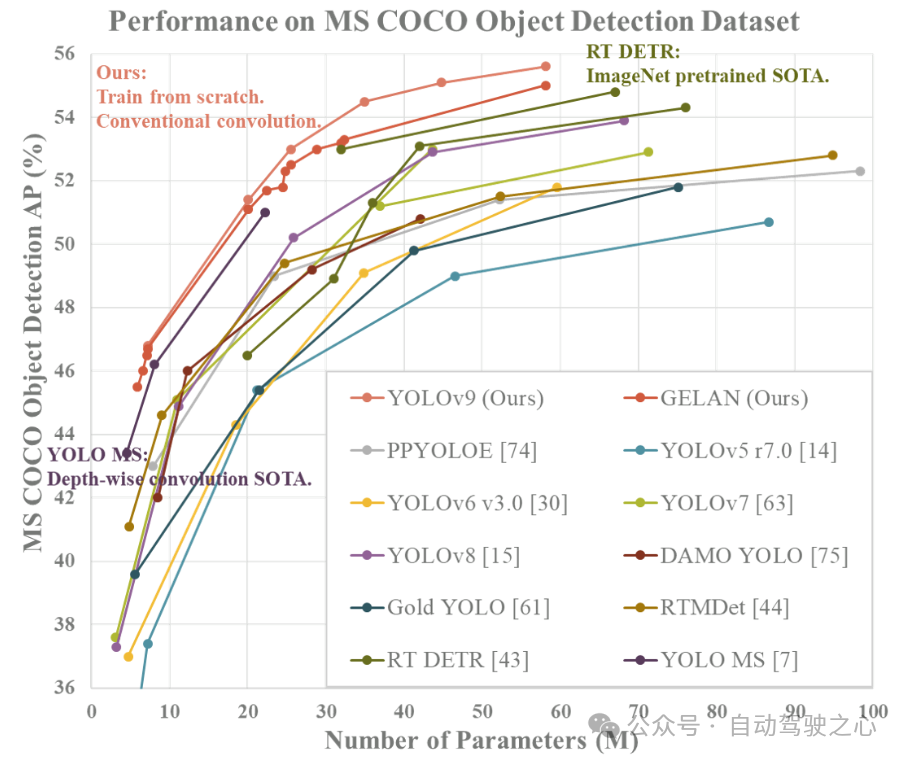
Der Beitrag dieses Artikels
- analysiert theoretisch die bestehende tiefe neuronale Netzwerkarchitektur aus der Perspektive reversibler Funktionen und erklärt erfolgreich viele Phänomene, die in der Vergangenheit schwer zu erklären waren. Auf Grundlage dieser Analyse wurden auch PGI- und reversible Hilfszweige entworfen, die hervorragende Ergebnisse erzielten.
- Das entwickelte PGI löst das Problem, dass Deep Supervision nur für extrem tiefe neuronale Netzwerkarchitekturen verwendet werden kann, wodurch die neue leichte Architektur wirklich für die tägliche Arbeit anwendbar wird.
- Das entworfene GELAN verwendet nur traditionelle Faltungen, um eine höhere Parameternutzung zu erreichen als Designs mit tiefer Faltung, die auf modernster Technologie basieren, und weist gleichzeitig große Vorteile auf, da es leichtgewichtig, schnell und genau ist.
- Durch die Kombination des vorgeschlagenen PGI und GELAN übertrifft die Objekterkennungsleistung von YOLOv9 im MS COCO-Datensatz in jeder Hinsicht die Leistung vorhandener Echtzeit-Objektdetektoren bei weitem.
Methode
PGI und zugehörige Netzwerkarchitektur und -methoden
Wie in der folgenden Abbildung gezeigt, (a) Path Aggregation Network (PAN), (b) Reversible Column (RevCol), (c) Traditional Depth Überwachung und (d) Programmable Gradient Information (PGI), vorgeschlagen von YOLOv9.
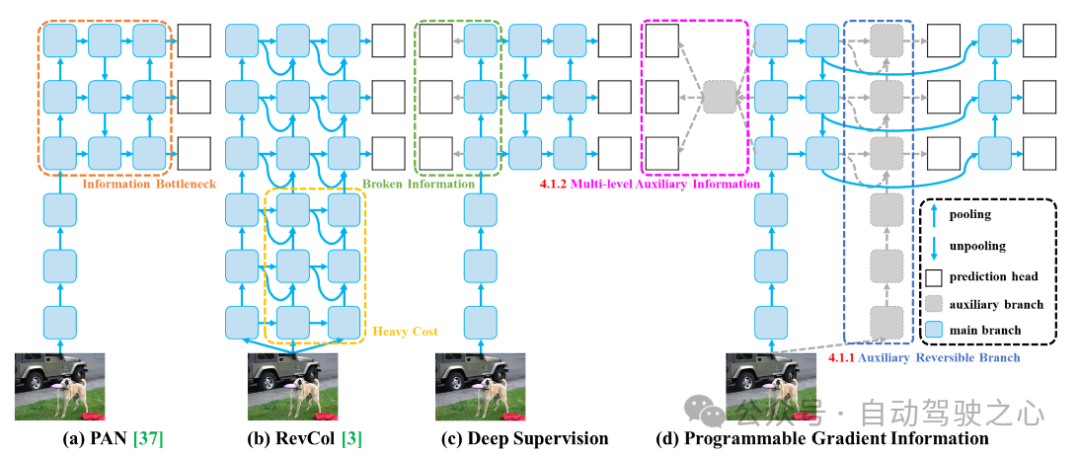
PGI besteht hauptsächlich aus drei Komponenten:
- Hauptzweig: die für die Inferenz verwendete Architektur;
- Hilfszweig: Erzeugen zuverlässiger Gradienten für die Rückwärtsübertragung vom Hauptzweig;
- Mehrstufige Hilfsinformationen: Steuern Sie den Hauptzweig, um programmierbare mehrstufige semantische Informationen zu lernen.
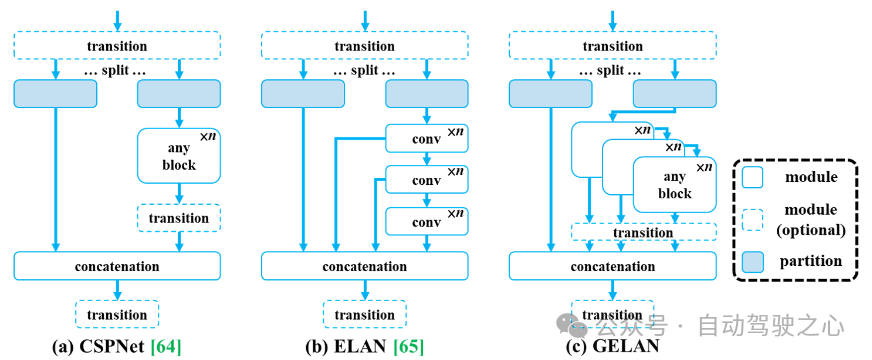
Die Architektur von GELAN
ist in der folgenden Abbildung dargestellt: (a) CSPNet, (b) ELAN und (c) GELAN, vorgeschlagen von YOLOv9. Es imitiert CSPNet und erweitert ELAN auf GELAN, das jeden Rechenblock unterstützen kann.
Ergebnisvergleich
Vergleich mit bestehenden Techniken
Die folgende Tabelle listet den Vergleich von YOLOv9 mit anderen von Grund auf trainierten Echtzeit-Objektdetektoren auf. Insgesamt sind YOLO MS-S für leichte Modelle, YOLO MS für mittlere Modelle, YOLOv7 AF für allgemeine Modelle und YOLOv8-X für große Modelle die leistungsstärksten Methoden unter den vorhandenen Methoden. Im Vergleich zu YOLO MS leichter und mittlerer Modelle verfügt YOLOv9 über etwa 10 % weniger Parameter und 5–15 % weniger Berechnungen, weist jedoch immer noch eine Verbesserung des AP um 0,4–0,6 % auf. Im Vergleich zu YOLOv7 AF hat YOLOv9-C 42 % weniger Parameter und 21 % weniger Berechnungen, erreicht aber den gleichen AP (53 %). Im Vergleich zu YOLOv8-X verfügt YOLOv9-X über 15 % weniger Parameter, 25 % weniger Berechnungen und eine deutliche Verbesserung des AP, der um 1,7 % zugenommen hat. Die obigen Vergleichsergebnisse zeigen, dass YOLOv9 in allen Aspekten gegenüber bestehenden Methoden deutlich verbessert ist.
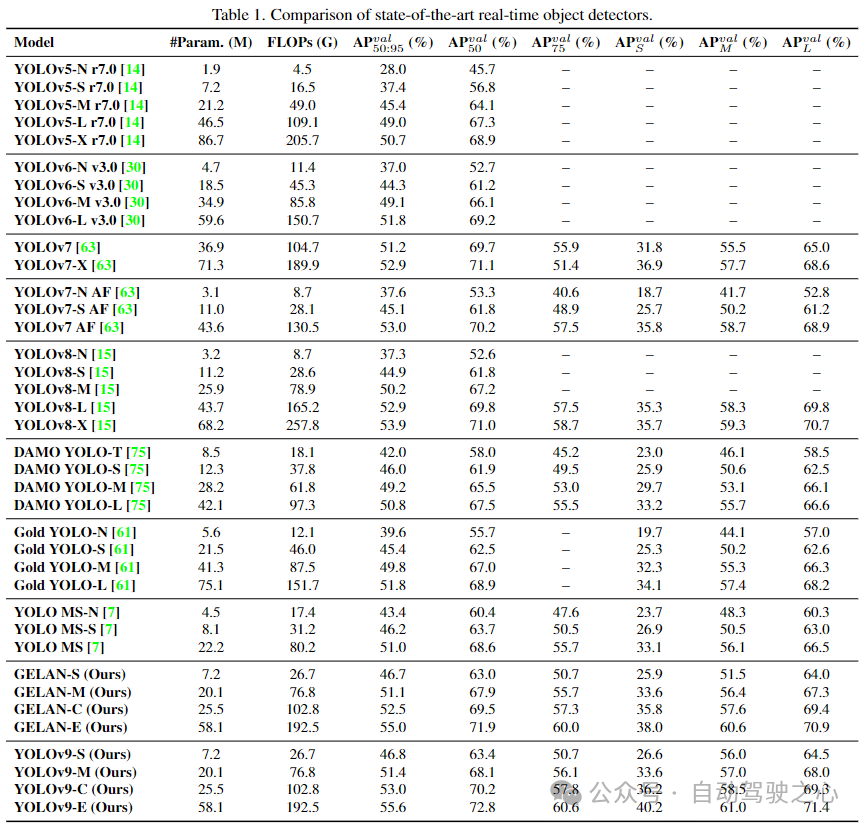
Vergleich mit hochmodernen Echtzeit-Objektdetektoren
Die am Vergleich teilnehmenden Methoden verwenden alle ImageNet als Gewichte vor dem Training, einschließlich RT DETR, RTMDet und PP-YOLOE. YOLOv9, das die Scratch-Trainingsmethode verwendet, übertrifft die Leistung anderer Methoden deutlich.
Visualisierte Ergebnisse
Feature-Map (visualisierte Ergebnisse): Ausgabe durch zufällige Anfangsgewichte von PlainNet, ResNet, CSPNet und GELAN in verschiedenen Tiefen. Nach 100 Schichten beginnt ResNet mit der Erzeugung einer Feed-Forward-Ausgabe, die ausreicht, um die Zielinformationen zu verwirren. Das hier vorgeschlagene GELAN kann auf der 150. Schicht immer noch recht vollständige Informationen behalten und verfügt auf der 200. Schicht immer noch über ausreichende Unterscheidungsfähigkeit.

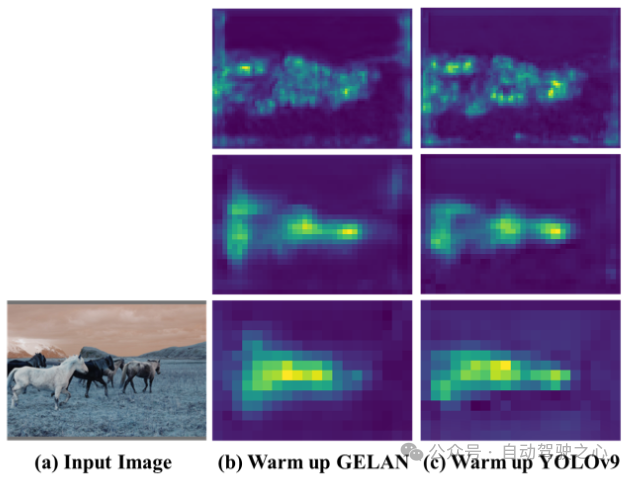
PAN-Feature-Maps (Visualisierungsergebnisse) von GELAN und YOLOv9 (GELAN + PGI): Nach einer Bias-Aufwärmrunde. GELAN wies zunächst einige Abweichungen auf, konnte sich aber nach dem Hinzufügen des reversiblen PGI-Zweigs besser auf das Zielobjekt konzentrieren.
Visualisierungsergebnisse zufälliger Ausgangsgewichtungs-Feature-Maps für verschiedene Netzwerkarchitekturen: (a) Eingabebild, (b) PlainNet, (c) ResNet, (d) CSPNet und (e) vorgeschlagenes GELAN. Aus der Abbildung ist ersichtlich, dass in verschiedenen Architekturen der Grad der zur Berechnung des Verlusts der Zielfunktion bereitgestellten Informationen unterschiedlich ist und unsere Architektur die vollständigsten Informationen speichern und die zuverlässigsten Gradienteninformationen für die Berechnung der Zielfunktion bereitstellen kann.

Fazit
In diesem Artikel wird vorgeschlagen, PGI zu verwenden, um das Problem von Informationsengpässen und das Problem zu lösen, dass tiefe Überwachungsmechanismen für leichte neuronale Netze nicht geeignet sind. hat GELAN entwickelt, ein effizientes und leichtes neuronales Netzwerk. In Bezug auf die Zielerkennung zeigt GELAN unter verschiedenen Rechenmodulen und Tiefeneinstellungen eine starke und stabile Leistung. Es ist in der Tat weitgehend auf Modelle skalierbar, die für eine Vielzahl von Inferenzgeräten geeignet sind. Als Reaktion auf die beiden oben genannten Probleme ermöglicht die Einführung von PGI sowohl bei leichten Modellen als auch bei tiefen Modellen erhebliche Verbesserungen der Genauigkeit. YOLOv9, das durch die Kombination von PGI und GELAN entwickelt wurde, zeigt eine starke Wettbewerbsfähigkeit. Sein hervorragendes Design ermöglicht es dem tiefen Modell, die Anzahl der Parameter um 49 % und den Berechnungsaufwand um 43 % im Vergleich zu YOLOv8 zu reduzieren, erreicht aber dennoch eine AP-Verbesserung von 0,6 % gegenüber dem MS COCO-Datensatz.
Originallink: https://mp.weixin.qq.com/s/nP4JzVwn1S-MeKAzbf97uw
Das obige ist der detaillierte Inhalt vonYOLO ist unsterblich! YOLOv9 wird veröffentlicht: Leistung und Geschwindigkeit SOTA~. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 YOLO ist unsterblich! YOLOv9 wird veröffentlicht: Leistung und Geschwindigkeit SOTA~
Feb 26, 2024 am 11:31 AM
YOLO ist unsterblich! YOLOv9 wird veröffentlicht: Leistung und Geschwindigkeit SOTA~
Feb 26, 2024 am 11:31 AM
Heutige Deep-Learning-Methoden konzentrieren sich darauf, die am besten geeignete Zielfunktion zu entwerfen, damit die Vorhersageergebnisse des Modells der tatsächlichen Situation am nächsten kommen. Gleichzeitig muss eine geeignete Architektur entworfen werden, um ausreichend Informationen für die Vorhersage zu erhalten. Bestehende Methoden ignorieren die Tatsache, dass bei der schichtweisen Merkmalsextraktion und räumlichen Transformation der Eingabedaten eine große Menge an Informationen verloren geht. Dieser Artikel befasst sich mit wichtigen Themen bei der Datenübertragung über tiefe Netzwerke, nämlich Informationsengpässen und umkehrbaren Funktionen. Darauf aufbauend wird das Konzept der programmierbaren Gradienteninformation (PGI) vorgeschlagen, um die verschiedenen Änderungen zu bewältigen, die tiefe Netzwerke zur Erreichung mehrerer Ziele erfordern. PGI kann vollständige Eingabeinformationen für die Zielaufgabe zur Berechnung der Zielfunktion bereitstellen und so zuverlässige Gradienteninformationen zur Aktualisierung der Netzwerkgewichte erhalten. Darüber hinaus wird ein neues, leichtgewichtiges Netzwerk-Framework entworfen
 Die Grundlage, Grenze und Anwendung von GNN
Apr 11, 2023 pm 11:40 PM
Die Grundlage, Grenze und Anwendung von GNN
Apr 11, 2023 pm 11:40 PM
Graphische neuronale Netze (GNN) haben in den letzten Jahren rasante und unglaubliche Fortschritte gemacht. Das graphische neuronale Netzwerk, auch bekannt als Graph Deep Learning, Graph Representation Learning (Graph Representation Learning) oder geometrisches Deep Learning, ist das am schnellsten wachsende Forschungsthema im Bereich des maschinellen Lernens, insbesondere des Deep Learning. Der Titel dieser Veröffentlichung lautet „Basics, Frontiers and Applications of GNN“ und stellt hauptsächlich den allgemeinen Inhalt des umfassenden Buches „Basics, Frontiers and Applications of Graph Neural Networks“ vor, das von den Wissenschaftlern Wu Lingfei, Cui Peng, Pei Jian und Zhao zusammengestellt wurde Liang. 1. Einführung in graphische neuronale Netze 1. Warum Graphen studieren? Graphen sind eine universelle Sprache zur Beschreibung und Modellierung komplexer Systeme. Der Graph selbst ist nicht kompliziert, er besteht hauptsächlich aus Kanten und Knoten. Wir können Knoten verwenden, um jedes Objekt darzustellen, das wir modellieren möchten, und Kanten, um zwei darzustellen
 Ein Überblick über die drei gängigen Chiparchitekturen für autonomes Fahren in einem Artikel
Apr 12, 2023 pm 12:07 PM
Ein Überblick über die drei gängigen Chiparchitekturen für autonomes Fahren in einem Artikel
Apr 12, 2023 pm 12:07 PM
Die aktuellen Mainstream-KI-Chips sind hauptsächlich in drei Kategorien unterteilt: GPU, FPGA und ASIC. Sowohl GPU als auch FPGA sind im Frühstadium relativ ausgereifte Chiparchitekturen und Allzweckchips. ASIC ist ein Chip, der für bestimmte KI-Szenarien angepasst ist. Die Industrie hat bestätigt, dass CPUs nicht für KI-Computing geeignet sind, sie aber auch für KI-Anwendungen unerlässlich sind. Vergleich der GPU-Lösungsarchitektur zwischen GPU und CPU Die CPU folgt der von Neumann-Architektur, deren Kern die Speicherung von Programmen/Daten und die serielle sequentielle Ausführung ist. Daher benötigt die CPU-Architektur viel Platz zum Platzieren der Speichereinheit (Cache) und der Steuereinheit (Steuerung). Im Gegensatz dazu nimmt die Recheneinheit (ALU) nur einen kleinen Teil ein, sodass die CPU eine große Leistung erbringt Paralleles Rechnen.
 „Der Eigentümer von Bilibili UP hat erfolgreich das weltweit erste Redstone-basierte neuronale Netzwerk geschaffen, das in den sozialen Medien für Aufsehen sorgte und von Yann LeCun gelobt wurde.'
May 07, 2023 pm 10:58 PM
„Der Eigentümer von Bilibili UP hat erfolgreich das weltweit erste Redstone-basierte neuronale Netzwerk geschaffen, das in den sozialen Medien für Aufsehen sorgte und von Yann LeCun gelobt wurde.'
May 07, 2023 pm 10:58 PM
In Minecraft ist Redstone ein sehr wichtiger Gegenstand. Es ist ein einzigartiges Material im Spiel. Schalter, Redstone-Fackeln und Redstone-Blöcke können Drähten oder Objekten stromähnliche Energie verleihen. Mithilfe von Redstone-Schaltkreisen können Sie Strukturen aufbauen, mit denen Sie andere Maschinen steuern oder aktivieren können. Sie können selbst so gestaltet sein, dass sie auf die manuelle Aktivierung durch Spieler reagieren, oder sie können wiederholt Signale ausgeben oder auf Änderungen reagieren, die von Nicht-Spielern verursacht werden, beispielsweise auf Bewegungen von Kreaturen und Gegenstände. Fallen, Pflanzenwachstum, Tag und Nacht und mehr. Daher kann Redstone in meiner Welt extrem viele Arten von Maschinen steuern, von einfachen Maschinen wie automatischen Türen, Lichtschaltern und Blitzstromversorgungen bis hin zu riesigen Aufzügen, automatischen Farmen, kleinen Spielplattformen und sogar in Spielcomputern gebauten Maschinen . Kürzlich, B-Station UP main @
 Eine Drohne, die starken Winden standhält? Caltech nutzt 12 Minuten Flugdaten, um Drohnen das Fliegen im Wind beizubringen
Apr 09, 2023 pm 11:51 PM
Eine Drohne, die starken Winden standhält? Caltech nutzt 12 Minuten Flugdaten, um Drohnen das Fliegen im Wind beizubringen
Apr 09, 2023 pm 11:51 PM
Wenn der Wind stark genug ist, um den Schirm zu blasen, ist die Drohne stabil, genau wie folgt: Das Fliegen im Wind ist ein Teil des Fliegens in der Luft. Wenn der Pilot das Flugzeug aus großer Höhe landet, kann die Windgeschwindigkeit variieren Auf einer kleineren Ebene können böige Winde auch den Drohnenflug beeinträchtigen. Derzeit werden Drohnen entweder unter kontrollierten Bedingungen, ohne Wind, geflogen oder von Menschen per Fernbedienung gesteuert. Drohnen werden von Forschern gesteuert, um in Formationen am freien Himmel zu fliegen. Diese Flüge werden jedoch normalerweise unter idealen Bedingungen und Umgebungen durchgeführt. Damit Drohnen jedoch autonom notwendige, aber routinemäßige Aufgaben wie die Zustellung von Paketen ausführen können, müssen sie sich in Echtzeit an die Windverhältnisse anpassen können. Um Drohnen beim Fliegen im Wind wendiger zu machen, hat ein Team von Ingenieuren des Caltech
 AI hat Sie klar gesehen, YOLO+ByteTrack+Multi-Label-Klassifizierungsnetzwerk
Apr 14, 2023 pm 06:25 PM
AI hat Sie klar gesehen, YOLO+ByteTrack+Multi-Label-Klassifizierungsnetzwerk
Apr 14, 2023 pm 06:25 PM
Heute möchte ich Ihnen ein System zur Analyse von Fußgängerattributen vorstellen. Fußgänger können anhand von Video- oder Kamera-Videostreams identifiziert und die Attribute jeder Person markiert werden. Die identifizierten Attribute umfassen die folgenden 10 Kategorien. Wenn die Körperausrichtung vorne, seitlich und hinten ist, gibt es im endgültigen Training 26 Attribute. Die Implementierung eines solchen Systems erfordert drei Schritte: Verwenden Sie YOLOv5, um Fußgänger zu identifizieren. Verwenden Sie ByteTrack, um dieselbe Person zu verfolgen und zu markieren. Trainieren Sie ein Bildklassifizierungsnetzwerk mit mehreren Etiketten, um 26 Attribute von Fußgängern zu identifizieren. 1. Fußgängererkennung und -verfolgung. Die Fußgängererkennung verwendet das YOLOv5-Zielerkennungsmodell Sie können das Modell selbst trainieren oder direkt das vorab trainierte YOLOv5-Modell verwenden. Die Fußgängerverfolgung nutzt die Multi-Object-Tracking-Technologie (MOT).
 Multipfad, Multidomäne, alles inklusive! Google AI veröffentlicht das allgemeine Modell MDL für Multi-Domain-Lernen
May 28, 2023 pm 02:12 PM
Multipfad, Multidomäne, alles inklusive! Google AI veröffentlicht das allgemeine Modell MDL für Multi-Domain-Lernen
May 28, 2023 pm 02:12 PM
Deep-Learning-Modelle für Sehaufgaben (z. B. Bildklassifizierung) werden normalerweise durchgängig mit Daten aus einem einzelnen visuellen Bereich (z. B. natürlichen Bildern oder computergenerierten Bildern) trainiert. Im Allgemeinen muss eine Anwendung, die Vision-Aufgaben für mehrere Domänen ausführt, mehrere Modelle für jede einzelne Domäne erstellen und diese unabhängig voneinander trainieren. Während der Inferenz verarbeitet jedes Modell eine bestimmte Domäne. Auch wenn sie auf unterschiedliche Bereiche ausgerichtet sind, sind einige Merkmale der frühen Schichten zwischen diesen Modellen ähnlich, sodass das gemeinsame Training dieser Modelle effizienter ist. Dies reduziert die Latenz und den Stromverbrauch und reduziert die Speicherkosten für die Speicherung jedes Modellparameters. Dieser Ansatz wird als Multi-Domain-Learning (MDL) bezeichnet. Darüber hinaus können MDL-Modelle auch Single-Modelle übertreffen
 1,3 ms dauert 1,3 ms! Tsinghuas neueste Open-Source-Architektur für mobile neuronale Netzwerke RepViT
Mar 11, 2024 pm 12:07 PM
1,3 ms dauert 1,3 ms! Tsinghuas neueste Open-Source-Architektur für mobile neuronale Netzwerke RepViT
Mar 11, 2024 pm 12:07 PM
Papieradresse: https://arxiv.org/abs/2307.09283 Codeadresse: https://github.com/THU-MIG/RepViTRepViT funktioniert gut in der mobilen ViT-Architektur und zeigt erhebliche Vorteile. Als nächstes untersuchen wir die Beiträge dieser Studie. In dem Artikel wird erwähnt, dass Lightweight-ViTs bei visuellen Aufgaben im Allgemeinen eine bessere Leistung erbringen als Lightweight-CNNs, hauptsächlich aufgrund ihres Multi-Head-Selbstaufmerksamkeitsmoduls (MSHA), das es dem Modell ermöglicht, globale Darstellungen zu lernen. Allerdings wurden die architektonischen Unterschiede zwischen Lightweight-ViTs und Lightweight-CNNs noch nicht vollständig untersucht. In dieser Studie integrierten die Autoren leichte ViTs in die effektiven
