
 Technologie-Peripheriegeräte
KI
Das 10-M-Kontextfenster von Google tötet RAG? Werden Zwillinge unterschätzt, nachdem sie von Sora aus dem Rampenlicht gestohlen wurden?
Technologie-Peripheriegeräte
KI
Das 10-M-Kontextfenster von Google tötet RAG? Werden Zwillinge unterschätzt, nachdem sie von Sora aus dem Rampenlicht gestohlen wurden?
Das 10-M-Kontextfenster von Google tötet RAG? Werden Zwillinge unterschätzt, nachdem sie von Sora aus dem Rampenlicht gestohlen wurden?

Um das deprimierendste Unternehmen der letzten Zeit zu sein, ist Google definitiv eines von ihnen: Sein eigenes Gemini 1.5 wurde gerade veröffentlicht und wurde von Sora von OpenAI gestohlen, was sein kann wird in der KI-Branche als „Wang Feng“ bezeichnet.
Konkret bringt Google die erste Version von Gemini 1.5 zum frühen Testen auf den Markt – Gemini 1.5 Pro. Es handelt sich um ein mittelgroßes multimodales Modell (über Text, Video, Audio) mit ähnlichen Leistungsniveaus wie Googles bisher größtes Modell, 1.0 Ultra, und führt bahnbrechende experimentelle Funktionen für das Verständnis langer Kontexte ein. Es kann bis zu 1 Million Token (entspricht 1 Stunde Video, 11 Stunden Audio, mehr als 30.000 Codezeilen oder 700.000 Wörter) stabil verarbeiten, mit einem Limit von 10 Millionen Token (entspricht „Herr der Ringe“) " Trilogie), Legen Sie einen Datensatz für das längste Kontextfenster fest.
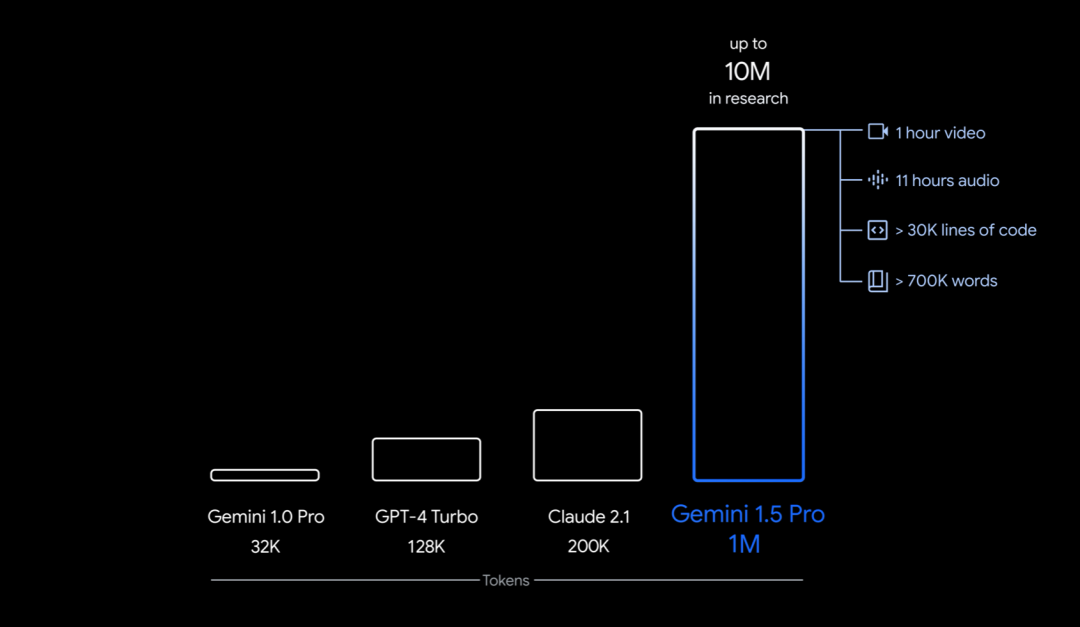
Darüber hinaus kann es auch die Übersetzung einer kleinen Sprache mit nur einem 500-seitigen Grammatikbuch, 2000 zweisprachigen Einträgen und 400 zusätzlichen Parallelsätzen lernen (im Internet gibt es keine relevanten Informationen). Niveau, das dem menschlichen Lernenden in der Übersetzung nahe kommt.
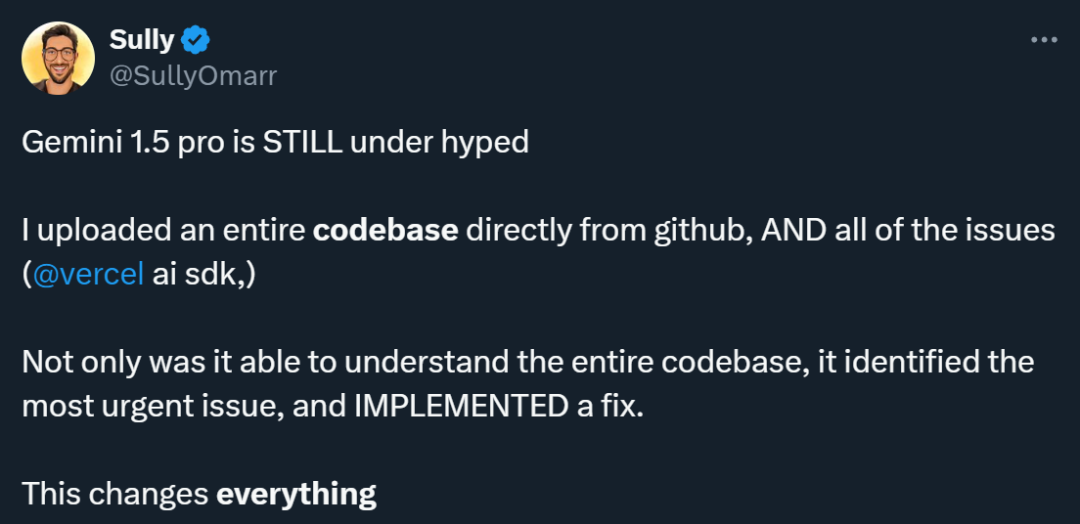
Viele Leute, die das Gemini 1.5 Pro verwendet haben, denken, dass dieses Modell unterschätzt wird. Jemand führte ein Experiment durch und gab die gesamte von Github heruntergeladene Codebasis und damit verbundene Probleme in Gemini 1.5 Pro ein. Die Ergebnisse waren überraschend: Es verstand nicht nur die gesamte Codebasis, sondern konnte auch die dringendsten Probleme identifizieren und beheben . .
In einem weiteren Code-bezogenen Test zeigte Gemini 1.5 Pro hervorragende Suchfunktionen und konnte schnell die relevantesten Beispiele in der Codebasis finden. Darüber hinaus zeigt es ein ausgeprägtes Verständnis und ist in der Lage, den Code, der Animationen steuert, genau zu finden und personalisierte Codevorschläge bereitzustellen. Ebenso zeigte Gemini 1.5 Pro hervorragende modusübergreifende Fähigkeiten, indem es Demoinhalte anhand von Screenshots lokalisieren konnte und Anleitungen für die Bearbeitung von Bildcode bereitstellte.

So ein Modell sollte alle Blicke auf sich ziehen. Darüber hinaus ist es erwähnenswert, dass die Fähigkeit von Gemini 1.5 Pro, extrem lange Kontexte zu verarbeiten, auch viele Forscher zu der Frage veranlasst hat, ob die traditionelle RAG-Methode noch notwendig ist.
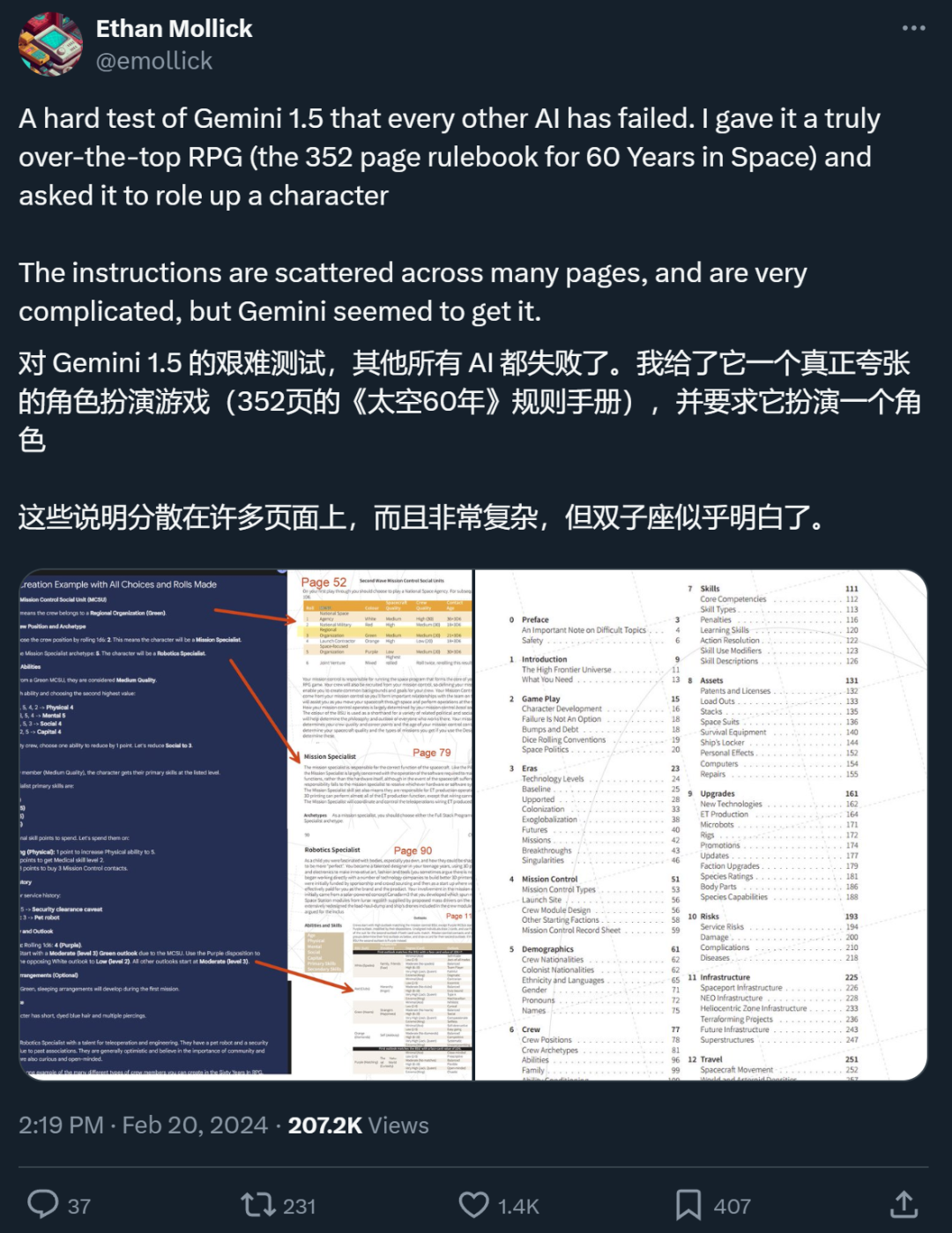
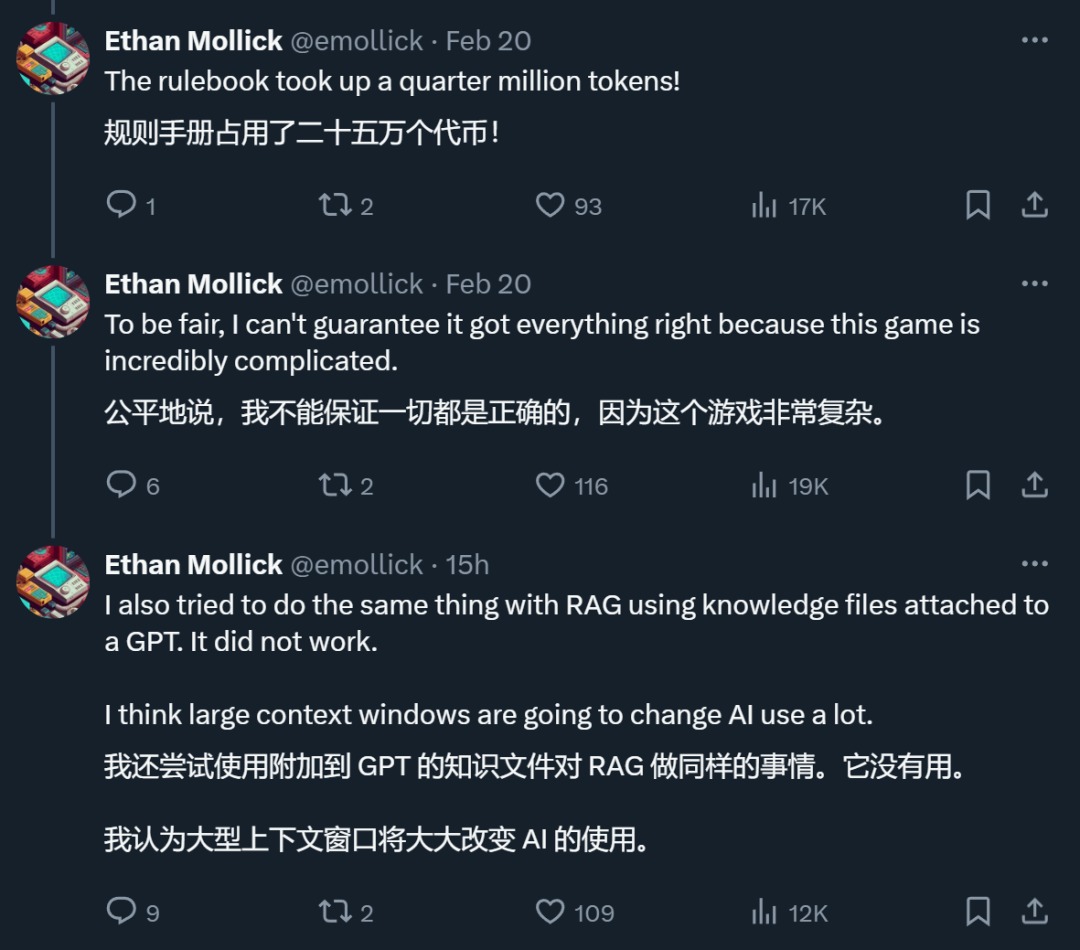
Ein X-Internetnutzer sagte, dass Gemini 1.5 Pro, das ultralange Kontexte unterstützt, in einem von ihm durchgeführten Test tatsächlich das getan habe, was RAG nicht konnte.
RAG wird durch das lange Kontextmodell getötet?
„Ein Modell mit einem 10-Millionen-Token-Kontextfenster macht die meisten vorhandenen RAG-Frameworks überflüssig, das heißt, 10-Millionen-Token-Kontext tötet RAG“, schrieb Fu Yao, ein Doktorand an der University of Edinburgh, in einem Beitrag über Gemini 1.5 Profi.

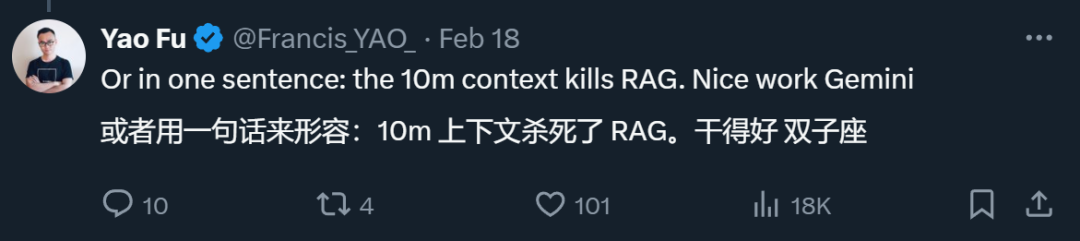
RAG ist die Abkürzung für „Retrieval-Augmented Generation“, was ins Chinesische als „Retrieval Enhanced Generation“ übersetzt werden kann. RAG besteht typischerweise aus zwei Phasen: dem Abrufen kontextrelevanter Informationen und der Verwendung des abgerufenen Wissens zur Steuerung des Generierungsprozesses. Als Mitarbeiter können Sie beispielsweise das große Vorbild direkt fragen: „Was sind die Strafen für Verspätung in unserem Unternehmen?“ Ohne das „Mitarbeiterhandbuch“ zu lesen, hat das große Vorbild keine Möglichkeit zu antworten. Mithilfe der RAG-Methode können wir jedoch zunächst ein Suchmodell nach den relevantesten Antworten im „Mitarbeiterhandbuch“ suchen lassen und dann Ihre Frage und die gefundenen relevanten Antworten an das Generierungsmodell senden, das das große Modell ermöglicht um eine Antwort zu generieren. Dadurch wird das Problem gelöst, dass das Kontextfenster vieler früherer großer Modelle nicht groß genug war (z. B. konnte es das „Mitarbeiterhandbuch“ nicht aufnehmen), RAGfangfa jedoch nicht in der Lage war, die subtilen Zusammenhänge zwischen Kontexten zu erfassen.
Fu Yao glaubt, dass, wenn ein Modell die Kontextinformationen von 10 Millionen Token direkt verarbeiten kann, keine zusätzlichen Abrufschritte erforderlich sind, um relevante Informationen zu finden und zu integrieren. Benutzer können alle benötigten Daten direkt als Kontext in das Modell einfügen und dann wie gewohnt mit dem Modell interagieren. „Das große Sprachmodell selbst ist bereits ein sehr leistungsfähiger Sucher. Warum sollte man sich also die Mühe machen, einen schwachen Sucher zu erstellen und viel technische Energie für Chunking, Einbettung, Indizierung usw. aufzuwenden?“, schrieb er weiter.

Fu Yaos Ansichten wurden jedoch von vielen Forschern widerlegt. Er sagte, dass viele der Einwände berechtigt seien, und er sortierte auch diese Meinungen systematisch aus:
1. Kostenproblem: Kritiker wiesen darauf hin, dass RAG günstiger sei als das Long-Context-Modell. Fu Yao räumte dies ein, verglich jedoch die Entwicklungsgeschichte verschiedener Technologien und wies darauf hin, dass kostengünstige Modelle (wie BERT-small oder n-gram) zwar tatsächlich billig seien, die Kosten für fortschrittliche Technologien jedoch in der Geschichte der KI-Entwicklung lägen wird irgendwann abnehmen. Ihm geht es darum, zuerst die Leistung intelligenter Modelle zu verfolgen und dann die Kosten durch technologischen Fortschritt zu senken, da es viel einfacher ist, intelligente Modelle billig zu machen, als billige Modelle intelligent zu machen.
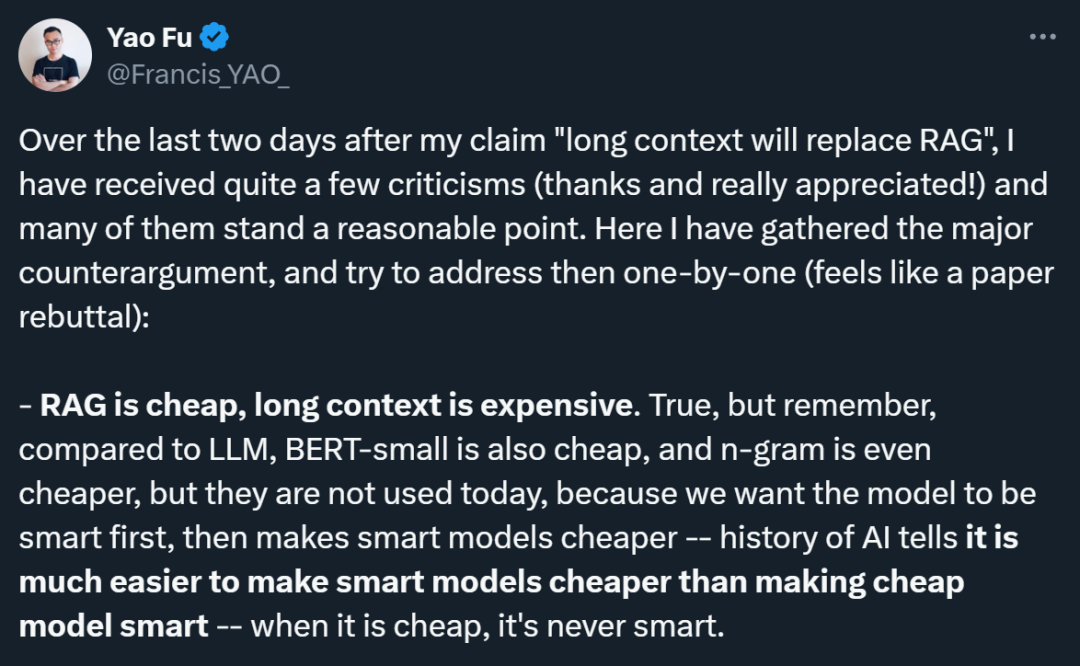
2. Integration von Abruf und Argumentation: Fu Yao betonte, dass das lange Kontextmodell in der Lage ist, Abruf und Argumentation während des gesamten Dekodierungsprozesses zu mischen, während RAG das Abrufen nur zu Beginn durchführt. Das lange Kontextmodell kann auf jeder Ebene und jedem Token abgerufen werden, was bedeutet, dass das Modell die abzurufenden Informationen basierend auf den Ergebnissen der vorläufigen Inferenz dynamisch bestimmen kann, wodurch eine engere Integration von Abruf und Inferenz erreicht wird.
3. Anzahl der unterstützten Token: Obwohl die Anzahl der von RAG unterstützten Token die Billionen-Grenze erreicht hat und das Long-Context-Modell derzeit die Millionen-Grenze unterstützt, glaubt Fu Yao, dass die meisten davon in natürlich verteilten Eingabedokumenten erforderlich sind Die Suchbedingungen liegen alle unterhalb der Millionengrenze. Als Beispiele nannte er die Analyse juristischer Dokumente und maschinelles Lernen und glaubte, dass das Eingabevolumen in diesen Fällen Millionen nicht überschreiten würde.

4. Caching-Mechanismus: In Bezug auf das Problem, dass das lange Kontextmodell die erneute Eingabe des gesamten Dokuments erfordert, wies Fu Yao darauf hin, dass es einen sogenannten KV-Caching-Mechanismus (Schlüsselwert) gibt, der entworfen werden kann Komplexe Cache- und Speicherhierarchien, um die Eingabe vorzunehmen. Es muss nur einmal gelesen werden und nachfolgende Abfragen können den KV-Cache wiederverwenden. Er erwähnte auch, dass KV-Caches zwar groß sein können, er jedoch optimistisch ist, dass in Zukunft effiziente KV-Cache-Komprimierungsalgorithmen entstehen werden.
5. Die Notwendigkeit, Suchmaschinen anzurufen: Er räumte ein, dass es kurzfristig immer noch notwendig sei, Suchmaschinen zum Abruf aufzurufen. Er schlug jedoch eine mutige Idee vor, die darin besteht, dem Sprachmodell direkten Zugriff auf den gesamten Google-Suchindex zu ermöglichen, um alle Informationen aufzunehmen, was die große Vorstellungskraft des zukünftigen Potenzials der KI-Technologie widerspiegelt.
6. Leistungsprobleme: Fu Yao gab zu, dass das aktuelle Gemini 1.5 bei der Verarbeitung von 1 Mio. Kontext langsam ist, ist jedoch hinsichtlich der Geschwindigkeitsverbesserung optimistisch und glaubt, dass die Geschwindigkeit des Langkontextmodells in Zukunft erheblich verbessert wird kann schließlich das gleiche Niveau wie die RAG-Geschwindigkeit erreichen.

Neben Fu Yao haben auch viele andere Forscher ihre Ansichten zu den Aussichten von RAG auf der X-Plattform geäußert, beispielsweise der KI-Blogger @elvis.
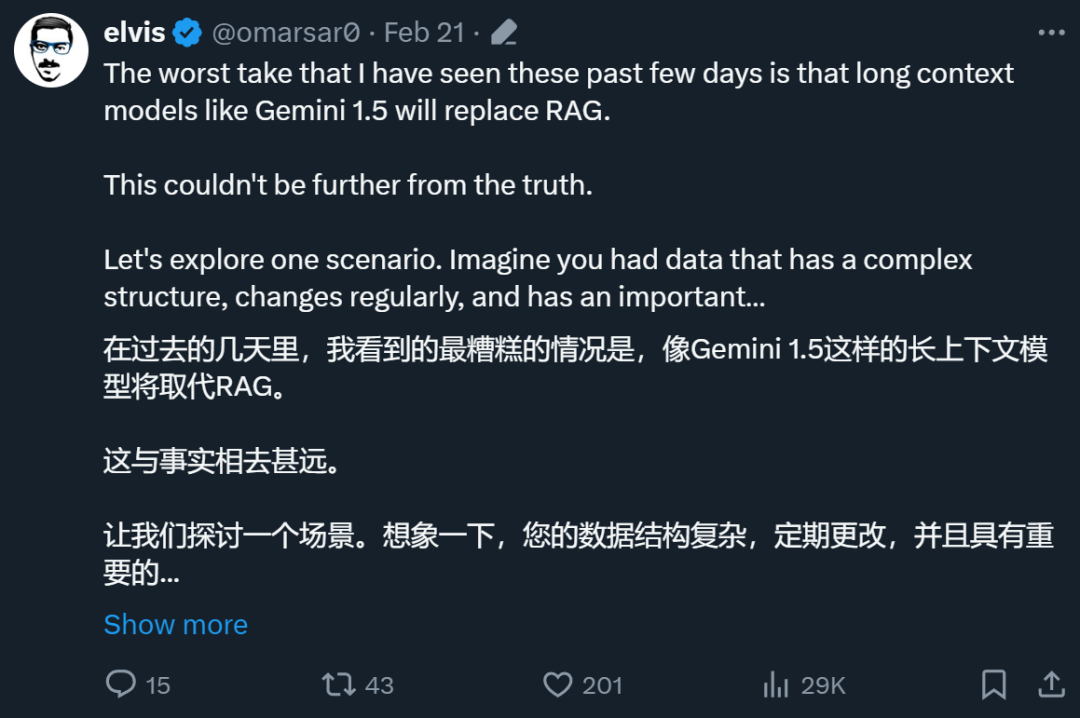
Im Allgemeinen glaubt er nicht, dass das lange Kontextmodell RAG ersetzen kann. Zu den Gründen gehören:
1. Herausforderungen bestimmter Datentypen: @elvis hat ein Szenario vorgeschlagen, bei dem die Daten eine komplexe Struktur haben ändert sich regelmäßig und hat eine wichtige zeitliche Dimension (z. B. Codebearbeitungen/-änderungen und Webprotokolle). Diese Art von Daten kann mit historischen Datenpunkten und möglicherweise mit weiteren Datenpunkten in der Zukunft verknüpft werden. @elvis glaubt, dass die heutigen Sprachmodelle mit langem Kontext allein Anwendungsfälle, die auf solchen Daten basieren, nicht bewältigen können, da die Daten für LLM möglicherweise zu komplex sind und das aktuelle maximale Kontextfenster für solche Daten nicht realisierbar ist. Wenn Sie mit dieser Art von Daten arbeiten, benötigen Sie möglicherweise einen cleveren Abrufmechanismus.
2. Verarbeitung dynamischer Informationen: Das heutige LLM mit langem Kontext schneidet bei der Verarbeitung statischer Informationen (wie Bücher, Videoaufzeichnungen, PDFs usw.) gut ab, wurde jedoch noch nicht in der Praxis getestet, wenn es um die Verarbeitung hochdynamischer Informationen geht Informationen und Wissen. @elvis glaubt, dass wir zwar Fortschritte bei der Lösung einiger Herausforderungen (z. B. „Lost in the Middle“) und beim Umgang mit komplexeren strukturierten und dynamischen Daten machen werden, wir aber noch einen langen Weg vor uns haben.

3. @elvis schlug vor, dass zur Lösung dieser Art von Problemen RAG und Long-Context-LLM kombiniert werden können, um ein leistungsstarkes System aufzubauen, das wichtige historische Informationen effektiv und effizient abrufen und analysieren kann. Er betonte, dass selbst dies in vielen Fällen möglicherweise nicht ausreiche. Gerade weil sich große Datenmengen schnell ändern können, erhöhen KI-basierte Agenten die Komplexität noch weiter. @elvis glaubt, dass es bei komplexen Anwendungsfällen höchstwahrscheinlich eine Kombination dieser Ideen sein wird und nicht ein LLM für allgemeine Zwecke oder einen langen Kontext, der alles ersetzt.
4. Nachfrage nach verschiedenen Arten von LLM: @elvis wies darauf hin, dass nicht alle Daten statisch sind und viele Daten dynamisch sind. Berücksichtigen Sie bei der Betrachtung dieser Anwendungen die drei Vs von Big Data: Geschwindigkeit, Volumen und Vielfalt. @elvis hat diese Lektion durch seine Erfahrung bei einem Suchunternehmen gelernt. Er glaubt, dass verschiedene Arten von LLMs zur Lösung unterschiedlicher Arten von Problemen beitragen werden, und wir müssen uns von der Vorstellung verabschieden, dass ein LLM sie alle beherrschen wird.

@elvis zitierte abschließend Oriol Vinyals (Vizepräsident für Forschung bei Google DeepMind) und erklärte, dass selbst jetzt, wo wir in der Lage seien, Kontexte von 1 Million oder mehr Tokens zu verarbeiten, die Ära der RAG noch lange nicht angebrochen sei über. RAG hat tatsächlich einige sehr nette Funktionen. Diese Eigenschaften können nicht nur durch lange Kontextmodelle verbessert werden, sondern auch lange Kontextmodelle können durch RAG verbessert werden. RAG ermöglicht es uns, relevante Informationen zu finden, aber die Art und Weise, wie das Modell auf diese Informationen zugreift, kann aufgrund der Datenkomprimierung zu eingeschränkt werden. Das Long-Context-Modell kann helfen, diese Lücke zu schließen, ähnlich wie L1/L2-Cache und Hauptspeicher in modernen CPUs zusammenarbeiten. In diesem kollaborativen Modell spielen Cache und Hauptspeicher jeweils unterschiedliche Rollen, ergänzen sich jedoch gegenseitig und erhöhen so die Verarbeitungsgeschwindigkeit und Effizienz. In ähnlicher Weise kann durch die kombinierte Verwendung von RAG und langem Kontext eine flexiblere und effizientere Informationsabfrage und -generierung erreicht werden, wobei ihre jeweiligen Vorteile bei der Bewältigung komplexer Daten und Aufgaben voll ausgenutzt werden.

Es scheint noch nicht entschieden zu sein, „ob die Ära der RAG zu Ende geht“. Viele Leute sagen jedoch, dass das Gemini 1.5 Pro als Modell mit besonders langem Kontextfenster wirklich unterschätzt wird. @elvis gab auch seine Testergebnisse bekannt. „Vorläufiger Bewertungsbericht für Gemini 1.5 Pro“ Er lud eine PDF-Datei hoch und stellte eine einfache Frage: Worum geht es in diesem Artikel?
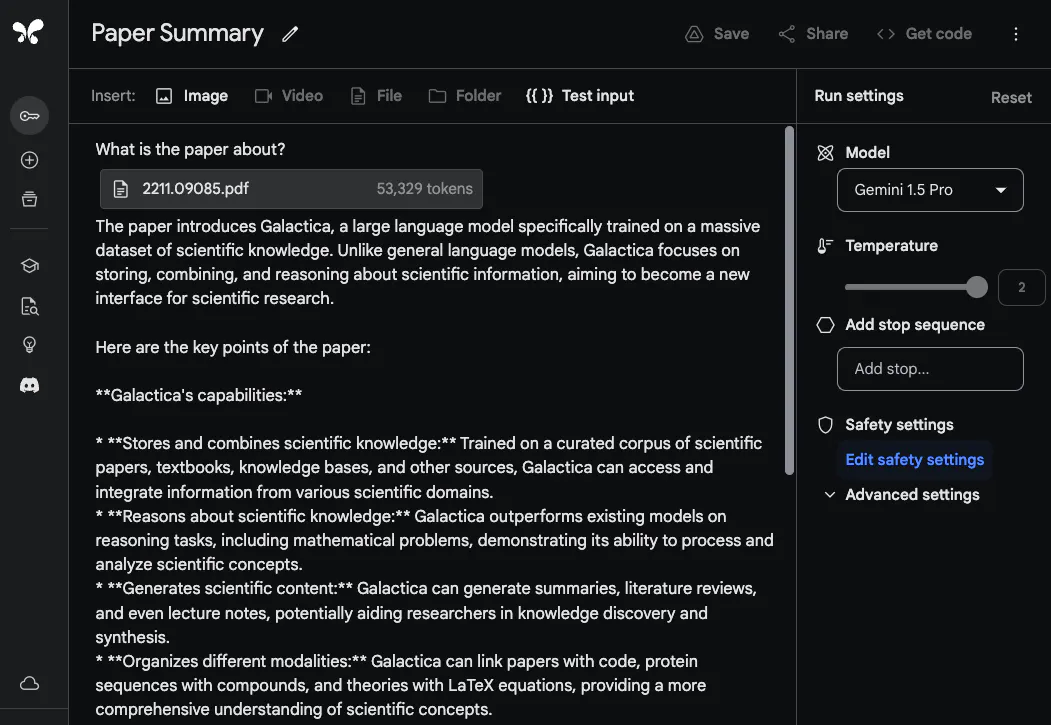
Die Antwort des Modells ist genau und prägnant, da sie eine akzeptable Zusammenfassung des Galactica-Papiers liefert. Das obige Beispiel verwendet Freiform-Eingabeaufforderungen in Google AI Studio, Sie können jedoch auch das Chat-Format verwenden, um mit hochgeladenen PDFs zu interagieren. Dies ist eine sehr nützliche Funktion, wenn Sie viele Fragen haben, die Sie anhand der bereitgestellten Dokumentation beantworten möchten.
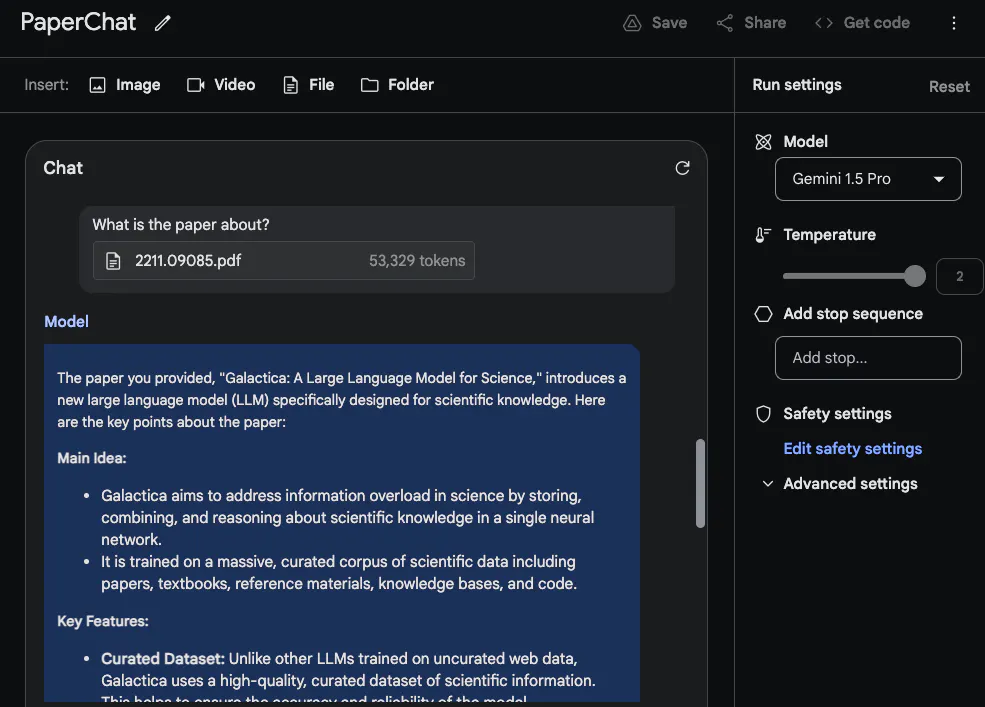
Um das lange Kontextfenster optimal zu nutzen, hat @elvis als nächstes zwei PDFs zum Testen hochgeladen und eine Frage gestellt, die sich über beide PDFs erstreckte. Die Antwort von
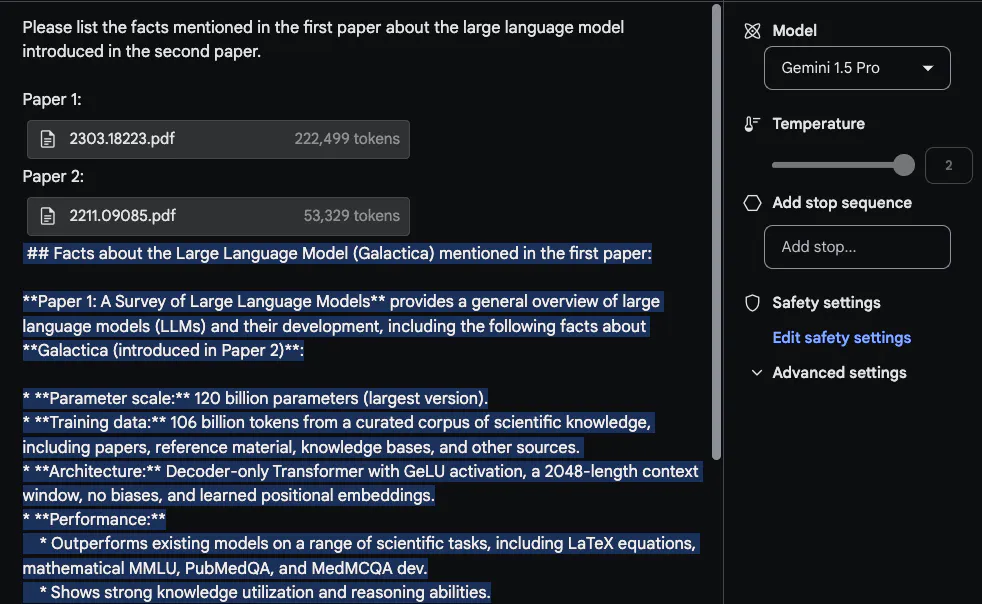
Gemini 1.5 Pro ist angemessen. Interessanterweise stammen die aus dem ersten Artikel (einem Übersichtsartikel zu LLM) extrahierten Informationen aus einer Tabelle. Auch die Angaben zur „Architektur“ scheinen korrekt zu sein. Der Teil „Leistung“ gehört jedoch nicht zu diesem Abschnitt, da er im ersten Artikel nicht enthalten war. Bei dieser Aufgabe ist es wichtig, die Aufforderung „Bitte listen Sie die im ersten Aufsatz erwähnten Fakten über das im zweiten Aufsatz eingeführte große Sprachmodell auf“ oben zu platzieren und den Aufsatz zu beschriften, z. B. „Aufsatz 1“ und „Aufsatz 2“. ". Eine weitere damit verbundene Folgeaufgabe zu diesem Labor besteht darin, eine verwandte Arbeit zu verfassen, indem Sie eine Reihe von Aufsätzen und Anweisungen zu deren Zusammenfassung hochladen. Eine weitere interessante Aufgabe bestand darin, das Modell dazu aufzufordern, neuere LLM-Artikel in eine Rezension einzubeziehen.
Video Understanding
Gemini 1.5 Pro ist von Anfang an auf multimodale Daten trainiert. @elvis hat einige Eingabeaufforderungen anhand des aktuellen LLM-Vorlesungsvideos von Andrej Karpathy getestet:
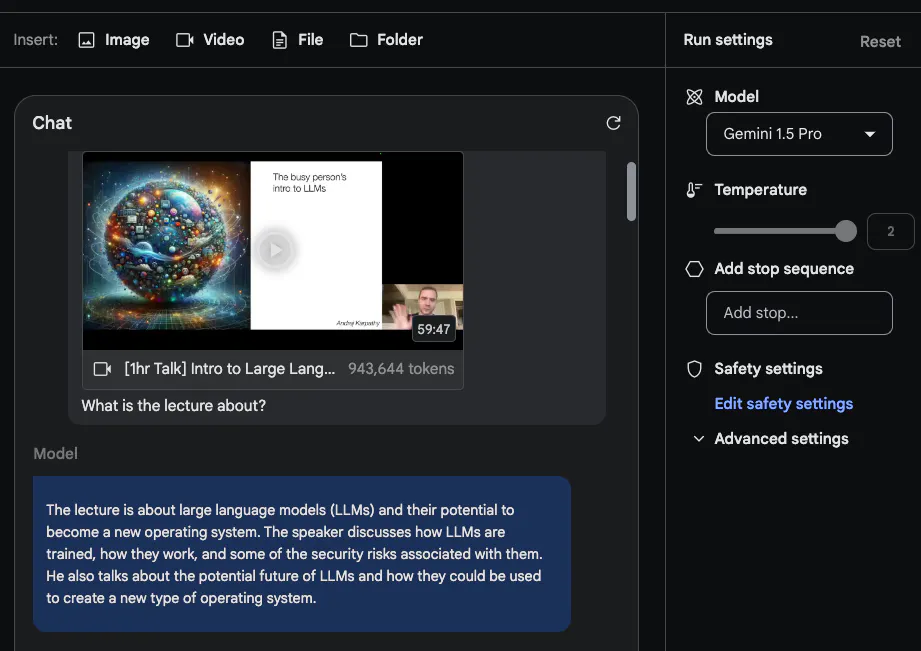
Die zweite Aufgabe, die er dem Modell stellen sollte, bestand darin, einen prägnanten und prägnanten Überblick über die Vorlesung zu geben (eine Seite lang). Die Antworten lauten wie folgt (der Kürze halber bearbeitet):

Die Zusammenfassung von Gemini 1.5 Pro ist sehr prägnant und fasst den Vorlesungsinhalt und die wichtigsten Punkte gut zusammen.
Wenn bestimmte Details wichtig sind, beachten Sie bitte, dass Models aus verschiedenen Gründen manchmal „halluzinieren“ oder falsche Informationen abrufen können. Wenn dem Modell beispielsweise die folgende Frage gestellt wird: „Welche FLOPs wurden in der Vorlesung für Lama 2 gemeldet?“, lautet die Antwort „Die Vorlesung berichtet, dass das Training von Lama 2 70B etwa 1 Billion FLOPs erfordert“, was ungenau ist. Die richtige Antwort sollte „~1e24 FLOPs“ lauten. Der technische Bericht enthält zahlreiche Beispiele dafür, wo diese Long-Context-Modelle ins Stolpern geraten, wenn ihnen spezifische Fragen zu Videos gestellt werden.
Die nächste Aufgabe besteht darin, Tabelleninformationen aus dem Video zu extrahieren. Testergebnisse zeigen, dass das Modell in der Lage ist, Tabellen zu generieren, in denen einige Details richtig und andere falsch sind. Beispielsweise sind die Spalten der Tabelle korrekt, aber die Bezeichnung für eine der Zeilen ist falsch (d. h. Concept Resolution sollte Coref Resolution lauten). Tester haben einige dieser Extraktionsaufgaben mit anderen Tabellen und anderen unterschiedlichen Elementen (z. B. Textfeldern) getestet und ähnliche Inkonsistenzen festgestellt.
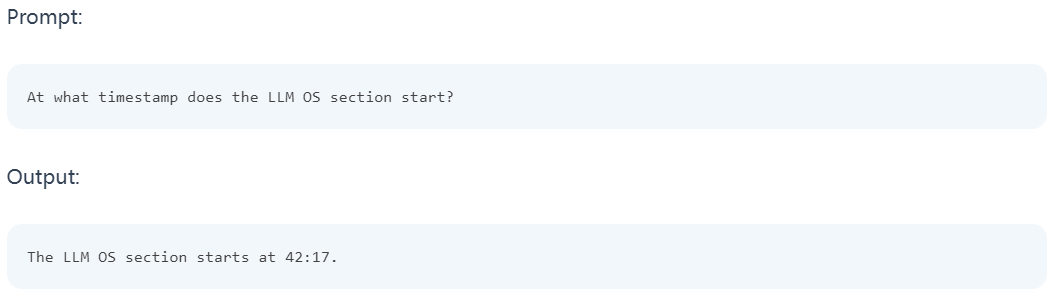
Ein interessantes Beispiel, das im technischen Bericht dokumentiert ist, ist die Fähigkeit des Modells, Details aus einem Video basierend auf einer bestimmten Szene oder einem Zeitstempel abzurufen. Im ersten Beispiel fragt der Tester das Modell, wo ein bestimmter Teil beginnt. Das Modell hat richtig geantwortet.
Im nächsten Beispiel bat er das Modell, eine Grafik auf der Folie zu erklären. Das Modell scheint die bereitgestellten Informationen gut zu nutzen, um die Ergebnisse in der Grafik zu erklären.

Nachfolgend ein Schnappschuss der entsprechenden Slideshow:
@elvis sagte, dass er mit der zweiten Testrunde begonnen habe und interessierte Schüler auf die X-Plattform gehen können, um zuzusehen.
Das obige ist der detaillierte Inhalt vonDas 10-M-Kontextfenster von Google tötet RAG? Werden Zwillinge unterschätzt, nachdem sie von Sora aus dem Rampenlicht gestohlen wurden?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 So fügen Sie eine neue Spalte in SQL hinzu
Apr 09, 2025 pm 02:09 PM
So fügen Sie eine neue Spalte in SQL hinzu
Apr 09, 2025 pm 02:09 PM
Fügen Sie einer vorhandenen Tabelle in SQL neue Spalten hinzu, indem Sie die Anweisung für die Änderung Tabelle verwenden. Zu den spezifischen Schritten gehören: Ermittlung des Tabellennamens und Spalteninformationen, Schreiben von Alter Tabellenanweisungen und Ausführungsanweisungen. Fügen Sie beispielsweise eine E -Mail -Spalte in die Tabelle der Kunden hinzu (VARCHAR (50)): Änderung der Tabelle Kunden addieren Sie E -Mail -Varchar (50).
 Was ist die Syntax zum Hinzufügen von Spalten in SQL
Apr 09, 2025 pm 02:51 PM
Was ist die Syntax zum Hinzufügen von Spalten in SQL
Apr 09, 2025 pm 02:51 PM
Die Syntax zum Hinzufügen von Spalten in SQL ist Alter table table_name add column_name data_type [nicht null] [Standard default_value]; Wenn table_name der Tabellenname ist, ist Column_Name der neue Spaltenname, Data_Type ist der Datentyp, nicht null Gibt an, ob Nullwerte zulässig sind, und Standard Standard_Value gibt den Standardwert an.
 SQL Clear Tabelle: Tipps zur Leistungsoptimierung
Apr 09, 2025 pm 02:54 PM
SQL Clear Tabelle: Tipps zur Leistungsoptimierung
Apr 09, 2025 pm 02:54 PM
Tipps zur Verbesserung der SQL -Tabellenlösungsleistung: Verwenden Sie die Truncate -Tabelle anstelle des Löschens, löschen Sie den Speicherplatz und setzen Sie die Identitätsspalte zurück. Deaktivieren Sie fremde Schlüsselbeschränkungen, um die Kaskadierung der Löschung zu verhindern. Verwenden Sie Transaktionskapselungsvorgänge, um die Datenkonsistenz sicherzustellen. Batch löschen Big Data und begrenzen Sie die Anzahl der Zeilen durch die Grenze. Bauen Sie den Index nach dem Löschen neu auf, um die Effizienz der Abfrage zu verbessern.
 So setzen Sie Standardwerte beim Hinzufügen von Spalten in SQL
Apr 09, 2025 pm 02:45 PM
So setzen Sie Standardwerte beim Hinzufügen von Spalten in SQL
Apr 09, 2025 pm 02:45 PM
Legen Sie den Standardwert für neu hinzugefügte Spalten fest, verwenden Sie die Anweisung für die Änderung der Tabelle: Hinzufügen von Spalten angeben und den Standardwert: Alter Table table_name hinzufügen column_name data_type Standard default_value; Verwenden Sie die Einschränkungsklausel, um den Standardwert anzugeben: Alter Table Table_Name add Column_Name Data_type Einschränkung default_constraint default default_value;
 Verwenden Sie die Löschanweisung, um SQL -Tabellen zu löschen
Apr 09, 2025 pm 03:00 PM
Verwenden Sie die Löschanweisung, um SQL -Tabellen zu löschen
Apr 09, 2025 pm 03:00 PM
Ja, mit der Anweisung Löschen kann eine SQL -Tabelle gelöscht werden. TABLE_NAME ERSETZEN AUS DER NAME DER TABELLE, DIE DELDET.
 Wie geht es mit Redis -Speicherfragmentierung um?
Apr 10, 2025 pm 02:24 PM
Wie geht es mit Redis -Speicherfragmentierung um?
Apr 10, 2025 pm 02:24 PM
Redis -Gedächtnisfragmentierung bezieht sich auf die Existenz kleiner freier Bereiche in dem zugewiesenen Gedächtnis, die nicht neu zugewiesen werden können. Zu den Bewältigungsstrategien gehören: Neustart von Redis: Der Gedächtnis vollständig löschen, aber den Service unterbrechen. Datenstrukturen optimieren: Verwenden Sie eine Struktur, die für Redis besser geeignet ist, um die Anzahl der Speicherzuweisungen und -freisetzungen zu verringern. Konfigurationsparameter anpassen: Verwenden Sie die Richtlinie, um die kürzlich verwendeten Schlüsselwertpaare zu beseitigen. Verwenden Sie den Persistenzmechanismus: Daten regelmäßig sichern und Redis neu starten, um Fragmente zu beseitigen. Überwachen Sie die Speicherverwendung: Entdecken Sie die Probleme rechtzeitig und ergreifen Sie Maßnahmen.
 PhpMyAdmin erstellt Datentabelle
Apr 10, 2025 pm 11:00 PM
PhpMyAdmin erstellt Datentabelle
Apr 10, 2025 pm 11:00 PM
Um eine Datentabelle mithilfe von PHPMYADMIN zu erstellen, sind die folgenden Schritte unerlässlich: Stellen Sie eine Verbindung zur Datenbank her und klicken Sie auf die neue Registerkarte. Nennen Sie die Tabelle und wählen Sie die Speichermotor (innoDB empfohlen). Fügen Sie Spaltendetails hinzu, indem Sie auf die Taste der Spalte hinzufügen, einschließlich Spaltenname, Datentyp, ob Nullwerte und andere Eigenschaften zuzulassen. Wählen Sie eine oder mehrere Spalten als Primärschlüssel aus. Klicken Sie auf die Schaltfläche Speichern, um Tabellen und Spalten zu erstellen.
 Erstellen einer Oracle -Datenbank So erstellen Sie eine Oracle -Datenbank
Apr 11, 2025 pm 02:33 PM
Erstellen einer Oracle -Datenbank So erstellen Sie eine Oracle -Datenbank
Apr 11, 2025 pm 02:33 PM
Das Erstellen einer Oracle -Datenbank ist nicht einfach, Sie müssen den zugrunde liegenden Mechanismus verstehen. 1. Sie müssen die Konzepte von Datenbank und Oracle DBMS verstehen. 2. Beherrschen Sie die Kernkonzepte wie SID, CDB (Containerdatenbank), PDB (Pluggable -Datenbank); 3.. Verwenden Sie SQL*Plus, um CDB zu erstellen und dann PDB zu erstellen. Sie müssen Parameter wie Größe, Anzahl der Datendateien und Pfade angeben. 4. Erweiterte Anwendungen müssen den Zeichensatz, den Speicher und andere Parameter anpassen und die Leistungsstimmung durchführen. 5. Achten Sie auf Speicherplatz, Berechtigungen und Parametereinstellungen und überwachen und optimieren Sie die Datenbankleistung kontinuierlich. Nur indem Sie es geschickt beherrschen, müssen Sie die Erstellung und Verwaltung von Oracle -Datenbanken wirklich verstehen.
