

Kann generative KI die Telekommunikationsbranche retten?


Auf der kürzlich stattfindenden MWC 2024-Konferenz veröffentlichte NVIDIA eine Reihe von Ankündigungen, darunter die Zusammenarbeit mit ARM, ServiceNow und SoftBank, die Gründung der AI-RAN Alliance und eine wichtige Vereinbarung mit Telenor Telenor hat Zugriff auf Nvidias neueste Hardware und Unternehmens-KI-Software, um die zahlreichen Anwendungsfälle künstlicher Intelligenz zu unterstützen, die in seinem Betrieb zum Einsatz kommen.
Untersuchung der breiteren Beziehung zwischen der Telekommunikationsbranche und generativer KI
Chris Penrose, Leiter der globalen Telekommunikationsgeschäftsentwicklung bei NVIDIA, führte in einem Interview mit eine eingehende Studie über die tiefere Verbindung zwischen der Telekommunikationsbranche und generativer KI durch Branchenmedien.
Auf die Frage nach dem größten Problem der Telekommunikationsbranche sagte er: „Ich würde sagen, dass Telekommunikationsunternehmen derzeit stark in 5G investieren, aber das führt nicht unbedingt zu einer erheblichen Umsatzsteigerung. Sie müssen Wege finden.“ Um eine Kapitalrendite sicherzustellen, waren in der Anfangszeit viele Leute von Killeranwendungen begeistert, die diesen Wert nutzen würden, und ich denke, wir befinden uns jetzt tatsächlich in einem interessanten Moment, weil ich glaube, dass generative KI das Potenzial hat, Killer zu sein . Anwendungen, und das ist im Entstehen
Da bestehende Anwendungen generative KI als Teil ihrer Benutzeroberfläche verwenden, gibt es jetzt wirklich eine Chance, sei es die Bereitstellung von Infrastruktur als Dienst, sei es die Bereitstellung von Schulungen als Dienst oder Inferenz As-a-Service und sogar KI-Anwendungen sind völlig neue Möglichkeiten, die durch generative KI vorangetrieben werden, und Telekommunikationsunternehmen versuchen, generative KI zu nutzen, um zusätzliche Einnahmen zu generieren, die es ihnen ermöglichen, die 5G-Grundlage auf die Art und Weise zu nutzen, wie sie es tun „Alle wollen. Einrichtungen.“ notwendigerweise im Mittelpunkt des Fahrverhaltens. Derzeit ist generative KI ein zentraler Geschäftsschwerpunkt großer Technologieunternehmen wie Google und Microsoft.
Penrose sagte: „Wir sehen, dass viele Telekommunikationsunternehmen Maßnahmen ergreifen, weil dies die nächste Welle der Technologie ist. Viele Länder und Regionen stellen die Frage: ‚Welche Art von Infrastruktur brauchen wir, um dies voranzutreiben?‘ „? KI-Prozess?“ Das nennen wir die Einrichtung von KI-Fabriken oder die Einrichtung souveräner KI-Clouds in diesen Ländern. Denken die Menschen also zunehmend darüber nach, wie sie in diesem Bereich eine Rolle spielen können? und betreiben ihre eigenen Rechenzentren mit ausreichend Platz und Strom, was die Benutzer wirklich brauchen, und Telekommunikationsunternehmen wissen, wie man große Infrastrukturprojekte durchführt
Dies ist eine sehr spezifische Art von Build, die dies erfordert. Um generative KI wirklich freizuschalten Hunderte oder Tausende von GPUs zu haben, um auf KI-Modellen trainieren zu können, und das sieht nicht unbedingt nach einer Standardbereitstellung aus, also müssen wir sie ermutigen, einen Schritt weiter zu gehen. Dies ist eine Entscheidung, die Telekommunikationsunternehmen treffen müssen Und sie müssen sich auf diese Reise begeben. Sie haben viele Vorteile, wie zum Beispiel enge Beziehungen zu Regierungsbehörden, eine gute Zusammenarbeit mit Geschäftskunden und sie sind vertrauenswürdige Partner in ihren eigenen Ländern. Können sie dabei wirklich an vorderster Front stehen? technologische Welle?“Das obige ist der detaillierte Inhalt vonKann generative KI die Telekommunikationsbranche retten?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.
Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Diese Seite berichtete am 27. Juni, dass Jianying eine von FaceMeng Technology, einer Tochtergesellschaft von ByteDance, entwickelte Videobearbeitungssoftware ist, die auf der Douyin-Plattform basiert und grundsätzlich kurze Videoinhalte für Benutzer der Plattform produziert Windows, MacOS und andere Betriebssysteme. Jianying kündigte offiziell die Aktualisierung seines Mitgliedschaftssystems an und führte ein neues SVIP ein, das eine Vielzahl von KI-Schwarztechnologien umfasst, wie z. B. intelligente Übersetzung, intelligente Hervorhebung, intelligente Verpackung, digitale menschliche Synthese usw. Preislich beträgt die monatliche Gebühr für das Clipping von SVIP 79 Yuan, die Jahresgebühr 599 Yuan (Hinweis auf dieser Website: entspricht 49,9 Yuan pro Monat), das fortlaufende Monatsabonnement beträgt 59 Yuan pro Monat und das fortlaufende Jahresabonnement beträgt 499 Yuan pro Jahr (entspricht 41,6 Yuan pro Monat). Darüber hinaus erklärte der Cut-Beamte auch, dass diejenigen, die den ursprünglichen VIP abonniert haben, das Benutzererlebnis verbessern sollen
 Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Verbessern Sie die Produktivität, Effizienz und Genauigkeit der Entwickler, indem Sie eine abrufgestützte Generierung und ein semantisches Gedächtnis in KI-Codierungsassistenten integrieren. Übersetzt aus EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, Autor JanakiramMSV. Obwohl grundlegende KI-Programmierassistenten natürlich hilfreich sind, können sie oft nicht die relevantesten und korrektesten Codevorschläge liefern, da sie auf einem allgemeinen Verständnis der Softwaresprache und den gängigsten Mustern beim Schreiben von Software basieren. Der von diesen Coding-Assistenten generierte Code eignet sich zur Lösung der von ihnen zu lösenden Probleme, entspricht jedoch häufig nicht den Coding-Standards, -Konventionen und -Stilen der einzelnen Teams. Dabei entstehen häufig Vorschläge, die geändert oder verfeinert werden müssen, damit der Code in die Anwendung übernommen wird
 Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) werden auf riesigen Textdatenbanken trainiert und erwerben dort große Mengen an realem Wissen. Dieses Wissen wird in ihre Parameter eingebettet und kann dann bei Bedarf genutzt werden. Das Wissen über diese Modelle wird am Ende der Ausbildung „verdinglicht“. Am Ende des Vortrainings hört das Modell tatsächlich auf zu lernen. Richten Sie das Modell aus oder verfeinern Sie es, um zu erfahren, wie Sie dieses Wissen nutzen und natürlicher auf Benutzerfragen reagieren können. Aber manchmal reicht Modellwissen nicht aus, und obwohl das Modell über RAG auf externe Inhalte zugreifen kann, wird es als vorteilhaft angesehen, das Modell durch Feinabstimmung an neue Domänen anzupassen. Diese Feinabstimmung erfolgt mithilfe von Eingaben menschlicher Annotatoren oder anderer LLM-Kreationen, wobei das Modell auf zusätzliches Wissen aus der realen Welt trifft und dieses integriert
 Das NVIDIA-Dialogmodell ChatQA wurde auf Version 2.0 weiterentwickelt, wobei die angegebene Kontextlänge 128 KB beträgt
Jul 26, 2024 am 08:40 AM
Das NVIDIA-Dialogmodell ChatQA wurde auf Version 2.0 weiterentwickelt, wobei die angegebene Kontextlänge 128 KB beträgt
Jul 26, 2024 am 08:40 AM
Die offene LLM-Community ist eine Ära, in der hundert Blumen blühen und konkurrieren. Sie können Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 und viele andere sehen hervorragende Darsteller. Allerdings weisen offene Modelle im Vergleich zu den proprietären Großmodellen GPT-4-Turbo in vielen Bereichen noch erhebliche Lücken auf. Zusätzlich zu allgemeinen Modellen wurden einige offene Modelle entwickelt, die sich auf Schlüsselbereiche spezialisieren, wie etwa DeepSeek-Coder-V2 für Programmierung und Mathematik und InternVL für visuelle Sprachaufgaben.
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
Herausgeber |. KX Im Bereich der Arzneimittelforschung und -entwicklung ist die genaue und effektive Vorhersage der Bindungsaffinität von Proteinen und Liganden für das Arzneimittelscreening und die Arzneimitteloptimierung von entscheidender Bedeutung. Aktuelle Studien berücksichtigen jedoch nicht die wichtige Rolle molekularer Oberflächeninformationen bei Protein-Ligand-Wechselwirkungen. Auf dieser Grundlage schlugen Forscher der Universität Xiamen ein neuartiges Framework zur multimodalen Merkmalsextraktion (MFE) vor, das erstmals Informationen über Proteinoberfläche, 3D-Struktur und -Sequenz kombiniert und einen Kreuzaufmerksamkeitsmechanismus verwendet, um verschiedene Modalitäten zu vergleichen Ausrichtung. Experimentelle Ergebnisse zeigen, dass diese Methode bei der Vorhersage von Protein-Ligand-Bindungsaffinitäten Spitzenleistungen erbringt. Darüber hinaus belegen Ablationsstudien die Wirksamkeit und Notwendigkeit der Proteinoberflächeninformation und der multimodalen Merkmalsausrichtung innerhalb dieses Rahmens. Verwandte Forschungen beginnen mit „S
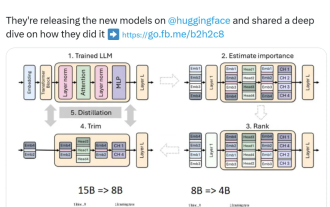 Nvidia spielt mit Beschneidung und Destillation: Halbierung der Llama 3.1 8B-Parameter, um bei gleicher Größe eine bessere Leistung zu erzielen
Aug 16, 2024 pm 04:42 PM
Nvidia spielt mit Beschneidung und Destillation: Halbierung der Llama 3.1 8B-Parameter, um bei gleicher Größe eine bessere Leistung zu erzielen
Aug 16, 2024 pm 04:42 PM
Der Aufstieg kleiner Modelle. Letzten Monat veröffentlichte Meta die Modellreihe Llama3.1, zu der das bisher größte Modell von Meta, das 405B-Modell, und zwei kleinere Modelle mit Parameterbeträgen von 70 Milliarden bzw. 8 Milliarden gehören. Llama3.1 gilt als der Beginn einer neuen Ära von Open Source. Obwohl die Modelle der neuen Generation leistungsstark sind, erfordern sie bei der Bereitstellung immer noch große Mengen an Rechenressourcen. Daher hat sich in der Branche ein weiterer Trend herausgebildet, der darin besteht, kleine Sprachmodelle (SLM) zu entwickeln, die bei vielen Sprachaufgaben eine ausreichende Leistung erbringen und zudem sehr kostengünstig in der Bereitstellung sind. Kürzlich haben Untersuchungen von NVIDIA gezeigt, dass durch strukturierte Gewichtsbereinigung in Kombination mit Wissensdestillation nach und nach kleinere Sprachmodelle aus einem zunächst größeren Modell gewonnen werden können. Turing-Preisträger, Meta Chief A
 Nvidia veröffentlicht die GDDR6-Speicherversion der GeForce RTX 4070-Grafikkarte, erhältlich ab September
Aug 21, 2024 am 07:31 AM
Nvidia veröffentlicht die GDDR6-Speicherversion der GeForce RTX 4070-Grafikkarte, erhältlich ab September
Aug 21, 2024 am 07:31 AM
Laut Nachrichten dieser Website vom 20. August berichteten mehrere Quellen im Juli, dass Grafikkarten vom Typ Nvidia RTX4070 und höher im August aufgrund des Mangels an GDDR6X-Videospeicher knapp sein werden. Anschließend verbreiteten sich im Internet Spekulationen über die Einführung einer GDDR6-Speicherversion der RTX4070-Grafikkarte. Wie diese Seite bereits berichtete, hat Nvidia heute den GameReady-Treiber für „Black Myth: Wukong“ und „Star Wars: Outlaws“ veröffentlicht. Gleichzeitig wurde in der Pressemitteilung auch die Veröffentlichung der GDDR6-Videospeicherversion der GeForce RTX4070 erwähnt. Nvidia gab an, dass die Spezifikationen des neuen RTX4070 mit Ausnahme des Videospeichers unverändert bleiben (natürlich wird auch weiterhin der Preis von 4.799 Yuan beibehalten) und eine ähnliche Leistung wie die Originalversion in Spielen und Anwendungen bieten und verwandte Produkte auf den Markt gebracht werden aus
