

CentOS TiDB-Installation


CentOS-Installations-Tracert
Benutzer, die mit LINUX-Systemen vertraut sind, wissen, dass die Installation einiger gängiger Software unter CentOS auf Herausforderungen stoßen kann. Denn im Gegensatz zu anderen Betriebssystemen installiert CentOS keine gängige Software vor. Heute stellen wir vor, wie man TiDB und Tracert unter CentOS installiert.
TiDB ist ein verteiltes Open-Source-Datenbanksystem mit horizontaler Skalierbarkeit und hoher Verfügbarkeit. Es eignet sich sehr gut für die Verarbeitung umfangreicher Online-Transaktionen und Online-Analysen. Als Nächstes stellen wir die Schritte zur Installation von TiDB auf dem CentOS-Betriebssystem vor.
1. Sie müssen Docker unter CentOS installieren. Sie können den folgenden Befehl verwenden, um Docker zu installieren:
“`
sudo lecker, installiere Docker
2. Nach der Installation von Docker müssen Sie den Docker-Dienst starten:
sudo systemctl start docker
3. Als nächstes müssen Sie das Docker-Image von TiDB herunterladen. Sie können den folgenden Befehl verwenden:
Docker Pull Pingcap/Tidb
4. Nachdem der Download abgeschlossen ist, können Sie den TiDB-Container ausführen:
docker run -d –name tidb-server -p 4000:4000 pingcap/tidb
5. Nachdem Sie TiDB erfolgreich auf CentOS installiert haben, können Sie über Port 4000 auf TiDB zugreifen.
tracert ist ein Befehlszeilentool zum Verfolgen des Paketroutings. Es kann Ihnen helfen, den Pfad von Paketen von der Quelle zum Ziel anzuzeigen. Lassen Sie uns vorstellen, wie Sie Tracert unter CentOS installieren
1. Sie müssen das Traceroute-Paket installieren. Sie können den folgenden Befehl verwenden, um Traceroute zu installieren:sudo yum installiere Traceroute
2. Nachdem die Installation abgeschlossen ist, können Sie den folgenden Befehl verwenden, um die Route des Pakets zu verfolgen:
traceroute www.example.com
3. Tracert zeigt die IP-Adresse und die Verzögerungszeit jedes Routers an, den das Datenpaket passiert, und hilft Ihnen so, den Übertragungspfad des Datenpakets anzuzeigen.
Durch die oben genannten Schritte können Sie TiDB und Tracert erfolgreich auf CentOS installieren und für die Datenbankverwaltung und Netzwerkroutenverfolgung verwenden.
LINUX teilt es mit Ihnen
In Linux-Systemen können Sie den Befehl „ps“ verwenden, um die im aktuellen System laufenden Prozesse anzuzeigen, zum Beispiel:ps aux
Dieser Befehl listet alle Prozesse im System auf und zeigt deren detaillierte Informationen an, einschließlich Prozess-ID, CPU-Auslastung, Speichernutzung usw. Mit diesem Befehl können Sie die Prozesse im System überwachen und so Ihr System besser verwalten.
Das obige ist der detaillierte Inhalt vonCentOS TiDB-Installation. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Detaillierte Schritte zum Bereinigen des Speichers in Xiaohongshu
Apr 26, 2024 am 10:43 AM
Detaillierte Schritte zum Bereinigen des Speichers in Xiaohongshu
Apr 26, 2024 am 10:43 AM
1. Öffnen Sie Xiaohongshu, klicken Sie unten rechts auf „Ich“. 2. Klicken Sie auf das Einstellungssymbol und dann auf „Allgemein“. 3. Klicken Sie auf „Cache leeren“.
 Was tun, wenn Ihr Huawei-Telefon nicht über genügend Speicher verfügt (Praktische Methoden zur Lösung des Problems des unzureichenden Speichers)
Apr 29, 2024 pm 06:34 PM
Was tun, wenn Ihr Huawei-Telefon nicht über genügend Speicher verfügt (Praktische Methoden zur Lösung des Problems des unzureichenden Speichers)
Apr 29, 2024 pm 06:34 PM
Unzureichender Speicher auf Huawei-Mobiltelefonen ist mit der Zunahme mobiler Anwendungen und Mediendateien zu einem häufigen Problem geworden, mit dem viele Benutzer konfrontiert sind. Um Benutzern zu helfen, den Speicherplatz ihres Mobiltelefons voll auszunutzen, werden in diesem Artikel einige praktische Methoden vorgestellt, um das Problem des unzureichenden Speichers auf Huawei-Mobiltelefonen zu lösen. 1. Cache bereinigen: Verlaufsdatensätze und ungültige Daten, um Speicherplatz freizugeben und von Anwendungen generierte temporäre Dateien zu löschen. Suchen Sie in den Huawei-Telefoneinstellungen nach „Speicher“, klicken Sie auf die Schaltfläche „Cache löschen“ und löschen Sie dann die Cache-Dateien der Anwendung. 2. Deinstallieren Sie selten verwendete Anwendungen: Um Speicherplatz freizugeben, löschen Sie einige selten verwendete Anwendungen. Ziehen Sie es an den oberen Rand des Telefonbildschirms, drücken Sie lange auf das Symbol „Deinstallieren“ der Anwendung, die Sie löschen möchten, und klicken Sie dann auf die Bestätigungsschaltfläche, um die Deinstallation abzuschließen. 3.Mobile Anwendung auf
 Wie man Deepseek vor Ort fein abgestimmt
Feb 19, 2025 pm 05:21 PM
Wie man Deepseek vor Ort fein abgestimmt
Feb 19, 2025 pm 05:21 PM
Die lokale Feinabstimmung von Deepseek-Klasse-Modellen steht vor der Herausforderung unzureichender Rechenressourcen und Fachkenntnisse. Um diese Herausforderungen zu bewältigen, können die folgenden Strategien angewendet werden: Modellquantisierung: Umwandlung von Modellparametern in Ganzzahlen mit niedriger Präzision und Reduzierung des Speicherboots. Verwenden Sie kleinere Modelle: Wählen Sie ein vorgezogenes Modell mit kleineren Parametern für eine einfachere lokale Feinabstimmung aus. Datenauswahl und Vorverarbeitung: Wählen Sie hochwertige Daten aus und führen Sie eine geeignete Vorverarbeitung durch, um eine schlechte Datenqualität zu vermeiden, die die Modelleffizienz beeinflusst. Batch -Training: Laden Sie für große Datensätze Daten in Stapel für das Training, um den Speicherüberlauf zu vermeiden. Beschleunigung mit GPU: Verwenden Sie unabhängige Grafikkarten, um den Schulungsprozess zu beschleunigen und die Trainingszeit zu verkürzen.
 Was tun, wenn der Edge-Browser zu viel Speicher beansprucht? Was tun, wenn der Edge-Browser zu viel Speicher beansprucht?
May 09, 2024 am 11:10 AM
Was tun, wenn der Edge-Browser zu viel Speicher beansprucht? Was tun, wenn der Edge-Browser zu viel Speicher beansprucht?
May 09, 2024 am 11:10 AM
1. Rufen Sie zunächst den Edge-Browser auf und klicken Sie auf die drei Punkte in der oberen rechten Ecke. 2. Wählen Sie dann in der Taskleiste [Erweiterungen] aus. 3. Schließen oder deinstallieren Sie als Nächstes die Plug-Ins, die Sie nicht benötigen.
 Für nur 250 US-Dollar zeigt Ihnen der technische Leiter von Hugging Face Schritt für Schritt, wie Sie Llama 3 verfeinern
May 06, 2024 pm 03:52 PM
Für nur 250 US-Dollar zeigt Ihnen der technische Leiter von Hugging Face Schritt für Schritt, wie Sie Llama 3 verfeinern
May 06, 2024 pm 03:52 PM
Die bekannten großen Open-Source-Sprachmodelle wie Llama3 von Meta, Mistral- und Mixtral-Modelle von MistralAI und Jamba von AI21 Lab sind zu Konkurrenten von OpenAI geworden. In den meisten Fällen müssen Benutzer diese Open-Source-Modelle anhand ihrer eigenen Daten verfeinern, um das Potenzial des Modells voll auszuschöpfen. Es ist nicht schwer, ein großes Sprachmodell (wie Mistral) im Vergleich zu einem kleinen mithilfe von Q-Learning auf einer einzelnen GPU zu optimieren, aber die effiziente Feinabstimmung eines großen Modells wie Llama370b oder Mixtral blieb bisher eine Herausforderung . Deshalb Philipp Sch, technischer Leiter von HuggingFace
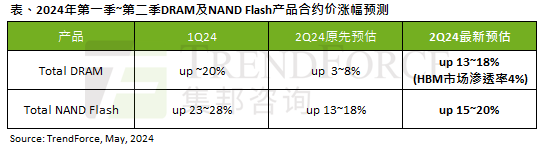 Die Auswirkungen der KI-Welle sind offensichtlich. TrendForce hat seine Prognose für Preiserhöhungen bei DRAM-Speicher und NAND-Flash-Speicher in diesem Quartal nach oben korrigiert.
May 07, 2024 pm 09:58 PM
Die Auswirkungen der KI-Welle sind offensichtlich. TrendForce hat seine Prognose für Preiserhöhungen bei DRAM-Speicher und NAND-Flash-Speicher in diesem Quartal nach oben korrigiert.
May 07, 2024 pm 09:58 PM
Laut einem TrendForce-Umfragebericht hat die KI-Welle erhebliche Auswirkungen auf die Märkte für DRAM-Speicher und NAND-Flash-Speicher. In den Nachrichten dieser Website vom 7. Mai sagte TrendForce heute in seinem neuesten Forschungsbericht, dass die Agentur die Vertragspreiserhöhungen für zwei Arten von Speicherprodukten in diesem Quartal erhöht habe. Konkret schätzte TrendForce ursprünglich, dass der DRAM-Speichervertragspreis im zweiten Quartal 2024 um 3 bis 8 % steigen wird, und schätzt ihn nun auf 13 bis 18 %, bezogen auf NAND-Flash-Speicher, die ursprüngliche Schätzung wird um 13 bis 18 % steigen 18 %, und die neue Schätzung liegt bei 15 %, nur eMMC/UFS weist einen geringeren Anstieg von 10 % auf. ▲Bildquelle TrendForce TrendForce gab an, dass die Agentur ursprünglich damit gerechnet hatte, dies auch weiterhin zu tun
 Auf welche Fallstricke sollten wir beim Entwurf verteilter Systeme mit Golang-Technologie achten?
May 07, 2024 pm 12:39 PM
Auf welche Fallstricke sollten wir beim Entwurf verteilter Systeme mit Golang-Technologie achten?
May 07, 2024 pm 12:39 PM
Fallstricke in der Go-Sprache beim Entwurf verteilter Systeme Go ist eine beliebte Sprache für die Entwicklung verteilter Systeme. Allerdings gibt es bei der Verwendung von Go einige Fallstricke zu beachten, die die Robustheit, Leistung und Korrektheit Ihres Systems beeinträchtigen können. In diesem Artikel werden einige häufige Fallstricke untersucht und praktische Beispiele für deren Vermeidung gegeben. 1. Übermäßiger Gebrauch von Parallelität Go ist eine Parallelitätssprache, die Entwickler dazu ermutigt, Goroutinen zu verwenden, um die Parallelität zu erhöhen. Eine übermäßige Nutzung von Parallelität kann jedoch zu Systeminstabilität führen, da zu viele Goroutinen um Ressourcen konkurrieren und einen Mehraufwand beim Kontextwechsel verursachen. Praktischer Fall: Übermäßiger Einsatz von Parallelität führt zu Verzögerungen bei der Dienstantwort und Ressourcenkonkurrenz, was sich in einer hohen CPU-Auslastung und einem hohen Aufwand für die Speicherbereinigung äußert.
 Was bedeutet sizeof in der C-Sprache?
Apr 29, 2024 pm 07:48 PM
Was bedeutet sizeof in der C-Sprache?
Apr 29, 2024 pm 07:48 PM
sizeof ist ein Operator in C, der die Anzahl der Bytes an Speicher zurückgibt, die von einem bestimmten Datentyp oder einer bestimmten Variablen belegt werden. Es dient den folgenden Zwecken: Bestimmt Datentypgrößen. Dynamische Speicherzuweisung. Erhält Struktur- und Union-Größen. Gewährleistet plattformübergreifende Kompatibilität
